Nextag talk
Download as PPT, PDF4 likes1,398 views

Hive provides an SQL-like interface to query data stored in Hadoop's HDFS distributed file system and processed using MapReduce. It allows users without MapReduce programming experience to write queries that Hive then compiles into a series of MapReduce jobs. The document discusses Hive's components, data model, query planning and optimization techniques, and performance compared to other frameworks like Pig.















































More Related Content
What's hot (20)
Similar to Nextag talk (20)


















Nextag talk
- 1. HBase and Hive a random walk down H street Joydeep Sen Sarma
- 2. this.toString() Oracle, Netapp, Yahoo, dead startups Facebook: Setup Hadoop@FB (circa 2007): ETL, custom jobs Conceived, prototyped and co-authored Hive Mentored Fair-Scheduler development Prototype/Architecture for FB Messages (HBase/Cassandra) FB Credits back-end contributor Nowadays: Job Scheduler Hive (sometimes) Chit-Chat (always)
- 3. Outline Hadoop Ecosystem Hive Introduction Examples Internals HDFS/MR Scheduler, HDFS-RAID, HA HBase Introduction Example uses Internals Operational Takeaways
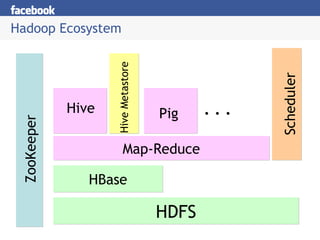
- 4. Hadoop Ecosystem HDFS ZooKeeper HBase Map-Reduce Scheduler Hive Metastore Hive Pig
- 5. OMG - NoSQL looks like a DBMS! Zookeeper for coordination atomic primitives (CAS), notifications, heartbeats Not a key-value store, not a file system, not a database Like a DLM in a database, can build locks/leases easily on top HDFS for large objects Shared storage like NFS or SAN HBase for small objects Every DB has an index at itâs heart Shared Storage DB (like Oracle) Map-Reduce/Hive/Pig etc. for analytics Missing: Transaction Monitor, Automatic/Transactional view/secondary-index maintenance, Triggers, Remote Replication etc.
- 6. Why HIVE? Human Cost >> Machine Cost Hadoopâs programming model is awesome, but .. map-reduce is impossible for non-engineers training 100s of engineers in java map-reduce == hard Map-reduce is non-trivial for engineers (sort vs. partition vs. grouping comparator anyone?) Much much easier to write Sql query Almost zero training cost Hard things become easy Files as insufficient data management abstraction Tables, Schemas, Partitions, Indices Metadata allows optimization, discovery, browsing Embrace all data formats: Complex Data Types, columnar or not, lazy retrieval
- 7. Quick Examples Create some tables: CREATE TABLE ad_imps (ad_id string, userid bigint, url string) PARTITIONED BY (ds string); CREATE TABLE dim_ads (ad_id string, campaign_id string) stored as textfile; Group-by + Join: SELECT a.campaign_id, count(1), count(DISTINCT b.user_id) FROM dim_ads a JOIN impression_logs b ON(b.ad_id = a.ad_id) WHERE b.dateid = '2008-12-01' GROUP BY a.campaign_id; Custom Transform + View: ADD FILE url_to_cat.py; CREATE VIEW tmp_adid_cat AS SELECT TRANSFORM (ad_id, url) USING âurl_to_cat.pyâ AS (ad_id, cat) FROM ad_imps WHERE ds=â2008-12-01â; SELECT a.campaign_id, b.cat, count(1) FROM dim_ads a JOIN tmp_adid_cat b ON (b.ad_id=a.ad_id) GROUP BY a.campaign_id;
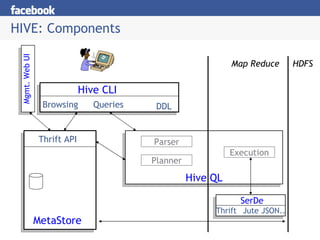
- 8. HIVE: Components HDFS Hive CLI DDL Queries Browsing Map Reduce MetaStore Thrift API SerDe Thrift Jute JSON.. Execution Hive QL Parser Planner Mgmt. Web UI
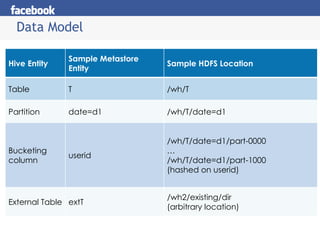
- 9. Data Model Hive Entity Sample Metastore Entity Sample HDFS Location Table T /wh/T Partition date=d1 /wh/T/date=d1 Bucketing column userid /wh/T/date=d1/part-0000 âĶ /wh/T/date=d1/part-1000 (hashed on userid) External Table extT /wh2/existing/dir (arbitrary location)
- 10. Using Hive: quick planner How to store data: Binary or text? Compressed or not? RCFile saves space over SequenceFile How to partition and load data: Initial data load using Dynamic Partitioning Incremental loading: Appending data to existing partitions? Mutable partitions/data? (hard!) Managing space consumption (use RETENTION) Performance Tuning Learning to read Explain plans ï
