Metody Deep Learning - Wykإ‚ad 7
Download as pptx, pdf0 likes846 views

Siأ³dma czؤ™إ›ؤ‡ wykإ‚adأ³w na temat deep learning i uczenia maszynowego. Prowadzone byإ‚y na AGH, przez firme Craftinity (Craftinity.com), razem z koإ‚em naukowym BIT (http://knbit.edu.pl/pl/)














Metody Deep Learning - Wykإ‚ad 7
- 1. Metody Deep Learning Wykإ‚ad 7 http://arxiv.org/pdf/1502.01852.pdf
- 4. Zaczynamy
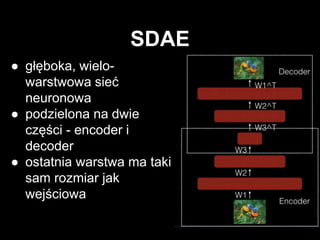
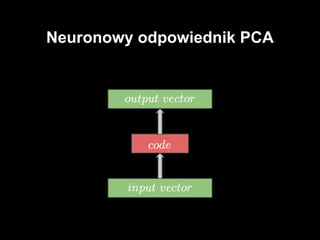
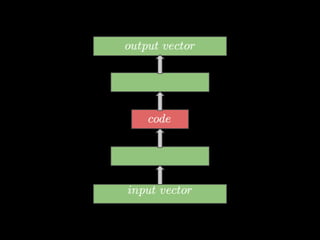
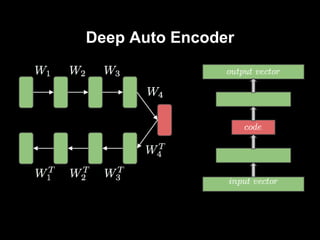
- 7. â—ڈ gإ‚ؤ™boka, wielo- warstwowa sieؤ‡ neuronowa â—ڈ podzielona na dwie czؤ™إ›ci - encoder i decoder â—ڈ ostatnia warstwa ma taki sam rozmiar jak wejإ›ciowa SDAE
- 8. SDAE - pre-training â—ڈ trenujemy DAE warstwa po warstwie w sposأ³b unsupervised â—ڈ moإ¼liwoإ›ci RBM lub DAE
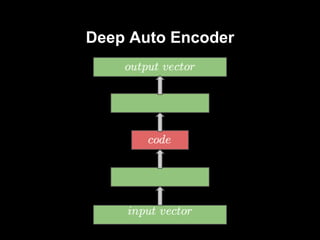
- 9. SDAE - unrolling â—ڈ po pretrenowaniu dodajemy kolejne warstwy w odwrotnej kolejnoإ›ci â—ڈ po dodaniu ostatniej, wyjإ›cie sieci ma ten sam wymiar co wejإ›cie
- 10. SDAE - fine-tuning â—ڈ parametry z pretrenowania warstwa po warstwie - inicjalizacja wag w warstwach â—ڈ trenujemy caإ‚y, gإ‚ؤ™boki autoencoder minimalizujؤ…c bإ‚ؤ…d rekonstrukcji -> backpropagation
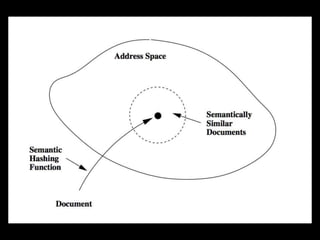
- 11. SDAE - zastosowania â—ڈ ekstrakcja cech z zaobserwowanych danych -> przydatne przy semantycznym haszowaniu â—ڈ wizualizacja wielowymiarowych danych
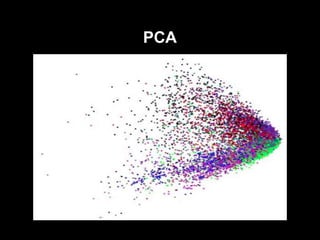
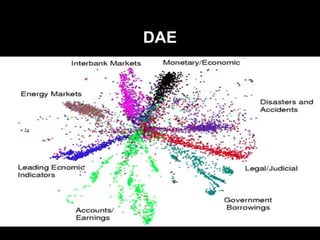
- 16. DAE vs PCA Hinton & Salakhutdinov, 2006
- 17. Semantic Hashing - Ruslan Salakhutdinov, Geoffrey Hinton, 2006
- 19. â—ڈ Reuters RCV2 â—ڈ ~ 400k dokumentأ³w z rأ³إ¼nych gaإ‚ؤ™zi biznesu â—ڈ 20 bitowe kody â—ڈ retrieval w إ›rednim czasie O(1)
