More modern gpu
?
58 likes?38,595 views

GPU§¨§ §ºÀŸ§§§Œ§´£¨§fi§ø§Ω§Œ…œ§«§…§Œ§Ë§¶§ •«©`•øòã‘ϧ‰•¢•Î•¥•Í•∫•‡£¨•È•§•÷•È•Í§¨ π§®§Î§Œ§´§Ú’h√˜§∑§fi§π°£Ãÿ§ÀMapReduce§ §…§Œ∑«æ˘Ÿ|§«£¨Îx…¢µƒ§ •¢•Î•¥•Í•∫•‡§¨§§§´§À∏flÀŸ§Àåg¨F§µ§Ï§Î§´§ÚΩBΩȧ∑§fi§π°£ ågÚY§À π§√§ø•≥©`•… https://github.com/hillbig/gpuexperiments •ª•fl• ©`§ŒÑ”ª≠ https://www.youtube.com/watch?v=WmETPBK3MOI



![§∑§´§∑Œ“°©§œCUDA§ÚﯧاŒ§´
l?? ∑Ò£°
®C? Àÿ?»À§œCUDA§Úﯧ§§∆§œ§ §È§ §§ ?[Okuta ?2015]
l?? cupy ?(chainer)
®C? ¥˘§…§Œnumpy§«ï¯§Ø ˝Çé”ãÀ„§œ§Ω§Œ§fi§fiGPUªØ§«§≠§Î
®C? •«•£©`•◊•È©`•À•Û•∞§¿§±§À§ƒ§´§¶§Œ§œŒÃÂüo§§
l?? modern ?gpu/thrust ?£®ΩÒªÿ§Œ•·•§•Û£©
®C? ÎxÎx…¢µƒ§ •¢•Î•¥•Í•∫•‡§ÚSTL§«ï¯§±§Î
®C? CUDA§Ú?“ª«–«–ﯧ´§∫§À§´§ §Íö¯?”√µƒ§À•¢•Î•¥•Í•∫•‡§Ú§´§±§Î
®C? •≥•Û•—•§•Î§¨flW§§§Œ§»•®•È©`ïr§À“‚Œ∂≤ª≤ª√˜
4](https://image.slidesharecdn.com/moremoderngpu-151203045715-lva1-app6891/85/More-modern-gpu-4-320.jpg)



![¥˙±Ìµƒ§ ÅK¡–¡–ÑI¿Ì¿Ì ?(Pre?x-©\??)Scan
l?? ≈‰¡–¡–X[0°≠n)§¨”Χ®§È§Ï§øïr£¨Scan§œ¥Œ§Ú«Û§·§Î
®C? X[i] ?:= ?X[0] ?+ ?X[1] ?+ ?... ?+ ?X[i-©\??1] ? ? ?exclusive ?scan
®C? X[i] ?:= ?X[0] ?+ ?X[1] ?+ ?°≠ ?+ ?X[i] ? ? ? ? ? ?inclusive ?scan
l?? Scan§œ¥Œ§Œ§Ë§¶§ÀÅK¡–¡–§À”ãÀ„§«§≠§Î
®C? ∏˜X[i]§À§ƒ§§§∆£¨X[i] ?+= ?X[i-©\??1]
®C? ∏˜X[i]§À§ƒ§§§∆, ? ?X[i] ?+= ?X[i-©\??2]
®C? ∏˜X[i]§À§ƒ§§§∆£¨X[i] ?+= ?X[i-©\??4]
®C? ...
l?? ¿˝¿˝£∫X[7]§Œïr£¨
®C? X[7] ?+= ?X[6]
®C? X[7] ?+= ?X[5] ?(=X[4]+X[5]) ?
l?? §≥§Ï§œO(log ?n)ïrÈg§«åg?––––§«§≠§Î
8](https://image.slidesharecdn.com/moremoderngpu-151203045715-lva1-app6891/85/More-modern-gpu-8-320.jpg)


![¿˝¿˝£∫•fi©`•∏•Ω©`•» ?(2/2)
÷¥Œµƒ§ •fi©`•∏•Ω©`•»
X, ?Y, ?Z ?
ix ?= ?0, ?iy ?= ?0, ?iz ?= ?0
while ?(iz ?< ?n+m) ?{
? ? ?if ?(comp(X[ix], ?Y[iy]) ?Z[iz++] ?= ?X[ix++]
? ? ?else ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?Z[iz++] ?= ?Y[iy++]
}
// ?æ≥ΩÁÃıº˛§œcomp§¨§¶§fi§§§≥§»§‰§√§∆§Ø§Ï§∆§Î§≥§»§À§∑§fi§π
§≥§Ï§Ú§…§Œ§Ë§¶§À∑÷∏Ó§π§Î§Œ§´£ø
11](https://image.slidesharecdn.com/moremoderngpu-151203045715-lva1-app6891/85/More-modern-gpu-11-320.jpg)
![•fi©`•∏•Ω©`•»§ŒΩ‚·ã
0 1 3 5 6 6 7 9 10
1
2
2
4
7
8
9
9
10
12
––§ÀA°¢¡–§ÀB§ÚÅK§Ÿ§ø––¡–§Úøº§®§Î°£
•fi©`•∏•Ω©`•»§À§™§±§ÎZ[iz++] = X[ix++]§œ”“§ÀflM§‡°¢Z[iz++] = Y[iy++]§œœ¬§À?
