Multiagent Cooperative and Competition with Deep Reinforcement Learning
ŌĆó
1 likeŌĆó631 views

MADRLņŖ¼ļĪ£ņÜ░ĒÄśņØ┤ĒŹ╝ - Multiagent Cooperative and Competition with Deep Reinforcement Learning























Multiagent Cooperative and Competition with Deep Reinforcement Learning
- 1. MADRL https://github.com/NeuroCSUT/DeepMind-Atari-Deep-Q-Learner-2Player Multiagent Cooperative and Competition with Deep Reinforcement Learning 1 Ļ╣Ćņśłņ░¼(Paul Kim)
- 2. Index 1. Introduction 2. Method - 2.1 The Deep Q-Learning Algorithm - 2.2 Adaptation of the Code for the Multiplayer Paradigm - 2.3 Game Selection - 2.4 Reward Schemes - 2.4.1 Score More than the Opponent(Fully Competitive) - 2.4.2 Loosing the Ball Penalizes Both Players(Fully Cooperative) - 2.4.3 Transition Between Cooperation and Competition - 2.5 Training Procedure - 2.6 Collecting the Game Statistics 3. Results - 3.1 Emergence of Competitive Agents - 3.2 Emergence of Collaborative Agents - 3.3 Progression from Competition to Collaboration 2
- 3. Abstract Abstract DeepMindĻ░Ć ņĀ£ņĢłĒĢ£ Deep Q-Learning NetworkņØä ņé¼ņÜ®ĒĢ┤ Multiagent systemņ£╝ļĪ£ ĒÖĢņןĒĢśĻ│Ā PongĒÖśĻ▓Į ņåŹņŚÉņä£ IQN(Independent Q-Networks)ļĪ£ ļæÉ Ļ░£ņØś agentļōżņØ┤ controlļÉśļŖöņ¦Ćļź╝ ņĪ░ņé¼ĒĢ© PongĒÖśĻ▓ĮņØś RewardņŖżĒéżļ¦łļź╝ ņé¼ņĀäņŚÉ ņĀĢņØśĒĢ┤ņä£ competitiveĒĢ£ Ļ▓ĮņÜ░ņÖĆ cooperativeĒĢ£ Ē¢ēņ£äĻ░Ć ņ¢┤ļ¢╗Ļ▓ī ļéśĒāĆļéśļŖöņ¦Ćļź╝ ĒÖĢņØĖ CompetitiveĒĢ£ agentsļŖö Ļ░ĆņĀĢĒĢ£ Ļ▓ĮņÜ░ņŚÉļŖö scoreļź╝ ņś¼ļ”¼Ļ▓ī ļüö ĒĢÖņŖĄņØ┤ ļÉśļŖö Ļ▓āņØä ĒÖĢņØĖ CooperativeĒĢ£ agentsļź╝ Ļ░ĆņĀĢĒĢ£ Ļ▓ĮņÜ░ņŚÉļŖö ļæÉ Ļ░£ņØś ņŚÉņØ┤ņĀäĒŖĖĻ░Ć Ļ░ĆļŖźĒĢ£ ņä£ļĪ£ ņśżļ×½ļÅÖņĢł Ļ│ĄņØä keepingĒĢśļŖö Ļ▓āņØä ĒÖĢņØĖ CompetitiveņŚÉņä£ CooperativeņØś ņ¦äĒ¢ēņØä ņäżļ¬ģ(RewardņØś Ļ░ÆņØä ņł£ņ░©ņĀüņ£╝ļĪ£ ļ│ĆĻ▓Įņŗ£ņ╝£ņä£ ĒÖĢņØĖ) Ļ▓░Ļ│╝ņĀüņ£╝ļĪ£ ņØ┤ ņŚ░ĻĄ¼ļģ╝ļ¼ĖņØś ņĀĆņ×ÉļōżņØĆ Deep Q-Networkļź╝ ļ│Ąņ×ĪĒĢ£ ĒÖśĻ▓Į ņåŹņŚÉņä£ ļŗżņżæ ņŚÉņØ┤ņĀäĒŖĖ ņŗ£ņŖżĒģ£ņØś decentralized(ļČäņé░) ĒĢÖņŖĄņØä ņŚ░ĻĄ¼ĒĢśĻĖ░ ņ£äĒĢ£ ņŗżņÜ®ņĀüņØĖ ļ░®ņŗØņØä ņĀ£ņĢłĒĢ© 3
