NVIDIA deep learningŚîĐÂÇéóin_żI
?
3 likes?786 views

_żIÊĐStartup Cafe Koza€ÇĐЀÀż„»„ß„Ê©`ÙYÁÏ









































NVIDIA deep learningŚîĐÂÇéóin_żI
- 1. „š„Ì„Ó„Ç„Ł„ąșÏÍŹ»áÉç „Ç„Ł©`„Ś„é©`„Ë„ó„°Čż ČżéL ŸźțD ÎäÊż NVIDIA GPU „Ç„Ł©`„Ś„é©`„Ë„ó„° ŚîĐÂÇéó IN _żI 2017Äê2ÔÂ04ÈŐ
- 2. 2 I1993Äê čČÍŹÁąŐߌæCEO „ž„§„ó„č„ó?„Ő„ą„ó ŁšJen-Hsun HuangŁ© 1999Äê NASDAQ€ËÉÏöŁšNVDAŁ© 1999Äê€ËGPU€ò°kĂś €œ€Îáá€ÎÀÛÓłöșÉÌšÊę€Ï10|ÒÔÉÏ 2015Äê¶È€ÎÓÉϞ߀Ï46|8,000Íò„É„ë ÉçT€ÏÊÀœçÈ«Ìć€Ç9,100ÈË Œs7,300Œț€ÎÌŰÔS€ò±ŁÓĐ ±ŸÉç€ÏĂŚčú„«„ê„Ő„©„ë„Ë„ąÖĘ„”„ó„ż„Ż„é„é
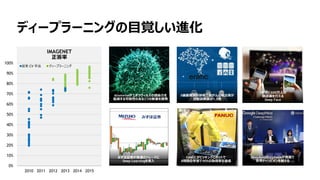
- 4. 4 AGENDA Deep Learning €È€ÏŁż €Ê€ŒGPU€ŹDeep Learning€ËÏò€€€Æ€€€ë€Î€« NVIDIA Deep Learning„Ś„é„Ă„È„Ő„©©`„à ŚîĐÂŃĐŸżÊÂÀę(Deep Learning Institute 2016€è€ê)
- 5. 5 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 2009 2010 2011 2012 2013 2014 2015 2016 „Ç„Ł©`„Ś„é©`„Ë„ó„°€ÎÄżÒ€·€€ßM»Ż IMAGENET ŐęŽđÂÊ ŸÀŽ CV ÊÖ·š „Ç„Ł©`„Ś„é©`„Ë„ó„° DeepMind€ÎAlphaGo€Źìł€Ç ÊÀœç„Á„ă„ó„Ô„Ș„ó€òÔœ€š€ë Atomwise€Ź„š„Ü„é„Š„Ł„ë„č€ÎžĐÈŸÁŠ€ò ”Íp€č€ëżÉÄÜĐԀ΀ą€ë2€Ä€ÎĐÂËa€òé_°k FANUC€Ź„Ô„Ă„„ó„°„í„Ü„Ă„È€Ç 8rég€ÎŃ§Ï°€Ç90%€ÎÈĄ”ĂÂÊ€òß_łÉ XŸ»ÏńŐiÓ°Ô\¶Ï€Ç·Î€Ź€ó€ÎÊłöÂÊ€Ź ŐiÓ°Ô\¶ÏÒœ€Î1.5±¶ €ß€ș€ÛÔ^ÈŻ€ŹÖêę€Î„È„ì©`„É€Ë Deep Learning€ò§Èë 1Ăëég€Ë600ÍòÈˀΠîŐJŚR€òĐĐ€š€ë Deep Face
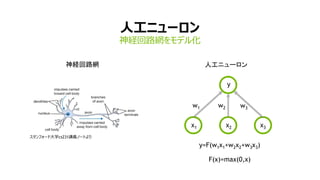
- 6. 6 ÈË耄˄ć©`„í„ó ÉńœU»Ű·ŸW€ò„â„DŽ뻯 „č„ż„ó„Ő„©©`„ÉŽóѧcs231ÖvÁx„Ω`„È€è€ê ÉńœU»Ű·ŸW w1 w2 w3 x1 x2 x3 y y=F(w1x1+w2x2+w3x3) F(x)=max(0,x) ÈË耄˄ć©`„í„ó
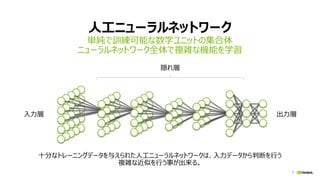
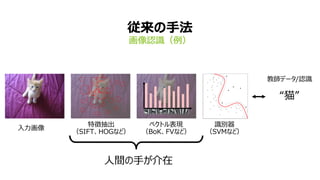
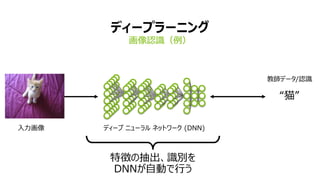
