
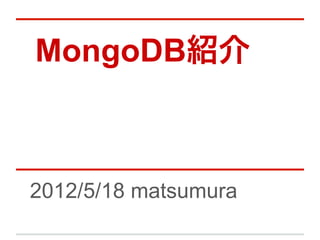


![ūįäėźĘźŃ®`źŪźŻź¾ź░ - phase1
Mongod (Shard A)
Mongod (Shard B)
źŪ®`ź┐ź┘®`ź╣ etcr
źŪ®`ź┐ź┘®`ź╣ etcr
ź│źņź»źĘźńź¾ ąąäė┬─Üs
ź│źņź»źĘźńź¾ ąąäė┬─Üs
Chunk ( ©C¤oŽ▐┤¾ ? ¤oŽ▐┤¾]
docA
docB
docC
źŪźšź®źļź╚
200MB](https://image.slidesharecdn.com/mongodb0518-121011080719-phpapp01/85/Mongodb-7-320.jpg)
![ūįäėźĘźŃ®`źŪźŻź¾ź░ - phase2
Mongod (Shard A)
Mongod (Shard B)
źŪ®`ź┐ź┘®`ź╣ etcr
źŪ®`ź┐ź┘®`ź╣ etcr
ź│źņź»źĘźńź¾ ąąäė┬─Üs
ź│źņź»źĘźńź¾ ąąäė┬─Üs
Chunk ( ©C¤oŽ▐┤¾ ? D]
docA
docB
docC
Chunk ( D ? ¤oŽ▐┤¾]
docD
docE
docF](https://image.slidesharecdn.com/mongodb0518-121011080719-phpapp01/85/Mongodb-8-320.jpg)
![ūįäėźĘźŃ®`źŪźŻź¾ź░ - phase3
Mongod (Shard A)
Mongod (Shard B)
źŪ®`ź┐ź┘®`ź╣ etcr
źŪ®`ź┐ź┘®`ź╣ etcr
ź│źņź»źĘźńź¾ ąąäė┬─Üs
ź│źņź»źĘźńź¾ ąąäė┬─Üs
Chunk ( ©C¤oŽ▐┤¾ ? D]
docA
docB
docC
docCĪ»
docCĪ»Ī»
docCĪ»Ī»Ī»
Chunk ( D ? ¤oŽ▐┤¾]
docD
docE
docF](https://image.slidesharecdn.com/mongodb0518-121011080719-phpapp01/85/Mongodb-9-320.jpg)
![ūįäėźĘźŃ®`źŪźŻź¾ź░ - phase4
Mongod (Shard A)
Mongod (Shard B)
źŪ®`ź┐ź┘®`ź╣ etcr
źŪ®`ź┐ź┘®`ź╣ etcr
ź│źņź»źĘźńź¾ ąąäė┬─Üs
ź│źņź»źĘźńź¾ ąąäė┬─Üs
Chunk ( ©C¤oŽ▐┤¾ ? CĪ»]
docA
docB
docC
Chunk (CĪ» ? D]
docCĪ»
docCĪ»Ī»
docCĪ»Ī»Ī»
Chunk ( D ? ¤oŽ▐┤¾]
docD
docE
docF](https://image.slidesharecdn.com/mongodb0518-121011080719-phpapp01/85/Mongodb-10-320.jpg)
![ūįäėźĘźŃ®`źŪźŻź¾ź░ - phase5
Mongod (Shard A)
Mongod (Shard B)
źŪ®`ź┐ź┘®`ź╣ etcr
źŪ®`ź┐ź┘®`ź╣ etcr
ź│źņź»źĘźńź¾ ąąäė┬─Üs
ź│źņź»źĘźńź¾ ąąäė┬─Üs
Chunk ( ©C¤oŽ▐┤¾ ? CĪ»]
Chunk ( D ? ¤oŽ▐┤¾]
docA
docB
docC
docD
docE
docF
Chunk (CĪ» ? D]
docCĪ»
docCĪ»Ī»
docCĪ»Ī»Ī»
╦«ŲĮĘĮŽ“ż╦
ź╣ź▒®`źļźóź”ź╚](https://image.slidesharecdn.com/mongodb0518-121011080719-phpapp01/85/Mongodb-11-320.jpg)






![ź»ź©źĻ findż╬įÆ (1)
?? Ś╩╦„╠§╝■żŽĪóbsonź¬źųźĖź¦ź»ź╚ż╬Ž╚Ņ^ż╦╝─ż╗żļ
1. db.activityHistoryDemo.find({owner_id: 123})