flM§‡§Àåùèͧπ§Î
§≥§Œ•—•π§Ú•fi©`•∏•—•π§»∫Ù§÷
X[4]=6 < Y[4]=7](https://image.slidesharecdn.com/moremoderngpu-151203045715-lva1-app6891/85/More-modern-gpu-12-320.jpg)

![•fi©`•∏•—•π§À§Ë§ÎÜñÓ}§Œ∑÷∏Ó
l?? •fi©`•∏•—•π§Ú 𧮧–ÜñÓ}§Ú’˝¥_§ÀÕ¨§∏?¥Û§≠§µ§ŒÜñÓ}§À∑÷§±§È§Ï§Î
®C? •fi©`•∏•—•π§Úµ√§Î§À§œ•fi©`•∏•Ω©`•»§¨±ÿ“™£®—≠≠h??£©
°˙•fi©`•∏•—•π§»§ŒΩª≤Óµ„§œ»´Ã§Ú?“ä“ä§ §Ø§∆§‚«Û§·§È§Ï§Î
15
0 1 3 5 6 6 7 9 10
1
2
2
4
7
8
9
9
10
§≥§ŒæÄ…œ§«∂˛∑÷ÃΩÀ˜
X[i] < Y[8 ®C i]
§»§ §Î◊Ó¥Û§Œi§Ú«Û§·§Î](https://image.slidesharecdn.com/moremoderngpu-151203045715-lva1-app6891/85/More-modern-gpu-15-320.jpg)


![GPU§«MapReduce
l?? Map+Shu?e(Sort)+Reduce§œGPU§«Ñø¬ ¬ ¬ µƒ§Àåg¨Fø…ƒ‹
l?? MapReduce§œ◊ÓΩ¸°¢∑÷…¢ÅK¡–¡–ÑI¿Ì¿Ì§«§œ?∑«Ñø¬ ¬ ¬ µƒ§»é¸§Ï§∆§≠§ø§¨°¢íQ§®§Î”ãÀ„
•Ø•È•π§œ?∑«≥£§Àé⁄§§
®C? ∑÷…¢•Ø•È•π•ø§«§œö∞ªÿ•«•£•π•Ø§Àﯧ≠fiz§‡≤ø∑÷§»Shu?e§¨•‹•»•Î•Õ•√•Ø
®C? GPU§Œàˆ∫œ°¢?∏flé°”ÚGPU•·•‚•Í§ÚΩȧ∑§∆ÑI¿Ì¿Ì§«§≠§Î
l?? Map£∫“™ÀÿD§´§Èø…â‰??ÈL§Œ•≠©`K§»ÇéV§Œ•ø•◊•Î§ŒºØ∫œ§Ú?…˙≥…§π§Î ?D-©\??> ?[K, ?V]
l?? Shu?e£∫Õ¨§∏•≠©`§Œ“™Àÿ§Ú§fi§»§·§Î ?[K, ?V] ?-©\??> ?[K, ?[V]]
l?? Reduce£∫Ç駌ºØ∫œ§ÚÇé§Àù¢§π ?[V] ?-©\??> ?Z
l?? »´Ã§»§∑§∆§œ ?[D] ?-©\??> ?[K, ?Z]
18](https://image.slidesharecdn.com/moremoderngpu-151203045715-lva1-app6891/85/More-modern-gpu-18-320.jpg)







More modern gpu
- 1. More ?Modern ?GPU å˘“∞‘≠?°°?¥Û›o hillbig@preferred.jp Preferred ?Networks, ?Inc. Preferred ?Infrastructure, ?Inc. 12/3 2015°°PFI/PFN »´Ã•ª•fl• ©`
