²Ń±č±ō³Ü²õ¤ĪŹ¹¤¤·½””³õ¼¶±ą
?
20 likes?50,322 views

¤³¤Ī„¹„鄤„ɤĪ„³©`„ɤĻMplus„Ē„ā°ę¤ĒgŠŠæÉÄܤĒ¤¹”£ http://www.statmodel.com/demo.shtml ¤Ž¤æ”¢¤³¤Į¤é¤Ī„Ś©`„ø¤Ė„µ„ó„ׄė„Ē©`„æ¤ņÖƤ¤¤Ę¤¤¤Ž¤¹”£ http://bit.ly/12NgDmI ÖŠ¼¾¤Ļ¤³¤Į¤é¤ņ¤É¤¦¤¾”£ http://www.slideshare.net/simizu706/mplus-lecture-2



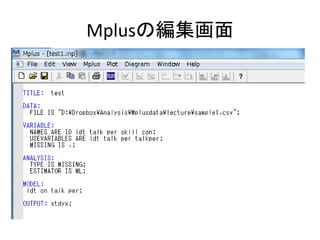
















![MODEL: „³„Ž„ó„É
? „ā„Ē„ė¤ņÖø¶Ø¤¹¤ė
ØC „ā„Ē„ė¤Īų¤·½¤Ī»ł±¾¤ĻŅŌĻĀ¤Ī5¤Ä”£
? »Ų¢·ÖĪö£ØŌģ·½³ĢŹ½£©¤Ļ ON
? Ņņ×Ó·ÖĪö£Øy¶Ø·½³ĢŹ½£©¤Ļ BY
? ¹²·ÖÉ¢¤Ļ WITH
? 䏿Ćū¤Ą¤±¤ņų¤Æ¤Č”¢·ÖÉ¢¤ņĶĘ¶Ø¤¹¤ėÖø¶Ø
? [䏿Ćū]¤Čų¤Æ¤Č”¢Ę½¾ł¤ņĶĘ¶Ø¤¹¤ėÖø¶Ø
? „Ń„é„į©`„æ¤ĪÖĘ¼s¤ņ¤¹¤ė
ØC MODEL CONSTRAINT:¤Īįį¤Ėų¤Æ
? ¤³¤ģ¤Ė¤Ä¤¤¤Ę¤Ļ”¢įįŹö](https://image.slidesharecdn.com/mpluslecture1-130312082227-phpapp02/85/Mplus-23-320.jpg)









![ßmŗĻ¶ČÖøĖ
? ĒéóĮæ»łŹ
ØC „ā„Ē„ė±ČŻ^¤ĖŹ¹¤¦
? ¦¶2\
ØC „ā„Ē„ė¤¬„Ē©`„æ¤ČµČ¤·¤¤¤Č¤¤
¤¦¢o¢Õh¤Ī“_ĀŹ
? RMSEA
ØC 0.05£Ø0.10£©ŅŌĻĀ¤¬¤č¤¤
ØC ¼sŠŌ¤ņæ¼]¤·¤æÖøĖ
? CFI
ØC 0.95ŅŌÉĻ¤¬¤č¤¤
ØC ¼sŠŌ¤ņ¤ä¤äæ¼]¤·¤æÖøĖ
? SRMR
ØC 0.05£Ø0.10£©ŅŌĻĀ¤¬¤č¤¤
ØC „ā„Ē„ė¤Č„Ē©`„æ¤Ī¾ąėx](https://image.slidesharecdn.com/mpluslecture1-130312082227-phpapp02/85/Mplus-34-320.jpg)



![Ę½¾ł¤ĪÖø¶Ø
? Ę½¾łŌģ¤ĪĶʶØ
ØC TYPE = GENERAL¤Ė¤·¤Ę¤Ŗ¤±¤Š”¢×ŌӵĤĖĘ½¾łŌģ¤ā
ĶĘ¶Ø¤µ¤ģ¤ė
ØC ×Ō·Ö¤ĒÖø¶Ø¤·¤Ę¤Ŗ¤¤æ¤¤öŗĻ¤Ļ”¢[]¤ņŹ¹¤Ć¤Ę
[idt];
? ¤Čų¤Æ”£
ØC Ę½¾ł¤Ė¹Ģ¶ØÖĘ¼s¤ņÓė¤Ø¤æ¤¤öŗĻ¤Ļ”¢
[idt@0];
? ¤Čų¤Æ”£
ØC Ę½¾ł¤ņĶĘ¶Ø¤·¤æ¤Æ¤Ź¤¤öŗĻ¤Ļ”¢ANALYSIS„³„Ž„ó„ɤĪ
¤Č¤³¤ķ¤Ė”¢MODEL = NOMEANSTRUCTURE;¤Čų¤Æ”£](https://image.slidesharecdn.com/mpluslecture1-130312082227-phpapp02/85/Mplus-42-320.jpg)






















²Ń±č±ō³Ü²õ¤ĪŹ¹¤¤·½””³õ¼¶±ą
- 1. ²Ń±č±ō³Ü²õµ¼Čė±ą?ČėĆűą ĒåĖ®Ō£Źæ Śu“óѧ“óѧŌŗ¾tŗĻæĘѧъ¾ææĘ
- 3. Mplus¤Č¤Ļ ? Muthئn£¦Muthئn¤¬×÷¤Ć¤æ½yÓ„½„Õ„Č„¦„§„¢ ØC Ö÷¤ĖŌģ·½³ĢŹ½„ā„Ē„ź„ó„°¤Ī¤æ¤į¤Ī„½„Õ„Č ØC http://www.statmodel.com/ ? ·Ē³£¤Ėø߶ȤŹ·ÖĪö¤¬æÉÄÜ ØC Amos¤¬¤Ē¤¤ė¤³¤Č¤ĻČ«²ææÉÄÜ ØC „«„Ę„“„ź„«„ė„Ē©`„æ·ÖĪö”¢„Ž„ė„Į„ģ„Ł„ė·ÖĪö”¢Ē±ŌŚ„Ƅ鄹 ·ÖĪö”¢¤½¤ģ¤é¤Ī½M¤ßŗĻ¤ļ¤»”¢¤Ź¤É ? CUI£ØCharacter User Interface)¤ņńÓĆ ØC ×ī³õ¤Ļ¤ä¤äT¤ģ¤¬±ŲŅŖ ØC ×īŠĀ°ę£ØMplus7£©¤Ļ”¢Ņ»²æGUI¤Ėź