- 4. Introduction Ļ░ĢĒÖöĒĢÖņŖĄņØś ņ▓ĀĒĢÖ Biological Ēś╣ņØĆ Engineered agentsļŖö ņśłņĖĪ ļČłĻ░ĆļŖźņä▒ņŚÉ ļīĆņ▓śĒĢ┤ņĢ╝ ĒĢśļ®░ trial-and-errorļź╝ ĒåĄĒĢ┤ņä£ ņāłļĪŁĻ│Ā ļ│ĆĒÖöļÉśļŖö ĒÖśĻ▓ĮņŚÉņä£ Ē¢ēļÅÖņØä ņĀüņØæņŗ£Ēé¼ ņłś ņ׳ņØī Ļ░ĢĒÖöĒĢÖņŖĄņŚÉņä£ ņŚÉņØ┤ņĀäĒŖĖļŖö ĒÖśĻ▓ĮĻ│╝ ņāüĒśĖņ×æņÜ®ĒĢśļ®┤ņä£ ņłśņ¦æĒĢ£ ļ│┤ņāüņŚÉ ļö░ļØ╝ Ē¢ēļÅÖņØä ņłśņĀĢĒĢśĻ│Ā ņØ┤ ļĢī ļ│┤ņāüņØä ņĄ£ļīĆĒÖöĒĢśĻĖ░ ņ£äĒĢ┤ņä£ ņŚÉņØ┤ņĀäĒŖĖļŖö ļ│Ąņ×ĪĒĢ£ ņןĻĖ░ņĀäļץņØä ĻĄ¼ĒśäĒĢśļŖö ļ░®ņŗØņØä Ēä░ļōØĒĢśĻ▓ī ļÉ© DQNĻ│╝ Multi-Agent Ļ░ĆļŖźĒĢ£ ņŗ£ļéśļ”¼ņśżļōżņØ┤ ļäłļ¼┤ļéśļÅä ļ¦ÄĻĖ░ ļĢīļ¼ĖņŚÉ Ļ░ĢĒÖöĒĢÖņŖĄņØĆ ļīĆĻ▓ī ļŗ©ņł£ĒĢ£ ĒÖśĻ▓ĮņŚÉļ¦ī ĻĄŁĒĢ£ļÉśņŚłĻ│Ā, ĒÖśĻ▓ĮņØś dynamicsņŚÉ ļīĆĒĢ£ ņČöĻ░Ć ņĀĢļ│┤ļĪ£ ļÅäņøĆņØä ļ░øņĢäņä£ ņĀæĻĘ╝Ē¢łņŚłņØī ĒĢśņ¦Ćļ¦ī DeepMindĻ░Ć VideoĻ▓īņ×äĻ│╝ Ļ░ÖņØĆ Ļ│Āņ░©ņøÉņĀüņØ┤Ļ│Ā ļ│Ąņ×ĪĒĢ£ ĒÖśĻ▓ĮņŚÉ RLņØä ņĀüņÜ®ĒĢ┤ ņä▒Ļ│╝ļź╝ ļāłĻ│Ā, super-humanņØś ņä▒ļŖźņØä ļŗ¼ņä▒. ĻĖ░ņ¢ĄĒĢĀ ņĀÉņØĆ raw sensory input(ņØ┤ļ»Ėņ¦Ć)ņÖĆ reward signal(Ļ▓īņ×äņĀÉņłś)ļ¦īņØä ņé¼ņÜ® Deep Q-Network(Convolution Neural Networkļź╝ Q-Learningņ£╝ļĪ£ representationĒĢśļŖö ļ¬©ļŹĖ)ļź╝ ņé¼ņÜ®Ē¢łĻ│Ā ļŗ╣ņŗ£(2015)ļź╝ ĻĖ░ņżĆņ£╝ļĪ£ Model-Free ļ░®ņŗØņ£╝ļĪ£ State-of-the-artļź╝ ļŗ¼ņä▒ ļŗżļźĖ Ļ▓īņ×äļōżņØä ļ░░ņÜ░ĻĖ░ ņ£äĒĢ┤ņä£ ļÅÖņØ╝ĒĢ£ ņĢīĻ│Āļ”¼ņ”śņØ┤ ņé¼ņÜ®ĒĢ£ļŗżļŖö Ļ▓āņØĆ generalĒĢ£ applicationņŚÉ ļīĆĒĢ£ Ļ░ĆļŖźņä▒ņØä ņŗ£ņé¼ĒĢ© 4
- 5. Introduction Ļ░ĢĒÖöĒĢÖņŖĄņØś ņ▓ĀĒĢÖ Biological Ēś╣ņØĆ Engineered agentsļŖö ņśłņĖĪ ļČłĻ░ĆļŖźņä▒ņŚÉ ļīĆņ▓śĒĢ┤ņĢ╝ ĒĢśļ®░ trial-and-errorļź╝ ĒåĄĒĢ┤ņä£ ņāłļĪŁĻ│Ā ļ│ĆĒÖöļÉśļŖö ĒÖśĻ▓ĮņŚÉņä£ Ē¢ēļÅÖņØä ņĀüņØæņŗ£Ēé¼ ņłś ņ׳ņØī Ļ░ĢĒÖöĒĢÖņŖĄņŚÉņä£ ņŚÉņØ┤ņĀäĒŖĖļŖö ĒÖśĻ▓ĮĻ│╝ ņāüĒśĖņ×æņÜ®ĒĢśļ®┤ņä£ ņłśņ¦æĒĢ£ ļ│┤ņāüņŚÉ ļö░ļØ╝ Ē¢ēļÅÖņØä ņłśņĀĢĒĢśĻ│Ā ņØ┤ ļĢī ļ│┤ņāüņØä ņĄ£ļīĆĒÖöĒĢśĻĖ░ ņ£äĒĢ┤ņä£ ņŚÉņØ┤ņĀäĒŖĖļŖö ļ│Ąņ×ĪĒĢ£ ņןĻĖ░ņĀäļץņØä ĻĄ¼ĒśäĒĢśļŖö ļ░®ņŗØņØä Ēä░ļōØĒĢśĻ▓ī ļÉ© DQNĻ│╝ Multi-Agent Ļ░ĆļŖźĒĢ£ ņŗ£ļéśļ”¼ņśżļōżņØ┤ ļäłļ¼┤ļéśļÅä ļ¦ÄĻĖ░ ļĢīļ¼ĖņŚÉ Ļ░ĢĒÖöĒĢÖņŖĄņØĆ ļīĆĻ▓ī ļŗ©ņł£ĒĢ£ ĒÖśĻ▓ĮņŚÉļ¦ī ĻĄŁĒĢ£ļÉśņŚłĻ│Ā, ĒÖśĻ▓ĮņØś dynamicsņŚÉ ļīĆĒĢ£ ņČöĻ░Ć ņĀĢļ│┤ļĪ£ ļÅäņøĆņØä ļ░øņĢäņä£ ņĀæĻĘ╝Ē¢łņŚłņØī ĒĢśņ¦Ćļ¦ī DeepMindĻ░Ć VideoĻ▓īņ×äĻ│╝ Ļ░ÖņØĆ Ļ│Āņ░©ņøÉņĀüņØ┤Ļ│Ā ļ│Ąņ×ĪĒĢ£ ĒÖśĻ▓ĮņŚÉ RLņØä ņĀüņÜ®ĒĢ┤ ņä▒Ļ│╝ļź╝ ļāłĻ│Ā, super-humanņØś ņä▒ļŖźņØä ļŗ¼ņä▒. ĻĖ░ņ¢ĄĒĢĀ ņĀÉņØĆ raw sensory input(ņØ┤ļ»Ėņ¦Ć)ņÖĆ reward signal(Ļ▓īņ×äņĀÉņłś)ļ¦īņØä ņé¼ņÜ® Deep Q-Network(Convolution Neural Networkļź╝ Q-Learningņ£╝ļĪ£ representationĒĢśļŖö ļ¬©ļŹĖ)ļź╝ ņé¼ņÜ®Ē¢łĻ│Ā ļŗ╣ņŗ£(2015)ļź╝ ĻĖ░ņżĆņ£╝ļĪ£ Model-Free ļ░®ņŗØņ£╝ļĪ£ State-of-the-artļź╝ ļŗ¼ņä▒ ļŗżļźĖ Ļ▓īņ×äļōżņØä ļ░░ņÜ░ĻĖ░ ņ£äĒĢ┤ņä£ ļÅÖņØ╝ĒĢ£ ņĢīĻ│Āļ”¼ņ”śņØ┤ ņé¼ņÜ®ĒĢ£ļŗżļŖö Ļ▓āņØĆ generalĒĢ£ applicationņŚÉ ļīĆĒĢ£ Ļ░ĆļŖźņä▒ņØä ņŗ£ņé¼ĒĢ© ņĀĆņ×ÉļōżņØś ņŚ░ĻĄ¼ļ░®Ē¢ź DQNņØä ņé¼ņÜ®ĒĢśĻ│Ā raw screen imageņÖĆ reward signalņØä inputņ£╝ļĪ£ ļ░øļŖö ĒÖśĻ▓Įņ£╝ļĪ£ Atariļź╝ ņé¼ņÜ®ĒĢ©. ĻĘĖļ”¼Ļ│Ā ļæÉ ņŚÉņØ┤ņĀäĒŖĖĻ░Ć ņĀĢņØśļÉ£ rewarding schemeļĪ£ trainingļÉĀ ļĢī ļ│Ąņ×ĪĒĢ£ ĒÖśĻ▓Į ņåŹņŚÉņä£ ņ¢┤ļ¢╗Ļ▓ī Ē¢ēļÅÖĒĢśĻ│Ā ņāüĒśĖņ×æņÜ®ĒĢśļŖöņ¦Ćļź╝ ĒÖĢņØĖĒĢśĻ│Āņ×É ĒĢ© CompetitiveĒĢ£ ņŚÉņØ┤ņĀäĒŖĖļŖö ņĀÉņłśļź╝ ņś¼ļ”¼ļŖö Ļ▓āņØä ĒĢÖņŖĄĒĢśņ¦Ćļ¦ī CooperativeĒĢ£ Ļ▓ĮņÜ░ņŚÉļŖö Ļ│ĄņØä ņĄ£ļīĆĒĢ£ ņ£Āņ¦ĆĒĢśļŖö ņĀäļץņØä ņ░ŠņĢäļé┤ļĀżĻ│Ā ĒĢ©. Competitive ļ¬©ļō£ņÖĆ Cooperativeļ¬©ļō£ ņé¼ņØ┤ņØś ņżæĻ░ä ņāüĒā£ļź╝ ņŚ░ĻĄ¼ĒĢśĻ│Ā CompetitiveņŚÉņä£ CooperativeļĪ£ņØś ņ¦äĒ¢ēņØä Ļ┤ĆņĖĪĒĢśĻĖ░ ņ£äĒĢ┤ņä£ rewarding schemesļź╝ tuning 5
- 6. Method : DQN Q-LearningĻ│╝ DQN RLņØś ļ¬®Ēæ£ļŖö dynamicĒĢ£ ĒÖśĻ▓ĮņŚÉņä£ ņŚÉņØ┤ņĀäĒŖĖņØś accumulative long term rewardļź╝ maximizeĒĢśļŖö ņĀĢņ▒ģņØä ņ░ŠļŖö Ļ▓ā. AgentĻ░Ć ĒÖśĻ▓ĮņØś dynamicsļéś rewardņÖĆ Ļ░ÖņØĆ implicitĒĢ£ ņĀĢļ│┤Ļ░Ć ņŚåņØä ļĢī ļ¼ĖņĀ£Ļ░Ć ļÉ©. ņØ┤ ļĢī Model- Freeļ░®ņŗØņØĖ Q-LearningņØä ļŗ╣ņŗ£(ņĢĮ 2015ļģä ņĀäĒøä)ņŚÉļŖö ļ¦ÄņØ┤ ņé¼ņÜ®Ē¢łņØī Q-LearningņØĆ ĒÖśĻ▓ĮņØś ĒŖ╣ņĀĢĒĢ£ ņāüĒā£ņŚÉņä£ Ē¢ēļÅÖņØś Ļ░Ćņ╣śļź╝ ĒÅēĻ░ĆĒĢĀ ņłś ņ׳ņØī DeepMindļŖö ņØ┤ļ¤¼ĒĢ£ Q-LearningņŚÉ Convolution Neural Networkļź╝ ĒÖ£ņÜ®ĒĢ┤ Q-Valueļź╝ approximateĒĢ┤ņä£ ļ╣äļööņśż Ļ▓īņ×äņŚÉņä£ super-human ņä▒ļŖźņØä ļŗ¼ņä▒ĒĢ© 6
