ML Model Serving at Twitter
•
1 like•207 views

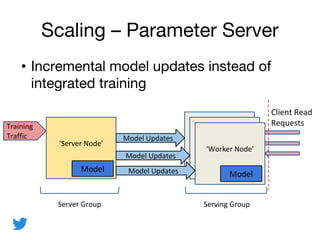
ML models are core to many Twitter products and services. The ML infrastructure supports billions of predictions daily across ads, recommendations, safety and other systems. Model serving faces challenges around performance, robustness, real-time changes and scaling. Twitter addresses these through optimizations like batching, shared transformations, and load balancing. Models are updated online and resilient to traffic spikes. A parameter server architecture allows incremental sharing of model updates across large, distributed serving groups.












ML Model Serving at Twitter
- 1. ML Model Serving @Twitter Joe Xie, Yue Lu and Jack Guo Twitter: @Joe_Xie, @Yue, @JackGuo8
- 2. Outline • ML Infra Overview • Model Serving Challenges • Deep Dive in Solutions – Performance Optimization – Robust & Resilient – Real-time Online Learning – Scaling with Parameter Server • Model Serving Scenarios
- 3. ML Infra - Overview • ML is increasingly at the core of everything we build at Twitter • ML infra supports many product teams – ads ranking, ads targeting, timeline ranking, product safety, recommendation, moments ranking, trends
- 4. ML Infra – Product Examples Ad Recap
- 5. ML Infra - High-level Architecture
- 6. ML Infra – Core Prediction Engine • Large scale online SGD learning • Architecture – Transform: MDL, Decision tree – Feature crossing – Logistic Regression: In-house JVM learner or Vowpal Wabbit
- 7. Model Serving Challenges • Performant: Trillions of predictions served daily • Robust & Resilient: Traffic spike during events, etc. Super bowl, Oscar award, world cup • Real-time: news, events, trends, hash tags, ads. Dynamically adapt to changes spanning as short as a few hours even minutes • Scalability: Horizontal scaling to handle organic growth, new features and advanced modeling
- 8. Performant – Prediction Engine Optimization • Reduce serialization cost – Model collocation – Batch request API • Reduce compute cost – Feature id instead of string name – Transform sharing across models – Feature cross done on the fly
- 9. Robust & Resilient • Resilient – Load factor to control the traffic based on the success rate of the requests • Robust – Snapshot models at fixed interval – Abnormal traffic detection
- 10. Real time – Online Learning Training Traffic Client Read Requests Prediction Service Instance Model Training Traffic Training Traffic
- 11. Scaling – Challenges • Network fan-out: Each prediction service has to receive all training traffic • Limit to Training Traffic Size: Training throughput limited by the capacity of a single instance • Inefficient serving : A big portion of the resource is allocated for training
- 12. Scaling – Parameter Server • Incremental model updates instead of integrated training Training Traffic ‘Server Node’ Model Updates Serving GroupServer Group Client Read Requests Model Model ‘Worker Node’ Model Model Updates Model Updates
- 13. Model Serving Scenarios • Static model in-memory integration • Static model standalone service • Online learning service with integrated training • Parameter server with incremental model updates
- 14. Thank you