- 11. Join Processing Sort-merge joins Uses vanilla map-reduce using join key for sorting Single MR job for multiple joins on the same key: FROM (a join b on a.key = b.key) join c on a.key = c.key Put largest table last (reduces memory usage) Map-Joins Load smaller table into memory on each mapper No sorting â map-side joins Automatic Map-Join in Hive 0.7 Bucketed (Map) Join Map-side join if join key is same as bucketing key
- 12. Group-By Processing Hash Based Map-side aggregation 90% improvement for count(1) aggregate Automatically reverts to regular map-reduce aggregation if cardinality is too high Can be turned off -> regular sort based group by Handling skews in groups 2-stage MR job 1 st MR - Partition on random value or distinct column (for distinct queries) and compute partial aggregates 2 nd MR â Compute full aggregates
- 13. Common Issues Too many files: Option to merge (small) files at the end of MR job ARCHIVE partitions with many small files Using CombineHiveInputFormat to reduce number of mappers over partition with many small files High latencies for small jobs Scheduling latencies are killer Optimize number of map-reduce jobs Use automatic local mode if possible
- 14. Other goodies Locks using Zookeeper (to prevent read/write race) Indexes Partitioned Views Storage Handlers (to query HBase directly) Statistics collection Security Future Block Sampling and faster LIMIT queries Help query authoring and data exploration Hive Server Much faster query execution
- 15. Hive vs. .. PIG Hive is not a procedural language But views are similar to Pig variables Core philosophy to integrate with other languages via Streaming PIG does not provide SQL interface PIG does not have a metastore or data management model More similar than different Cascading No metastore or data management model No declarative language Seems similar to Hiveâs internal execution operators
- 16. Hive Warehouse @ Facebook Two primary warehouses (HDFS + MR) High SLA pipelines Core Data Warehouse Core Warehouse, Jan 2011: ~2800 nodes 30 petabytes disk space Growing to 100PB by end of year Data access per day: ~40 terabytes added (compressed) /day 25000 map/reduce jobs/ day 300-400 users/month
- 17. Hive is just part of the story HDFS Improvements: HDFS RAID (saved ~5PB) High Availability(AvatarNode) NameNode improvements (locking, restart, decomissioning âĶ) JobScheduler improvements: More efficient/concurrent JobTracker Monitoring and killing runaway tasks FairScheduler features (preemption, speculation, FIFO+FAIR) Hadoop/Hive Administration Rolling Upgrades for Hive Tools/Configuration for managing multiple clusters Hive Replication
- 18. HBase png s via Lars George
- 19. Why/When use HBase? Very large indexed data store Lower management cost than building mysql cluster Very high write throughput Log Structured index trumps standard BTree Donât need complex multi-row transactions But need durability and strong consistency Read performance is not critical Reads from memory not as fast as memcache Random reads from disk suffer because of log-structure Reading recently written data is (potentially) faster Need Killer Map-Reduce integration
- 20. HBase Table Collection of Column Families HBase Table + Column Family == MySql Table HBase Column Family Collection of columns Each column has key (column qualifier) and value â Columnâ in HBase == row in Mysql Data Organization Table Sharded on row-key Data Indexed on row-key + column-family + column qualifier Multiple timestamped versions for each cell (mysql row) Data Model
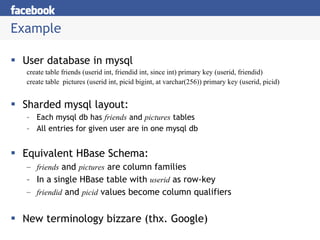
- 21. Example User database in mysql create table friends (userid int, friendid int, since int) primary key (userid, friendid) create table pictures (userid int, picid bigint, at varchar(256)) primary key (userid, picid) Sharded mysql layout: Each mysql db has friends and pictures tables All entries for given user are in one mysql db Equivalent HBase Schema: friends and pictures are column families In a single HBase table with userid as row-key friendid and picid values become column qualifiers New terminology bizzare (thx. Google)