- 2. GPU/CUDA§À§ƒ§§§∆ l?? GPU/CUDA§œΩ¸ƒÍƒÍ?¥Û§≠§ ≥…π¶§ÚÖߧ·§∆§§§Î ®C? •«•£©`•◊•È©`•À•Û•∞°¢ôC–µ—ß¡ï°¢•∑•fl•Â•Ï©`•∑•Á•Û°¢•∞•È•’•£•√•Ø•π l?? GPU§»CPU§Œ≤Ó§œº±ÀŸ§Àé⁄§¨§√§∆§§§Î ®C? •Ø•Ì•√•Ø÷‹≤® ˝§¨Ó^¥Ú§¡§À§ §Í°¢•≥•¢§Ú§ø§Ø§µ§ÛÅK§Ÿ§Î§≥§»§«?∏flÀŸªØ ®C? TitanX ?6TFlops ?(3092 ?cores), ?Xeon ?0.8TFlops ?(18 ?cores) ®C? CPU§œ2ƒÍƒÍö∞§À•≥•¢§¨?∂˛§ƒ§∫§ƒâ৮°¢4ƒÍƒÍö∞§ÀSIMD§Œ∑˘§¨±∂§À§ §Î ®C? GPU§œ2ƒÍƒÍö∞§À•≥•¢§¨?∂˛±∂§À§ §Î l?? GPU§œ•·•‚•Í•–•Û•…∑˘§¨?∑«≥£§À?¥Û§≠§§ ? ®C? •·•‚•Í§¨GPU§ÀΩM§flfiz§fi§Ï§∆§™§Í°¢ ˝∞ŸGB/s l?? § §º§≥§Œ§Ë§¶§ ≤Ó§¨?…˙§fi§Ï§∆§§§Î§Œ§´£ø 2
- 3. GPU§¨?¥Û§≠§ –‘ƒ‹œÚ…œ§Ú§œ§ø§∑§ø¿Ì¿Ì”… l?? •◊•Ì•∞•È•‡§À§™§±§Î√˜? 浃§ ÅK¡–¡–ÑI¿Ì¿Ì ®C? èæ¿¥§ŒCPU§œ÷¥Œµƒ§ ÑI¿Ì¿Ì§Úﯧذ£•≥•¢ ˝§¨â৮§∆§‚§Ω§Ï§Ú¿˚¿˚?”√§π§Î§≥§»§œ¿ßÎy ®C? GPU/CUDA§œ§œ§∏§·§´§È•◊•Ì•∞•È•fi§ÀÅK¡–¡–ÑI¿Ì¿Ì§Úﯧ´§ª§Î°£•◊•Ì•∞•È•fi§œ§π§¥§Ø?¥Û ≧¿§¨°¢GPU§Œ•≥•¢§¨â৮§Î§»–‘ƒ‹§¨•π•±©`•Î§π§Î£®•’•Í©`•È•Û•¡again£© l?? Å¢œÎåg?––––•≥©`•… ®C? Å¢œÎ•◊•Ì•∞•È•‡§œåg?––––ïr§Àåg?––––•≥©`•…§À•È•Û•ø•§•‡§Œ÷–§«â‰ìQ§µ§Ï§Î°£ ®C? HW§œª•ìQ–‘§Ú«–«–§√§ø–¬§∑§§•¢©`•≠•∆•Ø•¡•„§Ú∑eòOµƒ§ÀíÒ?”√§«§≠§Î°£ l?? ?¥Û¡ø¡ø§Œ•π•Ï•√•…§«•Ï•§•∆•Û•∑§ÚÎL§π ®C? CPU§Œ§Ë§¶§ •≠•„•√•∑•Â§œ≥÷§ø§∫°¢∑÷·™”Ëúy§‚§∑§ §§ ®C? •≥•¢ö∞§Œ•≠•„•√•∑•Â•≥•“©`•Ï•Û•∑§œÜñÓ}§À§ §È§ §§ ®C? ?¥Û¡ø¡ø§Œ•π•Ï•√•…§ÚÕ¨ïr§À≥÷§∆§Î§Ë§¶§À§∑£¨•«©`•ø§¨ìB§√§ø•π•Ï•√•…§´§Èåg?––––§π§Î
- 4. §∑§´§∑Œ“°©§œCUDA§ÚﯧاŒ§´ l?? ∑Ò£° ®C? Àÿ?»À§œCUDA§Úﯧ§§∆§œ§ §È§ §§ ?[Okuta ?2015] l?? cupy ?(chainer) ®C? ¥˘§…§Œnumpy§«ï¯§Ø ˝Çé”ãÀ„§œ§Ω§Œ§fi§fiGPUªØ§«§≠§Î ®C? •«•£©`•◊•È©`•À•Û•∞§¿§±§À§ƒ§´§¶§Œ§œŒÃÂüo§§ l?? modern ?gpu/thrust ?£®ΩÒªÿ§Œ•·•§•Û£© ®C? ÎxÎx…¢µƒ§ •¢•Î•¥•Í•∫•‡§ÚSTL§«ï¯§±§Î ®C? CUDA§Ú?“ª«–«–ﯧ´§∫§À§´§ §Íö¯?”√µƒ§À•¢•Î•¥•Í•∫•‡§Ú§´§±§Î ®C? •≥•Û•—•§•Î§¨flW§§§Œ§»•®•È©`ïr§À“‚Œ∂≤ª≤ª√˜ 4
