MS 빅데이터 서비스 및 게임사 PoC 사례 소개
•
0 likes•1,712 views

MS 빅데이터 서비스 및 게임사 PoC 사례 소개
















MS 빅데이터 서비스 및 게임사 PoC 사례 소개
- 1. MS 빅데이터 서비스 및 게임사 PoC 사례 소개 This content was developed prior to the product’s release to manufacturing, and as such, we cannot guarantee that all details included herein will be exactly as what is found in the shipping product. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication. The information represents the product at the time this document was printed and should be used for planning purposes only. Information subject to change at any time without prior notice.
- 2. ÔŨ ÎπÖÎç∞Ïù¥ÌÑ∞ÎûÄ Î¨¥ÏóáÏù∏Í∞Ä? ÔŨ Why? ÔÉÝ Azure Managed ÏÑúÎπÑÏä§ ÏÜåÍ∞ú ÔŨ PoC Ι©Ìëú ÔŨ PoC Í≤∞Í≥º ÔŨ To-Be Í∞úÏÑÝ Î∞©Ïïà ÏÝúÏñ∏
- 3. ‚Ä¢ Í∞ÄÌä∏ÎÑàÏùò ÏÝïÏùò (2012ÎÖÑ) ÔÇß ‚ÄúÎπÖ Îç∞Ïù¥ÌÑ∞Îäî ÌÅ∞ Ïö©Îüâ, ÎπÝΕ∏ ÏÜçÎèÑ, Í∑∏ζ¨Í≥Ý(ÎòêÎäî) ÎÜíÏùÄ Îã§ÏñëÏѱÏùÑ Í∞ñÎäî ÏÝïÎ≥¥ ÏûêÏÇ∞ÏúºÎ°úÏÑú Ïù¥Î•º ÌܵÌï¥ ÏùòÏǨ Í≤∞ÏÝï Î∞è ÌܵÏ∞∞ Î∞úÍ≤¨, ÌîÑΰúÏÑ∏Ïä§ ÏµúÏÝÅÌôîΕº Ìñ•ÏÉÅÏãúÌǧÍ∏∞ ÏúÑÌï¥ÏÑúÎäî ÏÉàΰúÏö¥ ÌòïÌÉúÏùò Ï≤òζ¨ Î∞©ÏãùÏù¥ ÌïÑÏöîÌïòÎã§.‚Äù ‚Ä¢ ÎπÖÎç∞Ïù¥ÌÑ∞Ïùò ÌäπÏßï -3 Vs of extreme scale ÔÇß Volume : The data exceeds the physical limits of vertical scalability, implying a scale out solution ÔÉÝ ÏàòÏßÅÏÝÅ ÌôïÏû•Ïóê ÌïúÍ≥ÑÍ∞Ä ÏûàÎäî ÎåÄÍ∑úΙ® Îç∞Ïù¥ÌÑ∞ ÔÇß Velocity : The decision window is small compared with the data change rate ÔÉÝ Îç∞Ïù¥ÌÑ∞ ÎπÝΕ∏ Î≥ÄÌôîΰú ÏùòÏǨ Í≤∞ÏÝï ÏãúÍ∞ÑÏù¥ ÎߧÏö∞ ÏßßÏùå ÔÇß Variety : Many different formats make integration difficult and expensive ÔÉÝ Îã§ÏñëÌïú Îç∞Ïù¥ÌÑ∞ Ìè¨Îß∑ÏúºÎ°ú ÌܵÌï©Ïùò ÎÇúÏù¥ÎèÑ Î∞è ÎπÑÏö©Ïù¥ ÎÜíÏùå ÎπÖÎç∞Ïù¥ÌÑ∞ÎûÄ Î¨¥ÏóáÏù∏Í∞Ä?