2. db.activityHistoryDemo.find({Ī«concerned.idĪ»: Ī«201Ī»})
{
owner_id: 123,
request: { type: '║Ž│╔', params: {}},
process: {category: 'composit'},
memo: ['lv.0 -> lv.15'],
concerned: [
{io: 'i', type: 'card', id: 100, object: '111', base: true},
{io: 'i', type: 'card', id: 201, object: '222'},
{io: 'o', type: 'card', id: 100, object: '111'},
]
})](https://image.slidesharecdn.com/mongodb0518-121011080719-phpapp01/85/Mongodb-18-320.jpg)
![ź»ź©źĻ findż╬įÆ (2)
?? bsonź¬źųźĖź¦ź»ź╚ļAīėż“╝ÜĘų╗»żĘż┐ż█ż”ż¼įńżż
db.activityHistoryDemo.find({Ī«concerned.idĪ»: Ī«201Ī»})
{
owner_id: 123,
request: { type: '║Ž│╔', params: {}},
process: {category: 'composit'},
memo: ['lv.0 -> lv.15'],
concerned: [
{io: 'i', type: 'card', id: 100, object: '111', base: true},
{io: 'i', type: 'card', id: 201, object: '222'},
{io: 'o', type: 'card', id: 100, object: '111'},
]
})](https://image.slidesharecdn.com/mongodb0518-121011080719-phpapp01/85/Mongodb-19-320.jpg)
![ź»ź©źĻ findż╬įÆ (3)
?? ╠§╝■ż╬ųĖČ©Ēśą“
o? And╠§╝■żŽĮY╣¹ż╬ąĪżĄż╩╠§╝■ż½żķĒś┤╬
Īņ?? ča╝»║Žż“¤oęĢż╣żļż╬żŪĪŻ
Ī db.sample.find({owner_id: 123, Ī«concerned.typeĪ»: Ī«cardĪ»})
Ī┴ db.sample.find({Ī«concerned.typeĪ»: Ī«cardĪ», owner_id: 123})
o? Or╠§╝■żŽĮY╣¹ż╬┤¾żŁż╩╠§╝■ż½żķĒś┤╬
Īņ?? ßߊA╠§╝■żŽča╝»║Žż½żķŚ╩╦„ż╣żļż╬żŪĪŻ
Ī db.sample.find({$or: [{Ī«concerned.typeĪ»: Ī«cardĪ»}, {owner_id: 123}])
Ī┴ db.sample.find({$or: [{owner_id: 123}, {Ī«concerned.typeĪ»: Ī«cardĪ»}])](https://image.slidesharecdn.com/mongodb0518-121011080719-phpapp01/85/Mongodb-20-320.jpg)
![ź»ź©źĻ findż╬įÆ (4)
?? DBRef
doc = {
name: 'ryooo',
card:[
{'$ref': 'card', '$id' : ObjectId('4b0552b0f0da7d1eb6f12xxx')},
]
}
doc.card[0].fetch() // Ī¹ź½®`ź╔ź¬źųźĖź¦ź»ź╚ż¼ż╚żņżļ
@ruby
db = Connection.new.db(Ī▒etcr ")
user_card = db["user_card"].save({:name => Ī▒ryoooĪ▒, :card_id => 123})
