[Paper review] tera pipe: token level pipeline parallelism for training large-scale language models, berkely, 2021
ŌĆó
0 likesŌĆó66 views

ļ▓äĒü┤ļ”¼ ļīĆĒĢÖņŚÉņä£ 2021ļģäņŚÉ ļ░£Ēæ£ĒĢ£ Large-Scale Transformer ļ¬©ļŹĖņØś ļ│æļĀ¼ ĒĢÖņŖĄņŚÉ ļīĆĒĢ£ ļģ╝ļ¼Ė ļ”¼ļĘ░ņ×ģļŗłļŗż. TeraPipe Token-Level Pipeline Parallelism for Training Large-Scale Language Models https://arxiv.org/abs/2102.07988










[Paper review] tera pipe: token level pipeline parallelism for training large-scale language models, berkely, 2021
- 1. Review by Seong Hoon Jung hoondori@gmail.com 2021.03 Apache spark Ray
- 2. Motivation ŌĆó Transformer-based LM grows substantially with its model size, attributing to the fact that they can be unsupervisedly trained on almost unlimited text data ŌĆó GPT-3 can have more than 175B parameters, which amounts to 350 GB(16-bit format) ŌĆó This significantly exceeds the memory capacity of existing hardware accelerators, such as GPUs and TPUs, which makes model-parallel training a necessity
- 3. Review: Transformer Architecture Left-to-right attention, Multi-head Ļ░äļŗ©ĒĢśĻ▓īļŖö X * A * B ņ▓śļ¤╝ 2ļ▓łņØś Ē¢ēļĀ¼Ļ│▒ņ£╝ļĪ£ ņØ┤ĒĢ┤ĒĢśļ®┤ ļÉ£ļŗż.
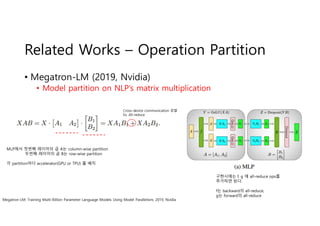
- 4. Related Works ŌĆō Operation Partition ŌĆó Megatron-LM (2019, Nvidia) ŌĆó Model partition on NLPŌĆÖs matrix multiplication Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, 2019, Nvidia MLPņŚÉņä£ ņ▓½ļ▓łņ¦Ė ļĀłņØ┤ņ¢┤ņØś Ļ│▒ AļŖö column-wise partition ļæÉļ▓łņ¦Ė ļĀłņØ┤ņ¢┤ņØś Ļ│▒ BļŖö row-wise partition Ļ░ü partitionļ¦łļŗż accelerator(GPU or TPU) ļź╝ ļ░░ņ╣ś Cross-device communication ņ£Āļ░£ Ex. All-reduce ĻĄ¼Ēśäņŗ£ņŚÉļŖö f, g ņŚÉ all-reduce opsļź╝ ņČöĻ░ĆĒĢśļ®┤ ļÉ£ļŗż. fļŖö backwardņØś all-reduce, gļŖö forwardņØś all-reduce
- 5. Related Works ŌĆō Operation Partition ŌĆó Megatron-LM (2019, Nvidia) ŌĆó Model partition on Self attentionŌĆÖs head Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, 2019, Nvidia AcceleratorĻ░Ć ĒŖ╣ņĀĢ headņŚÉņä£ņØś Attention ņØä Ļ│äņé░ f,gņŚÉņä£ ņĀĢļ░®Ē¢ź/ņŚŁļ░®Ē¢źņØś all-reduce ļŗ┤ļŗ╣
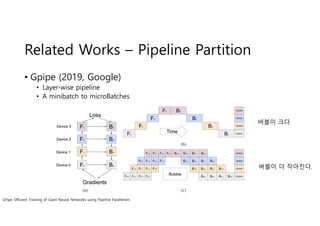
- 6. Related Works ŌĆō Pipeline Partition ŌĆó Gpipe (2019, Google) ŌĆó Layer-wise pipeline ŌĆó A minibatch to microBatches GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism ļ▓äļĖöņØ┤ Ēü¼ļŗż ļ▓äļĖöņØ┤ ļŹö ņ×æņĢäņ¦äļŗż.