- 7. Mplus¤Č¤Ļ ? CÄܤĪøī¤Ė¤«¤Ź¤ź°²¤¤ ØC ѧɜ¤ĪöŗĻ ? »ł±¾„ā„Ē„ė 2ĶņŅČõ ? Č«²æČė¤ź 4ĶņŅČõ ØC ½ĢT¤ĪöŗĻ ? »ł±¾„ā„Ē„ė 5Ķņ6Ē§Ņ ? Č«²æČė¤ź 8Ķņ4Ē§Ņ ØC ¤·¤«¤ā”¢Ķ¬¤ø„Š©`„ø„ē„󤏤éÓĄ¾Ć¤ĖŹ¹¤Ø¤ė ? „¢„ƄׄĒ©`„Ȥ¹¤ėöŗĻ¤Ļ”¢1Äźég¤ĻoĮĻ”£¤½¤ģŅŌ½µ¤ĻÓŠĮĻ
- 8. Amos¤Č¤Īß`¤¤ ? GUI£ØAmos£©¤«CUI£ØMplus£©¤« ØC ¤³¤ģ¤Ė¤ĻŅ»éLŅ»¶Ģ¤¬¤¢¤ė ? ŗ g¤Ź„Ń„¹„ā„Ē„ė¤ĻAmos¤Ī¤Ū¤¦¤¬ŗ g ? Mplus¤Ą¤Č”¢”±F1 by v1-v40;”± ¤Č¤¤¤¦„³©`„ɤĄ¤±¤Ē40ķÄæ¤ĪŅņ×Ó·ÖĪö¤¬¤Ē¤¤ė¤¬”¢ Amos¤Ą¤Č“ó䔣 ? ·ÖĪö¤ĪCÄÜ ØC ĶźČ«¤ĖMplus£¾Amos ? Amos¤Ē¤Ē¤¤ė¤³¤Č¤Ļ¤¹¤Ł¤Ę¤Ē¤¤ė ? „鄤„»„󄹤ĪQ¤¤ ØC Amos¤ĻIBM¤Ź¤Ī¤Ēøßż£¦Äź gĪ»¤ĒøüŠĀ¤¬±ŲŅŖ ØC Mplus¤ĻŅ»¶ČŁČė¤¹¤ģ¤Š”¢Ķ¬¤ø„Š©`„ø„ē„󤏤é¤ŗ¤Ć¤ČŹ¹¤Ø¤ė ? ČÕ±¾ÕZ¤Ų¤Īź ØC Amos¤ĻČÕ±¾ÕZ¤ĖĶźČ«ź Mplus¤ĻĶźČ«²»ź ØC ½ńįį¤āMplus¤ĻČÕ±¾ÕZ¤Ėź¤¹¤ė¤³¤Č¤Ļ¤Ź¤¤
- 10. ČėéT¾„į„Ė„å©` ? „Ē©`„æ¤ĪÕi¤ßŽz¤ß ØC „Ē©`„æ„»„ƄȤĪŹä ØC »ł±¾µÄ¤Ź„³©`„ɤĪų¤·½ ? ¤Č¤ź¤¢¤Ø¤ŗ»Ų¢·ÖĪö ØC ÖŲ»Ų¢·ÖĪö ØC „Ń„¹½āĪö ? ¤Č¤ź¤¢¤Ø¤ŗŅņ×Ó·ÖĪö ØC “_ÕJµÄŅņ×Ó·ÖĪö ØC Ģ½Ė÷µÄŅņ×Ó·ÖĪö
- 11. Mplus¤Ī³É ? „Ē©`„æ„Õ„”„¤„ė ØC Mplus¤Ī„Ē„Õ„©„ė„ȤĒ¤Ļ.dat¤Ī×Ó”£¤Ē¤ā.txt¤Č¤«¤Ē¤ā ¤č¤¤”£ ? ČėĮ¦„Õ„”„¤„ė ØC inp„Õ„”„¤„ė¤Čŗō¤Š¤ģ¤ė”£¤³¤ģ¤Ė¤¹¤Ł¤Ę¤Ī„³©`„ɤņų¤Æ”£ ØC ×Ó¤Ļ.inp ? ³öĮ¦„Õ„”„¤„ė ØC out„Õ„”„¤„ė¤Čŗō¤Š¤ģ¤ė”£¤³¤ģ¤Ė·ÖĪö½Y¹ū¤¬³öĮ¦¤µ¤ģ¤ė”£ ØC ×Ó¤Ļ.out
- 12. „Ē©`„æ„Õ„”„¤„ė¤ĪÕi¤ßŽz¤ß ? Õi¤ßŽz¤ß„Õ„”„¤„ė ØC dat„Õ„”„¤„ė(.dat) ØC „Ę„„¹„Č„Õ„”„¤„ė(.txt) ØC csv„Õ„”„¤„ė(.csv) ? „Ē©`„æĒųĒŠ¤ź ØC „¹„Ś©`„¹ ØC „æ„Ö ØC „«„ó„Ž ? WČĖ¤Ī„Ŗ„¹„¹„į¤Ļ”¢„æ„ÖĒųĒŠ¤ź¤Ī„Ę„„¹„Č„Õ„”„¤„ė
- 13. Ąż£ŗ„Ø„Æ„»„ė¤Ī„Ē©`„椫¤éMplus¤Ų 0 ? MplusÓƤĪ„Õ„©„ė„Ą¤ņ×÷¤ė ØC Mplus¤ĻČÕ±¾ÕZ¤Ī„Ń„¹¤ņÕi¤į¤Ź¤¤£” ? „ę©`„¶©`Ćū¤¬ČÕ±¾ÕZ¤ĪČĖ¤Ļ”¢„Ž„¤„É„„å„į„ó„ȤĖ¤Ŗ¤¤ ¤Ę¤āÕJ×R¤µ¤ģ¤Ź¤¤ ØC ĒåĖ®¤«¤é¤Ī„Ŗ„¹„¹„į ? C:?mplusfile?”«¤Ź¤É”¢C„Ʉ鄤„Ö¤ĖÖ±½Ó„Õ„©„ė„Ą¤ņ×÷¤ė ? W¤ĻD„Ʉ鄤„Ö¤ĖDropbox¤ņÖƤ¤¤Ę¤¤¤ė¤Ī¤Ē”¢¤½¤³¤Ė”£
- 14. Ąż£ŗ„Ø„Æ„»„ė¤Ī„Ē©`„椫¤éMplus¤Ų 1 ? „Ø„Æ„»„ė¤Ī„Ē©`„æ¤ņßxk¤·¤Ę„³„Ō©` ØC 䏿Ćū¤Ļŗ¬¤į¤Ź¤¤
- 16. Ąż£ŗ„Ø„Æ„»„ė¤Ī„Ē©`„椫¤éMplus¤Ų 3 ? „Õ„”„¤„ė¤Ī±£“ęöĖł ØC Mplus¤ĪČėĮ¦„Õ„”„¤„ė(.inp)¤ČĶ¬¤ø„Õ„©„ė„Ą¤ĖČė¤ģ¤ė¤³ ¤Č¤ņ„Ŗ„¹„¹„į¤¹¤ė”£Ō¼¤ĻįįŹö”£ ØC ¤µ¤Ć¤×÷¤Ć¤æ”¢MplusÓƤĪ„Õ„©„ė„Ą¤ĪÖŠ¤ĖČė¤ģ¤ė ? ±£“ę·½·Ø ØC ±£“ę¤¹¤ė¤Č¤”¢×Ó¤Ļ.dat¤Ī¤Ū¤¦¤¬±ćĄū¤«¤ā¤·¤ģ¤Ź ¤¤¤±¤É”¢¤½¤³¤ĻŗƤߤĒ”£ ? .dat¤«”¢.txt”¢.csv¤¢¤æ¤ź¤Ē”£ ØC ČÕ±¾ÕZ¤Ļ²»ź¤Ź¤Ī¤Ē”¢°ė½ĒÓ¢Źż×Ö¤Ē”£