ref = DBRef.new(Ī▒card", user_card.card_id)
db.dereference(ref)
#=> ź½®`ź╔ź¬źųźĖź¦ź»ź╚](https://image.slidesharecdn.com/mongodb0518-121011080719-phpapp01/85/Mongodb-21-320.jpg)


![ź»ź©źĻ insert/updateż╬įÆ (2)
?? IDéÄ
o? źŪźšź®źļź╚żŪżŽĪóIDżŽūįäėżŪš±żķżņżļ
o? ObjectId = BSON(
[4byte timestamp] +
[3byte hash(hostname)] +
[2byte pid] +
[3byte inc])
// parseż╣żņżąĢrķgżõźĄ®`źą®`ż╩ż╔żŌż’ż½żļ
object_id = '4b0552b0f0da7d1eb6f12yyyĪ»
createdDt = new Date(parseInt(object_id.substr(0, 8), 16) * 1000)
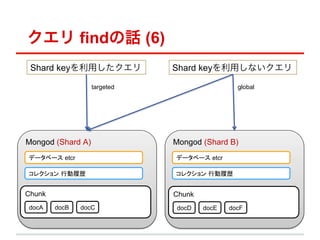
#=> Thu Nov 19 2009 23:14:08 GMT+0900 (JST)](https://image.slidesharecdn.com/mongodb0518-121011080719-phpapp01/85/Mongodb-25-320.jpg)




![Shard keyż╬┐╝▓ņ (ż”ż▒ż”żĻ)
?? [bad] ļx╔óźŪ®`ź┐
o? chunkĘųĖŅżŪżŁż╩żż
Īņ?? └²Ż║Č╝Ą└Ė«▒hź│®`ź╔
?? [bad] ģg╝āźżź¾ź»źĻźßź¾ź╚źŪ®`ź┐
o? ūŅßßż╬chunkż╬ż▀ż¼ĘųĖŅęŲäėżĄżņżļ
Īņ?? └²Ż║▀BĘ¼
?? [bad] źķź¾ź└źÓéÄ
o? ╩«Ęųż╦Ęų╔óż╣żļż▐żŪżŽŲ½żĻż¼żóżļż┐żßĪó┤¾żŁż╩chunkż¼żŪżŁżļ
Īņ?? └²Ż║źŽź├źĘźÕ
?? [good] ŠÅżõż½ż╦ēł╝ėż╣żļźŁ®`ż╚Ś╩╦„ż╦└¹ė├ż╣żļźŁ®`ż╬ĮM
ż▀║Žż’ż╗
o? Ś╩╦„└¹ė├źŁ®`żŪżęż╚į┬ż½ż▒żŲŲ½żĻż¼░k╔·żĘżŲż»żļż¼Īóżęż╚į┬ż┐żŲżąŲ½
żĻż¼źĻź╗ź├ź╚żĄżņżļ
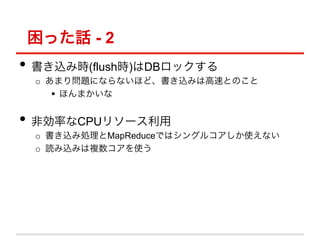
Īņ?? └²Ż║yyyymm-owner_id](https://image.slidesharecdn.com/mongodb0518-121011080719-phpapp01/85/Mongodb-31-320.jpg)
Mongodb ĮBĮķ
- 2. MongoDBż├żŲż╩ż¾żŠ - ČÓÖC─▄ but ░kš╣═Š╔Ž ?? ź╔źŁźÕźßź¾ź╚ųĖŽ“źŪ®`ź┐ź┘®`ź╣ o? ūŅą┬2.0.5 ?? ūįäėźĘźŃ®`źŪźŻź¾ź░ o? Read / Writeż¼ź╣ź▒®`źļźóź”ź╚ ?? ūįäėźšź¦źżźļź¬®`źą®` o? Master deadżŪżŌūįäėżŪźšź¦źżźļź¬®`źą®` ?? ╚ß▄øż╩ź»ź©źĻ o? SQLżŪ┐╔─▄ż╩ż│ż╚żŽJOINŠõęį═Ō ę╗═©żĻżŪżŁżļ ?? ź╣źŁ®`ź▐źņź╣ o? źŪ®`ź┐ż╦żĶż├żŲūįė╔ż╦│ųż─żŌż╬ż“øQżßżķżņżļ ╦¹ż╦żŌČÓÖC─▄
- 3. ╣╣│╔└² Web Web mongos mongos 3processżŪ ūŅąĪśŗ│╔╠©╩² ūŅ▀m╗» Ż│process data data meta mongod mongod Mongod (config) mongod mongod Mongod (config) mongod mongod Mongod Replica Replica (config) set set
