NoSQL thumbtack experience, –ê–Ω–∞—Ç–æ–ª–∏–π –ù–∏–∫—É–ª–∏–Ω
•
1 like•1,214 views

NoSQL, —Ç–∏–ø—ã, –≤–∏–¥—ã, –∏ —Ä–µ—à–µ–Ω–∏—è























NoSQL thumbtack experience, –ê–Ω–∞—Ç–æ–ª–∏–π –ù–∏–∫—É–ª–∏–Ω
- 1. NoSQL –û–ø—ã—Ç –ø—Ä–∏–º–µ–Ω–µ–Ω–∏—è NoSQL —Ä–µ—à–µ–Ω–∏–π –≤ –ø—Ä–æ–µ–∫—Ç–∞—Ö Thumbtack –ê–Ω–∞—Ç–æ–ª–∏–π –ù–∏–∫—É–ª–∏–Ω
- 2. 1. –û –∑–∞–¥–∞—á–∞—Ö 2. –û —Ä–∞–∑–Ω–æ–≤–∏–¥–Ω–æ—Å—Ç—è—Ö (–ø–æ —Å—Ç—Ä—É–∫—Ç—É—Ä–µ) 3. –û —Ä–∞–∑–Ω–æ–≤–∏–¥–Ω–æ—Å—Ç—è—Ö (CAP) 4. –û–± –æ—Å–æ–±–µ–Ω–Ω–æ—Å—Ç—è—Ö (—Ç—Ä–∞–Ω–∑–∞–∫—Ü–∏–∏, –∞–≥—Ä–µ–≥–∞—Ç—ã) 5. –ë–µ–≥–ª—ã–π –æ–±–∑–æ—Ä NoSQL —Ä–µ—à–µ–Ω–∏–π 6. –û –ø—Ä–æ–µ–∫—Ç–Ω–æ–º –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–∏
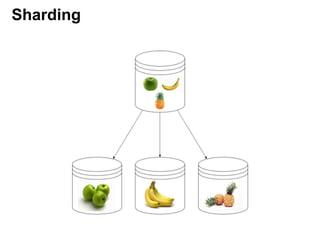
- 3. Sharding
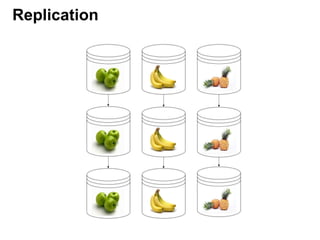
- 4. Replication
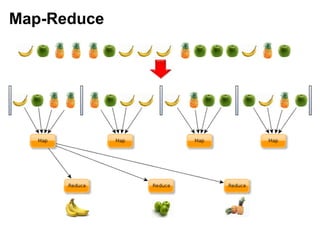
- 5. Map-Reduce
- 6. –û –∑–∞–¥–∞—á–∞—Ö –ö–æ–Ω–∫—Ä–µ—Ç–Ω–æ–µ, —ç—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–µ–π —á–µ–º –∞–±—Å—Ç—Ä–∞–∫—Ç–Ω–æ–µ.