- 7. Method : DQN DQNĻ│╝ Multi-Agent ļæÉ Ļ░£ ņØ┤ņāüņØś ņŚÉņØ┤ņĀäĒŖĖĻ░Ć ĒÖśĻ▓ĮņØä Ļ│Ąņ£ĀĒĢśļŖö Ļ▓ĮņÜ░ļŖö ņŗ▒ĻĖĆ ņŚÉņØ┤ņĀäĒŖĖņŚÉ ļ╣äĒĢ┤ ņØ┤ĒĢ┤Ļ░Ć ņēĮņ¦Ć ņĢŖņØī ĒĢÖņŖĄņØś ļČäņé░ļÉ£ ĒŖ╣ņä▒ņØĆ ņāłļĪ£ņÜ┤ ņØ┤ņĀÉņØä ņĀ£Ļ│ĄĒĢśņ¦Ćļ¦ī, ņóŗņØĆ ĒĢÖņŖĄ ļ¬®Ēæ£ņØś ņĀĢņØśļéś ņĢīĻ│Āļ”¼ņ”śņØś ņłśļĀ┤ ļ░Å ņØ╝Ļ┤Ćņä▒ Ļ░ÖņØĆ ņĀÉņØä Ļ│ĀļĀżĒĢ┤ņĢ╝ ĒĢ© Ex) Multi-Agent SettingņØś Ļ▓ĮņÜ░ ĒÖśĻ▓ĮņØś state transitionņÖĆ rewardĻ░Ć ļ¬©ļōĀ ņŚÉņØ┤ņĀäĒŖĖņØś Ļ│ĄļÅÖ ņ×æņŚģņŚÉ ņśüĒ¢źņØä ļ░øņØī. ņŚÉņØ┤ņĀäĒŖĖ1ņØś Ē¢ēļÅÖņŚÉ ļīĆĒĢ£ Ļ░Ćņ╣śĻ░Ć ļŗżļźĖ ņŚÉņØ┤ņĀäĒŖĖ2ņØś Ē¢ēļÅÖņŚÉ ļö░ļØ╝ ļ│ĆĻ▓ĮļÉśĻĖ░ ļĢīļ¼ĖņŚÉ Ļ░ü ņŚÉņØ┤ņĀäĒŖĖļŖö ļŗżļźĖ ĒĢÖņŖĄ ņŚÉņØ┤ņĀäĒŖĖļź╝ ņČöņĀüĒĢ┤ņĢ╝ļ¦ī ĒĢ©. ņØ╝ļ░śņĀüņ£╝ļĪ£ ļŗżļźĖ ņŚÉņØ┤ņĀäĒŖĖĻ░Ć ņ׳ļŖö ņāüĒā£ņŚÉņä£ ĒĢÖņŖĄņØä ņłśĒ¢ēĒĢśļ®┤ Ļ░ü ņŚÉņØ┤ņĀäĒŖĖņØś stabilityņÖĆ adaptive behaviorņé¼ņØ┤ņØś ĻĘĀĒśĢņØ┤ ĒĢäņÜöĒĢ© ļŗżņżæ ņŚÉņØ┤ņĀäĒŖĖņŚÉ Q-LearningņĢīĻ│Āļ”¼ņ”śņØä ņĀüņÜ®ĒĢśļŖö ņé¼ļĪĆĻ░Ć ņ׳ņ¦Ćļ¦ī ĻĘĖ ļŗ╣ņŗ£ļź╝ ĻĖ░ņżĆņ£╝ļĪ£ļŖö ĒŖ╣ņĀĢ ņ£ĀĒśĢņŚÉ ļö░ļØ╝ņä£ ņĀ£ņĢĮņØ┤ ņĪ┤ņ×¼ (ĻĘĖ ļŗ╣ņŗ£ ĻĖ░ņżĆ)Simplicity, decentrailized nature, computational speed ĻĘĖļ”¼Ļ│Ā ņ×æņŚģņØś ļ▓öņ£äņŚÉ ļīĆĒĢ┤ ņØ╝Ļ┤ĆļÉ£ Ļ▓░Ļ│╝ļź╝ ņé░ņČ£ĒĢĀ ņłś ņ׳ļŖö ļŖźļĀźņØ┤ DQNņŚÉ ņ׳ĻĖ░ ļĢīļ¼ĖņŚÉ ņØ┤ ļ░®ļ▓ĢņØä ņé¼ņÜ®. ĒīīļØ╝ļ»ĖĒä░ļŖö Human-level control through deep reinforcement learning ņØś ļģ╝ļ¼ĖĻ│╝ ļÅÖņØ╝ĒĢśĻ▓ī ņäżņĀĢ 7
- 8. Method : Adaptation of the Code for the Multiplayer Paradigm OpenAI GymĻ│╝ MultiAgent Setting ĻĖ░ņĪ┤ņØś Human-level control through deep reinforcement learning ļģ╝ļ¼ĖĻ│╝ ĒĢ©Ļ╗ś Ļ│ĄĻ░£ļÉ£ ņĮöļō£ļŖö ļ®ĆĒŗ░ ņŚÉņØ┤ņĀäĒŖĖ Ļ▓īņ×äņØä ņłśĒ¢ēĒĢĀ ņłś ņ׳ļŖö ĒÖśĻ▓ĮņØä Ļ│ĄĻ░£ĒĢśņ¦Ć ņĢŖņĢśņØī ņŚÉņØ┤ņĀäĒŖĖļŖö DQNņ£╝ļĪ£ ļÅģļ”ĮņĀüņ£╝ļĪ£ ĻĄ¼Ēśä ļÉśņ¢┤ņ׳Ļ│Ā, Atari Ļ▓īņ×äņØĆ ļŗżņżæ ĒöīļĀłņØ┤ņ¢┤ļź╝ ĒŚłņÜ®ĒĢśņ¦Ćļ¦ī ņŚÉņØ┤ņĀäĒŖĖņÖĆ ņŚÉļ«¼ļĀłņØ┤Ēä░ Ļ░äņØś communication protocolņØĆ ļŗ©ņØ╝ ĒöīļĀłņØ┤ņ¢┤ļź╝ ņé¼ņÜ®ĒĢśļÅäļĪØ ņĀ£ĒĢ£ņØä Ļ▒Ėņ¢┤ļåōņØī Ļ▓īņ×ä ĒÖöļ®┤ņØĆ Fully ObservableĒĢśĻ│Ā ļæÉ ņŚÉņØ┤ņĀäĒŖĖ Ļ░äņŚÉ Ļ│Ąņ£ĀļÉśļ»ĆļĪ£ ļÅÖņŗ£ņŚÉ ņŚ¼ļ¤¼ ņŚÉņØ┤ņĀäĒŖĖņŚÉ Ļ▓īņ×ä ņāüĒā£ļź╝ ņĀ£Ļ│ĄĒĢśĻĖ░ ņ£äĒĢ┤ņä£ ņČöĻ░ĆņĀüņØĖ ņłśņĀĢņØ┤ ĒĢäņÜöĒĢśņ¦Ć ņĢŖņĢśņØī 8
