NLP in the WILD or Building a System for Text Language Identification
ŌĆó
2 likesŌĆó691 views

The problem of Text Language Identification is analyzed from 3 points of view: linguistic, research, and engineering
























NLP in the WILD or Building a System for Text Language Identification
- 1. NLP in the WILD -or- Building a System for Text Language Identification Vsevolod Dyomkin 12/2016
- 2. A Bit about Me * Lisp programmer * 5+ years of NLP work at Grammarly * Occasional lecturer https://vseloved.github.io
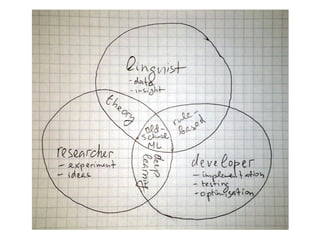
- 3. Roles
- 4. Langid Problem * 150+ langs in Wikipedia * >10 writing systems (script/alphabet) in active use * script-lang: 1:1, 1:2, 1:n, n:1 :) * Latin >50 langs, Cyrillyc >20 * Long texts easy, short hmmŌĆō ŌĆō * Internet texts (mixed langs) * Small task => resource-constrained
- 6. Prior Art * C++: https://github.com/CLD2Owners/cld2 * Python: https://github.com/saffsd/langid.py * Java:┬Ā https://github.com/shuyo/language-detection/ http://blog.mikemccandless.com/2011/10/accuracy -and-performance-of-googles.html http://lab.hypotheses.org/1083 http://labs.translated.net/language-identifier/
- 8. YALI WILD * All of them use weak models * Wanted to use Wiktionary ŌĆö 150+ languages, always evolving * Wanted to do in Lisp
- 9. Linguistics (domain knowledge) * Polyglots? * ISO 639 * Internet lang bias https://en.wikipedia.org/wiki/Languages_used_on_the_Internet * Rule-based ideas: - 1:1/1:2 scripts - unique letters * Per-script/per-lang segmentation insight data
- 10. Data * evaluation data: - smoke test - in-/out-of-domain data - precision-/recall-oriented * training data - where to get? Wikidata - how to get? SAX parsing
- 11. Wiktionary * good source for various dictionaries and word lists (word forms, definitions, synonyms,ŌĆ”) * ~100 langs
- 12. Wiktionary * good source for various dictionaries and word lists (word forms, definitions, synonyms,ŌĆ”) * ~100 langs
- 13. Wikipedia * >150 langs * size? Wikipedia abstracts * automation? * filtering?
- 14. Alternatives * API (defun get-examples (word) (remove-if-not ^(upper-case-p (char % 0)) (mapcar ^(substitute #Space #_ (? % "text")) (? (yason:parse (drakma:http-request (fmt "http://api.wordnik.com/v4/word.json/~A/examples" (drakma:url-encode word :utf-8)) :additional-headers *wordnik-auth-headers*)) "examples")))) * Web scraping (defmethod scrape ((site (eql :linguaholic)) source) (match-html source '(>> article (aside (>> a ($ user)) (>> li (strong "Native Tongue:") ($ lang))) (div |...| (>> (div :data-role "commentContent") ($ text) (span) |...|)) !!!))))
