MongoDB NoSQL DBMS
•Download as KEY, PDF•
1 like•1,155 views

This document provides an overview of NoSQL document stores. It discusses the structure of document stores, including collections, indexing, and map reduce functions. It also describes the distributed process architecture using shards, chunks, replication for failover, and a configuration server. Several use cases are highlighted, including archiving, e-commerce, healthcare, and science applications like particle physics research.





MongoDB NoSQL DBMS
- 1. NoSQL DBMS Document Store Presentation By Vladimir Bukhin on Sept 24th
- 2. Contents • Structure of the data store. • Querying language and functions. • Distributed Process Architecture and configuration. • Use cases.
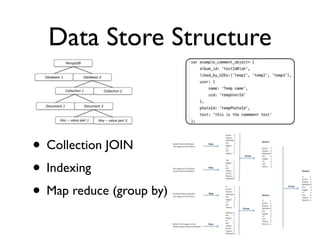
- 3. Data Store Structure • Collection JOIN • Indexing • Map reduce (group by)
- 4. Languages • System functions and cli use JS • Queries, updates, data: MQL + JSON • DB built in C++
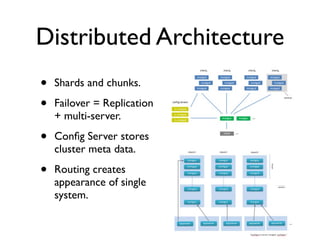
- 5. Distributed Architecture • Shards and chunks. • Failover = Replication + multi-server. • Config Server stores cluster meta data. • Routing creates appearance of single system.
- 6. Use Cases • 300+ production use cases on website. • Archiving, e-commerce, education, gaming, healthcare, mobile, telecom, finance, etc. • MongoDB In Science: • Mount Sinai Institute for Genomics and Multiscale Biology. • Realtime.springer.com: Science Journal DB • CERN (European Organization for Nuclear Research): Collider data stored across the world. (pic)
- 7. Bibliography • "Sharding Introduction." - MongoDB. 10gen, n.d. Web. 07 Sept. 2012. <http://www.mongodb.org/display/DOCS/Sharding+Introduction> • "Production Deployments." - MongoDB. 10gen, n.d. Web. 07 Sept. 2012. http://www.mongodb.org/display/DOCS/Production +Deployments#ProductionDeployments-Scientific> • "Querying." - MongoDB. 10gen, n.d. Web. 07 Sept. 2012. <http:// www.mongodb.org/display/DOCS/Querying>. • “Holy Large Hadron Collider, Batman!” - MongoDB. 10gen, n.d. Web. 03 June. 2010. <http://blog.mongodb.org/post/660037122/holy-large- hadron-collider-batman>
Editor's Notes
- \n
- \n
- 1. Collections are basically an array of JSON objects each with a unique id. When writing a query, you cannot access 2 collections at the same time. No joins. Can&#x2019;t get all user objs that liked this comment. (hence no transaction support here)\n2. Can index photoId value or, album_id - user.uid\n3. Suppose you needed to figure out ave likes per user.uid. The query would consist of getting all comment obj with uid=x, each step through an object would get liked_by_UIDs.length and keep a running total of how many objs processed, then take the ave. This would all be done in on the db server. take from object (map), aggregate partial information (reduce) and then you can use it like for average.\n
- 1. DB has global functions that can executed on objects or functions you can pass to the db. Instead of going back and forth, app to db, you can execute without additional network io. There are reasons not to use these: its not application code, a little bit harder to debug, a little bit more annoying to share code -> do only when complexity is very low.\n2. Queries, updates, and data written in JSON or JS by the user, converted to BSON (Binary JSON) by the database and used to perform operations.\n3. Built in C++, which usually has a performance advantage over dbs built in java.\n
- 1. Each Shard contains multiple mongod processes: server + data. Each mongod has several 64mb max chunks.\n2. The config server has metadata on each shard and chunk inside the shards.\n3. Routers coordinate which requests to different processes and merge data.\n4. Each box is a process. Green routers ask yellow config servers for info on where to find necessary info then request from mongod processes on shards and merge results.\n5. How you put it on different vms is your choice but this image is one one way to do it. Each shard has router, config and one mongo server and setup is replicated.\n\n
- 1. Archiving, Content Management, Ecommerce, Education, Finance, Gaming, Government, Healthcare, Mobile, Real-time stats/analytics, Scientific, Social Networks, Telecommunications.\n2. The Mount Sinai Institute for Genomics and Multiscale Biology uses MongoDB to help with various computational genomics tasks.\n3. Atomic Patricle accelerator/collider/detector data is distributed using the architecture discussed in the prev slides: routers, shards, servers, config servers all hosted in strategic places around the world. Users use MQL to query the mongodb and perform an aggregation of the data. The data may come from multiple mongo shards in multiple locations, then is aggregated and saved into cache before being transferred to the query originator. If the same aggregation is queried again, the aggregation is not performed again, it is taken from cache. Previously this kind of world wide setup existed using a relational db but it apparently took much longer to aggregate information. \n\n \n
- \n