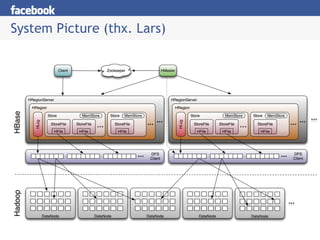
- 22. System Picture (thx. Lars)
- 23. HBase Index Internals LSM Trees: Data stored in a series of index files (Index organized table) Bloom Filters for skipping index files entirely Short Circuiting lookups Retrieve last value assuming client stores greatest timestamp last Retrieve values stored in given time range (donât scan all files) Compact multiple index files into one periodically In Memory caching Recent writes cached in MemStore (skip-list) Pins index headers and bloom filters in memory Block cache (not row cache) for index file data blocks
- 24. BigTable (HBase) vs. Dynamo (Cassandra, âĶ) Provides Strong Consistency with low read penalty Cassandra will require R>1 for strong consistency Data Resilience story is much better thx HDFS CRCs, replication, block placement Equally fast at disk reads Sticky Regions in HBase Fast path local reads in HDFS No partition tolerance, lower availability No read replicas, no built-in conflict resolution
- 25. Appendix
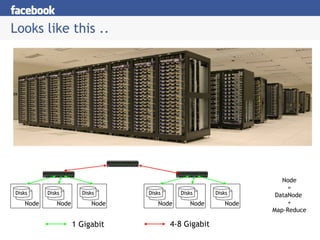
- 26. Looks like this .. Disks Node Disks Node Disks Node Disks Node Disks Node Disks Node 1 Gigabit 4-8 Gigabit Node = DataNode + Map-Reduce
- 27. HDFS Separation of Metadata from Data Metadata == Inodes, attributes, block locations, block replication File = ÎĢ data blocks (typically 128MB) Architected for large files and streaming reads Highly Reliable Each data block typically replicated 3X to different datanodes Clients compute and verify block checksums (end-to-end) Single namenode All metadata stored In-memory. Passive standby Client talks to both namenode and datanodes Bulk data from datanode to client ïĻ linear scalability Custom Client library in Java/C/Thrift Not POSIX, not NFS
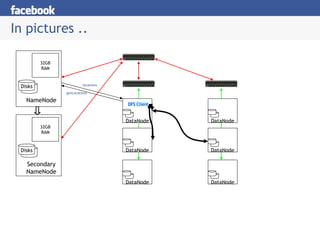
- 28. In pictures .. NameNode Disks 32GB RAM Secondary NameNode Disks 32GB RAM DataNode DataNode DataNode DFS Client DataNode DataNode DataNode getLocations locations
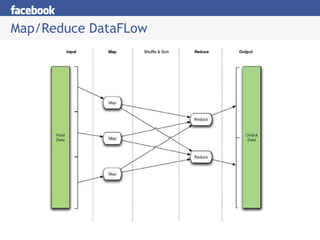
- 30. Programming with Map/Reduce Find the most imported package in Hive source: $ find . -name '*.java' -exec egrep '^import' '{}' \; | awk '{print $2}' | sort | uniq -c | sort -nr +0 -1 | head -1 208 org.apache.commons.logging.LogFactory; In Map-Reduce: 1a. Map using: egrep '^import'| awk '{print $2}' 1b. Reduce on first column (package name) 1c. Reduce Function: uniq -c 2a. Map using: awk â{print â%05d\t%s\nâ,100000-$1,$2}â 2b. Reduce using first column (inverse counts), 1 reducer 2c. Reduce Function: Identity Scales to Terabytes
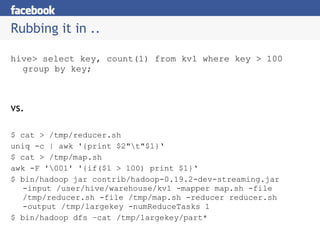
- 31. Rubbing it in .. hive> select key, count(1) from kv1 where key > 100 group by key; vs. $ cat > /tmp/reducer.sh uniq -c | awk '{print $2"\t"$1}â $ cat > /tmp/map.sh awk -F '\001' '{if($1 > 100) print $1}â $ bin/hadoop jar contrib/hadoop-0.19.2-dev-streaming.jar -input /user/hive/warehouse/kv1 -mapper map.sh -file /tmp/reducer.sh -file /tmp/map.sh -reducer reducer.sh -output /tmp/largekey -numReduceTasks 1 $ bin/hadoop dfs âcat /tmp/largekey/part*
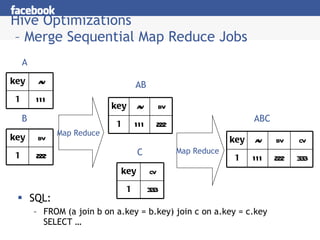
- 32. Hive Optimizations â Merge Sequential Map Reduce Jobs SQL: FROM (a join b on a.key = b.key) join c on a.key = c.key SELECT âĶ A Map Reduce B C AB Map Reduce ABC key av bv 1 111 222 key av 1 111 key bv 1 222 key cv 1 333 key av bv cv 1 111 222 333
Editor's Notes
- #2: Offline and Near-Real time data processing Not online
- #7: Simple map-reduce is easy â but it can get complicated very quickly.
- #16: Assume users know about Hadoop Streaming
- #27: Nomenclature: Core switch and Top of Rack
- #28: Compare to a standard unix file system
- #29: Rack local and node local access rocks Scalability is bound by switches
- #30: Point out that now we know how HDFS works â we can run maps close to data
- #31: Point out how data local computing is useful in this example Exposes some of the features we need in hadoop â output of reducer can be directly sent to another reducer As an exercise to the reader â the results from the shell do not equal those from hadoop â interesting to find why.