- 4. ╗∙▒ŠĄ─ż╩źŪ®`ź┐ż╬│ųż┴ĘĮ MySQLżŪ└²ż©żļż╚ mongod mysqld źŪ®`ź┐ź┘®`ź╣ etcr źŪ®`ź┐ź┘®`ź╣ ź│źņź»źĘźńź¾ ąąäė┬─Üs ź│źņź»źĘźńź¾ XXź▐ź╣ź┐ źŲ®`źųźļ doc doc doc doc doc doc źņź│®`ź╔ doc doc doc doc źŪ®`ź┐ź┘®`ź╣ other ź│źņź»źĘźńź¾ Ė„ĘNźĒź░ doc doc doc
- 5. źņźūźĻź½ź╗ź├ź╚ - MySQL═¼śö Mongod (Primary) Mongod(Secondary) Mongod(Secondary) źŪ®`ź┐ź┘®`ź╣ etcr źŪ®`ź┐ź┘®`ź╣ etcr źŪ®`ź┐ź┘®`ź╣ etcr ź│źņź»źĘźńź¾ ąąäė┬─Üs ź│źņź»źĘźńź¾ ąąäė┬─Üs ź│źņź»źĘźńź¾ ąąäė┬─Üs docA docB docC docA docB docC docA docB docC docD docE docF docD docE docF docD docE docF į┘¼F į┘¼F źŪ®`ź┐ź┘®`ź╣ local źŪ®`ź┐ź┘®`ź╣ local źŪ®`ź┐ź┘®`ź╣ local ź│źņź»źĘźńź¾ oplog ź│źņź»źĘźńź¾ oplog ź│źņź»źĘźńź¾ oplog ═¼ ▓┘ū„ ▓┘ū„ ▓┘ū„ Ų┌ ▓┘ū„ ▓┘ū„ ▓┘ū„ ▓┘ū„ ▓┘ū„ ▓┘ū„
- 6. ūįäėźšź¦źżźļź¬®`źą®` ?? Primaryż¼╦└ż╠ ?? Primaryż¼╦└ż¾ż└ż│ż╚ż¼replica set─┌żŪ╣▓ėą ?? ▓ąż├ż┐ź╬®`ź╔żŪ═ČŲ▒ż“ąąż” ?? ź╬®`ź╔ż┤ż╚ż╬ā׎╚Č╚įOČ©ĪóūŅĮK═¼Ų┌Ģr┐╠ż“żŌż╚ż╦═ČŲ▒ ż“ąąż” ?? ▀^░ļ╩²żĶżĻČÓż»ż╬Ų▒ż“╝»żßż┐ź╬®`ź╔ż¼Primaryż╚ż╩żļ ?? ż│ż╬ķg ╝s20s Ī½ 60s
- 7. ūįäėźĘźŃ®`źŪźŻź¾ź░ - phase1 Mongod (Shard A) Mongod (Shard B) źŪ®`ź┐ź┘®`ź╣ etcr źŪ®`ź┐ź┘®`ź╣ etcr ź│źņź»źĘźńź¾ ąąäė┬─Üs ź│źņź»źĘźńź¾ ąąäė┬─Üs Chunk ( ©C¤oŽ▐┤¾ ? ¤oŽ▐┤¾] docA docB docC źŪźšź®źļź╚ 200MB
- 8. ūįäėźĘźŃ®`źŪźŻź¾ź░ - phase2 Mongod (Shard A) Mongod (Shard B) źŪ®`ź┐ź┘®`ź╣ etcr źŪ®`ź┐ź┘®`ź╣ etcr ź│źņź»źĘźńź¾ ąąäė┬─Üs ź│źņź»źĘźńź¾ ąąäė┬─Üs Chunk ( ©C¤oŽ▐┤¾ ? D] docA docB docC Chunk ( D ? ¤oŽ▐┤¾] docD docE docF
- 9. ūįäėźĘźŃ®`źŪźŻź¾ź░ - phase3 Mongod (Shard A) Mongod (Shard B) źŪ®`ź┐ź┘®`ź╣ etcr źŪ®`ź┐ź┘®`ź╣ etcr ź│źņź»źĘźńź¾ ąąäė┬─Üs ź│źņź»źĘźńź¾ ąąäė┬─Üs Chunk ( ©C¤oŽ▐┤¾ ? D] docA docB docC docCĪ» docCĪ»Ī» docCĪ»Ī»Ī» Chunk ( D ? ¤oŽ▐┤¾] docD docE docF
- 10. ūįäėźĘźŃ®`źŪźŻź¾ź░ - phase4 Mongod (Shard A) Mongod (Shard B) źŪ®`ź┐ź┘®`ź╣ etcr źŪ®`ź┐ź┘®`ź╣ etcr ź│źņź»źĘźńź¾ ąąäė┬─Üs ź│źņź»źĘźńź¾ ąąäė┬─Üs Chunk ( ©C¤oŽ▐┤¾ ? CĪ»] docA docB docC Chunk (CĪ» ? D] docCĪ» docCĪ»Ī» docCĪ»Ī»Ī» Chunk ( D ? ¤oŽ▐┤¾] docD docE docF