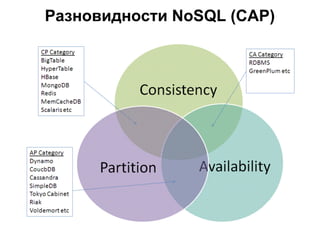
- 7. –Ý–∞–∑–Ω–æ–≤–∏–¥–Ω–æ—Å—Ç–∏ NoSQL (–ø–æ —Ç–∏–ø—É –¥–∞–Ω–Ω—ã—Ö) ‚óè KV ‚óè –ö–æ–ª–æ–Ω–æ—á–Ω—ã–µ ‚óè –î–æ–∫—É–º–µ–Ω—Ç–æ-–æ—Ä–∏–µ–Ω—Ç–∏—Ä–æ–≤–∞–Ω–Ω—ã–µ ‚óè –ì—Ä–∞—Ñ–æ–≤—ã–µ
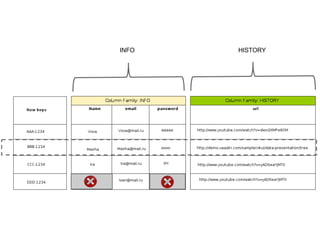
- 8. INFO HISTORY
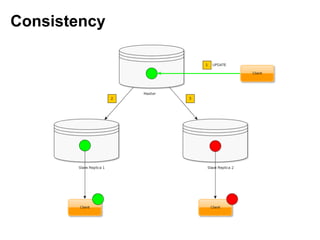
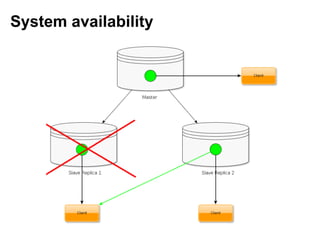
- 10. Consistency
- 13. ‚óè AC –ì–∏–±–∫–∏–µ –∑–∞–ø—Ä–æ—Å—ã, –æ—Ç–ª–∏—á–Ω–∞—è —Å–æ–≥–ª–∞—Å–æ–≤–∞–Ω–Ω–æ—Å—Ç—å, –Ω–æ –æ—Ç—Å—É—Ç—Å—Ç–≤–∏–µ –≥–æ—Ä–∏–∑–æ–Ω—Ç–∞–ª—å–Ω–æ–≥–æ –º–∞—Å—à—Ç–∞–±–∏—Ä–æ–≤–∞–Ω–∏—è: MySQL, MS SQL Server, Oracle DB ‚óè AP –ì–µ–æ–≥—Ä–∞—Ñ–∏—á–µ—Å–∫–∞—è –¥–æ—Å—Ç—É–ø–Ω–æ—Å—Ç—å: Cassandra*, MongoDB*,Couchbase ‚óè CP –ê–Ω–∞–ª–∏—Ç–∏–∫–∞, —Ä–∞—Å–ø—Ä–µ–¥–µ–ª–µ–Ω–Ω—ã–µ –≤—ã—á–∏—Å–ª–µ–Ω–∏—è: HBase, MongoDB* –ù–∞–∑–Ω–∞—á–µ–Ω–∏–µ
- 14. Redis ‚óè Open-source, –ù–ï —Ä–∞—Å–ø—Ä–µ–¥–µ–ª–µ–Ω–Ω–æ–µ, –±—ã—Å—Ç—Ä–æ–µ Key-Value —Ö—Ä–∞–Ω–∏–ª–∏—â–µ ‚óè In-memory —Å —Å–æ—Ö—Ä–∞–Ω–µ–Ω–∏–µ–º –Ω–∞ –¥–∏—Å–∫ (append only log / dump) ‚óè Master-slave —Ä–µ–ø–ª–∏–∫–∞—Ü–∏—è (backup). ‚óè –í–æ–∑–º–æ–∂–Ω–æ —Ö—Ä–∞–Ω–∏—Ç—å –∫–∞–∫ –ø—Ä–æ—Å—Ç—ã–µ –ø—Ä–∏–º–∏—Ç–∏–≤—ã, —Ç–∞–∫ –∏ —Å–ª–æ–∂–Ω—ã–µ —Å—Ç—Ä—É–∫—Ç—É—Ä—ã (—Å–ø–∏—Å–∫–∏, —Å–ª–æ–≤–∞—Ä–∏, –º–Ω–æ–∂–µ—Å—Ç–≤–∞) ‚óè –ü–æ–¥–¥–µ—Ä–∂–∏–≤–∞–µ—Ç —Å–ª–æ–∂–Ω—ã–µ –æ–ø–µ—Ä–∞—Ü–∏–∏ (—Ä–∞–±–æ—Ç–∞ —Å –±–∏—Ç–æ–≤—ã–º–∏ –º–∞—Å–∫–∞–º–∏, —Å—á–µ—Ç—á–∏–∫–∏)
