Me12tt tub
0 likes198 views

The document evaluates different feature selection methods for bag-of-words approaches to video categorization. It finds that feature selection can improve results by filtering out non-informative terms. Metadata-based features like tags and descriptions generally outperform visual and audio features, but feature selection provides benefits across different feature types. The best performance comes from combining multiple feature types with transformation and selection techniques.














Me12tt tub
- 1. Feature Selection Methods for Bag- of-(visual)-Words Approaches Schmiedeke, Kelm and Sikora Communication Systems Group Technische Universit├żt Berlin 4 October, 2012
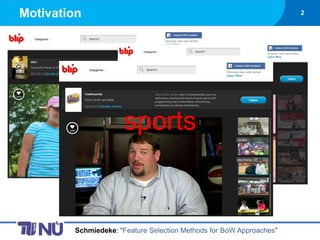
- 2. Motivation 2 sports Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
- 3. Lessons from last year 3 Features derived from metadata (esp. tags) outperform visual and ASR ones ŌĆó Metadata: Naive Bayes (non translated) ŌĆó Visual feat.: SVM (avg. pooled histograms) ŌĆó ASR transcripts: kNN (JSD) Uploader mainly contribute to a single category Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
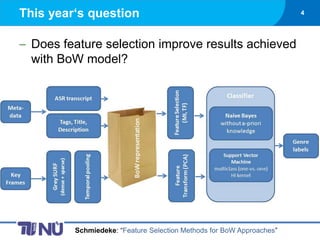
- 4. This yearŌĆśs question 4 Does feature selection improve results achieved with BoW model? Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
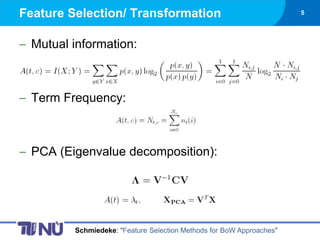
- 5. Feature Selection/ Transformation 5 Mutual information: Term Frequency: PCA (Eigenvalue decomposition): Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
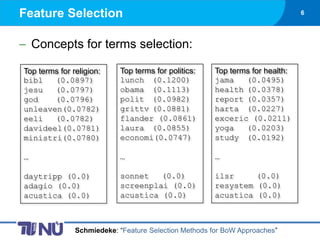
- 6. Feature Selection 6 Concepts for terms selection: Top terms for religion: Top terms for politics: Top terms for health: bibl (0.0897) lunch (0.1200) jama (0.0495) jesu (0.0797) obama (0.1113) health (0.0378) god (0.0796) polit (0.0982) report (0.0357) unleaven(0.0782) grittv (0.0881) harta (0.0227) eeli (0.0782) flander (0.0861) exceric (0.0211) davideel(0.0781) laura (0.0855) yoga (0.0203) ministri(0.0780) economi(0.0747) study (0.0192) ŌĆ” ŌĆ” ŌĆ” daytripp (0.0) sonnet (0.0) ilsr (0.0) adagio (0.0) screenplai (0.0) resystem (0.0) acustica (0.0) acustica (0.0) acustica (0.0) Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
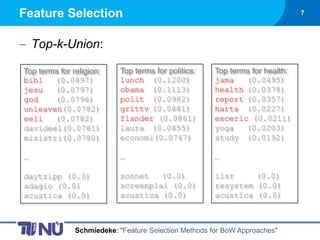
- 7. Feature Selection 7 Top-k-Union: Top terms for religion: Top terms for politics: Top terms for health: bibl (0.0897) lunch (0.1200) jama (0.0495) jesu (0.0797) obama (0.1113) health (0.0378) god (0.0796) polit (0.0982) report (0.0357) unleaven(0.0782) grittv (0.0881) harta (0.0227) eeli (0.0782) flander (0.0861) exceric (0.0211) davideel(0.0781) laura (0.0855) yoga (0.0203) misistri(0.0780) economi(0.0747) study (0.0192) ŌĆ” ŌĆ” ŌĆ” daytripp (0.0) sonnet (0.0) ilsr (0.0) adagio (0.0) screenplai (0.0) resystem (0.0) acustica (0.0) acustica (0.0) acustica (0.0) Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
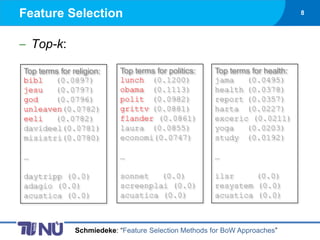
- 8. Feature Selection 8 Top-k: Top terms for religion: Top terms for politics: Top terms for health: bibl (0.0897) lunch (0.1200) jama (0.0495) jesu (0.0797) obama (0.1113) health (0.0378) god (0.0796) polit (0.0982) report (0.0357) unleaven(0.0782) grittv (0.0881) harta (0.0227) eeli (0.0782) flander (0.0861) exceric (0.0211) davideel(0.0781) laura (0.0855) yoga (0.0203) misistri(0.0780) economi(0.0747) study (0.0192) ŌĆ” ŌĆ” ŌĆ” daytripp (0.0) sonnet (0.0) ilsr (0.0) adagio (0.0) screenplai (0.0) resystem (0.0) acustica (0.0) acustica (0.0) acustica (0.0) Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