- 11. ūįäėźĘźŃ®`źŪźŻź¾ź░ - phase5 Mongod (Shard A) Mongod (Shard B) źŪ®`ź┐ź┘®`ź╣ etcr źŪ®`ź┐ź┘®`ź╣ etcr ź│źņź»źĘźńź¾ ąąäė┬─Üs ź│źņź»źĘźńź¾ ąąäė┬─Üs Chunk ( ©C¤oŽ▐┤¾ ? CĪ»] Chunk ( D ? ¤oŽ▐┤¾] docA docB docC docD docE docF Chunk (CĪ» ? D] docCĪ» docCĪ»Ī» docCĪ»Ī»Ī» ╦«ŲĮĘĮŽ“ż╦ ź╣ź▒®`źļźóź”ź╚
- 13. ź╣źŁ®`ź▐źņź╣ ?? Create table, Create column family ▓╗ę¬ o? InsertżĘż┐ĢrĄŃżŪū„żķżņżļ o? źóźūźĻę¬╝■ż╦║Žż’ż╗żŲ╚ß▄øż╦╚ļżņżķżņżļ Item1 = { _id: ObjectId('4b0552b0f0da7d1eb6f12xxx'), name: ├ž╦a, price: 100, } Item2 = { _id: ObjectId('4b0552b0f0da7d1eb6f12yyy'), name: ūįĘųė├├ž╦a, }
- 14. ╚ß▄øż╩ź»ź©źĻ ??SQL╬─ż“│ųż┐ż╩żż ??Demo ??źŽź├źĘźÕżŪO/Rź▐ź├źč®`ż╬żĶż”ż╦ųĖČ©ż╣żļ o? źšźĒź¾ź╚javascriptż½żķź»ź©źĻź¬źųźĖź¦ź»ź╚ż“ ╦═ż├żŲĪ󟥮`źą®`źĄźżź╔żŪżŽŚ╩į^ßßĪó╝┤īgąążŪżŁ żļ
- 15. ź»ź©źĻ ų▄▐xż╬įÆ (1) ??Index(B-Tree) o? ┼õ┴ążõź¬źųźĖź¦ź»ź╚ż╦īØżĘżŲżŌżŽżņżļ Īņ??ż┐ż└żĘĪó┼õ┴ążŽ1ż─ / indexż╦ųŲŽ▐ o? źßźŌźĻż╦ü\żļżĶż”ż╦intż“╩╣ż”ż╚╝¬ // indexż“ż─ż▒żļ db.test.ensureIndex({x:1, y:1, z:1}) Ī db.test.find({x:'a'}) Ī db.test.find({x:'a', y:'b'}) Ī db.test.find({x:'a', y:'b'}).sort({z:1}) // Ēśą“ż¼ųžę¬ Ī┴ db.test.find({y:'b', x:'a'})
- 16. ź»ź©źĻ ų▄▐xż╬įÆ(2) ??ź»ź©źĻź¬źūźŲźŻź▐źżźČ o?MySQLż╬żĶż”ż╩ź│ź╣ź╚ź┘®`ź╣żŪżŽż╩żż o?│§╗žż╬ź»ź©źĻżŪč}╩²ź»ź©źĻźūźķź¾ż“═¼Ģrīgąą o? ūŅżŌįńż½ż├ż┐ź»ź©źĻż“└¹ė├ o? źŪ®`ź┐┴┐ż╦ÅĻżĖżŲČ©Ų┌Ą─ż╦ęŖų▒żĘ o? explain()
- 17. ź»ź©źĻ ų▄▐xż╬įÆ(3) ??Capped ź│źņź»źĘźńź¾ o? żóżķż½żĖżßźĄźżź║ż“øQżßż┐ź│źņź»źĘźńź¾ o? ╣┼żżżŌż╬ż½żķĒś┤╬Ž¹ż©żŲżżż» o? ÆĘ╚ļĒśżŪż╬Ś╩╦„żŪĖ▀╦┘ o? ShardingżŪżŁż╩żż o? Ž„│²▓╗─▄ o? Create╬─ż“├„╩ŠĄ─ż╦░kąążĘżŲū„│╔ Īņ??db.createCollection("mycoll", {capped:true, size:100000})
