п▓п╣п╠п╦п╫п╟я─: п·я│п╫п╬п╡я▀ я─п╟я│п©п╟я─п╟п╩п╩п╣п╩п╦п╡п╟п╫п╦я▐ п║++ п©я─п╬пЁя─п╟п╪п╪ п©я─п╦ п©п╬п╪п╬я┴п╦ OpenMP
Б─╒
0 likesБ─╒827 views

п÷я─п╣п╥п╣п╫я┌п╟я├п╦я▐ я│ п©п╣я─п╡п╬пЁп╬ я┌п╣я┘п╫п╦я┤п╣я│п╨п╬пЁп╬ п╡п╣п╠п╦п╫п╟я─п╟ FlyElephant, п╫п╟ п╨п╬я┌п╬я─п╬п╪ п╠я▀п╩п╦ я─п╟я│я│п╪п╬я┌я─п╣п╫я▀ п╬я│п╫п╬п╡я▀ я─п╟я│п©п╟я─п╟п╩п╩п╣п╩п╦п╡п╟п╫п╦я▐ п║/п║++ п©я─п╬пЁя─п╟п╪п╪ п©я─п╦ п©п╬п╪п╬я┴п╦ OpenMP п╦ я─п╟я│я│п╨п╟п╥п╟п╫п╬ п╬ я└я┐п╫п╨я├п╦п╬п╫п╟п╩п╣ FlyElephant. п▓п╦п╢п╣п╬ п©я─п╣п╥п╣п╫я┌п╟я├п╦п╦: https://youtu.be/X1bqBPnJaHM п║п╟п╧я┌ FlyElephant: http://flyelephant.net/ п÷п═п·п⌠п═п░п°п°п░ п▒п∙п╒п░-п╒п∙п║п╒п≤п═п·п▓п░п²п≤п╞ FLYELEPHANT: http://flyelephant.net/beta/





















![п■п╦я─п╣п╨я┌п╦п╡я▀
п╓п╬я─п╪п╟я┌ п╢п╦я─п╣п╨я┌п╦п╡я▀ (п║/C ++)
#pragma omp < п╦п╪я▐> [ <п©я─п╣п╢п╩п╬п╤п╣п╫п╦п╣> {[,] <п©я─п╣п╢п╩п╬п╤п╣п╫п╦п╣>}]
п╦п╪я▐ Б─■ п╦п╪я▐ п╢п╦я─п╣п╨я┌п╦п╡я▀;
п©я─п╣п╢п╩п╬п╤п╣п╫п╦п╣ Б─■ п╨п╬п╫я│я┌я─я┐п╨я├п╦я▐, п╥п╟п╢п╟я▌я┴п╟я▐ п╢п╬п©п╬п╩п╫п╦я┌п╣п╩я▄п╫я┐я▌
п╦п╫я└п╬я─п╪п╟я├п╦я▌ п╦ п╥п╟п╡п╦я│я▐я┴п╟я▐ п╬я┌ п╢п╦я─п╣п╨я┌п╦п╡я▀;](https://image.slidesharecdn.com/flyelephant-150928183527-lva1-app6892/85/OpenMP-23-320.jpg)
![п■п╦я─п╣п╨я┌п╦п╡п╟ parallel
#pragma omp parallel [<п©я─п╣п╢п╩п╬п╤п╣п╫п╦п╣>]
<я│я┌я─я┐п╨я┌я┐я─п╫я▀п╧ п╠п╩п╬п╨>
Б─╒ п÷п╬я┌п╬п╨, п╡я│я┌я─п╣я┤п╟я▌я┴п╦п╧ п╨п╬п╫я│я┌я─я┐п╨я├п╦я▌ parallel, я│п╬п╥п╢п╟я▒я┌ п╨п╬п╪п╟п╫п╢я┐
п©п╬я┌п╬п╨п╬п╡, я│я┌п╟п╫п╬п╡я▐я│я▄ п╢п╩я▐ п╫п╣я▒ п╬я│п╫п╬п╡п╫я▀п╪.
Б─╒ п÷п╬я┌п╬п╨п╟п╪ п╨п╬п╪п╟п╫п╢я▀ п©я─п╦я│п╡п╟п╦п╡п╟я▌я┌я│я▐ я┐п╫п╦п╨п╟п╩я▄п╫я▀п╣ я├п╣п╩я▀п╣ п╫п╬п╪п╣я─п╟,
п╫п╟я┤п╦п╫п╟я▐ я│ 0 (п╬я│п╫п╬п╡п╫п╬п╧ п©п╬я┌п╬п╨).