- 9. 9 „Ç„Ł©`„Ś„é©`„Ë„ó„° »ÏńŐJŚRŁšÀ꣩ ÈëÁŠ»Ïń œÌ„Ç©`„ż/ŐJŚR Ą°ĂšĄ± „Ç„Ł©`„Ś „Ë„ć©`„é„ë „Í„Ă„È„ï©`„Ż (DNN) ÌŰՀγéłöĄąŚRe€ò DNN€ŹŚÔÓ€ÇĐĐ€Š
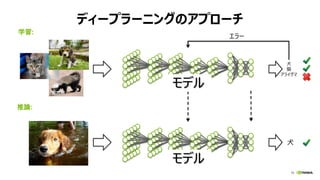
- 10. 10 „Ç„Ł©`„Ś„é©`„˄󄰀΄ą„Ś„í©`„Á ÍÆŐ: Èź Ăš ĂÛŃšĐÜ „š„é©` Èź Ăš „ą„é„€„°„Ț Èź Ń§Ï°: „â„Ç„ë „â„Ç„ë
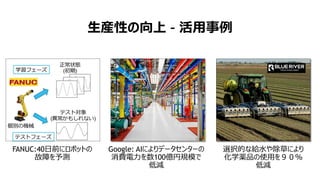
- 13. ÉúźbĐÔ€ÎÏòÉÏ šC »îÓĂÊÂÀę Google: AI€Ë€è€ê„Ç©`„ż„»„ó„ż©`€Î ÏûÙMëÁŠ€òÊę100|ÒÒÄŁ€Ç ”Íp FANUC:40ÈŐÇ°€Ë„í„Ü„Ă„È€Î čÊŐÏ€òÓèy ßxk”ĀʜoËź€äłęČʀˀè€ê »ŻŃ§ËaÆ·€ÎÊčÓĂ€òŁčŁ°Ł„ ”Íp
- 14. ±ăÀû€ÊÉú»î šC »îÓĂÊÂÀę Alibaba: „č„Ț©`„È„Ő„©„ó€ÇŽé€Ă€ż ĐŽŐ怫€éÍŹÒ»ÉÌÆ·ĄąîËÆÉÌÆ·€ò ÊËś WEpod:Žóѧ€ÈœüëO€Îńkég€òßB œj€č€ëŚÔÓß\ÜëĘŚÔÓÜ€Ź ”Çö Sharp: €Șßłę„í„Ü„Ă„È€ËÒôÉù ŐJŚR€òŽîĘdĄŁ„Ï„ó„ș„Ő„ê©`€Ç ßłę€òé_ÊŒ
- 15. AI CO-PILOT (1) Face Recognition Head Tracking
- 16. AI CO-PILOT (2) Lip ReadingGaze Tracking
- 18. °ČĐÄ?°ČÈ«€ÊÉú»î šC »îÓĂÊÂÀę Paypal:Č»ŐęQg€ÎÊłö€Î Ő`óÂÊ€Ź50%”Íp herta Security:„č„Ț©`„ȱOÒ „«„á„é€Ë€è€êżŐžÛ€ä„·„ç„Ă„Ô„ó„° „â©`„ë€Îč«čČ°ČÈ«€òÏòÉÏ vRad:CT„č„„ă„ó»Ïń€Ë€è€êĄąÇ± ÔڔĀËî^ÉwÄڀγöŃȘ€ÎżÉÄÜĐÔ €Źžß€€čwËù€òÌ۶š€·ĄąÓè·À
- 19. 20 DEEP LEARNING INSIGHT ŸÀŽ€Î„ą„ë„Ž„ê„ș„à „Ç„Ł©`„Ś„é©`„Ë„ó„° 0% 20% 40% 60% 80% 100% overall passenger channel indoor public area sunny day rainny day winter summer Pedestrian detection Recall rate Traditional Deep learning 70 75 80 85 90 95 100 vehicle color brand model sun blade safe belt phone calling Vehicle feature accuracy increased by Deep Learning traditional algorithm deep learning ±OÒ„«„á„é