- 5. cupy ?(chainer.cuda.cupy) l?? chainer§ŒÈ_∞k§Œ§ø§·§À◊˜§È§Ï§ønumpyª•ìQ•È•§•÷•È•Í l?? Numpy§»Õ¨§∏§Ë§¶§Àﯧ≠§ §¨§È°¢gpu§Œ–‘ƒ‹§Ú•’•Î§ÀªÓ§´§ª§Î£° l?? ΩÒ§fi§«CUDA§ÚﯧاŒ§¨§ §Û§¿§√§ø§Œ§´§»§§§¶–n샧Œ∫ÜÖg§µ l?? ÷–§Œ ÀΩM§fl ®C? åg?––––ïr§Àcuda•≥©`•…§ÚÑ”µƒ§À?…˙≥…§∑°¢•≥•Û•—•§•Î§∑°¢•≠•„•√•∑•Â ®C? Èv ˝§¥§»§Œ?∑«≥£§Àºö«–«–§Ï§Œcuda•È•§•÷•È•Í§¨?¥Û¡ø¡ø§À§«§≠§∆§§§Î u?? Chainer§Œ“郣§¿§» ˝ÕÚÇÄ ®C? Nvidia§Œ?»À?‘ª§Ø°¢÷±Ω”kernel§Úload§π§Î ÀΩM§fl§Ú¿˚¿˚?”√§∑§ø§Œ§Ú?“ä“ä§ø§Œ§œ?∂˛¿˝¿˝?ƒø§¿§» l?? §≠§√§»Chainer ?Meetup§«‘î§∑§§‘í§¨§µ§Ï§fi§π§Œ§«ΩÒ?»’§œ ° °¬‘¬‘ 5
- 6. ModernGPU§Œ’h√˜§Œ§fi§®§À?? ÅK¡–¡–ÑI¿Ì¿Ì§Œøº§®?∑Ω l?? ÅK¡–¡–ÑI¿Ì¿Ì§Œ∑NÓê ®C? MIMD£®Multiple ?Instruction, ?Multiple ?Data) u?? —} ˝§Œ√¸¡Ó¡Ó§«°¢—} ˝§Œ•«©`•ø§ÚÕ¨ïr§ÀÑI¿Ì¿Ì§π§Î u?? ¿˝¿˝£∫PESY-©\??SC(ÀØ…è)°¢datacenter ?as ?a ?computer ®C? SIMD£®Single ?Instruction, ?Multiple ?Data) u?? ?“ª§ƒ§Œ√¸¡Ó¡Ó§«°¢—} ˝§Œ•«©`•ø§ÚÕ¨ïr§ÀÑI¿Ì¿Ì§π§Î u?? ¿˝¿˝£∫SSE l?? GPU§œMIMD ?+ ?SIMD£®±À§È§œSIMT§»∫Ù§Û§«§§§Î£© ®C? ∏˜•π•»•Í©`•‡•◊•Ì•ª•√•µ(SM£©§œ∂¿?¡¢¡¢§ÀÑ”◊˜§∑ÆêÆê§ §Î•«©`•ø§ÚíQ§¶ ?MIMD ®C? ∏˜SM§œwarpÖgŒª£®ΩÒ§œ16?°´32£©§«Õ¨§∏√¸¡Ó¡Ó§«•«©`•ø§Ú§fi§»§·§∆ÑI¿Ì¿Ì§Ú§π§ÎSIMD u?? »´§∆§Œ•«©`•ø•¢•Ø•ª•π§œgather/scatter ®C? ∏˜SM§œ? Æ∑÷§ ¡ø¡ø§Œ•π•Ï•√•…§Ú≥÷§¡°¢•«©`•ø§¨ìB§√§ø•π•Ï•√•…§´§È åg?––––§π§Î§≥§»§«•Ï•§•∆•Û•∑§ÚÎL§π 6
- 7. ÅK¡–¡–ÑI¿Ì¿Ì§Œ¿ßÎy§µ l?? ÅK¡–¡–ÑI¿Ì¿Ì§œ÷¥ŒÑI¿Ì¿Ì§»§œøº§®?∑Ω§Ú≧®§ §§§»§§§±§ §§ ®C? ?“ª∑¨flW§§?»À§¨?◊„§Ú“˝§√èà§Í°¢»´Ã§Œ–‘ƒ‹§ÚõQ§·§Î ®C? §π§Ÿ§∆§Œ•Í•Ω©`•π§Ú 𧧫–«–§Î§Ë§¶§À?–ƒ§¨§±§Î £®¿˝¿˝°¢ÜñÓ}§Ú100§À§∑§´∑÷∏Ó§«§≠§ §§àˆ∫œ£¨3000•≥•¢÷–2900•≥•¢§œ π§Ô§Ï§ §§£© ®C? ÜñÓ}§œ?¥Û¡ø¡ø§Œ»´§ØÕ¨§∏?¥Û§≠§µ§Œ∂¿?¡¢¡¢§ÀΩ‚§±§ÎÜñÓ}§À∑÷Ω‚§µ§Ï§Î§Œ§¨¿Ì¿ÌœÎ l?? ÷¥ŒÑI¿Ì¿Ì§»§œfl`§¶•¢•Î•¥•Í•∫•‡°¢•«©`•øòã‘ϧ¨±ÿ“™ ®C? ?–°? ÷œ»§«§ŒÅK¡–¡–ªØ§œ–‘ƒ‹§œ§«§∫£¨flW§Ø§ §Î§≥§»§‚ 7