- 9. Feature Selection 9 Union>th: Top terms for religion: Top terms for politics: Top terms for health: bibl (0.0897) lunch (0.1200) jama (0.0495) jesu (0.0797) obama (0.1113) health (0.0378) god (0.0796) polit (0.0982) report (0.0357) unleaven(0.0782) grittv (0.0881) harta (0.0227) eeli (0.0782) flander (0.0861) exceric (0.0211) davideel(0.0781) laura (0.0855) yoga (0.0203) misistri(0.0780) economi(0.0747) study (0.0192) ŌĆ” ŌĆ” ŌĆ” daytripp (0.0) sonnet (0.0) ilsr (0.0) adagio (0.0) screenplai (0.0) resystem (0.0) acustica (0.0) acustica (0.0) acustica (0.0) 0.0002 0.0002 0.0001 Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
- 10. Feature Selection 10 Intersection>Th: Top terms for religion: Top terms for politics: Top terms for health: bibl (0.0897) lunch (0.1200) jama (0.0495) jesu (0.0797) obama (0.1113) health (0.0378) god (0.0796) polit (0.0982) report (0.0357) ŌĆ” ŌĆ” ŌĆ” web appl gossip python googl interview xbox teen iphon big music san expo tv texa ŌĆ” ŌĆ” ŌĆ” daytripp (0.0) sonnet (0.0) ilsr (0.0) adagio (0.0) screenplai (0.0) resystem (0.0) acustica (0.0) acustica (0.0) acustica (0.0) 0.0002 0.0002 0.0001 Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
- 11. Official runs 11 Bag of clustered SURF features transformed using PCA ŌĆó Result does not benefit from transformation official run without FS/FT mAP 0.2301 0.2309 CA 41.63 % 41.71 % Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
- 12. Official runs 12 Bag of filtered ASR transcripts terms (Union>Th) ŌĆó Result does benefit from selection official run without FS/FT mAP 0.1035 0.0522 CA 32.53 % 26.54 % Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
- 13. Official runs 13 Bag of clustered SURF features filtered using MI and intersection>th strategy ŌĆó Result does slightly benefit from selection official run without FS/FT mAP 0.2259 0.2221 CA 40.80 % 40.78 % Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
- 14. Official runs 14 Bag of filtered terms derived from tags, title and descriptions (Union>Th) ŌĆó Result does benefit from selection official run without FS/FT mAP 0.5225 0.4146 CA 58.18 % 55.70 % Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
- 15. Official runs 15 Bag of clustered SURF features transformed using PCA and decision fusion using uploader ŌĆó Result does benefit from transformation official run without FS/FT mAP 0.3304 0.2988 CA 52.14 % 49.19 % Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
- 16. Conclusion & Future Work 16 FS showed potential for improving the results Choice of using MI or TF is not critical, both methods achieve roughly same results ŌĆó Metadata (mAP) : MI12004 (0.5277) vs. TF14976 (0.5275) Investigation in different scaling schemes (NB) Use of class-independent selection score (MI) Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
- 17. Backup 17 Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
- 18. Backup 18 Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
- 19. Extracting visual features 19 SURF are extracted from each key frame ŌĆó At keypoints and at a regular grid Vocabulary is built using hierarchical clustering on SURF features of development set ŌĆó 4096/8196 codewords Term vector for a single video is obtained by bin- wise pooling of each key framesŌĆÖ term vector ŌĆó avg Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ
- 20. MediaEval 2012: Tagging Task 20 Question: What is the videosŌĆÖ blip.tv category? Blip.tv database (cc): ~ 3300 h ŌĆó 5288 training videos ŌĆó 9550 test videos Official evaluation measurement is Mean Average Precision (mAP) Workshop will be held 4-5 October 2012 in Pisa, Italy Schmiedeke: ŌĆ£Feature Selection Methods for BoW ApproachesŌĆØ