- 17. MplusŃŌÕZ¤Ī„ė©`„ė ? ĪÄÕĀ¤Ļ¤¹¤Ł¤Ę°ė½ĒÓ¢Źż×Ö ØC ČÕ±¾ÕZ²»æÉ ØC “óĪÄ×Ö?Š”ĪÄ×Ö¤ĪĒųe¤Ļ¤Ź¤¤ ? ĪÄÄ©¤Ė¤Ļ„»„ß„³„ķ„ó”±;”±¤ņø¶¤±¤ė ØC øÄŠŠ¤Ą¤±¤Ē¤Ļ”¢Ķ¬¤øĪÄÕĀ¤Ą¤ČÅŠ¶Ļ¤µ¤ģ¤ė ? ”°IS”±¤ä”±ARE”±¤Ļ”±=”°¤Ē“śÓƤĒ¤¤ė ØC „Ž„Ė„å„¢„ė¤Ė¤Ļ”±IS”±¤Č¤«”±ARE”±¤¬Ź¹¤ļ¤ģ¤Ę¤¤¤ė¤¬”¢”±=”°¤Ē“óÕÉ·ņ”£ ? ¤½¤ĪĖū ØC „³„į„ó„Č„¢„¦„ȤĻ”±!”±
- 18. Mplus¤Ī»ł±¾„³©`„É ? DATA: ØC „Ē©`„æ„Õ„”„¤„ė¤Ī¤¢¤ėöĖł¤ņÖø¶Ø ? VARIABLE: ØC ·ÖĪö¤ĖŹ¹¤¦äŹż¤ĪÖø¶Ø ? ANALYSIS: ØC ·ÖĪö·½·Ø¤ĪÖø¶Ø ? MODEL: ØC „ā„Ē„ė¤ĪÖø¶Ø ? OUTPUT: ØC ³öĮ¦¤ĪŌO¶Ø ? ¤½¤ĪĖū ØC PLOT”¢SAVEDATA”¢DEFINE¤Ź¤É¤Ź¤É
- 19. ¤³¤ó¤ŹøŠ¤ø
- 20. DATA: „³„Ž„ó„É ? Ź¹¤¦„Ē©`„æ„Õ„”„¤„ė¤ņÖø¶Ø¤¹¤ė ØC „Õ„”„¤„ė¤Ī„Ń„¹¤ņÖø¶Ø¤¹¤ė ? FILE = ”°D:?Dropbox?????sample1.dat”±; ? „Ń„¹¤Ī×īįį¤Ė„»„ß„³„ķ„ó¤ņĶü¤ģ¤ŗ¤Ė£” ØC inp„Õ„”„¤„ė¤ČĶ¬¤ø„Õ„©„ė„Ą¤ĖČė¤ģ¤ėöŗĻ??? ? FILE = ”°sample1.dat”±; ? „Õ„”„¤„ėĆū¤Ą¤±¤Ē¤č¤¤”£¤³¤Į¤é¤¬ŗ g¤Ź¤Ī¤Ē„Ŗ„¹„¹„į ? „ź„¹„Č„ļ„¤„ŗĻ÷³ż¤Īr¤Ė¤ĻŅŌĻĀ¤ņų¤Æ ØC LISTWISE = ON; ØC ¤æ¤Ą”¢LISTWISE¤Ļ»ł±¾¤ĻŹ¹¤ļ¤Ź¤Æ¤Ę¤č¤¤
- 21. VARIABLE: „³„Ž„ó„É ? Õi¤ßŽz¤ó¤ĄäŹż¤ņÖø¶Ø¤¹¤ė ØC „Ē©`„æ„Õ„”„¤„ė¤Ė¤¢¤ė䏿Ćū¤ņ¤¹¤Ł¤Ęų¤Æ ØC NAMES = v1 v2 v3; ? ÉĻ¤ĪöŗĻ”¢v1-v3; ¤Čų¤Æ¤³¤Č¤ā¤Ē¤¤ė ? ·ÖĪö¤ĖŹ¹ÓƤ¹¤ė䏿¤ņÖø¶Ø¤¹¤ė ØC USEVARIABLES = v1 v2; ? ų¤·½¤ĻÉĻ¤ČĶ¬¤ø ? Ē·p¤ņÖø¶Ø¤¹¤ė ØC MISSING = .; ? „Ō„ź„Ŗ„ɤĪöŗĻ¤ĻÉĻ¤Ī¤č¤¦¤Ėų¤Æ ? „Ą„Ö„ė„³©`„Ę©`„·„ē„ó¤Ļ¤Ä¤±¤Ź¤¤
- 22. ANALYSIS: „³„Ž„ó„É ? ·ÖĪö·½·Ø¤ņÖø¶Ø¤¹¤ė ØC TYPE = GENERAL; ? »ł±¾µÄ¤ŹSEM¤ņ¤¹¤ėöŗĻ¤Ļ¤³¤ģ¤Ą¤±¤ĒOK”£ ? Ėū¤Ė”¢TWOLEVEL£Ø„Ž„ė„Į„ģ„Ł„ė„ā„Ē„ė£© ”¢MIXTURE £ØĒ±ŌŚ„Ƅ鄹·ÖĪö£©”¢EFA£ØĢ½Ė÷µÄŅņ×Ó·ÖĪö£©¤Ź¤É¤¬¤¢¤ė”£ ØC ESTIMATOR = MLR; ? „Ē„Õ„©„ė„ȤĻMLR”£„ķ„Š„¹„Č×īÓČ·Ø¤Ī¤³¤Č”£ ? Ėū¤Ė”¢ML£Ø×īÓČ·Ø£©”¢WLSMV£ØÖŲ¤ß¤Ä¤×īŠ”¶ž\·Ø£©”¢ BAYES£Ø„Ł„¤„ŗ·Ø£©”¢GLS£Ø×īŠ”¶ž\·Ø£©¤Ź¤É¤¬¤¢¤ė”£ ØC Amos¤Č½Y¹ū¤ņŅ»ÖĀ¤µ¤»¤æ¤¤¤Ź¤é”¢ML¤ņŹ¹ÓƤ¹¤ė¤Č¤¤¤¤”£