- 15. Research (quality) * Simple task => simple models (NB) * Challenges - short texts - mixed langs - 90% of data - cryptic ideas experiments
- 16. Naive Bayes * Features: 3-/4-char ngrams * Improvement ideas: - add words (word unigrams) - factor in word lengths - use Internet lang bias Formula: (argmax (* (? priors lang) (or (? word-probs word) (norm (reduce '* ^(? 3g-probs %) (word-3gs word))))) langs) http://www.paulgraham.com/spam.html
- 18. Experiments * Usual ML setup (70:30) doesn't work here * ŌĆ£If you torment the data too much...ŌĆØ (~c) Yaser Abu-Mosafa * Comparison with existing systems helps
- 19. Confusion MatrixAB: 0.90 | FR:0.10 AF: 0.80 | EN:0.20 AK: 0.80 | NN:0.10 IT:0.10 AN: 0.90 | ES:0.10 AY: 0.90 | ES:0.10 BG: 0.60 | RU:0.40 BM: 0.80 | FR:0.10 LA:0.10 BS: 0.90 | EN:0.10 CO: 0.90 | IT:0.10 CR: 0.40 | FR:0.30 UND:0.20 MS:0.10 CS: 0.90 | IT:0.10 CU: 0.90 | VI:0.10 CV: 0.80 | RU:0.20 DA: 0.70 | FO:0.10 NO:0.10 NN:0.10 DV: 0.80 | UZ:0.10 EN:0.10 DZ: NIL | BO:0.80 IK:0.10 NE:0.10 EN: 0.90 | NL:0.10 ET: 0.80 | EN:0.20 FF: 0.50 | EN:0.20 FR:0.10 EO:0.10 SV:0.10 FI: 0.80 | FR:0.10 DA:0.10 FJ: 0.90 | OC:0.10 GL: 0.90 | ES:0.10 HA: 0.80 | YO:0.10 EN:0.10 HR: 0.70 | BS:0.10 DE:0.10 GL:0.10 ID: 0.80 | MS:0.20 IE: 0.90 | EN:0.10 IG: 0.60 | EN:0.40 IO: 0.86 | DA:0.14 KG: 0.90 | SW:0.10 KL: 0.90 | EN:0.10 KS: 0.30 | UR:0.60 UND:0.10 KU: 0.90 | EN:0.10 KW: 0.89 | UND:0.11 LA: 0.90 | FR:0.10 LB: 0.90 | EN:0.10 LG: 0.90 | IT:0.10 LI: 0.80 | NL:0.20 MI: 0.90 | ES:0.10 MK: 0.80 | IT:0.10 RU:0.10 MS: 0.80 | ID:0.10 EN:0.10 MT: 0.90 | DE:0.10 NO: 0.90 | DA:0.10 NY: 0.80 | AR:0.10 SW:0.10 OM: 0.90 | EN:0.10 OS: 0.90 | RU:0.10 QU: 0.70 | ES:0.20 EN:0.10 RM: 0.90 | EN:0.10 RN: 0.50 | RW:0.40 YO:0.10 SC: 0.90 | FR:0.10 SG: 0.90 | FR:0.10 SR: 0.80 | HR:0.10 BS:0.10 SS: 0.50 | EN:0.30 DA:0.10 ZU:0.10 ST: 0.90 | PT:0.10 SV: 0.90 | DA:0.10 TI: 0.40 | AM:0.40 LA:0.10 EN:0.10 TK: 0.80 | TR:0.20 TO: 0.50 | EN:0.50 TS: 0.80 | EN:0.10 UZ:0.10 TW: 0.40 | EN:0.40 AK:0.10 YO:0.10 TY: 0.90 | ES:0.10 UG: 0.60 | UZ:0.40 UK: 0.80 | UND:0.10 VI:0.10 VE: 0.90 | EN:0.10 WO: 0.80 | NL:0.10 FR:0.10 XH: 0.80 | UZ:0.10 EN:0.10 YO: 0.80 | EN:0.20 ZU: 0.60 | XH:0.30 PT:0.10 Total quality: 0.90
- 20. The Ladder of NLP Rule-based Linear ML Decision Trees & co. Sequence models Artificial Neural networks
- 21. Better Models What can be improved? * Account for word order * Discriminative models per script * DeepLearningŌäó model Marginal gain is not hugeŌĆ”
- 22. Engineer (efficiency) * Just a small piece of the pipeline: - good-enough speed - minimize space usage - minimize external dependencies * Proper floating-point calculations * Proper processing of big texts? * Pre-/post-processing * Clean API implementation optimization
- 23. Model Optimization Initial model size: ~1G Target: ~10M :) How to do it? - Lossy compression: pruning - Lossless compression: Huffman coding, efficient DS
- 24. API * Levels of detalization: - text-langs - word-langs - window? * UI: library, REPL & Web APIs
- 25. Recap * Triple view of any knowledge-related problem * Ladder of approaches to solving NLP problems * Importance of productive env: general- & special-purpose REPL lang API access to dataŌĆō ŌĆō efficient testingŌĆō * Main stages of problem solving: data experimentŌåÆ ŌåÆ implementation optimizationŌåÆ