






























Monitoring MongoDBﻗs Engines in the Wild
- 1. Tim Vaillancourt Sr. Technical Operations Architect Monitoring MongoDBﻗs Engines in the Wild
- 2. About Me ﻗ۱ Joined Percona in January 2016 ﻗ۱ Sr Technical Operations Architect for MongoDB ﻗ۱ Previous: ﻗ۱ EA DICE (MySQL DBA) ﻗ۱ EA SPORTS (Sys/NoSQL DBA Ops) ﻗ۱ Amazon/AbeBooks Inc (Sys/MySQL+NoSQL DBA Ops) ﻗ۱ Main techs: MySQL, MongoDB, Cassandra, Solr, Redis, queues, etc ﻗ۱ 10+ years tuning Linux for database workloads (off and on) ﻗ۱ Monitoring techs ﻗ۱ Nagios ﻗ۱ MRTG ﻗ۱ Munin ﻗ۱ Zabbix ﻗ۱ Cacti ﻗ۱ Graphite ﻗ۱ Prometheus
- 3. Storage Engines ﻗ۱ MMAPv1 ﻗ۱ Mostly done by Linux kernel ﻗ۱ WiredTiger ﻗ۱ Default as of 3.2 ﻗ۱ Percona In-Memory ﻗ۱ Same metrics as WiredTiger ﻗ۱ RocksDB ﻗ۱ PerconaFT / TokuMX ﻗ۱ Deprecated ﻗ۱ Fractal-tree based storage engine
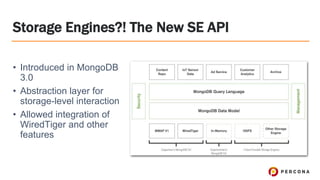
- 4. Storage Engines?! The New SE API ﻗ۱ Introduced in MongoDB 3.0 ﻗ۱ Abstraction layer for storage-level interaction ﻗ۱ Allowed integration of WiredTiger and other features
- 5. Storage Engines: MMAPv1 ﻗ۱ Default storage engine < 3.2 (now WiredTiger) ﻗ۱ Collection-level locking (common performance bottleneck) ﻗ۱ Monitored via Lock Ratio/Percent metrics ﻗ۱ In-place datafile updating (when possible) ﻗ۱ OS-level operations ﻗ۱ Uses OS-level mmap() to map BSON files on disk <=> memory ﻗ۱ Uses OS-level filesystem cache as block cache ﻗ۱ Much low(er) monitoring visibility ﻗ۱ Database metrics must be gathered from OS-level ﻗ۱ OS-level metrics are more vague
- 6. Storage Engines: MMAPv1 ﻗ۱ Document read path ﻗ۱ Try to load from cache ﻗ۱ If not in cache, load from BSON file on disk ﻗ۱ Document update/write path ﻗ۱ Try to update document in-place ﻗ۱ If too big, ﻗmoveﻗ document on disk until a free space is found
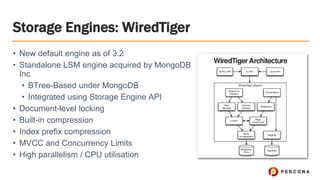
- 7. ﻗ۱ New default engine as of 3.2 ﻗ۱ Standalone LSM engine acquired by MongoDB Inc ﻗ۱ BTree-Based under MongoDB ﻗ۱ Integrated using Storage Engine API ﻗ۱ Document-level locking ﻗ۱ Built-in compression ﻗ۱ Index prefix compression ﻗ۱ MVCC and Concurrency Limits ﻗ۱ High parallelism / CPU utilisation Storage Engines: WiredTiger
- 8. Storage Engines: WiredTiger ﻗ۱ Document Write Path ﻗ۱ Update, delete or write is written to WT log ﻗ۱ Changes to data files are performed by checkpointing later ﻗ۱ Document Read Path ﻗ۱ Looks for data in in-heap cache ﻗ۱ Looks for data in the WT log ﻗ۱ Goes to data files for the data ﻗ۱ Kernel will look in filesystem cache, uncompress result if exists ﻗ۱ If not in FS cache, read from disk and uncompress result ﻗ۱ Switch compression algorithms if CPU is too high