- 23. MODEL: „³„Ž„ó„É ? „ā„Ē„ė¤ņÖø¶Ø¤¹¤ė ØC „ā„Ē„ė¤Īų¤·½¤Ī»ł±¾¤ĻŅŌĻĀ¤Ī5¤Ä”£ ? »Ų¢·ÖĪö£ØŌģ·½³ĢŹ½£©¤Ļ ON ? Ņņ×Ó·ÖĪö£Øy¶Ø·½³ĢŹ½£©¤Ļ BY ? ¹²·ÖÉ¢¤Ļ WITH ? 䏿Ćū¤Ą¤±¤ņų¤Æ¤Č”¢·ÖÉ¢¤ņĶĘ¶Ø¤¹¤ėÖø¶Ø ? [䏿Ćū]¤Čų¤Æ¤Č”¢Ę½¾ł¤ņĶĘ¶Ø¤¹¤ėÖø¶Ø ? „Ń„é„į©`„æ¤ĪÖĘ¼s¤ņ¤¹¤ė ØC MODEL CONSTRAINT:¤Īįį¤Ėų¤Æ ? ¤³¤ģ¤Ė¤Ä¤¤¤Ę¤Ļ”¢įįŹö
- 24. OUTPUT: „³„Ž„ó„É ? ³öĮ¦¤ĪŌO¶Ø¤ņ¤¹¤ė ØC ÓŹö½yÓĮæ¤ņ³öĮ¦¤¹¤ė ? SAMPSTAT ØC ĖŹ»ÆSŹż¤ņ³öĮ¦¤¹¤ė ? STANDARIZED ? ¤·¤«¤·”¢STDYX¤Čų¤¤¤æ·½¤¬ÓąÓ¤Ź¤Ī¤¬³ö¤Ź¤Æ¤Ę±ćĄū”£ ØC ŠÅīmĒųég¤ņ³öĮ¦¤¹¤ė ? CINTERVAL ? „Ö©`„Č„¹„Č„é„Ƅ׊ÅīmĒųég¤ņ³öĮ¦¤¹¤ėöŗĻ¤Ļ”¢ CINTERVAL£ØBOOTSTRAP)¤Čų¤Æ”£
- 25. ¤½¤ĪĖū¤Ī„³„Ž„ó„É ? SAVEDATA: „³„Ž„ó„É ØC Ņņ×ӵƵ椏¤É¤ņ±£“ę¤¹¤ė ØC SAVE £½ FSOCRES; ¤ĒŅņ×ӵƵć¤ņ±£“ę ? File = ###.txt; ¤Ē„Õ„”„¤„ėĆū¤ņÖø¶Ø”£ČÕ±¾ÕZ²»æÉ”£ ? PLOT:„³„Ž„ó„É ØC „°„é„Õ¤Ź¤É¤ņ³öĮ¦¤¹¤ė ? IRT¤ä„Ł„¤„ŗĶĘ¶Ø¤Īr¤ĖŹ¹¤¦ ? DEFINE:„³„Ž„ó„É ØC ŠĀ¤·¤¤äŹż¤ņ×÷¤Ć¤æ¤ź”¢äQ¤·¤æ¤ź¤¹¤ė¤Ī¤ĖŹ¹¤¦
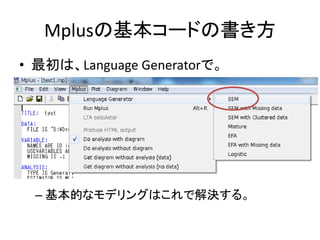
- 26. Mplus¤Ī»ł±¾„³©`„ɤĪų¤·½ ? ×ī³õ¤Ļ”¢Language Generator¤Ē”£ ØC »ł±¾µÄ¤Ź„ā„Ē„ź„ó„°¤Ļ¤³¤ģ¤Ē½āQ¤¹¤ė”£
- 27. ¤³¤ģ¤Ą¤±¤ĻŅ¤Ø¤Ę¤Ŗ¤³¤¦ DATA: FILE IS "sample1.dat"; !¤³¤³¤Ė„Õ„”„¤„ėĆū¤ņų¤Æ”£ČÕ±¾ÕZ²»æÉ”£ VARIABLE: NAMES = ID idt talk per skill con; !¤³¤³¤Ė„Ē©`„æ¤ĖČė¤Ć¤Ę¤¤¤ė䏿Ćū¤¹¤Ł¤Ęų¤Æ USEVARIABLES = idt talk per; !¤³¤³¤Ė·ÖĪö¤ĖŹ¹¤¦äŹż¤ņų¤Æ”£ MISSING = .; !Ē·pÓŗŤņų¤Æ”£ ANALYSIS: TYPE = GENERAL; !ĘÕĶؤĪSEM¤ņ¤¹¤ė¤Ź¤é”¢GENERAL¤Ē¤č¤¤”£ ESTIMATOR = ML; !Mplus¤Ī„Ē„Õ„©„ė„ȤĻMLR”£ML¤Ė¤¹¤ģ¤ŠAMOS¤ČĶ¬¤ø½Y¹ū¤Ė¤Ź¤ė”£ MODEL: !¤³¤³¤Ė„ā„Ē„ė¤ņų¤Æ”£ OUTPUT: SAMPSTAT STDYX MODINDICES(ALL); !¤³¤Ī3¤Ä¤Ļ³£¤Ėų¤¤¤Ę¤Ŗ¤¤¤Ę¤č¤¤”£
- 28. „µ„ó„ׄė„Ē©`„æ½B½é ? ¢ĻėµÄ¤Ź„Ē©`„æ¤ņĄūÓĆ ØC 3ČĖ¼Æā¤¬¼ÆāÓ×h¤ņŠŠ¤¦gņY£Ø100¼Æā300ČĖ£© ? ”łgėH¤ĖgņY¤ĻŠŠ¤Ć¤Ę¤¤¤Ž¤»¤ó£” ØC ŗĪ¤¬¼Æā„¢„¤„Ē„ó„Ę„£„Ę„£¤ņøߤį¤ėŅŖŅņ¤Č¤Ź¤ė¤Ī¤«£æ ? y¶Ø䏿 ØC ¼Æā„¢„¤„Ē„ó„Ę„£„Ę„£ ”ś idt ØC °kŃŌĮæ ”ś talk ØC ¼Æā„Ń„Õ„©©`„Ž„ó„¹ ”ś per ØC „³„ß„å„Ė„±©`„·„ē„󄹄„ė ”ś skill ØC gņYĢõ¼ž(0¤¬Ķ¬¤øĒéóĢõ¼ž”¢1¤¬ß`¤¦ĒéóĢõ¼ž) ”ś con
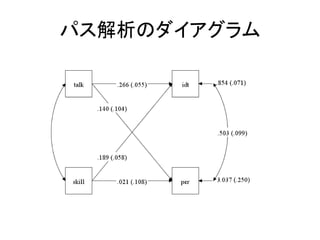
- 29. MODEL£ŗ„³„Ž„ó„ɤĪų¤·½ ? ÖŲ»Ų¢·ÖĪö¤ņ¤ä¤Ć¤Ę¤ß¤č¤¦???ON¤ņŹ¹¤¦”£ ØC ÄæµÄ䏿£ŗidt ØC ÕhĆ÷䏿£ŗtalk per idt on talk per; ØC ¤³¤ģ¤Ē½K¤ļ¤ź£” ØC Regressed on ¤ĪON!
