Novelties in social science statistics
ŌĆó
0 likesŌĆó30 views

Ji┼Ö├Ł Haviger from the University of Hradec Kralove discusses key topics in social science statistics including: 1) Determining sample size by specifying the acceptable type I error rate (╬▒), power (1- ╬▓), and estimated effect size to calculate the required sample size. 2) Using machine learning in social research for prediction rather than theory testing, with supervised models trained on data and evaluated on held-out samples. 3) Structural equation modeling to evaluate theoretical models describing relationships between observed and latent variables, with software like JASP used to estimate models and evaluate fit.































Novelties in social science statistics
- 1. Novelties in social science stats Ji┼Ö├Ł Haviger Faculty of Informatics nad Management University of Hradec Kralove Czech republic
- 2. Ji┼Ö├Ł Haviger psycholinguistic stat Text-Based Detection of the Risk of Depression quantitative linguistic Mutual Intelligibility between West-Slavic Languages stat for medicine CVID-Associated Tumors stat for psychology Using mood induction procedures in psychological research stat for math didactics The van Hiele geometry thinking levels Orcid 0000-0001-8353-497X Loop profile 550323 ResearcherID K-2198-2017 Scopus Author ID 24829164400 2
- 3. Points of presentation recap of IMRaD recap of inference stat Sample size determination Machine learning in social research Structural equation modeling 3
- 4. IMRaD ŌĆō structure of scientific storytelling Introduction ŌĆō WHY we create our reseach ? Opening Literature review Gap-of-knowledge Research question / hypothesis Method ŌĆō HOW we design our research ? Design Data collection Sample / Participants Procedure Results ŌĆō WHAT are our findings ? Remind the reader of the research question. Answer to the research question in words. Present the relevant statistics (table, graph). Discussion ŌĆō WHERE it is usefull ? Summary of the results Theoretical implications Practical implications Limits of our study Suggestions for future research 4
- 5. Introduction Why we create our reseach Reviewer ŌĆō topic Method How we design our research, obtain sample and handle with data Reviewer ŌĆō methodology and statistics Results What are our findings? Reviewer ŌĆō statistics Discussion Where it is useful? Reviewer ŌĆō topic 5 IMRaD - reviewers
- 6. Sample description old fashion article 6
- 7. Participants - article 1 Informed consent Ethical committee approval Short description Age mean, range Gender Recruitment method Exclusion / inclusion criteria important for Selection bias 7
- 8. Participants - article 2 Recruitment method Psychology students as a part of course Non-psychology students with a monetary compensation Inclusion criteria Informed consent important for Selection bias different motivation 8
- 9. Participants - article 3 Randomly assignation Usually in Design Recruitment method Voluntaries Credit in courses Power analysis Given strange of effect Given alpha, power important for Sample size determination Selection bias Voluntaries ŌĆō non random 9
- 10. Participants - article 4 Recruitment method Online survey panel Power analysis Monte Carlo simulation Given alpha, power Inclusion criteria Important for Sample size determination Selection bias Online = without control 10
- 11. How to determine sample size? reminder of classical hypothesis testing basic idea no information about population, but only about sample generalize (inference) from sample to population We hope that there is some difference, relation, ŌĆ” We have sample descriptive null hypothesis about population H0 usually diff = 0, can be different We want Come our sample from population where is H0 true? decision based on probabilities => p-value, sig 11