- 9. Storage Engines: RocksDB / MongoRocks ﻗ۱ MongoRocks developed by ﻗ۱ Tiered level compaction strategy ﻗ۱ First layer is called the MemTable ﻗ۱ N number of on-disk levels ﻗ۱ Compaction is triggered when any level is full ﻗ۱ In-heap Block Cache (default 30% RAM) ﻗ۱ Holds uncompressed data ﻗ۱ BlockCache reduces compression CPU hit ﻗ۱ Kernel-level Page Cache for compressed data ﻗ۱ Space amplification of LSM is about +10% ﻗ۱ Optional ﻗcountersﻗ: storage.rocksdb.counters
- 10. Storage Engines: RocksDB / MongoRocks ﻗ۱ Document Write path ﻗ۱ Updates, Deletes and Writes go to Meltable and complete ﻗ۱ Compaction resolves multi-versions of data in the background ﻗ۱ Document Read path ﻗ۱ Looks for data in MemTable ﻗ۱ Level 0 to Level N is asked for the data ﻗ۱ Data is read from filesystem cache, if present, then uncompressed ﻗ۱ Or, bloom filter is used to find data file, then data is read and uncompressed
- 11. Storage Engines: RocksDB / MongoRocks ﻗ۱ Watch for ﻗ۱ Pending compactions ﻗ۱ Stalls ﻗ۱ Indicates compaction system is overwhelmed, possibly due to I/O ﻗ۱ Level Read Latencies ﻗ۱ If high, disk throughput may be too low ﻗ۱ Rate of compaction in bytes vs any noticeable slowdown ﻗ۱ Rate of deletes vs read latency ﻗ۱ Deletes add expense to reads and compaction
- 12. Metric Sources: operationProfiling ﻗ۱ Writes slow database operations to a new MongoDB collection for analysis ﻗ۱ Capped Collection: ﻗsystem.profileﻗ in each database, default 100mb ﻗ۱ The collection is capped, ie: profile data doesnﻗt last forever ﻗ۱ Support for operationProfiling data in Percona Monitoring and Management in current future goals ﻗ۱ Enable operationProfiling in ﻗslowOpﻗ mode ﻗ۱ Start with a very high threshold and decrease it in steps ﻗ۱ Usually 50-100ms is a good threshold ﻗ۱ Enable in mongod.conf operationProfiling: slowOpThresholdMs: 100 mode: slowOp Or the command-line wayﻗ۵ mongod <other-flags> ﻗprofile 1 ﻗslowms 100
- 13. Metric Sources: operationProfiling ﻗ۱ op/ns/query: type, namespace and query of a profile ﻗ۱ keysExamined: # of index keys examined ﻗ۱ docsExamined: # of docs examined to achieve result ﻗ۱ writeConflicts: # of WCE encountered during update ﻗ۱ numYields: # of times operation yielded for others ﻗ۱ locks: detailed lock statistics
- 14. Metric Sources: operationProfiling ﻗ۱ nreturned: # of documents returned by the operation ﻗ۱ nmoved: # of documents moved on disk by the operation ﻗ۱ ndeleted/ninserted/nMatched/nModified: self explanatory ﻗ۱ responseLength: the byte-length of the server response ﻗ۱ millis: execution time in milliseconds ﻗ۱ execStats: detailed statistics explaining the queryﻗs execution steps ﻗ۱ SHARDING_FILTER = mongos sharded query ﻗ۱ COLLSCAN = no index, 35k docs examined(!)
