Nvidia kepler architecture performance efficiency availability @ hpcday 2012 kiev
ŌĆó
1 likeŌĆó471 views


























![C ą┤ą╗čÅ CUDA : C + ┬½čüąĖąĮčéą░ą║čüąĖč湥čüą║ąĖą╣ čüą░čģą░čĆ┬╗
void saxpy_serial(int n, float a, float *x, float *y)
{
for (int i = 0; i < n; ++i)
y[i] = a*x[i] + y[i];
} ąĪčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ą║ąŠą┤ C
// Invoke serial SAXPY kernel
saxpy_serial(n, 2.0, x, y);
__global__ void saxpy_parallel(int n, float a, float *x, float *y)
{
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) y[i] = a*x[i] + y[i];
}
ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗą╣ ą║ąŠą┤ C
// Invoke parallel SAXPY kernel with 256 threads/block
int nblocks = (n + 255) / 256;
saxpy_parallel<<<nblocks, 256>>>(n, 2.0, x, y);
26](https://image.slidesharecdn.com/nvidiakeplerarchitectureperformanceefficiencyavailabilityhpcday2012kiev-121117031047-phpapp01/85/Nvidia-kepler-architecture-performance-efficiency-availability-hpcday-2012-kiev-26-320.jpg)




Nvidia kepler architecture performance efficiency availability @ hpcday 2012 kiev
- 1. ąÉčĆčģąĖč鹥ą║čéčāčĆą░ NVIDIA Kepler ą¤čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī. ąŁčäč乥ą║čéąĖą▓ąĮąŠčüčéčī. ąöąŠčüčéčāą┐ąĮąŠčüčéčī. 1
- 2. Tesla: ą▓ 2-3 čĆą░ąĘą░ ą▒čŗčüčéčĆąĄąĄ ą║ą░ąČą┤čŗąĄ 2 ą│ąŠą┤ą░ 16 Maxwell 14 DP GFLOPS per Watt 12 10 8 6 Kepler 4 Fermi 2 T10 2008 2010 2012 2014 2
- 3. Kepler 3
- 4. Kepler ąĪąÉą£ą½ąÖ ąæą½ąĪąóąĀąÉą» ąś ąŁążążąĢąÜąóąśąÆąØąÉą» HPC ąÉąĀąźąśąóąĢąÜąóąŻąĀąÉ SMX Hyper-Q Dynamic Parallelism 4
- 5. Kepler: ąĪą║ąŠčĆąŠčüčéčī ąĖ ąŁčäč乥ą║čéąĖą▓ąĮąŠčüčéčī SM SMX M2090 K20 3x ąŻą¤ąĀąÉąÆąøą»ą«ą®ąÉą» ąøą×ąōąśąÜąÉ ąŻą¤ąĀąÉąÆąøą»ą«ą®ąÉą» ąøą×ąōąśąÜąÉ Perf / Watt 32 čÅą┤čĆą░ 192 čÅą┤čĆą░ 5
- 6. 1 ą¤ąĄčéčäą╗ąŠą┐ ąÆčüąĄą│ąŠ ą▓ 10 čüč鹊ą╣ą║ą░čģ 400 ą║ąÆčé 6
- 7. Hyper-Q CPU čÅą┤čĆą░ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ąĘą░ą┐čāčüą║ą░čÄčé ąĘą░ą┤ą░čćąĖ ąĮą░ Kepler FERMI KEPLER 1 MPI ąĘą░ą┤ą░čćą░ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ 32 MPI ąĘą░ą┤ą░čćąĖ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ 7