- 21. 22 „Ç„Ł©`„Ś„é©`„Ë„ó„°€òŒÓËÙ€č€ë3ÒȘÒò DNN GPU„Ó„Ă„°„Ç©`„ż 1·Öég€Ë100 rég€Î „Ó„Ç„Ș€Ź„ą„Ă„Ś„í©`„É ÈŐĄ©3.5|„€„á©`„ž €Ź„ą„Ă„Ś„í©`„É 1rég€Ë2.5ŐŚŒț€Î îżÍ„Ç©`„ż€Ź°kÉú 0.0 0.5 1.0 1.5 2.0 2.5 3.0 2008 2009 2010 2011 2012 2013 2014 NVIDIA GPU x86 CPU TFLOPS TORCH THEANO CAFFE MATCONVNET PURINEMOCHA.JL MINERVA MXNET*
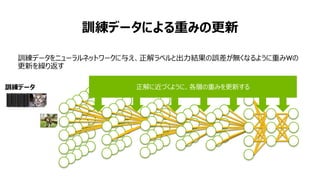
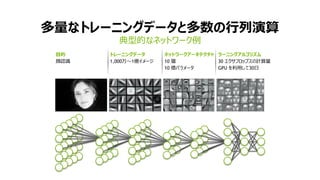
- 22. 23 ”äĐÍ”Ä€Ê„Í„Ă„È„ï©`„ŻÀę ¶àÁż€Ê„È„ì©`„Ë„ó„°„Ç©`„ż€È¶àÊę€ÎĐĐÁĐŃĘËă Äż”Ä îŐJŚR „È„ì©`„Ë„ó„°„Ç©`„ż 1,000ÍòĄ«1|„€„á©`„ž „Í„Ă„È„ï©`„Ż„ą©`„„Æ„Ż„Á„ă 10 Ó 10 |„Ń„é„á©`„ż „é©`„Ë„ó„°„ą„ë„Ž„ê„ș„à 30 „š„Ż„”„Ő„í„Ă„Ś„č€ÎÓËăÁż GPU €òÀûÓĂ€·€Æ30ÈŐ
- 23. 24 NVIDIA Deep Learning „Ś„é„Ă„È„Ő„©©`„à
- 24. 25 Ń§Ï°€ÈÍÆŐ„Ś„é„Ă„È„Ő„©©`„à „ï©`„Ż„č„Æ©`„·„ç„ó „”©`„Đ©` NVIDIA Tesla NVIDIA TEGRA/JETSON TX1 Ń§Ï° ÍÆŐ NVIDIA Tesla/DGX-1 „Ș„ó„é„€„ó „Ș„Ő„é„€„ó X
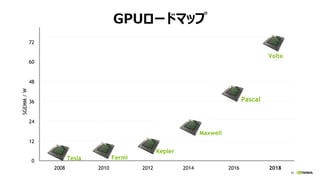
- 25. 26 GPU„í©`„É„Ț„Ă„ŚSGEMM/W 2012 20142008 2010 2016 48 36 12 0 24 60 2018 72 Tesla Fermi Kepler Maxwell Pascal Volta
- 26. 27 ±¶Ÿ«¶È 5.3TF | gŸ«¶È 10.6TF | °ëŸ«¶È 21.2TF TESLA P100 „Ï„€„Ń©`„脱©`„ë„Ç©`„ż„»„ó„ż©`€Î€ż€á€Î ÊÀœç€ÇŚî€âÏÈßM”Ä€Ê GPU
- 27. 28 P100€ÎŒŒĐgžïĐ 16nm FinFETPascal „ą©`„„Æ„Ż„Á„ă CoWoS /HBM2 NVLink
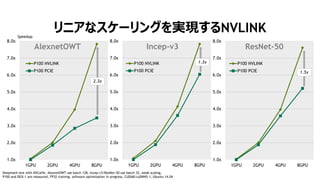
- 28. 29 „ê„Ë„ą€Ê„脱©`„ê„ó„°€ògŹF€č€ëNVLINK 1.0x 2.0x 3.0x 4.0x 5.0x 6.0x 7.0x 8.0x 1GPU 2GPU 4GPU 8GPU AlexnetOWT P100 NVLINK P100 PCIE Deepmark test with NVCaffe. AlexnetOWT use batch 128, Incep-v3/ResNet-50 use batch 32, weak scaling, P100 and DGX-1 are measured, FP32 training, software optimization in progress, CUDA8/cuDNN5.1, Ubuntu 14.04 1.0x 2.0x 3.0x 4.0x 5.0x 6.0x 7.0x 8.0x 1GPU 2GPU 4GPU 8GPU Incep-v3 P100 NVLINK P100 PCIE 1.0x 2.0x 3.0x 4.0x 5.0x 6.0x 7.0x 8.0x 1GPU 2GPU 4GPU 8GPU ResNet-50 P100 NVLINK P100 PCIE Speedup 2.3x 1.3x 1.5x