- 18. ź»ź©źĻ findż╬įÆ (1) ?? Ś╩╦„╠§╝■żŽĪóbsonź¬źųźĖź¦ź»ź╚ż╬Ž╚Ņ^ż╦╝─ż╗żļ 1. db.activityHistoryDemo.find({owner_id: 123}) 2. db.activityHistoryDemo.find({Ī«concerned.idĪ»: Ī«201Ī»}) { owner_id: 123, request: { type: '║Ž│╔', params: {}}, process: {category: 'composit'}, memo: ['lv.0 -> lv.15'], concerned: [ {io: 'i', type: 'card', id: 100, object: '111', base: true}, {io: 'i', type: 'card', id: 201, object: '222'}, {io: 'o', type: 'card', id: 100, object: '111'}, ] })
- 19. ź»ź©źĻ findż╬įÆ (2) ?? bsonź¬źųźĖź¦ź»ź╚ļAīėż“╝ÜĘų╗»żĘż┐ż█ż”ż¼įńżż db.activityHistoryDemo.find({Ī«concerned.idĪ»: Ī«201Ī»}) { owner_id: 123, request: { type: '║Ž│╔', params: {}}, process: {category: 'composit'}, memo: ['lv.0 -> lv.15'], concerned: [ {io: 'i', type: 'card', id: 100, object: '111', base: true}, {io: 'i', type: 'card', id: 201, object: '222'}, {io: 'o', type: 'card', id: 100, object: '111'}, ] })
- 20. ź»ź©źĻ findż╬įÆ (3) ?? ╠§╝■ż╬ųĖČ©Ēśą“ o? And╠§╝■żŽĮY╣¹ż╬ąĪżĄż╩╠§╝■ż½żķĒś┤╬ Īņ?? ča╝»║Žż“¤oęĢż╣żļż╬żŪĪŻ Ī db.sample.find({owner_id: 123, Ī«concerned.typeĪ»: Ī«cardĪ»}) Ī┴ db.sample.find({Ī«concerned.typeĪ»: Ī«cardĪ», owner_id: 123}) o? Or╠§╝■żŽĮY╣¹ż╬┤¾żŁż╩╠§╝■ż½żķĒś┤╬ Īņ?? ßߊA╠§╝■żŽča╝»║Žż½żķŚ╩╦„ż╣żļż╬żŪĪŻ Ī db.sample.find({$or: [{Ī«concerned.typeĪ»: Ī«cardĪ»}, {owner_id: 123}]) Ī┴ db.sample.find({$or: [{owner_id: 123}, {Ī«concerned.typeĪ»: Ī«cardĪ»}])
- 21. ź»ź©źĻ findż╬įÆ (4) ?? DBRef doc = { name: 'ryooo', card:[ {'$ref': 'card', '$id' : ObjectId('4b0552b0f0da7d1eb6f12xxx')}, ] } doc.card[0].fetch() // Ī¹ź½®`ź╔ź¬źųźĖź¦ź»ź╚ż¼ż╚żņżļ @ruby db = Connection.new.db(Ī▒etcr ") user_card = db["user_card"].save({:name => Ī▒ryoooĪ▒, :card_id => 123}) ref = DBRef.new(Ī▒card", user_card.card_id) db.dereference(ref) #=> ź½®`ź╔ź¬źųźĖź¦ź»ź╚