- 30. ¤Ē¤Ļ¤µ¤Ć¤½¤Æ·ÖĪö¤·¤Ę¤ß¤č¤¦”£ DATA: FILE IS "sample1.dat"; VARIABLE: NAMES = ID idt talk per skill con; USEVARIABLES = idt talk per; MISSING = .; ANALYSIS: TYPE = GENERAL; ESTIMATOR = ML; MODEL: idt on talk per; OUTPUT: SAMPSTAT STDYX MODINDICES(ALL);
- 31. ČėĮ¦„Õ„”„¤„ė¤Ī±£“ę¤ČgŠŠ ? ·ÖĪö¤ņgŠŠ¤¹¤ėĒ°¤Ė”¢inp„Õ„”„¤„ė¤ņ±£“ę ØC öĖł¤Ļ”¢¤µ¤Ć¤¤Ä¤Æ¤Ć¤æ„Õ„©„ė„Ą¤ĪÖŠ¤Ė ØC „Ē©`„æ„Õ„”„¤„ė¤¬¤¢¤ėöĖł¤¬±ćĄū ? „Õ„ė„Ń„¹¤ņų¤«¤Ź¤Æ¤Ę¤č¤¤¤«¤é ØC ×Ó¤Ļ.inp ? inp„Õ„”„¤„ė¤¬±£“ę¤Ē¤¤æ¤é”¢RUN„Ü„æ„ó¤ņŃŗ¤¹ ØC ×ī³õ¤Ļ”¢ŗĪ¤«¤·¤é„Ø„é©`¤¬³ö¤ė”£ ØC ¤³¤³¤ķ¤¬ÕŪ¤ģ¤½¤¦¤Ė¤Ź¤ė¤³¤Č¤ā¤¢¤ė¤¬”¢¤¬¤ó¤Š¤ė”£
- 32. ³öĮ¦¤ĪŅ·½ ? ½Y¹ū¤ņŅ¤ė¤Č¤¤ĪŠÄµĆ ØC ¤Ē¤¤ė¤Ą¤±Ō¼¤ņ¤Į¤ć¤ó¤ČŅ¤ė ? ·ÖĪö¤¬¤¦¤Ž¤Æ¤¤¤Ć¤Ę¤Ź¤¤öŗĻ”¢×ߤƤʤā¾Æø꤬³ö¤ė¤³¤Č ¤¬¤¢¤ė”£ ? ¤·¤æ¤«¤Ć¤æ·ÖĪö¤¬¤Į¤ć¤ó¤Č¤Ē¤¤Ę¤¤¤ė¤«”¢„Į„§„Ć„Æ”£ ØC ŹÖß`¤¤¤Ē·ÖĪö·Ø¤Ź¤É¤¬égß`¤Ø¤Ę¤¤¤ė¤«¤ā¤·¤ģ¤Ź¤¤ ØC ßmŗĻ¶Č¤Ļ±Ų¤ŗŅ¤ė ? ßmŗĻ¶Č¤¬¤«¤Ź¤ź¤¤¤Ź¤é”¢„Ē©`„æČėĮ¦¤Ī„ß„¹¤ĪæÉÄÜŠŌ ? T¤ģ¤Ź¤¤CUI¤Ē¤Ī„ā„Ē„ź„ó„°¤Ļ”¢„ß„¹¤ā¶ą¤¤
- 33. ·ÖĪö¤ĪŅŖŌ¼
- 34. ßmŗĻ¶ČÖøĖ ? ĒéóĮæ»łŹ ØC „ā„Ē„ė±ČŻ^¤ĖŹ¹¤¦ ? ¦¶2\ ØC „ā„Ē„ė¤¬„Ē©`„æ¤ČµČ¤·¤¤¤Č¤¤ ¤¦¢o¢Õh¤Ī“_ĀŹ ? RMSEA ØC 0.05£Ø0.10£©ŅŌĻĀ¤¬¤č¤¤ ØC ¼sŠŌ¤ņæ¼]¤·¤æÖøĖ ? CFI ØC 0.95ŅŌÉĻ¤¬¤č¤¤ ØC ¼sŠŌ¤ņ¤ä¤äæ¼]¤·¤æÖøĖ ? SRMR ØC 0.05£Ø0.10£©ŅŌĻĀ¤¬¤č¤¤ ØC „ā„Ē„ė¤Č„Ē©`„æ¤Ī¾ąėx
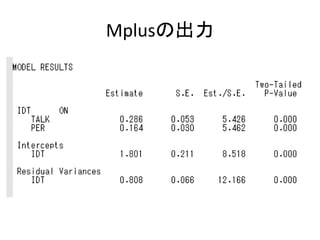
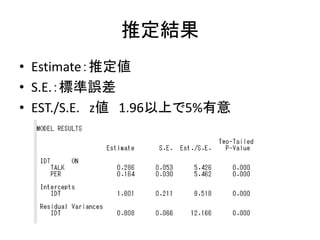
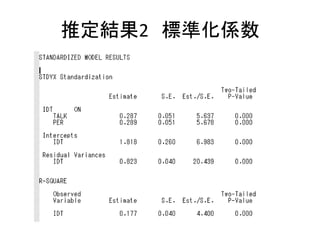
- 35. ĶĘ¶Ø½Y¹ū ? Estimate£ŗĶĘ¶Ø ? S.E.£ŗĖŹÕ`²ī ? EST./S.E. z 1.96ŅŌÉĻ¤Ē5%ÓŠŅā
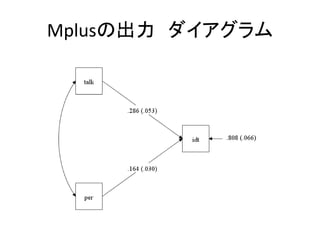
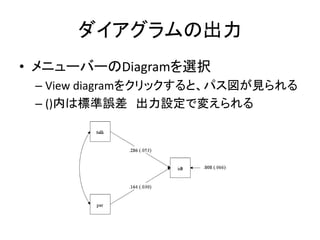
- 37. „Ą„¤„¢„°„é„ą¤Ī³öĮ¦ ? „į„Ė„å©`„Š©`¤ĪDiagram¤ņßxk ØC View diagram¤ņ„Æ„ź„Ć„Æ¤¹¤ė¤Č”¢„Ń„¹ķ¤¬Ņ¤é¤ģ¤ė ØC ()ÄŚ¤ĻĖŹÕ`²ī ³öĮ¦ŌO¶Ø¤Ēä¤Ø¤é¤ģ¤ė
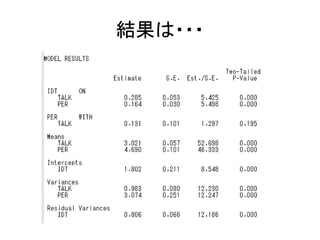
- 38. ·ÖÉ¢?¹²·ÖÉ¢¤ĪĶĘ¶Ø ? ·ÖÉ¢¤Č¹²·ÖÉ¢¤ņĶĘ¶Ø¤·¤Ę¤ß¤č¤¦???WITH¤ņŹ¹¤¦”£ ØC ¤µ¤Ć¤¤ČĶ¬¤ø„ā„Ē„ė¤Ē ØC ¤æ¤Ą¤·”¢¶ĄĮ¢äŹż¤Ī·ÖÉ¢¤āĶ¬r¤ĖĶĘ¶Ø¤¹¤ė idt on talk per; talk per; talk with per; ØC Mplus¤Ē¤Ļ”¢„Ē„Õ„©„ė„ȤĒ¤ĻČɜ䏿¤Ī·ÖÉ¢¤·¤«ĶĘ¶Ø¤·¤Ź¤¤”£ ØC Ķāɜ䏿¤Ī·ÖÉ¢¤ņÖø¶Ø¤¹¤ė¤Č”¢¤½¤ģ¤é¤Ī䏿ég¤Ī¹²·ÖÉ¢¤ā×ŌÓ µÄ¤ĖĶĘ¶Ø¤¹¤ė”£ ? ¤¹¤Ł¤Ę¤ĪĒ·p¤ņĶĘ¶Ø¤¹¤ė¤æ¤į¤Ė¤Ļ”¢¶ĄĮ¢äŹż¤ā·ÖÉ¢¤ņĶĘ¶Ø¤¹¤ė±Ų ŅŖ¤¬¤¢¤ė”£¤æ¤Ą”¢„Ē©`„æŅÄ£¤¬“ó¤¤Æ¤Ź¤ė¤æ¤į”¢ßmŗĻ¶Č¤¬¤Æ¤Ź¤ė¤³¤Č¤ā ¤¢¤ė
- 39. ½į¹ū¤Ļ???