Б─╒ п п╟п╤п╢я▀п╧ п©п╬я┌п╬п╨ п╦я│п©п╬п╩п╫я▐п╣я┌ п╨п╬п╢, п╬п©я─п╣п╢п╣п╩я▐п╣п╪я▀п╧ я│я┌я─я┐п╨я┌я┐я─п╫я▀п╪
п╠п╩п╬п╨п╬п╪, п╡ п╨п╬п╫я├п╣ п╨п╬я┌п╬я─п╬пЁп╬ п╫п╣я▐п╡п╫п╬ я┐я│я┌п╟п╫п╟п╡п╩п╦п╡п╟п╣я┌я│я▐ п╠п╟я─я▄п╣я─.](https://image.slidesharecdn.com/flyelephant-150928183527-lva1-app6892/85/OpenMP-24-320.jpg)

![п■п╦я─п╣п╨я┌п╦п╡п╟ for
#pragma omp for [<п©п╣п╢п╩п╬п╤п╣п╫п╦я▐>]
<я├п╦п╨п╩я▀ for>
п·пЁя─п╟п╫п╦я┤п╣п╫п╦я▐:
Б─╒ (п∙п╢п╦п╫я│я┌п╡п╣п╫п╫я▀п╧) я│я┤я▒я┌я┤п╦п╨ Б─■ я├п╣п╩п╬пЁп╬ я┌п╦п©п╟, я┐п╨п╟п╥п╟я┌п╣п╩я▄, п╦п╩п╦ п╦я┌п╣я─п╟я┌п╬я─
п©я─п╬п╦п╥п╡п╬п╩я▄п╫п╬пЁп╬ п╢п╬я│я┌я┐п©п╟. п■п╬п╩п╤п╣п╫ п╦п╥п╪п╣п╫я▐я┌я▄я│я▐ я┌п╬п╩я▄п╨п╬ п╡ п╥п╟пЁп╬п╩п╬п╡п╨п╣ я├п╦п╨п╩п╟.
Б─╒ пёя│п╩п╬п╡п╦п╣ я├п╦п╨п╩п╟: я│я─п╟п╡п╫п╣п╫п╦п╣ п©п╣я─п╣п╪п╣п╫п╫п╬п╧ я│ п╦п╫п╡п╟я─п╦п╟п╫я┌п╫я▀п╪ п╨ я├п╦п╨п╩я┐
п╡я▀я─п╟п╤п╣п╫п╦п╣п╪ п©я─п╦ п©п╬п╪п╬я┴п╦ <, <=, >, >=.
Б─╒ п≤п╥п╪п╣п╫п╣п╫п╦п╣ я│я┤я▒я┌я┤п╦п╨п╟: п©я─п╦ п©п╬п╪п╬я┴п╦ ++, --, i += d, i -= d, i = i + d, i = d +
i, i = i - d (d Б─■ п╦п╫п╡п╟я─п╦п╟п╫я┌п╫п╬п╣ п╨ я├п╦п╨п╩я┐ я├п╣п╩п╬п╣ п╡я▀я─п╟п╤п╣п╫п╦п╣)](https://image.slidesharecdn.com/flyelephant-150928183527-lva1-app6892/85/OpenMP-26-320.jpg)
![п■п╦я─п╣п╨я┌п╦п╡п╟ for
#pragma omp parallel
{
#pragma omp for
for (ptrdiff_t i = 0; i < n; i++)
dst[i] = sqrt(src[i]);
}](https://image.slidesharecdn.com/flyelephant-150928183527-lva1-app6892/85/OpenMP-27-320.jpg)
![#pragma omp parallel for
#pragma omp parallel for
for (ptrdiff_t i = 0; i < n; i++)
dst[i] = sqrt(src[i]);](https://image.slidesharecdn.com/flyelephant-150928183527-lva1-app6892/85/OpenMP-28-320.jpg)















п▓п╣п╠п╦п╫п╟я─: п·я│п╫п╬п╡я▀ я─п╟я│п©п╟я─п╟п╩п╩п╣п╩п╦п╡п╟п╫п╦я▐ п║++ п©я─п╬пЁя─п╟п╪п╪ п©я─п╦ п©п╬п╪п╬я┴п╦ OpenMP
- 1. п·я│п╫п╬п╡я▀ я─п╟я│п©п╟я─п╟п╩п╩п╣п╩п╦п╡п╟п╫п╦я▐ п║/п║++ п©я─п╬пЁя─п╟п╪п╪ п©я─п╦ п©п╬п╪п╬я┴п╦ OpenMP
- 2. п·п╠п╬ п╪п╫п╣ Б─╒ п÷я─п╣п©п╬п╢п╟п╡п╟я┌п╣п╩я▄ п·п²п÷пё п╨п╟я└п╣п╢я─я▀ п║п╦я│я┌п╣п╪п╫п╬пЁп╬ п©я─п╬пЁя─п╟п╪п╪п╫п╬пЁп╬ п╬п╠п╣я│п©п╣я┤п╣п╫п╦я▐ Б─╒ п·я│п╫п╬п╡п╟я┌п╣п╩я▄ FlyElephant п╦ GeeksLab.