- 7. Related Works ŌĆō Pipeline Partition ņŗżņĀ£ļĪ£ļŖö ļ▓äļĖöļÅä ņ×æĻ│Ā ĒĢÖņŖĄņŗ£Ļ░äļÅä ņżäņ¢┤ļōĀļŗż. L=Layerņłś, Pipeline-K (GPUĻ░£ņłś) hdim=8096, head=32, batch=32 ļŗ©ņØ╝ TPU ņé¼ņÜ®ļīĆļ╣ä 298ļ░░ Ēü░ ļ¬©ļŹĖ ĒĢÖņŖĄ Ļ░ĆļŖź K: TPU Ļ░£ņłś, M= # of micro-batch in mini-batch L=32 4 TPU ĻĖ░ņżĆ mini-batchļź╝ 4ļō▒ļČäĒĢśļ®┤ 3.2 x speed-up
- 8. Microbatch ņ▓śļ”¼ņØś ļ¼ĖņĀ£ņĀÉ ŌĆó ļ¼Ėņן ņĄ£ļīĆĻĖĖņØ┤(sequence length)Ļ░Ć ĻĖĖņ¢┤ņ¦Ćļ®┤ ļ®öļ¬©ļ”¼ ĒĢ£Ļ│äļĪ£ ņØĖ ĒĢ┤ņä£ ļ░░ņ╣śĒü¼ĻĖ░Ļ░Ć ņ×æņĢäņ¦ł ņłś ļ░¢ņŚÉ ņŚåļŗż. ļ®öļ¬©ļ”¼ fit = ļ¼Ėņן ĻĖĖņØ┤ x ļ░░ņ╣ś Ēü¼ĻĖ░ ļØ╝Ļ│Ā ĒĢśļ®┤ ļ¼Ėņן ĻĖĖņØ┤Ļ░Ć 2ļ░░ ļŖśņ¢┤ļéśļ®┤ ļ░░ņ╣śĒü¼ĻĖ░ļŖö ļ░śņ£╝ļĪ£ ņżäņŚ¼ņĢ╝ ĒĢ£ļŗż. ļ▓äļĖöņØ┤ ļŖśņ¢┤ļé£ļŗż
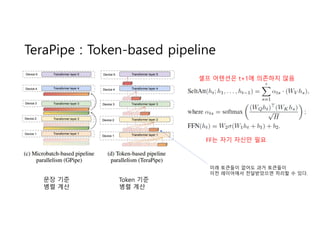
- 9. TeraPipe : Token-based pipeline ļ¼Ėņן ĻĖ░ņżĆ ļ│æļĀ¼ Ļ│äņé░ Token ĻĖ░ņżĆ ļ│æļĀ¼ Ļ│äņé░ ņģĆĒöä ņ¢┤ĒģÉņģśņØĆ t+1ņŚÉ ņØśņĪ┤ĒĢśņ¦Ć ņĢŖņØī FFļŖö ņ×ÉĻĖ░ ņ×ÉņŗĀļ¦ī ĒĢäņÜö ļ»Ėļל ĒåĀĒü░ļōżņØ┤ ņŚåņ¢┤ļÅä Ļ│╝Ļ▒░ ĒåĀĒü░ļōżņØ┤ ņØ┤ņĀä ļĀłņØ┤ņ¢┤ņŚÉņä£ ņĀäļŗ¼ļ░øņĢśņ£╝ļ®┤ ņ▓śļ”¼ĒĢĀ ņłś ņ׳ļŗż.
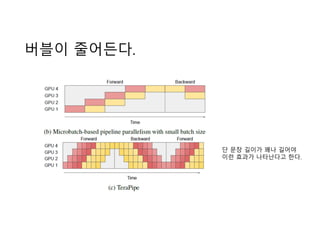
- 10. ļ▓äļĖöņØ┤ ņżäņ¢┤ļōĀļŗż. ļŗ© ļ¼Ėņן ĻĖĖņØ┤Ļ░Ć ĻĮżļéś ĻĖĖņ¢┤ņĢ╝ ņØ┤ļ¤░ ĒÜ©Ļ│╝Ļ░Ć ļéśĒāĆļé£ļŗżĻ│Ā ĒĢ£ļŗż.