- 40. ¹²·ÖÉ¢¤ņĶĘ¶Ø¤·¤æ¤Æ¤Ź¤¤öŗĻ ? ¹Ģ¶ØÄøŹż¤ĪÖĘ¼s¤ņ¤¹¤ė???@¤ņŹ¹¤¦”£ ØC ¹²·ÖÉ¢¤ņ0¤Ė¹Ģ¶Ø¤¹¤ė talk with per@0; ØC ¤³¤ģ¤Ētalk¤Čper¤Ī¹²·ÖÉ¢¤¬0¤Ė¹Ģ¶Ø¤µ¤ģ¤ė”£ idt on per@0; ØC ¤Č¤¹¤ģ¤Š”¢„Ń„¹SŹż¤ņ0¤Ė¹Ģ¶Ø¤¹¤ė¤³¤Č¤ā¤Ē¤¤ė”£
- 41. ¹²·ÖÉ¢¤ĪÖø¶Ø¤¢¤ģ¤³¤ģ ? Ņ»¶Č¤ĖČ«²æ¤Ī䏿¤Ī¹²·ÖÉ¢¤ņÖø¶Ø idt talk per WITH idt talk per; ØC ¤³¤ģ¤Ē3䏿ég¤Ī¹²·ÖÉ¢¤ņĶĘ¶Ø¤Ē¤¤ė ? „Ś„¢¤“¤Č¤Ī¹²·ÖÉ¢¤ņÖø¶Ø v1 v2 v3 PWITH v4 v5 v6; ØC £Ö1¤Čv4”¢v2¤Čv5”¢v3¤Čv6¤Ī¹²·ÖÉ¢¤ņĶĘ¶Ø ? ¹²·ÖÉ¢¤Ī×ŌÓĶĘ¶Ø¤ņ„Ŗ„Õ¤Ė¤¹¤ė ØC ANALYSIS„³„Ž„ó„ɤĖMODEL = NOCOVARIANCES ¤Čų¤Æ”£ ? ¤³¤ģ¤Ē”¢Ņņ×Óég¤ä·ÖÉ¢¤ņĶĘ¶Ø¤·¤æĶāɜ䏿ég¤Ī¹²·ÖÉ¢¤¬ ×ŌÓ¤ĒĶĘ¶Ø¤µ¤ģ¤Ź¤Æ¤Ź¤ė
- 42. Ę½¾ł¤ĪÖø¶Ø ? Ę½¾łŌģ¤ĪĶĘ¶Ø ØC TYPE = GENERAL¤Ė¤·¤Ę¤Ŗ¤±¤Š”¢×ŌӵĤĖĘ½¾łŌģ¤ā ĶĘ¶Ø¤µ¤ģ¤ė ØC ×Ō·Ö¤ĒÖø¶Ø¤·¤Ę¤Ŗ¤¤æ¤¤öŗĻ¤Ļ”¢[]¤ņŹ¹¤Ć¤Ę [idt]; ? ¤Čų¤Æ”£ ØC Ę½¾ł¤Ė¹Ģ¶ØÖĘ¼s¤ņÓė¤Ø¤æ¤¤öŗĻ¤Ļ”¢ [idt@0]; ? ¤Čų¤Æ”£ ØC Ę½¾ł¤ņĶĘ¶Ø¤·¤æ¤Æ¤Ź¤¤öŗĻ¤Ļ”¢ANALYSIS„³„Ž„ó„ɤĪ ¤Č¤³¤ķ¤Ė”¢MODEL = NOMEANSTRUCTURE;¤Čų¤Æ”£
- 43. „Ń„¹½āĪö ? ON¤ČWITH¤Ē„Ń„¹½āĪö¤¬æÉÄÜ ØC idt ¤Č per ¤ņ talk ¤Č skill ¤ĒÓčy¤¹¤ė„ā„Ē„ė ? skill¤ņusevariables¤Ė×·¼Ó¤¹¤ė¤Ī¤ņĶü¤ģ¤ŗ¤Ė£” idt per on talk skill; idt with per; ØC Ń}Źż¤ĪÄæµÄ䏿¤ĖĶ¬¤øÕhĆ÷䏿¤¬Óčy¤¹¤ėöŗĻ ¤Ļ”¢Ņ»ŠŠ¤Ēų¤±¤ė”£
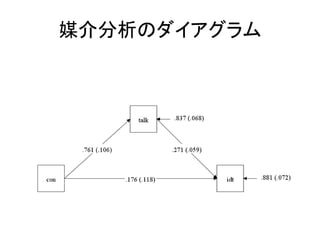
- 45. Ć½½é·ÖĪö ? ég½Óæ¹ū¤ņŹ¶Ø¤¹¤ė???IND¤ņŹ¹¤¦”£ ØC MODEL INDIRECT„Ŗ„ׄ·„ē„ó¤ņĄūÓĆ ØC Idt ¤Č con¤ĪévS¤ņtalk¤¬ÖŁ½é¤¹¤ė¤«¤ņŹµČ idt on talk con; talk on con; MODEL INDIRECT: idt IND talk con; ØC con ”ś talk ”ś idt¤Č¤¤¤¦Ć½½éæ¹ū¤ņŹ¶Ø
- 46. ég½Óæ¹ū¤ĪŹ¶Ø½Y¹ū ? Specific indirect¤Ī¤Č¤³¤ķ¤ņŅ¤ė”£ ØC ¤¤¤ļ¤ę¤ėSobel test¤Ī½Y¹ū”£
- 48. „Ö©`„Č„¹„Č„é„Ƅ׊ÅīmĒųég ? ég½Óæ¹ū¤Ī„Ö©`„Č„¹„Č„é„Ƅ׊ÅīmĒųég ØC BOOTSTRAP„Ŗ„ׄ·„ē„ó¤ņŹ¹¤¦ ? ANALYSIS„³„Ž„ó„ɤĖŅŌĻĀ¤ĪĪĤņų¤Æ”£ BOOT = 1000; ØC »ŲŹż¤Ļ1000”«10000»Ų¤Ī¹ ģ¤Ē”£ ØC CINTERVAL„Ŗ„ׄ·„ē„ó¤ĒŠÅīmĒųég¤ņ³öĮ¦¤¹¤ė ? OUTPUT„³„Ž„ó„ɤĖŅŌĻĀ¤ĪĪĤņų¤Æ”£ CINTERVAL(BOOT)
- 49. „³©`„ɤĻŅŌĻĀ¤ĪĶؤź ANALYSIS: TYPE = GENERAL; ESTIMATOR = ML; BOOT = 1000; MODEL: idt on talk con; talk on con; MODEL indirect: idt IND talk con; OUTPUT: SAMPSTAT STDYX MODINDICES(ALL) CINTERVAL(BOOT);
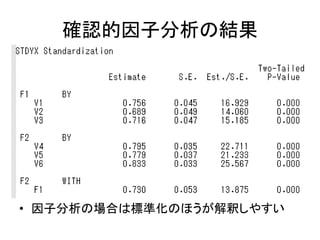
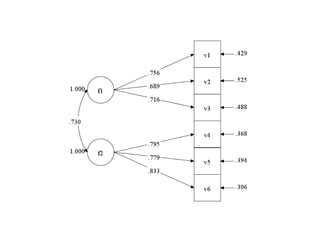