- 29. 30NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE. NVIDIA DGX-1 ÊÀœçłő„Ç„Ł©`„Ś„é©`„Ë„ó„° „č©`„Ń©`„ł„ó„Ô„ć©`„ż©` „Ç„Ł©`„Ś„é©`„Ë„ó„°Ïò€±€ËÔOÓ 170 TF FP16 8 Tesla P100 „Ï„€„Ö„ê„Ă„É?„„ć©`„Ö„á„Ă„·„ć ÖśÒȘ€ÊAI„Ő„ì©`„à„ï©`„Ż€òŒÓËÙ
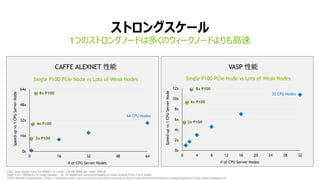
- 30. 31 0x 16x 32x 48x 64x 0 16 32 48 64 „č„È„í„󄰄脱©`„ë 1€Ä€Î„č„È„í„󄰄Ω`„É€Ï¶à€Ż€Î„Š„Ł©`„Ż„Ω`„É€è€ê€âžßËÙ VASP ĐÔÄÜ 2x P100 CPU: Dual Socket Intel E5-2680v3 12 cores, 128 GB DDR4 per node, FDR IB VASP 5.4.1_05Feb16, Si-Huge Dataset. 16, 32 Nodes are estimated based on same scaling from 4 to 8 nodes Caffe AlexNet scaling data: https://software.intel.com/en-us/articles/caffe-training-on-multi-node-distributed-memory-systems-based-on-intel-xeon-processor-e5 CAFFE ALEXNET ĐÔÄÜ 4x P100 8x P100 Single P100 PCIe Node vs Lots of Weak Nodes # of CPU Server Nodes Speed-upvs1CPUServerNode 0x 2x 4x 6x 8x 10x 12x 0 4 8 12 16 20 24 28 32 2x P100 8x P100 Single P100 PCIe Node vs Lots of Weak Nodes # of CPU Server Nodes Speed-upvs1CPUServerNode 4x P100 64 CPU Nodes 32 CPU Nodes
- 31. 32 Fastest AI Supercomputer in TOP500 4.9 Petaflops Peak FP64 Performance 19.6 Petaflops DL FP16 Performance 124 NVIDIA DGX-1 Server Nodes Most Energy Efficient Supercomputer #1 on Green500 List 9.5 GFLOPS per Watt 2x More Efficient than Xeon Phi System Rocket for Cancer Moonshot CANDLE Development Platform Optimized Frameworks DGX-1 as Single Common Platform INTRODUCING DGX SATURNV WorldĄŻs Most Efficient AI Supercomputer
