MapReduce Design Patterns
•Download as PPT, PDF•
1 like•1,220 views

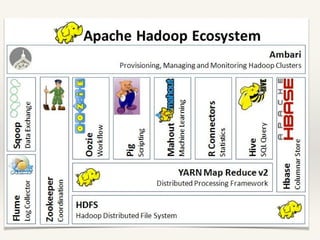
This document discusses MapReduce design patterns. It describes the core MapReduce components including the mapper, reducer, and shuffle and sort. It then outlines several common MapReduce patterns such as filtering, summarization, joins, data organization, and input/output. Specific filtering patterns like bloom filtering and top-N are explained in more detail.












![Pig examples
- - Inner Join:
A = JOIN comments BY userID, users BY userID;
- - Outer Join:
A = JOIN comments BY userID [LEFT | RIFGT| FULL] OUTER , users BY userID;
- - Binning:
SPLIT data INTO
eights IF col1 == 8,
bigs IF col1 > 8,
smalls IF (col1 < 8 and col1 > 0 );
- - Top Ten:
B = ORDER A BY col4 DESC’
C = limit B 10;
- - Filtering:
b = FILTER a BY value < 3;](https://image.slidesharecdn.com/mapreducedesignpatterns-140303100944-phpapp02/85/MapReduce-Design-Patterns-25-320.jpg)
MapReduce Design Patterns
- 1. MapReduce Design Patterns Anastasiia Kornilova, SoftServe Data Science Group
- 2. MapReduce Components ‚ùñ record reader ‚ùñ map ‚ùñ Reader combiner ‚ùñ partitioner ‚ùñ Mapper Combiner Partitioner Shuffle and sort shuffle and sort ‚ùñ reduce ‚ùñ output format Reducer Output
- 4. MapReduce Patterns ‚ùñ Filtering Patterns ‚ùñ Summarization Patterns ‚ùñ Join Patterns ‚ùñ Data Organization Patterns ‚ùñ Metapatterns ‚ùñ Input and Output Patterns
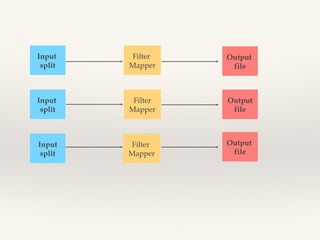
- 6. Filtering ‚ùñ Closer view of data ‚ùñ Tracking a thread of events ‚ùñ Distributed grep ‚ùñ Data cleansing ‚ùñ Simple random sampling ‚ùñ Removing low scoring data
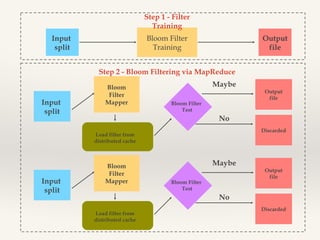
- 8. Bloom filtering ❖ Removing most of non watched values ❖ Prefiltering a data set for an expensive set membership check • • • Probabilistic data structure Hash functions comparing Answer: probably yes or now
- 9. Step 1 - Filter Training Bloom Filter Training Input split Output file Step 2 - Bloom Filtering via MapReduce Input split Bloom Filter Mapper Maybe Bloom Filter Test No Discarded Load filter from distributed cache Input split Output file Bloom Filter Mapper Maybe Bloom Filter Test Output file No Load filter from distributed cache Discarded
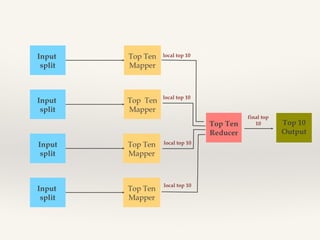
- 10. Top N ‚ùñ Outlier analysis ‚ùñ Select interesting data ‚ùñ Catchy dashboards