- 12. How to determine sample size? reminder of classical hypothesis testing example Example: We would like to proof, that there is some effect of intervention between experimental and control group We have mean + sd from experimental, mean + sd from control null hypothesis: effect(experimental) ŌĆō effect(control) = 0 ╬▒ (alpha), usually ╬▒ = 0.05 (see next) We want Come our sample from population where is H0 true? prob (sample is from popul with H0) = sig (p-value) Decision sig < ╬▒ => H0 in popul is improbable (H0 is not true) => discovery sig > ╬▒ => H0 in popul is probable (H0 is true) => non-discovery 12
- 13. Experimental ŌĆō control = ╬ö Problem: Sig (p-value) depends on ╬ö and sample size ╬ö increasing => sig decreasing (itŌĆśs OK) n increasing => sig decreasing bigger samples => more significant results https://imgs.xkcd.com/comics/slope_hypothesis_testing.png Solution - set minimal acceptable values based on expert minimal clinical important difference (MID,MCID) based on distribution effect size measures (CohenŌĆśs D, PearsonŌĆśs r, ŌĆ”) How to determine sample size? Problem with sig 13
- 14. we would like to generalize (inference) from sample to population decision based on probabilities => sig Medicine and data mining terminology: test gives negative result (T-) H0 true no effect (difference) detected non-discoveries (no illness) positive result (T+) H0 false effect (differnce) detected discoveries (illness) Decision about effect of intervention in population two possible error Test result sig > ╬▒ test negative(T-) sig < ╬▒ test positive(T+) In reality In population health True Negative False Positive Falsely detected illness illness False Negative Missed illness True Positive How to determine sample size? reminder of classical hypothesis testing test vs reality in population ŌĆō two kind of errors 14
- 15. We would like to control prob of erros in acceptable values falsely detect effect FP type I error p (reject H0 | H0 true) control via ╬▒ missed effect FN type II error p (accept H0 | H0 false) control via ╬▓ Statistical power TP p (reject H0 | H0 false) control via 1-╬▓ Error I prob, that study detects difference if a difference not exists Error II prob, that study misses difference if a difference really exists Power prob, that study detects a difference if a difference really exists Two possible error in decision Test-based decission T- T+ Population P- True nondiscoveries False discoveries Acceptable p(FP) = ╬▒ P+ False nondicoveries Acceptable p(FN) = ╬▓ True discoveries Acceptable p(TP) = 1-╬▓ How to determine sample size? reminder of classical hypothesis testing two kind of errors 15
- 16. There are four values in relation n required sample size ╬▒ required maximal prob of error one 1-╬▓ required minimal power (or max prob of error two, ╬▓) D required effect size, eg. Cohens D From three of them you can determine last one https://rpsychologist.com/d3/nhst/ Four values in relation 16
- 17. Effect size interpretation CohenŌĆÖs d PearsonŌĆÖs r Pointless d < 0.2 |r| < 0.1 Small d >= 0.2 |r| >= 0.1 Medium d >= 0.5 |r| >= 0.3 Large d >= 0.8 |r| >= 0.5 https://digitalcommons.wayne.edu/jmasm/vol8/iss2/26/ How to determine sample size? Effect size interpretation 17
- 18. A priori given (╬▒ , ╬▓, D) compute required sample size Sensitivity given (╬▒ , ╬▓, n) compute required D Post hoc given (╬▒ , n, D) computed achievenment ╬▓ ŌĆ” How to determine sample size? Type of power analysis 18
- 19. App G* power https://www.psychologie.hhu.de/arbeitsgruppen/allgemeine- psychologie-und-arbeitspsychologie/gpower R pwr package https://www.statmethods.net/stats/power.html Python power part of stat package https://machinelearningmastery.com/statistical-power-and- power-analysis-in-python/ How to determine sample size? G* power application 19