- 8. Hyper-Q ą£ą░ą║čüąĖą╝ą░ą╗čīąĮą░čÅ čāčéąĖą╗ąĖąĘą░čåąĖčÅ GPU, čüąŠą║čĆą░čēąĄąĮąĖąĄ ą▓čĆąĄą╝ąĄąĮąĖ ą┐čĆąŠčüč鹊čÅ CPU 100 100 ąŻčéąĖą╗ąĖąĘą░čåąĖčÅ GPU % ąŻčéąĖą╗ąĖąĘą░čåąĖčÅ GPU % 50 50 0 0 Time Time 8
- 9. Dynamic Parallelism GPU ą░ą┤ą░ą┐čéąĖčĆčāąĄčéčüčÅ ą║ ą┤ą░ąĮąĮčŗą╝, ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖ ą┐ąŠčĆąŠąČą┤ą░čÅ ąĮąŠą▓čŗąĄ ą┐ąŠč鹊ą║ąĖ CPU Fermi GPU CPU Kepler GPU 9
- 10. Dynamic Parallelism ą¤čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ ąĮą░ GPU ą┐čĆąŠčēąĄ ąĖ ą┤ąŠčüčéčāą┐ąĮąĄąĄ ąĪą╗ąĖčłą║ąŠą╝ ą│čĆčāą▒ąŠ ąĪą╗ąĖčłą║ąŠą╝ ą╝ąĄą╗ą║ąŠ ąÜą░ą║ ąĮą░ą┤ąŠ 10
- 11. Tesla K10 Tesla K20 3x ąŠą┤ąĖąĮą░čĆąĮą░čÅ č鹊čćąĮąŠčüčéčī 3x ą┤ą▓ąŠą╣ąĮą░čÅ č鹊čćąĮąŠčüčéčī 1.8x ą┐čĆąŠą┐čāčüąĮą░čÅ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī ą┐ą░ą╝čÅčéąĖ Hyper-Q, Dynamic Parallelism ą×ą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĘąŠą▒čĆą░ąČąĄąĮąĖą╣, čüąĖą│ąĮą░ą╗ąŠą▓, CFD, FEA, čäąĖąĮą░ąĮčüčŗ, čäąĖąĘąĖą║ą░ čüąĄą╣čüą╝ąŠčĆą░ąĘą▓ąĄą┤ą║ą░ ąŻąČąĄ ą┤ąŠčüčéčāą┐ąĮąŠ ąöąŠčüčéčāą┐ąĮąŠ ą▓ Q4 2012 11
- 12. Tesla K10 ąóąŠąČąĄ ą┐ąŠčéčĆąĄą▒ą╗ąĄąĮąĖąĄ, 2x ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī Fermi Product Name M2090 K10 GPU Architecture Fermi Kepler GK104 # of GPUs 1 2 Board Per GPU Single Precision Flops 1.3 TF 4.58 TF 2.29 TF Double Precision Flops 0.66 TF 0.190 TF 0.095 TF # CUDA Cores 512 3072 1536 Memory size 6 GB 8 GB 4GB Memory BW (ECC off) 177.6 GB/s 320 GB/s 160GB/s PCI-Express Gen 2 Gen 3 (Gen 2 compatible) Board Power 225 watts 225 watts 12
- 13. K10 ą┤ą╗čÅ ąĮąĄčäč鹥ą│ą░ąĘą░ 2 čüąĄą╣čüą╝ąŠą░ąĮą░ą╗ąĖąĘ 1.5 1 0.5 0 ŌĆó 1.8X čüąĖą╝čāą╗čÅčåąĖą╣ ą▓ ą┤ąĄąĮčī ą┤ą╗čÅ ą▒ąŠą╗ąĄąĄ č鹊čćąĮčŗčģ ą╝ąŠą┤ąĄą╗ąĄą╣ ŌĆó ąØąĖąČąĄ čĆąĖčüą║ąĖ ąĖ ą▓čŗčłąĄ ąĮą░ą┤ąĄąČąĮąŠčüčéčī ŌĆó 2X GPU ą▓ č鹊ą╝ ąČąĄ č乊čĆą╝ą░č鹥 13
- 14. K10 ą┤ą╗čÅ ąŠą▒ąŠčĆąŠąĮčŗ ą¦ąĖčüą╗ąŠą▓ą░čÅ ą░ąĮą░ą╗ąĖčéąĖą║ą░ 2 1.5 1 0.5 0 M2090 k10 ŌĆó 1.9X ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ ą▓ ą┤ąĄąĮčī ą┤ą╗čÅ ą▒ąŠą╗ąĄąĄ č鹊čćąĮčŗčģ ą╝ąŠą┤ąĄą╗ąĄą╣ ŌĆó ąæčŗčüčéčĆąĄąĄ ą░ąĮą░ą╗ąĖčéąĖą║ą░ ąĖ č鹊čćąĮąĄąĄ čĆąĄčłąĄąĮąĖčÅ ŌĆó 2X GPU ą▓ č鹊ą╝ ąČąĄ č乊čĆą╝ą░č鹥 14