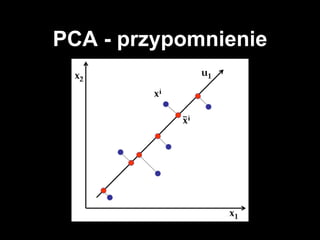
- 21. PCA
- 22. DAE
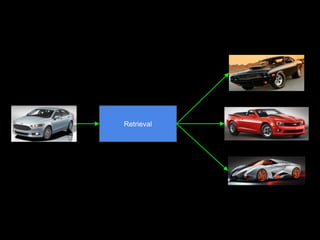
- 24. Retrieval
- 25. Using Very Deep Autoencoders for Content-Based image retrieval - Alex Krizhevsky, Geoffrey Hinton, 2007
- 26. â—ڈ 80 mln obrazkأ³w TinyImages â—ڈ 32 x 32 piksele
- 28. Demo
Editor's Notes
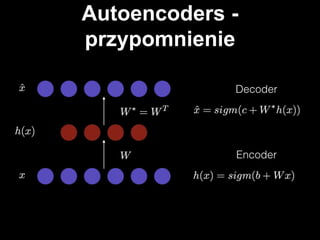
- #7: sieؤ‡ neuronowa z jednؤ… warstwؤ… ukrytؤ… aktywacja neuronأ³w w warstwie ukrytej - encoder aktywacja na widocznej - dekoder rozmiar wejإ›ciowej == rozmiar dekodera cel: kompresja danych, ekstrakcja cech z danych
- #8: budujemy gإ‚ؤ™boki model liczؤ…c na to, إ¼e wyekstrachuje nam lepsze cechy -> idea taka sama jak w przypadku innych modeli gإ‚ؤ™bokich sieؤ‡ zwؤ™إ¼a siؤ™ do pewnego momentu, pأ³إ؛niej rozszerza siؤ™ w taki sam sposأ³b jak poprzednio siؤ™ zwؤ™إ¼aإ‚a podobnie jak w autoencoderze na wyjإ›ciu chcemy uzyskaؤ‡ maإ‚y bإ‚ؤ…d rekonstrukcji problem z trenowaniem -> zwykإ‚e backpropagation powoduje underfitting - bإ‚ؤ…d rekonstrukcji bardzo duإ¼y staramy siؤ™ ratowaؤ‡ tym samym czym siؤ™ ratujemy w przypadku gإ‚ؤ™bokich sieci FF
- #9: pretrenowanie warstwa po warstwa mogؤ… byؤ‡ autoencoder-y albo RBM-y ciekawostka: w przypadku sieci FF uإ¼ywanych przy Supervised Learning pretrenowanie dziaإ‚a jak dobry regularyzator - unikamy overfittingu w tym przyapdku pomagamy sobie osiؤ…gajؤ…c lepsze minimum funkcji kosztu
- #11: إ›rodkowa warstwa to warstwa kodu
- #14: liniowy model redukcji wymiarowoإ›ci intuicja: bierze n-wymiarowe dane i znajduje m ortogonalnych kierunkأ³w w ktأ³rych dane majؤ… najwiؤ™kszؤ… wariancjؤ™. To M kierunkأ³w tworzy maإ‚o wymiarowؤ… przestrzeإ„, do ktأ³rej rzutujemy dane dziaإ‚a kiepsko bo jest tylko liniowy
- #15: sparse autoencoder liniowy