- 22. ź»ź©źĻ findż╬įÆ (5) ?? Ś╩╦„╠§╝■ż╦ķv╩²żŌ╩╣ż©żļ(javascript) // śOČ╦ż╩įÆĪóż│ż¾ż╩ź»ź©źĻżŌĢ°ż▒ż┴żŃżżż▐ż╣ db.cards.find(function(){ row = db.user_summary.findOne({owner_id: this.owner_id}) return this._id == row.leader_card_id; }) ?? mongoźĄ®`źą®`źĄźżź╔ż╦ķv╩²ż“ĄŪÕhżŪżŁżļ // ķv╩²ż“ĄŪÕh db.system.js.save({_id:Ī»name', value: function (){ //implementation }}); f = db.system.js.findOne({_id:Ī»name'}) // Ś╩╦„żŪ└¹ė├(fżŽźĄ®`źą®`é╚żŪīgąążĄżņżļ) Db.cards.find(f)
- 23. ź»ź©źĻ findż╬įÆ (6) Shard keyż“└¹ė├żĘż┐ź»ź©źĻ Shard keyż“└¹ė├żĘż╩żżź»ź©źĻ targeted global Mongod (Shard A) Mongod (Shard B) źŪ®`ź┐ź┘®`ź╣ etcr źŪ®`ź┐ź┘®`ź╣ etcr ź│źņź»źĘźńź¾ ąąäė┬─Üs ź│źņź»źĘźńź¾ ąąäė┬─Üs Chunk Chunk docA docB docC docD docE docF
- 24. ź»ź©źĻ insert/updateż╬įÆ (1) ?? fire and forget o? ░k╗╝┤═³╚┤ Īņ?? ĮY╣¹ż“┤_šJż╗ż║returnż╣żļ Īņ?? ĮY╣¹ż“ų¬żĻż┐ż▒żņżągetlasterrorź¬źūźĘźńź¾ż“ųĖČ© ?? ┤_īgż╦commitżĄż╗żļ o? źŪ®`ź┐źšźĪźżźļż╦źšźķź├źĘźÕżĄż╗żļ Īņ?? fsync: true o? 2╠©ż╬źßź¾źą®`ż╦Ģ°żŁ▐zż▀ż¼═Ļ┴╦ż╣żļż▐żŪ┤²ÖC(timeout:5000) Īņ?? db.getlasterror(2, 5000) Īņ?? db.getlasterror('majority')
- 25. ź»ź©źĻ insert/updateż╬įÆ (2) ?? IDéÄ o? źŪźšź®źļź╚żŪżŽĪóIDżŽūįäėżŪš±żķżņżļ o? ObjectId = BSON( [4byte timestamp] + [3byte hash(hostname)] + [2byte pid] + [3byte inc]) // parseż╣żņżąĢrķgżõźĄ®`źą®`ż╩ż╔żŌż’ż½żļ object_id = '4b0552b0f0da7d1eb6f12yyyĪ» createdDt = new Date(parseInt(object_id.substr(0, 8), 16) * 1000) #=> Thu Nov 19 2009 23:14:08 GMT+0900 (JST)
- 26. ź»ź©źĻ insert/updateż╬įÆ (3) ?? Padding o? insertĢrż╦ĪóźčźŪźŻź¾ź░ŅIė“ż“┤_▒ŻżĘżŲżżżļ Īņ?? ┼õ┴ąż╦ūĘ╝ėżĄżņżļż╩ż╔Īóź╔źŁźÕźßź¾ź╚źĄźżź║ż¼Æł┤¾żĘżŲżŌĖ▀ ╦┘ż╦updateż╣żļż┐żß(In-place update) o? PaddingŅIė“ż“įĮż©żļĖ³ą┬ Īņ?? ź╔źŁźÕźßź¾ź╚ż╬į┘┼õų├ż¼░k╔·(▀Wżż) Īņ?? ēł╝ėąįż“│ųż├ż┐ź│źņź»źĘźńź¾żŽPaddingźĄźżź║š{š¹ż¼▒žę¬ ?? Atomicż╩▓┘ū„ o? 1ż─ż╬ź╔źŁźÕźßź¾ź╚ż╬Ė³ą┬ż╦īØżĘżŲäeż╬ź»ź©źĻż“źųźĒź├ź» o? ź╚źķź¾źČź»źĘźńź¾ż╬ACIDż╬A(atomic : all or nothing)żŪżŽż╩żżĪŻ o? shardingŁhŠ│żŪźĄź▌®`ź╚żĄżņż╩żż