- 3. п÷п╩п╟п╫ Б─╒ п╖п╟я│я┌я▄ 1. п·я│п╫п╬п╡я▀ я─п╟я│п©п╟я─п╟п╩п╩п╣п╩п╦п╡п╟п╫п╦я▐ п║/п║++ п©я─п╬пЁя─п╟п╪п╪ п©я─п╦ п©п╬п╪п╬я┴п╦ OpenMP Б─╒ п╖п╟я│я┌я▄ 2. п≈п╫п╟п╨п╬п╪я│я┌п╡п╬ я│ FlyElephant
- 5. п≤я│я┌п╬я─п╦я▐ п╡я▀я┤п╦я│п╩п╦я┌п╣п╩я▄п╫п╬п╧ я┌п╣я┘п╫п╦п╨п╦ Cray-1 1976 пЁп╬п╢ 133 п°я└п╩п╬п©я│п╟
- 6. п≤я│я┌п╬я─п╦я▐ п╡я▀я┤п╦я│п╩п╦я┌п╣п╩я▄п╫п╬п╧ я┌п╣я┘п╫п╦п╨п╦ IBM POWER4 2001 пЁп╬п╢ 2 я▐п╢я─п╟
- 7. п≤я│я┌п╬я─п╦я▐ п╡я▀я┤п╦я│п╩п╦я┌п╣п╩я▄п╫п╬п╧ я┌п╣я┘п╫п╦п╨п╦ GPU п╦ CUDA 2007 пЁп╬п╢
- 8. п≤я│я┌п╬я─п╦я▐ п╡я▀я┤п╦я│п╩п╦я┌п╣п╩я▄п╫п╬п╧ я┌п╣я┘п╫п╦п╨п╦ Intel MIC - 2010 пЁп╬п╢ 32 я▐п╢я─п╟ п═п╣п╠я─п╣п╫п╢п╦п╫пЁ п╡ Xeon Phi 2012 пЁп╬п╢ 61 я▐п╢я─п╬ ~1 TFLOPS
- 11. п°п╬п╢п╣п╩п╦ п©п╟я─п╟п╩п╩п╣п╩я▄п╫я▀я┘ п©я─п╬пЁя─п╟п╪п╪ п▓я▀я┤п╦я│п╩п╦я┌п╣п╩я▄п╫я▀п╣ я│п╦я│я┌п╣п╪я▀ я│ п╬п╠я┴п╣п╧ п©п╟п╪я▐я┌я▄я▌ п║п╦я│я┌п╣п╪я▀ я│ я─п╟я│п©я─п╣п╢п╣п╩п╣п╫п╫п╬п╧ п©п╟п╪я▐я┌я▄я▌ п⌠п╦п╠я─п╦п╢п╫я▀п╣ я│п╦я│я┌п╣п╪я▀
- 12. п║п╦я│я┌п╣п╪я▀ я│ п╬п╠я┴п╣п╧ п©п╟п╪я▐я┌я▄я▌ Б─╒ п÷я─п╣п╦п╪я┐я┴п╣я│я┌п╡п╟: Б─╒ п²п╣ я┌я─п╣п╠я┐п╣я┌я│я▐ п╬п╠п╪п╣п╫ п╢п╟п╫п╫я▀п╪п╦ Б─╒ п÷я─п╬я│я┌п╬ п©п╦я│п╟я┌я▄ п©я─п╬пЁя─п╟п╪п╪я▀ Б─╒ п п╬п╪п©п╟п╨я┌п╫п╬я│я┌я▄ я│п╦я│я┌п╣п╪ Б─╒ п²п╣п╢п╬я│я┌п╟я┌п╨п╦: Б─╒ п÷я─п╬п╠п╩п╣п╪п╟ я│п╬п╡п╪п╣я│я┌п╫п╬пЁп╬ п╢п╬я│я┌я┐п©п╟ п╨ п©п╟п╪я▐я┌п╦ Б─╒ п÷я─п╬п╠п╩п╣п╪п╟ я│п╦п╫я┘я─п╬п╫п╫п╬я│я┌п╦ п╨я█я┬п╣п╧ Б─╒ п·пЁя─п╟п╫п╦я┤п╣п╫п╫я▀п╧ п╬п╠я▄п╣п╪ п·п≈пё Б─╒ п÷я─п╬п╠п╩п╣п╪п╟ п╪п╟я│я┬я┌п╟п╠п╦я─я┐п╣п╪п╬я│я┌п╦