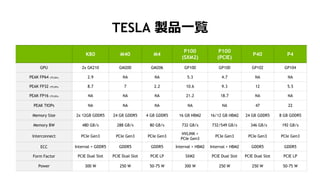
- 32. 33 K80 M40 M4 P100 (SXM2) P100 (PCIE) P40 P4 GPU 2x GK210 GM200 GM206 GP100 GP100 GP102 GP104 PEAK FP64 (TFLOPs) 2.9 NA NA 5.3 4.7 NA NA PEAK FP32 (TFLOPs) 8.7 7 2.2 10.6 9.3 12 5.5 PEAK FP16 (TFLOPs) NA NA NA 21.2 18.7 NA NA PEAK TIOPs NA NA NA NA NA 47 22 Memory Size 2x 12GB GDDR5 24 GB GDDR5 4 GB GDDR5 16 GB HBM2 16/12 GB HBM2 24 GB GDDR5 8 GB GDDR5 Memory BW 480 GB/s 288 GB/s 80 GB/s 732 GB/s 732/549 GB/s 346 GB/s 192 GB/s Interconnect PCIe Gen3 PCIe Gen3 PCIe Gen3 NVLINK + PCIe Gen3 PCIe Gen3 PCIe Gen3 PCIe Gen3 ECC Internal + GDDR5 GDDR5 GDDR5 Internal + HBM2 Internal + HBM2 GDDR5 GDDR5 Form Factor PCIE Dual Slot PCIE Dual Slot PCIE LP SXM2 PCIE Dual Slot PCIE Dual Slot PCIE LP Power 300 W 250 W 50-75 W 300 W 250 W 250 W 50-75 W TESLA ŃuÆ·Ò»ÓE
- 33. 34 TEGRA JETSON TX1 „â„ž„ć©`„ëĐÍ„č©`„Ń©`„ł„ó„Ô„ć©` „ż©` Öś€Ê„č„Ú„Ă„Ż GPU 1 TFLOP/s 256„ł„ą Maxwell CPU 64„Ó„Ă„È ARM A57 CPU „á„â„ê 4 GB LPDDR4 | 25.6 GB/s „č„È„ì©`„ž 16 GB eMMC Wifi/BT 802.11 2x2 ac / BT Ready „Í„Ă„È„ï©`„Ż 1 Gigabit Ethernet „”„€„ș 50mm x 87mm „€„ó„ż©`„Ő„§©`„č 400„Ô„ó „Ü©`„ÉégœÓŸA„ł„Í„Ż„ż ÏûÙMëÁŠ ŚîŽó10W Under 10 W for typical use cases
- 34. 35 NVIDIA DRIVE PX 2 12 CPU„ł„ą | Pascal GPU | 8 TFLOPS | 24 DL TOPS | 16nm FF | 250W | „ê„„Ă„É„Ż©`„ê„ó„°·œÊœ ÊÀœçłő ŚÔÓß\ÜÏò€±AI„č©`„Ń©`„ł„ó„Ô„ć©`„ż
- 35. 36 NVIDIA GPU „脱©`„é„Ö„ë „ą©`„„Æ„Ż„Á„ă „â„Đ„€„뀫€é„č©`„Ń©`„ł„ó„Ô„ć©`„ż€Ț€Ç Tesla In Super Computers Quadro In Work Stations GeForce In PCs Mobile GPU In Tegra Tegra