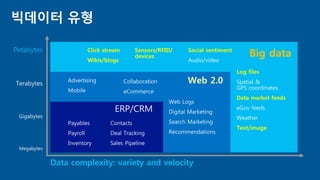
- 4. ÎπÖÎç∞Ïù¥ÌÑ∞ ÏúÝÌòï Big data Log files Data market feeds Text/image Click stream Wikis/blogs Sensors/RFID/ devices Social sentiment Web 2.0
- 5. ÎπÖÎç∞Ïù¥ÌÉÄ ÏÝïÏùòÏôÄ ÏïÑÌååÏπò «ÍòÎë°
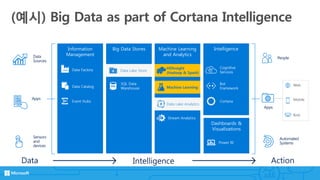
- 6. Machine Learning and Analytics (예시) Big Data as part of Cortana Intelligence Action People Automated Systems Apps Web Mobile Bots Intelligence Dashboards & Visualizations Cortana Bot Framework Cognitive Services Power BI Information Management Event Hubs Data Catalog Data Factory Intelligence Stream Analytics HDInsight (Hadoop & Spark) Big Data Stores Data Lake Store SQL Data Warehouse Data Sources Apps Sensors and devices Data Data Lake Analytics Machine Learning
- 7. < Apache Hadoop Ecosystem > ÏïÑÌååÏπò «ÍòÎë° ÏóêÏΩî ÏãúÏä§ÌÖúÍ≥º Azure HDInsight Microsoft‚Äôs managed Hadoop as a Service 100% open source Apache Hadoop Built on the latest releases across Hadoop (2.6) ÔÉÝ Ìñ•ÌõÑÏóêÎèÑ ÎπÝΕ¥Í≤å Í∞úÏÑÝÎêòÍ≥Ý ÏûàÎäî «ÍòÎë° ÏóêÏΩî ÏãúÏä§ÌÖúÏùò ϵúÏãÝ Î≤ÑÏÝÑ ÌôúÏö© ÔÉÝ Í≤Ä϶ùÎêú Î∞∞Ìè¨Ìåê Up and running in minutes with no hardware to deploy ÔÉÝ ÌïÑÏöîÌïú ÏãúÏÝêÏóê Î∞îΰú Î∞∞Ìè¨ÌïòÏó¨ ÏǨÏö© / Opex vs. Capex / ÎπÑÏö© ÏÝàÍ∞ê Hadoop Meets the Cloud