- 13. п║п╦я│я┌п╣п╪я▀ я│ я─п╟я│п©я─п╣п╢п╣п╩я▒п╫п╫п╬п╧ п©п╟п╪я▐я┌я▄я▌ Б─╒ п÷я─п╣п╦п╪я┐я┴п╣я│я┌п╡п╟: Б─╒ п÷я─п╬я│я┌п╬я┌п╟ п╦ п╢п╣я┬п╣п╡п╦п╥п╫п╟ п©п╬я│я┌я─п╬п╣п╫п╦я▐ Б─╒ п╜я└я└п╣п╨я┌п╦п╡п╫п╬п╣ я─п╣я┬п╣п╫п╦п╣ п╥п╟п╢п╟я┤, я┌я─п╣п╠я┐я▌я┴п╦я┘ п╪п╟п╩п╬пЁп╬ п╬п╠п╪п╣п╫п╟ п╢п╟п╫п╫я▀п╪п╦ Б─╒ п▓п╬п╥п╪п╬п╤п╫п╬я│я┌я▄ я─п╣я┬п╟я┌я▄ п╥п╟п╢п╟я┤п╦, я┌я─п╣п╠я┐я▌я┴п╦п╣ п╬я┤п╣п╫я▄ п╠п╬п╩я▄я┬п╦я┘ п╬п╠я┼я▒п╪п╬п╡ п╬п©п╣я─п╟я┌п╦п╡п╫п╬п╧ п©п╟п╪я▐я┌п╦ Б─╒ п▓п╬п╥п╪п╬п╤п╫п╬я│я┌я▄ п╪п╟я│я┬я┌п╟п╠п╦я─п╬п╡п╟п╫п╦я▐ Б─╒ п²п╣п╢п╬я│я┌п╟я┌п╨п╦: Б─╒ п÷я─п╬п╠п╩п╣п╪п╟ п╬п╠п╪п╣п╫п╟ п╢п╟п╫п╫я▀п╪п╦ Б─╒ п║п╩п╬п╤п╫п╬п╣ п©я─п╬пЁя─п╟п╪п╪п╦я─п╬п╡п╟п╫п╦п╣ Б─╒ п▒п╬п╩я▄я┬п╬п╧ я─п╟п╥п╪п╣я─ я│п╦я│я┌п╣п╪ Б─╒ п▒п╬п╩я▄я┬п╬п╣ я█п╫п╣я─пЁп╬п©п╬я┌я─п╣п╠п╩п╣п╫п╦п╣
- 15. п≤п╫я│я┌я─я┐п╪п╣п╫я┌п╟я─п╦п╧ OpenMP Open Multi-Processing MPI Message Passing Interface Hadoop Spark
- 16. OpenMP
- 17. OpenMP (Open Multi-Processing) п╬я┌п╨я─я▀я┌я▀п╧ я│я┌п╟п╫п╢п╟я─я┌ п╢п╩я▐ я─п╟я│п©п╟я─п╟п╩п╩п╣п╩п╦п╡п╟п╫п╦п╣ п©я─п╬пЁя─п╟п╪п╪ п╫п╟ я▐п╥я▀п╨п╟я┘ п║, п║++ п╦ Fortran. http://openmp.org/ v1 - 1997 пЁп╬п╢ GCC 4.1 v 4.0 - July 2013 Intel C++ Compiler v 4.1 - п╡ я─п╟п╠п╬я┌п╣ Visual C++
- 18. п÷я─п╣п╦п╪я┐я┴п╣я│я┌п╡п╟ OpenMP Б─╒ п⌡я▒пЁп╨п╬я│я┌я▄ п╦я│п©п╬п╩я▄п╥п╬п╡п╟п╫п╦я▐. Б─╒ п я─п╬я│я│-п©п╩п╟я┌я└п╬я─п╪п╣п╫п╫п╬я│я┌я▄ п╢п╩я▐ я│п╦я│я┌п╣п╪ я│ п╬п╠я┴п╣п╧ п©п╟п╪я▐я┌я▄я▌. Б─╒ п║п╬п╨я─я▀я┌п╦п╣ п╫п╦п╥п╨п╬я┐я─п╬п╡п╫п╣п╡я▀я┘ п╬п©п╣я─п╟я├п╦п╧. Б─╒ п≤п╫п╨я─п╣п╪п╣п╫я┌п╫п╬п╣ я─п╟я│п©п╟я─п╟п╩п╩п╣п╩п╦п╡п╟п╫п╦п╣. Б─╒ п÷п╬п╢п╢п╣я─п╤п╨п╟ п©п╟я─п╟п╩п╩п╣п╩я▄п╫п╬п╧ п╦ п©п╬я│п╩п╣п╢п╬п╡п╟я┌п╣п╩я▄п╫п╬п╧ п╡п╣я─я│п╦п╧ п©я─п╬пЁя─п╟п╪п╪.
- 19. п п╬п╪п©п╬п╫п╣п╫я┌я▀ Б─╒ п÷п╣я─п╣п╪п╣п╫п╫я▀п╣ п╬п╨я─я┐п╤п╣п╫п╦я▐. Б─╒ п■п╦я─п╣п╨я┌п╦п╡я▀ п╨п╬п╪п©п╦п╩я▐я┌п╬я─п╟ Б─■ я─п╟я│я┬п╦я─п╣п╫п╦я▐ я▐п╥я▀п╨п╬п╡ п║/ C++ п╦ Fortran. Б─╒ п╓я┐п╫п╨я├п╦п╦.
