NoSQL ņ£äņŚÉņä£ MMORPG Ļ░£ļ░£ĒĢśĻĖ░
ŌĆó
27 likesŌĆó5,195 views

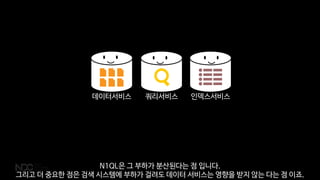
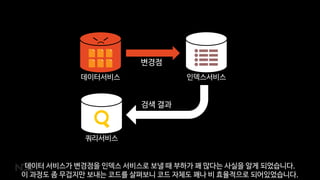
ŃĆłņĢ╝ņāØņØś ļĢģ: ļōĆļ×æĻ│ĀŃĆēļŖö ļ®öņØĖ DBļĪ£ Couchbaseļź╝ ņō░Ļ│Ā ņ׳ņŖĄļŗłļŗż. CouchbaseņŚÉņä£ Ļ▓īņ×äņØä Ļ░£ļ░£ĒĢśļ®┤ņä£ ņ׳ņŚłļŹś ņĀ£ņĢĮĻ│╝ ĻĘĖ ņĀ£ņĢĮņØä ĒĢ┤Ļ▓░ĒĢśĻĖ░ ņ£äĒĢ£ ļ░®ļ▓ĢļōżņØä ņĀĢļ”¼ĒĢ┤ ļ│┤ņĢśņŖĄļŗłļŗż.













![Couchbase
{
name: Ļ╣ĆļåŹļČĆ
job: ļåŹļČĆ
level: 34
items: [
{item:Ļ│ĪĻ┤ŁņØ┤,
level:20},
{item:ļ░Ćņ¦Üļ¬©ņ×É,
level:15}
]
}
{
name: Ļ╣ĆĻĄ░ņØĖ
job: ĻĄ░ņØĖ
level: 27
items: [
{item:ĻĄ░ļ▓łņżä,
level:1}
]
}
{
name: Ļ╣ĆĒĢÖņāØ
job: ĒĢÖņāØ
level: 29
items: []
}
ļ░śļ®┤ CouchbaseļŖö JSON ĻĖ░ļ░śņØś document ļŹ░ņØ┤Ēä░ļ▓ĀņØ┤ņŖżņØ┤ĻĖ░ ļĢīļ¼ĖņŚÉ
ņŚ░Ļ┤ĆļÉ£ ļŹ░ņØ┤Ēä░ļź╝ ļ¼Čņ¢┤ ĒĢśļéśņØś ļ¼Ėņä£ņŚÉ Ļ░ÖņØ┤ ļ│┤Ļ┤ĆĒĢśļŖö Ļ▓ĮņÜ░Ļ░Ć ļ¦ÄņŖĄļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-15-320.jpg)
![Couchbase
{
name: Ļ╣ĆļåŹļČĆ
job: ļåŹļČĆ
level: 34
items: [
{item:Ļ│ĪĻ┤ŁņØ┤,
level:20},
{item:ļ░Ćņ¦Üļ¬©ņ×É,
level:15}
]
}
1
2
3
4
5
6
7
8
class Item:
item = declare(unicode)
level = declare(int)
class Entity:
job = declare(unicode)
level = declare(int)
items = declare(list(Item))
JSONņ£╝ļĪ£ ņĀĆņןĒĢĀ ļĢīņØś Ļ░Ćņן Ēü░ ĒŖ╣ņ¦ĢņØĆ ļĪ£ņ¦üņØś ļŹ░ņØ┤Ēä░ ĻĄ¼ņĪ░ņÖĆ ņ£Āņé¼ĒĢśļŗżļŖö ņĀÉ ņ×ģļŗłļŗż.
JSONņØ┤ĻĖ░ ļĢīļ¼ĖņŚÉ ļŹ░ņØ┤Ēä░ļ▓ĀņØ┤ņŖż ņé¼ņÜ®ņ×ÉĻ░Ć ņ×äņØśļĪ£ ĻĄ¼ņĪ░ļź╝ ņĀĢĒĢĀ ņłś ņ׳ĻĖ░ ļĢīļ¼ĖņØ┤ņŻĀ.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-16-320.jpg)
![Couchbase
{
name: Ļ╣ĆļåŹļČĆ
job: ļåŹļČĆ
level: 34
items: [
{item:Ļ│ĪĻ┤ŁņØ┤,
level:20},
{item:ļ░Ćņ¦Üļ¬©ņ×É,
level:15}
]
}
1
2
3
4
5
6
7
8
class Item:
item = declare(unicode)
level = declare(int)
class Entity:
job = declare(unicode)
level = declare(int)
items = declare(list(Item))
ļĢīļ¼ĖņŚÉ RDBņÖĆ ļŗżļź┤Ļ▓ī ļ®öļ¬©ļ”¼ ņāüņØś ļŹ░ņØ┤Ēä░ņÖĆ DBņāüņØś ļŹ░ņØ┤Ēä░ņØś ĻĄ¼ņĪ░ļź╝ ņØ╝ņ╣śņŗ£Ēé¼ ņłś ņ׳ņ¢┤
Ļ▓īņ×ä ĒöīļĀłņØ┤ ļĪ£ņ¦ü Ļ░£ļ░£ņØ┤ ĻĄēņןĒ׳ ņłśņøöĒĢ®ļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-17-320.jpg)






![Couchbase
{
name: Ļ╣ĆļåŹļČĆ
job: ļåŹļČĆ
level: 34
emotion: ļČäļģĖ
items: [
{item:Ļ│ĪĻ┤ŁņØ┤,
level:20},
{item:ļ░Ćņ¦Üļ¬©ņ×É,
level:15}
]
}
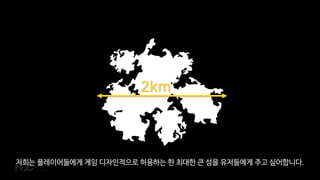
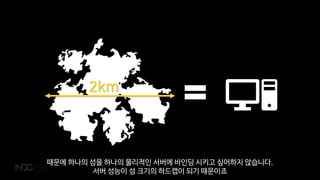
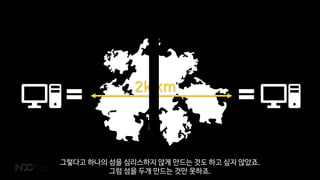
CouchbaseņŚÉņä£ļÅä ĒĢśļéśņØś ļ¼Ėņä£ļź╝ ļ│ĆĻ▓ĮĒĢĀ ļĢÉ ACID ĒŖĖļ×£ņףņģśņØ┤ļØ╝Ļ│Ā ĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.
ņØĮĻ│Ā, ņō░Ļ│Ā, ņĀĆņןĒĢśļ®┤ ļÉśļŗłĻ╣īņÜö. ļ¼Ėņä£ ļŗ©ņ£äļĪ£ ļÅÖņ×æĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ļ¼Ėņä£Ļ░Ć ņĀĆņןņØ┤ ļÉśļŗżĻ░Ć ļ¦ÉĻ▒░ļéś ĒĢśļŖö ņØ╝ņØĆ ņŚåņŖĄļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-26-320.jpg)

![Couchbase
{
name: Ļ╣ĆļåŹļČĆ
job: ļåŹļČĆ
level: 34
emotion: ļČäļģĖ
items: [
{item:Ļ│ĪĻ┤ŁņØ┤,
level:20},
{item:ļ░Ćņ¦Üļ¬©ņ×É,
level:15}
]
}](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-30-320.jpg)
![Couchbase
{
name: Ļ╣ĆļåŹļČĆ
job: ļåŹļČĆ
level: 34
emotion: ļČäļģĖ
items: [
{item:Ļ│ĪĻ┤ŁņØ┤,
level:20},
{item:ļ░Ćņ¦Üļ¬©ņ×É,
level:15}
]
}
{
name: Ļ╣ĆĻĄ░ņØĖ
job: ĻĄ░ņØĖ
level: 27
emotion: ļČäļģĖ
items: [
{item:ĻĄ░ļ▓łņżä,
level:1}
]
}
{
name: Ļ╣ĆĒĢÖņāØ
job: ĒĢÖņāØ
level: 29
items: []
}
ļĢīļ¼ĖņŚÉ ņŚ¼ļ¤¼ Ļ░£ņØś ļ¼Ėņä£ļź╝ ņĀĆņןĒĢśļŗż ļ│┤ļ®┤ ļ¬ć Ļ░£ļŖö ņŗżĒī©ĒĢĀ ņłśļÅä ņ׳ņŻĀ.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-31-320.jpg)
![Couchbase
{
name: Ļ╣ĆļåŹļČĆ
job: ļåŹļČĆ
level: 34
emotion: ļČäļģĖ
items: [
{item:Ļ│ĪĻ┤ŁņØ┤,
level:20},
{item:ļ░Ćņ¦Üļ¬©ņ×É,
level:15}
]
}
JSON ņłśņ¢ĄĻ░£
ļŹöĻĄ░ļŗżļéś ļ¼Ėņä£Ļ░Ć ņłśņ¢ĄĻ░£ ņ»ż ļÉ£ļŗżļ®┤ ņŗżĒī©ĒĢ£ Ļ▓āļōżņØä ņ×¼ņŗ£ļÅäĒĢ┤ņä£ ņĀĆņןĒĢśļŖö Ļ▓āļÅä ņēĮņ¦Ć ņĢŖņØĆ ņØ╝ņØ┤ ļÉ®ļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-32-320.jpg)

![on-demand migration
{
version: 0
name: Ļ╣ĆļåŹļČĆ
job: ļåŹļČĆ
level: 34
items: [
{item:Ļ│ĪĻ┤ŁņØ┤,
level:20},
{item:ļ░Ćņ¦Üļ¬©ņ×É,
level:15}
]
}
1
2
3
4
5
6
7
8
9
class Item:
item = declare(unicode)
level = declare(int)
class Entity:
__version__ = 0
job = declare(unicode)
level = declare(int)
items = declare(list(Item))
on-demand migratioņØĆ ļ¼Ėņä£ņØś ļŹ░ņØ┤Ēä░ņÖĆ ļ®öļ¬©ļ”¼ ņāüņØś ļŹ░ņØ┤Ēä░Ļ░Ć ļÅÖņØ╝ĒĢśļŗżļŖö ļČĆļČäņŚÉņä£ ņČ£ļ░£ĒĢ®ļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-34-320.jpg)
![on-demand migration
{
version: 0
name: Ļ╣ĆļåŹļČĆ
job: ļåŹļČĆ
level: 34
items: [
{item:Ļ│ĪĻ┤ŁņØ┤,
level:20},
{item:ļ░Ćņ¦Üļ¬©ņ×É,
level:15}
]
}
1
2
3
4
5
6
7
8
9
class Item:
item = declare(unicode)
level = declare(int)
class Entity:
__version__ = 0
job = declare(unicode)
level = declare(int)
items = declare(list(Item))
ņĀĆņןļÉ£ ļŹ░ņØ┤Ēä░ņÖĆ ņĢĀĒöīļ”¼ņ╝ĆņØ┤ņģśņŚÉņä£ ņäĀņ¢ĖĒĢ£ ņŖżĒéżļ¦łņŚÉ ļ▓äņĀäņØä ļČĆņŚ¼ĒĢśĻ│Ā
ļæśņØ┤ Ļ░ÖņĢäņ¦ĆļÅäļĪØ ņĢĀĒöīļ”¼ņ╝ĆņØ┤ņģśņŚÉņä£ Ļ┤Ćļ”¼ĒĢśļŖö Ļ▓üļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-35-320.jpg)

![on-demand migration
1
2
3
4
5
6
7
8
9
10
@migrate(Entity, 0, 1)
def migration(document):
document[ŌĆśemotionŌĆÖ] = ŌĆśļČäļģĖŌĆÖ
def load(cls, key):
doc = db.load(key)
if doc[ŌĆśversionŌĆÖ] != cls.version:
doc = migrate(doc[ŌĆśversionŌĆÖ], cls.version, doc)
db.update(key, doc)
return unpack(doc)
ļ▓äņĀäņØ┤ 0ņŚÉņä£ 1ļĪ£ ņś¼ļØ╝Ļ░ł ļĢī ļ¼Ėņä£ņØś ļ¦łņØ┤ĻĘĖļĀłņØ┤ņģśņØä ņ¢┤ļ¢╗Ļ▓ī ĒĢĀņ¦Ć ĒĢ©ņłśļĪ£ ļ¦īļōżņ¢┤ ļæĪļŗłļŗż.
ĻĘĖļ”¼Ļ│Ā ļ¼Ėņä£ļź╝ ņĢĀĒöīļ”¼ņ╝ĆņØ┤ņģśņŚÉņä£ ņØĮņØä ļĢī ņĀĆņןļÉ£ ļ▓äņĀäņØ┤ Ēśäņ×¼ņÖĆ ļŗżļź┤ļ®┤ ĒĢ┤ļŗ╣ ĒĢ©ņłśļź╝ ņŗżĒ¢ēņŗ£ĒéĄļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-37-320.jpg)
![on-demand migration
{
version: 0
name: Ļ╣ĆļåŹļČĆ
job: ļåŹļČĆ
level: 34
items: [
{item:Ļ│ĪĻ┤ŁņØ┤,
level:20},
{item:ļ░Ćņ¦Üļ¬©ņ×É,
level:15}
]
}
{
version: 1
name: Ļ╣ĆĻĄ░ņØĖ
job: ĻĄ░ņØĖ
level: 27
emotion: ļČäļģĖ
items: [
{item:ĻĄ░ļ▓łņżä,
level:1}
]
}
{
version: 1
name: Ļ╣ĆĒĢÖņāØ
job: ĒĢÖņāØ
level: 29
emotion: ļČäļģĖ
items: []
}
ņØ┤ļĀćĻ▓ī ļÉśļ®┤ ļŗżļźĖ ļ▓äņĀäņØś ļŹ░ņØ┤Ēä░Ļ░Ć Ļ│ĄņĪ┤ĒĢĀ ņłś ņ׳ņ¦Ćļ¦ī, ņ¢┤ņ░©Ēö╝ ņØĮņ¢┤ņä£ ņōĖ ļĢīļŖö ļ▓äņĀäņØ┤ ļ¦×ņČ░ņ¦Ćļŗł Ļ┤£ņ░«ņŖĄļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-38-320.jpg)















![{
name: B
job: ļ░®ļ×æņ×É
exp: 50
}
{
promises: [
(add_exp, 30)
(add_exp, 20)
(add_exp, 40)
]
}
ĒĢśļéśņØś ņ║Éļ”ŁĒä░ņŚÉĻ▓īļŖö ņ¢ĖņĀ£ļéś ĒĢśļéśņØś promise ĒüÉļź╝ ļ¦īļōżņ¢┤ ļæÉĻ│Ā
ņŗ£ņĢ╝ņŚÉ ņŚåļŖö ņ║Éļ”ŁĒä░ņŚÉĻ▓īļŖö ņĢĮņåŹļ¦ī Ļ▒Ėņ¢┤ļæÉļ®┤](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-72-320.jpg)
![{
name: B
job: ļ░®ļ×æņ×É
exp: 140
}
{
promises: []
}
ĒĢ┤ļŗ╣ ņ║Éļ”ŁĒä░Ļ░Ć ņĀæņåŹĒ¢łņØä ļĢī ņĢīņĢäņä£ ĒĢ┤ļŗ╣ ĒüÉņØś ņ×æņŚģļōżņØä ņłśĒ¢ēĒĢśļŖö ļ░®ņŗØņØ┤ņŻĀ.
ņØ┤ļ»Ė ņĀæņåŹ ņżæņØ┤ņŚłļŗżļ®┤ ļ░öļĪ£ ņŗżĒ¢ēĒĢĀ Ļ▓ā ņ×ģļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-73-320.jpg)



![{
name: Ļ░Ćļ░®
items: []
}
{
name: ņāüņ×É
items: [
Ļ░ĆņŻĮ ņןĒÖö
]
}
ĒĢśņ¦Ćļ¦ī ļæÉĻ░£ņØś ļ¼Ėņä£ļź╝ ļÅÖņŗ£ņŚÉ ņĀĆņןĒĢĀ ņØ╝ņØĆ ĒĢäņÜöĒĢśĻĖ░ ļ¦łļĀ©ņ×ģļŗłļŗż.
ņāüņ×ÉņŚÉņä£ Ļ░Ćļ░®ņ£╝ļĪ£ ņĢäņØ┤Ēģ£ņØä ņś«ĻĖ░ļŖö Ļ▓āņØ┤ ļīĆĒæ£ņĀüņØĖ ņśłņØ┤ņŻĀ.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-77-320.jpg)
![{
name: Ļ░Ćļ░®
items: [
Ļ░ĆņŻĮ ņןĒÖö
]
}
{
name: ņāüņ×É
items: []
}
ņØ┤ļĀćĻ▓ī ļ┐ģ ĒĢśĻ│Ā ņś«Ļ▓©ņ¦Ćļ®┤ ņóŗĻ▓Āņ¦Ćļ¦ī, CouchbaseņŚÉņä£ļŖö ņØ┤ Ļ│╝ņĀĢņØ┤ ņēĮņ¦Ć ņĢŖņŖĄļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-78-320.jpg)
![{
name: Ļ░Ćļ░®
items: []
}
{
name: ņāüņ×É
items: []
}
ņĢäņØ┤Ēģ£ņØ┤ ņåīņŗżļÉśļŖö ļ¼ĖņĀ£Ļ░Ć ņāØĻ╣üļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-80-320.jpg)
![{
name: Ļ░Ćļ░®
items: [
Ļ░ĆņŻĮ ņןĒÖö
]
}
{
name: ņāüņ×É
items: [
Ļ░ĆņŻĮ ņןĒÖö
]
}
ņĢäņØ┤Ēģ£ ļ│Ąņé¼Ļ░Ć ņØ╝ņ¢┤ļéśņŻĀ.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-82-320.jpg)

![{
name: Ļ░Ćļ░®
items: []
}
{
name: ņāüņ×É
items: [
Ļ░ĆņŻĮ ņןĒÖö
]
}
BASE ĒŖĖļ×£ņףņģśņØś ņÜ®ņ¢┤ļź╝ ņØ╝ņØ╝Ē׳ ļ©╝ņĀĆ ņØ┤ĒĢ┤ĒĢśļŖö Ļ▓ā ļ│┤ļŗż ņśłņŗ£ļź╝ ļ│┤Ļ│Ā ņÜ®ņ¢┤ļź╝ ļŗżņŗ£ ļ│┤ļ®┤
ņØ┤ĒĢ┤Ļ░Ć ņē¼ņÜĖ Ļ▓ā Ļ░ÖņŖĄļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-84-320.jpg)
![1. ņØ┤ļÅÖ ļ¬ģņäĖ ļ¼Ėņä£ ņāØņä▒
{
name: Ļ░Ćļ░®
items: []
}
{
name: ņāüņ×É
items: [
Ļ░ĆņŻĮ ņןĒÖö
]
}
{
id: transfer_001
source: ņāüņ×É
destination: Ļ░Ćļ░®
state: pending
items: [
Ļ░ĆņŻĮ ņןĒÖö
]
}
ņĢäņØ┤Ēģ£ņØä ņś«ĻĖ░ļĀżĻ│Ā ĒĢśļ®┤ ņØ╝ļŗ© ņĢäņØ┤Ēģ£ ņØ┤ļÅÖ ņ×Éņ▓┤ņŚÉ ļīĆĒĢ£ ļ¬ģņäĖ ļ¼Ėņä£ļź╝ ļ¦īļōżņ¢┤ DBņŚÉ ņĀĆņןĒĢ®ļŗłļŗż.