- 9. HDInsight ÏßÄÏõê ÌÅ¥Îü¨Ïä§ÌÑ∞ ÏúÝÌòï Î∞è Ïö©ÎèÑ HDInsightÎäî 4Í∞ÄÏßÄ ÎåÄÌëúÏÝÅÏù∏ ÏïÑÌååÏπò ÎπÖÎç∞Ïù¥ÌÑ∞ ÌîåÎû´ÌèºÏùÑ Managed ÌòïÌÉúΰú ÏÝúÍ≥µÌïòÎäî MSÏùò ÎπÖÎç∞Ïù¥ÌÑ∞ ÏÑúÎπÑÏä§ (Ìò∏ÌäºÏõçÏä§ Î∞∞Ìè¨Ìåê Í∏∞Î∞ò) 1. Hadoop : Î∞∞Ïπò 2. HBase : NoSQL 3. Storm : Ïã§ÏãúÍ∞Ñ Ïä§Ìä∏ζ¨Î∞ç 4. Spark : Î∞∞Ïπò & Ïä§Ìä∏ζ¨Î∞ç & ή∏ÏãÝÎü¨Îãù
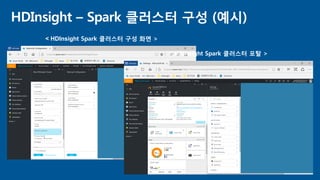
- 10. HDInsight – Spark 클러스터 구성 (예시) < HDInsight Spark 클러스터 구성 화면 > < HDInsight Spark 클러스터 포탈 >
- 12. ‚Ä¢ Í≥ÝÍ∞ùÏǨ ÌòÑÌô© ÔɺOn-PremÍ≥º ÌÅ¥ÎùºÏö∞ÎìúΕº ÌòºÏö©ÌïòÏó¨ Í≤åÏûÑ Î°úÍ∑∏ Îç∞Ïù¥ÌÑ∞ Î∂ÑÏÑùÏùÑ ÏàòÌñâ ϧë ÔɺHadoop ÌôòÍ≤ΩÏóêÏÑú Îߵζ¨ÎìÄÏä§ Ïñ¥Ìîåζ¨ÏºÄÏù¥ÏÖò / ή∏ÏãÝÎü¨Îãù ÏǨÏö© Í≥ÝÍ∞ùÏǨ ΰúÍ∑∏ Îç∞Ïù¥ÌÑ∞ Î∂ÑÏÑù ÌòÑÌô©
- 13. PoC Ι©Ìëú (1/2) (1) ΰúÍ∑∏ Îç∞Ïù¥ÌÑ∞ Î∂ÑÏÑù Ïù∏ÌîÑÎùº Ïö¥ÏòÅ ÌôòÍ≤Ω Í∞úÏÑÝ Apache Drill Î∞è Spark ÏÝÅÏö©ÏúºÎ°ú Î∂ÑÏÑù ÏѱÎä• Í∞úÏÑÝ ÔÉÝ «ÍòÎë° Ïô∏ Ï∂îÍ∞ÄÏÝÅÏù∏ Î∂ÑÏÑù ÌîåÎû´Ìèº ÏòµÏÖò Î∞è Î∂ÑÏÑù ÏãúÍ∞Ñ Í∞êÏÜå Î∂ÑÏÑù Ïöîͱ¥ Î∞è Îç∞Ïù¥ÌÑ∞ÎüâÏóê Îî∞Ε∏ ÏúÝÏó∞Ìïú Î∂ÑÏÑù Ïù∏ÌîÑÎùº ÌôòÍ≤Ω Íµ¨Ï∂ï ÔÉÝ Î∂ÑÏÑù Ïöîͱ¥Ïóê Îî∞Ε∏ ÏúÝÏó∞Ìïú Ïù∏ÌîÑÎùº ͵¨Ïѱ(scale-out/in)ÏúºÎ°ú Î∂ÑÏÑù Ι©Ìëú ÏãúÍ∞Ñ Í∞úÏÑÝ Î∞è ÎπÑÏö© ÏÝàÍ∞ê (Î∂ÑÎãπ ÏǨÏö©Îüâ Í∏∞Î∞ò Í≥ºÍ∏à)
- 14. PoC Ι©Ìëú (2/2) (2) ÏøºÎ¶¨ Í∏∞Î∞ò ΰúÍ∑∏ Îç∞Ïù¥ÌÑ∞ Î∂ÑÏÑù ÌôòÍ≤Ω Íµ¨Ï∂ï ÏǨÎÇ¥ Îç∞Ïù¥ÌÑ∞ ÏÝÑΨ∏Í∞ÄÎì§ÏùÑ ÏúÑÌïú ÏøºÎ¶¨ Í∏∞Î∞ò ΰúÍ∑∏ Îç∞Ïù¥ÌÑ∞ Î∂ÑÏÑù ÌôòÍ≤Ω ÏÝúÍ≥µ ÔÉÝDB ÏøºÎ¶¨ ÌôòÍ≤ΩÏóê ÏùµÏàôÌïú ÏǨÎÇ¥ Îç∞Ïù¥ÌÑ∞ ÏÝÑΨ∏Í∞ÄÏóêÍ≤å ΰúÍ∑∏ Îç∞Ïù¥ÌÑ∞ Î∂ÑÏÑù Ìôò Í≤Ω ÏÝúÍ≥µÌïòÏó¨ ÏÝëÍ∑ºÏѱ Í∞úÏÑÝ Î∞è Ïù¥Ïóê Îî∞Ε∏ Î∂ÑÏÑù ζ¨Îìú ÌÉÄÏûÑ Í∞êÏÜå ÔÉÝPower BI / ÏóëÏÖÄ Îì±ÏùÑ ÌôúÏö©Ìïú ÌòÑÏóÖ ÏǨÏö©Ïûê ÌܵÍ≥Ñ Î∂ÑÏÑù ÌôòÍ≤Ω ÏÝúÍ≥µ ÔÉÝÎ≥¥Í≥ÝÏÑú Î∞è ÎåÄÏãúÎ≥¥Îìú ÏßÄÏõê (ÏãúÍ∞ÅÌôî)