- 21. OpenMP п╦ GCC GCC v4.1 -openmp g++ test.cpp -o test -fopenmp #include<omp.h>
- 22. п÷п╣я─п╣п╪п╣п╫п╫я▀п╣ п╬п╨я─я┐п╤п╣п╫п╦я▐ Б─╒ OMP_NUM_THREADS - пёя│я┌п╟п╫п╟п╡п╩п╦п╡п╟п╣я┌ п╨п╬п╩п╦я┤п╣я│я┌п╡п╬ п©п╬я┌п╬п╨п╬п╡ п╡ п©п╟я─п╟п╩п╩п╣п╩я▄п╫п╬п╪ п╠п╩п╬п╨п╣. п÷п╬ я┐п╪п╬п╩я┤п╟п╫п╦я▌, п╨п╬п╩п╦я┤п╣я│я┌п╡п╬ п©п╬я┌п╬п╨п╬п╡ я─п╟п╡п╫п╬ п╨п╬п╩п╦я┤п╣я│я┌п╡я┐ п╡п╦я─я┌я┐п╟п╩я▄п╫я▀я┘ п©я─п╬я├п╣я│я│п╬я─п╬п╡. Б─╒ OMP_SCHEDULE - пёя│я┌п╟п╫п╟п╡п╩п╦п╡п╟п╣я┌ я┌п╦п© я─п╟я│п©я─п╣п╢п╣п╩п╣п╫п╦я▐ я─п╟п╠п╬я┌ п╡ п©п╟я─п╟п╩п╩п╣п╩я▄п╫я▀я┘ я├п╦п╨п╩п╟я┘ я│ я┌п╦п©п╬п╪ runtime. Б─╒ OMP_DYNAMIC - п═п╟п╥я─п╣я┬п╟п╣я┌ п╦п╩п╦ п╥п╟п©я─п╣я┴п╟п╣я┌ п╢п╦п╫п╟п╪п╦я┤п╣я│п╨п╬п╣ п╦п╥п╪п╣п╫п╣п╫п╦п╣ п╨п╬п╩п╦я┤п╣я│я┌п╡п╟ п©п╬я┌п╬п╨п╬п╡, п╨п╬я┌п╬я─я▀п╣ я─п╣п╟п╩я▄п╫п╬ п╦я│п©п╬п╩я▄п╥я┐я▌я┌я│я▐ п╢п╩я▐ п╡я▀я┤п╦я│п╩п╣п╫п╦п╧ (п╡ п╥п╟п╡п╦я│п╦п╪п╬я│я┌п╦ п╬я┌ п╥п╟пЁя─я┐п╥п╨п╦ я│п╦я│я┌п╣п╪я▀). п≈п╫п╟я┤п╣п╫п╦п╣ п©п╬ я┐п╪п╬п╩я┤п╟п╫п╦я▌ п╥п╟п╡п╦я│п╦я┌ п╬я┌ я─п╣п╟п╩п╦п╥п╟я├п╦п╦. Б─╒ OMP_NESTED - п═п╟п╥я─п╣я┬п╟п╣я┌ п╦п╩п╦ п╥п╟п©я─п╣я┴п╟п╣я┌ п╡п╩п╬п╤п╣п╫п╫я▀п╧ п©п╟я─п╟п╩п╩п╣п╩п╦п╥п╪ (я─п╟я│п©п╟я─п╟п╩п╩п╣п╩п╦п╡п╟п╫п╦п╣ п╡п╩п╬п╤п╣п╫п╫я▀я┘ я├п╦п╨п╩п╬п╡). п÷п╬ я┐п╪п╬п╩я┤п╟п╫п╦я▌ Б─⌠ п╥п╟п©я─п╣я┴п╣п╫п╬.
- 23. п■п╦я─п╣п╨я┌п╦п╡я▀ п╓п╬я─п╪п╟я┌ п╢п╦я─п╣п╨я┌п╦п╡я▀ (п║/C ++) #pragma omp < п╦п╪я▐> [ <п©я─п╣п╢п╩п╬п╤п╣п╫п╦п╣> {[,] <п©я─п╣п╢п╩п╬п╤п╣п╫п╦п╣>}] п╦п╪я▐ Б─■ п╦п╪я▐ п╢п╦я─п╣п╨я┌п╦п╡я▀; п©я─п╣п╢п╩п╬п╤п╣п╫п╦п╣ Б─■ п╨п╬п╫я│я┌я─я┐п╨я├п╦я▐, п╥п╟п╢п╟я▌я┴п╟я▐ п╢п╬п©п╬п╩п╫п╦я┌п╣п╩я▄п╫я┐я▌ п╦п╫я└п╬я─п╪п╟я├п╦я▌ п╦ п╥п╟п╡п╦я│я▐я┴п╟я▐ п╬я┌ п╢п╦я─п╣п╨я┌п╦п╡я▀;
- 24. п■п╦я─п╣п╨я┌п╦п╡п╟ parallel #pragma omp parallel [<п©я─п╣п╢п╩п╬п╤п╣п╫п╦п╣>] <я│я┌я─я┐п╨я┌я┐я─п╫я▀п╧ п╠п╩п╬п╨> Б─╒ п÷п╬я┌п╬п╨, п╡я│я┌я─п╣я┤п╟я▌я┴п╦п╧ п╨п╬п╫я│я┌я─я┐п╨я├п╦я▌ parallel, я│п╬п╥п╢п╟я▒я┌ п╨п╬п╪п╟п╫п╢я┐ п©п╬я┌п╬п╨п╬п╡, я│я┌п╟п╫п╬п╡я▐я│я▄ п╢п╩я▐ п╫п╣я▒ п╬я│п╫п╬п╡п╫я▀п╪. Б─╒ п÷п╬я┌п╬п╨п╟п╪ п╨п╬п╪п╟п╫п╢я▀ п©я─п╦я│п╡п╟п╦п╡п╟я▌я┌я│я▐ я┐п╫п╦п╨п╟п╩я▄п╫я▀п╣ я├п╣п╩я▀п╣ п╫п╬п╪п╣я─п╟, п╫п╟я┤п╦п╫п╟я▐ я│ 0 (п╬я│п╫п╬п╡п╫п╬п╧ п©п╬я┌п╬п╨). Б─╒ п п╟п╤п╢я▀п╧ п©п╬я┌п╬п╨ п╦я│п©п╬п╩п╫я▐п╣я┌ п╨п╬п╢, п╬п©я─п╣п╢п╣п╩я▐п╣п╪я▀п╧ я│я┌я─я┐п╨я┌я┐я─п╫я▀п╪ п╠п╩п╬п╨п╬п╪, п╡ п╨п╬п╫я├п╣ п╨п╬я┌п╬я─п╬пЁп╬ п╫п╣я▐п╡п╫п╬ я┐я│я┌п╟п╫п╟п╡п╩п╦п╡п╟п╣я┌я│я▐ п╠п╟я─я▄п╣я─.