- 27. ź»ź©źĻ removeż╬įÆ ?? ČŽŲ¼╗» o? Ž„│²ĢrżŽź╔źŁźÕźßź¾ź╚ż╬į┘┼õų├ż“ąąż’ż╩żżż╬żŪČŽŲ¼╗»ż╣żļ o? repairź│ź▐ź¾ź╔ Īņ?? ═¼╚▌┴┐ż╬┐šżŁŅIė“ż¼▒žę¬ Īņ?? źĄ®`źą®`ģg╬╗(shardingŁhŠ│ż╩żķĖ„shardżŪ) o? compactź│ź▐ź¾ź╔ Īņ?? żĶżĻ╔┘ż╩żż┐šżŁŅIė“żŪ┐╔─▄ Īņ?? ź│źņź»źĘźńź¾ģg╬╗ Īņ?? paddingżŌŽ„│²ż╣żļż╬żŪĪóēł╝ėąįż“│ųż├ż┐ź│źņź»źĘźńź¾żŽźŪ źšźķź░ßßż╦updateźčźšź®®`ź▐ź¾ź╣ÉÖ╗»
- 28. └¦ż├ż┐įÆ - 1 ?? flushŪ░ż╬źŪ®`ź┐źĒź╣ź╚ o? źŪźšź®źļź╚żŪżŽ60sż╦1╗žflushżĄżņżļż▐żŪżŽźßźŌźĻżŪ▒Ż│ų Īņ?? ūŅ┤¾żŪ60├ļķgż╬źŪ®`ź┐źĒź╣ź╚ż╬┐╔─▄ąį o? īØ▓▀1 (Ī½ver1.8) Īņ?? 60├ļż╬įOČ©ż“Č╠┐sż╣żļ Īņ?? getlasterror()żŪflushżĄż╗żļ ?? ųžż»ż╩żļ o? īØ▓▀2 źĖźŃ®`ź╩źļźŌ®`ź╔ (ver1.8Ī½) Īņ?? źĖźŃ®`ź╩źļźĒź░(disc)ż╦100msż╦1╗žĢ°żŁ▐zżÓ Īņ?? flushż╚▀`żżĪóźŪ®`ź┐ż╬Ė³ą┬Ž╚ż╩ż╔ż“ęŌūRżĘż╩żżż┐żßįńżż Īņ?? ŲäėĢrż╦JournalźŪźŻźņź»ź╚źĻż¼żóżņżąÅ═į¬żĘĪóš²│ŻĮK┴╦Ģr żŽźŪźŻźņź»ź╚źĻż“Ž„│²ż╣żļĪŻ
- 29. └¦ż├ż┐įÆ - 2 ?? Ģ°żŁ▐zż▀Ģr(flushĢr)żŽDBźĒź├ź»ż╣żļ o? żóż▐żĻå¢Ņ}ż╦ż╩żķż╩żżż█ż╔ĪóĢ°żŁ▐zż▀żŽĖ▀╦┘ż╚ż╬ż│ż╚ Īņ?? ż█ż¾ż▐ż½żżż╩ ?? ĘŪä┐┬╩ż╩CPUźĻźĮ®`ź╣└¹ė├ o? Ģ°żŁ▐zż▀äI└Ēż╚MapReduceżŪżŽźĘź¾ź░źļź│źóżĘż½╩╣ż©ż╩żż o? šiż▀▐zż▀żŽč}╩²ź│źóż“╩╣ż”
- 30. ż▀ż¾ż╩ż¼┐Óä║żĘżŲżżżļż╬żŽ ?? Shard key ż╬øQżßĘĮ o? Chunkż╬ęŲäėż¼żóż▐żĻŲż│żķż╩żżż│ż╚ o? ķLŲ┌ż╬▀\ė├żŪżŌŠ_¹Éż╦Ęų╔óż╣żļż│ż╚ o? Shard keyż“╩╣ż├żŲä┐┬╩żĶż»Ś╩╦„żŪżŁżļż│ż╚ ?? Shard keyżŽę╗Č╚øQżßżļż╚ēõż©żķżņż╩żż ?? Migrationųąż╬▓ą─Ņż╩źčźšź®®`ź▐ź¾ź╣ż╚▓╗š¹║Ž
- 31. Shard keyż╬┐╝▓ņ (ż”ż▒ż”żĻ) ?? [bad] ļx╔óźŪ®`ź┐ o? chunkĘųĖŅżŪżŁż╩żż Īņ?? └²Ż║Č╝Ą└Ė«▒hź│®`ź╔ ?? [bad] ģg╝āźżź¾ź»źĻźßź¾ź╚źŪ®`ź┐ o? ūŅßßż╬chunkż╬ż▀ż¼ĘųĖŅęŲäėżĄżņżļ Īņ?? └²Ż║▀BĘ¼ ?? [bad] źķź¾ź└źÓéÄ o? ╩«Ęųż╦Ęų╔óż╣żļż▐żŪżŽŲ½żĻż¼żóżļż┐żßĪó┤¾żŁż╩chunkż¼żŪżŁżļ Īņ?? └²Ż║źŽź├źĘźÕ ?? [good] ŠÅżõż½ż╦ēł╝ėż╣żļźŁ®`ż╚Ś╩╦„ż╦└¹ė├ż╣żļźŁ®`ż╬ĮM ż▀║Žż’ż╗ o? Ś╩╦„└¹ė├źŁ®`żŪżęż╚į┬ż½ż▒żŲŲ½żĻż¼░k╔·żĘżŲż»żļż¼Īóżęż╚į┬ż┐żŲżąŲ½ żĻż¼źĻź╗ź├ź╚żĄżņżļ Īņ?? └²Ż║yyyymm-owner_id
- 32. źĘź¾źūźļż╩ĮŌ╬÷▒╩╣¾ż╬└² Web Web ╩╣ż├ż┐ż│ż╚ż╩żżżŌż╬ż“ ╩╦╩┬żŪ╩╣ż├żŲż▀ż┐żżż╚żżż”Žļżż ĮŌ╬÷ė├źĄ®`źą®` ╚š┤╬ēłĘųż“Map/ ReduceżŪ╝»ėŗ šJį^ÖC─▄ż¼▒žę¬ż╩ż┐żßĪŻ I/Oż“jsonżŪę╗ų┬żĄż╗żŲ ķ_░kź╣źį®`ź╔źóź├źū