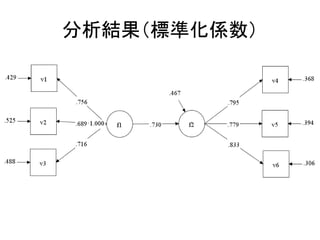
- 51. “_ÕJµÄŅņ×Ó·ÖĪö ? sample2.dat¤ņŹ¹¤¦ ØC ID¤Č6ķÄæ¤Ī䏿 ØC v1-v3¤¬Ķ¬¤øŅņ×Ó”¢£ö4-£ö6¤Ļe¤ĪŅņ×Ó ? Ņņ×Ó·ÖĪö¤ņ¤¹¤ė???BY¤ņŹ¹¤¦”£ ØC F1¤ČF2¤Č¤¤¤¦Ē±ŌŚäŹż¤¬£ö1-£ö10¤Ēy¶Ø¤µ¤ģ¤Ę¤¤¤ė F1 by v1-v3; F2 by v4-v6; ØC F1¤ČF2¤ĪŅņ×ÓégĻąév¤Ļ×ŌӵĤĖĶĘ¶Ø¤µ¤ģ¤ė ? ¤ā¤Į¤ķ¤ó”¢F1 with F2@0; ¤Čų¤±¤Š”¢Ö±½»»ŲܤȤŹ¤ė”£
- 52. “_ÕJµÄŅņ×Ó·ÖĪö ? ¤¤¤Æ¤Ä¤«¤Ī×¢Ņāµć ØC ĘÕĶؤĖF1 by v1-v3;¤Č¤«¤Æ¤Č”¢v1¤Ų¤ĪŅņ×ÓŲŗÉĮæ¤Ļ”¢ ×ŌӵĤĖ£±¤Ė¹Ģ¶Ø¤µ¤ģ¤ė ? ¤³¤ģ¤Ļ”¢„ā„Ē„ė¤Ī×Re¤Ī¤æ¤į¤Ė±ŲŅŖ¤ŹÖĘ¼s ØC ¤æ¤Ą”¢·ÖÉ¢¤ņ1¤Ė¹Ģ¶Ø¤·¤Ę¤āŅņ×Ó·ÖĪö¤ĻæÉÄÜ ? ¤æ¤Ą¤·”¢Ņņ×Ó¤¬Ķāɜ䏿¤ĪöŗĻ¤ĖĻŽ¤ė F1@1; ? ¤Čų¤±¤Š”¢F1¤Ī·ÖÉ¢¤ņ1¤Ė¹Ģ¶Ø¤¹¤ė¤³¤Č¤¬¤Ē¤¤ė”£ ? ¤Ž¤æ”¢v1¤ņ×ŌÓÉĶĘ¶Ø¤¹¤ė¤č¤¦¤ĖÖø¶Ø¤¹¤ė¤³¤Č¤¬¤Ē¤¤ė”£ F1 by v1* v2-v3; ? ¤¢¤ė¤¤¤Ļ F1 by v1-v5*; *¤Ļ×ŌÓÉĶĘ¶Ø¤ĪÖø¶Ø”£
- 53. ŅŌĻĀ¤Ī„³©`„ɤņų¤Æ DATA: FILE IS "sample2.dat"; VARIABLE: NAMES = ID v1-v6 sex; USEVARIABLES = v1-v6; MISSING = .; ANALYSIS: TYPE = GENERAL; ESTIMATOR = ML; MODEL: F1 by v1-v3*; F2 by v4-v6*; F1-F2@1; OUTPUT: SAMPSTAT STDYX MODINDICES(ALL);
- 56. “_ÕJµÄŅņ×Ó·ÖĪö¤ĪßmŗĻ¶Č ? Ņņ×Ó·ÖĪö¤ĻßmŗĻ¶Č¤¬µĶ¤Æ¤Ź¤ź¤¬¤Į ØC SRMR¤Ļ¤«¤Ź¤ź¤Æ¤Ź¤ė¤Ī¤Ē”¢¤¢¤Ž¤ź²ĪÕÕ¤·¤Ź¤¤ ØC ¤ą¤·¤ķ”¢CFI¤äRMSEA¤Ė×¢Ä椹¤ė ? CFI¤Ļ.85¤°¤é¤¤¤Ē¤ā¤½¤³¤½¤³óø꥿¤¬¤¢¤ė ? RMSEA¤Ļ0.05ŅŌĻĀ¤¬Ķū¤Ž¤·¤¤¤¬”¢0.10ŅŌĻĀ¤Ē¤ā¤¢¤ź ? Ņņ×ÓŹż¤ņ¤É¤¦Q¶Ø¤¹¤ė¤« ØC BIC¤Ź¤É¤ĪĒéóĮæ»łŹ¤ņÓƤ¤¤ė ? BIC¤¬Ņ»·¬Š”¤µ¤Æ¤Ź¤ėŅņ×ÓŹż¤ņńÓĆ ? ¤½¤ģ¤Ą¤±¤Ē¤Ļ¤Ź¤ÆRMSEA¤Ź¤É¤āßmŅĖ²ĪÕÕ
- 57. “_ÕJµÄŅņ×Ó·ÖĪö¤ĪÕ`²īĻąév ? Õ`²īĻąév¤Č¤Ļ ØC y¶ØķÄæ¤ĪÕ`²īķ¤Īég¤Ė¹²·ÖÉ¢¤ņ¢¶Ø¤¹¤ė F1 by v1-v3; v1 with v2; ØC Ąż¤Ø¤Š”¢ÉĻ¤Ī¤č¤¦¤ŹøŠ¤ø”£ ? ¤É¤¦¤¤¤¦r¤ĖÕ`²īĻąév¤ņ¢¶Ø¤¹¤ė¤« ØC y¶Ø·½·ØÕÉĻ”¢y¶ØÕ`²ī¤ĖĻąév¤¬¢¶Ø¤µ¤ģ¤ėöŗĻ ? Ł|ķÄ椬Ėʤʤ¤¤ė£ØĶ¬¤øŃŌČ~¤¬ŗ¬¤Ž¤ģ¤Ę¤¤¤ė”¢¤Ź¤É£© ? Ķ¬¤ø¤³¤Č¤Ė¤Ä¤¤¤Ę”¢ß`¤¦ČĆ꤫¤éŁ|¤·¤Ę¤¤¤ė ØC ßmŗĻ¶Č¤ņÉĻ¤²¤ė¤æ¤į¤Ą¤±¤Ė¤ą¤ä¤ß¤Ė¢¶Ø¤¹¤ė¤Ł¤¤Ē¤Ļ¤Ź¤¤ ? ¤·¤«¤·”¢Ļąév¤ņ¢¶Ø¤¹¤ė¤³¤Č¤¬Ķ×µ±¤Ź¤é”¢¢¶Ø¤¹¤ė·½¤¬¤č¤¤”£
- 58. „ā„Ē„ė¤Ī×Re ? ×Reī}¤Č¤Ļ£æ ØC ĢŲ¤ĖĒ±ŌŚäŹż¤Ź¤É¤ņĄūÓƤ¹¤ė¤Č”¢ĶĘ¶Ø¤¹¤ė¤Ł¤„Ń „é„į©`„椬¶ą¤Æ¤Ź¤ź”¢„ā„Ē„ė¤¬×Re¤Ē¤¤Ź¤¤ ? Mplus¤ĪöŗĻ”¢ĖŹÕ`²ī¤ĪĶĘ¶Ø¤¬¤Ē¤¤Ź¤Æ¤Ź¤ė ? ¹Ģ¶ØÄøŹż¤ņĄūÓƤ·¤Ę”¢„ā„Ē„ė¤ņ×Re¤µ¤»¤ė ? µäŠĶµÄ¤Ź×Reī}¤Ų¤ĪI ØC Ņņ×ÓŲŗÉĮæ¤ņ1¤Ė¹Ģ¶Ø ØC Ņņ×Ó¤Ī·ÖÉ¢¤ņ1¤Ė¹Ģ¶Ø£ØŅņ×Ó¤¬Ķāɜ䏿¤Ī¤Č¤£© ØC Ņņ×ÓŲŗÉĮæ¤ņµČ¤Ė¤¹¤ė£Ø2ķÄæ¤ĪöŗĻ¤Ź¤É£©