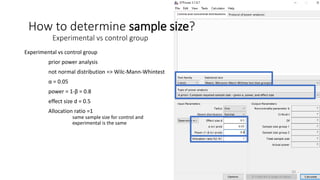
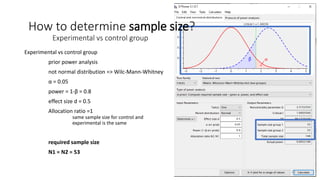
- 20. Experimental vs control group prior power analysis not normal distribution => Wilc-Mann-Whintest ╬▒ = 0.05 power = 1-╬▓ = 0.8 effect size d = 0.5 Allocation ratio =1 same sample size for control and experimental is the same 20 How to determine sample size? Experimental vs control group
- 21. Experimental vs control group prior power analysis not normal distribution => Wilc-Mann-Whitney ╬▒ = 0.05 power = 1-╬▓ = 0.8 effect size d = 0.5 Allocation ratio =1 same sample size for control and experimental is the same required sample size N1 = N2 = 53 21 How to determine sample size? Experimental vs control group
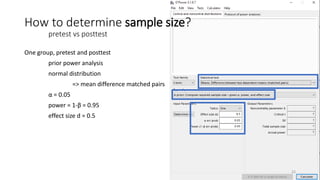
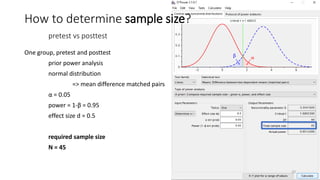
- 22. One group, pretest and posttest prior power analysis normal distribution => mean difference matched pairs ╬▒ = 0.05 power = 1-╬▓ = 0.95 effect size d = 0.5 How to determine sample size? pretest vs posttest 22
- 23. One group, pretest and posttest prior power analysis normal distribution => mean difference matched pairs ╬▒ = 0.05 power = 1-╬▓ = 0.95 effect size d = 0.5 required sample size N = 45 How to determine sample size? pretest vs posttest 23
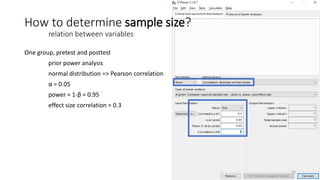
- 24. One group, pretest and posttest prior power analysis normal distribution => Pearson correlation ╬▒ = 0.05 power = 1-╬▓ = 0.95 effect size correlation = 0.3 How to determine sample size? relation between variables 24
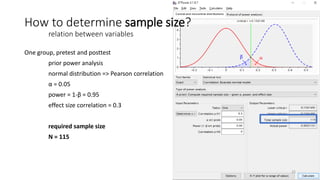
- 25. One group, pretest and posttest prior power analysis normal distribution => Pearson correlation ╬▒ = 0.05 power = 1-╬▓ = 0.95 effect size correlation = 0.3 required sample size N = 115 How to determine sample size? relation between variables 25
- 26. + verification research + hypothesis of difference, relation, univariate regression + software, packages + conected with effect size - exploratory research - factor analysis EFA - multiple testing problem - CFA, SEM - most of machine learning methods https://xkcd.com/2303/ How to determine sample size? 26
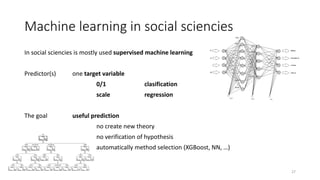
- 27. Machine learning in social sciencies In social sciencies is mostly used supervised machine learning Predictor(s) one target variable 0/1 clasification scale regression The goal useful prediction no create new theory no verification of hypothesis automatically method selection (XGBoost, NN, ŌĆ”) 27
- 28. Machine learning in social sciencies In social sciencies is mostly used supervised machine learning What we mean as (supervised) machine learning proces? General model with unknown parametrs Estimation parametrs from training part of dataset => trained model Used trained model to testing part of data => quality of model Visualisation of NN http://playground.tensorflow.org/ 28
- 29. Machine learning in social sciencies General model => learning => trained model What we mean as general model? Classification logistic regression (!), decission tree, XGBoost, ŌĆ” Regression (multi) linear regression (!), ordinal, curve estimation, neural networks, ŌĆ” 29
- 30. Machine learning in social sciencies For commonly used regressions (linear, logistic) shoul be used ML proces too. train at trainning part of dataset only quality measures at testing part of dataset only regression R, R^2 Correlation target vs predicted MSE, RMSE (root) mean square error MAPE (%) mean absolute percentage error classification Nagelkerke R^2 ACC accuracy Pre, Rec Precission, recall Sen, Spec Sensitivity, specificity 30
