NDC 2016, [žäąŪĆźžõĆ] Žß®Žē֞󟞥ú ŽćįžĚīŪĄį Ž∂ĄžĄĚ žčúžä§ŪÖú ŽßƎ吏ĖīŽāėÍįÄÍłį
‚ÄĘ
16 likes‚ÄĘ2,443 views

žõźŽ≥ł: http://beingryu.github.io/ndc-2016






































































![Í∑ł ŪĆƞ̾žĚī ÍįúŽįúžěźÍįÄ Ž≥īÍłįžóź žĘčžēėŽÖłŽĚľ
spark-shell: Spark-powered Scala REPL Shell
scala> val df = sqlContext.read.parquet(".../log_pvp/gl")
df: org.apache.spark.sql.DataFrame = [lord_idx: bigint, ...]
scala> df.registerTempTable("pvp")
scala> val win_df = sqlContext.sql(
"SELECT lord_idx, SUM(is_win) AS win_count FROM pvp
WHERE time_ym = 201604 AND time_d = 26 AND is_win = 1
GROUP BY lord_idx")
win_df: org.apache.spark.sql.DataFrame = [lord_idx: bigint, win_count: bigint]
scala> win_df.sort($"win_count".desc).limit(10).collect()
res1: Array[org.apache.spark.sql.Row] = Array([12345, 42], [23456, 41], ...)](https://image.slidesharecdn.com/ndc-2016-160429031551/85/NDC-2016-74-320.jpg)









![NDC 2016, [žäąŪĆźžõĆ] Žß®Žē֞󟞥ú ŽćįžĚīŪĄį Ž∂ĄžĄĚ žčúžä§ŪÖú ŽßƎ吏ĖīŽāėÍįÄÍłį](https://image.slidesharecdn.com/ndc-2016-160429031551/85/NDC-2016-84-320.jpg)























{ return x.userId(...).action(...); });
// semi-structured
ServerLogger.logs(ctx, "action",
[&](auto x){ return x.field("userId", ...).field("action", ...); });
// unstructured
ServerLogger.logf(ctx, "user %d trying to do %s", ...);](https://image.slidesharecdn.com/ndc-2016-160429031551/85/NDC-2016-111-320.jpg)

![NDC 2016, [žäąŪĆźžõĆ] Žß®Žē֞󟞥ú ŽćįžĚīŪĄį Ž∂ĄžĄĚ žčúžä§ŪÖú ŽßƎ吏ĖīŽāėÍįÄÍłį](https://image.slidesharecdn.com/ndc-2016-160429031551/85/NDC-2016-113-320.jpg)
![NDC 2016, [žäąŪĆźžõĆ] Žß®Žē֞󟞥ú ŽćįžĚīŪĄį Ž∂ĄžĄĚ žčúžä§ŪÖú ŽßƎ吏ĖīŽāėÍįÄÍłį](https://image.slidesharecdn.com/ndc-2016-160429031551/85/NDC-2016-114-320.jpg)
![NDC 2016, [žäąŪĆźžõĆ] Žß®Žē֞󟞥ú ŽćįžĚīŪĄį Ž∂ĄžĄĚ žčúžä§ŪÖú ŽßƎ吏ĖīŽāėÍįÄÍłį](https://image.slidesharecdn.com/ndc-2016-160429031551/85/NDC-2016-115-320.jpg)
![NDC 2016, [žäąŪĆźžõĆ] Žß®Žē֞󟞥ú ŽćįžĚīŪĄį Ž∂ĄžĄĚ žčúžä§ŪÖú ŽßƎ吏ĖīŽāėÍįÄÍłį](https://image.slidesharecdn.com/ndc-2016-160429031551/85/NDC-2016-116-320.jpg)
![NDC 2016, [žäąŪĆźžõĆ] Žß®Žē֞󟞥ú ŽćįžĚīŪĄį Ž∂ĄžĄĚ žčúžä§ŪÖú ŽßƎ吏ĖīŽāėÍįÄÍłį](https://image.slidesharecdn.com/ndc-2016-160429031551/85/NDC-2016-117-320.jpg)

![NDC 2016, [žäąŪĆźžõĆ] Žß®Žē֞󟞥ú ŽćįžĚīŪĄį Ž∂ĄžĄĚ žčúžä§ŪÖú ŽßƎ吏ĖīŽāėÍįÄÍłį](https://image.slidesharecdn.com/ndc-2016-160429031551/85/NDC-2016-120-320.jpg)
























NDC 2016, [žäąŪĆźžõĆ] Žß®Žē֞󟞥ú ŽćįžĚīŪĄį Ž∂ĄžĄĚ žčúžä§ŪÖú ŽßƎ吏ĖīŽāėÍįÄÍłį
- 1. <žäąŪĆźžõĆ> Žß®Žē֞󟞥ú ŽćįžĚīŪĄį Ž∂ĄžĄĚ žčúžä§ŪÖú ŽßƎ吏ĖīŽāėÍįÄÍłį ŽāīÍįÄ Í∑łŽ•ľ ž†Āžě¨ŪēėÍłį ž†ĄžóźŽäĒ Í∑łŽäĒ Žč§ŽßĆ ŪēėŽāėžĚė Ž†ąžĹĒŽďúžóź žßÄŽāėžßÄ žēäžēėŽč§ ŽāīÍįÄ Í∑łŽ•ľ Ž≥ÄŪôėŪĖąžĚĄ ŽēĆ Í∑łŽäĒ ŽāėžóźÍ≤ĆŽ°ú žôÄžĄú ž†ēŽ≥īÍįÄ ŽźėžóąŽč§ ŽĄ•žä®žßÄŪčį žįĹž°įÍłįžą†ŪĆ∂ń Ž•ėžõźŪēė (wonha.ryu@nexon-gt.com)
- 2. žÜĆÍįú žöįŽ¶į ŽąĄÍĶįÍįÄ Žėź Ž¨īžä® žĚīžēľÍłįŽ•ľ ŪēėŽ†§ ŪēėŽäĒÍįÄ
- 3. <žäąŪćľ ŪĆźŪÉÄžßÄ žõĆ> ŽĄ•žä®žßÄŪčį žěźž≤ī ÍįúŽįú žĄł Ž≤ąžßł Ž™®ŽįĒžĚľ ŪÉÄžĚīŪčÄ ŪĄī Žį©žčĚ SRPG Unity, Node.js, MySQL
- 6. (žĪĄžö©Í≥ĶÍ≥† Žįúž∑Ć) ‚Ķ žįĹž°įÍłįžą†ŪĆ∂ńžóźžĄúŽäĒ žó¨Žü¨ Í≤ĆžěĄ ÍįúŽįú ŪĒĄŽ°úž†ĚŪ䳞󟞥ú Í≤™Í≥† žěąŽäĒ ‚Ķ Žč§žĖĎŪēú Ž¨łž†úŪēīÍ≤įžĚĄ žßĄŪĖČŪēėŽ©į Í∑łžóź ŪēĄžöĒŪēú ÍłįŽįėÍłįžą†žĚĄ žóįÍĶ¨Íįú Žįú, ž†Āžö©ŪēėŽäĒ žĚľžĚĄ ŪēėÍ≥† žěąžäĶŽčąŽč§. ‚Ķ žóÖŽ¨ī Ž≤ĒžúĄžóź ž†úŪēúžĚÄ žóÜžúľŽāė, žĶúÍ∑ľžóź žßĄŪĖČŪēėžėÄŽćė žóÖŽ¨īžĚė žėąŽäĒ Žč§ žĚĆÍ≥ľ ÍįôžäĶŽčąŽč§. ŽĻÖŽćįžĚīŪĄį Í∑úŽ™®žĚė Ž°úÍ∑ł ŽįŹ DB ŽćįžĚīŪĄį žąėžßĎ ÍįÄÍ≥Ķ, Ž∂ĄžĄĚ Ūôúžö© žčú žä§ŪÖú ÍįúŽįú Í≤ĆžěĄ ÍįúŽįú ŪĒĄŽ°úž†ĚŪäłžĚė Íłįžą† žä§ŪÉĚžóź ŽĆÄŪēú ÍīÄŽ¶¨ ŽįŹ Íłįžą†ž†Ā žĚėžā¨ Í≤įž†ē žįłžó¨ ÍįúŽįú žßÄžčĚžĚė ž†ēŽ¶¨, Ž≥īž°ī, Í≥Ķžú†
- 7. (žĪĄžö©Í≥ĶÍ≥† Žįúž∑Ć) ‚Ķ žįĹž°įÍłįžą†ŪĆ∂ńžóźžĄúŽäĒ žó¨Žü¨ Í≤ĆžěĄ ÍįúŽįú ŪĒĄŽ°úž†ĚŪ䳞󟞥ú Í≤™Í≥† žěąŽäĒ ‚Ķ Žč§žĖĎŪēú Ž¨łž†úŪēīÍ≤įžĚĄ žßĄŪĖČŪēėŽ©į Í∑łžóź ŪēĄžöĒŪēú ÍłįŽįėÍłįžą†žĚĄ žóįÍĶ¨Íįú Žįú, ž†Āžö©ŪēėŽäĒ žĚľžĚĄ ŪēėÍ≥† žěąžäĶŽčąŽč§. ‚Ķ žóÖŽ¨ī Ž≤ĒžúĄžóź ž†úŪēúžĚÄ žóÜžúľŽāė, žĶúÍ∑ľžóź žßĄŪĖČŪēėžėÄŽćė žóÖŽ¨īžĚė žėąŽäĒ Žč§ žĚĆÍ≥ľ ÍįôžäĶŽčąŽč§. ŽĻÖŽćįžĚīŪĄį Í∑úŽ™®žĚė Ž°úÍ∑ł ŽįŹ DB ŽćįžĚīŪĄį žąėžßĎ ÍįÄÍ≥Ķ, Ž∂ĄžĄĚ Ūôúžö© žčú žä§ŪÖú ÍįúŽįú Í≤ĆžěĄ ÍįúŽįú ŪĒĄŽ°úž†ĚŪäłžĚė Íłįžą† žä§ŪÉĚžóź ŽĆÄŪēú ÍīÄŽ¶¨ ŽįŹ Íłįžą†ž†Ā žĚėžā¨ Í≤įž†ē žįłžó¨ ÍįúŽįú žßÄžčĚžĚė ž†ēŽ¶¨, Ž≥īž°ī, Í≥Ķžú†
- 8. (žĪĄžö©Í≥ĶÍ≥† Žįúž∑Ć) ‚Ķ žįĹž°įÍłįžą†ŪĆ∂ńžóźžĄúŽäĒ žó¨Žü¨ Í≤ĆžěĄ ÍįúŽįú ŪĒĄŽ°úž†ĚŪ䳞󟞥ú Í≤™Í≥† žěąŽäĒ ‚Ķ Žč§žĖĎŪēú Ž¨łž†úŪēīÍ≤įžĚĄ žßĄŪĖČŪēėŽ©į Í∑łžóź ŪēĄžöĒŪēú ÍłįŽįėÍłįžą†žĚĄ žóįÍĶ¨Íįú Žįú, ž†Āžö©ŪēėŽäĒ žĚľžĚĄ ŪēėÍ≥† žěąžäĶŽčąŽč§. ‚Ķ žóÖŽ¨ī Ž≤ĒžúĄžóź ž†úŪēúžĚÄ žóÜžúľŽāė, žĶúÍ∑ľžóź žßĄŪĖČŪēėžėÄŽćė žóÖŽ¨īžĚė žėąŽäĒ Žč§ žĚĆÍ≥ľ ÍįôžäĶŽčąŽč§. ŽĻÖŽćįžĚīŪĄį Í∑úŽ™®žĚė Ž°úÍ∑ł ŽįŹ DB ŽćįžĚīŪĄį žąėžßĎ ÍįÄÍ≥Ķ, Ž∂ĄžĄĚ Ūôúžö© žčú žä§ŪÖú ÍįúŽįú Í≤ĆžěĄ ÍįúŽįú ŪĒĄŽ°úž†ĚŪäłžĚė Íłįžą† žä§ŪÉĚžóź ŽĆÄŪēú ÍīÄŽ¶¨ ŽįŹ Íłįžą†ž†Ā žĚėžā¨ Í≤įž†ē žįłžó¨ ÍįúŽįú žßÄžčĚžĚė ž†ēŽ¶¨, Ž≥īž°ī, Í≥Ķžú†
- 9. (žĪĄžö©Í≥ĶÍ≥† Žįúž∑Ć) ‚Ķ žįĹž°įÍłįžą†ŪĆ∂ńžóźžĄúŽäĒ žó¨Žü¨ Í≤ĆžěĄ ÍįúŽįú ŪĒĄŽ°úž†ĚŪ䳞󟞥ú Í≤™Í≥† žěąŽäĒ ‚Ķ Žč§žĖĎŪēú Ž¨łž†úŪēīÍ≤įžĚĄ žßĄŪĖČŪēėŽ©į Í∑łžóź ŪēĄžöĒŪēú ÍłįŽįėÍłįžą†žĚĄ žóįÍĶ¨Íįú Žįú, ž†Āžö©ŪēėŽäĒ žĚľžĚĄ ŪēėÍ≥† žěąžäĶŽčąŽč§. ‚Ķ žóÖŽ¨ī Ž≤ĒžúĄžóź ž†úŪēúžĚÄ žóÜžúľŽāė, žĶúÍ∑ľžóź žßĄŪĖČŪēėžėÄŽćė žóÖŽ¨īžĚė žėąŽäĒ Žč§ žĚĆÍ≥ľ ÍįôžäĶŽčąŽč§. ŽĻÖŽćįžĚīŪĄį Í∑úŽ™®žĚė Ž°úÍ∑ł ŽįŹ DB ŽćįžĚīŪĄį žąėžßĎ ÍįÄÍ≥Ķ, Ž∂ĄžĄĚ Ūôúžö© žčú žä§ŪÖú ÍįúŽįú Í≤ĆžěĄ ÍįúŽįú ŪĒĄŽ°úž†ĚŪäłžĚė Íłįžą† žä§ŪÉĚžóź ŽĆÄŪēú ÍīÄŽ¶¨ ŽįŹ Íłįžą†ž†Ā žĚėžā¨ Í≤įž†ē žįłžó¨ ÍįúŽįú žßÄžčĚžĚė ž†ēŽ¶¨, Ž≥īž°ī, Í≥Ķžú†
- 10. Ž™©žį®
- 11. Ž™©žį® 1. Í≥ĄÍłį
- 12. Ž™©žį® 1. Í≥ĄÍłį 2. (ŽįėŽ≥Ķ žčúžěĎ) žĖīŽĖ§ žÉĀŪô©žĚīžóąŽāėžöĒ?