- 15. Metric Sources: db.serverStatus() ﻗ۱ A function that dumps status info about MongoDBﻗs current status ﻗ۱ Think ﻗSHOW FULL STATUSﻗ + ﻗSHOW ENGINE INNODB STATUSﻗ ﻗ۱ Sections ﻗ۱ Asserts ﻗ۱ backgroundFlushing ﻗ۱ connections ﻗ۱ dur (durability) ﻗ۱ extra_info ﻗ۱ globalLock + locks ﻗ۱ network ﻗ۱ opcounters ﻗ۱ opcountersRepl ﻗ۱ repl (replication) ﻗ۱ storageEngine ﻗ۱ mem (memory) ﻗ۱ metrics ﻗ۱ (Optional) wiredTiger ﻗ۱ (Optional) rocksdb
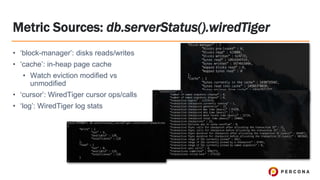
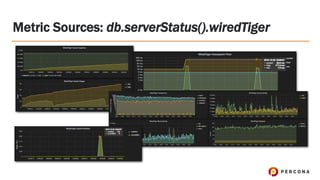
- 18. ﻗ۱ ﻗblock-managerﻗ: disks reads/writes ﻗ۱ ﻗcacheﻗ: in-heap page cache ﻗ۱ Watch eviction modified vs unmodified ﻗ۱ ﻗcursorﻗ: WiredTiger cursor ops/calls ﻗ۱ ﻗlogﻗ: WiredTiger log stats Metric Sources: db.serverStatus().wiredTiger
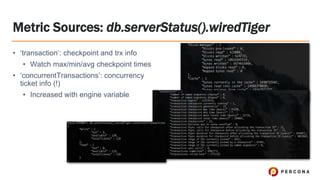
- 19. ﻗ۱ ﻗtransactionﻗ: checkpoint and trx info ﻗ۱ Watch max/min/avg checkpoint times ﻗ۱ ﻗconcurrentTransactionsﻗ: concurrency ticket info (!) ﻗ۱ Increased with engine variable Metric Sources: db.serverStatus().wiredTiger
- 21. Metric Sources: rs.status() ﻗ۱ A function that dumps replication status ﻗ۱ Think ﻗSHOW MASTER STATUSﻗ or ﻗSHOW SLAVE STATUSﻗ ﻗ۱ Contains ﻗ۱ Replication set name and term ﻗ۱ Member status ﻗ۱ State ﻗ۱ Optime state ﻗ۱ Election state ﻗ۱ Heartbeat state
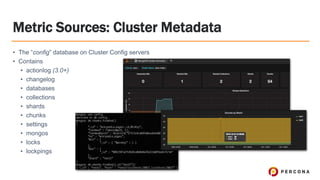
- 22. Metric Sources: Cluster Metadata ﻗ۱ The ﻗconfigﻗ database on Cluster Config servers ﻗ۱ Contains ﻗ۱ actionlog (3.0+) ﻗ۱ changelog ﻗ۱ databases ﻗ۱ collections ﻗ۱ shards ﻗ۱ chunks ﻗ۱ settings ﻗ۱ mongos ﻗ۱ locks ﻗ۱ lockpings
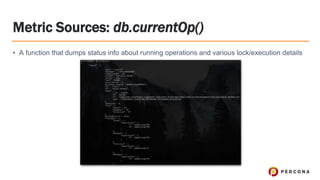
- 23. Metric Sources: db.currentOp() ﻗ۱ A function that dumps status info about running operations and various lock/execution details
- 24. Metric Sources: Log Files ﻗ۱ Interesting details are logged to the mongod/mongos log files ﻗ۱ Slow queries ﻗ۱ Storage engine details (sometimes) ﻗ۱ Index operations ﻗ۱ Chunk moves ﻗ۱ Connections
- 25. Monitoring: Percona PMM ﻗ۱ Open-source monitoring from Percona! ﻗ۱ Based on open- source technology ﻗ۱ Simple deployment ﻗ۱ Examples in this demo are from PMM ﻗ۱ 800+ metrics per ping
- 26. Monitoring: Prometheus + Grafana ﻗ۱ Percona-Lab GitHub ﻗ۱ grafana_mongodb_dashboards for Grafana ﻗ۱ prometheus_mongodb_exporter for Prometheus ﻗ۱ Sources ﻗ۱ db.serverStatus() ﻗ۱ rs.status() ﻗ۱ sh.status() ﻗ۱ Config-server metadata ﻗ۱ Others and more soon.. ﻗ۱ Supports MMAPv1, WT and RocksDB ﻗ۱ node_exporter for Prometheus ﻗ۱ OS-level (mostly Linux) exporter