ņČ£ļ░£ņ¦ĆņÖĆ ļ¬®ņĀüņ¦Ć, ņĢäņØ┤Ēģ£ ĻĘĖļ”¼Ļ│Ā ņØ┤ļÅÖņŚÉ ļīĆĒĢ£ Ēśäņ×¼ ņāüĒā£ļÅä ļäŻņ¢┤ļæ¼ņĢ╝Ļ▓ĀņŻĀ.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-85-320.jpg)
![2. ņāüņ×ÉņÖĆ ļ¬ģņäĖ ļ¼Ėņä£ļź╝ ņŚ░Ļ▓░ĒĢśĻĖ░
{
name: Ļ░Ćļ░®
items: []
}
{
name: ņāüņ×É
items: []
transferring:
transfer_001
}
{
id: transfer_001
source: ņāüņ×É
destination: Ļ░Ćļ░®
state: pending
items: [
Ļ░ĆņŻĮ ņןĒÖö
]
}
ĻĘĖ ļŗżņØīņŚö ļ©╝ņĀĆ ņČ£ļ░£ņ¦ĆņŚÉņä£ ņĢäņØ┤Ēģ£ņØä ļ╣╝Ļ│Ā ļ¬ģņäĖ ļ¼Ėņä£ņÖĆņØś ņŚ░Ļ▓░ Ļ│Āļ”¼ļź╝ ļ¦īļōŁļŗłļŗż.
Ēś╣ņŗ£ ņŗżĒī©ĒĢ£ļŗżļ®┤ ņØ┤ ļ¬ģņäĖļź╝ ņ░ĖĻ│ĀĒĢ┤ņä£ ņøÉļל ņāüĒā£ļĪ£ ļ│ĄņøÉĒĢĀ ņłśļÅä ņ׳Ļ│Ā, ļŗżņŗ£ ņØ┤ļÅÖņØä ņØ┤ņ¢┤ņä£ ņ¦äĒ¢ēĒĢĀ ņłśļÅä ņ׳ņŖĄļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-86-320.jpg)
![3. Ļ░Ćļ░®Ļ│╝ ļ¬ģņäĖ ļ¼Ėņä£ļź╝ ņŚ░Ļ▓░ĒĢśĻĖ░
{
name: Ļ░Ćļ░®
items: []
transferring:
transfer_001
}
{
name: ņāüņ×É
items: []
transferring:
transfer_001
}
{
id: transfer_001
source: ņāüņ×É
destination: Ļ░Ćļ░®
state: pending
items: [
Ļ░ĆņŻĮ ņןĒÖö
]
}
ļÅäņ░®ņ¦ĆņŚÉļÅä ņØ┤ļÅÖņØä ļ░śņśüĒĢ®ļŗłļŗż. ņĢäņØ┤Ēģ£ ļČĆĒä░ ļäŻņ£╝ļ®┤ ņĢäņ¦ü ĒöäļĪ£ņäĖņŖżĻ░Ć ļüØļéśņ¦Ć ņĢŖņĢśļŖöļŹ░ļÅä
ņĢäņØ┤Ēģ£ņØä ņé¼ņÜ®ĒĢ┤ ļ▓äļ”¼ļŖö ņØ╝ņØ┤ ņ׳ņØä ņłś ņ׳ņ£╝ļŗł ļ¬ģņäĖ ļ¼Ėņä£ļ¦ī ļ¦üĒü¼ļĪ£ Ļ▒Ėņ¢┤ ļæĪļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-87-320.jpg)
![4. ļ¬ģņäĖ ņāüĒā£ ļ│ĆĻ▓Į
{
name: Ļ░Ćļ░®
items: []
transferring:
transfer_001
}
{
name: ņāüņ×É
items: []
transferring:
transfer_001
}
{
id: transfer_001
source: ņāüņ×É
destination: Ļ░Ćļ░®
state: committed
items: [
Ļ░ĆņŻĮ ņןĒÖö
]
}
ņ¢æņ¬Į ņØĖļ▓żĒåĀļ”¼ņŚÉ ļ¬ģņäĖ ļ¼Ėņä£Ļ░Ć ļŗż ļ¦üĒü¼ ļÉ£ Ļ▓āņØä ĒÖĢņØĖĒĢśļ®┤ ņāüĒā£ļź╝ committedļĪ£ ļ░öĻ┐ēļŗłļŗż.
ņé¼ņŗżņāü ņØ┤ļÅÖņØ┤ ņÖäļŻīļÉ£ Ļ▓āņØ┤ĻĖ░ ļĢīļ¼ĖņØ┤ņŻĀ.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-88-320.jpg)
![5. ņĢäņØ┤Ēģ£ ņØ┤ļÅÖ ņÖäļŻī
{
name: Ļ░Ćļ░®
items: [
Ļ░ĆņŻĮ ņןĒÖö
]
}
{
name: ņāüņ×É
items: []
}
{
id: transfer_001
source: ņāüņ×É
destination: Ļ░Ćļ░®
state: committed
items: [
Ļ░ĆņŻĮ ņןĒÖö
]
}
ļ¬ģņäĖ ļ¼Ėņä£ņŚÉ committedĻ░Ć ĻĖ░ļĪØļÉśņŚłņ£╝ļŗł Ļ░ü ņØĖļ▓żĒåĀļ”¼ļŖö ņØ┤ļÅÖ ļ¬ģņäĖļź╝ ņ░ĖĻ│ĀĒĢ┤ņä£
Ļ▓░Ļ│╝ļź╝ ņŖżņŖżļĪ£ ļ░śņśüĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-89-320.jpg)







![{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
[1, 1]: Ļ╣Ćņä£ļ»╝
]
}
Grid ļ¼Ėņä£ļź╝ ņé┤ĒÄ┤ļ│┤ļ®┤ ļīĆņČ® ņØ┤ņÖĆ Ļ░ÖņØĆ ļ¬©ņŖĄņØä ĒĢśĻ│Ā ņ׳ņŖĄļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-98-320.jpg)
![{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
[1, 1]: Ļ╣Ćņä£ļ»╝
]
}
{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
[1, 1]: Ļ╣Ćņä£ļ»╝
]
}
{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
[1, 1]: Ļ╣Ćņä£ļ»╝
]
}
{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
[1, 1]: Ļ╣Ćņä£ļ»╝
]
}
ņØ┤ļ¤░ Ļ▓āņØ┤ ņŚ¼ļ¤¼ Ļ░£ ļ¬©ņŚ¼ ĒĢśļéśņØś ļĢģ ņ”ē Gridļź╝ ņØ┤ļŻ©ņŻĀ.
ļŹö Ēü¼Ļ▓ī ļ│┤ļ®┤ ņä¼ ņŚ¼ļ¤¼ Ļ░£ļĪ£ ņØ┤ļŻ©ņ¢┤ņ¦ä ļōĆļ×æĻ│ĀļŖö Ļ▓░ĻĄŁ ņØ┤ Chunk ļŗ©ņ£ä ļ¼Ėņä£ļōżņØś ļ¬©ņØīņØ┤ļØ╝Ļ│Ā ĒĢśĻ▓ĀņŖĄļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-99-320.jpg)

![MapReduce
map(f, [i1, i2, i3, ...]) = [f(i1), f(i2), f(i3) ...]
reduce(g, [i1, i2, i3, ...]) = g(i1, g(i2, g(i3, ...)))
mapĻ│╝ reduceļŖö ņŚ¼ļ¤¼ļČäņØ┤ ņĢäņŗ£ļŖö ĻĘĖĻ▓āņØ┤ ļ¦×ņŖĄļŗłļŗż.
ņØ┤Ļ▒Ė ņ¢┤ļ¢╗Ļ▓ī ĒÖ£ņÜ®ĒĢ£ļŗżļŖö Ļ▓āņØ╝Ļ╣īņÜö?](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-103-320.jpg)
![{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
[1, 1]: Ļ╣Ćņä£ļ»╝
]
}
{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
[1, 1]: Ļ╣Ćņä£ļ»╝
]
}
{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
[1, 1]: Ļ╣Ćņä£ļ»╝
]
}
{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
[1, 1]: Ļ╣Ćņä£ļ»╝
]
}
ņØ┤ļ”ä ņ£äņ╣ś
Ļ╣ĆļČĆņ×É [3, 2]
Ļ╣ĆļČĆņ×É [2, 1]
Ļ╣ĆļČĆņ×É [2, 2]
Ļ╣ĆļČĆņ×É [3, 3]
Ļ╣ĆļČĆņ×É [1, 2]
Ļ╣Ćņä£ļ»╝ [1, 1]
ŌĆ” ŌĆ”
ņÜ░ļ”¼ļŖö ņØ┤ļ¤░ ņŚ¼ļ¤¼ Ļ░£ņØś ļ¼Ėņä£ļĪ£ļČĆĒä░ ņśżļźĖņ¬Į Ļ░ÖņØĆ ĒģīņØ┤ļĖöņØä ņ¢╗ĻĖ░ļź╝ ņøÉĒĢśņŻĀ](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-104-320.jpg)
![{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
[1, 1]: Ļ╣Ćņä£ļ»╝
]
}
ņÜ░ņäĀ ĒĢśļéśņØś ļ¼Ėņä£ļ¦ī ļīĆņāüņ£╝ļĪ£ ļåōĻ│Ā ĒĢ┤ļ│╝Ļ╣īņÜö?](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-105-320.jpg)
![1
2
3
4
5
6
function(doc)
for (var cell in doc[ŌĆśestatesŌĆÖ]) {
var owner = doc[ŌĆśestatesŌĆÖ][cell]
emit(owner, cell)
}
}
ņØ┤ļ¤░ ĒĢ©ņłśļ®┤ ņČ®ļČäĒĢĀ Ļ▓ā Ļ░ÖļäżņÜö! ĒÄĖņØśņāü ņÜö ĒĢ©ņłśļź╝ FļØ╝Ļ│Ā Ēæ£ĻĖ░ĒĢśĻ▓ĀņŖĄļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-106-320.jpg)
![1
2
3
4
5
{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
[1, 1]: Ļ╣Ćņä£ļ»╝
]
}
( )
ņØ┤ļ”ä ņ£äņ╣ś
Ļ╣ĆļČĆņ×É [3, 2]
Ļ╣ĆļČĆņ×É [2, 1]
Ļ╣ĆļČĆņ×É [2, 2]
Ļ╣Ćņä£ļ»╝ [1, 1]
F
ĒĢśļéśņØś ļ¼Ėņä£ļź╝ FņŚÉ ļäŻņ£╝ļ®┤ ņśżļŖśņ¬Į ņ▓śļ¤╝ ļŹ░ņØ┤Ēä░Ļ░Ć ļéśņśżĻ▓ĀļäżņÜö.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-107-320.jpg)
![F
{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
[1, 1]: Ļ╣Ćņä£ļ»╝
]
}
{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
[1, 1]: Ļ╣Ćņä£ļ»╝
]
}
{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
[1, 1]: Ļ╣Ćņä£ļ»╝
]
}
{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
[1, 1]: Ļ╣Ćņä£ļ»╝
]
}
map( , )
ņØ┤ļ”ä ņ£äņ╣ś
Ļ╣ĆļČĆņ×É [3, 2]
Ļ╣ĆļČĆņ×É [2, 1]
Ļ╣ĆļČĆņ×É [2, 2]
Ļ╣ĆĒÅēļ▓ö [1, 1]
ņØ┤ļ”ä ņ£äņ╣ś
Ļ╣ĆļČĆņ×É [3, 2]
Ļ╣ĆļČĆņ×É [2, 1]
Ļ╣ĆļČĆņ×É [2, 2]
Ļ╣ĆĒÅēļ▓ö [1, 1]
ņØ┤ļ”ä ņ£äņ╣ś
Ļ╣ĆļČĆņ×É [3, 2]
Ļ╣ĆļČĆņ×É [2, 1]
Ļ╣ĆļČĆņ×É [2, 2]
Ļ╣ĆĒÅēļ▓ö [1, 1]
ņØ┤ļ”ä ņ£äņ╣ś
Ļ╣ĆļČĆņ×É [3, 2]
Ļ╣ĆļČĆņ×É [2, 1]
Ļ╣ĆļČĆņ×É [2, 2]
Ļ╣Ćņä£ļ»╝ [1, 1]
mapņØä ņŚ¼ĻĖ░ņä£ ņé¼ņÜ®ĒĢśļ®┤ ļÉśĻ▓Āņ¢┤ņÜö.
ņŚ¼ļ¤¼ Ļ░£ņØś ļŹ░ņØ┤Ēä░ļź╝ FņÖĆ ĒĢ©Ļ╗ś mapņŚÉ ļäŻņ£╝ļ®┤ Ļ░üĻĖ░ ļŹ░ņØ┤Ēä░ļź╝ ļ│æļĀ¼ ņ▓śļ”¼ĒĢ┤ņä£ ņ×æņØĆ ĒģīņØ┤ļĖöļōżņØä ņŻ╝Ļ▓ĀļäżņÜö.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-108-320.jpg)
![ņØ┤ļ”ä ņ£äņ╣ś
Ļ╣ĆļČĆņ×É [3, 2]
Ļ╣ĆļČĆņ×É [2, 1]
Ļ╣ĆļČĆņ×É [2, 2]
Ļ╣ĆĒÅēļ▓ö [1, 1]
ņØ┤ļ”ä ņ£äņ╣ś
Ļ╣ĆļČĆņ×É [3, 2]
Ļ╣ĆļČĆņ×É [2, 1]
Ļ╣ĆļČĆņ×É [2, 2]
Ļ╣ĆĒÅēļ▓ö [1, 1]
ņØ┤ļ”ä ņ£äņ╣ś
Ļ╣ĆļČĆņ×É [3, 2]
Ļ╣ĆļČĆņ×É [2, 1]
Ļ╣ĆļČĆņ×É [2, 2]
Ļ╣ĆĒÅēļ▓ö [1, 1]
ņØ┤ļ”ä ņ£äņ╣ś
Ļ╣ĆļČĆņ×É [3, 2]
Ļ╣ĆļČĆņ×É [2, 1]
Ļ╣ĆļČĆņ×É [2, 2]
Ļ╣Ćņä£ļ»╝ [1, 1]
reduce(add, )
ņØ┤ļ”ä ņ£äņ╣ś
Ļ╣ĆļČĆņ×É [3, 2]
Ļ╣ĆļČĆņ×É [2, 1]
Ļ╣ĆļČĆņ×É [2, 2]
Ļ╣ĆļČĆņ×É [3, 3]
Ļ╣ĆļČĆņ×É [1, 2]
Ļ╣Ćņä£ļ»╝ [1, 1]
ŌĆ” ŌĆ”
ņØ┤ļĀćĻ▓ī ļ░øņØĆ ņŚ¼ļ¤¼ Ļ░£ņØś ĒģīņØ┤ļĖöņØĆ reduceļź╝ ņØ┤ņÜ®ĒĢ┤ņä£ ļ¬©ņ£╝ĻĖ░ļ¦ī ĒĢśļ®┤ ļÉśĻ▓ĀļäżņÜö.
(ļŗżņ¢æĒĢ£ ĒĢ©ņłśļź╝ ņØ┤ņÜ®ĒĢśļ®┤ ņØ┤ ļŗ©Ļ│äņŚÉņä£ ļŹö ļ¦ÄņØĆ Ļ░ĆĻ│ĄņØä ĒĢĀ ņłś ņ׳ņ¦Ćļ¦ī ņ¦ĆĻĖłņØś ņśłņŗ£ļŖö ļŗ©ņł£Ē׳ ĒĢ®ņ╣śļŖö ļŹ░ļ¦ī ņöüļŗłļŗż)](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-109-320.jpg)
![ņØ┤ļ”ä ņ£äņ╣ś
Ļ╣ĆļČĆņ×É [3, 2]
Ļ╣ĆļČĆņ×É [2, 1]
Ļ╣ĆļČĆņ×É [2, 2]
Ļ╣ĆļČĆņ×É [3, 3]
Ļ╣ĆļČĆņ×É [1, 2]
Ļ╣ĆĒÅēļ▓ö [1, 1]
ŌĆ” ŌĆ”
ņØ┤ļ”ä ņ£äņ╣ś
Ļ╣ĆļČĆņ×É [3, 2]
Ļ╣ĆļČĆņ×É [2, 1]
Ļ╣ĆļČĆņ×É [2, 2]
Ļ╣ĆļČĆņ×É [3, 3]
Ļ╣ĆļČĆņ×É [1, 2]
Ļ╣ĆĒÅēļ▓ö [1, 1]
ŌĆ” ŌĆ”
ņØ┤ļ”ä ņ£äņ╣ś
Ļ╣ĆļČĆņ×É [3, 2]
Ļ╣ĆļČĆņ×É [2, 1]
Ļ╣ĆļČĆņ×É [2, 2]
Ļ╣ĆļČĆņ×É [3, 3]
Ļ╣ĆļČĆņ×É [1, 2]
Ļ╣ĆĒÅēļ▓ö [1, 1]
ŌĆ” ŌĆ”
ņØ┤ļ”ä ņ£äņ╣ś
Ļ╣ĆļČĆņ×É [3, 2]
Ļ╣ĆļČĆņ×É [2, 1]
Ļ╣ĆļČĆņ×É [2, 2]
Ļ╣ĆļČĆņ×É [3, 3]
Ļ╣ĆļČĆņ×É [1, 2]
Ļ╣ĆĒÅēļ▓ö [1, 1]
ŌĆ” ŌĆ”
ņØ┤ļ”ä ņ£äņ╣ś
Ļ╣ĆļČĆņ×É [3, 2]
Ļ╣ĆļČĆņ×É [2, 1]
Ļ╣ĆļČĆņ×É [2, 2]
Ļ╣ĆļČĆņ×É [3, 3]
Ļ╣ĆļČĆņ×É [1, 2]
Ļ╣Ćņä£ļ»╝ [1, 1]
ŌĆ” ŌĆ”
CouchbaseļŖö ļČäņé░ ĻĄ¼ņĪ░ļź╝ ĒāØĒĢśĻ│Ā ņ׳ĻĖ░ ļĢīļ¼ĖņŚÉ Ļ░ü ļŹ░ņØ┤Ēä░ņä£ļ╣äņŖżņŚÉņä£ MapReduceļź╝ ĒåĄĒĢ┤ ņłśņ¦æĒĢ£ ļŹ░ņØ┤Ēä░ļź╝
ĒĢ£ļ▓ł ļŹö ļ¬©ņ£╝ļ®┤ ņÜ░ļ”¼Ļ░Ć ņøÉĒĢśļŖö Ļ▓░Ļ│╝Ļ░Ć ļéśņśĄļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-110-320.jpg)










![{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
]
}
ĻĘĖļלņä£ ņ┐╝ļ”¼ļź╝ ņé¼ņÜ®ĒĢśņ¦Ć ņĢŖļŖö ļ░®ņŗØņ£╝ļĪ£ ņ×¼ ĻĄ¼ĒśäĒĢśĻĖ░ļĪ£ Ļ▓░ņĀĢĒĢśņśĆņŖĄļŗłļŗż.
