














![[data analytics showcase] B11: ビッグデータを高速に検索?分析する「Elasticsearch」~新プラグイン「Graph」...](https://cdn.slidesharecdn.com/ss_thumbnails/waubsfngq2iqk8eggult-signature-33a079331e4d341f615beadcebfcdc44a5e412d60f4705c29726afdc4cbdaa7a-poli-161007073051-thumbnail.jpg?width=560&fit=bounds)










![[Cassandra summit Tokyo, 2015] Apache Cassandra日本人コミッターが伝える、"Apache Cassandra...](https://cdn.slidesharecdn.com/ss_thumbnails/cassandra-summit-tokyo-2015-yuki-150624053034-lva1-app6891-thumbnail.jpg?width=560&fit=bounds)
![[Cassandra summit Tokyo, 2015] Cassandra 2015 最新情報 by ジョナサン?エリス(Jonathan Ellis)](https://cdn.slidesharecdn.com/ss_thumbnails/tokyocassandrasummit2015withnotes-150624051836-lva1-app6892-thumbnail.jpg?width=560&fit=bounds)
![[db tech showcase Tokyo 2015] E35: Web, IoT, モバイル時代のデータベース、Apache Cassandraを学ぼう](https://cdn.slidesharecdn.com/ss_thumbnails/e35cassandra-150624022814-lva1-app6891-thumbnail.jpg?width=560&fit=bounds)
![[db tech showcase Tokyo 2015] A27: RDBエンジニアの為のNOSQL, 今どうしてNOSQLなのか?](https://cdn.slidesharecdn.com/ss_thumbnails/a27nosqlforrdbengineer-150624020431-lva1-app6891-thumbnail.jpg?width=560&fit=bounds)








More Related Content
More from datastaxjp (10)
Recently uploaded (8)
検索エンジン笔补迟丑别别が础锄耻谤别と颁补蝉蝉补苍诲谤补をどう利用しているのか
- 1. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. Con?dential 検索索エンジンPatheeがMSAzureと Cassandraをどう利利?用しているのか Con?dential To ?Be ?The ?Next ?Big ?Thing
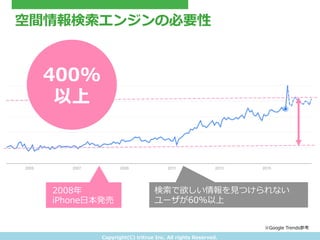
- 3. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. 空間情報検索索エンジンの必要性 ※Google ?Trends参考 2008年年 iPhone?日本発売 400% 以上 検索索で欲しい情報を?見見つけられない ユーザが60%以上
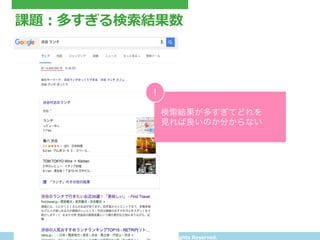
- 4. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. 課題:多すぎる検索索結果数 検索結果が多すぎてどれを 見れば良いのか分からない !
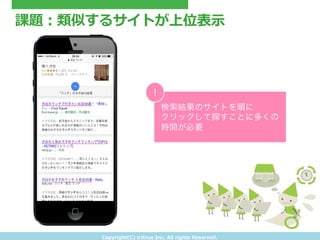
- 5. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. 課題:類似するサイトが上位表?示 検索結果のサイトを順に クリックして探すことに多くの 時間が必要 !
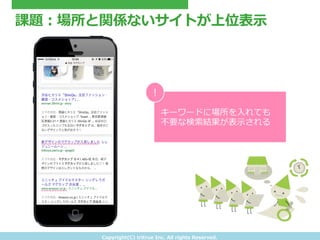
- 6. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. 課題:場所と関係ないサイトが上位表?示 キーワードに場所を?入れても 不不要な検索索結果が表?示される !