- 31. Machine learning in social sciencies + universal method not necessary to know, what is meaning of variables + more possibility to set general models (eg NN: #layers, #neurons in layer, Transform function, ŌĆ”ŌĆ”) => no-one know, which model is ŌĆ×correctŌĆ£, only wich is better and which worst => more possibility in parametrs => more probability of sucess + small possiblility to ŌĆ×hackŌĆ£ results, cause of quality measure in testing part only - (!) blackŌĆōbox, problematic explanation of model - (!) difficulty to compare with theory - (!) difficuilty establish new thoery GOOD for decision making, POOR for explanation and theory 31
- 32. We have observed variables model(s) We want verificate our theoretical model(s) describing weight of relations Goal of SEM evaluate given models(s) Based on https://semopy.com/syntax.html Structural equation modelling (SEM) 32
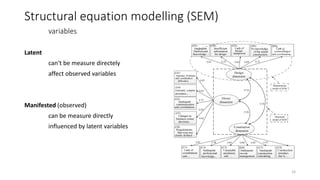
- 33. Latent canŌĆśt be measure directely affect observed variables Manifested (observed) can be measure directly influenced by latent variables Structural equation modelling (SEM) variables 33
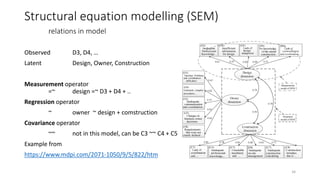
- 34. Observed D3, D4, ŌĆ” Latent Design, Owner, Construction Measurement operator =~ design =~ D3 + D4 + .. Regression operator ~ owner ~ design + comstruction Covariance operator ~~ not in this model, can be C3 ~~ C4 + C5 Example from https://www.mdpi.com/2071-1050/9/5/822/htm Structural equation modelling (SEM) relations in model 34
- 35. App JASP ŌĆō SEM https://jasp-stats.org/ R lavaan package, https://lavaan.ugent.be/tutorial/syntax1.html Python SEMOPY package https://semopy.com/ Structural equation modelling (SEM) 35
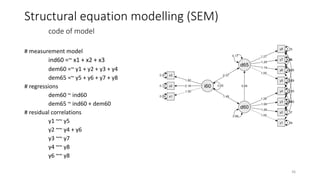
- 36. # measurement model ind60 =~ x1 + x2 + x3 dem60 =~ y1 + y2 + y3 + y4 dem65 =~ y5 + y6 + y7 + y8 # regressions dem60 ~ ind60 dem65 ~ ind60 + dem60 # residual correlations y1 ~~ y5 y2 ~~ y4 + y6 y3 ~~ y7 y4 ~~ y8 y6 ~~ y8 Structural equation modelling (SEM) code of model 36
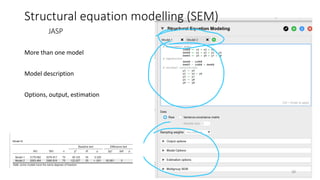
- 37. Structural equation modelling (SEM) JASP 37 As deafault disable Enable in +
- 38. Structural equation modelling (SEM) JASP 38 More than one model Model description Options, output, estimation
- 39. Structural equation modelling (SEM) JASP 39 Output additional fit measure Path diagram
- 40. Structural equation modelling (SEM) JASP - output 40 Compare more models Chisq p-value should be > .05 Same df not possible to compute difference test https://easystats.github.io/effectsize/reference/interpret_gfi.html
- 41. Structural equation modelling (SEM) JASP ŌĆō output and criterion 41 Fit indices CFI should be > .90 Information criteria for comparing models AIC lower => better BIC lower => better Other fit measures RMSEA should be < .08 or < .05. GFI 1 perfect fit. Ōēź 0.95 excellent fit (Kline, 2005) Ōēź 0.9 reasonable fit (Hu & Bentler, 1998) https://easystats.github.io/effectsize/reference/interpret_gfi.html https://uedufy.com/how-to-interpret-model-fit-results-in-amos/
- 42. Structural equation modeling + more relations (better than hypothesis testing) + more than one target (better than ML) + theory-based model (better than ML) + recomandation for sample size (https://www.danielsoper.com/statcalc/calculator.aspx?id=89 ) + general model confirmatory factor analysis, mediation analysis, ŌĆ” - no recomandation how to create good model, - no automatic way to generate model - two math ways ŌĆō SEM / Partial Least Square Path Modeling (PLS PM), - (!) poor implication to real application Sometimes not clear how to intervate to expect good effect GOOD for explanation and theory, POOR for application 42
- 43. Summary Sample size determination Machine learning in social research SEM Ji┼Ö├Ł Haviger Faculty of Informatics nad Management University of Hradec Kralove Czech republic 43