- 11. ļ¼ĖņןņØä ĻĘĀņØ╝ĒĢśĻ▓ī ņ¬╝Ļ░£ļ®┤ ļ╣äĒÜ©ņ£©ņĀüņØ┤ļŗż. Left-right self-attention ĒŖ╣ņä▒ņāü ļ¼Ėņן ļüØņ£╝ļĪ£ Ļ░Ćļ®┤ņä£ ņ▓śļ”¼ņŗ£Ļ░äņØ┤ ĻĖĖņ¢┤ņ¦äļŗż. ņśłļź╝ ļōżņ¢┤ 16Ļ░£ ļŗ©ņ¢┤ļĪ£ ĻĄ¼ņä▒ļÉ£ ļ¼ĖņןņØä 4ļō▒ļČä ĒĢśļ®┤ t1ņŚÉņä£ļŖö 4Ļ░£ ļŗ©ņ¢┤Ļ░Ć ņ×ģļĀźņØ┤ņ¦Ćļ¦ī, T2ņŚÉņä£ļŖö 8Ļ░£ ļŗ©ņ¢┤, t3ņŚÉņä£ļŖö 12Ļ░£ ļŗ©ņ¢┤, t4ņŚÉņäĀ 16Ļ░£ ļŗ©ņ¢┤Ļ░Ć ņ×ģļĀźņØ┤ ļÉ£ļŗż. => ļ▓äļĖöņØ┤ ļŖśņ¢┤ļé£ļŗż. ļ¼ĖņןņØä ĻĘĀļō▒ĒĢśĻ▓ī ņ×Éļź┤ļŖö Ļ▓āņØ┤ ņĢäļŗłļØ╝ ņåīņÜöņŗ£Ļ░äņØ┤ ļ╣äņŖĘĒĢ┤ņ¦ĆĻ▓ī ņ×Éļź┤ļŖö Ļ▓āņØ┤ ļŹö ĒÜ©Ļ│╝ņĀüņØ┤ļŗż. ņĀĢļ░®Ē¢ź ņĀäĒīī ņ┤Ø ņåīņÜöņŗ£Ļ░ä Tļź╝ ņĄ£ņåīĒÖö ĒĢĀ ņłś ņ׳ļŖö ļ¼Ėņן ņ×Éļź┤ĻĖ░ scheme ļÅäņČ£ Knapsack problem with fixed t_max => Dynamic Programming
- 12. Parallel ņĪ░ĒĢ® Data Parallel : ļ░░ņ╣ś ļČäĒĢĀ with ļ¬©ļŹĖ ļ│ĄņĀ£ Pipeline Parallel (micro-batch, token) : ņĖĄļČäĒĢĀ, ļ░░ņ╣ś ļČäĒĢĀ, Token ļČäĒĢĀ Operation Parallel : Ē¢ēļĀ¼Ļ│▒ņØś ļČäĒĢĀ c.f) Swith Transformer ņŚÉņä£ļŖö expert parallel
- 13. ļ¬©ļŹĖ Ēü¼ĻĖ░ ņ╗żņ¦É = Small Batch = DataParallel ĒÜ©ņÜ®ņä▒ Ļ░Éņåī = Micro-batch ļ▓äļĖö ņ╗żņ¦É => Token parallel ņżæņÜöĒĢ┤ņ¦É (2), (3) ņØä ņĀ£ņÖĖĒĢśĻ│ĀļŖö ļ¬©ļōĀ ņĪ░ĒĢ®ņŚÉņä£ token parallelļĪ£ ņØĖĒĢ┤ņä£ speed up (2), (3) ņŚÉņä£ļŖö DPĻ░Ć token parallelņØä ņé¼ņÜ®ĒĢśņ¦Ć ņĢŖĻĖ░ļĪ£ Ļ▓░ņĀĢĒĢ£ Ļ▓ĮņÜ░ ĒŖ╣Ē׳ Largeļ¬©ļŹĖņŚÉņä£ļŖö ņ¦äĻ░Ćļź╝ ļ░£Ē£ś
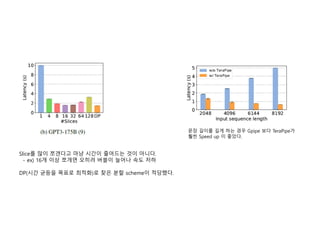
- 14. Sliceļź╝ ļ¦ÄņØ┤ ņ¬╝Ļ░ĀļŗżĻ│Ā ļ¦łļāź ņŗ£Ļ░äņØ┤ ņżäņ¢┤ļō£ļŖö Ļ▓āņØ┤ ņĢäļŗłļŗż. - ex) 16Ļ░£ ņØ┤ņāü ņ¬╝Ļ░£ļ®┤ ņśżĒ׳ļĀż ļ▓äļĖöņØ┤ ļŖśņ¢┤ļéś ņåŹļÅä ņĀĆĒĢś DP(ņŗ£Ļ░ä ĻĘĀļō▒ņØä ļ¬®Ēæ£ļĪ£ ņĄ£ņĀüĒÖö)ļĪ£ ņ░ŠņØĆ ļČäĒĢĀ schemeņØ┤ ņĀüļŗ╣Ē¢łļŗż. ļ¼Ėņן ĻĖĖņØ┤ļź╝ ĻĖĖĻ▓ī ĒĢśļŖö Ļ▓ĮņÜ░ Gpipe ļ│┤ļŗż TeraPipeĻ░Ć Ēø©ņö¼ Speed up ņØ┤ ņóŗņĢśļŗż.
- 15. Ļ▓░ļĪĀ ŌĆó TeraPipe: high-performance token-level pipeline parallel algorithm for training large-scale Transformer LM ŌĆó Optimal pipeline execution scheme by DP ŌĆó TeraPipe is orthogonal to other model parallel training methods and can be combined with them ŌĆó TeraPipe accelerates the synchronous training of the largest GPT-3 models with 175 billion parameters by 5.0x compared to previous methods.