- 13. Ž™©žį® 1. Í≥ĄÍłį 2. (ŽįėŽ≥Ķ žčúžěĎ) žĖīŽĖ§ žÉĀŪô©žĚīžóąŽāėžöĒ? 3. žĖīŽĖĽÍ≤Ć ŪĖąŽāėžöĒ? (ŽįėŽ≥Ķ ŽĀĚ)
- 14. Ž™©žį® 1. Í≥ĄÍłį 2. (ŽįėŽ≥Ķ žčúžěĎ) žĖīŽĖ§ žÉĀŪô©žĚīžóąŽāėžöĒ? 3. žĖīŽĖĽÍ≤Ć ŪĖąŽāėžöĒ? (ŽįėŽ≥Ķ ŽĀĚ) 4. žĚīÍ≤ÉžĚī ŽĮłŽěėžĄłÍ≥ĄŽč§
- 15. Ž™©žį® 1. Í≥ĄÍłį 2. (ŽįėŽ≥Ķ žčúžěĎ) žĖīŽĖ§ žÉĀŪô©žĚīžóąŽāėžöĒ? 3. žĖīŽĖĽÍ≤Ć ŪĖąŽāėžöĒ? (ŽįėŽ≥Ķ ŽĀĚ) 4. žĚīÍ≤ÉžĚī ŽĮłŽěėžĄłÍ≥ĄŽč§ 5. ŪöĆÍ≥†
- 16. Ž™©žį® 1. Í≥ĄÍłį 2. (ŽįėŽ≥Ķ žčúžěĎ) žĖīŽĖ§ žÉĀŪô©žĚīžóąŽāėžöĒ? 3. žĖīŽĖĽÍ≤Ć ŪĖąŽāėžöĒ? (ŽįėŽ≥Ķ ŽĀĚ) 4. žĚīÍ≤ÉžĚī ŽĮłŽěėžĄłÍ≥ĄŽč§ 5. ŪöĆÍ≥† žįłÍ≥†: Íłįžą† žĄłžÖėžĚīŽ©į, Í≤ĆžěĄžóź ŽĆÄŪēú ŽćįžĚīŪĄįŽāė ž†ēŽ≥īŽäĒ Žč§Ž£®žßÄ žēäžäĶŽčąŽč§.
- 17. Í≥ĄÍłį
- 18. ͳĎ°úŽ≤Ć ŽŹôžčú ŽüįžĻ≠ 2015ŽÖĄ 11žõĒ 5žĚľ! žā¨žč§ žÜĆŪĒĄŪ䳎üįžĻ≠žĚĄ ŪēėÍłī ŪĖąžßÄŽßĆ
- 19. ŪĚĒŪēú ŪĒĄŽ°úž†ĚŪäłžĚė žěĎžóÖ žöįžĄ†žąĶ”úĄ
- 20. ŪĚĒŪēú ŪĒĄŽ°úž†ĚŪäłžĚė žěĎžóÖ žöįžĄ†žąĶ”úĄ 1. žĽ®ŪÖźžł† ÍĶ¨ŪėĄ
- 21. ŪĚĒŪēú ŪĒĄŽ°úž†ĚŪäłžĚė žěĎžóÖ žöįžĄ†žąĶ”úĄ 1. žĽ®ŪÖźžł† ÍĶ¨ŪėĄ 2. Ž≤ĄÍ∑łŪĒĹžä§
- 22. ŪĚĒŪēú ŪĒĄŽ°úž†ĚŪäłžĚė žěĎžóÖ žöįžĄ†žąĶ”úĄ 1. žĽ®ŪÖźžł† ÍĶ¨ŪėĄ 2. Ž≤ĄÍ∑łŪĒĹžä§ 3. žĽ®ŪÖźžł† ÍĶ¨ŪėĄ
- 23. ŪĚĒŪēú ŪĒĄŽ°úž†ĚŪäłžĚė žěĎžóÖ žöįžĄ†žąĶ”úĄ 1. žĽ®ŪÖźžł† ÍĶ¨ŪėĄ 2. Ž≤ĄÍ∑łŪĒĹžä§ 3. žĽ®ŪÖźžł† ÍĶ¨ŪėĄ 4. žĽ®ŪÖźžł† ÍĶ¨ŪėĄ
- 24. ŪĚĒŪēú ŪĒĄŽ°úž†ĚŪäłžĚė žěĎžóÖ žöįžĄ†žąĶ”úĄ 1. žĽ®ŪÖźžł† ÍĶ¨ŪėĄ 2. Ž≤ĄÍ∑łŪĒĹžä§ 3. žĽ®ŪÖźžł† ÍĶ¨ŪėĄ 4. žĽ®ŪÖźžł† ÍĶ¨ŪėĄ 5. Ž≤ĄÍ∑łŪĒĹžä§
- 25. ŪĚĒŪēú ŪĒĄŽ°úž†ĚŪäłžĚė žěĎžóÖ žöįžĄ†žąĶ”úĄ 1. žĽ®ŪÖźžł† ÍĶ¨ŪėĄ 2. Ž≤ĄÍ∑łŪĒĹžä§ 3. žĽ®ŪÖźžł† ÍĶ¨ŪėĄ 4. žĽ®ŪÖźžł† ÍĶ¨ŪėĄ 5. Ž≤ĄÍ∑łŪĒĹžä§ 6. ‚Ķ‚Ķ.