- 8. ¥˙±Ìµƒ§ ÅK¡–¡–ÑI¿Ì¿Ì ?(Pre?x-©\??)Scan l?? ≈‰¡–¡–X[0°≠n)§¨”Χ®§È§Ï§øïr£¨Scan§œ¥Œ§Ú«Û§·§Î ®C? X[i] ?:= ?X[0] ?+ ?X[1] ?+ ?... ?+ ?X[i-©\??1] ? ? ?exclusive ?scan ®C? X[i] ?:= ?X[0] ?+ ?X[1] ?+ ?°≠ ?+ ?X[i] ? ? ? ? ? ?inclusive ?scan l?? Scan§œ¥Œ§Œ§Ë§¶§ÀÅK¡–¡–§À”ãÀ„§«§≠§Î ®C? ∏˜X[i]§À§ƒ§§§∆£¨X[i] ?+= ?X[i-©\??1] ®C? ∏˜X[i]§À§ƒ§§§∆, ? ?X[i] ?+= ?X[i-©\??2] ®C? ∏˜X[i]§À§ƒ§§§∆£¨X[i] ?+= ?X[i-©\??4] ®C? ... l?? ¿˝¿˝£∫X[7]§Œïr£¨ ®C? X[7] ?+= ?X[6] ®C? X[7] ?+= ?X[5] ?(=X[4]+X[5]) ? l?? §≥§Ï§œO(log ?n)ïrÈg§«åg?––––§«§≠§Î 8
- 9. Modern ?GPU l?? GPU§¨”–Ñø§ §Œ§œ”ãÀ„¡£¡£∂»∂»§¨Õ¨§∏§Ë§¶§ ˝Çé”ãÀ„ÜñÓ}§Œ§fl§´£ø °˙?°°Õ®≥£§ŒÎxÎx…¢µƒ•¢•Î•¥•Í•∫•‡§«§‚”–Ñø l?? Modern ?GPU ®C? Nvidia§¨2013ƒÍƒÍ§À∞k±Ì°¢•È•§•÷•È•Í§»°¢•…•≠•Â•·•Û•»§´§Èòã≥…§µ§Ï§Î ®C? http://nvlabs.github.io/moderngpu/ l?? ª˘±æµƒ§ øº§® ®C? 1. ?ÜñÓ}§ÚÑI¿Ì¿Ì¡ø¡ø§¨»´§ØÕ¨§∏?¥Û§≠§µ§Œ?–°§µ§ ÜñÓ}§À∑÷∏Ó§π§Î ®C? 2. ?∏˜ÜñÓ}§Ú∂¿?¡¢¡¢§À∆’Õ®§Œ÷¥Œµƒ§ •¢•Î•¥•Í•∫•‡§«Ω‚§Ø ®C? 3. ?£®±ÿ“™§Àèͧ∏§∆£©Ω‚§Ú§fi§»§·§Î l?? ÷ÿ“™§ §Œ§œ1§Œ»´§ØÕ¨§∏?¥Û§≠§µ§À∑÷∏Ó§π§Î§»§≥§Ì 9
- 10. ¿˝¿˝£∫•fi©`•∏•Ω©`•» ?(1/2) l?? ?∂˛§ƒ§Œ•Ω©`•»úg§fl≈‰¡–¡–X, ?Y§¨”Χ®§È§Ï§øïr£¨§≥§Ï§È§Ú§¢§Ô§ª§∆•Ω©`•»§ª§Ë l?? X ?= ?{1, ?3, ?3, ?5, ?7, ?9, ?10, ?10, ?11, ?13, ?15} l?? Y ?= ?{0, ?2, ?3, ?3, ?7, ?8, ? ? ?8, ? ? ?9, ?10, ?11, ?14} l?? Z={0, ?1, ?2, ?3, ?3, ?3, ?3, ?5, ?7, ?7 ?8, ?8, ?9, ?9, ?10, ?10, ?10, ?11, ?11, ?13, ?14, ?15} l?? §Ω§Ï§æ§Ï§Œ≈‰¡–¡–??ÈL§Ún=|X|, ?m=|Y|§»§∑§øïr£¨”ãÀ„¡ø¡ø§œO(n+m) 10
- 11. ¿˝¿˝£∫•fi©`•∏•Ω©`•» ?(2/2) ÷¥Œµƒ§ •fi©`•∏•Ω©`•» X, ?Y, ?Z ? ix ?= ?0, ?iy ?= ?0, ?iz ?= ?0 while ?(iz ?< ?n+m) ?{ ? ? ?if ?(comp(X[ix], ?Y[iy]) ?Z[iz++] ?= ?X[ix++] ? ? ?else ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?Z[iz++] ?= ?Y[iy++] } // ?æ≥ΩÁÃıº˛§œcomp§¨§¶§fi§§§≥§»§‰§√§∆§Ø§Ï§∆§Î§≥§»§À§∑§fi§π §≥§Ï§Ú§…§Œ§Ë§¶§À∑÷∏Ó§π§Î§Œ§´£ø 11