- 15. K10 ą┤ą╗čÅ ą▒ąĖąŠąĖąĮč乊čĆą╝ą░čéąĖą║ąĖ 3 2.5 2 1.5 1 0.5 0 ŌĆó 2.2X čüąĖą╝čāą╗čÅčåąĖą╣ ą┤ą╗čÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ ą£ąö ŌĆó ąæąŠą╗čīčłąĖąĄ 菹║čüą┐ąĄčĆąĖą╝ąĄąĮčéčŗ ąĮą░ ą╝ąĄąĮčīčłąĖčģ ą║ą╗ą░čüč鹥čĆą░čģ ŌĆó 2X GPU ą▓ č鹊ą╝ ąČąĄ č乊čĆą╝ą░č鹥 Gromacs 4.6 pre-beta version * 2 instances of AMBER 12 (with beta patch) 15
- 16. Tesla K10 vs M2090: 2x ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī / ąÆą░čéčé 2.50 2.00 1.50 1.00 0.50 0.00 Seismic LAMMPS NAMD AMBER* Radio Nbody Defense Processing Astronomy (Integer Ops) Cross-Correlator * 2 instances of AMBER running JAC 16
- 17. 118 ą║ąŠą╝ą╝ąĄčĆč湥čüą║ąĖčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ čāčüą║ąŠčĆčÅčÄčéčüčÅ ąĮą░ GPU www.nvidia.com/teslaapps 17
- 18. MSC Nastran čåąĄąĮą░/ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī čĆąĄčłąĄąĮąĖčÅ MSC Nastran 2012 and Model 3.4M DOF NOTE: Based on Extra 13% cost Results from PSG cluster node (fs0), 2x Nehalem 2.27GHz, 6 yields 160% Factors Gain Over Base License Results 96GB memory, Linux/CentOS; 2x Tesla C2050, CUDA 4.0 performance (over 8 cores) * Solution Cost Basis - Linear Structures Package 5 CPU Speed-up 5.3 (Base SMP license) GPU Speed-up 4.6 4 Solution Cost - Expert Package (Nonlinear) 3 3.3 - Implicit HPC Package (DMP Network License) 2 2.6 - GPU License - $10K for System cost 1 1.24 1.4 - $4K for 2x Tesla 20-series 1.0 1.0 1.0 1.13 Performance Basis 0 SOL101 Model: - 3.4M DOF - Stress analysis Nastran SMP Nastran SMP Nastran DMP Nastran SMP Nastran DMP - Direct sparse License 4 Cores 8 Cores + GPU License + GPU License 1 Core 1 Core + 1 GPU 2 Cores + 2 GPUs * 1 year lease for SW pricing 18
- 20. 20
- 21. NVIDIA cuBLAS NVIDIA cuRAND NVIDIA cuSPARSE NVIDIA NPP Vector Signal GPU Accelerated Matrix Algebra on Image Processing Linear Algebra GPU and Multicore NVIDIA cuFFT Sparse Linear Building-block C++ STL Features IMSL Library Algebra Algorithms for CUDA for CUDA ąæąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ą┤ą╗čÅ GPU ŌĆ£Copy-pasteŌĆØ ą┤ą╗čÅ čāčüą║ąŠčĆąĄąĮąĖčÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ 21