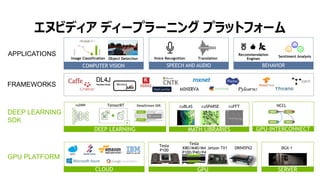
- 36. 37 „š„Ì„Ó„Ç„Ł„ą „Ç„Ł©`„Ś„é©`„Ë„ó„° „Ś„é„Ă„È„Ő„©©`„à COMPUTER VISION SPEECH AND AUDIO BEHAVIOR Object Detection Voice Recognition Translation Recommendation Engines Sentiment Analysis DEEP LEARNING MATH LIBRARIES cuBLAS cuSPARSE GPU-INTERCONNECT NCCLcuFFT Mocha.jl Image Classification DEEP LEARNING SDK FRAMEWORKS APPLICATIONS GPU PLATFORM CLOUD GPU Tesla P100 Tesla K80/M40/M4 P100/P40/P4 Jetson TX1 SERVER DGX-1 TensorRT DRIVEPX2
- 37. 38 „š„Ì„Ó„Ç„Ł„ą DIGITS DETECTION SEGMENTATION CLASSIFICATION
- 39. ŚîĐ€ÎŃĐŸżÊÂÀę
- 40. Quanzheng Li Associate Professor, Massachusetts General Hospital DEEP LEARNING ON METASTASIS DETECTION OF BREAST CANCER USING DGX-1 SESSION 1
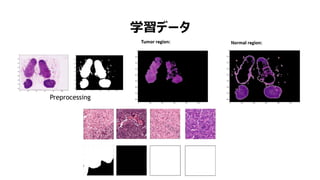
- 42. ŃĐŸż€ÎÓC ? „ê„ó„ŃčÜÒƀπۀȀó€É€Î°©€Î„ż„€„Ś€Ç°kÉú€č€ë Łše.g. ĐŰČżĄąÇ°ÁąÏÙĄąœYÄc) ? „ê„ó„Ńč€ÏĐĄ€”€ÊĂâÒߌ°û€ÎK€Ç„ê„ó„ŃÏ”€Î „Ő„Ł„ë„ż©`€È€·€ÆÓŚś€č€ë ? Ă|€ÎÏ€΄ê„ó„ŃčŁšÒžÏ„ê„ó„Ńč)€ÏÈ透€ó€Ź Ú€Ź€ê€ä€č€€Śîłő€ÎčwËù€Ç€ą€ë ? „ê„ó„Ńč€ÎŚŽB€ÏÓèáá€ËŽó€€ŻévßB€č€ëĄą °©€Ź„ê„ó„Ńč€ËÚ€Ź€Ă€Æ€€€ë€ÈÓèáဏ€Ż€Ê€ë ? ČĄÀíÊËÒœ€ÎÔ\¶Ï€ÎÊÖí€Ï gŐ{€Ç rég€Ź€«€«€ëŚśI€ÇĄąŐ`€Ă€żœâá€òÒę€Æđ€ł€čöșÏ€Ź€ą€ë
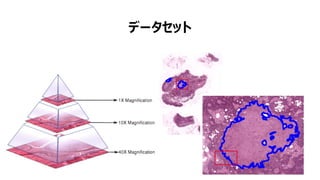
- 43. ? „Ç©`„ż„»„Ă„È€ÏCamelyon16 Challenge€Î€â€Î€òÀûÓĂ https://camelyon16.grand-challenge.org/ ? „Ç©`„ż€Ë€Ï2€Ä€Î¶ÀÁą€·€ż„Ç©`„ż„»„Ă„È€«€éșÏÓ400€ÎiÉÚ„ê„ó„Ńč€ÎWSI(Whole-slide-image)€ŹșŹ €Ț€ì€Æ€€€ë ? „È„ì©`„Ë„ó„°„Ç©`„ż ? „Æ„č„È„Ç©`„ż „Ș„é„ó„À€Î„é„É„Đ„Š„ÉŽóѧ„á„Ç„Ł„«„ë„»„ó„ż©`/„æ„È„ì„Ò„ÈŽóѧ„á„Ç„Ł„«„ë„»„ó„ż©`€«€éŒŻ€á€ż130€ÎWSI „Ç©`„ż„»„Ă„È