- 12. •fi©`•∏•Ω©`•»§ŒΩ‚·ã 0 1 3 5 6 6 7 9 10 1 2 2 4 7 8 9 9 10 12 ––§ÀA°¢¡–§ÀB§ÚÅK§Ÿ§ø––¡–§Úøº§®§Î°£ •fi©`•∏•Ω©`•»§À§™§±§ÎZ[iz++] = X[ix++]§œ”“§ÀflM§‡°¢Z[iz++] = Y[iy++]§œœ¬§À? flM§‡§Àåùèͧπ§Î §≥§Œ•—•π§Ú•fi©`•∏•—•π§»∫Ù§÷ X[4]=6 < Y[4]=7
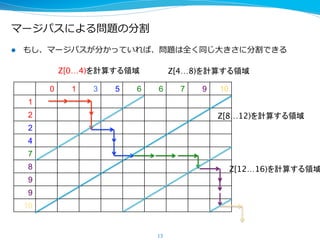
- 13. •fi©`•∏•—•π§À§Ë§ÎÜñÓ}§Œ∑÷∏Ó l?? §‚§∑°¢•fi©`•∏•—•π§¨∑÷§´§√§∆§§§Ï§–°¢ÜñÓ}§œ»´§ØÕ¨§∏?¥Û§≠§µ§À∑÷∏Ó§«§≠§Î 13 0 1 3 5 6 6 7 9 10 1 2 2 4 7 8 9 9 10 Z[0°≠4)§Ú”ãÀ„§π§ÎÓI”Ú Z[4°≠8)§Ú”ãÀ„§π§ÎÓI”Ú Z[8°≠12)§Ú”ãÀ„§π§ÎÓI”Ú Z[12°≠16)§Ú”ãÀ„§π§ÎÓI”Ú
- 14. •fi©`•∏•—•π§À§Ë§ÎÜñÓ}§Œ∑÷∏Ó l?? X ?= ?0 ?1 ?3 ?5 ?6 ?6 ?7 ?9 ?10 ? l?? Y ?= ?1 ?2 ?2 ?4 ?7 ?8 ?9 ?9 ?10 l?? §Ω§Ï§æ§Ï§ŒÜñÓ}§œ°¢??ÈL§µ4§ŒΩYπ˚§Ú≥ˆ?¡¶¡¶§π§Î•fi©`•∏•Ω©`•»§À∑÷∏Ó§µ§Ï§Î l?? 0 ?1 ?§» ?1 ?2 ?§Œ•fi©`•∏•Ω©`•» l?? 3 ?5 ?§» ?2 ?4 ?§Œ•fi©`•∏•Ω©`•» l?? 6 ?6 ?7 ?§» ?7 ?§Œ•fi©`•∏•Ω©`•» l?? 9 ?§» ?8 ?9 ?9 ?§Œ•fi©`•∏•Ω©`•» l?? 10 ?§» ?10 ?§Œ•fi©`•∏•Ω©`•»£®◊Ó··§¿§±??ÈL§µ§œfl`§¶£©
- 15. •fi©`•∏•—•π§À§Ë§ÎÜñÓ}§Œ∑÷∏Ó l?? •fi©`•∏•—•π§Ú 𧮧–ÜñÓ}§Ú’˝¥_§ÀÕ¨§∏?¥Û§≠§µ§ŒÜñÓ}§À∑÷§±§È§Ï§Î ®C? •fi©`•∏•—•π§Úµ√§Î§À§œ•fi©`•∏•Ω©`•»§¨±ÿ“™£®—≠≠h??£© °˙•fi©`•∏•—•π§»§ŒΩª≤Óµ„§œ»´Ã§Ú?“ä“ä§ §Ø§∆§‚«Û§·§È§Ï§Î 15 0 1 3 5 6 6 7 9 10 1 2 2 4 7 8 9 9 10 §≥§ŒæÄ…œ§«∂˛∑÷ÃΩÀ˜ X[i] < Y[8 ®C i] §»§ §Î◊Ó¥Û§Œi§Ú«Û§·§Î
- 16. •fi©`•∏•—•π§À§Ë§ÎÅK¡–¡–•fi©`•∏•Ω©`•»§fi§»§· l?? ÜñÓ}§Ú∑÷∏Ó§π§Î ®C? ?∂˛∑÷ÃΩÀ˜À˜§Ú•÷•Ì•√•Ø ˝§¿§±§‰§Î£®ÅK¡–¡–£© l?? ∑÷∏Ó§µ§Ï§øÜñÓ}§Ú§Ω§Ï§æ§Ï∂¿?¡¢¡¢§À÷¥Œµƒ§ÀΩ‚§Ø ®C? ¥§®§ÚﯧØZ§ŒŒª÷√§‚∑÷§´§√§∆§§§Î ®C? πÃ∂®??ÈL§ŒÜñÓ}§ §Œ§«°¢•Î©`•◊§œ’πÈ_§∑§∆§™§±§Î ?#pragma ?unroll ®C? §≥§Œàˆ∫œ°¢Ω‚§œ§fi§»§·§Î±ÿ“™§¨§ §§ l?? ?∑«≥£§À?∏flÀŸ ®C? TitanX§À§™§§§∆ ? ?288GB/√Σ®32•”•√•»’˚ ˝§Œàˆ∫œ£¨700É|º˛/√Σ© 16