- 15. Redis ‚óè –í—Å—Ç—Ä–æ–µ–Ω–Ω—ã–π —è–∑—ã–∫ Lua ‚óè TTL ‚óè –Ý–µ–∞–ª–∏–∑–æ–≤–∞–Ω –º–µ—Ö–∞–Ω–∏–∑–º Pub/Sub ‚óè –¢—Ä–∞–Ω–∑–∞–∫—Ü–∏–∏
- 16. Aerospike ‚óè Proprietary, —Ä–∞—Å–ø—Ä–µ–¥–µ–ª–µ–Ω–Ω–æ–µ, –±—ã—Å—Ç—Ä–æ–µ Key-Value —Ö—Ä–∞–Ω–∏–ª–∏—â–µ ‚óè In-memory, SSD ‚óè –®–∞—Ä–¥–∏–Ω–≥ ‚óè –í–æ–∑–º–æ–∂–Ω–æ —Ö—Ä–∞–Ω–∏—Ç—å –∫–∞–∫ –ø—Ä–æ—Å—Ç—ã–µ –ø—Ä–∏–º–∏—Ç–∏–≤—ã, —Ç–∞–∫ –∏ —Å–ª–æ–∂–Ω—ã–µ —Å—Ç—Ä—É–∫—Ç—É—Ä—ã ‚óè –ü–æ–¥–¥–µ—Ä–∂–∏–≤–∞–µ—Ç –≤—Ç–æ—Ä–∏—á–Ω—ã–µ –∏–Ω–¥–µ–∫—Å—ã
- 17. Aerospike ‚óè –í—Å—Ç—Ä–æ–µ–Ω–Ω—ã–π —è–∑—ã–∫ Lua ‚óè CP –≤ CAP —Ç–µ–æ—Ä–µ–º–µ ‚óè –ü–æ–¥–¥–µ—Ä–∂–∏–≤–∞–µ—Ç —Ä–µ–ø–ª–∏–∫–∞—Ü–∏—é –º–µ–∂–¥—É –¥–∞—Ç–∞ —Ü–µ–Ω—Ç—Ä–∞–º–∏ ‚óè –ü–æ–¥–¥–µ—Ä–∂–∏–≤–∞–µ—Ç —Å–ª–æ–∂–Ω—ã–µ –æ–ø–µ—Ä–∞—Ü–∏–∏ (compare and set, set if unmodified, set if unique)
- 18. Couchbase ‚óè Open-source, —Ä–∞—Å–ø—Ä–µ–¥–µ–ª–µ–Ω–Ω–æ–µ, –¥–æ–∫—É–º–µ–Ω—Ç–æ- –æ—Ä–∏–µ–Ω—Ç–∏—Ä–æ–≤–∞–Ω–Ω–æ–µ —Ö—Ä–∞–Ω–∏–ª–∏—â–µ, –º–æ–∂–µ—Ç –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å—Å—è –∫–∞–∫ –±—ã—Å—Ç—Ä–æ–µ KV (–∫–µ—à). ‚óè Memcache - —Å–æ–≤–º–µ—Å—Ç–∏–º–æ–µ, —Å —Å–æ—Ö—Ä–∞–Ω–µ–Ω–∏–µ–º –Ω–∞ –¥–∏—Å–∫. ‚óè Protocol: memcached + extensions ‚óè –Ø–∑—ã–∫ –∑–∞–ø—Ä–æ—Å–æ–≤ N1QL