- 15. PoC 결과
- 16. 1. ÌÅ¥Îü¨Ïä§ÌÑ∞ ÎÇ¥ Îç∞Ïù¥ÌÑ∞ ÎÖ∏Îìú Ïàò ϶ùÍ∞Ä(Ïä§ÏºÄÏùº ÏïÑÏõÉ)Ïóê Îî∞Ε∏ ÏѱÎä• Í∞úÏÑÝ ÔÇß ÏÝÄÏö©Îüâ Îç∞Ïù¥ÌÑ∞Ïùò Í≤ΩÏö∞, Ïä§ÏºÄÏùº ÏïÑÏõÉÏóê Îî∞Ε∏ ÏѱÎä• Ìö®Í≥ºÎäî ÏóÜÏùå (HDFS small data issue) ÔÇß ÎåÄÏö©Îüâ Îç∞Ïù¥ÌÑ∞Ïùò Í≤ΩÏö∞(5Î≤à ÏøºÎ¶¨), CPU ÏѱÎä•Ïù¥ ÎÜíÏïÑÏßà Ïàòΰù Ï≤òζ¨ ÏãúÍ∞ÑÏù¥ ÌŨÍ≤å Í∞úÏÑÝÎê® (D Ïãúζ¨Ï¶à Í∏∞ϧÄÏúºÎ°ú 8 Core Îãπ ÏïΩ 15% Ï≤òζ¨ ÏãúÍ∞ÑÏù¥ ÏÑÝÌòïÏÝÅÏúºÎ°ú Í∞úÏÑÝ) 2. Ïä§ÏºÄÏùºÏóÖÍ≥º Ïä§ÏºÄÏùºÏïÑÏõÉÏóê Îî∞Ε∏ ÏѱÎä• ÎπÑ͵ê ÔÇß Ï¥ù Core ÏàòÍ∞Ä ÎèôÏùºÌïú Í≤ΩÏö∞, Ïä§ÏºÄÏùºÏóÖÍ≥º Ïä§ÏºÄÏùºÏïÑÏõÉ Í∞ÑÏùò ÏѱÎä• Ï∞®Ïù¥Îäî ÏóÜÏùå (D12 v2 vs. D13 v2 vs. D14 v2 Í∞Ñ ÎπÑ͵ê) 3. VM Type ϧë AÏãúζ¨Ï¶àÏôÄ DÏãúζ¨Ï¶àÏôÄÏùò ÏѱÎä• ÎπÑ͵ê ÔÇß A Ïãúζ¨Ï¶àÏôÄ D v2 Ïãúζ¨Ï¶à Í∞ÑÏùò Í∞ÄÍ≤© Ï∞®Ïù¥ÏôÄ ÌÖåÏä§Ìä∏ ÏѱÎä• Í≤∞Í≥º Ï∞®Ïù¥Î•º Í≥ÝÎݧÌïòΩ¥ D Ïãúζ¨Ï¶àÍ∞Ä ÎπÑÏö© ÎåÄÎπÑ Ìö®Í≥ºÏÝÅÏûÑ 4. Parquet ÌååÏùº ÏѱÎä• ÔÇß ÎåÄÏö©Îüâ ÌååÏùºÏóê ÎåÄÌïú ÏøºÎ¶¨ Í∏∞ϧÄÏúºÎ°ú ϵúÏÜå 40Î∞∞ (Spark) / 70Î∞∞ (Drill) Ïù¥ÏÉÅÏùò ÏѱÎä• Í∞úÏÑÝ ÔÇß Ï∂îÍ∞ÄÏÝÅÏù∏ ETLÏùÑ Í≥ÝÎݧ ÌïÑÏöî (PoCÏö© Îç∞Ïù¥ÌÑ∞ Í∏∞준 31Î∂Ñ) ÏѱÎä• ÌÖåÏä§Ìä∏ Í≤∞Í≥º ÏöîÏïΩ
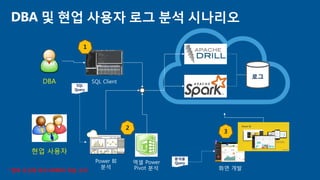
- 17. ΰúÍ∑∏ DBA Î∞è ÌòÑÏóÖ ÏǨÏö©Ïûê ΰúÍ∑∏ Î∂ÑÏÑù ÏãúÎÇòζ¨Ïò§ ÌòÑÏóÖ ÏǨÏö©Ïûê DBA SQL Client Power BI Î∂ÑÏÑù ÏóëÏÖÄ Power Pivot Î∂ÑÏÑù SQL Query ÌôîΩ¥ Í∞úÎ∞ú Î∂ÑÏÑùÏö© Query 1 2 3 * Ìñ•ÌõÑ Ïöîͱ¥Ïóê Îî∞Îùº RDBMS ÏÝÅÏö© Í≥ÝÎݧ