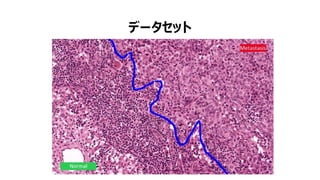
- 44. „Ç©`„ż„»„Ă„È
- 45. „Ç©`„ż„»„Ă„È
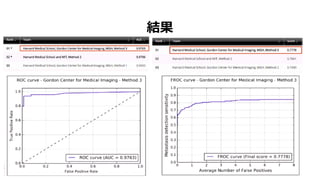
- 46. TASK „č„é„€„É„Ù©`„č€ÎÔuę ? ÜÒÆ€òșŹ€à„č„é„€„É€ÈŐ곣€Ê„č„é„€„É€ÎÇűe ? „č„é„€„É„ì„Ù„ë€Ç€ÎROC·ÖÎö ? „ą„ë„Ž„ê„ș„à€Î±ÈĘ^€ÏROCÇúŸÏÂĂæ·eŁšAUCŁ©€òÓĂ€€€ë ČĄä„Ù©`„č€ÎÔuę ? ĐĆîm„č„ł„ą€ò°é€ŠÄ[ŻîIÓò€ÎÊłö ? FROCÇúŸ€òÊčÓĂ ? ŚîœK„č„ł„ą€Ï€ą€é€«€ž€áQ€á€é€ì€żFalse-PositiveÂÊ€ÎžĐ¶È€È€·€ÆQ€á€é€ì€ë 1/4,1/2,1,2,4,8
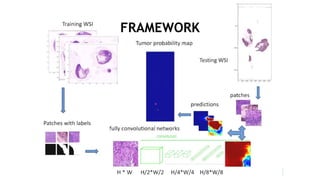
- 47. FRAMEWORK
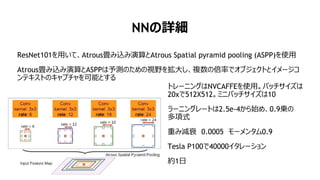
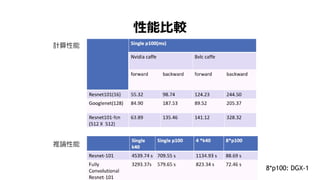
- 49. NN€ÎÔŒ ResNet101€òÓĂ€€€ÆĄąAtrousź€ßȚz€ßŃĘËă€ÈAtrous Spatial pyramid pooling (ASPP)€òÊčÓĂ Atrousź€ßȚz€ßŃĘËă€ÈASPP€ÏÓèy€Î€ż€á€ÎÒÒ°€òŽó€·ĄąŃ}Êę€Î±¶ÂʀDŽȘ„Ö„ž„§„Ż„ȀȄ€„á©`„ž„ł „ó„Æ„„č„Ȁ΄„ă„Ś„Á„ă€òżÉÄ܀Ȁč€ë „È„ì©`„Ë„ó„°€ÏNVCAFFE€òÊčÓĂĄŁ„Ń„Ă„Á„”„€„ș€Ï 20x€Ç512X512ĄŁ„ß„Ë„Đ„Ă„Á„”„€„ș€Ï10 „é©`„Ë„ó„°„ì©`„È€Ï2.5e-4€«€éÊŒ€áĄą0.9\€Î ¶àíÊœ ÖŰ€ßpË„ 0.0005 „â©`„á„ó„ż„à0.9 Tesla P100€Ç40000„€„ż„ì©`„·„ç„ó Œs1ÈŐ
- 50. ·Öî„ż„č„Ż Tumor Probability map€«€é€â€Ă€È€âŽó€€ÊÄ[ Ż€òÈĄ€êłö€č€ż€á€ËžßŽÎ€ÎÌŰŐ€òłéłö Łšskimage€ÎĄ±regionpropsĄ±€Çź€Ê€ëé€òÓĂ €€€ëŁ© ·Öî€Ë€Ï„é„ó„À„à„Ő„©„ì„č„È€òÊčÓĂ Êłö„ż„č„Ż Tumor Probability map€Ë€Ș€€€Æ„Ò©`„È„Ț„Ă„Ś€Î îIÓò€òœYșÏ€č€ë ŁšConnectivity=2ĄąThreshold=0.95)
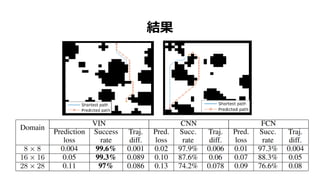
- 52. œáčû
- 53. Joon Son Chung et al, Department of Engineering Science, University of Oxford. Google DeepMind LIP READING SENTENCES IN THE WILD SESSION 2 https://arxiv.org/pdf/1611.05358v1.pdf
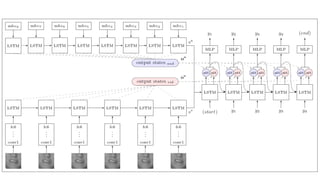
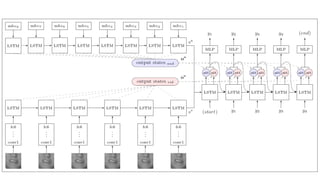