- 17. ¥Œ§Œ§Ë§¶§ ÜñÓ}§‚Õ¨òî§À§∑§∆Ω‚§±§Î l?? Bulk ?Insert, ?Bulk ?Delete ®C? §fi§»§·§∆í∑?»Î°¢§fi§»§·§∆œ˜≥˝ l?? Segmented ?Vector ?Reduction ®C? ??ÈL§µ§ŒÆêÆê§ §Î≈‰¡–¡–§ŒºØ∫œ§Àåù§∑£¨∏˜≈‰¡–¡–ö∞§ÀReduction§Ú§π§Î l?? DB§À§™§±§ÎJoin ®C? Outer, ?Inner, ?Left-©\??, ?Right-©\?? ?Join ®C? §‰§√§∆§§§Î§≥§»§œ•fi©`•∏•Ω©`•»§»§€§‹Õ¨§∏ l?? Ãÿ§À≈dŒ∂…Ó§§§Œ§¨MapReduce§¨§«§≠§Îµ„ l?? §≥§Ï§È§œ£¨Modern ?GPU£¨Thrust, ?Cub§ §…§Œ•È•§•÷•È•Í§«Ã·π©§µ§Ï§∆§§§Î 17
- 18. GPU§«MapReduce l?? Map+Shu?e(Sort)+Reduce§œGPU§«Ñø¬ ¬ ¬ µƒ§Àåg¨Fø…ƒ‹ l?? MapReduce§œ◊ÓΩ¸°¢∑÷…¢ÅK¡–¡–ÑI¿Ì¿Ì§«§œ?∑«Ñø¬ ¬ ¬ µƒ§»é¸§Ï§∆§≠§ø§¨°¢íQ§®§Î”ãÀ„ •Ø•È•π§œ?∑«≥£§Àé⁄§§ ®C? ∑÷…¢•Ø•È•π•ø§«§œö∞ªÿ•«•£•π•Ø§Àﯧ≠fiz§‡≤ø∑÷§»Shu?e§¨•‹•»•Î•Õ•√•Ø ®C? GPU§Œàˆ∫œ°¢?∏flé°”ÚGPU•·•‚•Í§ÚΩȧ∑§∆ÑI¿Ì¿Ì§«§≠§Î l?? Map£∫“™ÀÿD§´§Èø…â‰??ÈL§Œ•≠©`K§»ÇéV§Œ•ø•◊•Î§ŒºØ∫œ§Ú?…˙≥…§π§Î ?D-©\??> ?[K, ?V] l?? Shu?e£∫Õ¨§∏•≠©`§Œ“™Àÿ§Ú§fi§»§·§Î ?[K, ?V] ?-©\??> ?[K, ?[V]] l?? Reduce£∫Ç駌ºØ∫œ§ÚÇé§Àù¢§π ?[V] ?-©\??> ?Z l?? »´Ã§»§∑§∆§œ ?[D] ?-©\??> ?[K, ?Z] 18
- 19. GPU§«‹û÷√•’•°•§•Î§Ú◊˜§√§∆§fl§Ë§¶ l?? ‹û÷√•’•°•§•Î ®C? ∏˜Ög’Zö∞§À§Ω§Œ≥ˆ¨FŒª÷√§Ú”õÂh 1.? ?Œƒ◊÷¡–¡–÷–§ŒÖg’Z ˝§Ú ˝§®§Î 1.? Ög’Zæ≥ΩÁ§Œ ˝§Ú ˝§®§Î£®!isAlpha(right) ?&& ?isAlpha(left)) ? 2.? ∏˜Ög’Z§Œ≥ˆ¨FŒª÷√§»°¢§Ω§Œ•œ•√•∑•ÂÇé§Ú”ãÀ„§π§Î 1.? §≥§Ï§œSegmented ?Reduction§«Ω‚§±§Î 2.? £®•œ•√•∑•ÂÇé°¢Œª÷√°¢??ÈL§µ£©§ÚReduce§π§Î 3.? KR∑®§«•œ•√•∑•ÂÇé§Ú”ãÀ„§π§Î§Œ§«Reduce§ŒÌò§À§Ë§È§ §§ 3.? •œ•√•∑•ÂÇ駫Ög’Z§Ú•Ω©`•»§∑ºØ§·§Î 4.? •œ•√•∑•ÂÇ駫Segmented ?Reduction 1.? ∏˜Ög’Zö∞§Œ≥ˆ¨FŒª÷√§Ú§fi§»§·§Î 19