- 9. Method : Game Selection GameĒÖśĻ▓Į Ļ▓░ņĀĢ ĻĖ░ņżĆ ALE(Atari Learning Environment)ļŖö 61Ļ░£ņØś Ļ▓īņ×äņØä ņ¦ĆņøÉĒĢśĻ│Ā ņ׳ņ¦Ćļ¦ī 2Ļ░£ņØś ĒöīļĀłņØ┤ņ¢┤ ļ¬©ļō£Ļ░Ć Ļ░ĆļŖźĒĢ£ Ļ▓īņ×äĒÖśĻ▓ĮņØĆ ĻĄēņןĒ׳ ņĀüņØī. ĻĘĖļלņä£ ņŗżĒŚśņØä ņ£äĒĢ┤ņä£ ņĢäļלņØś 3Ļ░Ćņ¦ĆņØś ĻĖ░ņżĆņ£╝ļĪ£ ņŗżĒŚśĒÖśĻ▓ĮņØä ĒĢäĒä░ļ¦ü 1. Real-time two-player modeĻ░Ć ņ׳ņ¢┤ņĢ╝ĒĢ© : ņśłļź╝ ļōżņ¢┤ BreakoutņØś Ļ▓ĮņÜ░ļŖö ļæÉ ļ¬ģņØś ĒöīļĀłņØ┤ņ¢┤Ļ░Ć ļ▓łĻ░łņĢä ņłśĒ¢ēĒĢ┤ņĢ╝ĒĢśļŖö ļŗ©ņĀÉņØ┤ ņ׳ņ£╝ļ»ĆļĪ£ ņé¼ņÜ® X 2. Deep Q-Learning ņĢīĻ│Āļ”¼ņ”śņØ┤ ņŗ▒ĻĖĆ ĒöīļĀłņØ┤ņ¢┤ ļ¬©ļō£ņŚÉņä£ ņØĖĻ░ä ņłśņżĆ ņØ┤ņāüņØś Ļ▓īņ×äņØä ņłśĒ¢ēĒĢ£ Ļ▓āņØ┤ Ļ▓Ćņ”ØļÉ£ ĒÖśĻ▓Įļ¦ī ņé¼ņÜ®ĒĢ© : ņśłļź╝ ļōżņ¢┤ ŌĆ£Wor of WizardŌĆØļØ╝ļŖö Ļ▓īņ×äņØĆ 2ņØĖ ļ¬©ļō£ļź╝ ņĀ£Ļ│ĄĒĢśņ¦Ćļ¦ī ļ»ĖļĪ£ ĒāÉņāēņØĆ ĻĖ░ņĪ┤ņØś DQNņ£╝ļĪ£ ļ¦łņŖżĒä░ĒĢĀ ņłś ņŚåņŚłņØī 3. Ļ▓īņ×ä ņ×Éņ▓┤Ļ░Ć Ļ▓Įņ¤ü ļ¬©ļō£ņØĖ Ļ▓ĮņÜ░ : ĻĘĖļ”¼Ļ│Ā reward functionņØä ļ│ĆĻ▓ĮĒĢ┤ņä£ CooperationĒĢ£ Ļ▓ĮņÜ░ņÖĆ CompetitiveĒĢ£ Ļ▓ĮņÜ░ļź╝ ņĀäĒÖśĒĢĀ ņłś ņ׳ļŖö Ļ▓īņ×äņØ┤ņ¢┤ņĢ╝ ĒĢ© Ļ▓░Ļ│╝ņĀüņ£╝ļĪ£ PongĻ▓īņ×ä ĒÖśĻ▓ĮņØ┤ ļ¬©ļōĀ ĻĖ░ņżĆņØä ļ¦īņĪ▒ĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ņäĀĒāØĒĢśĻ▓ī ļÉśņŚłĻ│Ā ņāüļīĆņĀüņ£╝ļĪ£ ļäÉļ”¼ ņĢīļĀżņ¦ä Ļ▓īņ×äņØ┤ļ»ĆļĪ£ ņäĀĒāØ!! 9
- 10. Method : Game Selection GameĒÖśĻ▓Į Ļ▓░ņĀĢ ĻĖ░ņżĆ PongņŚÉņä£ Ļ░ü ņŚÉņØ┤ņĀäĒŖĖļŖö ĒÖöļ®┤ņØś ņÖ╝ņ¬ĮĻ│╝ ņśżļźĖņ¬ĮņŚÉ ņ£äņ╣śĒĢ£ Ēī©ļōż ņżæ ĒĢśļéśņŚÉ ĒĢ┤ļŗ╣ ļæÉ ņŚÉņØ┤ņĀäĒŖĖĻ░Ć ĒĢĀ ņłś ņ׳ļŖö Ē¢ēļÅÖņØś ņĪ░ĒĢ®ņØĆ 4Ļ░Ćņ¦Ć : ņ£äļĪ£ ņØ┤ļÅÖ, ņĢäļלļĪ£ ņØ┤ļÅÖ, ņĀĢņ¦Ć ļ░Å ļ░£ņé¼(ļ│╝ņØä ņŗ£ņ×æĒĢśĻ▒░ļéś Ļ▓īņ×ä ņŗ£ņ×æ) ņ¢┤ļ¢ż Ē¢ēļÅÖņØ┤ Ļ▓░ņĀĢļÉśļŖöņ¦ĆļŖö Ļ░üĻ░üņØś DQNņŚÉ ņØśĒĢ┤ ļæÉ ņŚÉņØ┤ņĀäĒŖĖĻ░Ć ļ│äĻ░£ļĪ£ Ļ▓░ņĀĢņØ┤ ļÉ£ļŗżļŖö Ļ▓āņØä ĻĖ░ņ¢ĄĒĢ┤ņĢ╝ ĒĢ© Ēśäņ×¼ ņŚ░ĻĄ¼ ļ▓öņ£äļź╝ ļ▓Śņ¢┤ļéśņ¦Ćļ¦ī Ļ▓Įņ¤üĻ│╝ ĒśæņŚģņŚÉ Ļ┤ĆĒĢ┤ ĒØźļ»ĖļĪ£ņÜ┤ Ļ│╝ĒĢÖņĀü ņ¦łļ¼ĖĻ│╝ ņל ņ¢┤ņÜĖļ”¼ļŖö ļŗżļźĖ ļæÉ Ļ░Ćņ¦Ć Ļ▓īņ×äņŚÉ ļīĆĒĢ┤ņä£ ĒÖĢņØĖ(Outlaw, Warlords) 1. OutlawļŖö ņĀ£ĒĢ£ļÉ£ Ļ▓īņ×ä ļ¬©ļō£ņŚÉņä£ ņŻäņłśņØś ļö£ļĀłļ¦łņŚÉ ļīĆĒĢ£ ņŗżņŗ£Ļ░ä ĻĘ╝ņé¼ņ╣śļĪ£ ļ│╝ ņłś ņ׳ļŖö Ļ░äļŗ©ĒĢ£ ņŖłĒīģĻ▓īņ×ä 2. WarlordsļŖö ņĄ£ļīĆ 4ļ¬ģņØś ĒöīļĀłņØ┤ņ¢┤Ļ░Ć ņĀüņØ┤ ļéśĒāĆļé¼ņØä ļĢī collaborationņØ┤ ļéśĒāĆļéśļŖöņ¦Ćļź╝ ĒģīņŖżĒŖĖĒĢĀ ņłś ņ׳ļŖö Ļ▓īņ×ä 10
- 11. Method : Rewarding Schemes Rewarding Schemes ņŗżĒŚśņØś ļ¬®Ēæ£ļŖö agentņŚÉĻ▓ī ļ│┤ņāüņØä ļ░øļŖö ļ░®ļ▓ĢņŚÉ ļö░ļØ╝ņä£ ļŗżņ¢æĒĢśĻ▓ī ņĪ░ņĀĢļÉ£ Ē¢ēļÅÖņØ┤ ļéśĒāĆļéśļŖö Ļ▓āņØä ņŚ░ĻĄ¼ĒĢśļŖö Ļ▓āņ×ä. ņØ┤ļ¤¼ĒĢ£ ļ¬®Ēæ£ņŚÉ ļö░ļØ╝ņä£ ņŚ¼ļ¤¼Ļ░Ćņ¦ĆņØś Rewarding SchemeļōżņØä ņäżņĀĢĒ¢łņØī 1. Score More than the Opponent(Fully Competitive) 2. Loosing the Ball Penalizes Both Players(Fully Cooperative) 3. Transition Between Cooperation and Competition 11
- 12. Score More than the Opponent(Fully Competitive) CompetitiveĒĢ£ Zero-Sum Schemes : ņØ┤ĻĖ░ļ®┤ +1, ņ¦Ćļ®┤ -1 PongņŚÉņä£ļŖö Ļ│ĄņØä ļ¦łņ¦Ćļ¦ēņ£╝ļĪ£ Ēä░ņ╣śĒĢ£ PlayerĻ░Ć Ēöīļ¤¼ņŖż ņĀÉņłśļź╝ ņ¢╗Ļ│Ā, Ļ│ĄņØä ļåōņ╣śļŖö PlayerĻ░Ć ļ¦łņØ┤ļäłņŖż ņĀÉņłśļź╝ ņ¢╗ņØī. ĻĖ░ļ│ĖņĀüņØĖ Zero-SumĻ▓īņ×äņØ┤ ļÉśļŖö ĻĄ¼ņĪ░. ļ¦īņĢĮ ņÖ╝ņ¬Į ĒöīļĀłņØ┤ņ¢┤Ļ░Ć ĻĖŹņĀĢņĀüņØĖ ļ│┤ņāüņØä ņ¢╗Ļ▓ī ļÉśļ®┤ ņśżļźĖņ¬ĮņŚÉ ņ׳ļŖö PlayerļŖö ļČĆņĀĢņĀüņØĖ ļ│┤ņāüņØä ļ░øĻ▓ī ļÉśĻ│Ā ļ░śļīĆļÅä ļ¦łņ░¼Ļ░Ćņ¦Ć ņØ┤ļ¤¼ĒĢ£ Ļ▓ĮņÜ░ļź╝ ņÖäņĀäĒĢ£ Ļ▓Įņ¤üļ¬©ļō£ļØ╝Ļ│Ā ļČĆļ”ä 12
- 13. Loosing the Ball Penalizes Both Players(Fully Cooperative) Cooperative Mode : BallņØä ņ×āņ¢┤ļ▓äļ”¼ļ®┤ ĒÄśļäÉĒŗ░ Ļ░ĆļŖźĒĢ£ ņŚÉņØ┤ņĀäĒŖĖļōżņØ┤ ņśżļ×½ļÅÖņĢł Ļ▓īņ×äņŚÉņä£ Ļ│ĄņØä ņ£Āņ¦ĆĒĢśļŖö ļ▓ĢņØä ļ░░ņÜ░ļŖö Ļ▓ā. Ļ│ĄņØä ļåōņ╣śļŖö Ļ▓ĮņÜ░ņŚÉ ļæÉ PlayerņŚÉĻ▓ī ļČĆņĀĢņĀüņØĖ ļ│┤ņāüņØä ņäżņĀĢĒĢ© ĻĖ░ņ¢ĄĒĢĀ ņĀÉņØĆ ņ¢┤ļŖÉ PlayerĻ░Ć Ļ│ĄņØä ņ│Éņä£ ņāüļīĆļ░®ņŚÉĻ▓ī ļŹśņ¦ĆļŖöņ¦ĆļŖö ņżæņÜöĒĢśņ¦Ć ņĢŖĻ│Ā ĻĖŹņĀĢņĀüņØĖ ļ│┤ņāüņØä ļ░øņØä ņłś ņ׳ļŖö ņäżņĀĢņØĆ ņĪ┤ņ×¼ĒĢśņ¦Ć ņĢŖņØī tip) ļśÉ ļŗżļźĖ Ļ░ĆļŖźĒĢ£ ĒśæļĀź ļ¬©ļō£ļŖö Ļ░üĻ░üņØś ļéśĻ░ĆļŖö Ļ│ĄņŚÉņä£ ļæÉ ņäĀņłśņŚÉĻ▓ī ļ│┤ņāüņØä ĒĢśļŖö Ļ▓āņØ┤ņ¦Ćļ¦ī ņŗżĒŚśņØä ĒĢśņ¦Ć ņĢŖņĢśļŗżĻ│Ā ĒĢ© 13