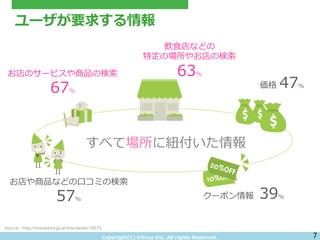
- 7. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. ユーザが要求する情報 7 ? お店のサービスや商品の検索索 67% 飲?食店などの 特定の場所やお店の検索索 63% お店や商品などの?口コミの検索索 57% すべて場所に紐紐付いた情報 Source : http://markezine.jp/article/detail/16675 価格 ?47% クーポン情報 ? ?39%
- 8. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. 既存検索索サービスとの違い 歩いて?行行ける 情報のみを表?示 場所に紐紐づく 情報のみを表?示 通常の検索索サービス 地図上に情報を マッピング
- 9. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. 既存地図サービス 地図上の情報(コンテンツ)が貧弱
- 10. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. 全ての空間情報を整理して、 誰でもアクセス(場所?情報)可能にすること
- 11. 空间検索索エンジン
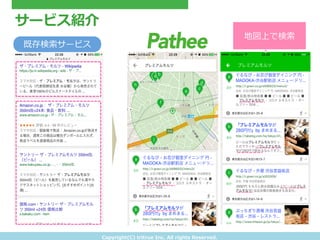
- 12. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. サービス紹介 既存検索索サービス 地図上で検索索
- 13. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. サービス紹介 デモ
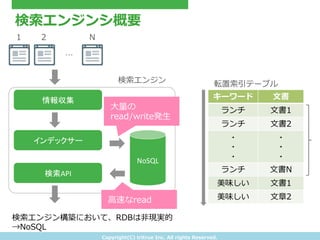
- 14. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. 検索索エンジンシ概要 情報収集 インデックサー 検索API NoSQL 検索索エンジン … キーワード ?文書 ランチ ?文書1 ランチ ?文書2 ? ? ? ? ? ? ランチ ?文書N 美味しい ?文書1 美味しい ?文章2 転置索索引テーブル 1 2 N ?大量量の read/write発?生 ?高速なread 検索索エンジン構築において、RDBは?非現実的 →NoSQL
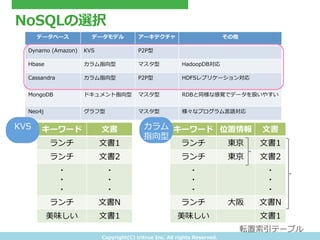
- 15. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. NoSQLの選択 データベース データモデル アーキテクチャ その他 Dynamo ?(Amazon) KVS P2P型 Hbase カラム指向型 マスタ型 HadoopDB対応 Cassandra カラム指向型 P2P型 HDFSレプリケーション対応 MongoDB ドキュメント指向型 マスタ型 RDBと同様な感覚でデータを扱いやすい Neo4j グラフ型 マスタ型 様々なプログラム?言語対応 キーワード 位置情報 ?文書 ランチ 東京 ?文書1 ランチ 東京 ?文書2 ? ? ? ? ? ? ランチ ?大阪 ?文書N 美味しい ?文書1 転置索索引テーブル キーワード ?文書 ランチ ?文書1 ランチ ?文書2 ? ? ? ? ? ? ランチ ?文書N 美味しい ?文書1 KVS カラム 指向型
- 16. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. (ベンチャー企業における)課題 1.お?金金が無い 2.時間がない 3.リソースが無い →インフラにかけられるコストは?月数万 →オンプレ無料料で貸して頂ける! →検索索精度度やサービスのUI/UXに注?力力 →インフラ構築?整備は、後回しに →頑張る! →そもしもインフラエンジニア不不在 →解決不不可能!?自分で何とかする! ?最低限のパフォーマンス? →? (優先度度:?高)NoSQL ??手間がかからない? ? ? ? →? (優先度度:中)構築や管理理が容易易 ?問題発?生時に容易易に対応? →? (優先度度:?高)マニュアルが潤沢 オンプレ Hbase ?+ ?Hadoop+