- 54. LIP READING
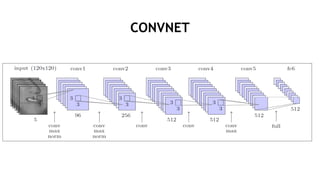
- 56. CONVNET
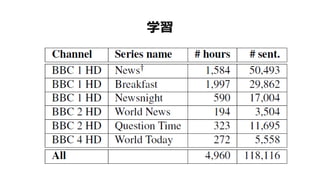
- 58. Ń§Ï°
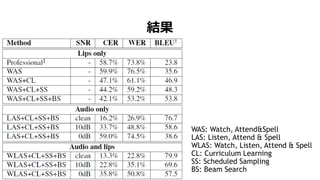
- 59. œáčû WAS: Watch, Attend&Spell LAS: Listen, Attend & Spell WLAS: Watch, Listen, Attend & Spell CL: Curriculum Learning SS: Scheduled Sampling BS: Beam Search
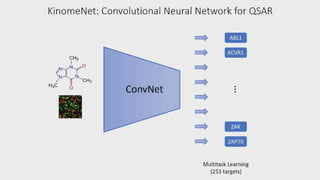
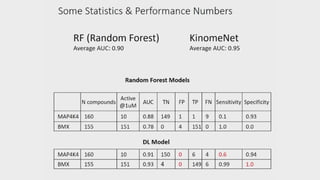
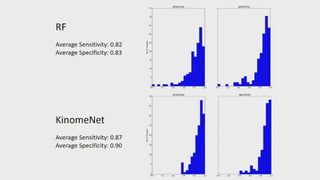
- 60. Olexandr Isayev Research Assistant Professor, University of North Carolina at Chapel Hill ACCURATE PREDICTION OF PROTEIN KINASE INHIBITORS WITH DEEP CONVOLUTIONAL NEURAL NETWORKS SESSION 3
- 71. Han Zhang et al, Department of Computer Science, Rutgers University et al. STACKGAN: TEXT TO PHOTO-REALISTIC IMAGE SYNTHESIS WITH STACKED GENERATIVE ADVERSARIAL NETWORKS SESSION 4 https://arxiv.org/pdf/1612.03242v1.pdf
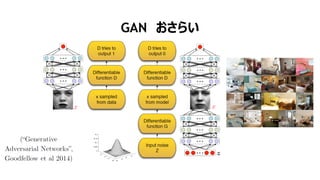
- 72. GAN €Ș€”€é€€
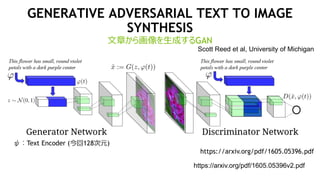
- 73. GENERATIVE ADVERSARIAL TEXT TO IMAGE SYNTHESIS ÎÄŐ€«€é»Ïń€òÉúłÉ€č€ëGAN ŠŚŁșText Encoder (œń»Ű128ŽÎÔȘ) https://arxiv.org/pdf/1605.05396v2.pdf Scott Reed et al, University of Michigan https://arxiv.org/pdf/1605.05396.pdf
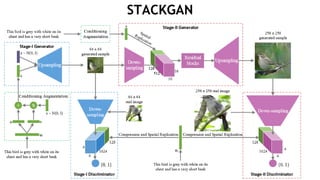
- 75. STACKGAN
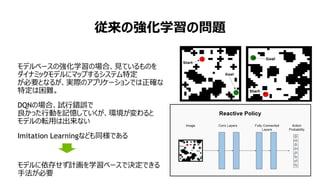
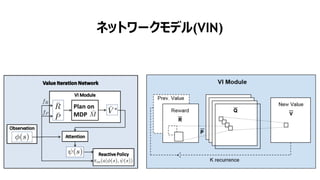
- 77. Aviv Tamar, Yi Wu, Garrett Thomas, Sergey Levine, and Pieter Abbeel Dept. of Electrical Engineering and Computer Sciences, UC Berkeley VALUE ITERATION NETWORKS SESSION 5
- 81. œáčû