- 26. ŪĚĒŪēú ŪĒĄŽ°úž†ĚŪäłžĚė žěĎžóÖ žöįžĄ†žąĶ”úĄ 1. žĽ®ŪÖźžł† ÍĶ¨ŪėĄ 2. Ž≤ĄÍ∑łŪĒĹžä§ 3. žĽ®ŪÖźžł† ÍĶ¨ŪėĄ 4. žĽ®ŪÖźžł† ÍĶ¨ŪėĄ 5. Ž≤ĄÍ∑łŪĒĹžä§ 6. ‚Ķ‚Ķ. 42. žā¨ŪõĄ Ž∂ĄžĄĚžĚĄ žúĄŪēú žĄ§Í≥Ą ŽįŹ ÍłįŽä• ÍĶ¨ŪėĄ
- 27. ž∂úžčú žĚīŪõĄžóĒ ŽćįžĚīŪĄįÍįÄ Ž≥īÍ≥† žč∂žĖīžßĄŽč§
- 28. ž∂úžčú žĚīŪõĄžóĒ ŽćįžĚīŪĄįÍįÄ Ž≥īÍ≥† žč∂žĖīžßĄŽč§ žú†ž†ÄŽď§žĚė žĽ®ŪÖźžł† žÜĆŽĻĄ žÜ掏Ą ŪĆĆžēÖ
- 29. ž∂úžčú žĚīŪõĄžóĒ ŽćįžĚīŪĄįÍįÄ Ž≥īÍ≥† žč∂žĖīžßĄŽč§ žú†ž†ÄŽď§žĚė žĽ®ŪÖźžł† žÜĆŽĻĄ žÜ掏Ą ŪĆĆžēÖ ÍįĀžĘÖ žĽ§žä§ŪÖÄ žßÄŪĎú
- 30. ž∂úžčú žĚīŪõĄžóĒ ŽćįžĚīŪĄįÍįÄ Ž≥īÍ≥† žč∂žĖīžßĄŽč§ žú†ž†ÄŽď§žĚė žĽ®ŪÖźžł† žÜĆŽĻĄ žÜ掏Ą ŪĆĆžēÖ ÍįĀžĘÖ žĽ§žä§ŪÖÄ žßÄŪĎú žĖīŽ∑įžßē ŽĆÄžĚĎ
- 31. ž∂úžčú žĚīŪõĄžóĒ ŽćįžĚīŪĄįÍįÄ Ž≥īÍ≥† žč∂žĖīžßĄŽč§ žú†ž†ÄŽď§žĚė žĽ®ŪÖźžł† žÜĆŽĻĄ žÜ掏Ą ŪĆĆžēÖ ÍįĀžĘÖ žĽ§žä§ŪÖÄ žßÄŪĎú žĖīŽ∑įžßē ŽĆÄžĚĎ "Data Exploration"
- 32. ž∂úžčú žĚīŪõĄžóĒ ŽćįžĚīŪĄįÍįÄ Ž≥īÍ≥† žč∂žĖīžßĄŽč§ žú†ž†ÄŽď§žĚė žĽ®ŪÖźžł† žÜĆŽĻĄ žÜ掏Ą ŪĆĆžēÖ ÍįĀžĘÖ žĽ§žä§ŪÖÄ žßÄŪĎú žĖīŽ∑įžßē ŽĆÄžĚĎ "Data Exploration" ŪēėžßÄŽßĆ ÍįúŽįúŪĆÄžĚÄ ŽčĻžóįŪěą Í∑łŽüī žó¨žú†ÍįÄ žóÜŽč§
- 33. žįĹž°įÍłįžą†ŪĆ∂ń ž∂úŽŹô ŽĄ§ Í∑łŽüľ ž†ÄŲ̄ÍįÄ Ž∂ĄžĄĚŪē† žąė žěąÍ≤Ć ŽŹĄžôÄŽďúŽ¶¨ž£†! ŽĮŅžĚĆžßĀ ŪĆÄ Ž°úÍ≥† ÍįĖÍ≥† žč∂žĖīžöĒ‚Ķ
- 34. žĖīŽĖ§ žÉĀŪô©žĚīžóąŽāėžöĒ? ž≤ę Ž≤ąžßł žčúŽŹĄžóź ŽĆÄŪēėžó¨
- 35. DB! DBŽ•ľ Ž≥īžěź! ž†ēŪėē ŽćįžĚīŪĄįŽ≤†žĚīžä§ ž†ēŪėē Ž°úÍ∑ł ‚Üí RDBMSžóź Í≥ĪÍ≤Ć Ž≥īÍīÄ ÍįĄŽč®Ūē† Í≤ÉžúľŽ°ú žėąžÉĀ žŅľŽ¶¨ Ž™á ÍįúŽßĆ žěė žßúŽ©ī ŽźėÍ≤†žßÄ
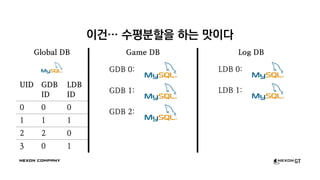
- 36. žĚīÍĪī‚Ķ žąėŪŹČŽ∂ĄŪē†žĚĄ ŪēėŽäĒ ŽßõžĚīŽč§ Global DB Game DB GDB 0: Log DB LDB 0:
- 37. žĚīÍĪī‚Ķ žąėŪŹČŽ∂ĄŪē†žĚĄ ŪēėŽäĒ ŽßõžĚīŽč§ Global DB UID GDB ID LDB ID 0 0 0 1 1 1 2 2 0 3 0 1 Game DB GDB 0: GDB 1: GDB 2: Log DB LDB 0: LDB 1:
- 38. žĖī Í∑łŽüľ ž°įžĚłžĚī žēąŽźėÍ≤†ŽĄ§?? N √ó M Video courtesy of Star Trek the Next Generation
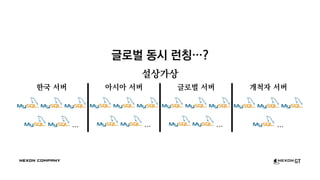
- 40. ͳĎ°úŽ≤Ć ŽŹôžčú ŽüįžĻ≠‚Ķ? žĄ§žÉĀÍįÄžÉĀ ŪēúÍĶ≠ žĄúŽ≤Ą ‚Ķ žēĄžčúžēĄ žĄúŽ≤Ą ‚Ķ ͳĎ°úŽ≤Ć žĄúŽ≤Ą ‚Ķ Íįúž≤ôžěź žĄúŽ≤Ą ‚Ķ
- 41. žĖīž©ĆŽ©ī žĘčžßĂĶ N √ó M √ó K Video courtesy of Star Trek the Next Generation
- 42. žĖīŽĖĽÍ≤Ć ŪĖąŽāėžöĒ? ž≤ę Ž≤ąžßł žčúŽŹĄ
- 43. One Instance to Rule Them All ŪēúÍĶ≠ žĄúŽ≤Ą ‚Ķ žēĄžčúžēĄ žĄúŽ≤Ą ‚Ķ ͳĎ°úŽ≤Ć žĄúŽ≤Ą ‚Ķ Íįúž≤ôžěź žĄúŽ≤Ą ‚Ķ MySQLŽď§žēĄ ŽāīÍ≤Ć ŪěėžĚĄ Ž™®žēĄž§ė ‚áď
- 44. One Instance to Rule Them All ŪēúÍĶ≠ žĄúŽ≤Ą ‚Ķ žēĄžčúžēĄ žĄúŽ≤Ą ‚Ķ ͳĎ°úŽ≤Ć žĄúŽ≤Ą ‚Ķ Íįúž≤ôžěź žĄúŽ≤Ą ‚Ķ MySQLŽď§žēĄ ŽāīÍ≤Ć ŪěėžĚĄ Ž™®žēĄž§ė ‚áď
- 45. ŽßěŽäĒ Žį©ŪĖ•žĚłžßÄ žĚėžč¨žä§ŽüĹŽč§ ÍįĞߥ ÍĪī full snapshot backupŽŅź EC2 Ūēú žĚłžä§ŪĄīžä§žóź mysqld_multiŽ°ú DB žĚłžä§ŪĄīžä§ 14Íįú žÉĚžĄĪ ž†úŽĆÄŽ°ú ÍįÄÍ≥† žěąŽäĒ ÍĪį ŽßěŽāė‚Ķ
- 46. ŽĀĚŽāėžßÄ žēäŽäĒ Ž≥Ķžõź žěĎžóÖ 14 √ó (žēēž∂ē Ūēīž†ú + Ž≥Ķžõź + Í≥†žú† ID Ž≥ÄÍ≤ĹžļźŽ¶≠ŪĄį, žě•ŽĻĄ ID + ŽāīŽ≥īŽāīÍłį + Ž∂ąŽü¨žė§Íłį)
- 47. Ž∂ĄžĄĚžĚÄ Ūē† žąė žěąÍłįŽäĒ ŪĖąŽč§ žĖīž®ĆŽď† žŅľŽ¶¨ŽäĒ Žā†Ž¶ī žąė žěąžúľŽčąÍĻƂĶ
- 48. žôú žěė žēąŽźźŽāėžöĒ? ž≤ę Ž≤ąžßł žčúŽŹĄžóź ŽĆÄŪēėžó¨
- 49. Ž≥ĶžõźŪēėŽäĒ Žćį Ž©įžĻ† ÍĪłŽ†łžĚĄÍĻĆžöĒ?
- 50. Ž≥ĶžõźŪēėŽäĒ Žćį Ž©įžĻ† ÍĪłŽ†łžĚĄÍĻĆžöĒ? ‚Čą 4žĚľ!
- 51. Ž≥ĶžõźŪēėŽäĒ Žćį Ž©įžĻ† ÍĪłŽ†łžĚĄÍĻĆžöĒ? ‚Čą 4žĚľ! Í∑łž†úžĄúžēľ ŽćįžĚīŪĄįŽ•ľ ž†Āžě¨ŪĖąžĚĄ ŽŅź, žēĄŽ¨īŽüį Ž∂ĄžĄĚŽŹĄ ŪēėžßÄ Ž™ĽŪēú žÉĀŪÉú žĚłŽćĪžä§ŽŹĄ Ž≥ĄŽ°ú žóÜŽäĒŽćį‚Ķ
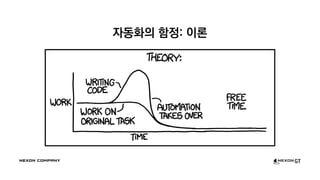
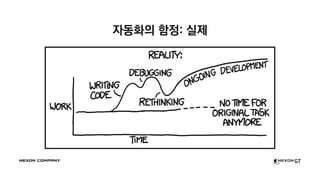
- 52. Ž≥ĶžõźŪēėŽäĒ Žćį Ž©įžĻ† ÍĪłŽ†łžĚĄÍĻĆžöĒ? ‚Čą 4žĚľ! Í∑łž†úžĄúžēľ ŽćįžĚīŪĄįŽ•ľ ž†Āžě¨ŪĖąžĚĄ ŽŅź, žēĄŽ¨īŽüį Ž∂ĄžĄĚŽŹĄ ŪēėžßÄ Ž™ĽŪēú žÉĀŪÉú žĚłŽćĪžä§ŽŹĄ Ž≥ĄŽ°ú žóÜŽäĒŽćį‚Ķ ž†ēŽ≥īžóźŽäĒ žú†ŪÜĶÍłįŪēúžĚī žěąŽč§ ŽüįžĻ≠ žßĀŪõĄžĚľžąėŽ°Ě ŽćĒŽćĒžöĪ ž§ĎžöĒ
- 53. ž†úÍįÄ žąėŽ•ľ žĄłŽäĒ Ž≤ē
- 54. ž†úÍįÄ žąėŽ•ľ žĄłŽäĒ Ž≤ē 0Íįú
- 55. ž†úÍįÄ žąėŽ•ľ žĄłŽäĒ Ž≤ē 0Íįú, 1Íįú
- 56. ž†úÍįÄ žąėŽ•ľ žĄłŽäĒ Ž≤ē 0Íįú, 1Íįú, 2Íįú
- 57. ž†úÍįÄ žąėŽ•ľ žĄłŽäĒ Ž≤ē 0Íįú, 1Íįú, 2Íįú, ŽßéŽč§„Öč„Ą≤„Öą„ÖĀ
- 58. ž†úÍįÄ žąėŽ•ľ žĄłŽäĒ Ž≤ē 0Íįú, 1Íįú, 2Íįú, ŽßéŽč§„Öč„Ą≤„Öą„ÖĀ žĚīÍĪī ŽĎź Ž≤ąŽŹĄ Ž™ĽŪēī žēąŽŹľ
- 59. ž†úÍįÄ žąėŽ•ľ žĄłŽäĒ Ž≤ē 0Íįú, 1Íįú, 2Íįú, ŽßéŽč§„Öč„Ą≤„Öą„ÖĀ žĚīÍĪī ŽĎź Ž≤ąŽŹĄ Ž™ĽŪēī žēąŽŹľ Ž©ėŪÉąžóźŽŹĄ Í∑ĻŽŹĄŽ°ú žēą žĘčžēėÍ≥†, žčúÍįĄŽŹĄ ŽßéžĚī žćľŽč§ žįĹž°įÍłįžą†ŪĆ∂ń Ž™®Ū܆: "žöįŽ¶¨žĚė Ž©ėŪÉąžĚÄ ŽĻĄžčľ žěźžõźžĚīŽč§"
- 60. ž†úÍįÄ žąėŽ•ľ žĄłŽäĒ Ž≤ē 0Íįú, 1Íįú, 2Íįú, ŽßéŽč§„Öč„Ą≤„Öą„ÖĀ žĚīÍĪī ŽĎź Ž≤ąŽŹĄ Ž™ĽŪēī žēąŽŹľ Ž©ėŪÉąžóźŽŹĄ Í∑ĻŽŹĄŽ°ú žēą žĘčžēėÍ≥†, žčúÍįĄŽŹĄ ŽßéžĚī žćľŽč§ žįĹž°įÍłįžą†ŪĆ∂ń Ž™®Ū܆: "žöįŽ¶¨žĚė Ž©ėŪÉąžĚÄ ŽĻĄžčľ žěźžõźžĚīŽč§" žĚīÍĪł žĚľŽ≥ĄŽ°ú ž¶ĚŽ∂Ąž†ĀžúľŽ°ú Ūē† žąė žěąžĚĄÍĻĆ? žĆďžĚīŽäĒ žÜ掏Ą? DB ŪĀ¨Íłį? žĚīŽĮł Íŧ žĽłžĚĆ
- 61. ž†úÍįÄ žąėŽ•ľ žĄłŽäĒ Ž≤ē 0Íįú, 1Íįú, 2Íįú, ŽßéŽč§„Öč„Ą≤„Öą„ÖĀ žĚīÍĪī ŽĎź Ž≤ąŽŹĄ Ž™ĽŪēī žēąŽŹľ Ž©ėŪÉąžóźŽŹĄ Í∑ĻŽŹĄŽ°ú žēą žĘčžēėÍ≥†, žčúÍįĄŽŹĄ ŽßéžĚī žćľŽč§ žįĹž°įÍłįžą†ŪĆ∂ń Ž™®Ū܆: "žöįŽ¶¨žĚė Ž©ėŪÉąžĚÄ ŽĻĄžčľ žěźžõźžĚīŽč§" žĚīÍĪł žĚľŽ≥ĄŽ°ú ž¶ĚŽ∂Ąž†ĀžúľŽ°ú Ūē† žąė žěąžĚĄÍĻĆ? žĆďžĚīŽäĒ žÜ掏Ą? DB ŪĀ¨Íłį? žĚīŽĮł Íŧ žĽłžĚĆ ÍłįÍĽŹ Ž∂ĄŪē†Ūēú ÍĪł Žč§žčú Ūē©žĻėŽč§Žčą?
