



![? We can model events as nodes with properties, related through [:NEXT] edges:
(PageView1)-[:NEXT]->(PageView2).
? We can model events as relationships, eg (User)-[:VIEWS]->(Page).
? We can mix and match different methods.
? ItˇŻs not obvious which model is ˇ®the right oneˇŻ: if there even is such a thing.
ˇ but modelling events as a graph
is relatively unexplored](https://image.slidesharecdn.com/modellingeventleveldata-180611162147/85/Modelling-Event-Data-As-A-Graph-5-320.jpg)
![? In a relational database, youˇŻd always use the same query to get specific properties of an
event:
SELECT user_id, page_url FROM events;
? However, in a graph database your query syntax depends on whether those dimensions have
been modelled as nodes, relationships, or properties of nodes or relationships:
MATCH (u:User)-[:VIEWS]->(p:Page)
RETURN u.id, p.url;
MATCH (e:Event)
RETURN e.user_id, e.page_url;
Choosing the model dictates what
queries we can run](https://image.slidesharecdn.com/modellingeventleveldata-180611162147/85/Modelling-Event-Data-As-A-Graph-6-320.jpg)


![MATCH (u:User)-[r:VIEWS]->(p:Page)
WHERE u.email = 'alice@mail.com'
RETURN COUNT(r)
But what if we have more than just page views, eg also link clicks, downloads, form
submits, etc?
This model makes it hard to find all
events by the same user](https://image.slidesharecdn.com/modellingeventleveldata-180611162147/85/Modelling-Event-Data-As-A-Graph-9-320.jpg)

![MATCH (u:User)<-[:HAS]-(e:Event)-[:HAS]ˇŞ>(p:Page)
WHERE u.email = 'alice@mail.com'
RETURN COUNT(DISTINCT p)
We can still find all pages visited by the user, but we always have to add a ˇ®hopˇŻ in the
query, because entities are related to each other only through the event node they belong
to.
The event-graph model makes other
queries harder](https://image.slidesharecdn.com/modellingeventleveldata-180611162147/85/Modelling-Event-Data-As-A-Graph-11-320.jpg)
![MATCH (u:User)-[:VIEWS]->(p:Page)
WHERE u.email = 'alice@mail.com'
RETURN COUNT(DISTINCT p)
MATCH p = (u:User)<-[:HAS]-(Event)-[:NEXT*1..5]ˇŞ>(Event)
WHERE u.email = 'alice@mail.com'
RETURN p
Now we can easily write a variety of
queries](https://image.slidesharecdn.com/modellingeventleveldata-180611162147/85/Modelling-Event-Data-As-A-Graph-13-320.jpg)