GridņÖĆ ļ│äĻ░£ļĪ£ ņé¼ņ£Āņ¦Ć ĒĢśļéś ļ│äļĪ£ ļĢģļ¼Ėņä£ļź╝ ļ¦īļō£ļŖö ļ░®ņŗØņØ┤ņŚłņŖĄļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-125-320.jpg)
![{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
]
}
ņØ┤ņĀäņŚÉļÅä ļĢģļ¼Ėņä£ņŚÉ ņŻ╝ņØĖņØ┤ ļ¦üĒü¼ļÉśņ¢┤ ņ׳ļŖö Ļ▓āņØĆ Ļ░ÖņĢśņ¦Ćļ¦ī ņāł ņŗ£ņŖżĒģ£ņØś Ļ░Ćņן ņżæņÜöĒĢ£ ņ░©ņØ┤ņĀÉņØĆ
ļŹ░ņØ┤Ēä░ņØś ĻĘ╝ņøÉņØ┤ ļĢģņØ┤ ņĢäļŗłļØ╝ ļĢģļ¼Ėņä£ļØ╝ļŖö ņĀÉ ņØ┤ņŚłņŖĄļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-126-320.jpg)
![{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
]
}
ņśłņĀäņŚö GridņŚÉ ņØ┤ ļĢģņØś ņŻ╝ņØĖņØ┤ ļłäĻĄ¼ņØĖņ¦Ć ņĀüĒśĆņ׳ņ£╝ļ®┤ ĻĘĖĻ▓āņØä ļ»┐ņŚłņ¦Ćļ¦ī
ņØ┤ņĀ£ļŖö ļĢģļ¼Ėņä£ļź╝ ĒÖĢņØĖĒĢ┤ņä£ ĻĘĖ ļĢģņØ┤ ĻĖ░ļĪØļÉśņ¢┤ ņ׳ņ¦Ć ņĢŖļŗżļ®┤](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-127-320.jpg)
![{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
]
}
ĻĘĖ ļĢģņØĆ Gridļź╝ ļ»┐ņ¦Ć ņĢŖĻ│Ā ņŻ╝ņØĖņØ┤ ņŚåļŖö ļĢģņ£╝ļĪ£ Ļ░äņŻ╝ĒĢśļŖö Ļ▓āņ×ģļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-128-320.jpg)
![{
estates: [
[3, 2]: Ļ╣ĆļČĆņ×É
[2, 1]: Ļ╣ĆļČĆņ×É
[2, 2]: Ļ╣ĆļČĆņ×É
]
}
ņØ┤ ļ░®ņŗØņØĆ GridļŖö ļŗ©ņł£Ē׳ ļĢģļ¼Ėņä£ļź╝ ĒÖĢņØĖĒĢśĻĖ░ ņ£äĒĢ£ ņŚ░Ļ▓░ņŚÉ ļČłĻ│╝ĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ
ļ¬©ļōĀ ļĢģņŚÉņä£ ņØ┤ ļĢģņØś ņŻ╝ņØĖņØä ĒÖĢņØĖĒĢśļĀżļ®┤ ņ¦ĆņåŹņĀüņ£╝ļĪ£ ļĢģļ¼Ėņä£ļź╝ ņØĮņ¢┤ņĢ╝ ĒĢ£ļŗżļŖö ņĀÉņØ┤ ļČĆļŗ┤ņØ┤ ļÉ®ļŗłļŗż.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-129-320.jpg)





NoSQL ņ£äņŚÉņä£ MMORPG Ļ░£ļ░£ĒĢśĻĖ░
- 1. NoSQL ņ£äņŚÉņä£ MMORPG Ļ░£ļ░£ĒĢśĻĖ░ ŃĆłņĢ╝ņāØņØś ļĢģ: ļōĆļ×æĻ│ĀŃĆēņØś ņé¼ļĪĆļź╝ ļ░öĒāĢņ£╝ļĪ£ What! Studio ņĄ£ĒśĖņśü
- 2. ļōĆļ×æĻ│Ā ņä£ļ▓äņ£Āļŗø Ļ▓īņ×äĒöīļĀłņØ┤ĒīīĒŖĖ ļŻ©ļŗłņĢä ņĀäĻĖ░ 2009-2012 ņĢ╝ņāØņØś ļĢģ: ļōĆļ×æĻ│Ā 2012- Ļ░ĆņŻĮ ņןĒÖöļź╝ ļ©╣Ļ▓ī ĒĢ┤ļŗ¼ļØ╝ļŗł NDC2014 ŃĆłņĢ╝ņāØņØś ļĢģ: ļōĆļ×æĻ│ĀŃĆē ņżæņĢÖ ņä£ļ▓ä ņŚåļŖö Ļ▓īņ×ä ļĪ£ņ¦ü NDC2016
- 3. ļ░£Ēæ£ņŚÉņä£ ļŗżļŻ©ļŖö Ļ▓ā ŌĆó NoSQL ņżæ CouchbaseņØś ĒŖ╣ņ¦Ģ ŌĆó Couchbase ņ£äņŚÉņä£ Ļ▓īņ×ä ĒöīļĀłņØ┤ ļĪ£ņ¦üņØä ļ¦īļōĀ Ļ▓ĮĒŚś ŌĆó CouchbaseĻ░Ć Ļ░Ćņ¦ĆļŖö ņןņĀÉĻ│╝ ļŗ©ņĀÉ
- 4. ļ░£Ēæ£ņŚÉņä£ ļŗżļŻ©ņ¦Ć ņĢŖļŖö Ļ▓ā ŌĆó NoSQLņØś ņŚŁņé¼ ŌĆó NoSQLņØś ņóģļźśņÖĆ ņä▒ļŖź ļ╣äĻĄÉ ŌĆó Couchbaseļź╝ ņäĀĒāØĒĢ£ ņØ┤ņ£Ā
- 5. ņŗ£ņ×æĒĢśĻĖ░ ņĀä ņŖżĒéżļ¦ł ļŹ░ņØ┤Ēä░ņØś ņĀĆņן ļæÉĻ░£ ņØ┤ņāüņØś ļ¼Ėņä£ņŚÉ ļīĆĒĢ£ ņĀĆņןĻ│╝ ļ│ĆĻ▓Į ņ┐╝ļ”¼ĒĢśĻĖ░ ņĀĢļ”¼
- 6. NoSQL? NoSQLņØĆ ņØ┤ļ¤░ 4Ļ░Ćņ¦Ć ĒŖ╣ņ¦ĢņØä Ļ│Ąņ£ĀĒĢ£ļŗżĻ│Āļōż ĒĢśņ¦Ćļ¦ī ņŗ£ļźśļź╝ Ļ░Ćļ”¼ĒéżļŖö ļ¦ÉņŚÉ Ļ░ĆĻ╣Øņ¦ĆļÅä ĒĢśĻ│Ā ņØ┤ļ»Ė ņ£ĀĒ¢ēĒĢ£ņ¦ĆļÅä 10ļģäņØ┤ Ļ░ĆĻ╣īņøī ņśżĻĖ░ ļĢīļ¼ĖņŚÉ, ņÜöņ”śņŚö ļö▒Ē׳ ņ¦Ćņ╝£ņ¦ĆļŖö Ļ▓ā Ļ░Öņ¦Ć ņĢŖņŖĄļŗłļŗż.
- 7. ņśżļŖś ņŻ╝ļĪ£ ļŗżļŻ░ CouchbaseļŖö NoSQLņØś ĒŖ╣ņ¦ĢļōżņØä ņČ®ņŗżĒĢśĻ▓ī ņ¦ĆĒé© ļŹ░ņØ┤Ēä░ļ▓ĀņØ┤ņŖżņ×ģļŗłļŗż.
- 9. ļČäņé░ĒśĢ ĻĄ¼ņĪ░ļź╝ ņé¼ņÜ®ĒĢśĻ│Ā ņłśĒÅē ĒÖĢņןņØ┤ ņÜ®ņØ┤ĒĢ®ļŗłļŗż. ļŹĢļČäņŚÉ ļČĆĒĢś ļČäņé░ņØ┤ ņל ļÉśĻ│Ā, ļ®öļ¬©ļ”¼ļź╝ ņĀüĻĘ╣ņĀüņ£╝ļĪ£ ĒÖ£ņÜ®ĻĖ░ļÅä ĒĢśņŚ¼ ņ║Éņŗ£ĻĖē ņä▒ļŖź ļé┤ļŖö Ļ▓āņØ┤ ņןņĀÉņ×ģļŗłļŗż.
- 10. {key:value} CouchbaseļŖö key-value storeņØ┤ĻĖ░ ļĢīļ¼ĖņŚÉ ļŹ░ņØ┤Ēä░ņØś ņĀĆņן/ņĪ░ĒÜīĻ░Ć keyļź╝ ĒåĄĒĢ┤ņä£ļ¦ī ņØ┤ļŻ©ņ¢┤ņ¦æļŗłļŗż.
- 11. JSON ValueļĪ£ļŖö ļŗżņ¢æĒĢ£ Ēżļ¦ĘņØä ņĀĆņןĒĢĀ ņłś ņ׳ņ¦Ćļ¦ī JSONņØä ĻČīņןĒĢśĻ│Ā ņ׳ņŖĄļŗłļŗż. Views, N1QL ļō▒ņØä JSONņØä ņé¼ņÜ®ĒĢĀ ļĢīļ¦ī ņ¦ĆņøÉĒĢśĻĖ░ ļĢīļ¼Ėņ×ģļŗłļŗż. ņÜö ļČĆļČäņØĆ ļéśņżæņŚÉ ļŗżņŗ£ ņ×ÉņäĖĒ׳ ļŗżļŻ©Ļ▓ĀņŖĄļŗłļŗż.
- 12. JSON Document-oriented CouchbaseļŖö Key-Value StoreņØś ĒĢ£ ņóģļźśņØĖ Document-orientedļĪ£ļÅä ļČäļźśļÉśļŖöļŹ░ ĻĄ¼ņĪ░ĒÖöļÉ£ ļŹ░ņØ┤Ēä░ņØĖ JSONņØä ņØ┤ņÜ®ĒĢ┤ņä£ ņĀĆņן/ļÅÖņ×æĒĢśĻĖ░ ļĢīļ¼Ėņ×ģļŗłļŗż.
- 13. ņŗ£ņ×æĒĢśĻĖ░ ņĀä ņŖżĒéżļ¦ł ļŹ░ņØ┤Ēä░ņØś ņĀĆņן ļæÉĻ░£ ņØ┤ņāüņØś ļ¼Ėņä£ņŚÉ ļīĆĒĢ£ ņĀĆņןĻ│╝ ļ│ĆĻ▓Į ņ┐╝ļ”¼ĒĢśĻĖ░ ņĀĢļ”¼
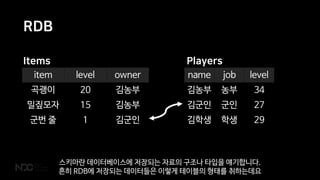
- 14. RDB name job level Ļ╣ĆļåŹļČĆ ļåŹļČĆ 34 Ļ╣ĆĻĄ░ņØĖ ĻĄ░ņØĖ 27 Ļ╣ĆĒĢÖņāØ ĒĢÖņāØ 29 item level owner Ļ│ĪĻ┤ŁņØ┤ 20 Ļ╣ĆļåŹļČĆ ļ░Ćņ¦Üļ¬©ņ×É 15 Ļ╣ĆļåŹļČĆ ĻĄ░ļ▓ł ņżä 1 Ļ╣ĆĻĄ░ņØĖ PlayersItems ņŖżĒéżļ¦łļ×Ć ļŹ░ņØ┤Ēä░ļ▓ĀņØ┤ņŖżņŚÉ ņĀĆņןļÉśļŖö ņ×ÉļŻīņØś ĻĄ¼ņĪ░ļéś ĒāĆņ×ģņØä ņ¢śĻĖ░ĒĢ®ļŗłļŗż. ĒØöĒ׳ RDBņŚÉ ņĀĆņןļÉśļŖö ļŹ░ņØ┤Ēä░ļōżņØĆ ņØ┤ļĀćĻ▓ī ĒģīņØ┤ļĖöņØś ĒśĢĒā£ļź╝ ņĘ©ĒĢśļŖöļŹ░ņÜö
- 15. Couchbase { name: Ļ╣ĆļåŹļČĆ job: ļåŹļČĆ level: 34 items: [ {item:Ļ│ĪĻ┤ŁņØ┤, level:20}, {item:ļ░Ćņ¦Üļ¬©ņ×É, level:15} ] } { name: Ļ╣ĆĻĄ░ņØĖ job: ĻĄ░ņØĖ level: 27 items: [ {item:ĻĄ░ļ▓łņżä, level:1} ] } { name: Ļ╣ĆĒĢÖņāØ job: ĒĢÖņāØ level: 29 items: [] } ļ░śļ®┤ CouchbaseļŖö JSON ĻĖ░ļ░śņØś document ļŹ░ņØ┤Ēä░ļ▓ĀņØ┤ņŖżņØ┤ĻĖ░ ļĢīļ¼ĖņŚÉ ņŚ░Ļ┤ĆļÉ£ ļŹ░ņØ┤Ēä░ļź╝ ļ¼Čņ¢┤ ĒĢśļéśņØś ļ¼Ėņä£ņŚÉ Ļ░ÖņØ┤ ļ│┤Ļ┤ĆĒĢśļŖö Ļ▓ĮņÜ░Ļ░Ć ļ¦ÄņŖĄļŗłļŗż.
- 16. Couchbase { name: Ļ╣ĆļåŹļČĆ job: ļåŹļČĆ level: 34 items: [ {item:Ļ│ĪĻ┤ŁņØ┤, level:20}, {item:ļ░Ćņ¦Üļ¬©ņ×É, level:15} ] } 1 2 3 4 5 6 7 8 class Item: item = declare(unicode) level = declare(int) class Entity: job = declare(unicode) level = declare(int) items = declare(list(Item)) JSONņ£╝ļĪ£ ņĀĆņןĒĢĀ ļĢīņØś Ļ░Ćņן Ēü░ ĒŖ╣ņ¦ĢņØĆ ļĪ£ņ¦üņØś ļŹ░ņØ┤Ēä░ ĻĄ¼ņĪ░ņÖĆ ņ£Āņé¼ĒĢśļŗżļŖö ņĀÉ ņ×ģļŗłļŗż. JSONņØ┤ĻĖ░ ļĢīļ¼ĖņŚÉ ļŹ░ņØ┤Ēä░ļ▓ĀņØ┤ņŖż ņé¼ņÜ®ņ×ÉĻ░Ć ņ×äņØśļĪ£ ĻĄ¼ņĪ░ļź╝ ņĀĢĒĢĀ ņłś ņ׳ĻĖ░ ļĢīļ¼ĖņØ┤ņŻĀ.
- 17. Couchbase { name: Ļ╣ĆļåŹļČĆ job: ļåŹļČĆ level: 34 items: [ {item:Ļ│ĪĻ┤ŁņØ┤, level:20}, {item:ļ░Ćņ¦Üļ¬©ņ×É, level:15} ] } 1 2 3 4 5 6 7 8 class Item: item = declare(unicode) level = declare(int) class Entity: job = declare(unicode) level = declare(int) items = declare(list(Item)) ļĢīļ¼ĖņŚÉ RDBņÖĆ ļŗżļź┤Ļ▓ī ļ®öļ¬©ļ”¼ ņāüņØś ļŹ░ņØ┤Ēä░ņÖĆ DBņāüņØś ļŹ░ņØ┤Ēä░ņØś ĻĄ¼ņĪ░ļź╝ ņØ╝ņ╣śņŗ£Ēé¼ ņłś ņ׳ņ¢┤ Ļ▓īņ×ä ĒöīļĀłņØ┤ ļĪ£ņ¦ü Ļ░£ļ░£ņØ┤ ĻĄēņןĒ׳ ņłśņøöĒĢ®ļŗłļŗż.
- 18. Schemaless ņØ┤ļĀćļō» DBņŚÉ ļö▒ļö▒ĒĢ£ ņŖżĒéżļ¦łĻ░Ć ņĀĢņØśļÉśļŖö Ļ▓āņØ┤ ņĢäļŗłĻĖ░ ļĢīļ¼ĖņŚÉ SchemalessļØ╝Ļ│Ā ļČłļ”Įļŗłļŗż.
- 19. ļ¦Éļ×æļ¦Éļ×æĒĢ£ ņŖżĒéżļ¦ł ĒĢ£ĻĄŁļ¦ÉļĪ£ Ēæ£ĒśäĒĢśļ®┤ ļ¦Éļ×æļ¦Éļ×æĒĢ£ ņŖżĒéżļ¦łĻ░Ć ļÉśĻ▓ĀļäżņÜö.
- 20. ļ¦Éļ×æļ¦Éļ×æĒĢ£ ņŖżĒéżļ¦ł ņłśņøöĒĢ£ ļĪ£ņ¦ü ĻĄ¼Ēśä Ļ▓īņ×ä ĒöīļĀłņØ┤ ĒöäļĪ£ĻĘĖļלļ©ĖņØś ņ▒ģņ×ä ņ”ØĻ░Ć ĒĢ£ĻĄŁļ¦ÉļĪ£ Ēæ£ĒśäĒĢśļ®┤ ļ¦Éļ×æļ¦Éļ×æĒĢ£ ņŖżĒéżļ¦łĻ░Ć ļÉśĻ▓ĀļäżņÜö. ĒĢśņ¦Ćļ¦ī ļŗ╣ņŚ░Ē׳ ņןņĀÉļ¦ī ņ׳ļŖö Ļ▓āņØĆ ņĢäļŗłņŻĀ.
- 21. ņŖżĒéżļ¦łņØś ļ│ĆĻ▓Į ņŖżĒéżļ¦łļź╝ ļ│ĆĻ▓ĮĒĢĀ ļĢīĻ░Ć ļīĆĒæ£ņĀüņØ┤ļØ╝Ļ│Ā ĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.
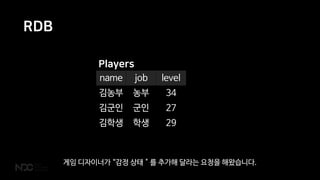
- 22. RDB name job level Ļ╣ĆļåŹļČĆ ļåŹļČĆ 34 Ļ╣ĆĻĄ░ņØĖ ĻĄ░ņØĖ 27 Ļ╣ĆĒĢÖņāØ ĒĢÖņāØ 29 Players Ļ▓īņ×ä ļööņ×ÉņØ┤ļäłĻ░Ć ŌĆ£Ļ░ÉņĀĢ ņāüĒā£’╝éļź╝ ņČöĻ░ĆĒĢ┤ ļŗ¼ļØ╝ļŖö ņÜöņ▓ŁņØä ĒĢ┤ņÖöņŖĄļŗłļŗż.
- 23. RDB ALTER TABLE Players ADD emotion VARCHAR NOT NULL DEFAULT(ŌĆØļČäļģĖŌĆØ) ļīĆņČ® ņØ┤ļ¤░ ņ┐╝ļ”¼ļ¼ĖņØä ņ¦£ņä£ ļÅīļ”¼ļ®┤ ļÉśĻ▓ĀļäżņÜö.
