openai.pptx
?
0 likes?53 views

The document discusses using a vector database to enable question answering with custom data. Key points: - Data is converted to vector embeddings and stored in a vector database like Pinecone to allow for similarity searches. - When a user asks a question, it is converted to a vector and queried against the database to retrieve similar content to provide as input to a language model for generating an answer. - The OpenAI API can also be used to build an assistant using a language model, where custom data is loaded to enable answering questions about that data as a "support manager."






openai.pptx
- 1. OPEN AI query on your own data Dori Waldman
- 2. RAG ? Retrieval and generation: the actual RAG chain, which takes the user query at run time and retrieves the relevant data from the index, then passes that to the model ? model is language model like OpenAI ? Store can be Pinecone vector DB Data Query
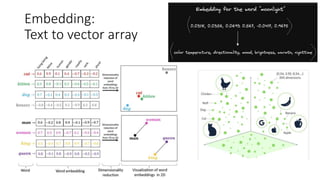
- 3. Embedding: Text to vector array
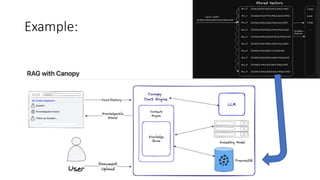
- 4. Example:
- 5. Before Assistant api ? Convert your data to vector presentation (embedding) ? Split your data to parts , you can add metadata per part ? Persist it in vector db ? Convert your question to vector ? Query database to find similar content/doc related to the question ? In vector database cat and mouse are similar (distance in space) ? On the result use language model to Ī░understandĪ▒ the document you got from DB and return an answer to the user ? Return also the answer resource to the user (from which doc the answer is from) ? Optional - get feedback how good is the answer
- 6. With assistant api ? Create assistant ? Select language model ? Add system instruction : Ī░answer as support managerĪŁĪ▒ ? Load file (your custom data) ? Start chat
- 7. Resources ? https://www.youtube.com/watch?v=TLf90ipMzfE ? https://youtu.be/qItoyPzz01s?si=47pmtUMjZUsQlbzb ? https://www.youtube.com/watch?v=vQhEiR2bNY8 ? https://www.youtube.com/watch?v=lNdpu6u9ZYM&t=2s ? https://www.youtube.com/watch?v=lTF43_-TjbQ ? https://www.youtube.com/watch?v=Vurdg6yrPL8&list=PLpdmBGJ6ELUIYHjmzYTuePlNRf 7yeCACz ? https://weaviate.io/blog/what-is-a-vector-database ? https://github.com/pinecone-io/canopy ? https://clickhouse.com/blog/vector-search-clickhouse-p1 ? https://weaviate.io/blog/distance-metrics-in-vector-search ? https://python.langchain.com/docs/use_cases/question_answering/ ? https://cobusgreyling.medium.com/knowledge-retrieval-via-the-openai-playground- 8b04682ebe37