- 21. ågÚY l?? ”¢?Œƒ700MB l?? •fi•∑•Û£∫Titan ?X l?? ætÖg’Z ˝ ?106,888,008 l?? ÆêÆê§ §ÍÖg’Z ˝ ?1,252,268 l?? GPUåg?––––ïrÈg£∫1.67√Î ®C? §Ω§Œ§¶§¡°¢CPU-©\??>GPU ?•≥•‘©`ïrÈg£∫0.2√Î ®C? µ´§∑°¢•≠©`§Œ0.1%Œ¥ú∫§œ–nÕª§∑§∆§§§Î l?? ?±»›^£∫CPUåg?––––ïrÈg ?14.80√Î l?? ºs10±∂»ı§œÀŸ§Ø§ §√§ø 21
- 22. 22 input=300000000 wordCount=45788064 distinctWord=1129243 words=45788064 0 2528465 the 1 1564080 of 2 1219248 and 3 986168 in 4 862412 a 5 862356 to 6 507386 is 7 484451 The 8 445334 was 9 336005 for 10 334510 s 11 316207 as 12 295183 by 13 282728 with 14 281566 on 15 241960 that 16 235218 doc 17 221649 from 18 193797 at 19 189947 his 20 157175 an
- 23. •≥•Û•—•§•ÎïrÈg l?? nvcc ?+ ?thrust ?§ŒΩM§fl∫œ§Ô§ª§œ•≥•Û•—•§•ÎïrÈg§¨§‰§–§§ ®C? »´§∆template§«•≥•Û•—•§•Îïr§À’πÈ_§µ§Ï§Î§¿§±§«§ §Ø°¢nvccÇ»§Œ◊ÓflmªØ§‚ ®C? 1∑÷§∞§È§§§´§´§Î l?? §™Ñ·§·§œÈv ˝ö∞§ÀÑe•Ω©`•π•’•°•§•Î§«•≥•Û•—•§•Î ®C? 10√Χ∞§È§§§ §Œ§«£¨‘S»›π†áÏ?? 23
- 24. §fi§»§· l?? GPU§À§Ë§ÎÅK¡–¡–ÑI¿Ì¿Ì§ÚΩBΩȧ∑§ø ®C? ÎxÎx…¢µƒ§«?∑«æ˘Ÿ|§ ÜñÓ}§‚Ñø¬ ¬ ¬ µƒ§ÀΩ‚§±§Î•¢•Î•¥•Í•∫•‡§¨µ«àˆ§∑§∆§≠§ø ®C? cupy, ?thrust, ?cub£®Œ¥ΩBΩÈ£©§ §…§Ú 𧮧–CUDA§Úﯧ´§ §Ø§∆§‚ÅK¡–¡–ÑI¿Ì¿Ì§«§≠§Î l?? ΩÒ··§œ?∑«Õ¨∆⁄£¨ÅK¡–¡–ÑI¿Ì¿Ì§¨÷ÿ“™§À§ §Î ®C? ÷–—κØòÿ–Õ£¨÷¥Œ–Õ§œ–‘ƒ‹?√Ê£¨Îä?¡¶¡¶œ˚ŸM?√ʧ«∏Ç’˘?¡¶¡¶§¨¬‰¬‰§¡§∆§§§Ø ®C? Go§Œchannel, ?go ?routine§Œ§Ë§¶§ ?—‘’Z§À§Ë§Î•Õ•§•∆•£•÷•µ•›©`•»§¨±ÿ“™ ®C? •«©`•ø§Œ“¿¥ÊÈvÇS§Ú?◊‘»ª§À±Ì§∑§ø£¨•«©`•ø•’•Ì©`•‚•«•Î l?? ŒÙ§Œ•«©`•ø•ª•Û•ø©`§¨ΩÒ§œ£±•¡•√•◊§«åg¨F ®C? Datacenter ?as ?a ?computer§Œ÷¯’fl§¨”Ë?—‘§∑§∆§§§ø•«©`•ø•ª•Û•ø©`§¨1•¡•√•◊§ÀÖß §fi§Îïr¥˙§¨µΩ¿¥§∑§ƒ§ƒ§¢§Î ?( ˝? ÆTFlops ?in ?1 ?chip) ®C? Õ®–≈§œ•Ï•§•∆•Û•∑£¨•π•Î©`•◊•√•»£¨Îä?¡¶¡¶¡ø¡ø§¨ÜñÓ}£Æœ¡§§àˆÀ˘§«ÑI¿Ì¿Ì§π§Ï§–»´≤øΩ‚õQ 24
- 25. Copyright ?? ?2015-©\?? Preferred ?Networks ?All ?Right ?Reserved.