- 62. ž†úÍįÄ žąėŽ•ľ žĄłŽäĒ Ž≤ē 0Íįú, 1Íįú, 2Íįú, ŽßéŽč§„Öč„Ą≤„Öą„ÖĀ žĚīÍĪī ŽĎź Ž≤ąŽŹĄ Ž™ĽŪēī žēąŽŹľ Ž©ėŪÉąžóźŽŹĄ Í∑ĻŽŹĄŽ°ú žēą žĘčžēėÍ≥†, žčúÍįĄŽŹĄ ŽßéžĚī žćľŽč§ žįĹž°įÍłįžą†ŪĆ∂ń Ž™®Ū܆: "žöįŽ¶¨žĚė Ž©ėŪÉąžĚÄ ŽĻĄžčľ žěźžõźžĚīŽč§" žĚīÍĪł žĚľŽ≥ĄŽ°ú ž¶ĚŽ∂Ąž†ĀžúľŽ°ú Ūē† žąė žěąžĚĄÍĻĆ? žĆďžĚīŽäĒ žÜ掏Ą? DB ŪĀ¨Íłį? žĚīŽĮł Íŧ žĽłžĚĆ ÍłįÍĽŹ Ž∂ĄŪē†Ūēú ÍĪł Žč§žčú Ūē©žĻėŽč§Žčą? ŽāėŽäĒ ŽąĄÍĶįÍįÄ žó¨Íłī Žėź žĖīŽĒėÍįÄ
- 63. žĚīŽ†áÍ≤Ć Žźú žĚīžÉĀ SparkŽ°ú ÍįĄŽč§ Žįįžöī Í≤Ć ŽŹĄŽĎĎžßąžě֎蹎č§
- 64. žĚīŽ†áÍ≤Ć Žźú žĚīžÉĀ SparkŽ°ú ÍįĄŽč§ Žįįžöī Í≤Ć ŽŹĄŽĎĎžßąžěÖŽčąŽč§ ŽąĄÍĶ¨Žāė žěźžč†žĚė Žä•Ž†•Í≥ľ Í≤ĹŪóėžĚĄ ŽįĒŪÉēžúľŽ°ú Ž¨łž†úŽ•ľ ŪíÄ ŽŅźžě֎蹎č§.
- 65. žĚīŽ†áÍ≤Ć Žźú žĚīžÉĀ SparkŽ°ú ÍįĄŽč§ Žįįžöī Í≤Ć ŽŹĄŽĎĎžßąžěÖŽčąŽč§ ŽąĄÍĶ¨Žāė žěźžč†žĚė Žä•Ž†•Í≥ľ Í≤ĹŪóėžĚĄ ŽįĒŪÉēžúľŽ°ú Ž¨łž†úŽ•ľ ŪíÄ ŽŅźžě֎蹎č§. ‚ÄĒ Ž•ėžõźŪēė
- 66. žĖīŽĖĽÍ≤Ć ŪĖąŽāėžöĒ? žĘĆž∂©žöįŽŹĆ Spark Ž∂ĄŪą¨Íłį
- 67. žĚľŽč® Žč§ ÍįÄž†łžôÄžĄú ž†Äžě•ŪēīŽ≥īžěź Spark ‚̧ Parquet
- 68. žė§Ž•īŽßČ ž£ľžĚė "ŽĻÖ ŽćįžĚīŪĄį" žÉĚŪÉúÍ≥Ą žĚīžēľÍłį‚Ķ
- 69. Apache Spark‚ĄĘ is a fast and general engine for large- scale data processing.
- 70. Apache Spark (cont.) žĽīŪď®ŪĆÖ ŪĒĄŽ†ąžěĄžõĆŪĀ¨: MRžĚė ŽĆÄž≤īžě¨? Scala/JVM ÍłįŽįė PySparkŽŹĄ žěąžĚĆ ŪēĶžč¨ ÍįúŽÖź: "Resilient Distributed Datasets" (RDD) In-memory, DAG-based computing val lines = sc.textFile("data.txt") val lineLengths = lines.map(s => s.length) val totalLength = lineLengths.reduce((a, b) => a + b)
- 71. Spark SQL Pig Latin, HiveQLž≤ėŽüľ ÍĶ¨ž°įŪôĒŽźú ŽćįžĚīŪĄįŽ•ľ Ū鳎¶¨ŪēėÍ≤Ć Žč§Ž£®Íłį DataFrameRow ÍłįŽįė ŽüįŪÉÄžěĄ ž°įžěĎ & Dataset1.6žóź Žāėžė® žÉą API; Strongly typed ÍįēŽ†•Ūēú žŅľŽ¶¨ žóĒžßĄ: Catalyst + Plan žĶúž†ĀŪôĒ žóĒžßĄ Predicate pushdown, Bytecode compilation ŽďĪ val df = context.read.format("json").load("s3n://...") df.registerTempTable("people") val names = context.sql("SELECT name FROM people WHERE age >= 42") val names = df.where("age >= 42").select("name") // this works too names.write.format("parquet").save("s3n://.../names.parquet")
- 72. ORCžôÄ žú†žā¨Ūēú žóī Žč®žúĄŽ°ú ž†Äžě•ŪēėŽäĒ ŪĆƞ̾ Í∑úÍ≤© Žč®žąúŪēú ŪÉÄžěÖ Ž™á ÍįúžôÄ blob, Í∑łŽ¶¨Í≥† ž§Ďž≤© ÍĶ¨ž°į žĚłžĹĒŽĒ©Í≥ľ žēēž∂ē žßÄžõź Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.
- 73. Spark + Parquet Ž™®Žď† Ž°úÍ∑łŽ•ľ ÍįÄž†łŽč§ÍįÄ ParquetžúľŽ°ú ž†Äžě• žßĀž†Ď ÍĶ¨ŪėĄŪĖąžúľŽāė Apache SqoopŽŹĄ žěąžäĶŽčąŽč§ žĚłŽćĪžčĪ X, žēēž∂ē O ‚Üí Í∑łŽü≠ž†ÄŽü≠ žěĎžēĄžßĄ žö©ŽüČ ŽćįžĚīŪĄįÍįÄ žěĎžúľŽčą Ž°úžĽ¨ ŪĆƞ̾žčúžä§ŪÖúžóź ž†Äžě•Ūē©žčúŽč§ S3/EMRFSŽäĒ žĚľŽč® Ž≥īŽ•ė Hive žä§ŪÉĞ̾ ŪĆĆŪčįžÖĒŽčĚ: user_part=42/time_ym=201604/time_d=26/*.parquet ž†ĀŽčĻŪēú ŽćįžĚīŪĄį Ž¶¨ŪÖźžÖė ž†ēžĪÖ // Sample DataFrame schema root |-- idx: long (nullable = true) |-- reg_date: timestamp (nullable = true) |-- user_idx: long (nullable = true) |-- action_type: integer (nullable = true) ...
- 74. Í∑ł ŪĆƞ̾žĚī ÍįúŽįúžěźÍįÄ Ž≥īÍłįžóź žĘčžēėŽÖłŽĚľ spark-shell: Spark-powered Scala REPL Shell scala> val df = sqlContext.read.parquet(".../log_pvp/gl") df: org.apache.spark.sql.DataFrame = [lord_idx: bigint, ...] scala> df.registerTempTable("pvp") scala> val win_df = sqlContext.sql( "SELECT lord_idx, SUM(is_win) AS win_count FROM pvp WHERE time_ym = 201604 AND time_d = 26 AND is_win = 1 GROUP BY lord_idx") win_df: org.apache.spark.sql.DataFrame = [lord_idx: bigint, win_count: bigint] scala> win_df.sort($"win_count".desc).limit(10).collect() res1: Array[org.apache.spark.sql.Row] = Array([12345, 42], [23456, 41], ...)
- 75. Í∑łŽüįŽćį, žôú žěė žēąŽźźŽāėžöĒ?
- 76. Ž∂ĄžĄĚ Ž≥ĎŽ™©: ŽćįžĚīŪĄį žóĒžßÄŽčąžĖī Spark SQL ‚Ȇ SQL žčúžä§ŪÖúžóź ŽĆÄŪēú žĚīŪēī žóÜžĚī ž†ĎÍ∑ľ Ž∂ąÍįÄŽä•Ūēú žěźŽ£ĆŽď§ ŽćįžĚīŪĄį žóĒžßÄŽčąžĖīÍįÄž†ĎŽčąŽč§ Í∑łŽēĆÍ∑łŽēĆ žöĒÍĶ¨žā¨Ūē≠žóź Žßěž∂į ŽćįžĚīŪĄįŽ•ľ ŽįõžēĄ ŽāīŽ†§ž£ľŽäĒ ŪĚźŽ¶Ą
- 77. žĚīžÉĀ: Data Exploration ŽćįžĚīŪĄįŽ•ľ ŽįĒŪÉēžúľŽ°ú žĚīÍ≤Éž†ÄÍ≤É Ží§ž†Āžó¨ Žīźžēľ ž†ēŽ≥īžôÄ žßĀÍīĞ̥ žĖĽŽäĒŽč§ ÍįúŽįúžěźŽäĒ žčúžä§ŪÖú ÍĶ¨ž∂ēŪēīž£ľÍłįŽŹĄ ŽįĒžĀėŽĮÄŽ°ú, ŪÉźžÉČžĚÄ ž†ĄŽ¨łÍįÄÍįÄ Ūēīžēľ ŪēúŽč§ ŪēĄžöĒŪēú Žāīžö©žĚī Í≥†ž†ēŽźėŽ©īžä§ŪéôžĚī Žāėžė§Ž©ī ž†ēŽ°ÄŪôĒŽ•ľ žúĄŪēú Ž°úžßĀžĚÄ žóĒžßÄŽčąžĖīÍįÄ žßúŽ©ī ŽźúŽč§ Žā†Í≤ÉžĚė ŽćįžĚīŪĄįŽäĒ žóĎžÖÄÍįĀžĚÄ žēĄŽčąŽĚľ žĖīž©Ē žąė žóÜŽč§ žóĎžÖÄ, žĖīŽĒĒÍĻĆžßÄ ÍįÄ Žī§Žčą?
- 78. žěźŽŹôŪôĒ! žěźŽŹôŪôĒÍįÄ ŪēĄžöĒŪēėŽč§! žčúžä§ŪÖú žóĒžßÄŽčąžĖīžĚė žĶúžĘÖ Ž™©ŪĎú: žčúžä§ŪÖúžóźžĄú 'Žāė'Ž•ľ ž†úÍĪįŪēėÍłį‚Ķ?