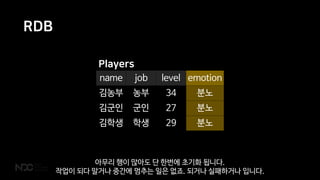
- 24. RDB A C I D tomicity onsistency solation urability RDBļŖö ņŚ¼ļ¤¼ļČäņØ┤ ņל ņĢäņŗ£ļŖö ļīĆļĪ£ ACID ĒŖĖļ×£ņףņģśņØä ņ¦ĆņøÉĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ
- 25. RDB name job level emotion Ļ╣ĆļåŹļČĆ ļåŹļČĆ 34 ļČäļģĖ Ļ╣ĆĻĄ░ņØĖ ĻĄ░ņØĖ 27 ļČäļģĖ Ļ╣ĆĒĢÖņāØ ĒĢÖņāØ 29 ļČäļģĖ Players ņĢäļ¼┤ļ”¼ Ē¢ēņØ┤ ļ¦ÄņĢäļÅä ļŗ© ĒĢ£ļ▓łņŚÉ ņ┤łĻĖ░ĒÖö ļÉ®ļŗłļŗż. ņ×æņŚģņØ┤ ļÉśļŗż ļ¦ÉĻ▒░ļéś ņżæĻ░äņŚÉ ļ®łņČöļŖö ņØ╝ņØĆ ņŚåņŻĀ. ļÉśĻ▒░ļéś ņŗżĒī©ĒĢśĻ▒░ļéś ņ×ģļŗłļŗż.
- 26. Couchbase { name: Ļ╣ĆļåŹļČĆ job: ļåŹļČĆ level: 34 emotion: ļČäļģĖ items: [ {item:Ļ│ĪĻ┤ŁņØ┤, level:20}, {item:ļ░Ćņ¦Üļ¬©ņ×É, level:15} ] } CouchbaseņŚÉņä£ļÅä ĒĢśļéśņØś ļ¼Ėņä£ļź╝ ļ│ĆĻ▓ĮĒĢĀ ļĢÉ ACID ĒŖĖļ×£ņףņģśņØ┤ļØ╝Ļ│Ā ĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż. ņØĮĻ│Ā, ņō░Ļ│Ā, ņĀĆņןĒĢśļ®┤ ļÉśļŗłĻ╣īņÜö. ļ¼Ėņä£ ļŗ©ņ£äļĪ£ ļÅÖņ×æĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ļ¼Ėņä£Ļ░Ć ņĀĆņןņØ┤ ļÉśļŗżĻ░Ć ļ¦ÉĻ▒░ļéś ĒĢśļŖö ņØ╝ņØĆ ņŚåņŖĄļŗłļŗż.
- 27. Couchbase ĒĢśņ¦Ćļ¦ī Couchbaseļź╝ ĒŖ╣ļ│äĒĢśĻ▓ī ļ¦īļō£ļŖö ļČäņé░ĒśĢ ĻĄ¼ņĪ░ņÖĆ ļåÆņØĆ ĒÖĢņןņä▒ņØĆ ļŗżļ¼Ėņä£ļź╝ ņĀĆņןĒĢĀ ļĢī ACID ĒŖĖļ×£ņףņģśņØä ņ¦ĆņøÉĒĢśĻĖ░ ĒלļōżĻ▓ī ļ¦īļōŁļŗłļŗż.
- 28. Couchbase JSON ĒĢśļéśņØś ļ¼Ėņä£ļź╝ ņĀĆņןĒĢĀ ļĢīļŖö Ļ┤£ņ░«ņ¦Ćļ¦ī
- 29. Couchbase JSONJSON JSONJSON JSON ņŚ¼ļ¤¼ Ļ░£ņØś ļ¼Ėņä£ļź╝ ņĀĆņןĒĢĀ ļĢīļŖö ļÅÖņŗ£ņŚÉ ņĀĆņןĒĢśņ¦Ć ļ¬╗ĒĢśĻ│Ā ņĢĀĒöīļ”¼ņ╝ĆņØ┤ņģśņŚÉņä£ ņł£ņä£ļīĆļĪ£ ņĀĆņןĒĢĀ ņłś ņ׳ņØä ļ┐É ņ×ģļŗłļŗż.
- 30. Couchbase { name: Ļ╣ĆļåŹļČĆ job: ļåŹļČĆ level: 34 emotion: ļČäļģĖ items: [ {item:Ļ│ĪĻ┤ŁņØ┤, level:20}, {item:ļ░Ćņ¦Üļ¬©ņ×É, level:15} ] }
- 31. Couchbase { name: Ļ╣ĆļåŹļČĆ job: ļåŹļČĆ level: 34 emotion: ļČäļģĖ items: [ {item:Ļ│ĪĻ┤ŁņØ┤, level:20}, {item:ļ░Ćņ¦Üļ¬©ņ×É, level:15} ] } { name: Ļ╣ĆĻĄ░ņØĖ job: ĻĄ░ņØĖ level: 27 emotion: ļČäļģĖ items: [ {item:ĻĄ░ļ▓łņżä, level:1} ] } { name: Ļ╣ĆĒĢÖņāØ job: ĒĢÖņāØ level: 29 items: [] } ļĢīļ¼ĖņŚÉ ņŚ¼ļ¤¼ Ļ░£ņØś ļ¼Ėņä£ļź╝ ņĀĆņןĒĢśļŗż ļ│┤ļ®┤ ļ¬ć Ļ░£ļŖö ņŗżĒī©ĒĢĀ ņłśļÅä ņ׳ņŻĀ.
- 32. Couchbase { name: Ļ╣ĆļåŹļČĆ job: ļåŹļČĆ level: 34 emotion: ļČäļģĖ items: [ {item:Ļ│ĪĻ┤ŁņØ┤, level:20}, {item:ļ░Ćņ¦Üļ¬©ņ×É, level:15} ] } JSON ņłśņ¢ĄĻ░£ ļŹöĻĄ░ļŗżļéś ļ¼Ėņä£Ļ░Ć ņłśņ¢ĄĻ░£ ņ»ż ļÉ£ļŗżļ®┤ ņŗżĒī©ĒĢ£ Ļ▓āļōżņØä ņ×¼ņŗ£ļÅäĒĢ┤ņä£ ņĀĆņןĒĢśļŖö Ļ▓āļÅä ņēĮņ¦Ć ņĢŖņØĆ ņØ╝ņØ┤ ļÉ®ļŗłļŗż.
- 33. on-demand migration ĻĘĖļלņä£ ņĀĆĒؼļŖö on-demand migrationņØ┤ļØ╝Ļ│Ā ļČĆļź┤ļŖö ĻĖ░ļ▓ĢņØä ņé¼ņÜ®ĒĢśĻ│Ā ņ׳ņŖĄļŗłļŗż.
- 34. on-demand migration { version: 0 name: Ļ╣ĆļåŹļČĆ job: ļåŹļČĆ level: 34 items: [ {item:Ļ│ĪĻ┤ŁņØ┤, level:20}, {item:ļ░Ćņ¦Üļ¬©ņ×É, level:15} ] } 1 2 3 4 5 6 7 8 9 class Item: item = declare(unicode) level = declare(int) class Entity: __version__ = 0 job = declare(unicode) level = declare(int) items = declare(list(Item)) on-demand migratioņØĆ ļ¼Ėņä£ņØś ļŹ░ņØ┤Ēä░ņÖĆ ļ®öļ¬©ļ”¼ ņāüņØś ļŹ░ņØ┤Ēä░Ļ░Ć ļÅÖņØ╝ĒĢśļŗżļŖö ļČĆļČäņŚÉņä£ ņČ£ļ░£ĒĢ®ļŗłļŗż.
- 35. on-demand migration { version: 0 name: Ļ╣ĆļåŹļČĆ job: ļåŹļČĆ level: 34 items: [ {item:Ļ│ĪĻ┤ŁņØ┤, level:20}, {item:ļ░Ćņ¦Üļ¬©ņ×É, level:15} ] } 1 2 3 4 5 6 7 8 9 class Item: item = declare(unicode) level = declare(int) class Entity: __version__ = 0 job = declare(unicode) level = declare(int) items = declare(list(Item)) ņĀĆņןļÉ£ ļŹ░ņØ┤Ēä░ņÖĆ ņĢĀĒöīļ”¼ņ╝ĆņØ┤ņģśņŚÉņä£ ņäĀņ¢ĖĒĢ£ ņŖżĒéżļ¦łņŚÉ ļ▓äņĀäņØä ļČĆņŚ¼ĒĢśĻ│Ā ļæśņØ┤ Ļ░ÖņĢäņ¦ĆļÅäļĪØ ņĢĀĒöīļ”¼ņ╝ĆņØ┤ņģśņŚÉņä£ Ļ┤Ćļ”¼ĒĢśļŖö Ļ▓üļŗłļŗż.
- 36. on-demand migration 1 2 3 4 5 6 7 8 9 10 class Item: item = declare(unicode) level = declare(int) class Entity: __version__ = 1 job = declare(unicode) level = declare(int) emotion = declare(unicode) items = declare(list(Item)) ņØ┤ļĀćĻ▓ī EntityņØś ļ▓äņĀäņØä 0ņŚÉņä£ 1ļĪ£ ņś¼ļ”¼Ļ│Ā
- 37. on-demand migration 1 2 3 4 5 6 7 8 9 10 @migrate(Entity, 0, 1) def migration(document): document[ŌĆśemotionŌĆÖ] = ŌĆśļČäļģĖŌĆÖ def load(cls, key): doc = db.load(key) if doc[ŌĆśversionŌĆÖ] != cls.version: doc = migrate(doc[ŌĆśversionŌĆÖ], cls.version, doc) db.update(key, doc) return unpack(doc) ļ▓äņĀäņØ┤ 0ņŚÉņä£ 1ļĪ£ ņś¼ļØ╝Ļ░ł ļĢī ļ¼Ėņä£ņØś ļ¦łņØ┤ĻĘĖļĀłņØ┤ņģśņØä ņ¢┤ļ¢╗Ļ▓ī ĒĢĀņ¦Ć ĒĢ©ņłśļĪ£ ļ¦īļōżņ¢┤ ļæĪļŗłļŗż. ĻĘĖļ”¼Ļ│Ā ļ¼Ėņä£ļź╝ ņĢĀĒöīļ”¼ņ╝ĆņØ┤ņģśņŚÉņä£ ņØĮņØä ļĢī ņĀĆņןļÉ£ ļ▓äņĀäņØ┤ Ēśäņ×¼ņÖĆ ļŗżļź┤ļ®┤ ĒĢ┤ļŗ╣ ĒĢ©ņłśļź╝ ņŗżĒ¢ēņŗ£ĒéĄļŗłļŗż.
- 38. on-demand migration { version: 0 name: Ļ╣ĆļåŹļČĆ job: ļåŹļČĆ level: 34 items: [ {item:Ļ│ĪĻ┤ŁņØ┤, level:20}, {item:ļ░Ćņ¦Üļ¬©ņ×É, level:15} ] } { version: 1 name: Ļ╣ĆĻĄ░ņØĖ job: ĻĄ░ņØĖ level: 27 emotion: ļČäļģĖ items: [ {item:ĻĄ░ļ▓łņżä, level:1} ] } { version: 1 name: Ļ╣ĆĒĢÖņāØ job: ĒĢÖņāØ level: 29 emotion: ļČäļģĖ items: [] } ņØ┤ļĀćĻ▓ī ļÉśļ®┤ ļŗżļźĖ ļ▓äņĀäņØś ļŹ░ņØ┤Ēä░Ļ░Ć Ļ│ĄņĪ┤ĒĢĀ ņłś ņ׳ņ¦Ćļ¦ī, ņ¢┤ņ░©Ēö╝ ņØĮņ¢┤ņä£ ņōĖ ļĢīļŖö ļ▓äņĀäņØ┤ ļ¦×ņČ░ņ¦Ćļŗł Ļ┤£ņ░«ņŖĄļŗłļŗż.
- 39. on-demand migration ļČäņé░ļÉ£ ļ¦łņØ┤ĻĘĖļĀłņØ┤ņģś ņłśĒ¢ē ļČĆļŗ┤ņØ┤ ņĀüņØĆ ņĀÉĻ▓Ć ņØ┤ ļ░®ņŗØņØĆ ĒĢäņÜöĒĢĀ ļĢīļ¦ī ņŗżĒ¢ēļÉśĻĖ░ ļĢīļ¼ĖņŚÉ ņל ļČäņé░ļÉśņ¢┤ ņŗżĒ¢ēļÉśĻ│Ā ņĀÉĻ▓Ć ņŗ£Ļ░äņŚÉ ĒĢĀ ņØ╝ņØ┤ ņżäņ¢┤ļōżņ¢┤ ņĀÉņä¼ ņŗ£Ļ░ä ņ×Éņ▓┤Ļ░Ć ņżäņ¢┤ļōŁļŗłļŗż.
- 40. on-demand migration ļČäņé░ļÉ£ ļ¦łņØ┤ĻĘĖļĀłņØ┤ņģś ņłśĒ¢ē ļČĆļŗ┤ņØ┤ ņĀüņØĆ ņĀÉĻ▓Ć ņĀÉĻ▓ĆņØ┤ ļüØļéśĻ│Ā ļ▓äĻĘĖ ļ░£Ļ▓¼ ĒĢśņ¦Ćļ¦ī ņĀÉĻ▓ĆņØ┤ ļüØļéśņĢ╝ ņŗżņĀ£ ļ¦łņØ┤ĻĘĖļĀłņØ┤ņģśņØ┤ ņé░ļ░£ņĀüņ£╝ļĪ£ ņ¦äĒ¢ēļÉśĻĖ░ ļĢīļ¼ĖņŚÉ ļ▓äĻĘĖĻ░Ć ņ׳ņØä Ļ▓ĮņÜ░ ļÆĘņłśņŖĄņØ┤ ĒלļōŁļŗłļŗż. ĻĘĖļלņä£ ņĀĆĒؼļŖö ļ¦łņØ┤ĻĘĖļĀłņØ┤ņģś ņ×æņŚģņØ┤ ņ׳ņØä Ļ▓ĮņÜ░ ļ╣╝ļ©╣ņ¦Ć ņĢŖļÅäļĪØ Ļ┤ĆļĀ©ļÉ£ ĒģīņŖżĒŖĖ ĒöäļĪ£ņäĖņŖżļź╝ ļö░ļĪ£ ņÜ┤ņśüņżæņ×ģļŗłļŗż.
- 41. ņŗ£ņ×æĒĢśĻĖ░ ņĀä ņŖżĒéżļ¦ł ļŹ░ņØ┤Ēä░ņØś ņĀĆņן ļæÉĻ░£ ņØ┤ņāüņØś ļ¼Ėņä£ņŚÉ ļīĆĒĢ£ ņĀĆņןĻ│╝ ļ│ĆĻ▓Į ņ┐╝ļ”¼ĒĢśĻĖ░ ņĀĢļ”¼
- 42. ņĀĆĒؼļŖö ĒöīļĀłņØ┤ņ¢┤ļōżņŚÉĻ▓ī Ļ▓īņ×ä ļööņ×ÉņØĖņĀüņ£╝ļĪ£ ĒŚłņÜ®ĒĢśļŖö ĒĢ£ ņĄ£ļīĆĒĢ£ Ēü░ ņä¼ņØä ņ£ĀņĀĆļōżņŚÉĻ▓ī ņŻ╝Ļ│Ā ņŗČņ¢┤ĒĢ®ļŗłļŗż.
- 43. ļĢīļ¼ĖņŚÉ ĒĢśļéśņØś ņä¼ņØä ĒĢśļéśņØś ļ¼╝ļ”¼ņĀüņØĖ ņä£ļ▓äņŚÉ ļ░öņØĖļö® ņŗ£ĒéżĻ│Ā ņŗČņ¢┤ĒĢśņ¦Ć ņĢŖņŖĄļŗłļŗż. ņä£ļ▓ä ņä▒ļŖźņØ┤ ņä¼ Ēü¼ĻĖ░ņØś ĒĢśļō£ņ║ĪņØ┤ ļÉśĻĖ░ ļĢīļ¼ĖņØ┤ņŻĀ
- 44. ĻĘĖļĀćļŗżĻ│Ā ĒĢśļéśņØś ņä¼ņØä ņŗ¼ļ”¼ņŖżĒĢśņ¦Ć ņĢŖĻ▓ī ļ¦īļō£ļŖö Ļ▓āļÅä ĒĢśĻ│Ā ņŗČņ¦Ć ņĢŖņĢśņŻĀ. ĻĘĖļ¤╝ ņä¼ņØä ļæÉĻ░£ ļ¦īļō£ļŖö Ļ▓āļ¦ī ļ¬╗ĒĢśņŻĀ.
- 45. A BA B ĻĘĖļĀćĻĖ░ ļĢīļ¼ĖņŚÉ ņĀĆĒؼļŖö ļ¼╝ļ”¼ņĀüņØĖ ņä£ļ▓äņŚÉ ņ¦ĆņŚŁņØä ļ¼Čņ¦Ć ņĢŖĻ│Ā ļ¼╝ļ”¼ņĀüņØĖ ņä£ļ▓äņŚÉņä£ļŖö ņĀüļŗ╣Ē׳ ļ░░ņĀĢļÉ£ ĒöīļĀłņØ┤ņ¢┤ ņ║Éļ”ŁĒä░ļ¦ī ļŗ┤ļŗ╣ĒĢśĻ▓ī ĒĢśņśĆņŖĄļŗłļŗż.
- 46. A BA B ĻĘĖļĀćĻĖ░ ļĢīļ¼ĖņŚÉ ļ░öļĪ£ ņśåņŚÉ ņ׳ļŖö Ļ▓ā Ļ░ÖņĢśļŹś ļŗżļźĖ ņ║Éļ”ŁĒä░Ļ░Ć ņé¼ņŗżņØĆ ļŗżļźĖ ļ¼╝ļ”¼ņĀüņØĖ ļģĖļō£ņŚÉ ņ׳ņØä ņłś ņ׳ļŖö Ļ▓üļŗłļŗż. ĒĢśņ¦Ćļ¦ī ņØ┤ ņāüĒÖ®ņŚÉņä£ ņ║Éļ”ŁĒä░ņØś ļŹ░ņØ┤Ēä░ļź╝ ļ│ĆĻ▓ĮĒĢśļĀżĻ│Ā ĒĢśļ®┤ ļ¼ĖņĀ£Ļ░Ć ņāØĻĖĖ ņłś ņ׳ņŖĄļŗłļŗż.
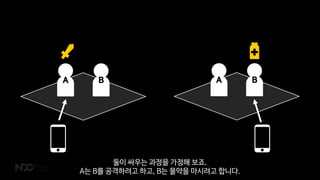
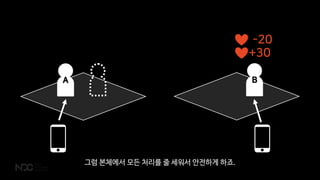
- 47. A BA B ļæśņØ┤ ņŗĖņÜ░ļŖö Ļ│╝ņĀĢņØä Ļ░ĆņĀĢĒĢ┤ ļ│┤ņŻĀ. AļŖö Bļź╝ Ļ│ĄĻ▓®ĒĢśļĀżĻ│Ā ĒĢśĻ│Ā, BļŖö ļ¼╝ņĢĮņØä ļ¦łņŗ£ļĀżĻ│Ā ĒĢ®ļŗłļŗż.