- 14. Transition Between Cooperation and Competition Transition Between Cooperation and Competition CooperativeĒĢ£ Ļ▓ĮņÜ░ņÖĆ CompetitiveĒĢ£ Ļ▓ĮņÜ░ ļ¬©ļæÉ Ļ│ĄņØä ņ×āņ¢┤ļ▓äļ”¼ļ®┤ penaltyļź╝ ļ░øņØī ļæÉ Ļ░Ćņ¦ĆņØś ņĀäļץņØä ĻĄ¼ļ│äĒĢśļŖö Ļ▓āņØĆ Reward MatrixņØś ļīĆĻ░üņäĀ ņāüņŚÉ ņĪ┤ņ×¼ĒĢśļŖö Ļ░Æņ×ä. ļ│┤ņāü ņŚÉņØ┤ņĀäĒŖĖļōżņØ┤ ļŗżļźĖ Playerļź╝ ņ¦Ćļéśņ│Éņä£ Ļ│ĄņØä ļŹśņ¦Ćļ®┤ņä£ ņ¢╗ņØī. RewardņØś Ļ░Ćņ╣śĻ░Ć -1ņŚÉņä£ 1ļĪ£ ņĀÉņ¦äņĀüņ£╝ļĪ£ ļ│ĆĒÖöļÅäļĪØ ĒŚłņÜ®ĒĢśļ®┤ CompetitiveņÖĆ CooperationņŚÉ ņ׳ļŖö ņżæĻ░ä ņŗ£ļéśļ”¼ņśżļź╝ ĒÖĢņØĖĒĢĀ ņłś ņ׳ņØī ĒżņØĖĒŖĖ rhoļź╝ ņĀÉņłśļĪ£ ĒĢśļŖö ļ│┤ņāüņØ┤ -1ņŚÉņä£ 1ļĪ£ ļ│ĆĒÖöĒĢśĻ│Ā Ļ│ĄņØś ņåÉņŗżņŚÉ ļīĆĒĢ£ ĒÄśļäÉĒŗ░ļŖö -1ļĪ£ Ļ│ĀņĀĢņŗ£ņ╝£ņä£ ņĀæĻĘ╝ĒĢ©. 14
- 15. Training Procedure Training Procedure ļ¬©ļōĀ ņŗżĒŚśņŚÉņä£, 50 Epochsļź╝ ņäżņĀĢĒĢśĻ│Ā timestepņØĆ 1~250000ņØä ņäżņĀĢ Frame skippingņØä ņé¼ņÜ®ĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ņŚÉņØ┤ņĀäĒŖĖĻ░Ć 4ļ▓łņ¦Ė ĒöäļĀłņ×äņØä ĻĖ░ņżĆņ£╝ļĪ£ ņłśĒ¢ēļÉ©. ŌĆ£visible frameŌĆØ, ŌĆ£frameŌĆØ, ŌĆ£time stepŌĆØņØä ņé¼ņÜ®ĒĢ© Epsilon greedyļź╝ ņé¼ņÜ®ĒĢśņŚ¼ Epsilon decayļź╝ ņäżņĀĢ(1ņŚÉņä£ 0ņ£╝ļĪ£ 0.05ļź╝ ņäżņĀĢĒĢśņŚ¼ ņĀæĻĘ╝) 15
- 16. Collecting the Game Statics PongĒÖśĻ▓ĮņŚÉņä£ ņŚÉņØ┤ņĀäĒŖĖņØś Ē¢ēļÅÖņŚÉ ļīĆĒĢ£ ņĀĢļ¤ēņĀüņØĖ ņĖĪņĀĢņØä ņ¢╗ĻĖ░ ņ£äĒĢ┤ņä£ Ļ▓īņ×äņØś ņØ┤ļ▓żĒŖĖļź╝ ĒÖĢņØĖĒĢśĻ│Ā Ļ│äņé░Ē¢łņØī(ļ│╝ņØ┤ Paddle ļśÉļŖö WallņŚÉ ļČĆļö¬Ē׳ļŖö Ļ▓ĮņÜ░) - stella : ŌĆ£A Multi-Platform Atari 2600 VCS EmulatorŌĆØ ļź╝ ņé¼ņÜ®ĒĢ┤ņä£ ņØ┤ļ▓żĒŖĖļź╝ Ļ░Éņ¦Ć CooperativeņÖĆ Competitiveļź╝ ņ¢æņĀüņ£╝ļĪ£ ĒÅēĻ░ĆĒĢśĻĖ░ ņ£äĒĢ┤ņä£ ļ¬©ļōĀ rewarding schemeņŚÉ ļīĆĒĢ┤ņä£ Ļ░ü ĒøłļĀ© epochņØ┤ ļüØļé£ ņØ┤ĒøäņŚÉ ņĖĪņĀĢļÉ£ Ļ▓░Ļ│╝ļź╝ ņłśņ¦æĒĢ©. Ļ░ü epochņØ┤ ļüØļé£ ņØ┤ĒøäņŚÉ ļæÉ PlayerņØś Ēśäņ×¼ stateņŚÉ ņ׳ļŖö Q-Networkļź╝ ĒÖ£ņÜ®ĒĢśļ®░ random seedņØś Ļ░ÆņØä ļ│ĆĻ▓ĮĒĢ┤ 10ļ▓łņØś Ļ▓īņ×äņØä ņŗżĒŚśĒĢśĻ│Ā ĒåĄĻ│äņ╣śļź╝ ņłśņ¦æĒĢ©. Testingļŗ©Ļ│äņŚÉņä£ļŖö epsilon(exploration rate)ņØś Ļ░ÆņØä 0.01ļĪ£ ņäżņĀĢĒĢ© 1. Average paddle-bounces per point pointļ│ä ĒÅēĻĘĀ paddle-bouncesļŖö ļæÉ Player ņżæ ĒĢ£ ļ¬ģņØ┤ ļōØņĀÉĒĢśĻĖ░ ņĀäņŚÉ Ļ│ĄņØ┤ ļæÉ ņäĀņłś ņé¼ņØ┤ņŚÉņä£ ļ¬ć ļ▓ł ĒŖĆļŖöņ¦Ćļź╝ ņäĖņ¢┤ļ│┤ļŖö Ļ▓āņ×ä. Random playļź╝ ĒĢśļŖö ņŚÉņØ┤ņĀäĒŖĖļŖö Ļ│ĄņØä Ļ▒░ņØś ņ╣śņ¦Ć ļ¬╗ĒĢ©. ņŗżĒŚśņŚÉņä£ļŖö Paddle- bouncesļØ╝Ļ│Ā ļ¬ģļ¬ģ 2. Average wall-bounces per paddle-bounce paddle-bounceļŗ╣ ĒÅēĻĘĀ wall-bounceļŖö ņāüļīĆ PlayerņŚÉĻ▓ī ļÅäļŗ¼ĒĢśĻĖ░ ņĀäņŚÉ ņ£äņ¬ĮĻ│╝ ņĢäļלņ¬Į ļ▓ĮņŚÉņä£ ņ¢╝ļ¦łļéś ļ¦ÄņØ┤ Ļ│ĄņØ┤ ļČĆļö¬Ē׳ļŖöņ¦Ćļź╝ ņØśļ»ĖĒĢ©. ņāüļīĆļ░® PlayerņŚÉĻ▓ī ļŗ┐ĻĖ░ ņĀäņŚÉ ņŚ¼ļ¤¼ ļ▓ł ļ▓ĮņØä ĒŖĢĻĖ░ļÅäļĪØ ļéĀņ╣┤ļĪ£ņÜ┤ Ļ░üļÅäļĪ£ Ļ│ĄņØä ņ╣Ā ņłś ņ׳ņØī. ņŗżĒŚśņŚÉņä£ļŖö wall-bounceļØ╝Ļ│Ā ļ¬ģļ¬ģ 3. Average serving time per point pointļ│ä ĒÅēĻĘĀ servingņŗ£Ļ░äņØĆ PlayerĻ░Ć Ēī©ĒĢ£ Ēøä Ļ▓ĮĻĖ░ļź╝ ļŗżņŗ£ ņŗ£ņ×æĒĢśļŖöļŹ░ Ļ▒Ėļ”¼ļŖö ņŗ£Ļ░ä. Ļ▓īņ×äņØä ļŗżņŗ£ ņŗ£ņ×æĒĢśļĀżļ®┤ ļōØņĀÉņØä ņ¢╗ņØĆ PlayerĻ░Ć fireļØ╝ļŖö ĒŖ╣ņĀĢ ļ¬ģļĀ╣ņØä ņłśĒ¢ēĒĢ┤ņĢ╝ĒĢ©. ņŗżĒŚśņŚÉņä£ļŖö serving timeņØ┤ļØ╝Ļ│Ā ļ¬ģļ¬ģ 16
- 17. Results : Emergence of Competitive Agents Results : Emergence of Competitive Agents 17
- 18. Results : Emergence of Competitive Agents Results : Emergence of Competitive Agents 18
- 19. Results : Emergence of Competitive Agents Competitive AgentsĻ▓░Ļ│╝ ļÅÖņśüņāü 19
- 20. Results : Emergence of Cooperative Agents Results : Emergence of Cooperative Agents 20
- 21. Results : Emergence of Cooperative Agents Results : Emergence of Cooperative Agents 21
- 22. Results : Emergence of Cooperative Agents Cooperative AgentsĻ▓░Ļ│╝ ļÅÖņśüņāü 22
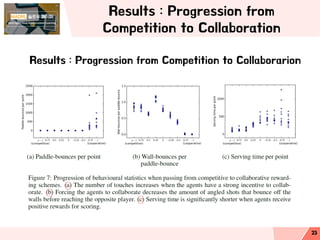
- 23. Results : Progression from Competition to Collaboration Results : Progression from Competition to Collaborarion 23
- 24. Results : Progression from Competition to Collaboration Results : Progression from Competition to Collaborarion 24