- 80. žĚľŽ≥Ą ŽįįžĻė žěĎžóÖ žôĄž†Ą Žā†Í≤ÉžĚė ŽćįžĚīŪĄįŽäĒ ŪÉźžÉČ/Ž∂ĄžĄĚ Ž∂ąÍįÄ, žěĄžĚėžĚė aggregation Ž°úÍ∑łŽ•ľ ÍłĀžĖī žė§ŽďĮ, Žß§žĚľ ŽįįžĻė žěĎžóÖ žč§žčúÍįĄÍĻĆžßÄŽäĒ žĚľŽč® Ž¨īŽ¶¨ žĚľŽč® Í∑ł Í≤įÍ≥ľŽŹĄ ŽėĎÍįôžĚī Parquet-ify žĶúÍ∑ľ NžĚľÍįĄžĚė ŽćįžĚīŪĄįŽäĒ RDBMSŽĄĶMySQL žóź ž†Āžě¨ ÍįúŽ≥Ą žěĎžóÖžĚÄ ScalaŽ°ú, žěĎžóÖ ÍīÄŽ¶¨žěźŽäĒ RubyŽ°ú ÍĶ¨ŪėĄ Spark Ž¶¨žÜĆžä§ ÍīÄŽ¶¨ Ž¨łž†ú
- 81. BI: Business Intelligence žēĹžĚÄ žēĹžā¨žóźÍ≤Ć Ž∂ĄžĄĚžĚÄ Ž∂ĄžĄĚÍįÄžóźÍ≤Ć
- 82. žĘčžĚÄ ŽŹĄÍĶ¨, žĘčžĚÄ Í≤įÍ≥ľŽ¨ľ JupyterÍįôžĚÄ ÍĪł ž•źžĖīž£ľÍłįžóĒ ŽĄąŽ¨ī žĖīŽ†ĶŽč§, BI ŽŹĄÍĶ¨Žď§ ÍįÄžöīŽćįžĄú ŪěėžĄłÍ≥† ÍįēŪēú ŽŹĄÍĶ¨!Ž•ľ žįĺžěź Tableau Qlik SAP ‚Ķ SAS ‚Ķ Oracle ‚Ķ IBM ‚Ķ Microsoft ‚Ķ
- 83. žĘčžĚÄ ŽŹĄÍĶ¨, žĘčžĚÄ Í≤įÍ≥ľŽ¨ľ JupyterÍįôžĚÄ ÍĪł ž•źžĖīž£ľÍłįžóĒ ŽĄąŽ¨ī žĖīŽ†ĶŽč§, BI ŽŹĄÍĶ¨Žď§ ÍįÄžöīŽćįžĄú ŪěėžĄłÍ≥† ÍįēŪēú ŽŹĄÍĶ¨!Ž•ľ žįĺžěź Tableau Qlik SAP ‚Ķ SAS ‚Ķ Oracle ‚Ķ IBM ‚Ķ Microsoft ‚Ķ
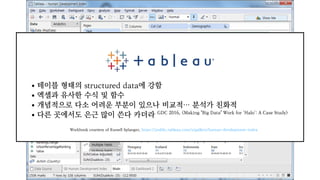
- 85. ŪÖĆžĚīŽłĒ ŪėēŪÉúžĚė structured datažóź ÍįēŪē® žóĎžÖÄÍ≥ľ žú†žā¨Ūēú žąėžčĚ ŽįŹ Ūē®žąė ÍįúŽÖźž†ĀžúľŽ°ú Žč§žÜĆ žĖīŽ†§žöī Ž∂ÄŽ∂ĄžĚī žěąžúľŽāė ŽĻĄÍĶźž†Ā‚Ķ Ž∂ĄžĄĚÍįÄ žĻúŪôĒž†Ā Žč§Ž•ł Í≥≥žóźžĄúŽŹĄ žĚÄÍ∑ľ ŽßéžĚī žďīŽč§ žĻīŽćĒŽĚľ GDC 2016, <Making "Big Data" Work for 'Halo': A Case Study> Workbook courtesy of Russell Splanger, https://public.tableau.com/s/gallery/human-development-index
- 87. TableauŽ°ú ŽćįžĚīŪĄį Ž∂ąŽü¨Žď§žĚīÍłį Spark SQL Connector: Ž≤Ąž†Ą Ž¨łž†úŽ°ú žč§ŪĆ®
- 88. TableauŽ°ú ŽćįžĚīŪĄį Ž∂ąŽü¨Žď§žĚīÍłį Spark SQL Connector: Ž≤Ąž†Ą Ž¨łž†úŽ°ú žč§ŪĆ® Hive: žĖłž††ÍįÄ Ūēīžēľ ŪēėžßÄŽßĆ žßÄÍłą žĄłŪĆÖŪēėÍ≥† žč∂žßÄŽäĒ žēäžĚĆžĚīŽĮł ŽĄąŽ¨ī ŽįÄŽ†łžĖī
- 89. TableauŽ°ú ŽćįžĚīŪĄį Ž∂ąŽü¨Žď§žĚīÍłį Spark SQL Connector: Ž≤Ąž†Ą Ž¨łž†úŽ°ú žč§ŪĆ® Hive: žĖłž††ÍįÄ Ūēīžēľ ŪēėžßÄŽßĆ žßÄÍłą žĄłŪĆÖŪēėÍ≥† žč∂žßÄŽäĒ žēäžĚĆžĚīŽĮł ŽĄąŽ¨ī ŽįÄŽ†łžĖī Í∑łŽÉ• RDBMSŽĄĶMySQL žóź žŹüžēĄŽĄ£žěź‚Ķ TableauŽĚľÍ≥† žąė GB Žč®žúĄŽ°ú ŽćįžĚīŪĄįŽ•ľ žČĹÍ≤Ć ŽāīŽ†§ŽįõžĚĄ žąė žěąŽäĒ ÍĪī žēĄŽčė
- 90. TableauŽ°ú ŽćįžĚīŪĄį Ž∂ąŽü¨Žď§žĚīÍłį Spark SQL Connector: Ž≤Ąž†Ą Ž¨łž†úŽ°ú žč§ŪĆ® Hive: žĖłž††ÍįÄ Ūēīžēľ ŪēėžßÄŽßĆ žßÄÍłą žĄłŪĆÖŪēėÍ≥† žč∂žßÄŽäĒ žēäžĚĆžĚīŽĮł ŽĄąŽ¨ī ŽįÄŽ†łžĖī Í∑łŽÉ• RDBMSŽĄĶMySQL žóź žŹüžēĄŽĄ£žěź‚Ķ TableauŽĚľÍ≥† žąė GB Žč®žúĄŽ°ú ŽćįžĚīŪĄįŽ•ľ žČĹÍ≤Ć ŽāīŽ†§ŽįõžĚĄ žąė žěąŽäĒ ÍĪī žēĄŽčė ŪēėŽäĒ ÍĻÄžóź Í≤ĆžěĄDB ž†ēŽ≥īŽŹĄ žĚľž†ē ž£ľÍłįŽ°ú Ž≥Ķž†ú
- 91. TableauŽ°ú ŽćįžĚīŪĄį Ž∂ąŽü¨Žď§žĚīÍłį Spark SQL Connector: Ž≤Ąž†Ą Ž¨łž†úŽ°ú žč§ŪĆ® Hive: žĖłž††ÍįÄ Ūēīžēľ ŪēėžßÄŽßĆ žßÄÍłą žĄłŪĆÖŪēėÍ≥† žč∂žßÄŽäĒ žēäžĚĆžĚīŽĮł ŽĄąŽ¨ī ŽįÄŽ†łžĖī Í∑łŽÉ• RDBMSŽĄĶMySQL žóź žŹüžēĄŽĄ£žěź‚Ķ TableauŽĚľÍ≥† žąė GB Žč®žúĄŽ°ú ŽćįžĚīŪĄįŽ•ľ žČĹÍ≤Ć ŽāīŽ†§ŽįõžĚĄ žąė žěąŽäĒ ÍĪī žēĄŽčė ŪēėŽäĒ ÍĻÄžóź Í≤ĆžěĄDB ž†ēŽ≥īŽŹĄ žĚľž†ē ž£ľÍłįŽ°ú Ž≥Ķž†ú Í≤ĆžěĄDB + Ž°úÍ∑ł + žĚľŽ≥Ą ŽįįžĻė žěĎžóÖ Í≤įÍ≥ľ ‚Üí RDBMS ‚Üí Tableau ÍĻĆžßÄ ETL ŪĆĆžĚīŪĒĄŽĚľžĚł Extract Transform Load
- 92. žßÄÍłąÍĻĆžßÄ ŪĖąŽćė žĚľŽď§ ž†ēŽ¶¨
- 93. žßÄÍłąÍĻĆžßÄ ŪĖąŽćė žĚľŽď§ ž†ēŽ¶¨ žĶúžīąžóź žāĹžßąŽŹĄ žĘÄ žěąžóąžßÄŽßĆ,
- 94. žßÄÍłąÍĻĆžßÄ ŪĖąŽćė žĚľŽď§ ž†ēŽ¶¨ žĶúžīąžóź žāĹžßąŽŹĄ žĘÄ žěąžóąžßÄŽßĆ, MySQLžóź žĆďžĚÄ ž†ēŪėē Ž°úÍ∑łŽ•ľ ŽįĒŪÉēžúľŽ°ú
- 95. žßÄÍłąÍĻĆžßÄ ŪĖąŽćė žĚľŽď§ ž†ēŽ¶¨ žĶúžīąžóź žāĹžßąŽŹĄ žĘÄ žěąžóąžßÄŽßĆ, MySQLžóź žĆďžĚÄ ž†ēŪėē Ž°úÍ∑łŽ•ľ ŽįĒŪÉēžúľŽ°ú ž£ľÍłįž†ĀžúľŽ°ú ŪēīŽčĻ Ž°úÍ∑łŽ•ľ ÍįÄž†łÍįÄ ŪĆƞ̾ ŪŹ¨Žß∑žĚĄ Ž≥ÄŪôėŪēī ž†Äžě•ŪēėÍ≥†
- 96. žßÄÍłąÍĻĆžßÄ ŪĖąŽćė žĚľŽď§ ž†ēŽ¶¨ žĶúžīąžóź žāĹžßąŽŹĄ žĘÄ žěąžóąžßÄŽßĆ, MySQLžóź žĆďžĚÄ ž†ēŪėē Ž°úÍ∑łŽ•ľ ŽįĒŪÉēžúľŽ°ú ž£ľÍłįž†ĀžúľŽ°ú ŪēīŽčĻ Ž°úÍ∑łŽ•ľ ÍįÄž†łÍįÄ ŪĆƞ̾ ŪŹ¨Žß∑žĚĄ Ž≥ÄŪôėŪēī ž†Äžě•ŪēėÍ≥† žĚľŽ≥ĄŽ°ú ŽįįžĻė žěĎžó̥֞ ŽŹĆŽ†§ Í∑ł Í≤įÍ≥ľŽ•ľ ÍįÄžßÄÍ≥†
- 97. žßÄÍłąÍĻĆžßÄ ŪĖąŽćė žĚľŽď§ ž†ēŽ¶¨ žĶúžīąžóź žāĹžßąŽŹĄ žĘÄ žěąžóąžßÄŽßĆ, MySQLžóź žĆďžĚÄ ž†ēŪėē Ž°úÍ∑łŽ•ľ ŽįĒŪÉēžúľŽ°ú ž£ľÍłįž†ĀžúľŽ°ú ŪēīŽčĻ Ž°úÍ∑łŽ•ľ ÍįÄž†łÍįÄ ŪĆƞ̾ ŪŹ¨Žß∑žĚĄ Ž≥ÄŪôėŪēī ž†Äžě•ŪēėÍ≥† žĚľŽ≥ĄŽ°ú ŽįįžĻė žěĎžó̥֞ ŽŹĆŽ†§ Í∑ł Í≤įÍ≥ľŽ•ľ ÍįÄžßÄÍ≥† ž†ĄŽ¨ł ŽćįžĚīŪĄį Ž∂ĄžĄĚ ŽŹĄÍĶ¨Ž•ľ Ž∂ôžó¨ ŽćįžĚīŪĄįŽ•ľ ŪÉźžÉČŪēėÍ≥† žßĀÍīĞ̥ ŽįúÍ≤¨ŪĖąŽč§
- 100. ž§ĎÍįĄ Í≤įŽ°† žôĄŽ≤ĹŪēú žÜĒŽ£®žÖėžĚĄ ÍĶ¨ž∂ēŪēú Í≤ÉžĚÄ žēĄŽčąžßÄŽßĆ, žĶúžÜĆŪēúžĚė ŽÖłŽ†•žúľŽ°ú žĶúŽĆÄŪēúžĚė Í≤įÍ≥ľŽ•ľ ŽāīŽ†§ ŽÖłŽ†• Comics courtesy of XKCD, https://xkcd.com/1319/
- 101. žēĄŽ¨īŪäľ Í∑łŽď§žĚÄ žė§Žěėžė§Žěė ŪĖČŽ≥Ķ«ÍėÍ≤Ć
- 102. žēĄŽ¨īŪäľ Í∑łŽď§žĚÄ žė§Žěėžė§Žěė ŪĖČŽ≥Ķ«ÍėÍ≤Ć žĚľŪĖąžúľŽ©ī žĘčžēėžĚĄŪÖźŽćį
- 103. žēěžúľŽ°úŽäĒ?