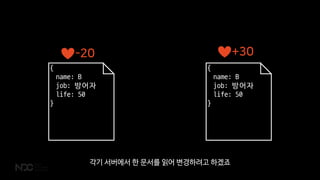
- 48. A BA B -20 +30 ļæÉĻ░Ćņ¦Ć ņĢĪņģśņØĆ ļŗżļźĖ ņ║Éļ”ŁĒä░Ļ░Ć ļŗżļźĖ ņä£ļ▓äņŚÉņä£ ņ¦äĒ¢ēĒ¢łņ¦Ćļ¦ī Ļ▓░Ļ│╝ļŖö ĒĢśļéśņØś ļ¼Ėņä£ņŚÉ ļ░śņśüļÉśņ¢┤ņĢ╝ ĒĢ®ļŗłļŗż.
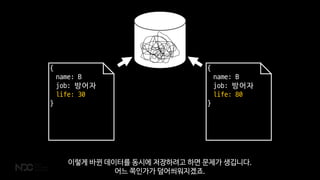
- 49. -20 +30 { name: B job: ļ░®ņ¢┤ņ×É life: 50 } { name: B job: ļ░®ņ¢┤ņ×É life: 50 } Ļ░üĻĖ░ ņä£ļ▓äņŚÉņä£ ĒĢ£ ļ¼Ėņä£ļź╝ ņØĮņ¢┤ ļ│ĆĻ▓ĮĒĢśļĀżĻ│Ā ĒĢśĻ▓ĀņŻĀ
- 50. { name: B job: ļ░®ņ¢┤ņ×É life: 80 } { name: B job: ļ░®ņ¢┤ņ×É life: 30 } ņØ┤ļĀćĻ▓ī ļ░öļĆÉ ļŹ░ņØ┤Ēä░ļź╝ ļÅÖņŗ£ņŚÉ ņĀĆņןĒĢśļĀżĻ│Ā ĒĢśļ®┤ ļ¼ĖņĀ£Ļ░Ć ņāØĻ╣üļŗłļŗż. ņ¢┤ļŖÉ ņ¬ĮņØĖĻ░ĆĻ░Ć ļŹ«ņ¢┤ņöīņøīņ¦ĆĻ▓ĀņŻĀ.
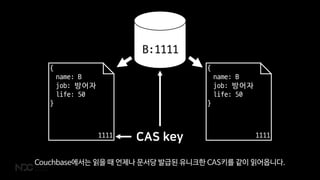
- 51. CAS ņØ┤ļ¤░ ņØ╝ņØä ļ░®ņ¦ĆĒĢśĻĖ░ ņ£äĒĢ┤ņä£ CouchbaseļŖö CAS ņŗ£ņŖżĒģ£ņØä ņĀ£Ļ│ĄĒĢ®ļŗłļŗż. Check And Set ļśÉļŖö Compare And SwapņØ┤ļØ╝Ļ│Ā ĒĢśņŻĀ.
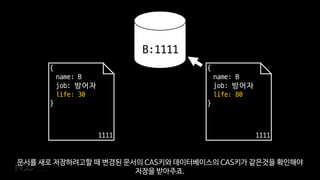
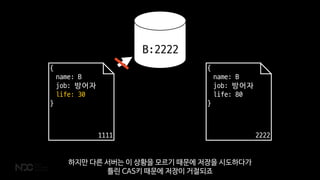
- 52. { name: B job: ļ░®ņ¢┤ņ×É life: 50 } 1111 { name: B job: ļ░®ņ¢┤ņ×É life: 50 } 1111 B:1111 CAS key CouchbaseņŚÉņä£ļŖö ņØĮņØä ļĢī ņ¢ĖņĀ£ļéś ļ¼Ėņä£ļŗ╣ ļ░£ĻĖēļÉ£ ņ£ĀļŗłĒü¼ĒĢ£ CASĒéżļź╝ Ļ░ÖņØ┤ ņØĮņ¢┤ņśĄļŗłļŗż.
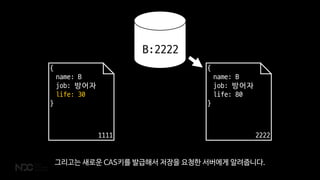
- 53. { name: B job: ļ░®ņ¢┤ņ×É life: 30 } 1111 { name: B job: ļ░®ņ¢┤ņ×É life: 80 } 1111 B:1111 ļ¼Ėņä£ļź╝ ņāłļĪ£ ņĀĆņןĒĢśļĀżĻ│ĀĒĢĀ ļĢī ļ│ĆĻ▓ĮļÉ£ ļ¼Ėņä£ņØś CASĒéżņÖĆ ļŹ░ņØ┤Ēä░ļ▓ĀņØ┤ņŖżņØś CASĒéżĻ░Ć Ļ░ÖņØĆĻ▓āņØä ĒÖĢņØĖĒĢ┤ņĢ╝ ņĀĆņןņØä ļ░øņĢäņŻ╝ņŻĀ.
- 54. { name: B job: ļ░®ņ¢┤ņ×É life: 30 } 1111 { name: B job: ļ░®ņ¢┤ņ×É life: 80 } 2222 B:2222 ĻĘĖļ”¼Ļ│ĀļŖö ņāłļĪ£ņÜ┤ CASĒéżļź╝ ļ░£ĻĖēĒĢ┤ņä£ ņĀĆņןņØä ņÜöņ▓ŁĒĢ£ ņä£ļ▓äņŚÉĻ▓ī ņĢīļĀżņżŹļŗłļŗż.
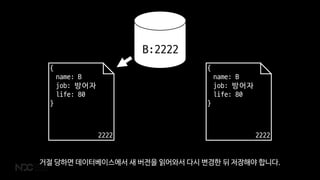
- 55. { name: B job: ļ░®ņ¢┤ņ×É life: 30 } 1111 { name: B job: ļ░®ņ¢┤ņ×É life: 80 } 2222 B:2222 ĒĢśņ¦Ćļ¦ī ļŗżļźĖ ņä£ļ▓äļŖö ņØ┤ ņāüĒÖ®ņØä ļ¬©ļź┤ĻĖ░ ļĢīļ¼ĖņŚÉ ņĀĆņןņØä ņŗ£ļÅäĒĢśļŗżĻ░Ć ĒŗĆļ”░ CASĒéż ļĢīļ¼ĖņŚÉ ņĀĆņןņØ┤ Ļ▒░ņĀłļÉśņŻĀ
- 56. { name: B job: ļ░®ņ¢┤ņ×É life: 80 } 2222 { name: B job: ļ░®ņ¢┤ņ×É life: 80 } 2222 B:2222 Ļ▒░ņĀł ļŗ╣ĒĢśļ®┤ ļŹ░ņØ┤Ēä░ļ▓ĀņØ┤ņŖżņŚÉņä£ ņāł ļ▓äņĀäņØä ņØĮņ¢┤ņÖĆņä£ ļŗżņŗ£ ļ│ĆĻ▓ĮĒĢ£ ļÆż ņĀĆņןĒĢ┤ņĢ╝ ĒĢ®ļŗłļŗż.
- 57. ļéÖĻ┤ĆņĀü ļÅÖņŗ£ņä▒ ņĀ£ņ¢┤ ņØ┤ļ¤░ ļ░®ņŗØņØä ļéÖĻ┤ĆņĀü ļÅÖņŗ£ņä▒ ņĀ£ņ¢┤ļØ╝Ļ│Ā ļČĆļ”ģļŗłļŗż. ņĢäļ¦ł ņä▒Ļ│ĄĒĢĀ Ļ▓āņØ┤ļØ╝Ļ│Ā ļéÖĻ┤ĆĒĢśĻ│Ā ņØ╝ļŗ© ņĀĆņןņØä ņŗ£ļÅäĒĢśļŖö Ļ▒░ņŻĀ. ļ¼╝ļĪĀ ņŗżĒī©ĒĢĀ ņłśļÅä ņ׳ņ¦Ćļ¦ī ĻĘĖĻ▒┤ ļéśņżæņŚÉ ņāØĻ░üĒĢ®ļŗłļŗż.
- 58. ļéÖĻ┤ĆņĀü ļÅÖņŗ£ņä▒ ņĀ£ņ¢┤ ļŻ©ĒöäņØś ĒĢ©ņĀĢ ŌĆó Ļ▓ĮĒĢ®ņØ┤ ņ×”ņØĆ Ļ││ņŚÉņä£ļŖö ĻĖēĻ▓®ĒĢśĻ▓ī ĒŹ╝Ēżļ©╝ņŖżĻ░Ć ļéśļ╣Āņ¦äļŗż ŌĆó ļŻ©Ēöä ņĢłņŚÉņä£ļŖö ņé¼ņØ┤ļō£ ņØ┤ĒÄÖĒŖĖĻ░Ć ņŚåņ¢┤ņĢ╝ ĒĢ£ļŗż ĒĢśņ¦Ćļ¦ī ņØ╝ļŗ© ņĀĆņןĒĢśĻ│Ā ņŗżĒī©ĒĢśļ®┤ ļŗżņŗ£ ņØĮņ¢┤ņÖĆņä£ ļ│ĆĻ▓ĮĒĢ£ ļÆż ņĀĆņןņØä ņŗ£ļÅäĒĢśļŖö ļ░®ņŗØņØĆ ļŗ©ņĀÉņØ┤ ņ׳ņŖĄļŗłļŗż. Ļ▓ĮĒĢ®ņØ┤ ņ×”ņØĆ Ļ││ņŚÉņä£ņØś ļ¼ĖņĀ£ļÅä ļ¼ĖņĀ£ņ¦Ćļ¦ī, ļŹ░ņØ┤Ēä░ļź╝ ļ│ĆĻ▓ĮĒĢśļŖö Ļ││ņØ┤ ņ░ĖņĪ░ Ēł¼ļ¬ģņä▒ņØä Ļ░¢ņČ░ņĢ╝ ĒĢ£ļŗżļŖö ņĀÉņØ┤ņŻĀ.
- 59. ļéÖĻ┤ĆņĀü ļÅÖņŗ£ņä▒ ņĀ£ņ¢┤ ļŻ©ĒöäņØś ĒĢ©ņĀĢ ŌĆó Ļ▓ĮĒĢ®ņØ┤ ņ×”ņØĆ Ļ││ņŚÉņä£ļŖö ĻĖēĻ▓®ĒĢśĻ▓ī ĒŹ╝Ēżļ©╝ņŖżĻ░Ć ļéśļ╣Āņ¦äļŗż ŌĆó ļŻ©Ēöä ņĢłņŚÉņä£ļŖö ņé¼ņØ┤ļō£ ņØ┤ĒÄÖĒŖĖĻ░Ć ņŚåņ¢┤ņĢ╝ ĒĢ£ļŗż 1 2 3 4 def eat_medicine(self, item): for doc in self.saving(): doc.life += item.life broad_cast(ŌĆśI ate medicineŌĆÖ) ņĢäļ¦łļÅä Ļ░£ļ░£ņ×ÉļŖö ļ¼╝ņĢĮņØä ļ©╣ņŚłņØä ļĢī ņŻ╝ļ│ĆņŚÉ ļéś ļ©╣ņŚłļŗżĻ│Ā ņĢīļ”¼Ļ│Ā ņŗČņŚłņØä ļ┐É ņ×ģļŗłļŗż. ĒĢśņ¦Ćļ¦ī ļČĆņŻ╝ņØśĒĢśĻ▓ī ļéÖĻ┤ĆņĀü ļÅÖņŗ£ņä▒ ņĀ£ņ¢┤ ļŻ©Ēöä ņĢłņŚÉ ļäŻļŖö ļ░öļ×īņŚÉ ņĀĆņןņØä ņ×¼ņŗ£ļÅäĒĢĀ ļĢīļ¦łļŗż ļéĀļ”¼Ļ▓ī ļÉśņŚłņŻĀ
- 60. ļéÖĻ┤ĆņĀü ļÅÖņŗ£ņä▒ ņĀ£ņ¢┤ ņØ┤ļ¤░ ĒŖ╣ņ¦Ģ ļĢīļ¼ĖņŚÉ ņ║Éļ”ŁĒä░ Ļ░ä ņØĖĒä░ļ×Öņģś Ļ░ÖņØĆ ļ│Ąņ×ĪĒĢ£ ļĪ£ņ¦üņŚÉņä£ ļéÖĻ┤ĆņĀü ļÅÖņŗ£ņä▒ ņĀ£ņ¢┤ļź╝ ļ»┐Ļ│Ā ĒöäļĪ£ĻĘĖļלļ░Ź ĒĢśļŖö Ļ▓āņØĆ ļ¦żņÜ░ ņ¢┤ļĀżņÜ┤ ņØ╝ņ×ģļŗłļŗż.
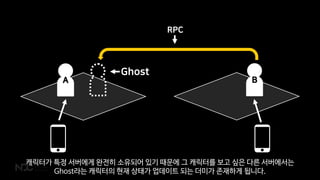
- 61. ņä£ļ▓ä ļģĖļō£Ļ░Ć ļ¼Ėņä£ņØś ņåīņ£ĀĻČīņØä ļÅģņĀÉĒĢśĻĖ░ ĻĘĖļלņä£ ņĀĆĒؼļŖö ņóĆ ļŗżļźĖ ļ░®ņŗØņØä ņé¼ņÜ®ĒĢśĻ│Ā ņ׳ņŖĄļŗłļŗż. ņ¢┤ļ¢ż ļ¼Ėņä£ņØś ņåīņ£ĀĻČīņØä ļ¬ģĒÖĢĒ׳ ĒĢśļŖö ļ░®ņŗØņØ┤ņŻĀ.
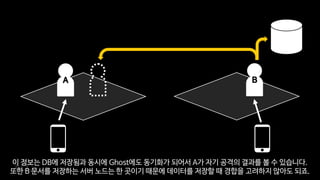
- 62. BA Ghost RPC ņ║Éļ”ŁĒä░Ļ░Ć ĒŖ╣ņĀĢ ņä£ļ▓äņŚÉĻ▓ī ņÖäņĀäĒ׳ ņåīņ£ĀļÉśņ¢┤ ņ׳ĻĖ░ ļĢīļ¼ĖņŚÉ ĻĘĖ ņ║Éļ”ŁĒä░ļź╝ ļ│┤Ļ│Ā ņŗČņØĆ ļŗżļźĖ ņä£ļ▓äņŚÉņä£ļŖö GhostļØ╝ļŖö ņ║Éļ”ŁĒä░ņØś Ēśäņ×¼ ņāüĒā£Ļ░Ć ņŚģļŹ░ņØ┤ĒŖĖ ļÉśļŖö ļŹöļ»ĖĻ░Ć ņĪ┤ņ×¼ĒĢśĻ▓ī ļÉ®ļŗłļŗż.
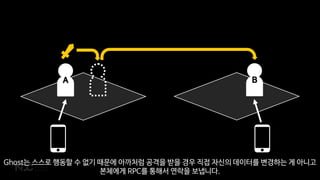
- 63. BA GhostļŖö ņŖżņŖżļĪ£ Ē¢ēļÅÖĒĢĀ ņłś ņŚåĻĖ░ ļĢīļ¼ĖņŚÉ ņĢäĻ╣īņ▓śļ¤╝ Ļ│ĄĻ▓®ņØä ļ░øņØä Ļ▓ĮņÜ░ ņ¦üņĀæ ņ×ÉņŗĀņØś ļŹ░ņØ┤Ēä░ļź╝ ļ│ĆĻ▓ĮĒĢśļŖö Ļ▓ī ņĢäļŗłĻ│Ā ļ│Ėņ▓┤ņŚÉĻ▓ī RPCļź╝ ĒåĄĒĢ┤ņä£ ņŚ░ļØĮņØä ļ│┤ļāģļŗłļŗż.
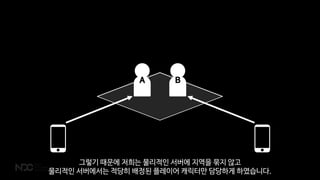
- 64. BA -20 +30 ĻĘĖļ¤╝ ļ│Ėņ▓┤ņŚÉņä£ ļ¬©ļōĀ ņ▓śļ”¼ļź╝ ņżä ņäĖņøīņä£ ņĢłņĀäĒĢśĻ▓ī ĒĢśņŻĀ.
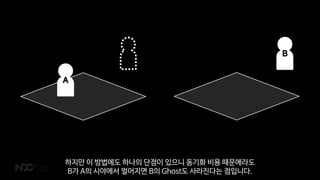
- 65. BA ņØ┤ ņĀĢļ│┤ļŖö DBņŚÉ ņĀĆņןļÉ©Ļ│╝ ļÅÖņŗ£ņŚÉ GhostņŚÉļÅä ļÅÖĻĖ░ĒÖöĻ░Ć ļÉśņ¢┤ņä£ AĻ░Ć ņ×ÉĻĖ░ Ļ│ĄĻ▓®ņØś Ļ▓░Ļ│╝ļź╝ ļ│╝ ņłś ņ׳ņŖĄļŗłļŗż. ļśÉĒĢ£ B ļ¼Ėņä£ļź╝ ņĀĆņןĒĢśļŖö ņä£ļ▓ä ļģĖļō£ļŖö ĒĢ£ Ļ││ņØ┤ĻĖ░ ļĢīļ¼ĖņŚÉ ļŹ░ņØ┤Ēä░ļź╝ ņĀĆņןĒĢĀ ļĢī Ļ▓ĮĒĢ®ņØä Ļ│ĀļĀżĒĢśņ¦Ć ņĢŖņĢäļÅä ļÉśņŻĀ.
- 66. B A ĒĢśņ¦Ćļ¦ī ņØ┤ ļ░®ļ▓ĢņŚÉļÅä ĒĢśļéśņØś ļŗ©ņĀÉņØ┤ ņ׳ņ£╝ļŗł ļÅÖĻĖ░ĒÖö ļ╣äņÜ® ļĢīļ¼ĖņŚÉļØ╝ļÅä BĻ░Ć AņØś ņŗ£ņĢ╝ņŚÉņä£ ļ®Ćņ¢┤ņ¦Ćļ®┤ BņØś GhostļÅä ņé¼ļØ╝ņ¦äļŗżļŖö ņĀÉņ×ģļŗłļŗż.
- 67. ? ļ│Ėņ▓┤ņÖĆņØś ņŚ░ļØĮ ĒåĄļĪ£ņØĖ Ghost ņŚåņØ┤ļŖö ļŗżļźĖ ņ║Éļ”ŁĒä░ņŚÉĻ▓ī ņśüĒ¢źļĀźņØä ņĀäĒśĆ Ē¢ēņé¼ĒĢĀ ņłś ņŚåņŻĀ. ņ▓śņØīņŚÉļŖö ņØ┤ļלļÅä Ļ┤£ņ░«Ļ▓ī ņāØĻ░üĒ¢łņ¦Ćļ¦ī, ņ¦£ņ×ö ņĀłļīĆļØ╝ļŖö Ļ▒┤ ņŚåļŹöĻĄ░ņÜö.