- 27. Monitoring: Prometheus + Grafana
- 28. Usual Performance Suspects ﻗ۱ Locking ﻗ۱ Collection-level locks ﻗ۱ Document-level locks ﻗ۱ Software mutex/semaphore ﻗ۱ Limits ﻗ۱ Max connections ﻗ۱ Operation rate limits ﻗ۱ Resource limits ﻗ۱ Resources ﻗ۱ Lack of IOPS, RAM, CPU, network, etc
- 29. MongoDB Resources and Consumers ﻗ۱ CPU ﻗ۱ System CPU ﻗ۱ FS cache ﻗ۱ Networking ﻗ۱ Disk I/O ﻗ۱ Threading ﻗ۱ User CPU (MongoDB) ﻗ۱ Compression (WiredTiger and RocksDB) ﻗ۱ Session Management ﻗ۱ BSON (de)serialisation ﻗ۱ Filtering / scanning / sorting ﻗ۱ Optimiser ﻗ۱ Disk ﻗ۱ Data file read/writes ﻗ۱ Journaling ﻗ۱ Error logging ﻗ۱ Network ﻗ۱ Query request/response ﻗ۱ Replication
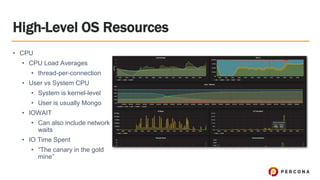
- 30. High-Level OS Resources ﻗ۱ CPU ﻗ۱ CPU Load Averages ﻗ۱ thread-per-connection ﻗ۱ User vs System CPU ﻗ۱ System is kernel-level ﻗ۱ User is usually Mongo ﻗ۱ IOWAIT ﻗ۱ Can also include network waits ﻗ۱ IO Time Spent ﻗ۱ ﻗThe canary in the gold mineﻗ
- 31. High-Level OS Resources ﻗ۱ Process Count ﻗ۱ 1 connection = 1 fork() ﻗ۱ Context Switches ﻗ۱ High switches can == too few CPUs ﻗ۱ Memory ﻗ۱ True used % without caches/buffers ﻗ۱ Cached / Buffers ﻗ۱ Needed for block- caching ﻗ۱ Disk ﻗ۱ Free space percent(!) ﻗ۱ LSM trees use more disk
- 32. MMAPv1: Page Faults ﻗ۱ Linux/Operating System ﻗ۱ Data pages in RAM are swapped to disk due to no free memory ﻗ۱ MongoDB MMAPv1 ﻗ۱ Data is read/written to data file blocks that are not in RAM ﻗ۱ Some page faults are expected but a high rate is suspicious ﻗ۱ A high rate often indicates: ﻗ۱ A working set too large for RAM (or cache size) ﻗ۱ Inefficient patterns (eg: missing index) ﻗ۱ Too many indices vs updates ﻗ۱ A cold-focused access pattern
- 33. MMAPv1: Lock Ratio / Percent ﻗ۱ MMAPv1 ﻗ۱ Lock Ratio/Percent indicates rate of collection- level locking ﻗ۱ ﻗdb.serverStatus.globalLock.ratioﻗ in older versions ﻗ۱ ﻗdb.serverStatus.locksﻗ in newer versions ﻗ۱ RocksDB and WiredTiger ﻗ۱ Global, DB and Collections Locks are ﻗintentﻗ locks/non-blocking
- 34. MMAPv1: Fragmentation ﻗ۱ Can cause serious slowdowns on scans, range queries, etc ﻗ۱ db.<collection>.stats() ﻗ۱ Shows various storage info for a collection ﻗ۱ Fragmentation can be computed by dividing ﻗstorageSizeﻗ by ﻗsizeﻗ ﻗ۱ Any value > 1 indicates fragmentation ﻗ۱ Compact when you near a value of 2 by rebuilding secondaries or using the ﻗcompactﻗ command ﻗ۱ WiredTiger and RocksDB have little/no fragmentation