- 104. žēěžúľŽ°úŽäĒ? Žāī ŽćįžĚīŪĄįÍįÄ žĚīŽ†áÍ≤Ć Í∑Äžó¨žöł Ž¶¨ žóÜžĖī
- 105. žēěžúľŽ°úŽäĒ? Žāī ŽćįžĚīŪĄįÍįÄ žĚīŽ†áÍ≤Ć Í∑Äžó¨žöł Ž¶¨ žóÜžĖī ŽćĒ ŪĀį žĄúŽĻĄžä§Ž•ľ Žßąž£ľŪēėÍ≤Ć ŽźúŽč§Ž©ī?
- 106. žēěžúľŽ°úŽäĒ? Žāī ŽćįžĚīŪĄįÍįÄ žĚīŽ†áÍ≤Ć Í∑Äžó¨žöł Ž¶¨ žóÜžĖī ŽćĒ ŪĀį žĄúŽĻĄžä§Ž•ľ Žßąž£ľŪēėÍ≤Ć ŽźúŽč§Ž©ī? Í∑łŽěėžĄú žĘÄ ŽćĒ ž†úŽĆÄŽ°ú žčúžä§ŪÖúžĚĄ ÍĶ¨ž∂ēŪēīžēľ ŪēúŽč§Ž©ī?
- 107. žēěžúľŽ°úŽäĒ? Žāī ŽćįžĚīŪĄįÍįÄ žĚīŽ†áÍ≤Ć Í∑Äžó¨žöł Ž¶¨ žóÜžĖī ŽćĒ ŪĀį žĄúŽĻĄžä§Ž•ľ Žßąž£ľŪēėÍ≤Ć ŽźúŽč§Ž©ī? Í∑łŽěėžĄú žĘÄ ŽćĒ ž†úŽĆÄŽ°ú žčúžä§ŪÖúžĚĄ ÍĶ¨ž∂ēŪēīžēľ ŪēúŽč§Ž©ī? žĶúžīą Ž∂ĄžĄĚžĚĄ ŽĻ®Ž¶¨ žßĄŪĖČŪēīžĄú ŽćĒ ŽāėžĚÄ žē°žÖėžĚĄ ž∑®Ūē† žąė žěąžóąŽč§Ž©ī?
- 108. Ž≥łÍ≤© ŽĻÖŽćįžĚīŪĄį žēĄŪā§ŪÖćž≤ė žĄ§Í≥ĄžēąžěÖžĹĒŽĒ© Image courtesy of Camelia.boban, under CC BY-SA 3.0https://commons.wikimedia.org/wiki/File:BigData_2267x1146_white.png
- 110. ŽěúŽć§Ūēú žĄ§Í≥Ą žēĄžĚīŽĒĒžĖīŽď§ ž†ēŪėē Ž°úÍ∑ł = ‚̧, ŽĻĄž†ēŪėē Ž°úÍ∑ł = žčúÍ≥Ąžóī ÍĶ¨ÍįĄŽŹĄ ŪēĄžöĒ žčúžěĎÍ≥ľ ŽĀĚ žĄłžÖė, žĚłŽćė ŪĒĆŽ†ąžĚī, ‚Ķ Í≤ĆžěĄ žĄúŽ≤ĄŽ°úžĄúžĚė žĄúŽĻĄžä§žôÄ Í≤ĆžěĄ žĄúŽ≤ĄŽ°úžĄúžĚė žĄúŽĻĄžä§ žßĀŽ†¨ŪôĒ Žį©žčĚžóź ŽĆÄŪēú Í≥†ŽĮľ JSONžĚė ŪÉÄžěÖžĚÄ ŽāėžĀėžßÄŽßĆ Ž™Ľ žďł ž†ēŽŹĄŽäĒ žēĄŽčĆŽćį‚Ķ?
- 111. žĘčžĚÄ Ž°úÍĻÖ ŽĚľžĚīŽłĆŽü¨Ž¶¨ÍįÄ ŪēĄžöĒŪēėžßÄ žēäžĚĄÍĻĆ žēĄž£ľ Ž≥Ķžě°Ūē† ŪēĄžöĒŽäĒ žóÜžßÄŽßĆ, žú†Ūėēžóź ŽĒįŽĚľ: ž†ēŪėē, Žįėž†ēŪėē, ŽĻĄž†ēŪėē žöįžĄ†žąĶ”úĄžóź ŽĒįŽĚľ: Guaranteed, Best-effort ÍłįŽä•žóź ŽĒįŽĚľ: ŪĀīŽĚľžĚīžĖłŪäł, žĄúŽ≤Ą, ‚Ķ žßĀŽ†¨ŪôĒ Í∑úÍ≤©žóź ŽĒįŽĚľ: Text/JSON, msgpack, ‚Ķ // structured ServerLogger.logAction(ctx, [&](auto x){ return x.userId(...).action(...); }); // semi-structured ServerLogger.logs(ctx, "action", [&](auto x){ return x.field("userId", ...).field("action", ...); }); // unstructured ServerLogger.logf(ctx, "user %d trying to do %s", ...);
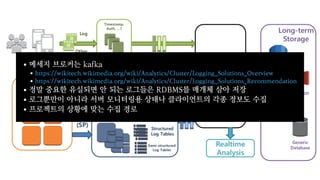
- 118. Ž©ĒžĄłžßÄ ŽłĆŽ°úžĽ§ŽäĒ kafka ž†ēŽßź ž§ĎžöĒŪēú žú†žč§ŽźėŽ©ī žēą ŽźėŽäĒ Ž°úÍ∑łŽď§žĚÄ RDBMSŽ•ľ Žß§Íįúž≤ī žāľžēĄ ž†Äžě• Ž°úÍ∑łŽŅźŽßĆžĚī žēĄŽčąŽĚľ žĄúŽ≤Ą Ž™®ŽčąŪĄįŽßĀžö© žÉĀŪÉúŽāė ŪĀīŽĚľžĚīžĖłŪäłžĚė ÍįĀžĘÖ ž†ēŽ≥īŽŹĄ žąėžßĎ ŪĒĄŽ°úž†ĚŪäłžĚė žÉĀŪô©žóź ŽßěŽäĒ žąėžßĎ Í≤ĹŽ°ú https://wikitech.wikimedia.org/wiki/Analytics/Cluster/Logging_Solutions_Overview https://wikitech.wikimedia.org/wiki/Analytics/Cluster/Logging_Solutions_Recommendation
- 121. žôú ž∂Ēž≤úŪēėŽāėžöĒ? ŪÖćžä§Ūäł Ž°úÍ∑łžĚė ŪéłžĚėžĄĪ Ž™®Žď† Ž°úÍ∑łŽ•ľ ParquetžúľŽ°ú ž†Äžě•Ūē† ŪēĄžöĒÍĻĆžßÄŽäĒ žóÜŽćĒŽĚľ Snappy Framing Format HadoopžóźžĄú žā¨žö© ÍįÄŽä•Ūēú Ž∂Ąžāį ž≤ėŽ¶¨ ÍįÄŽä• žēēž∂ē ŪŹ¨Žß∑ (Žč®ž†ź: žßĀž†Ď ÍĶ¨ŪėĄŪēīžēľ‚Ķ) LZOŽäĒ GPL, bz2ŽäĒ ÍĶ¨Ž¶ľ ŪĒĄŽ°úž†ĚŪäłžóź ŽßěŽäĒ ž°įž†ēžĚī ŪēĄžöĒ Ž°úÍ∑ł žú†ŪėēžĚī Žč§žĖĎŪēú RPGŽĚľŽ©ī Ž°úÍ∑ł ŪÉÄžěÖžąúžúľŽ°ú ž†ēŽ†¨ŪēėÍłįŽ≥īŽč§ŽäĒ UIDŽ°ú ÍĻĆžßďÍĪį ŽĎė Žč§ ŪēėŽ©ī ŽźėžßÄžö©ŽüČžĚī ŽĎź ŽįįžĚľ ŽŅź žč§žčúÍįĄ ž†Āžě¨ŽŹĄ ŪĒĄŽ°úž†ĚŪäłžóź ŽĒįŽĚľ žēĄŽ¨īŪäľ ž†Ąž≤īž†ĀžúľŽ°ú žôĄžĄĪŽŹĄ ŽÜížĚÄ ŽĒĒžěźžĚł!
- 123. Ž∂ĄžĄĚÍįÄ-žóĒžßÄŽčąžĖī ŪĒľŽďúŽįĪ Ž£®ŪĒĄÍįÄ ž§ĎžöĒ ŽĆÄž≤īŽ°ú Ž∂ĄžĄĚÍįÄŽäĒ žĹĒŽďúŽ•ľ žďł žąė žóÜÍ≥†, žóĒžßÄŽčąžĖīŽäĒ Ž∂ĄžĄĚžĚī ŪēėÍłį žčęžĚĆ Ž∂ĄžĄĚÍįÄŽäĒ Í≥ĄžÜć ŽćįžĚīŪĄįžĚė ŽŹôŪĖ•žĚĄ ŪĆĆžēÖŪēīžēľ Ūē® MLžĚė ŪēúÍ≥Ą: ŽćįžĚīŪĄįžÖčžĚė ŪäĻžĄĪžĚī ŽįĒŽÄĆŽ©ī Ž™®ŽćłžĚī ŽįĒŽÄĆžĖīžēľ Ž∂ĄžĄĚÍįÄžĚė žöĒÍĶ¨žā¨Ūē≠žĚÄ Í≥ĄžÜć ŽįĒŽÄĆÍ≥† žěźÍłįŽŹĄ žěė Ž™®Ž¶Ą Ž∂ĄžĄĚÍįÄžóźÍ≤Ć žĶúŽĆÄŪēúžĚė žěźžú†ŽŹĄŽ•ľ ž£ľŽäĒ Žį©Ž≤ēžĚĄ ž∂ĒÍĶ¨ŪēėÍ≥†ŪĒĒ ‚ĶÍ≤įÍĶ≠ ŽćįžĚīŪĄįžÖčžĚĄ Í∑łŽĆÄŽ°ú ž£ľŽäĒ ŪéłžĚī ŽāęžßÄ žēäŽāė?