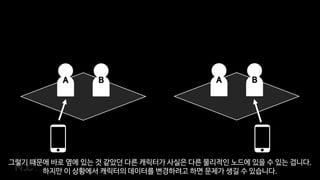
- 68. B A AņÖĆ BĻ░Ć Ļ│ĄļŻĪņØä ņé¼ļāźĒĢśĻ│Ā ņ׳ļŖöļŹ░
- 69. A BĻ░Ć Ļ░æņ×ÉĻĖ░ ņé¼ļØ╝ņĪīņŖĄļŗłļŗż. ĻĘĖļāź ļ®Ćņ¢┤ņ¦ä Ļ▒ĖņłśļÅä ņ׳Ļ│Ā, ņĀæņåŹņØä ņóģļŻīĒ¢łņØä ņłśļÅä ņ׳ņŻĀ.
- 70. A A Ēś╝ņ×Éņä£ ņé¼ļāźņØä ļ¦łļ¼┤ļ”¼ Ē¢łļŖöļŹ░, ĒÜŹļōØĒĢ£ Ļ▓ĮĒŚśņ╣śļź╝ ĻĖ░ņŚ¼ļÅäĻ░Ć ņ׳ļŖö BņŚÉĻ▓ī ļéśļłĀņŻ╝Ļ│Ā ņŗČņ¢┤ļÅä GhostĻ░Ć ņŚåņ¢┤ņä£ ļéśļłĀņżä ņłśĻ░Ć ņŚåņŖĄļŗłļŗż.
- 71. Promise ņØ┤ļ¤┤ ļĢī ņĀĆĒؼļŖö promiseļØ╝Ļ│Ā ļČĆļź┤ļŖö ļ░®ļ▓ĢņØä ņöüļŗłļŗż.
- 72. { name: B job: ļ░®ļ×æņ×É exp: 50 } { promises: [ (add_exp, 30) (add_exp, 20) (add_exp, 40) ] } ĒĢśļéśņØś ņ║Éļ”ŁĒä░ņŚÉĻ▓īļŖö ņ¢ĖņĀ£ļéś ĒĢśļéśņØś promise ĒüÉļź╝ ļ¦īļōżņ¢┤ ļæÉĻ│Ā ņŗ£ņĢ╝ņŚÉ ņŚåļŖö ņ║Éļ”ŁĒä░ņŚÉĻ▓īļŖö ņĢĮņåŹļ¦ī Ļ▒Ėņ¢┤ļæÉļ®┤
- 73. { name: B job: ļ░®ļ×æņ×É exp: 140 } { promises: [] } ĒĢ┤ļŗ╣ ņ║Éļ”ŁĒä░Ļ░Ć ņĀæņåŹĒ¢łņØä ļĢī ņĢīņĢäņä£ ĒĢ┤ļŗ╣ ĒüÉņØś ņ×æņŚģļōżņØä ņłśĒ¢ēĒĢśļŖö ļ░®ņŗØņØ┤ņŻĀ. ņØ┤ļ»Ė ņĀæņåŹ ņżæņØ┤ņŚłļŗżļ®┤ ļ░öļĪ£ ņŗżĒ¢ēĒĢĀ Ļ▓ā ņ×ģļŗłļŗż.
- 74. Promise ņØ╝ļ░®ņĀü ņÜöņ▓Ł ņĀĢĒÖĢĒĢ£ ņŗżĒ¢ē ĒāĆņØ┤ļ░Ź ņśłņĖĪ ļČłĻ░Ć PromiseļŖö ņ£ĀņÜ®ĒĢśņ¦Ćļ¦ī ņÜöņ▓ŁņØ┤ ņØ╝ļ░®ņĀüņØ┤ņ¢┤ņä£ ņØĖĒä░ļ×Öņģś ņÜ®ļÅäļĪ£ ņĀüņĀłĒĢśņ¦Ć ļ¬╗ĒĢśĻ│Ā ņĀæņåŹĒĢĀ ļĢī ņ▓śļ”¼ļÉĀ ņłś ņ׳ĻĖ░ ļĢīļ¼ĖņŚÉ ņĀĢĒÖĢĒĢ£ ņŗżĒ¢ē ĒāĆņØ┤ļ░ŹņØä ņśłņĖĪĒĢśĻĖ░ ĒלļōżļŗżļŖö ļ¼ĖņĀ£Ļ░Ć ņ׳ņŖĄļŗłļŗż.
- 75. ņŗ£ņ×æĒĢśĻĖ░ ņĀä ņŖżĒéżļ¦ł ļŹ░ņØ┤Ēä░ņØś ņĀĆņן ļæÉĻ░£ ņØ┤ņāüņØś ļ¼Ėņä£ņŚÉ ļīĆĒĢ£ ņĀĆņןĻ│╝ ļ│ĆĻ▓Į ņ┐╝ļ”¼ĒĢśĻĖ░ ņĀĢļ”¼
- 76. ACID transactionACID ņ┤łļ░śņŚÉ ņäżļ¬ģĒ¢łļō»ņØ┤ CouchbaseļŖö ņŚ¼ļ¤¼ Ļ░£ ļ¼Ėņä£ņŚÉ ļīĆĒĢ£ ņĀĆņןņØä ACIDĒĢśĻ▓ī ņ▓śļ”¼ĒĢśņ¦Ć ļ¬╗ĒĢ®ļŗłļŗż.
- 77. { name: Ļ░Ćļ░® items: [] } { name: ņāüņ×É items: [ Ļ░ĆņŻĮ ņןĒÖö ] } ĒĢśņ¦Ćļ¦ī ļæÉĻ░£ņØś ļ¼Ėņä£ļź╝ ļÅÖņŗ£ņŚÉ ņĀĆņןĒĢĀ ņØ╝ņØĆ ĒĢäņÜöĒĢśĻĖ░ ļ¦łļĀ©ņ×ģļŗłļŗż. ņāüņ×ÉņŚÉņä£ Ļ░Ćļ░®ņ£╝ļĪ£ ņĢäņØ┤Ēģ£ņØä ņś«ĻĖ░ļŖö Ļ▓āņØ┤ ļīĆĒæ£ņĀüņØĖ ņśłņØ┤ņŻĀ.
- 78. { name: Ļ░Ćļ░® items: [ Ļ░ĆņŻĮ ņןĒÖö ] } { name: ņāüņ×É items: [] } ņØ┤ļĀćĻ▓ī ļ┐ģ ĒĢśĻ│Ā ņś«Ļ▓©ņ¦Ćļ®┤ ņóŗĻ▓Āņ¦Ćļ¦ī, CouchbaseņŚÉņä£ļŖö ņØ┤ Ļ│╝ņĀĢņØ┤ ņēĮņ¦Ć ņĢŖņŖĄļŗłļŗż.
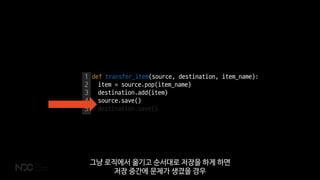
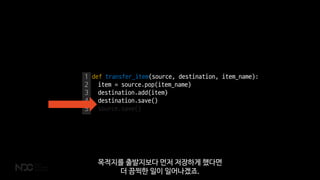
- 79. 1 2 3 4 5 def transfer_item(source, destination, item_name): item = source.pop(item_name) destination.add(item) source.save() destination.save() ĻĘĖļāź ļĪ£ņ¦üņŚÉņä£ ņś«ĻĖ░Ļ│Ā ņł£ņä£ļīĆļĪ£ ņĀĆņןņØä ĒĢśĻ▓ī ĒĢśļ®┤ ņĀĆņן ņżæĻ░äņŚÉ ļ¼ĖņĀ£Ļ░Ć ņāØĻ▓╝ņØä Ļ▓ĮņÜ░
- 80. { name: Ļ░Ćļ░® items: [] } { name: ņāüņ×É items: [] } ņĢäņØ┤Ēģ£ņØ┤ ņåīņŗżļÉśļŖö ļ¼ĖņĀ£Ļ░Ć ņāØĻ╣üļŗłļŗż.
- 81. 1 2 3 4 5 def transfer_item(source, destination, item_name): item = source.pop(item_name) destination.add(item) destination.save() source.save() ļ¬®ņĀüņ¦Ćļź╝ ņČ£ļ░£ņ¦Ćļ│┤ļŗż ļ©╝ņĀĆ ņĀĆņןĒĢśĻ▓ī Ē¢łļŗżļ®┤ ļŹö ļüöņ░ŹĒĢ£ ņØ╝ņØ┤ ņØ╝ņ¢┤ļéśĻ▓ĀņŻĀ.
- 82. { name: Ļ░Ćļ░® items: [ Ļ░ĆņŻĮ ņןĒÖö ] } { name: ņāüņ×É items: [ Ļ░ĆņŻĮ ņןĒÖö ] } ņĢäņØ┤Ēģ£ ļ│Ąņé¼Ļ░Ć ņØ╝ņ¢┤ļéśņŻĀ.
- 83. B A S E asically vailable oft state ventual consistency ņØ┤ļ¤░ Ļ▓ĮņÜ░ņŚÉ BASE ĒŖĖļ×£ņףņģśņØä ņŹ©ņĢ╝ ĒĢ®ļŗłļŗż. ACIDņØś ļ░śļīĆ Ēæ£ĒśäņØĖ BASEņŚÉ ļ¦×ņČöĻĖ░ ņ£äĒĢ┤ņä£ ņĢĀļź╝ ņō┤ Ļ▓āņØ┤ ļ│┤ņØ┤ļŖö ņÜ®ņ¢┤ņ×ģļŗłļŗż.
- 84. { name: Ļ░Ćļ░® items: [] } { name: ņāüņ×É items: [ Ļ░ĆņŻĮ ņןĒÖö ] } BASE ĒŖĖļ×£ņףņģśņØś ņÜ®ņ¢┤ļź╝ ņØ╝ņØ╝Ē׳ ļ©╝ņĀĆ ņØ┤ĒĢ┤ĒĢśļŖö Ļ▓ā ļ│┤ļŗż ņśłņŗ£ļź╝ ļ│┤Ļ│Ā ņÜ®ņ¢┤ļź╝ ļŗżņŗ£ ļ│┤ļ®┤ ņØ┤ĒĢ┤Ļ░Ć ņē¼ņÜĖ Ļ▓ā Ļ░ÖņŖĄļŗłļŗż.
- 85. 1. ņØ┤ļÅÖ ļ¬ģņäĖ ļ¼Ėņä£ ņāØņä▒ { name: Ļ░Ćļ░® items: [] } { name: ņāüņ×É items: [ Ļ░ĆņŻĮ ņןĒÖö ] } { id: transfer_001 source: ņāüņ×É destination: Ļ░Ćļ░® state: pending items: [ Ļ░ĆņŻĮ ņןĒÖö ] } ņĢäņØ┤Ēģ£ņØä ņś«ĻĖ░ļĀżĻ│Ā ĒĢśļ®┤ ņØ╝ļŗ© ņĢäņØ┤Ēģ£ ņØ┤ļÅÖ ņ×Éņ▓┤ņŚÉ ļīĆĒĢ£ ļ¬ģņäĖ ļ¼Ėņä£ļź╝ ļ¦īļōżņ¢┤ DBņŚÉ ņĀĆņןĒĢ®ļŗłļŗż. ņČ£ļ░£ņ¦ĆņÖĆ ļ¬®ņĀüņ¦Ć, ņĢäņØ┤Ēģ£ ĻĘĖļ”¼Ļ│Ā ņØ┤ļÅÖņŚÉ ļīĆĒĢ£ Ēśäņ×¼ ņāüĒā£ļÅä ļäŻņ¢┤ļæ¼ņĢ╝Ļ▓ĀņŻĀ.
- 86. 2. ņāüņ×ÉņÖĆ ļ¬ģņäĖ ļ¼Ėņä£ļź╝ ņŚ░Ļ▓░ĒĢśĻĖ░ { name: Ļ░Ćļ░® items: [] } { name: ņāüņ×É items: [] transferring: transfer_001 } { id: transfer_001 source: ņāüņ×É destination: Ļ░Ćļ░® state: pending items: [ Ļ░ĆņŻĮ ņןĒÖö ] } ĻĘĖ ļŗżņØīņŚö ļ©╝ņĀĆ ņČ£ļ░£ņ¦ĆņŚÉņä£ ņĢäņØ┤Ēģ£ņØä ļ╣╝Ļ│Ā ļ¬ģņäĖ ļ¼Ėņä£ņÖĆņØś ņŚ░Ļ▓░ Ļ│Āļ”¼ļź╝ ļ¦īļōŁļŗłļŗż. Ēś╣ņŗ£ ņŗżĒī©ĒĢ£ļŗżļ®┤ ņØ┤ ļ¬ģņäĖļź╝ ņ░ĖĻ│ĀĒĢ┤ņä£ ņøÉļל ņāüĒā£ļĪ£ ļ│ĄņøÉĒĢĀ ņłśļÅä ņ׳Ļ│Ā, ļŗżņŗ£ ņØ┤ļÅÖņØä ņØ┤ņ¢┤ņä£ ņ¦äĒ¢ēĒĢĀ ņłśļÅä ņ׳ņŖĄļŗłļŗż.
- 87. 3. Ļ░Ćļ░®Ļ│╝ ļ¬ģņäĖ ļ¼Ėņä£ļź╝ ņŚ░Ļ▓░ĒĢśĻĖ░ { name: Ļ░Ćļ░® items: [] transferring: transfer_001 } { name: ņāüņ×É items: [] transferring: transfer_001 } { id: transfer_001 source: ņāüņ×É destination: Ļ░Ćļ░® state: pending items: [ Ļ░ĆņŻĮ ņןĒÖö ] } ļÅäņ░®ņ¦ĆņŚÉļÅä ņØ┤ļÅÖņØä ļ░śņśüĒĢ®ļŗłļŗż. ņĢäņØ┤Ēģ£ ļČĆĒä░ ļäŻņ£╝ļ®┤ ņĢäņ¦ü ĒöäļĪ£ņäĖņŖżĻ░Ć ļüØļéśņ¦Ć ņĢŖņĢśļŖöļŹ░ļÅä ņĢäņØ┤Ēģ£ņØä ņé¼ņÜ®ĒĢ┤ ļ▓äļ”¼ļŖö ņØ╝ņØ┤ ņ׳ņØä ņłś ņ׳ņ£╝ļŗł ļ¬ģņäĖ ļ¼Ėņä£ļ¦ī ļ¦üĒü¼ļĪ£ Ļ▒Ėņ¢┤ ļæĪļŗłļŗż.
- 88. 4. ļ¬ģņäĖ ņāüĒā£ ļ│ĆĻ▓Į { name: Ļ░Ćļ░® items: [] transferring: transfer_001 } { name: ņāüņ×É items: [] transferring: transfer_001 } { id: transfer_001 source: ņāüņ×É destination: Ļ░Ćļ░® state: committed items: [ Ļ░ĆņŻĮ ņןĒÖö ] } ņ¢æņ¬Į ņØĖļ▓żĒåĀļ”¼ņŚÉ ļ¬ģņäĖ ļ¼Ėņä£Ļ░Ć ļŗż ļ¦üĒü¼ ļÉ£ Ļ▓āņØä ĒÖĢņØĖĒĢśļ®┤ ņāüĒā£ļź╝ committedļĪ£ ļ░öĻ┐ēļŗłļŗż. ņé¼ņŗżņāü ņØ┤ļÅÖņØ┤ ņÖäļŻīļÉ£ Ļ▓āņØ┤ĻĖ░ ļĢīļ¼ĖņØ┤ņŻĀ.
- 89. 5. ņĢäņØ┤Ēģ£ ņØ┤ļÅÖ ņÖäļŻī { name: Ļ░Ćļ░® items: [ Ļ░ĆņŻĮ ņןĒÖö ] } { name: ņāüņ×É items: [] } { id: transfer_001 source: ņāüņ×É destination: Ļ░Ćļ░® state: committed items: [ Ļ░ĆņŻĮ ņןĒÖö ] } ļ¬ģņäĖ ļ¼Ėņä£ņŚÉ committedĻ░Ć ĻĖ░ļĪØļÉśņŚłņ£╝ļŗł Ļ░ü ņØĖļ▓żĒåĀļ”¼ļŖö ņØ┤ļÅÖ ļ¬ģņäĖļź╝ ņ░ĖĻ│ĀĒĢ┤ņä£ Ļ▓░Ļ│╝ļź╝ ņŖżņŖżļĪ£ ļ░śņśüĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.
- 90. ņĢäņØ┤Ēģ£ ņØ┤ļÅÖņØś ĒĢĄņŗ¼ ŌĆó ĒĢśļéśņØś ļŗ©Ļ│äņŚÉņäĀ ĒĢśļéśņØś ļ¼Ėņä£ļ¦ī ļ│ĆĻ▓Į ŌĆó ņĢäņØ┤Ēģ£ ņØ┤ļÅÖņŚÉ ļīĆĒĢ£ ļ¬ģņäĖļź╝ ļ¼Ėņä£ĒÖö ĒĢśņŚ¼ ņ¢┤ļŖÉ ļŗ©Ļ│äņŚÉņä£ ļ®łņČ░ļÅä ļŗżņŗ£ ņĢäņØ┤Ēģ£ ņØ┤ļÅÖņØä ņ×¼Ļ░£ĒĢĀ ņłś ņ׳ņØī Ļ░ü ļŗ©Ļ│äņŚÉņäĀ ACID ĒŖĖļ×£ņףņģśņØä ļ│┤ņןĒĢśļŖö ĒĢśļéśņØś ļ¼Ėņä£ņŚÉ ļīĆĒĢ┤ņä£ļ¦ī ļÅÖņ×æĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ņĢäĒåĀļ»╣ĒĢ©ņØ┤ ļ│┤ņןļÉśĻ│Ā ļ¬ģņäĖ ļ¼Ėņä£ļź╝ ĒåĄĒĢ┤ņä£ Ļ┤Ćļ”¼ĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ņ¢ĖņĀ£ ņ¦äĒ¢ēņØ┤ ļ®łņČ░ļÅä ļŗżņŗ£ ņ¦äĒ¢ēĒĢĀ ņłś ņ׳ļŗżļŖö ņĀÉņØ┤ ĒĢĄņŗ¼ņ×ģļŗłļŗż.
- 91. B A S E asically vailable oft state ventual consistency ņØ┤ņĀ£ BASE ĒŖĖļ×£ņףņģśņØś ņÜ®ņ¢┤ļź╝ ļŗżņŗ£ ĒĢ£ļ▓ł ļ│╝Ļ╣īņÜö?
- 92. BA S E ņĢäņØ┤Ēģ£ ņØ┤ļÅÖņØ┤ ņ¦äĒ¢ēļÉśļŖö ņżæņŚÉļÅä ņāüņ×ÉņÖĆ Ļ░Ćļ░®ņØĆ ņĀĢņāü ļÅÖņ×æĒĢ© ņĢäņØ┤Ēģ£ ņØ┤ļÅÖņŚÉ ļīĆĒĢ£ ņāüĒā£Ļ░Ć ĒÖĢņĀĢļÉśņ¦Ć ņĢŖņØĆ ņł£Ļ░äņØ┤ ņĪ┤ņ×¼ĒĢ© ņł£Ļ░äņĀüņ£╝ļĪ£ ņĢäņØ┤Ēģ£ņØ┤ ņ¢æņ¬ĮņŚÉņä£ ņé¼ļØ╝ņ¦ä Ļ▓āņ▓śļ¤╝ ļ│┤ņØ╝ ņłś ņ׳ņ¦Ćļ¦ī, ņ¢ĖņĀĀĻ░ĆļŖö ņØ┤ļÅÖņØ┤ ņÖäļŻīļÉ© BASE ĒŖĖļ×£ņףņģśņØĆ ACID ĒŖĖļ×£ņףņģśņØä ņ¦ĆņøÉĒĢśņ¦Ć ņĢŖņØä ļĢīņŚÉ ņĢĀĒöīļ”¼ņ╝ĆņØ┤ņģś ļĀłļ▓©ņŚÉņä£ ACIDņÖĆ ļ╣äņŖĘĒĢ£ ļÅÖņ×æņØä ņ£äĒĢ┤ņä£ ļ¦īņĪ▒ĒĢ┤ņĢ╝ ĒĢśļŖö ĒŖ╣ņä▒ļōżņØä ļ¬©ņĢäļæö Ļ▓āņØ┤ļØ╝ ĒĢśĻ▓ĀņŖĄļŗłļŗż.