- 19. Couchbase ‚óè –í—Å–µ –Ω–æ–¥—ã —Ä–∞–≤–Ω–æ—Ü–µ–Ω–Ω—ã (master-master replication) ‚óè –û—Ç–ª–∏—á–Ω—ã–π web –∏–Ω—Ç–µ—Ä—Ñ–µ–π—Å –¥–ª—è —É–ø—Ä–∞–≤–ª–µ–Ω–∏—è –∫–ª–∞—Å—Ç–µ—Ä–æ–º ‚óè –ò–Ω–∫—Ä–µ–º–µ–Ω—Ç–∞–ª—å–Ω—ã–π map/reduce ‚óè –Ý–µ–ø–ª–∏–∫–∞—Ü–∏—è –º–µ–∂–¥—É-–¥–∞—Ç–∞ —Ü–µ–Ω—Ç—Ä–∞–º–∏ ‚óè –í—Ç–æ—Ä–∏—á–Ω—ã–µ –∏–Ω–¥–µ–∫—Å—ã
- 20. MongoDB ‚óè Open-source, —Ä–∞—Å–ø—Ä–µ–¥–µ–ª–µ–Ω–Ω–æ–µ, –¥–æ–∫—É–º–µ–Ω—Ç–æ- –æ—Ä–∏–µ–Ω—Ç–∏—Ä–æ–≤–∞–Ω–Ω–æ–µ —Ö—Ä–∞–Ω–∏–ª–∏—â–µ ‚óè –ù–µ —Ä–∞–≤–Ω–æ–∑–Ω–∞—á–Ω—ã–µ –Ω–æ–¥—ã Master/slave replication ‚óè –ü—Ä–æ—Ç–æ–∫–æ–ª: Custom, binary (BSON) ‚óè Javascript –∏—Å–ø–æ–ª—å–∑—É–µ—Ç—Å—è –≤ –∫–∞—á–µ—Å—Ç–≤–µ —è–∑—ã–∫–∞ –∑–∞–ø—Ä–æ—Å–æ–≤ ‚óè –§—É–Ω–∫—Ü–∏–∏ –Ω–∞ —Å—Ç–æ—Ä–æ–Ω–µ —Å–µ—Ä–≤–µ—Ä–∞. –ò–Ω–∫—Ä–µ–º–µ–Ω—Ç–∞–ª—å–Ω—ã–π map/reduce ‚óè –í—Ç–æ—Ä–∏—á–Ω—ã–µ –∏–Ω–¥–µ–∫—Å—ã
- 21. HBase ‚óè Open-source, —Ä–∞—Å–ø—Ä–µ–¥–µ–ª–µ–Ω–Ω–∞—è, –≤–µ—Ä—Å–∏–æ–Ω–Ω–∞—è, –∫–æ–ª–æ–Ω–æ—á–Ω–∞—è ‚óè –•—Ä–∞–Ω–∏—Ç –º–∏–ª–ª–∏–æ–Ω—ã –∫–æ–ª–æ–Ω–æ–∫, –º–∏–ª–ª–∏–∞—Ä–¥—ã –∑–∞–ø–∏—Å–µ–π. ‚óè –Ý–∞–±–æ—Ç–∞–µ—Ç –ø–æ –≤–µ—Ä—Ö HDFS ‚óè –ò—Å–ø–æ–ª—å–∑—É–µ—Ç—Å—è –¥–ª—è –∞–Ω–∞–ª–∏—Ç–∏–∫–∏ –¥–∞–Ω–Ω—ã—Ö ‚óè CP –≤ CAP —Ç–µ–æ—Ä–µ–º–µ ‚óè –ù–µ –ø–æ–¥–¥–µ—Ä–∂–∏–≤–∞–µ—Ç –∫–ª–∞—Å—Å–∏—á–µ—Å–∫–∏–π update
- 22. HBase ‚óè –ü–æ–¥–¥–µ—Ä–∂–∏–≤–∞–µ—Ç: ‚óã Hadoop MapReduce ‚óã Random, fast read and write access ‚óã –ó–∞–ø—Ä–æ—Å—ã –ø–æ –¥–∏–∞–ø–∞–∑–æ–Ω–∞–º, —Å –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–µ–º —Ñ–∏–ª—å—Ç—Ä–æ–≤ ‚óã –ê—Ç–æ–º–∞—Ä–Ω—ã–π compare and set ‚óã Strong consistent reads and writes ‚óè –ù–µ –ø–æ–¥–¥–µ—Ä–∂–∏–≤–∞–µ—Ç: ‚óã ACID —Ç—Ä–∞–Ω–∑–∞–∫—Ü–∏–∏
