Multiquery optimization on spark
?Download as PPTX, PDF?
0 likes?240 views

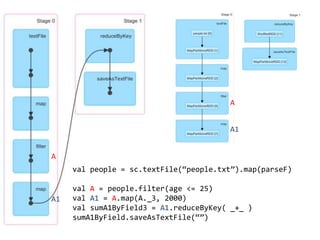
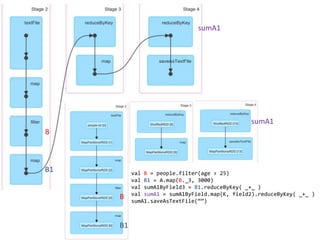
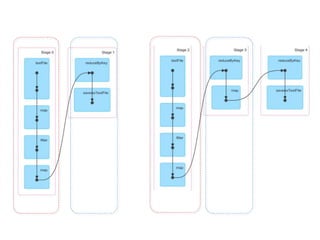
The document loads a text file of people data, filters the data into those aged 25 and under (A) and over 25 (B), maps values to those groups, performs reduce by key operations on fields 3 of A and B to sum values, and saves the results as text files. It also shows the various Spark stages involved in the distributed processing.

Multiquery optimization on spark
- 2. val people = sc.textFile(Ī░people.txtĪ▒).map(parseF) val A = people.filter(age <= 25) val A1 = A.map(A._3, 2000) val sumA1ByField3 = A1.reduceByKey( _+_ ) sumA1ByField.saveAsTextFile(Ī░Ī▒) A A A1 A1
- 3. val B = people.filter(age > 25) val B1 = A.map(B._3, 3000) val sumA1ByField3 = B1.reduceByKey( _+_ ) val sumA1 = sumA1ByField.map(K, field2).reduceByKey( _+_ ) sumA1.saveAsTextFile(Ī░Ī▒) B B B1 B1 sumA1 sumA1
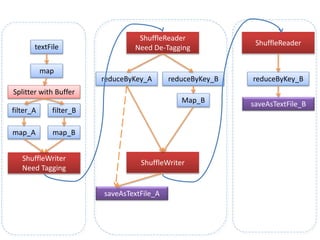
- 5. textFile map filter_Bfilter_A map_A map_B ShuffleWriter Need Tagging Splitter with Buffer reduceByKey_A saveAsTextFile_A reduceByKey_B Map_B ShuffleReader Need De-Tagging ShuffleWriter reduceByKey_B ShuffleReader saveAsTextFile_B