- 93. ņŗ£ņ×æĒĢśĻĖ░ ņĀä ņŖżĒéżļ¦ł ļŹ░ņØ┤Ēä░ņØś ņĀĆņן ļæÉĻ░£ ņØ┤ņāüņØś ļ¼Ėņä£ņŚÉ ļīĆĒĢ£ ņĀĆņןĻ│╝ ļ│ĆĻ▓Į ņ┐╝ļ”¼ĒĢśĻĖ░ ņĀĢļ”¼
- 94. ņĀĆĒؼ Ļ▓īņ×äņŚÉļŖö ņé¼ņ£Āņ¦ĆļØ╝Ļ│Ā ĒĢśļŖö ĻĖ░ļŖźņØ┤ ņ׳ņŖĄļŗłļŗż. ĒŖ╣ņĀĢ ņ£ĀņĀĆĻ░Ć ļĢģņØä ļÅģņĀÉĒĢśļŖö ĻĖ░ļŖźņØ┤ņŻĀ.
- 95. Grid ļĢģņØś ĻĖ░ļĪØ ņØ┤ļ¤░ ņé¼ņ£Āņ¦ĆņŚÉ ļīĆĒĢ£ ņĀĢļ│┤ļŖö ņ£äņ╣ś ĻĖ░ļ░śņ£╝ļĪ£ ļÅÖņ×æĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ļĢģņŚÉ ĻĖ░ļĪØļÉśņ¢┤ņĢ╝ ĒĢśļŖöļŹ░ņÜö. ņĀĆĒؼļŖö ņØ┤ ļĢģņØä ļé┤ļČĆņĀüņ£╝ļĪ£ GridļØ╝Ļ│Ā ļČĆļź┤Ļ│Ā ņ׳ņŖĄļŗłļŗż.
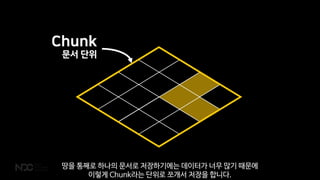
- 96. Chunk ļ¼Ėņä£ ļŗ©ņ£ä ļĢģņØä ĒåĄņ¦ĖļĪ£ ĒĢśļéśņØś ļ¼Ėņä£ļĪ£ ņĀĆņןĒĢśĻĖ░ņŚÉļŖö ļŹ░ņØ┤Ēä░Ļ░Ć ļäłļ¼┤ ļ¦ÄĻĖ░ ļĢīļ¼ĖņŚÉ ņØ┤ļĀćĻ▓ī ChunkļØ╝ļŖö ļŗ©ņ£äļĪ£ ņ¬╝Ļ░£ņä£ ņĀĆņןņØä ĒĢ®ļŗłļŗż.
- 97. Cell ņé¼ņ£Āņ¦Ć ļŗ©ņ£ä ĒĢśļéśņØś Chunk ņĢłņŚÉļŖö ņé¼ņ£Āņ¦ĆņØś ļŗ©ņ£äĻ░Ć ļÉśļŖö CellņØ┤ ņŚ¼ļ¤¼ Ļ░£ ļōżņ¢┤ņ׳ņŻĀ.
- 98. { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É [1, 1]: Ļ╣Ćņä£ļ»╝ ] } Grid ļ¼Ėņä£ļź╝ ņé┤ĒÄ┤ļ│┤ļ®┤ ļīĆņČ® ņØ┤ņÖĆ Ļ░ÖņØĆ ļ¬©ņŖĄņØä ĒĢśĻ│Ā ņ׳ņŖĄļŗłļŗż.
- 99. { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É [1, 1]: Ļ╣Ćņä£ļ»╝ ] } { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É [1, 1]: Ļ╣Ćņä£ļ»╝ ] } { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É [1, 1]: Ļ╣Ćņä£ļ»╝ ] } { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É [1, 1]: Ļ╣Ćņä£ļ»╝ ] } ņØ┤ļ¤░ Ļ▓āņØ┤ ņŚ¼ļ¤¼ Ļ░£ ļ¬©ņŚ¼ ĒĢśļéśņØś ļĢģ ņ”ē Gridļź╝ ņØ┤ļŻ©ņŻĀ. ļŹö Ēü¼Ļ▓ī ļ│┤ļ®┤ ņä¼ ņŚ¼ļ¤¼ Ļ░£ļĪ£ ņØ┤ļŻ©ņ¢┤ņ¦ä ļōĆļ×æĻ│ĀļŖö Ļ▓░ĻĄŁ ņØ┤ Chunk ļŗ©ņ£ä ļ¼Ėņä£ļōżņØś ļ¬©ņØīņØ┤ļØ╝Ļ│Ā ĒĢśĻ▓ĀņŖĄļŗłļŗż.
- 100. ņé¼ņ£Āņ¦ĆļŖö ņ£äņ╣ś ĻĖ░ļ░ś ņŗ£ņŖżĒģ£ņØ┤ļØ╝ ļĢģņŚÉ ĻĖ░ļĪØļÉ£ ļŹ░ņØ┤Ēä░ņ¦Ćļ¦ī Ļ░ĆļüöņØĆ ņé¼ņ£Āņ¦Ć ņŻ╝ņØĖņØś ņØ┤ļ”äņ£╝ļĪ£ ņé¼ņ£Āņ¦ĆĻ░Ć ņ¢┤ļööņ¢┤ļöö ņ׳ļŖöņ¦Ć ņ░ŠņĢäņĢ╝ ĒĢĀ ĒĢäņÜöĻ░Ć ņ׳ņŖĄļŗłļŗż.
- 101. Ļ▓īļŗżĻ░Ć ņŻ╝ņØĖļÅä ļé┤ ņé¼ņ£Āņ¦ĆņØś ĻČīĒĢ£ņØä ļ®Ćļ”¼ņä£ļÅä ļ░öĻŠĖĻ│Ā ņŗČĻĖ░ ļĢīļ¼ĖņŚÉ ļé┤ ņé¼ņ£Āņ¦ĆĻ░Ć ņ¢┤ļööņŚÉ ņ׳ļŖöņ¦Ć ņĢīņĢäņĢ╝ ļ│ĆĻ▓ĮļÉ£ ĻČīĒĢ£ņØä ļ®Ćļ”¼ņä£ļÅä ļ░öļĪ£ ņĀüņÜ®ņŗ£Ēé¼ ņłś ņ׳Ļ▓ĀņŻĀ.
- 102. Views MapReduce ņŚ¼ļ¤¼ Ļ░£ņØś ļ¼Ėņä£ņŚÉ ĒØ®ņ¢┤ņ¦ä ņĀĢļ│┤ļź╝ ņ░ŠĻĖ░ ņ£äĒĢ┤ņä£ CouchbaseļŖö ViewsļØ╝ļŖö ĻĖ░ļŖźņØä ņ¦ĆņøÉĒĢ®ļŗłļŗż. MapReduceļØ╝ļŖö ĻĖ░ņłĀņØ┤ ĻĖ░ļ░śņØ┤ ļÉ£ ļČĆĻ░ĆĻĖ░ļŖźņØ┤ņŻĀ.
- 103. MapReduce map(f, [i1, i2, i3, ...]) = [f(i1), f(i2), f(i3) ...] reduce(g, [i1, i2, i3, ...]) = g(i1, g(i2, g(i3, ...))) mapĻ│╝ reduceļŖö ņŚ¼ļ¤¼ļČäņØ┤ ņĢäņŗ£ļŖö ĻĘĖĻ▓āņØ┤ ļ¦×ņŖĄļŗłļŗż. ņØ┤Ļ▒Ė ņ¢┤ļ¢╗Ļ▓ī ĒÖ£ņÜ®ĒĢ£ļŗżļŖö Ļ▓āņØ╝Ļ╣īņÜö?
- 104. { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É [1, 1]: Ļ╣Ćņä£ļ»╝ ] } { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É [1, 1]: Ļ╣Ćņä£ļ»╝ ] } { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É [1, 1]: Ļ╣Ćņä£ļ»╝ ] } { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É [1, 1]: Ļ╣Ćņä£ļ»╝ ] } ņØ┤ļ”ä ņ£äņ╣ś Ļ╣ĆļČĆņ×É [3, 2] Ļ╣ĆļČĆņ×É [2, 1] Ļ╣ĆļČĆņ×É [2, 2] Ļ╣ĆļČĆņ×É [3, 3] Ļ╣ĆļČĆņ×É [1, 2] Ļ╣Ćņä£ļ»╝ [1, 1] ŌĆ” ŌĆ” ņÜ░ļ”¼ļŖö ņØ┤ļ¤░ ņŚ¼ļ¤¼ Ļ░£ņØś ļ¼Ėņä£ļĪ£ļČĆĒä░ ņśżļźĖņ¬Į Ļ░ÖņØĆ ĒģīņØ┤ļĖöņØä ņ¢╗ĻĖ░ļź╝ ņøÉĒĢśņŻĀ
- 105. { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É [1, 1]: Ļ╣Ćņä£ļ»╝ ] } ņÜ░ņäĀ ĒĢśļéśņØś ļ¼Ėņä£ļ¦ī ļīĆņāüņ£╝ļĪ£ ļåōĻ│Ā ĒĢ┤ļ│╝Ļ╣īņÜö?
- 106. 1 2 3 4 5 6 function(doc) for (var cell in doc[ŌĆśestatesŌĆÖ]) { var owner = doc[ŌĆśestatesŌĆÖ][cell] emit(owner, cell) } } ņØ┤ļ¤░ ĒĢ©ņłśļ®┤ ņČ®ļČäĒĢĀ Ļ▓ā Ļ░ÖļäżņÜö! ĒÄĖņØśņāü ņÜö ĒĢ©ņłśļź╝ FļØ╝Ļ│Ā Ēæ£ĻĖ░ĒĢśĻ▓ĀņŖĄļŗłļŗż.
- 107. 1 2 3 4 5 { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É [1, 1]: Ļ╣Ćņä£ļ»╝ ] } ( ) ņØ┤ļ”ä ņ£äņ╣ś Ļ╣ĆļČĆņ×É [3, 2] Ļ╣ĆļČĆņ×É [2, 1] Ļ╣ĆļČĆņ×É [2, 2] Ļ╣Ćņä£ļ»╝ [1, 1] F ĒĢśļéśņØś ļ¼Ėņä£ļź╝ FņŚÉ ļäŻņ£╝ļ®┤ ņśżļŖśņ¬Į ņ▓śļ¤╝ ļŹ░ņØ┤Ēä░Ļ░Ć ļéśņśżĻ▓ĀļäżņÜö.
- 108. F { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É [1, 1]: Ļ╣Ćņä£ļ»╝ ] } { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É [1, 1]: Ļ╣Ćņä£ļ»╝ ] } { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É [1, 1]: Ļ╣Ćņä£ļ»╝ ] } { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É [1, 1]: Ļ╣Ćņä£ļ»╝ ] } map( , ) ņØ┤ļ”ä ņ£äņ╣ś Ļ╣ĆļČĆņ×É [3, 2] Ļ╣ĆļČĆņ×É [2, 1] Ļ╣ĆļČĆņ×É [2, 2] Ļ╣ĆĒÅēļ▓ö [1, 1] ņØ┤ļ”ä ņ£äņ╣ś Ļ╣ĆļČĆņ×É [3, 2] Ļ╣ĆļČĆņ×É [2, 1] Ļ╣ĆļČĆņ×É [2, 2] Ļ╣ĆĒÅēļ▓ö [1, 1] ņØ┤ļ”ä ņ£äņ╣ś Ļ╣ĆļČĆņ×É [3, 2] Ļ╣ĆļČĆņ×É [2, 1] Ļ╣ĆļČĆņ×É [2, 2] Ļ╣ĆĒÅēļ▓ö [1, 1] ņØ┤ļ”ä ņ£äņ╣ś Ļ╣ĆļČĆņ×É [3, 2] Ļ╣ĆļČĆņ×É [2, 1] Ļ╣ĆļČĆņ×É [2, 2] Ļ╣Ćņä£ļ»╝ [1, 1] mapņØä ņŚ¼ĻĖ░ņä£ ņé¼ņÜ®ĒĢśļ®┤ ļÉśĻ▓Āņ¢┤ņÜö. ņŚ¼ļ¤¼ Ļ░£ņØś ļŹ░ņØ┤Ēä░ļź╝ FņÖĆ ĒĢ©Ļ╗ś mapņŚÉ ļäŻņ£╝ļ®┤ Ļ░üĻĖ░ ļŹ░ņØ┤Ēä░ļź╝ ļ│æļĀ¼ ņ▓śļ”¼ĒĢ┤ņä£ ņ×æņØĆ ĒģīņØ┤ļĖöļōżņØä ņŻ╝Ļ▓ĀļäżņÜö.
- 109. ņØ┤ļ”ä ņ£äņ╣ś Ļ╣ĆļČĆņ×É [3, 2] Ļ╣ĆļČĆņ×É [2, 1] Ļ╣ĆļČĆņ×É [2, 2] Ļ╣ĆĒÅēļ▓ö [1, 1] ņØ┤ļ”ä ņ£äņ╣ś Ļ╣ĆļČĆņ×É [3, 2] Ļ╣ĆļČĆņ×É [2, 1] Ļ╣ĆļČĆņ×É [2, 2] Ļ╣ĆĒÅēļ▓ö [1, 1] ņØ┤ļ”ä ņ£äņ╣ś Ļ╣ĆļČĆņ×É [3, 2] Ļ╣ĆļČĆņ×É [2, 1] Ļ╣ĆļČĆņ×É [2, 2] Ļ╣ĆĒÅēļ▓ö [1, 1] ņØ┤ļ”ä ņ£äņ╣ś Ļ╣ĆļČĆņ×É [3, 2] Ļ╣ĆļČĆņ×É [2, 1] Ļ╣ĆļČĆņ×É [2, 2] Ļ╣Ćņä£ļ»╝ [1, 1] reduce(add, ) ņØ┤ļ”ä ņ£äņ╣ś Ļ╣ĆļČĆņ×É [3, 2] Ļ╣ĆļČĆņ×É [2, 1] Ļ╣ĆļČĆņ×É [2, 2] Ļ╣ĆļČĆņ×É [3, 3] Ļ╣ĆļČĆņ×É [1, 2] Ļ╣Ćņä£ļ»╝ [1, 1] ŌĆ” ŌĆ” ņØ┤ļĀćĻ▓ī ļ░øņØĆ ņŚ¼ļ¤¼ Ļ░£ņØś ĒģīņØ┤ļĖöņØĆ reduceļź╝ ņØ┤ņÜ®ĒĢ┤ņä£ ļ¬©ņ£╝ĻĖ░ļ¦ī ĒĢśļ®┤ ļÉśĻ▓ĀļäżņÜö. (ļŗżņ¢æĒĢ£ ĒĢ©ņłśļź╝ ņØ┤ņÜ®ĒĢśļ®┤ ņØ┤ ļŗ©Ļ│äņŚÉņä£ ļŹö ļ¦ÄņØĆ Ļ░ĆĻ│ĄņØä ĒĢĀ ņłś ņ׳ņ¦Ćļ¦ī ņ¦ĆĻĖłņØś ņśłņŗ£ļŖö ļŗ©ņł£Ē׳ ĒĢ®ņ╣śļŖö ļŹ░ļ¦ī ņöüļŗłļŗż)
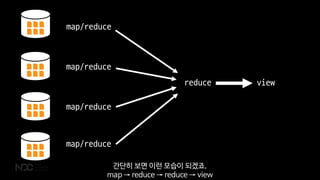
- 110. ņØ┤ļ”ä ņ£äņ╣ś Ļ╣ĆļČĆņ×É [3, 2] Ļ╣ĆļČĆņ×É [2, 1] Ļ╣ĆļČĆņ×É [2, 2] Ļ╣ĆļČĆņ×É [3, 3] Ļ╣ĆļČĆņ×É [1, 2] Ļ╣ĆĒÅēļ▓ö [1, 1] ŌĆ” ŌĆ” ņØ┤ļ”ä ņ£äņ╣ś Ļ╣ĆļČĆņ×É [3, 2] Ļ╣ĆļČĆņ×É [2, 1] Ļ╣ĆļČĆņ×É [2, 2] Ļ╣ĆļČĆņ×É [3, 3] Ļ╣ĆļČĆņ×É [1, 2] Ļ╣ĆĒÅēļ▓ö [1, 1] ŌĆ” ŌĆ” ņØ┤ļ”ä ņ£äņ╣ś Ļ╣ĆļČĆņ×É [3, 2] Ļ╣ĆļČĆņ×É [2, 1] Ļ╣ĆļČĆņ×É [2, 2] Ļ╣ĆļČĆņ×É [3, 3] Ļ╣ĆļČĆņ×É [1, 2] Ļ╣ĆĒÅēļ▓ö [1, 1] ŌĆ” ŌĆ” ņØ┤ļ”ä ņ£äņ╣ś Ļ╣ĆļČĆņ×É [3, 2] Ļ╣ĆļČĆņ×É [2, 1] Ļ╣ĆļČĆņ×É [2, 2] Ļ╣ĆļČĆņ×É [3, 3] Ļ╣ĆļČĆņ×É [1, 2] Ļ╣ĆĒÅēļ▓ö [1, 1] ŌĆ” ŌĆ” ņØ┤ļ”ä ņ£äņ╣ś Ļ╣ĆļČĆņ×É [3, 2] Ļ╣ĆļČĆņ×É [2, 1] Ļ╣ĆļČĆņ×É [2, 2] Ļ╣ĆļČĆņ×É [3, 3] Ļ╣ĆļČĆņ×É [1, 2] Ļ╣Ćņä£ļ»╝ [1, 1] ŌĆ” ŌĆ” CouchbaseļŖö ļČäņé░ ĻĄ¼ņĪ░ļź╝ ĒāØĒĢśĻ│Ā ņ׳ĻĖ░ ļĢīļ¼ĖņŚÉ Ļ░ü ļŹ░ņØ┤Ēä░ņä£ļ╣äņŖżņŚÉņä£ MapReduceļź╝ ĒåĄĒĢ┤ ņłśņ¦æĒĢ£ ļŹ░ņØ┤Ēä░ļź╝ ĒĢ£ļ▓ł ļŹö ļ¬©ņ£╝ļ®┤ ņÜ░ļ”¼Ļ░Ć ņøÉĒĢśļŖö Ļ▓░Ļ│╝Ļ░Ć ļéśņśĄļŗłļŗż.