- 23. Cassandra ‚óè Open-source, —Ä–∞—Å–ø—Ä–µ–¥–µ–ª–µ–Ω–Ω–∞—è, –∫–æ–ª–æ–Ω–æ—á–Ω–∞—è ‚óè –•—Ä–∞–Ω–∏—Ç –º–∏–ª–ª–∏–æ–Ω—ã –∫–æ–ª–æ–Ω–æ–∫, –º–∏–ª–ª–∏–∞—Ä–¥—ã –∑–∞–ø–∏—Å–µ–π. ‚óè –°–∞–º–æ–¥–æ—Å—Ç–∞—Ç–æ—á–Ω–∞ (–≤ –æ—Ç–ª–∏—á–∏–∏ –æ—Ç HBase –∫–æ—Ç–æ—Ä–∞—è —Ä–∞–±–æ—Ç–∞–µ—Ç –ø–æ –≤–µ—Ä—Ö HDFS) ‚óè AP/CP –≤ CAP —Ç–µ–æ—Ä–µ–º–µ ‚óè –û—á–µ–Ω—å —Ö–æ—Ä–æ—à–∞ –¥–ª—è —Ä–µ–ø–ª–∏–∫–∞—Ü–∏–∏ –¥–∞–Ω–Ω—ã—Ö –º–µ–∂–¥—É –¥–∞—Ç–∞ —Ü–µ–Ω—Ç—Ä–∞–º–∏
- 24. Cassandra ‚óè –ü–æ–¥–¥–µ—Ä–∂–∏–≤–∞–µ—Ç: ‚óã –Ø–∑—ã–∫ CQL (–±–µ–∑ JION) ‚óã –ö–æ–Ω—Ñ–∏–≥—É—Ä–∏—Ä—É–µ–º–∞—è consistency ‚óã Random, fast read and write access ‚óã –ê—Ç–æ–º–∞—Ä–Ω—ã–π compare and set, counters ‚óã MapReduce (–Ω—É–∂–µ–Ω Hadoop) ‚óã –í—Ç–æ—Ä–∏—á–Ω—ã–µ –∏–Ω–¥–µ–∫—Å—ã* ‚óè –ù–µ –ø–æ–¥–¥–µ—Ä–∂–∏–≤–∞–µ—Ç: ‚óã ACID —Ç—Ä–∞–Ω–∑–∞–∫—Ü–∏–∏
- 25. HBase vs Cassandra –≠—Ç–æ –±—Ä–∞—Ç—å—è, –∞ –Ω–µ –∫–æ–Ω–∫—É—Ä–µ–Ω—Ç—ã Cassandra - AP (–¥–æ—Å—Ç—É–ø–Ω–æ—Å—Ç—å) HBase - CP (–∞–Ω–∞–ª–∏—Ç–∏–∫–∞)
- 26. Neo4J ‚óè Open-source, –≥—Ä–∞—Ñ–æ–≤–æ–µ —Ö—Ä–∞–Ω–∏–ª–∏—â–µ ‚óè Persistent disk-based storage written in Java ‚óè ACID —Ç—Ä–∞–Ω–∑–∞–∫—Ü–∏–∏ ‚óè –ú–∏–ª–ª–∏–∞—Ä–¥—ã –≤–µ—Ä—à–∏–Ω –Ω–∞ –æ–¥–Ω–æ–º —Ö–æ—Å—Ç–µ. ‚óè –ò–Ω–¥–µ–∫—Å—ã –∏ –∞—Ç—Ä–∏–±—É—Ç—ã —Å–≤—è–∑–∏. ‚óè –ú–æ—â–Ω—ã–π –ø–æ–∏—Å–∫ –ø–æ –≥—Ä–∞—Ñ—É —á–µ—Ä–µ–∑ API –∏ —è–∑—ã–∫ –∑–∞–ø—Ä–æ—Å–æ–≤ –ø–æ –≥—Ä–∞—Ñ—É Cypher