- 35. MMAPv1: Background Flushing ﻗ۱ Stats on the count/time taken to flush in the background ﻗ۱ If ﻗaverage_msﻗ grow continuously, writes will eventually go direct to disk based on: ﻗ۱ Linux sysctl ﻗvm.dirty_ratioﻗ ﻗ۱ Writes go to disk if dirty page ratio exceeds this number ﻗ۱ Linux sysctl ﻗvm.dirty_background_ratioﻗ
- 36. Rollbacks ﻗ۱ JSON file written to ﻗrollbackﻗ dir on-disk when PRIMARY crashes when ahead of SECONDARYs ﻗ۱ Monitor for this file existing
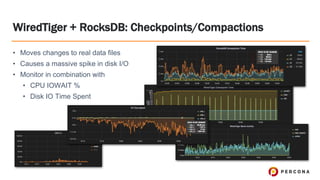
- 37. WiredTiger + RocksDB: Checkpoints/Compactions ﻗ۱ Moves changes to real data files ﻗ۱ Causes a massive spike in disk I/O ﻗ۱ Monitor in combination with ﻗ۱ CPU IOWAIT % ﻗ۱ Disk IO Time Spent
- 38. Replication Lag and Oplog Time Range ﻗ۱ Replication in MongoDB is lightweight BUT it is single threaded ﻗ۱ Shard for more replication throughput ﻗ۱ Replication Lag/Delay ﻗ۱ Subtract PRIMARY and SECONDARY ﻗoptimeﻗ ﻗ۱ Oplog Time Range ﻗ۱ Length of oplog from start -> finish ﻗ۱ Equal to the amount of time to rebuild a node without needing a full re-sync! ﻗ۱ More oplog changes == shorter time range
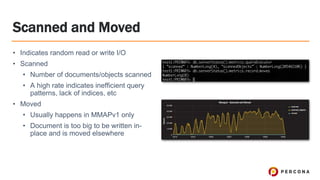
- 39. Scanned and Moved ﻗ۱ Indicates random read or write I/O ﻗ۱ Scanned ﻗ۱ Number of documents/objects scanned ﻗ۱ A high rate indicates inefficient query patterns, lack of indices, etc ﻗ۱ Moved ﻗ۱ Usually happens in MMAPv1 only ﻗ۱ Document is too big to be written in- place and is moved elsewhere
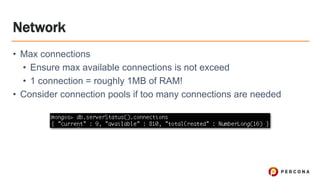
- 40. Network ﻗ۱ Max connections ﻗ۱ Ensure max available connections is not exceed ﻗ۱ 1 connection = roughly 1MB of RAM! ﻗ۱ Consider connection pools if too many connections are needed
- 41. Low-level OS Resources ﻗ۱ Linux Virtual Memory ﻗ۱ vm.swappiness vs swapping rate ﻗ۱ vm.dirty_ratio vs op latency ﻗ۱ Consider lowering to match RAID controller ﻗ۱ Filesystem cached vs Block-device read-ahead ﻗ۱ Linux Network Stack ﻗ۱ Throughput vs total capacity ﻗ۱ SYN Backlogs for TCP ﻗ۱ TIME_WAIT connections ﻗ۱ Network errors/retransmit ﻗ۱ Disk ﻗ۱ Average wait time ﻗ۱ Percent utilisation
- 42. High-level Monitoring Tips ﻗ۱ Polling Frequency ﻗ۱ A lot can happen in 1-10 seconds! ﻗ۱ History ﻗ۱ Have another app/launch to compare with ﻗ۱ Annotate maintenances, launches, DDoS, important events ﻗ۱ What to Monitor ﻗ۱ Fetch more than you graph, thereﻗs no time machine ﻗ۱ (IMHO) monitor until it hurts, then just a bit less than that
- 43. Questions?