- 25. п■п╦я─п╣п╨я┌п╦п╡п╟ parallel #include <iostream> #include <omp.h> int main() { #pragma omp parallel std::cout << "Hello, world!" << std::endl; }
- 26. п■п╦я─п╣п╨я┌п╦п╡п╟ for #pragma omp for [<п©п╣п╢п╩п╬п╤п╣п╫п╦я▐>] <я├п╦п╨п╩я▀ for> п·пЁя─п╟п╫п╦я┤п╣п╫п╦я▐: Б─╒ (п∙п╢п╦п╫я│я┌п╡п╣п╫п╫я▀п╧) я│я┤я▒я┌я┤п╦п╨ Б─■ я├п╣п╩п╬пЁп╬ я┌п╦п©п╟, я┐п╨п╟п╥п╟я┌п╣п╩я▄, п╦п╩п╦ п╦я┌п╣я─п╟я┌п╬я─ п©я─п╬п╦п╥п╡п╬п╩я▄п╫п╬пЁп╬ п╢п╬я│я┌я┐п©п╟. п■п╬п╩п╤п╣п╫ п╦п╥п╪п╣п╫я▐я┌я▄я│я▐ я┌п╬п╩я▄п╨п╬ п╡ п╥п╟пЁп╬п╩п╬п╡п╨п╣ я├п╦п╨п╩п╟. Б─╒ пёя│п╩п╬п╡п╦п╣ я├п╦п╨п╩п╟: я│я─п╟п╡п╫п╣п╫п╦п╣ п©п╣я─п╣п╪п╣п╫п╫п╬п╧ я│ п╦п╫п╡п╟я─п╦п╟п╫я┌п╫я▀п╪ п╨ я├п╦п╨п╩я┐ п╡я▀я─п╟п╤п╣п╫п╦п╣п╪ п©я─п╦ п©п╬п╪п╬я┴п╦ <, <=, >, >=. Б─╒ п≤п╥п╪п╣п╫п╣п╫п╦п╣ я│я┤я▒я┌я┤п╦п╨п╟: п©я─п╦ п©п╬п╪п╬я┴п╦ ++, --, i += d, i -= d, i = i + d, i = d + i, i = i - d (d Б─■ п╦п╫п╡п╟я─п╦п╟п╫я┌п╫п╬п╣ п╨ я├п╦п╨п╩я┐ я├п╣п╩п╬п╣ п╡я▀я─п╟п╤п╣п╫п╦п╣)
- 27. п■п╦я─п╣п╨я┌п╦п╡п╟ for #pragma omp parallel { #pragma omp for for (ptrdiff_t i = 0; i < n; i++) dst[i] = sqrt(src[i]); }
- 28. #pragma omp parallel for #pragma omp parallel for for (ptrdiff_t i = 0; i < n; i++) dst[i] = sqrt(src[i]);
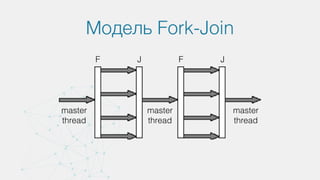
- 29. п■я─я┐пЁп╦п╣ п╢п╦я─п╣п╨я┌п╦п╡я▀ single - п╣я│п╩п╦ п╡ п©п╟я─п╟п╩п╩п╣п╩я▄п╫п╬п╧ п╬п╠п╩п╟я│я┌п╦ п╨п╟п╨п╬п╧-п╩п╦п╠п╬ я┐я┤п╟я│я┌п╬п╨ п╨п╬п╢п╟ п╢п╬п╩п╤п╣п╫ п╠я▀я┌я▄ п╡я▀п©п╬п╩п╫п╣п╫ п╩п╦я┬я▄ п╬п╢п╦п╫ я─п╟п╥. sections - п╦я│п©п╬п╩я▄п╥я┐п╣я┌я│я▐ п╢п╩я▐ п╥п╟п╢п╟п╫п╦я▐ п╨п╬п╫п╣я┤п╫п╬пЁп╬ (п╫п╣п╦я┌п╣я─п╟я┌п╦п╡п╫п╬пЁп╬) п©п╟я─п╟п╩п╩п╣п╩п╦п╥п╪п╟. master - п╡я▀п╢п╣п╩я▐п╣я┌ я┐я┤п╟я│я┌п╬п╨ п╨п╬п╢п╟, п╨п╬я┌п╬я─я▀п╧ п╠я┐п╢п╣я┌ п╡я▀п©п╬п╩п╫п╣п╫ я┌п╬п╩я▄п╨п╬ п╫п╦я┌я▄я▌- п╪п╟я│я┌п╣я─п╬п╪. critical - п╬я└п╬я─п╪п╩я▐п╣я┌я│я▐ п╨я─п╦я┌п╦я┤п╣я│п╨п╟я▐ я│п╣п╨я├п╦я▐ п©я─п╬пЁя─п╟п╪п╪я▀. п я─п╦я┌п╦я┤п╣я│п╨п╟я▐ я│п╣п╨я├п╦я▐ п╥п╟п©я─п╣я┴п╟п╣я┌ п╬п╢п╫п╬п╡я─п╣п╪п╣п╫п╫п╬п╣ п╦я│п©п╬п╩п╫п╣п╫п╦п╣ я│я┌я─я┐п╨я┌я┐я─п╦я─п╬п╡п╟п╫п╫п╬пЁп╬ п╠п╩п╬п╨п╟ п╠п╬п╩п╣п╣ я┤п╣п╪ п╬п╢п╫п╦п╪ п©п╬я┌п╬п╨п╬п╪. barrier - я│п©п╬я│п╬п╠ я│п╦п╫я┘я─п╬п╫п╦п╥п╟я├п╦п╦, п╢п╟п╣я┌ п╡я│п╣п╪ п©п╬я┌п╬п╨п╟п╪ я┐п╨п╟п╥п╟п╫п╦п╣ п╬п╤п╦п╢п╟я┌я▄ п╢я─я┐пЁ п╢я─я┐пЁп╟ п©п╣я─п╣п╢ я┌п╣п╪, п╨п╟п╨ п╬п╫п╦ п©я─п╬п╢п╬п╩п╤п╟я┌ п╡я▀п©п╬п╩п╫п╣п╫п╦п╣ п╥п╟ п╠п╟я─я▄п╣я─п╬п╪.
- 30. п║п©п╦я│п╬п╨ OpenMP я└я┐п╫п╨я├п╦п╧ Б─╒ omp_set_num_threads пёя│я┌п╟п╫п╬п╡п╦я┌я▄ п╨п╬п╩п╦я┤п╣я│я┌п╡п╬ п©п╬я┌п╬п╨п╬п╡ Б─╒ omp_get_num_threads п▓п╣я─п╫я┐я┌я▄ п╨п╬п╩п╦я┤п╣я│я┌п╡п╬ п©п╬я┌п╬п╨п╬п╡ п╡ пЁя─я┐п©п©п╣ Б─╒ omp_get_max_threads п°п╟п╨я│п╦п╪п╟п╩я▄п╫п╬п╣ п╨п╬п╩п╦я┤п╣я│я┌п╡п╬ п©п╬я┌п╬п╨п╬п╡ Б─╒ omp_get_thread_num ID п©п╬я┌п╬п╨п╟ Б─╒ omp_get_num_procs п°п╟п╨я│п╦п╪п╟п╩я▄п╫п╬п╣ п╨п╬п╩п╦я┤п╣я│я┌п╡п╬ п©я─п╬я├п╣я│я│п╬я─п╬п╡ Б─╒ omp_in_parallel п▓ п©п╟я─п╟п╩п╩п╣п╩я▄п╫п╬п╪ я─п╣пЁп╦п╬п╫п╣? Б─╒ omp_set_dynamic Activate dynamic thread adjustment Б─╒ omp_get_dynamic Check for dynamic thread adjustment Б─╒ omp_set_nested Activate nested parallelism Б─╒ omp_get_nested Check for nested parallelism Б─╒ omp_get_wtime п▓п╣я─п╫я┐я┌я▄ п╡я─п╣п╪я▐ Б─╒ omp_get_wtick Number of seconds between clock ticks
- 32. Platform for scientiО╛│c computing and data management
- 33. п п╟п╨п╦п╣ п╪п╬пЁя┐я┌ п╠я▀я┌я▄ п╥п╟п╢п╟я┤п╦? Б─╒ п²п╟я┐я┤п╫я▀п╣ я─п╟я│я┤п╣я┌я▀ Б─╒ п░п╫п╟п╩п╦п╥ п╢п╟п╫п╫я▀я┘ Б─╒ п═п╣п╫п╢п╣я─п╦п╫пЁ Б─╒ п°п╬п╢п╣п╩п╦я─п╬п╡п╟п╫п╦п╣ Б─╒ п÷я─п╬пЁп╫п╬п╥п╦я─п╬п╡п╟п╫п╦п╣ Б─╒ Б─╕
- 34. Problems Б─╒ Time-consuming deployment and support of the elastic infrastructure. Б─╒ Complicated process of connection between the large number of computing tools.
- 35. Solution Б─╒ Platform-as-a-Service that provides elastic multi- core systems, HPC clusters and GPU clusters. Б─╒ Software, templates, algorithms and data available at one place.