- 111. map/reduce map/reduce map/reduce map/reduce reduce view Ļ░äļŗ©Ē׳ ļ│┤ļ®┤ ņØ┤ļ¤░ ļ¬©ņŖĄņØ┤ ļÉśĻ▓ĀņŻĀ. map ŌåÆ reduce ŌåÆ reduce ŌåÆ view
- 112. Views ļČäņé░ ĒśĢ ĻĄ¼ņĪ░ļź╝ Ļ░Ćņ¦ä CouchbaseņŚÉņä£ MapReduceļź╝ ĒÖ£ņÜ®ĒĢ£ ViewļŖö ĻĮż Ļ┤£ņ░«ņØĆ ņĀäļץņ×ģļŗłļŗż.
- 113. Views ĒĢśņ¦Ćļ¦ī ĻĮż Ļ┤£ņ░«ņØä ļ┐ÉņØ┤ņŚłņŻĀ. ņĀĆĒؼ ņé¼ņ£Āņ¦Ć ņŗ£ņŖżĒģ£ņØĆ ļČĆĒĢśĻ░Ć ļäłļ¼┤ ņŗ¼ĒĢ┤ņä£ Ļ▓ĆņāēņØä ņ£äĒĢ£ Views ļĢīļ¼ĖņŚÉ ļŹ░ņØ┤Ēä░ ņä£ļ╣äņŖżņŚÉ ņ¦ĆņןņØ┤ ņ׳ņØä ņĀĢļÅäņśĆņŖĄļŗłļŗż.
- 114. N1QL JSONņØä ņ£äĒĢ£ ņ£Āņé¼ SQL ĻĘĖļלņä£ N1QLņØä ĒÖ£ņÜ®ĒĢ┤ ļ│┤ĻĖ░ļĪ£ Ē¢łņŖĄļŗłļŗż. CouchbaseņŚÉņä£ ņĀ£Ļ│ĄĒĢśļŖö ņ£Āņé¼ SQLņ×ģļŗłļŗż.
- 115. ļŹ░ņØ┤Ēä░ņä£ļ╣äņŖż ņØĖļŹ▒ņŖżņä£ļ╣äņŖżņ┐╝ļ”¼ņä£ļ╣äņŖż Couchbase 4.0 ļČĆĒä░ ļČäļ”¼ Viewsļź╝ ņōĖ ļĢīļÅä ņ׳ņŚłņ¦Ćļ¦ī ņä▒ļŖźņØ┤ ņōĖ ņłś ņŚåļŖö ņłśņżĆņØ┤ņŚłņ¦Ćļ¦ī 4.0 ļ▓äņĀäļČĆĒä░ ņ┐╝ļ”¼ņÖĆ ņØĖļŹ▒ņŖż ņä£ļ╣äņŖżĻ░Ć ļČäļ”¼ļÉśņ¢┤ņä£ ņä▒ļŖźļ®┤ņŚÉņä£ ļ¦ÄņØ┤ ņóŗņĢäņĪīņŖĄļŗłļŗż.
- 116. ļŹ░ņØ┤Ēä░ņä£ļ╣äņŖż ņØĖļŹ▒ņŖżņä£ļ╣äņŖż ņ┐╝ļ”¼ņä£ļ╣äņŖż ļ│ĆĻ▓ĮņĀÉ Ļ▓Ćņāē Ļ▓░Ļ│╝ Ļ░äļץĒĢśĻ▓ī ņäżļ¬ģĒĢśļ®┤ ņØ┤ļ¤░ ļ░®ņŗØņ£╝ļĪ£ ļÅÖņ×æĒĢśļŖö ĻĄ¼ņĪ░ņ×ģļŗłļŗż.
- 117. ļŹ░ņØ┤Ēä░ņä£ļ╣äņŖż ņĀ£ņØ╝ ņżæņÜöĒĢ£ ņĀÉņØĆ ViewsļŖö ļŹ░ņØ┤Ēä░ ņä£ļ╣äņŖż Ēś╝ņ×Éņä£ Ļ│ĀņāØĒĢśļŖö ņŗ£ņŖżĒģ£ņØ┤ļØ╝ļ®┤
- 118. ļŹ░ņØ┤Ēä░ņä£ļ╣äņŖż ņØĖļŹ▒ņŖżņä£ļ╣äņŖżņ┐╝ļ”¼ņä£ļ╣äņŖż N1QLņØĆ ĻĘĖ ļČĆĒĢśĻ░Ć ļČäņé░ļÉ£ļŗżļŖö ņĀÉ ņ×ģļŗłļŗż. ĻĘĖļ”¼Ļ│Ā ļŹö ņżæņÜöĒĢ£ ņĀÉņØĆ Ļ▓Ćņāē ņŗ£ņŖżĒģ£ņŚÉ ļČĆĒĢśĻ░Ć Ļ▒ĖļĀżļÅä ļŹ░ņØ┤Ēä░ ņä£ļ╣äņŖżļŖö ņśüĒ¢źņØä ļ░øņ¦Ć ņĢŖļŖö ļŗżļŖö ņĀÉ ņØ┤ņŻĀ.
- 119. ņśżĒ└┐
- 120. ņØĖļŹ▒ņŖżņä£ļ╣äņŖżņ┐╝ļ”¼ņä£ļ╣äņŖżļŹ░ņØ┤Ēä░ņä£ļ╣äņŖż ĒĢśņ¦Ćļ¦ī ņĀĆĒؼņØś ĻĖ░ļīĆņÖĆ ļŗ¼ļ”¼ Views ļ│┤ļŗ© ļŹ£ĒĢśņ¦Ćļ¦ī ņŚ¼ņĀäĒ׳ N1QLļÅä ļŹ░ņØ┤Ēä░ ņä£ļ╣äņŖżļź╝ Ļ┤┤ļĪŁĒ×īļŗżļŖö ņé¼ņŗżņØ┤ ņśżĒ└┐ ĒøäņŚÉ ļ░£Ļ▓¼ļÉśņŚłņŖĄļŗłļŗż.
- 121. ļŹ░ņØ┤Ēä░ņä£ļ╣äņŖż ņØĖļŹ▒ņŖżņä£ļ╣äņŖż ņ┐╝ļ”¼ņä£ļ╣äņŖż ļ│ĆĻ▓ĮņĀÉ Ļ▓Ćņāē Ļ▓░Ļ│╝ ļŹ░ņØ┤Ēä░ ņä£ļ╣äņŖżĻ░Ć ļ│ĆĻ▓ĮņĀÉņØä ņØĖļŹ▒ņŖż ņä£ļ╣äņŖżļĪ£ ļ│┤ļé╝ ļĢī ļČĆĒĢśĻ░Ć ĻĮż ļ¦ÄļŗżļŖö ņé¼ņŗżņØä ņĢīĻ▓ī ļÉśņŚłņŖĄļŗłļŗż. ņØ┤ Ļ│╝ņĀĢļÅä ņóĆ ļ¼┤Ļ▓üņ¦Ćļ¦ī ļ│┤ļé┤ļŖö ņĮöļō£ļź╝ ņé┤ĒÄ┤ļ│┤ļŗł ņĮöļō£ ņ×Éņ▓┤ļÅä ĻĮżļéś ļ╣ä ĒÜ©ņ£©ņĀüņ£╝ļĪ£ ļÉśņ¢┤ņ׳ņŚłņŖĄļŗłļŗż.
- 122. ļŹ░ņØ┤Ēä░ņä£ļ╣äņŖż ŌĆó ņĀĆņןņØ┤ ļ╣łļ▓łĒĢĀ ņłśļĪØ ŌĆó ņĀĆņןĒĢ£ ļ¼Ėņä£ Ēü¼ĻĖ░Ļ░Ć Ēü┤ ņłśļĪØ ŌĆó N1QL ņØĖļŹ▒ņŖżĻ░Ć ļ¦ÄņØä ņłśļĪØ ļŗżņ¢æĒĢ£ ņŗżĒŚśĻ│╝ ņŚ░ĻĄ¼ļź╝ ĒåĄĒĢ┤ņä£ ņØ┤ļ¤░ ĒŖ╣ņ¦ĢļōżņØä ņĢīņĢäļé┤Ļ│Ā
- 123. ļŹ░ņØ┤Ēä░ņä£ļ╣äņŖż ŌĆó ļØ╝ņØ┤ļĖīņŚÉ ĒĢäņÜö ņŚåļŖö ņØĖļŹ▒ņŖż ļČäļ”¼ ŌĆó ļ¼Ėņä£ņØś Ēü¼ĻĖ░ ņżäņØ┤ĻĖ░ ļé┤ļČĆņĀüņØĖ ĒŖ£ļŗØņØä Ļ▒░ņ│Éņä£ ņ¢┤ļŖÉ ņĀĢļÅä Ļ░Éļŗ╣ņØ┤ Ļ░ĆļŖźĒĢ£ ņĀĢļÅäļĪ£ ļČĆĒĢśļź╝ ņżäņØ╝ ņłśņ׳ņŚłņŖĄļŗłļŗż.
- 124. Ļ┤Ćņä▒ņØś ĒĢ©ņĀĢ ŌĆó CouchbaseļŖö Key-Value Store ŌĆó Views, N1QLņØĆ ļČĆĻ░Ć ĻĖ░ļŖź ŌĆó RDBļź╝ ņé¼ņÜ®ĒĢśļŹś ļŖÉļéī ĻĘĖļīĆļĪ£ ļĪ£ņ¦üņØä ļööņ×ÉņØĖĒĢ© ĒĢśņ¦Ćļ¦ī ĻĘĖņÖĆ ļ│äĻ░£ļĪ£ ņĀĆĒؼļŖö ņ┐╝ļ”¼ ņä£ļ╣äņŖżņŚÉ ņØśņĪ┤ĒĢśņ¦Ć ņĢŖņĢäņĢ╝ ĒĢ£ļŗżļŖö Ļ▓░ļĪĀņØä ļé┤ļ”¼Ļ│Ā ņÜ░ļ”¼Ļ░Ć ļäłļ¼┤ RDB ņŖżļ¤¼ņÜ┤ DB ņé¼ņÜ®ļ▓ĢņŚÉ ņØĄņłÖĒĢ┤ņĀĖ ņ׳ļŖö Ļ▓āņØĆ ņĢäļŗīĻ░ĆņŚÉ ļīĆĒĢ£ ļ░śņä▒ņØä Ē¢łņŖĄļŗłļŗż.
- 125. { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É ] } ĻĘĖļלņä£ ņ┐╝ļ”¼ļź╝ ņé¼ņÜ®ĒĢśņ¦Ć ņĢŖļŖö ļ░®ņŗØņ£╝ļĪ£ ņ×¼ ĻĄ¼ĒśäĒĢśĻĖ░ļĪ£ Ļ▓░ņĀĢĒĢśņśĆņŖĄļŗłļŗż. GridņÖĆ ļ│äĻ░£ļĪ£ ņé¼ņ£Āņ¦Ć ĒĢśļéś ļ│äļĪ£ ļĢģļ¼Ėņä£ļź╝ ļ¦īļō£ļŖö ļ░®ņŗØņØ┤ņŚłņŖĄļŗłļŗż.
- 126. { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É ] } ņØ┤ņĀäņŚÉļÅä ļĢģļ¼Ėņä£ņŚÉ ņŻ╝ņØĖņØ┤ ļ¦üĒü¼ļÉśņ¢┤ ņ׳ļŖö Ļ▓āņØĆ Ļ░ÖņĢśņ¦Ćļ¦ī ņāł ņŗ£ņŖżĒģ£ņØś Ļ░Ćņן ņżæņÜöĒĢ£ ņ░©ņØ┤ņĀÉņØĆ ļŹ░ņØ┤Ēä░ņØś ĻĘ╝ņøÉņØ┤ ļĢģņØ┤ ņĢäļŗłļØ╝ ļĢģļ¼Ėņä£ļØ╝ļŖö ņĀÉ ņØ┤ņŚłņŖĄļŗłļŗż.
- 127. { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É ] } ņśłņĀäņŚö GridņŚÉ ņØ┤ ļĢģņØś ņŻ╝ņØĖņØ┤ ļłäĻĄ¼ņØĖņ¦Ć ņĀüĒśĆņ׳ņ£╝ļ®┤ ĻĘĖĻ▓āņØä ļ»┐ņŚłņ¦Ćļ¦ī ņØ┤ņĀ£ļŖö ļĢģļ¼Ėņä£ļź╝ ĒÖĢņØĖĒĢ┤ņä£ ĻĘĖ ļĢģņØ┤ ĻĖ░ļĪØļÉśņ¢┤ ņ׳ņ¦Ć ņĢŖļŗżļ®┤
- 128. { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É ] } ĻĘĖ ļĢģņØĆ Gridļź╝ ļ»┐ņ¦Ć ņĢŖĻ│Ā ņŻ╝ņØĖņØ┤ ņŚåļŖö ļĢģņ£╝ļĪ£ Ļ░äņŻ╝ĒĢśļŖö Ļ▓āņ×ģļŗłļŗż.
- 129. { estates: [ [3, 2]: Ļ╣ĆļČĆņ×É [2, 1]: Ļ╣ĆļČĆņ×É [2, 2]: Ļ╣ĆļČĆņ×É ] } ņØ┤ ļ░®ņŗØņØĆ GridļŖö ļŗ©ņł£Ē׳ ļĢģļ¼Ėņä£ļź╝ ĒÖĢņØĖĒĢśĻĖ░ ņ£äĒĢ£ ņŚ░Ļ▓░ņŚÉ ļČłĻ│╝ĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ļ¬©ļōĀ ļĢģņŚÉņä£ ņØ┤ ļĢģņØś ņŻ╝ņØĖņØä ĒÖĢņØĖĒĢśļĀżļ®┤ ņ¦ĆņåŹņĀüņ£╝ļĪ£ ļĢģļ¼Ėņä£ļź╝ ņØĮņ¢┤ņĢ╝ ĒĢ£ļŗżļŖö ņĀÉņØ┤ ļČĆļŗ┤ņØ┤ ļÉ®ļŗłļŗż.
- 130. ĒĢśņ¦Ćļ¦ī CouchbaseļŖö ņ×ÉņŗĀņØś ņןņĀÉņØä ņŗŁļČä ļ░£Ē£śĒĢśņŚ¼ Key-Value ņØĮĻĖ░ļŖö ņ║Éņŗ£ĻĖē ņä▒ļŖźņ£╝ļĪ£ ņČ®ļČäĒ׳ ĻĘ╣ļ│ĄĒĢśņśĆņŖĄļŗłļŗż. ņĀĆĒØ░ DBņØś ņĄ£Ļ│Ā ņןņĀÉņØä ļæÉĻ│Ā ļČłņÖäņĀäĒĢ£ ļČĆĻ░ĆĻĖ░ļŖźņ£╝ļĪ£ ņŚ┤ņŗ¼Ē׳ ņö©ļ”äĒĢśĻ│Ā ņ׳ļŹś ņģłņØ┤ņŚłņŻĀ.
- 131. ņŗ£ņ×æĒĢśĻĖ░ ņĀä ņŖżĒéżļ¦ł ļŹ░ņØ┤Ēä░ņØś ņĀĆņן ļæÉĻ░£ ņØ┤ņāüņØś ļ¼Ėņä£ņŚÉ ļīĆĒĢ£ ņĀĆņןĻ│╝ ļ│ĆĻ▓Į ņ┐╝ļ”¼ĒĢśĻĖ░ ņĀĢļ”¼
- 132. NoSQL ŌĆó RDBĻ░Ć ļŗ¼ņä▒ĒĢĀ ņłś ņŚåļŗżĻ│Ā ņāØĻ░üļÉśļŖö ļ¬®Ēæ£ļź╝ ņ£äĒĢ┤ ņל ļŗżņĀĖņ¦ä ĒÖśĻ▓ĮņØä ļ▓äļ”¼Ļ│Ā ļéśņś© Ļ▓āļōż ŌĆó ņĢäņ¦üļÅä ļ░£ņĀäĒĢśĻ│Ā ņ׳Ļ│Ā Ļ│äņåŹĒĢ┤ņä£ ļ░öļĆīĻ│Ā ņ׳ņØī ŌĆó ĻĘĖļלņä£ ļČäļ¬ģĒ׳ ļŗ©ļŗ©ĒĢśņ¦Ć ļ¬╗ĒĢ£ ļČĆļČäļōżņØ┤ ņĪ┤ņ×¼ĒĢ© ŌĆó ļŗ©ļŗ©ĒĢśņ¦Ć ļ¬╗ĒĢ£ ļČĆļČäņØä ņĢĀĒöīļ”¼ņ╝ĆņØ┤ņģśņŚÉņä£ ņ╗żļ▓äĒĢśĻ│Ā ņ׳ļŖö ļŖÉļéīņØä ļ░øņØī ŌĆó ņŗ£Ļ░äņØ┤ ĒØÉļź┤ļ®┤ RDBņ▓śļ¤╝ ļÉĀĻ╣ī?
- 133. Ļ▓īņ×ä ĒöīļĀłņØ┤ ĒöäļĪ£ĻĘĖļלļ©ĖļĪ£ņŹ© ŌĆó RDBļź╝ ņé¼ņÜ®ĒĢśļŹś ņŗ£ņĀłņŚÉļŖö ļ¬©ļōĀĻ▒Ė DBAņÖĆ ņāüļŗ┤ĒĢ© ŌĆó ĒĢśņ¦Ćļ¦ī Couchbaseļź╝ ņé¼ņÜ®ĒĢśļŗł Ļ▓īņ×ä ĒöīļĀłņØ┤ ļĪ£ņ¦üĻ│╝ ļŹ░ņØ┤Ēä░ļ▓ĀņØ┤ņŖżĻ░Ć ņĀüņØæĒĢśĻĖ░ Ēלļōż ņĀĢļÅäļĪ£ ĻĖēĻ▓®ĒĢśĻ▓ī Ļ░ĆĻ╣īņøīņ¦É ŌĆó ļŹ░ņØ┤Ēä░ļ▓ĀņØ┤ņŖżļź╝ Ļ╣ŖĻ▓ī ņØ┤ĒĢ┤ ĒĢ┤ņĢ╝ņ¦Ćļ¦ī Ļ▓īņ×ä ĒöīļĀłņØ┤ ļĪ£ņ¦üņØä ĻĄ¼ĒśäĒĢĀ ņłś ņ׳ņŚłļŗż.
- 134. ņĢ×ņ£╝ļĪ£ ŌĆó ņŚ¼ļ¤¼Ļ░Ćņ¦ĆņØś ļŹ░ņØ┤Ēä░ļ▓ĀņØ┤ņŖżļź╝ ĒĢäņÜöņŚÉ ņØśĒĢ┤ņä£ ņĪ░ĒĢ®ĒĢ┤ņä£ ņé¼ņÜ®ĒĢśļŖö ņŗ£ļīĆ ŌĆó ņĢ×ņ£╝ļĪ£ļÅä NoSQLņØä Ļ│äņåŹ ņé¼ņÜ®ĒĢ┤ņĢ╝ ĒĢĀ Ļ▓ā Ļ░ÖņØĆļŹ░ DBAņÖĆ Ļ▓īņ×ä ĒöīļĀłņØ┤ ĒöäļĪ£ĻĘĖļלļ©ĖņØś ņżæĻ░ä ņ¢┤ļööņ»ż ņ׳ļŖö ņŚŁĒĢĀņØ┤ ņāłļĪŁĻ▓ī ĒĢäņÜöĒĢ┤ņ¦ä Ļ▓āņØĆ ņĢäļŗīĻ░Ć ĒĢśļŖö ņāØĻ░ü