- 59. Ņņ×ÓŲŗÉĮæ¤ĪµČÖĘ¼s ? ø÷ķÄæ¤ĪŅņ×ÓŲŗÉĮ椬µČ¤·¤¤¤Č¤¤¤¦¢¶Ø ØC „ā„Ē„ė¤Ī¼sŠŌ¤¬ĻņÉĻ¤¹¤ėæÉÄÜŠŌ¤¬¤¢¤ė ØC „Ń„é„į©`„æĆū¤ņŌO¶Ø¤·”¢µČ¤ĖÖø¶Ø¤¹¤ė F1 by v1-v3*(p1); F2 by v4-v6*(p2); ØC v1-£ö3¤Ļ”¢p1¤Č¤¤¤¦Ķ¬¤ø„Ń„é„į©`„æ¤Ē¤¢¤ė¤³¤Č¤ņÖø¶Ø ØC v4-v6¤āĶ¬¤Ė”¢p2¤Č¤¤¤¦Ķ¬¤ø„Ń„é„į©`„æ
- 61. Ē±ŌŚäŹż¤ņŗ¬¤ą„Ń„¹½āĪö ? Ņņ×Óég¤ĖŅņ¹ūévS¤ņ¢¶Ø¤¹¤ė ØC F1¤¬F2¤ņ»Ų¢¤¹¤ė¤č¤¦¤ŹöŗĻ”£ F1 by v1- v3; F2 by v4-v6; F2 on F1; ØC ½ń»Ų¤Ļ”¢Ņņ×ÓŲŗÉĮæ¤ņ1¤Ė¹Ģ¶Ø¤·¤ĘĶʶØ
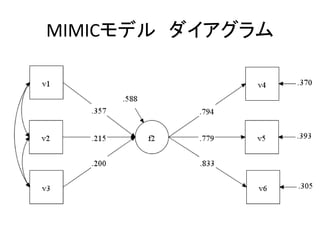
- 63. MIMIC„ā„Ē„ė ? Multiple indicator Multiple Cause Model ØC Ń}Źż¤ĪÕhĆ÷䏿¤¬”¢Ē±ŌŚäŹż¤ņ½U¤ĘŃ}Źż¤ĪÄæµÄ 䏿¤ĖÓ°ķ¤¹¤ė„ā„Ē„ė”£ F2 by v4-v6; F2 on v1-v3; ØC ĢŲ¤Ėėy¤·¤¤ÖĘ¼s¤Ļ±ŲŅŖ¤Ź¤¤”£
- 65. Ģ½Ė÷µÄŅņ×Ó·ÖĪö ? ŹĀĒ°¤Ė¤É¤ĪķÄ椬¤É¤¦¤¤¤¦Ņņ×Ó¤ņ³É¤¹¤ė¤«¤ļ ¤«¤Ć¤Ę¤Ź¤¤öŗĻ¤ĖŹ¹¤¦·½·Ø ØC SPSS¤Ź¤É¤ĖČė¤Ć¤Ę¤¤¤ėŅņ×Ó·ÖĪö¤ČĶ¬¤ø”£ ? 2·Nī¤Ī·½·Ø¤¬¤¢¤ė ØC EFA£ØĢ½Ė÷µÄŅņ×Ó·ÖĪö£©¤ņŹ¹¤¦ ? „ׄķ„Ž„Ć„Æ„¹»ŲܤŹ¤ÉŹ¹¤Ø¤ė»Ųܤ¬¶ą¤¤ ØC ESEM£ØĢ½Ė÷µÄŌģ·½³ĢŹ½„ā„Ē„ė£©¤ņŹ¹¤¦ ? Ņņ×ӵƵć¤ņ¤½¤Ī¤Ž¤ŽSEM¤ĖŹ¹¤Ø¤ė ? »ŲܤĻ”¢„ׄķ„Ž„Ć„Æ„¹¤ĻŹ¹¤Ø¤Ź¤¤¤¬”¢¤æ¤¤¤Ę¤¤¤ĻŹ¹¤Ø¤ė
- 66. EFA¤Ē¤Ī¤ä¤ź·½ ? ANALYSIS„³„Ž„ó„ɤņTYPE = EFA¤Č¤¹¤ė”£ ØC EFA¤Ī¤¢¤Č”¢ŗĪŅņ×Ó¤ņÖø¶Ø¤¹¤ė¤«¤ņ×īŠ”¤Č×ī“ó¤ņÖø¶Ø”£ ? ĻĀ¤ĪĄż¤ĪöŗĻ”¢1Ņņ×Ó¤Č2Ņņ×Ó¤Ī2¤Ä¤ņ×ߤ餻¤ė”£ ØC ROTATION„Ŗ„ׄ·„ē„ó¤Ė”¢»ŲܷؤņÖø¶Ø”£ ? VARIMAX, PROMAX, OBIIMIN, GEOMIN ØC „Ē„Õ„©„ė„ȤĻGEOMIN»ŲÜ ? MODEL„³„Ž„ó„ɤĻ¤¤¤é¤Ź¤¤”£ ANALYSIS: TYPE = EFA 1 2; ESTIMATOR = ML; ROTATION = oblimin;
- 67. ·”¹ó“”¤Ī½į¹ū
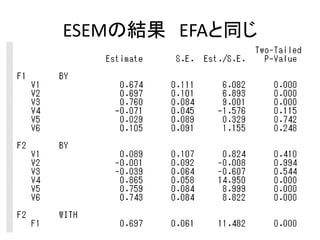
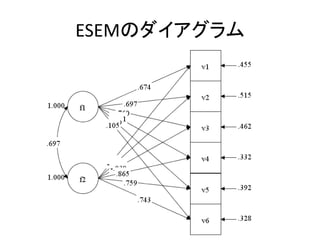
- 68. ESEM¤Ē¤Ī¤ä¤ź·½ ? MODEL„³„Ž„ó„ɤņų¤Æ±ŲŅŖ¤¬¤¢¤ė ØC „ā„Ē„ė¤Ī×īįį¤Ė(*1)¤Čų¤Æ”£ ØC »ŲܷؤāÖø¶Ø¤·¤Ę¤ä¤ė ANALYSIS: TYPE = GENERAL; ESTIMATOR = ML; ROTATION = oblimin; MODEL: F1-F2 by v1-v6(*1);
- 71. 2¤Ä¤ĪĢ½Ė÷µÄŅņ×Ó·ÖĪö ? „ā„Ē„ė¤ĪÖŠ¤Ė¶ž¤ÄŅŌÉĻ¤ĪĢ½Ė÷µÄŅņ×Ó·ÖĪö¤¬ŗ¬ ¤Ž¤ģ¤Ę¤¤¤ėöŗĻ ØC (*1)¤Č¤Ļe¤Ė(*2)¤Č¤¹¤ė”£ ANALYSIS: TYPE = GENERAL; ESTIMATOR = ML; ROTATION = oblimin; MODEL: F1 by v1-v3(*1); F2 by v4-v6(*2);
- 72. ČėéT¾ ¤Ŗ¤µ¤é¤¤ ? Mplus¤Ī„³©`„ɤĪ»ł±¾ ØC »Ų¢¤ĻON ØC Ļąév¤ĻWITH ØC Ņņ×Ó·ÖĪö¤ĻBY ØC ¹Ģ¶Ø„Ń„é„į©`„æ¤Ļ@ ØC ×ŌÓÉ„Ń„é„į©`„æ¤Ļ* ØC „Ń„¹¤ĪµČÖĘ¼s¤Ļ()