- 37. п²п╟я┐я┤п╫я▀п╧ я─п╟я│я┤п╣я┌. п п╟п╨ я█я┌п╬ я─п╟п╠п╬я┌п╟п╣я┌ п╡ я─п╣п╟п╩я▄п╫п╬п╧ п╤п╦п╥п╫п╦
- 38. п²п╟я┐я┤п╫я▀п╧ я─п╟я│я┤п╣я┌. п п╟п╨ я█я┌п╬ я─п╟п╠п╬я┌п╟п╣я┌ я┐ п╫п╟я│
- 40. п╓я┐п╫п╨я├п╦п╬п╫п╟п╩, п╨п╬я┌п╬я─я▀п╧ п╣я│я┌я▄ я│п╣п╧я┤п╟я│ Б─╒ п╥п╟пЁя─я┐п╥п╨п╟ я└п╟п╧п╩п╬п╡ п╡ я┘я─п╟п╫п╦п╩п╦я┴п╣; Б─╒ п╥п╟п©я┐я│п╨ п╡я▀я┤п╦я│п╩п╦я┌п╣п╩я▄п╫я▀я┘ п©я─п╬пЁя─п╟п╪п╪, п╫п╟п©п╦я│п╟п╫я▀я┘ п╫п╟ п║/п║++, п╨п╬я┌п╬я─я▀п╣ п╠я┐п╢я┐я┌ п╡я▀п©п╬п╩п╫я▐я┌я▄я│я▐ я│ п©п╬п╪п╬я┴я▄я▌ п╨п╬п╪п©п╦п╩я▐я┌п╬я─п╟ GCC я│ п©п╬п╢п╢п╣я─п╤п╨п╬п╧ OpenMP; Б─╒ п╡п╦я─я┌я┐п╟п╩я▄п╫я▀п╣ п╪п╟я┬п╦п╫я▀ п╬п╠п╩п╟п╨п╟ Azure я│ п╨п╬п╩п╦я┤п╣я│я┌п╡п╬п╪ я▐п╢п╣я─ п╬я┌ 1 п╢п╬ 32 п╦ п·п≈пё п╢п╬ 448 п⌠п▒; Б─╒ п©я─п╬я│п╪п╬я┌я─ п╦ я│п╨п╟я┤п╦п╡п╟п╫п╦п╣ я└п╟п╧п╩п╬п╡ я─п╣п╥я┐п╩я▄я┌п╟я┌п╬п╡ я─п╟я│я┤п╣я┌п╟; Б─╒ п╠п╦п╩п╩п╦п╫пЁ, п©п╬п©п╬п╩п╫п╣п╫п╦п╣ я│я┤п╣я┌п╟ п©я─п╦ п©п╬п╪п╬я┴п╦ п©п╩п╟я│я┌п╦п╨п╬п╡я▀я┘ п╨п╟я─я┌ п╦ п©я─п╬п╪п╬-п╨п╬п╢п╬п╡.
- 41. п÷я─п╬пЁя─п╟п╪п╪п╟ п╠п╣я┌п╟- я┌п╣я│я┌п╦я─п╬п╡п╟п╫п╦я▐ Б─╒ п÷п╬п╩я┐я┤п╦я┌я▄ п╠п╣я│п©п╩п╟я┌п╫я▀п╧ п╢п╬я│я┌я┐п© Б─╒ п≤я│п©п╬п╩я▄п╥п╬п╡п╟я┌я▄ п╫п╬п╡я▀п╣ я└я┐п╫п╨я├п╦п╦ п©п╣я─п╡я▀п╪п╦ Б─╒ п÷п╬п╪п╬пЁп╟я┌я▄ я│п╢п╣п╩п╟я┌я▄ FlyElephant п╩я┐я┤я┬п╣ http://О╛┌yelephant.net/beta/
- 42. п╓я┐п╫п╨я├п╦п╬п╫п╟п╩, п╨п╬я┌п╬я─я▀п╧ п╤п╢п╣я┌ п╫п╟я│ п╡ я│п╨п╬я─п╬п╪ п╠я┐п╢я┐я┴п╣п╪ Б─╒ п÷п╬п╢п╢п╣я─п╤п╨п╟ Python, R, Java п╦ MPI. Б─╒ п║п╦я│я┌п╣п╪п╟ п╡п╦п╥я┐п╟п╩п╦п╥п╟я├п╦п╦ я─п╣п╥я┐п╩я▄я┌п╟я┌п╬п╡ Б─╒ п║п╦я│я┌п╣п╪п╟ я┐п©я─п╟п╡п╩п╣п╫п╦я▐ я─п╣п╥я┐п╩я▄я┌п╟я┌п╟п╪п╦ я─п╟я│я┤п╣я┌п╬п╡ Б─╒ п▓п╫я┐я┌я─п╣п╫п╫я▐я▐ я│п╬я├п╦п╟п╩я▄п╫п╟я▐ я│п╣я┌я▄ Б─╒ п║п╦я│я┌п╣п╪п╟ API
- 43. п·я┌п╢п╣п╩я▄п╫я▀п╧ п╦п╫я┌п╣я─я└п╣п╧я│ п╢п╩я▐ я┐я┤п╣п╠п╫п╬пЁп╬ п©я─п╬я├п╣я│я│п╟ п÷п╬п╢п╢п╣я─п╤п╨п╟ п╬я┌п╨я─я▀я┌я▀я┘ п╫п╟я┐я┤п╫я▀я┘ п╦я│я│п╩п╣п╢п╬п╡п╟п╫п╦п╧