- 22. ąöąĖčĆąĄą║čéąĖą▓čŗ OpenACC CPU GPU ą¤čĆąŠčüčéčŗąĄ čāą║ą░ąĘą░č鹥ą╗ąĖ ą┤ą╗čÅ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ Program myscience ... serial code ... !$acc kernels ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘčāąĄčé ą║ąŠą┤ do k = 1,n1 do i = 1,n2 OpenACC ą╝ąĄčéą║ąĖ ... parallel code ... ą┤ą╗čÅ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ enddo ąĀą░ą▒ąŠčéą░ąĄčé ąĮą░ ą╝ąĮąŠą│ąŠčÅą┤ąĄčĆąĮčŗčģ enddo !$acc end kernels ... End Program myscience CPU ąĖ ą╝ą░čüčüąĖą▓ąĮąŠ ąśčüčģąŠą┤ąĮčŗą╣ ą║ąŠą┤ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗčģ GPU ąĮą░ C/Fortran 22
- 23. ą£ąĖąĮąĖą╝čāą╝ čāčüąĖą╗ąĖą╣. ą×čēčāčéąĖą╝čŗą╣ čĆąĄąĘčāą╗čīčéą░čé ą£ąŠą┤ąĄą╗čī ąČąĖąĘąĮąĄąĮąĮąŠą│ąŠ ąŚą▓ąĄąĘą┤čŗ ąĖ ą│ą░ą╗ą░ą║čéąĖą║ąĖ ąØąĄą╣čĆąŠčüąĄčéąĖ ą┤ą╗čÅ čåąĖą║ą╗ą░ ą╝ąŠčĆčüą║ąŠą╣ čäą░čāąĮčŗ 12.5 ą╝ą╗čĆą┤ ą╗ąĄčé ąĮą░ąĘą░ą┤ čüą░ą╝ąŠąŠą▒čāčćą░ąĄą╝čŗčģ čĆąŠą▒ąŠč鹊ą▓ ąŻąĮąĖą▓ąĄčĆčüąĖč鹥čé ą£ąĄą╗čīą▒čāčĆąĮą░ ąŻąĮąĖą▓ąĄčĆčüąĖč鹥čé ąōčĆąŠąĮąĖąĮą│ąĄąĮą░ ąŻąĮąĖą▓ąĄčĆčüąĖč鹥čé ą¤ą╗ąĖą╝čāčéą░ 65x ąĘą░ 2 ą┤ą╗čÅ 5.6x ąĘą░ 5 ą┤ąĮąĄą╣ 4.7x ąĘą░ 4 čćą░čüą░ 23
- 24. ąÆąŠčĆą║čłąŠą┐ ą┐ąŠ OpenACC ą▓ čüčāą┐ąĄčĆą║ąŠą╝ą┐čīčÄč鹥čĆąĮąŠą╝ čåąĄąĮčéčĆąĄ ą¤ąĖčéčüą▒čāčĆą│ą░ ąÜ ą║ąŠąĮčåčā ą▓č鹊čĆąŠą│ąŠ ą┤ąĮčÅ ą┐ąŠą╗čāč湥ąĮąŠ 10-ą║čĆą░čéąĮąŠąĄ čāčüą║ąŠčĆąĄąĮąĖąĄ ąŠą┤ąĮąŠą│ąŠ ąĖąĘ ą░čéą╝ąŠčüč乥čĆąĮčŗčģ čÅą┤ąĄčĆ 6 ą┤ąĖčĆąĄą║čéąĖą▓ Technology Director National Center for Atmospheric Research (NCAR) 24
- 25. ą¤ąŠą┤ą┤ąĄčƹȹ║ą░ čÅąĘčŗą║ąŠą▓ C, C++, Fortran ą╝ąŠą┤ąĄą╗čīčÄ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą│ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ CUDA GPU Computing Applications Libraries and Middleware cuFFT PhysX LAPACK NPP VSIPL iray cuBLAS Video MATLAB CULA cuDPP SVM Rendering cuRAND OptiX Ray Mathematica MAGMA Thrust OpenCurrent RealityServer cuSPARSE tracing Java Python Direct C++ C Fortran OpenCL tm Wrappers Compute NVIDIA GPU CUDA Parallel Computing Architecture OpenCL is trademark of Apple Inc. used under license to the Khronos Group25 Inc.