- 124. Ž∂ĄžĄĚÍįÄ-žóĒžßÄŽčąžĖī ŪĒľŽďúŽįĪ Ž£®ŪĒĄÍįÄ ž§ĎžöĒ ŽĆÄž≤īŽ°ú Ž∂ĄžĄĚÍįÄŽäĒ žĹĒŽďúŽ•ľ žďł žąė žóÜÍ≥†, žóĒžßÄŽčąžĖīŽäĒ Ž∂ĄžĄĚžĚī ŪēėÍłį žčęžĚĆ Ž∂ĄžĄĚÍįÄŽäĒ Í≥ĄžÜć ŽćįžĚīŪĄįžĚė ŽŹôŪĖ•žĚĄ ŪĆĆžēÖŪēīžēľ Ūē® MLžĚė ŪēúÍ≥Ą: ŽćįžĚīŪĄįžÖčžĚė ŪäĻžĄĪžĚī ŽįĒŽÄĆŽ©ī Ž™®ŽćłžĚī ŽįĒŽÄĆžĖīžēľ Ž∂ĄžĄĚÍįÄžĚė žöĒÍĶ¨žā¨Ūē≠žĚÄ Í≥ĄžÜć ŽįĒŽÄĆÍ≥† žěźÍłįŽŹĄ žěė Ž™®Ž¶Ą Ž∂ĄžĄĚÍįÄžóźÍ≤Ć žĶúŽĆÄŪēúžĚė žěźžú†ŽŹĄŽ•ľ ž£ľŽäĒ Žį©Ž≤ēžĚĄ ž∂ĒÍĶ¨ŪēėÍ≥†ŪĒĒ ‚ĶÍ≤įÍĶ≠ ŽćįžĚīŪĄįžÖčžĚĄ Í∑łŽĆÄŽ°ú ž£ľŽäĒ ŪéłžĚī ŽāęžßÄ žēäŽāė? žēĹžĚÄ žēĹžā¨žóźÍ≤Ć, Ž∂ĄžĄĚžĚÄ Ž∂ĄžĄĚÍįÄžóźÍ≤Ć
- 125. Ž∂ĄžĄĚÍįÄ-žóĒžßÄŽčąžĖī ŪĒľŽďúŽįĪ Ž£®ŪĒĄÍįÄ ž§ĎžöĒ ŽĆÄž≤īŽ°ú Ž∂ĄžĄĚÍįÄŽäĒ žĹĒŽďúŽ•ľ žďł žąė žóÜÍ≥†, žóĒžßÄŽčąžĖīŽäĒ Ž∂ĄžĄĚžĚī ŪēėÍłį žčęžĚĆ Ž∂ĄžĄĚÍįÄŽäĒ Í≥ĄžÜć ŽćįžĚīŪĄįžĚė ŽŹôŪĖ•žĚĄ ŪĆĆžēÖŪēīžēľ Ūē® MLžĚė ŪēúÍ≥Ą: ŽćįžĚīŪĄįžÖčžĚė ŪäĻžĄĪžĚī ŽįĒŽÄĆŽ©ī Ž™®ŽćłžĚī ŽįĒŽÄĆžĖīžēľ Ž∂ĄžĄĚÍįÄžĚė žöĒÍĶ¨žā¨Ūē≠žĚÄ Í≥ĄžÜć ŽįĒŽÄĆÍ≥† žěźÍłįŽŹĄ žěė Ž™®Ž¶Ą Ž∂ĄžĄĚÍįÄžóźÍ≤Ć žĶúŽĆÄŪēúžĚė žěźžú†ŽŹĄŽ•ľ ž£ľŽäĒ Žį©Ž≤ēžĚĄ ž∂ĒÍĶ¨ŪēėÍ≥†ŪĒĒ ‚ĶÍ≤įÍĶ≠ ŽćįžĚīŪĄįžÖčžĚĄ Í∑łŽĆÄŽ°ú ž£ľŽäĒ ŪéłžĚī ŽāęžßÄ žēäŽāė? žēĹžĚÄ žēĹžā¨žóźÍ≤Ć, Ž∂ĄžĄĚžĚÄ Ž∂ĄžĄĚÍįÄžóźÍ≤Ć ŪąīžĚīŽāė ŽćįžĚīŪĄį žÜƞ䧞Ěė ŪėēŪÉúÍįÄ ž§ĎžöĒŪēú Í≤ÉžĚī žēĄŽčąŽĚľ ŪĒľŽďúŽįĪ Ž£®ŪĒĄÍįÄ ž§ĎžöĒ žā¨ŽěĆžĚė Ž¨łž†ú
- 126. ž†ēŽ¶¨ ŽįŹ ÍĶźŪõą
- 127. ž†ēŽ¶¨: žöįŽ¶¨ŽäĒ Ž¨īžóážĚĄ ŪĖąŽäĒÍįÄ (repeat)
- 128. ž†ēŽ¶¨: žöįŽ¶¨ŽäĒ Ž¨īžóážĚĄ ŪĖąŽäĒÍįÄ (repeat) žĶúžīąžóź žāĹžßąŽŹĄ žĘÄ žěąžóąžßÄŽßĆ,
- 129. ž†ēŽ¶¨: žöįŽ¶¨ŽäĒ Ž¨īžóážĚĄ ŪĖąŽäĒÍįÄ (repeat) žĶúžīąžóź žāĹžßąŽŹĄ žĘÄ žěąžóąžßÄŽßĆ, MySQLžóź žĆďžĚÄ ž†ēŪėē Ž°úÍ∑łŽ•ľ ŽįĒŪÉēžúľŽ°ú
- 130. ž†ēŽ¶¨: žöįŽ¶¨ŽäĒ Ž¨īžóážĚĄ ŪĖąŽäĒÍįÄ (repeat) žĶúžīąžóź žāĹžßąŽŹĄ žĘÄ žěąžóąžßÄŽßĆ, MySQLžóź žĆďžĚÄ ž†ēŪėē Ž°úÍ∑łŽ•ľ ŽįĒŪÉēžúľŽ°ú ž£ľÍłįž†ĀžúľŽ°ú ŪēīŽčĻ Ž°úÍ∑łŽ•ľ ÍįÄž†łÍįÄ ŪĆƞ̾ ŪŹ¨Žß∑žĚĄ Ž≥ÄŪôėŪēī ž†Äžě•ŪēėÍ≥†
- 131. ž†ēŽ¶¨: žöįŽ¶¨ŽäĒ Ž¨īžóážĚĄ ŪĖąŽäĒÍįÄ (repeat) žĶúžīąžóź žāĹžßąŽŹĄ žĘÄ žěąžóąžßÄŽßĆ, MySQLžóź žĆďžĚÄ ž†ēŪėē Ž°úÍ∑łŽ•ľ ŽįĒŪÉēžúľŽ°ú ž£ľÍłįž†ĀžúľŽ°ú ŪēīŽčĻ Ž°úÍ∑łŽ•ľ ÍįÄž†łÍįÄ ŪĆƞ̾ ŪŹ¨Žß∑žĚĄ Ž≥ÄŪôėŪēī ž†Äžě•ŪēėÍ≥† žĚľŽ≥ĄŽ°ú ŽįįžĻė žěĎžó̥֞ ŽŹĆŽ†§ Í∑ł Í≤įÍ≥ľŽ•ľ ÍįÄžßÄÍ≥†
- 132. ž†ēŽ¶¨: žöįŽ¶¨ŽäĒ Ž¨īžóážĚĄ ŪĖąŽäĒÍįÄ (repeat) žĶúžīąžóź žāĹžßąŽŹĄ žĘÄ žěąžóąžßÄŽßĆ, MySQLžóź žĆďžĚÄ ž†ēŪėē Ž°úÍ∑łŽ•ľ ŽįĒŪÉēžúľŽ°ú ž£ľÍłįž†ĀžúľŽ°ú ŪēīŽčĻ Ž°úÍ∑łŽ•ľ ÍįÄž†łÍįÄ ŪĆƞ̾ ŪŹ¨Žß∑žĚĄ Ž≥ÄŪôėŪēī ž†Äžě•ŪēėÍ≥† žĚľŽ≥ĄŽ°ú ŽįįžĻė žěĎžó̥֞ ŽŹĆŽ†§ Í∑ł Í≤įÍ≥ľŽ•ľ ÍįÄžßÄÍ≥† ž†ĄŽ¨ł ŽćįžĚīŪĄį Ž∂ĄžĄĚ ŽŹĄÍĶ¨Ž•ľ Ž∂ôžó¨ ŽćįžĚīŪĄįŽ•ľ ŪÉźžÉČŪēėÍ≥† žßĀÍīĞ̥ ŽįúÍ≤¨ŪĖąŽč§
- 133. Spark ž†Āžö© žÜĆÍįź Spark SQL + Parquet = Awesome! DataFrame APIŽäĒ ÍįēŪēú ŪÉÄžěÖ ÍłįŽįė žĖłžĖīžĚł ScalažôÄ Ž≠ĒÍįÄ žĖīžĄ§ŪĒą ž°įŪē©žĚīžßÄŽßƂĶ ŽĒĒŽ≤ĄÍĻÖžĚī žČ¨žöī ŪôėÍ≤ĹžĚÄ žēĄŽčąŽč§ žěĎžóÖžĚī ž£ĹžúľŽ©ī ŪÉúžä§ŪĀ¨žĚłžßÄ ŽďúŽĚľžĚīŽ≤ĄžĚłžßÄ ÍĶ¨Ž∂ĄŪēėŽĚľ ŪäĻŪěą OOMžĚÄ žěźž£ľ Žßąž£ľŪē† žöīŽ™ÖžĚīŽč§ ŽĄąŽ¨ī Íłī RDD ž≤īžĚłžĚÄ žĘčžßÄ žēäŽč§ Ž¶¨žÜĆžä§ ÍīÄŽ¶¨Ž•ľ ŽĄąŽ¨ī žěė ŪēėŽ†§Í≥† ŪēėžßÄ ŽßąŽĚľ JVM ÍłįŽįėžĚīŽĚľ žĖīž©Ē žąė žóÜŽäĒ Ž∂ÄŽ∂ĄŽď§žĚī žěąŽč§
- 134. Spark ž†Āžö© žÜĆÍįź Spark SQL + Parquet = Awesome! DataFrame APIŽäĒ ÍįēŪēú ŪÉÄžěÖ ÍłįŽįė žĖłžĖīžĚł ScalažôÄ Ž≠ĒÍįÄ žĖīžĄ§ŪĒą ž°įŪē©žĚīžßÄŽßƂĶ ŽĒĒŽ≤ĄÍĻÖžĚī žČ¨žöī ŪôėÍ≤ĹžĚÄ žēĄŽčąŽč§ žěĎžóÖžĚī ž£ĹžúľŽ©ī ŪÉúžä§ŪĀ¨žĚłžßÄ ŽďúŽĚľžĚīŽ≤ĄžĚłžßÄ ÍĶ¨Ž∂ĄŪēėŽĚľ ŪäĻŪěą OOMžĚÄ žěźž£ľ Žßąž£ľŪē† žöīŽ™ÖžĚīŽč§ ŽĄąŽ¨ī Íłī RDD ž≤īžĚłžĚÄ žĘčžßÄ žēäŽč§ Ž¶¨žÜĆžä§ ÍīÄŽ¶¨Ž•ľ ŽĄąŽ¨ī žěė ŪēėŽ†§Í≥† ŪēėžßÄ ŽßąŽĚľ JVM ÍłįŽįėžĚīŽĚľ žĖīž©Ē žąė žóÜŽäĒ Ž∂ÄŽ∂ĄŽď§žĚī žěąŽč§
- 135. Spark ž†Āžö© žÜĆÍįź Spark SQL + Parquet = Awesome! DataFrame APIŽäĒ ÍįēŪēú ŪÉÄžěÖ ÍłįŽįė žĖłžĖīžĚł ScalažôÄ Ž≠ĒÍįÄ žĖīžĄ§ŪĒą ž°įŪē©žĚīžßÄŽßƂĶ ŽĒĒŽ≤ĄÍĻÖžĚī žČ¨žöī ŪôėÍ≤ĹžĚÄ žēĄŽčąŽč§ žěĎžóÖžĚī ž£ĹžúľŽ©ī ŪÉúžä§ŪĀ¨žĚłžßÄ ŽďúŽĚľžĚīŽ≤ĄžĚłžßÄ ÍĶ¨Ž∂ĄŪēėŽĚľ ŪäĻŪěą OOMžĚÄ žěźž£ľ Žßąž£ľŪē† žöīŽ™ÖžĚīŽč§ ŽĄąŽ¨ī Íłī RDD ž≤īžĚłžĚÄ žĘčžßÄ žēäŽč§ Ž¶¨žÜĆžä§ ÍīÄŽ¶¨Ž•ľ ŽĄąŽ¨ī žěė ŪēėŽ†§Í≥† ŪēėžßÄ ŽßąŽĚľ JVM ÍłįŽįėžĚīŽĚľ žĖīž©Ē žąė žóÜŽäĒ Ž∂ÄŽ∂ĄŽď§žĚī žěąŽč§
- 136. Spark ž†Āžö© žÜĆÍįź Spark SQL + Parquet = Awesome! DataFrame APIŽäĒ ÍįēŪēú ŪÉÄžěÖ ÍłįŽįė žĖłžĖīžĚł ScalažôÄ Ž≠ĒÍįÄ žĖīžĄ§ŪĒą ž°įŪē©žĚīžßÄŽßƂĶ ŽĒĒŽ≤ĄÍĻÖžĚī žČ¨žöī ŪôėÍ≤ĹžĚÄ žēĄŽčąŽč§ žěĎžóÖžĚī ž£ĹžúľŽ©ī ŪÉúžä§ŪĀ¨žĚłžßÄ ŽďúŽĚľžĚīŽ≤ĄžĚłžßÄ ÍĶ¨Ž∂ĄŪēėŽĚľ ŪäĻŪěą OOMžĚÄ žěźž£ľ Žßąž£ľŪē† žöīŽ™ÖžĚīŽč§ ŽĄąŽ¨ī Íłī RDD ž≤īžĚłžĚÄ žĘčžßÄ žēäŽč§ Ž¶¨žÜĆžä§ ÍīÄŽ¶¨Ž•ľ ŽĄąŽ¨ī žěė ŪēėŽ†§Í≥† ŪēėžßÄ ŽßąŽĚľ JVM ÍłįŽįėžĚīŽĚľ žĖīž©Ē žąė žóÜŽäĒ Ž∂ÄŽ∂ĄŽď§žĚī žěąŽč§
- 137. ž†Ąž≤ī Ž∂ĄžĄĚ Í≥ľž†ēžóźžĄú žĖĽžĚÄ ÍĶźŪõą
- 138. ž†Ąž≤ī Ž∂ĄžĄĚ Í≥ľž†ēžóźžĄú žĖĽžĚÄ ÍĶźŪõą Ž¨īžóźžĄú žú†Ž•ľ žįĹž°įŪē† žąú žóÜŽćĒŽĚľ: žäąŪĆźžõĆžĚė Í≤Ĺžöį ŽĮŅžĚĄŽßĆŪēú Ž°úÍ∑łŽď§žĚĄ žĆďÍ≥† žěąžóąÍłįžóź žĄĪÍ≥Ķž†ĀžĚł Ž∂ĄžĄĚžĚĄ Ūē† žąė žěąžóąŽč§.