- 18. ‚Ä¢ PoC Í≤∞Í≥ºÎ•º Í∏∞Ï¥àΰú Îã§ÏùåÍ≥º Í∞ôÏùÄ To-Be Í∞úÏÑÝ Î∞©ÏïàÏùÑ ÏÝúÏñ∏ ÎìúζΩÎãàÎã§. To-Be Í∞úÏÑÝ Î∞©Ïïà ÏÝúÏñ∏ (1/2) 1. Managed ÏÑúÎπÑÏä§ Í∏∞Î∞òÏùò SQL on Hadoop Î∞è Parquet ÌååÏùº ÏÝÅÏö© ÔÇß ÌòÑÌñâ ΰúÍ∑∏ Î∂ÑÏÑù ÏãúÏä§ÌÖú Í∞úÎ∞ú Ïãú, Í∞ÑÌé∏Ìïú SQLÍ≥º ÏóÖΨ¥ ΰúÏßÅ ÏΩîÎìú Ï°∞Ìï©ÏùÑ ÌܵÌï¥ Í∞úÎ∞ú ÏÉùÏÇ∞Ïѱ Ìñ•ÏÉÅ ÔÇß Î∂ÑÏÑù ÏãúÍ∞Ñ Í∞êÏÜå Î∞è Î∂ÑÎã®ÏúÑ Í≥ºÍ∏àÏúºÎ°ú ÎπÑÏö© ÏÝàÍ∞ê Ôɺ SQL on Hadoop Î∞è Partquet ÌååÏùºÏùÑ ÌôúÏö©Ìïú Îç∞Ïù¥ÌÑ∞ Î∂ÑÏÑù ÏãúÍ∞Ñ Í∞êÏÜå Ôɺ Î∂ÑÎã®ÏúÑ Í≥ºÍ∏à / ÏúÝÏó∞Ìïú ÌÅ¥Îü¨Ïä§ÌÑ∞ Ïö¥ÏòÅ (Pay as you go, Ïä§ÏºÄÏùºÏù∏/ÏïÑÏõÉ, ÌÅ¥Îü¨Ïä§ÌÑ∞ Î∞∞Ìè¨/ÏÇ≠ÏÝú Ïä§ÏºÄÏ•¥ÎßÅ) ÔÇß Managed ÏÑúÎπÑÏä§ Í∏∞Î∞òÏùò ÌÅ¥Îü¨Ïä§ÌÑ∞ Ïö¥ÏòÅÏúºÎ°ú Ìö®Ïú®ÏÝÅÏù∏ Í¥Äζ¨ Í∞ÄÎä• ÔÇß Ìñ•ÌõÑ ÏóÖÎç∞Ïù¥Ìä∏Îêú ÌÅ¥Îü¨Ïä§ÌÑ∞ Î≤ÑÏÝÑÏóê ÎåÄÌïú Í∞ÑÌé∏Ìïú ÏÝÅÏö©
- 19. ‚Ä¢ PoC Í≤∞Í≥ºÎ•º Í∏∞Ï¥àΰú Îã§ÏùåÍ≥º Í∞ôÏùÄ To-Be Í∞úÏÑÝ Î∞©ÏïàÏùÑ ÏÝúÏñ∏ ÎìúζΩÎãàÎã§. To-Be Í∞úÏÑÝ Î∞©Ïïà ÏÝúÏñ∏ (2/2) 2. ÏøºÎ¶¨ Í∏∞Î∞ò Î∂ÑÏÑù ÌôòÍ≤Ω ÏÝúÍ≥µÏúºÎ°ú ΰúÍ∑∏ Îç∞Ïù¥ÌÑ∞ ÏÝëÍ∑ºÏѱ ÌôïÎåÄ ÔÇß ÏǨÎÇ¥ ÏÝÑΨ∏Í∞Ä(DBA / ÌòÑÏóÖ ÏÝÑΨ∏Í∞Ä)Ïùò ΰúÍ∑∏ Îç∞Ïù¥ÌÑ∞ ÏÝëÍ∑ºÏѱ Í∞úÏÑÝ Î∞è Ïù¥Ïóê Îî∞Ε∏ Î∂ÑÏÑù ζ¨Îìú ÌÉÄÏûÑ Í∞êÏÜå ÔÇß Î°úÍ∑∏ Îç∞Ïù¥ÌÑ∞Ïùò Í∏∞Î≥∏ Î∂ÑÏÑù ÏßÄÏõê Î∂ÄÎã¥ÏùÄ Í∞êÏÜåÏãúÌǧÍ≥Ý Í≥ÝÍ∏â Î∂ÑÏÑùÏóê ÏóÖΨ¥ Ïßëϧë Í∞ÄÎä• 3. Î∂ÑÏÑù Í≤∞Í≥ºÏóê ÎåÄÌïú ÏãúÍ∞ÅÌôî(Visualization) Í∏∞Îä• Í∞ïÌôî ÔÇß Î≥¥Í≥ÝÏÑú Î∞è ÎåÄÏãúÎ≥¥ÎìúΕº ÌôúÏö©ÌïòÏó¨ Î∂ÑÏÑù Í≤∞Í≥ºÎ•º Ìé∏ζ¨ÌïòÍ≤å ÏǨÎÇ¥ Í≥µÏúÝ ÔÇß Ïô∏Î∂Ä Î∂ÑÏÑù ÏÑúÎπÑÏä§ ÏÝúÍ≥µ Ïãú, Ìö®Í≥ºÏÝÅÏù∏ ÎèÑ͵¨Î°ú ÌôúÏö© Í∞ÄÎä•