- 26. C ą┤ą╗čÅ CUDA : C + ┬½čüąĖąĮčéą░ą║čüąĖč湥čüą║ąĖą╣ čüą░čģą░čĆ┬╗ void saxpy_serial(int n, float a, float *x, float *y) { for (int i = 0; i < n; ++i) y[i] = a*x[i] + y[i]; } ąĪčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ą║ąŠą┤ C // Invoke serial SAXPY kernel saxpy_serial(n, 2.0, x, y); __global__ void saxpy_parallel(int n, float a, float *x, float *y) { int i = blockIdx.x*blockDim.x + threadIdx.x; if (i < n) y[i] = a*x[i] + y[i]; } ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗą╣ ą║ąŠą┤ C // Invoke parallel SAXPY kernel with 256 threads/block int nblocks = (n + 255) / 256; saxpy_parallel<<<nblocks, 256>>>(n, 2.0, x, y); 26
- 27. NVIDIA ą┤ąĄą╗ą░ąĄčé ą┐ą╗ą░čéč乊čĆą╝čā CUDA ąŠčéą║čĆčŗč鹊ą╣ ą▒ą╗ą░ą│ąŠą┤ą░čĆčÅ LLVM CUDA ą¤ąŠą┤ą┤ąĄčƹȹ║ą░ CUDA ą▒菹║ąĄąĮą┤ č鹥ą┐ąĄčĆčī ą┤ąŠčüčéčāą┐ąĄąĮ ą┤ą╗čÅ LLVM C, C++, Fortran ąĮąŠą▓čŗčģ čÅąĘčŗą║ąŠą▓ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ SDK ą▓ą║ą╗čÄčćą░ąĄčé ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖčÄ, ą┐čĆąĖą╝ąĄčĆčŗ ąĖ ą▓ąĄčĆąĖčäąĖą║ą░č鹊čĆ LLVM ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą┤ą╗čÅ CUDA ąÆąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ CUDA ą▓ ąĮąŠą▓čŗąĄ čÅąĘčŗą║ąĖ ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆčŗ NVIDIA x86 ą¤ąŠą┤ą┤ąĄčƹȹ║ą░ GPUs CPUs ąØąŠą▓čŗčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ą¤ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ http://developer.nvidia.com/cuda-source 27
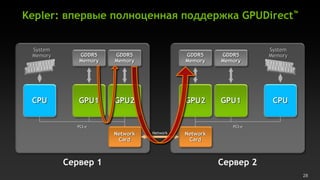
- 28. Kepler: ą▓ą┐ąĄčĆą▓čŗąĄ ą┐ąŠą╗ąĮąŠčåąĄąĮąĮą░čÅ ą┐ąŠą┤ą┤ąĄčƹȹ║ą░ GPUDirectŌäó System System Memory GDDR5 GDDR5 GDDR5 GDDR5 Memory Memory Memory Memory Memory CPU GPU1 GPU2 GPU2 GPU1 CPU PCI-e PCI-e Network Network Network Card Card ąĪąĄčĆą▓ąĄčĆ 1 ąĪąĄčĆą▓ąĄčĆ 2 28
- 29. CUDA ą▓ čåąĖčäčĆą░čģ: >375,000,000 CUDA GPU ąĮą░ čĆčŗąĮą║ąĄ >1,000,000 čüą║ą░čćąĖą▓ą░ąĮąĖą╣ SDK >120,000 ą░ą║čéąĖą▓ąĮčŗčģ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąŠą▓ >500 čāąĮąĖą▓ąĄčĆčüąĖč鹥č鹊ą▓ ą┐čĆąĄą┐ąŠą┤ą░čÄčé CUDA 29
- 30. ą¦č鹊 ą┤ą░ą╗čīčłąĄ? 30
- 31. CUDA ą┤ą╗čÅ ARM ąśčüčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīčüą║ą░čÅ ą┐ą╗ą░čéč乊čĆą╝ą░ CUDA GPU Tegra ARM CPU 4-čģ čÅą┤ąĄčĆąĮčŗą╣ ą┐čĆąŠčåąĄčüčüąŠčĆ NVIDIA Tegra 3 ąĮą░ ą▒ą░ąĘąĄ ARM NVIDIA CUDA GPU Gbit čüąĄčéčī ąØą░ą▒ąŠčĆ ą┤ą╗čÅ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąŠą▓ CUDA SDK http://www.secoqseven.com/en/item/secocq7-mxm/ ąöąŠčüčéčāą┐ąĮąŠ čüąĄą╣čćą░čü 31