- 139. ž†Ąž≤ī Ž∂ĄžĄĚ Í≥ľž†ēžóźžĄú žĖĽžĚÄ ÍĶźŪõą Ž¨īžóźžĄú žú†Ž•ľ žįĹž°įŪē† žąú žóÜŽćĒŽĚľ: žäąŪĆźžõĆžĚė Í≤Ĺžöį ŽĮŅžĚĄŽßĆŪēú Ž°úÍ∑łŽď§žĚĄ žĆďÍ≥† žěąžóąÍłįžóź žĄĪÍ≥Ķž†ĀžĚł Ž∂ĄžĄĚžĚĄ Ūē† žąė žěąžóąŽč§. Ž™®ŽěėŽį≠žóź Ž¨īžĖłÍįÄŽ•ľ žßĞ̥ žąú žóÜŽćĒŽĚľ: žäąŪĆźžõĆžĚė Í≤Ĺžöį RDBMSžóź ž†Äžě•ŪēėÍ≥† žěąžóąÍłįžóź Žč®Žč®Ūēú ŽćįžĚīŪĄį Í≥ĶͳȞõźžĚī žěąžóąŽč§.
- 140. ž†Ąž≤ī Ž∂ĄžĄĚ Í≥ľž†ēžóźžĄú žĖĽžĚÄ ÍĶźŪõą Ž¨īžóźžĄú žú†Ž•ľ žįĹž°įŪē† žąú žóÜŽćĒŽĚľ: žäąŪĆźžõĆžĚė Í≤Ĺžöį ŽĮŅžĚĄŽßĆŪēú Ž°úÍ∑łŽď§žĚĄ žĆďÍ≥† žěąžóąÍłįžóź žĄĪÍ≥Ķž†ĀžĚł Ž∂ĄžĄĚžĚĄ Ūē† žąė žěąžóąŽč§. Ž™®ŽěėŽį≠žóź Ž¨īžĖłÍįÄŽ•ľ žßĞ̥ žąú žóÜŽćĒŽĚľ: žäąŪĆźžõĆžĚė Í≤Ĺžöį RDBMSžóź ž†Äžě•ŪēėÍ≥† žěąžóąÍłįžóź Žč®Žč®Ūēú ŽćįžĚīŪĄį Í≥ĶͳȞõźžĚī žěąžóąŽč§. ÍīÄŽ¶¨ŽźėžßÄ žēäŽäĒ Ž°úÍ∑łŽäĒ žó܎䟎蹎ßĆ Ž™ĽŪēú Í≤É ÍįôŽćĒŽĚľ: ÍįúŽįú žīąÍłįžóź ŽßĆŽď§Í≥† Žį©žĻėŪēú ÍĻ®žßĄ žįĹŽ¨łžĚÄ Ž°úÍ∑łžĚľžßÄŽĚľŽŹĄ žúĄŪóėŪēėŽč§.
- 141. ž†Ąž≤ī Ž∂ĄžĄĚ Í≥ľž†ēžóźžĄú žĖĽžĚÄ ÍĶźŪõą Ž¨īžóźžĄú žú†Ž•ľ žįĹž°įŪē† žąú žóÜŽćĒŽĚľ: žäąŪĆźžõĆžĚė Í≤Ĺžöį ŽĮŅžĚĄŽßĆŪēú Ž°úÍ∑łŽď§žĚĄ žĆďÍ≥† žěąžóąÍłįžóź žĄĪÍ≥Ķž†ĀžĚł Ž∂ĄžĄĚžĚĄ Ūē† žąė žěąžóąŽč§. Ž™®ŽěėŽį≠žóź Ž¨īžĖłÍįÄŽ•ľ žßĞ̥ žąú žóÜŽćĒŽĚľ: žäąŪĆźžõĆžĚė Í≤Ĺžöį RDBMSžóź ž†Äžě•ŪēėÍ≥† žěąžóąÍłįžóź Žč®Žč®Ūēú ŽćįžĚīŪĄį Í≥ĶͳȞõźžĚī žěąžóąŽč§. ÍīÄŽ¶¨ŽźėžßÄ žēäŽäĒ Ž°úÍ∑łŽäĒ žó܎䟎蹎ßĆ Ž™ĽŪēú Í≤É ÍįôŽćĒŽĚľ: ÍįúŽįú žīąÍłįžóź ŽßĆŽď§Í≥† Žį©žĻėŪēú ÍĻ®žßĄ žįĹŽ¨łžĚÄ Ž°úÍ∑łžĚľžßÄŽĚľŽŹĄ žúĄŪóėŪēėŽč§. 'žóÖž†Ā'žĚÄ ŪõĆŽ•≠Ūēú ž†ēŽ≥īŽćĒŽĚľ: ŪäĻž†ē žóÖž†ĀŽď§žĚė Ž≥īžú† žó¨Ž∂ÄžôÄ žčúž†źžĚÄ žĚīŽĮł žó¨Žü¨ÍįÄžßÄ Ž∂ĄžĄĚžĚĄ ŽŹĆŽ¶į Í≤įÍ≥ľŽ¨ľžĚīŽāė Žč§Ž¶ĄžóÜŽč§.
- 142. ž†Ąž≤ī Ž∂ĄžĄĚ Í≥ľž†ēžóźžĄú žĖĽžĚÄ ÍĶźŪõą Ž¨īžóźžĄú žú†Ž•ľ žįĹž°įŪē† žąú žóÜŽćĒŽĚľ: žäąŪĆźžõĆžĚė Í≤Ĺžöį ŽĮŅžĚĄŽßĆŪēú Ž°úÍ∑łŽď§žĚĄ žĆďÍ≥† žěąžóąÍłįžóź žĄĪÍ≥Ķž†ĀžĚł Ž∂ĄžĄĚžĚĄ Ūē† žąė žěąžóąŽč§. Ž™®ŽěėŽį≠žóź Ž¨īžĖłÍįÄŽ•ľ žßĞ̥ žąú žóÜŽćĒŽĚľ: žäąŪĆźžõĆžĚė Í≤Ĺžöį RDBMSžóź ž†Äžě•ŪēėÍ≥† žěąžóąÍłįžóź Žč®Žč®Ūēú ŽćįžĚīŪĄį Í≥ĶͳȞõźžĚī žěąžóąŽč§. ÍīÄŽ¶¨ŽźėžßÄ žēäŽäĒ Ž°úÍ∑łŽäĒ žó܎䟎蹎ßĆ Ž™ĽŪēú Í≤É ÍįôŽćĒŽĚľ: ÍįúŽįú žīąÍłįžóź ŽßĆŽď§Í≥† Žį©žĻėŪēú ÍĻ®žßĄ žįĹŽ¨łžĚÄ Ž°úÍ∑łžĚľžßÄŽĚľŽŹĄ žúĄŪóėŪēėŽč§. 'žóÖž†Ā'žĚÄ ŪõĆŽ•≠Ūēú ž†ēŽ≥īŽćĒŽĚľ: ŪäĻž†ē žóÖž†ĀŽď§žĚė Ž≥īžú† žó¨Ž∂ÄžôÄ žčúž†źžĚÄ žĚīŽĮł žó¨Žü¨ÍįÄžßÄ Ž∂ĄžĄĚžĚĄ ŽŹĆŽ¶į Í≤įÍ≥ľŽ¨ľžĚīŽāė Žč§Ž¶ĄžóÜŽč§. uniqueŽäĒ ž†ēŽßź uniqueŪēīžēľ ŪēėŽćĒŽĚľ: žąėŪŹČŽ∂ĄŪē†žĚĄ ŪēúŽč§Ž©ī žčúžěĎ Ūā§Ž•ľ Žč§Ž•īÍ≤Ć, ŽěúŽć§Ūēú ÍįížĚÄ ž∂©Ž∂ĄŪěą žĽ§žēľ ŪēúŽč§. Birthday Paradox
- 143. žįłÍ≥† žěźŽ£Ć žěĄž§ĎÍ∑ľ(ŽćįŽłĆžčúžä§ŪĄįž¶ą), <žŅ†Ūā§Žüį> ŽįĒžĀėÍ≥† ÍįÄŽāúŪēú ÍįúŽįúžěźŽ•ľ žúĄŪēú S3 ÍłįŽįė Ž°úÍ∑ł žčúžä§ŪÖú, NDC 2015 Tom Mathews(Microsoft, 343 Industries), Making "Big Data" Work for 'Halo': A Case Study, GDC 2016 Maurizio De Pascale(Ubisoft Montreal), Unified Telemetry, Building an Infrastructure for Big Data in Games Development, GDC 2016 https://wikitech.wikimedia.org/wiki/Analytics/Cluster/Logging_Solutions_Overview https://wikitech.wikimedia.org/wiki/Analytics/Cluster/Logging_Solutions_Recommendation If I have seen further, it is by standing on the shoulders of giants.