- 27. –¢—Ä–∞–Ω–∑–∞–∫—Ü–∏–∏, –∞–≥—Ä–µ–≥–∞—Ç—ã, JOIN ‚óè –¢—Ä–∞–Ω–∑–∞–∫—Ü–∏–∏ –Ω–µ –≤—Å–µ–≥–¥–∞ –Ω—É–∂–Ω—ã. ‚óè –ö–æ–≥–¥–∞ –µ—Å—Ç—å —Å–∞–º–æ–¥–æ—Å—Ç–∞—Ç–æ—á–Ω—ã–µ –∞–≥—Ä–µ–≥–∞—Ç—ã. ‚óè –ë–ª–æ–∫–∏—Ä–æ–≤–∫–∏ –Ω–∞ —É—Ä–æ–≤–Ω–µ –∞–≥—Ä–µ–≥–∞—Ç–æ–≤. ‚óè JOIN -> Map-Reduce
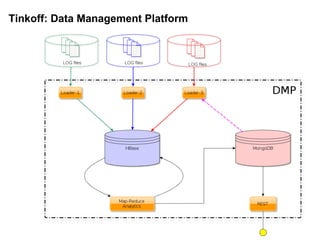
- 28. –í –ø—Ä–æ–µ–∫—Ç–∞—Ö: Tinkoff digital ‚óè HBase - –∞–Ω–∞–ª–∏—Ç–∏–∫–∞ (—Å–æ—Ä—Ç–∏—Ä–æ–≤–∞–Ω–Ω—ã–µ –¥–∞–Ω–Ω—ã–µ, —Ä–∞–Ω–¥–æ–º–Ω—ã–π –¥–æ—Å—Ç—É–ø, –≤ —Å—Ä–∞–≤–Ω–µ–Ω–∏–∏ —Å –ª–æ–≥–∞–º–∏) ‚óè MongoDB - –∫—É–ø–∏–ª–∏—Å—å –Ω–∞ —à–∞—Ä–¥–∏–Ω–≥ –∏ –∏–Ω–¥–µ–∫—Å—ã (–ø–ª–æ—Ö–∞—è –∏–¥–µ—è)
- 29. Tinkoff: Data Management Platform
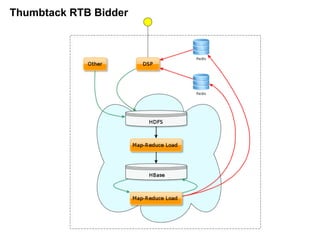
- 30. –í –ø—Ä–æ–µ–∫—Ç–∞—Ö: Thumbtack RTB Bidder ‚óè Redis –ë—ã—Å—Ç—Ä–æ–µ KV —Ö—Ä–∞–Ω–∏–ª–∏—â–µ –¥–ª—è –æ–ø–µ—Ä–∞—Ç–∏–≤–Ω–æ–≥–æ –¥–æ—Å—Ç—É–ø–∞ –∫ —Å—Ç–∞—Ç–∏—Å—Ç–∏–∫–µ ‚óè HBase –∞–Ω–∞–ª–∏—Ç–∏–∫–∞ –∏ —Ä–∞—Å–ø—Ä–µ–¥–µ–ª–µ–Ω–Ω—ã–µ –≤—ã—á–∏—Å–ª–µ–Ω–∏—è
- 32. –Ý–µ–∑—é–º–µ –ù—É–∂–µ–Ω –±—ã—Å—Ç—Ä—ã–π –¥–æ—Å—Ç—É–ø –∫ –¥–∞–Ω–Ω—ã–º? Redis, Aerospoke, Couchbase BigData? HBase, Cassandra –Ý–∞–∑–Ω–æ-—Å—Ç—Ä—É–∫—Ç—É—Ä–∏—Ä–æ–≤–∞–Ω–Ω—ã–µ –¥–∞–Ω–Ω—ã–µ –∏ –≥–∏–±–∫–∞—è —Å–∏—Å—Ç–µ–º–∞ –∑–∞–ø—Ä–æ—Å–æ–≤? MongoDB
- 33. –í–æ–ø—Ä–æ—Å—ã?