Modelling Event Data As A Graph
- 2. Modelling event data as a graph Combining event graphs with event grammar
- 3. ? People tend to intuitively visualise concepts as graphs which do not translate nicely to a tabular structure. ? Graph databases are often designed for low-latency performance, which can make them a better choice for certain applications, such as recommendation engines, especially at scale. ? There are some questions (for example path analysis) that are difficult to answer when using a relational database, but that are easy to answer with a graph. Graph DBs have some key advantages over relational DBs
- 4. ? In a relational event data model, each event is a record in a table or index. ? The table has as many columns or properties as there are facets to that event, eg user, timestamp, URL, etc. ? There isnˇŻt much scope for deviation from this basic model. We know how to model events in a tableˇ
- 5. ? We can model events as nodes with properties, related through [:NEXT] edges: (PageView1)-[:NEXT]->(PageView2). ? We can model events as relationships, eg (User)-[:VIEWS]->(Page). ? We can mix and match different methods. ? ItˇŻs not obvious which model is ˇ®the right oneˇŻ: if there even is such a thing. ˇ but modelling events as a graph is relatively unexplored
- 6. ? In a relational database, youˇŻd always use the same query to get specific properties of an event: SELECT user_id, page_url FROM events; ? However, in a graph database your query syntax depends on whether those dimensions have been modelled as nodes, relationships, or properties of nodes or relationships: MATCH (u:User)-[:VIEWS]->(p:Page) RETURN u.id, p.url; MATCH (e:Event) RETURN e.user_id, e.page_url; Choosing the model dictates what queries we can run
- 7. Taking an event-grammar approach In the event-grammar model, an event is a snapshot of a set of entities in time. This model is already a graph, with nodes representing the various entities and relationships between the nodes. However, when mapping this model to a tabular structure, the roles of each entity and the relationships between them are lost to users without knowledge of the model and the domain.
- 8. To make the roles and relationships explicit, we have to interpret the event
- 9. MATCH (u:User)-[r:VIEWS]->(p:Page) WHERE u.email = 'alice@mail.com' RETURN COUNT(r) But what if we have more than just page views, eg also link clicks, downloads, form submits, etc? This model makes it hard to find all events by the same user
- 10. The event graph approach A popular option for modelling events in a graph is to make each event a node that is related to the event that happened immediately before it and after it through a?NEXT?/?PREVIOUS?relationship. The event node then has outgoing?HAS?relationships to all of its entities, such as user nodes, context nodes, etc. This is an easy model to do path analysis.
- 11. MATCH (u:User)<-[:HAS]-(e:Event)-[:HAS]ˇŞ>(p:Page) WHERE u.email = 'alice@mail.com' RETURN COUNT(DISTINCT p) We can still find all pages visited by the user, but we always have to add a ˇ®hopˇŻ in the query, because entities are related to each other only through the event node they belong to. The event-graph model makes other queries harder
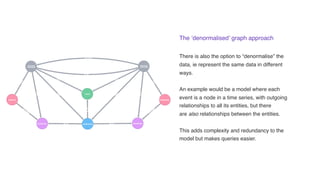
- 12. The ˇ®denormalisedˇŻ graph approach There is also the option to ˇ°denormaliseˇ± the data, ie represent the same data in different ways. An example would be a model where each event is a node in a time series, with outgoing relationships to all its entities, but there are?also?relationships between the entities. This adds complexity and redundancy to the model but makes queries easier.
- 13. MATCH (u:User)-[:VIEWS]->(p:Page) WHERE u.email = 'alice@mail.com' RETURN COUNT(DISTINCT p) MATCH p = (u:User)<-[:HAS]-(Event)-[:NEXT*1..5]ˇŞ>(Event) WHERE u.email = 'alice@mail.com' RETURN p Now we can easily write a variety of queries
- 14. One key advantage is that any insight you glean from analysing the relationships of entities in your events, can be readily attached to your existing data set. How is modelling event-level data as a graph valuable?
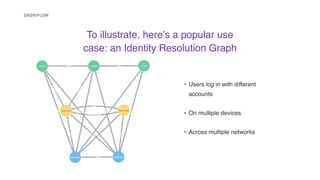
- 15. ? Users log in with different accounts ? On multiple devices ? Across multiple networks To illustrate, hereˇŻs a popular use case: an Identity Resolution Graph
- 16. You need to write extra code to: ? Check the Identity Graph for all aliases of a specific user / device / network; ? Fill in those aliases in SQL queries against your relational database; ? Union the results of those queries. An identity graph is powerful but it remains locked away from the rest of your relational data
- 17. You will be able to easily: ? Find all events for a specific user / device / network; ? Build relationships that link all known aliases for this user / device / network to the same events; ? Quickly discover all of the user / device / network history, regardless of which alias they are using at the moment. Contrast that with building the ID graph on top of your existing event graph
- 19. If you would like to explore how Snowplow can enable you to take control of your data, and what that can make possible, visit our product page, request a demo or get in touch. Sign up to our mailing list and stay up-to-date with our new releases and other news.
- 20. snowplowanalytics.com ? 2018 Snowplow Technology and services provider in digital analytics. All Rights Reserved.