- 11. Input split Top Ten Mapper local top 10 Input split Top Ten Mapper local top 10 Top Ten Reducer Input split Top Ten Mapper local top 10 Input split Top Ten Mapper local top 10 final top 10 Top 10 Output
- 12. Distinct ‚ùñ Deduplicate data ‚ùñ Getting distinct values ‚ùñ Protecting from inner join explosions
- 13. Summarization patterns ‚ùñ Numerical summarization ‚ùñ Inverted index ‚ùñ Counting with counters
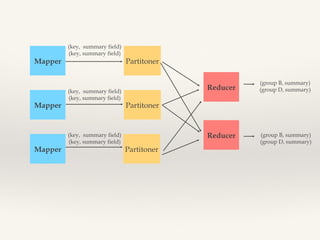
- 14. Numerical summarization ‚ùñ Word count ‚ùñ Record count ‚ùñ Min/Max/Count ‚ùñ Average/Median/Standart deviation
- 15. Mapper Mapper Mapper (key, summary field) (key, summary field) (key, summary field) (key, summary field) (key, summary field) (key, summary field) Partitoner Reducer (group B, summary) (group D, summary) Reducer (group B, summary) (group D, summary) Partitoner Partitoner
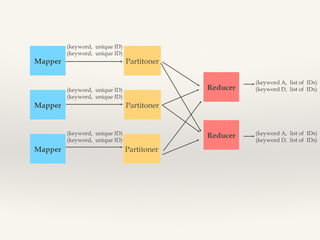
- 16. Inverted index
- 17. Mapper (keyword, unique ID) (keyword, unique ID) Partitoner Reducer Reducer (keyword, unique ID) (keyword, unique ID) (keyword A, list of IDs) (keyword D, list of IDs) Partitoner Mapper (keyword, unique ID) (keyword, unique ID) Mapper (keyword A, list of IDs) (keyword D, list of IDs) Partitoner
- 18. Data Organization Patterns ‚ùñ Structured to Hierarchical ‚ùñ Partitioning ‚ùñ Binning ‚ùñ Total Order Sorting ‚ùñ Shuffling
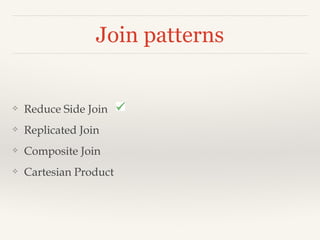
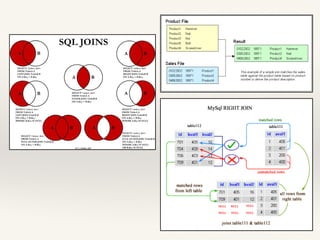
- 19. Join patterns ‚ùñ Reduce Side Join ‚ùñ Replicated Join ‚ùñ Composite Join ‚ùñ Cartesian Product
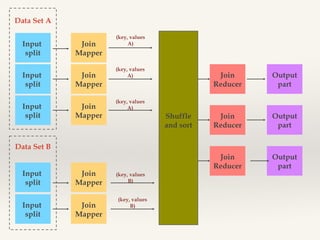
- 21. Data Set A Input split Input split Input split Join Mapper Join Mapper Join Mapper (key, values A) (key, values A) Join Reducer Output part Join Reducer Output part Join Reducer Output part (key, values A) Shuffle and sort Data Set B Input split Input split Join Mapper Join Mapper (key, values B) (key, values B)
- 22. Node table id title tagnames authorized User table body node type parent id abs parent id added at score state string last edited id last activity id last activity at activity revision extra extra def extra count user id reputation gold silver bronze
- 25. Pig examples - - Inner Join: A = JOIN comments BY userID, users BY userID; - - Outer Join: A = JOIN comments BY userID [LEFT | RIFGT| FULL] OUTER , users BY userID; - - Binning: SPLIT data INTO eights IF col1 == 8, bigs IF col1 > 8, smalls IF (col1 < 8 and col1 > 0 ); - - Top Ten: B = ORDER A BY col4 DESC’ C = limit B 10; - - Filtering: b = FILTER a BY value < 3;