- 17. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. Hbaseの採?用 運?用フェーズからインフラに異異変が!! ■システム構築 ? →マニュアルやコミュニティーが豊富なため、容易易に稼働開始 ■サービス運?用 ? →?高速レスポンス(数msec) ■サービスインまでの時間短縮 ? →ThriftAPIの利利?用 開発からデモそしてサービスインまで順調
- 18. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. Hbaseの運?用フェーズにおける問題 ■情報収集速度度を向上による問題発?生 ? →Read/Writeが?大量量発?生 ? →負荷だけでなく、コンパクションが終わらないなどの問題 ■レスポンスの低下 ? →データの偏りや負荷増加のため ■パッケージのアップデート失敗 ? →パッケージのバージョン不不?一致の問題(CDHなどありますが) ? →Hadoop、Zookeeper、RegionServerなどなど ■実験不不?足による想定外の管理理コスト ? →余剰マシンが無く、テストが不不?十分に ? →マスターノード多重化 ? →ダウンテスト不不可 データ量量の増加とデータアクセス数の増加
- 19. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. Hbaseの運?用フェーズにおける問題 ■コンポーネントが多いため、切切り分けが困難 ? ?障害発?生 ? ?バージョンアップ ? ?実験環境構築 ? ?レスポンス低下 ■オンプレ問題 ? ?実験環境の構築困難 ■オンプレ問題 ? ?実験?運?用コストが?高い(ハードの故障も発?生) パッケージの多さによるが問題 システム構成の問題 オンプレ管理理の?高コストの問題
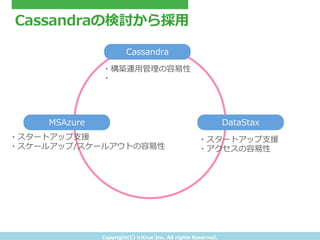
- 20. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. Cassandraの検討から採?用 MSAzure DataStax Cassandra ?スタートアップ?支援 ?スケールアップ/スケールアウトの容易易性 ?スタートアップ?支援 ?アクセスの容易易性 ?構築運?用管理理の容易易性 ?
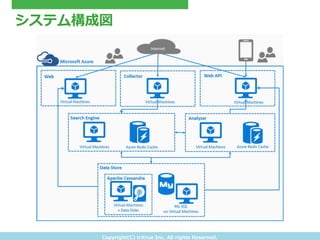
- 21. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. システム構成図
- 22. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. モニタリングシステムOpsCenter デモ
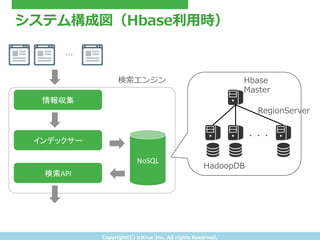
- 23. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. システム構成図(Hbase利利?用時) 情報収集 インデックサー 検索API NoSQL 検索索エンジン … ??? Hbase Master RegionServer HadoopDB
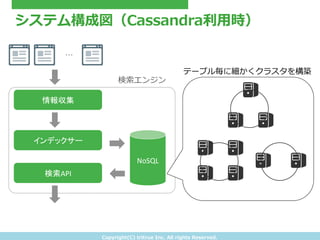
- 24. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. システム構成図(Cassandra利利?用時) 情報収集 インデックサー 検索API NoSQL 検索索エンジン … テーブル毎に細かくクラスタを構築
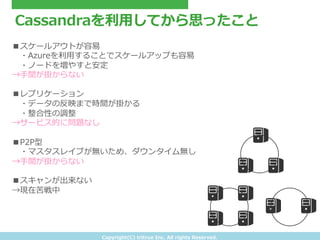
- 25. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. Cassandraを利利?用してから思ったこと ■スケールアウトが容易易 ? ?Azureを利利?用することでスケールアップも容易易 ? ?ノードを増やすと安定 →?手間が掛からない ■レプリケーション ? ?データの反映まで時間が掛かる ? ?整合性の調整 →サービス的に問題なし ■P2P型 ? ?マスタスレイブが無いため、ダウンタイム無し →?手間が掛からない ■スキャンが出来ない →現在苦戦中
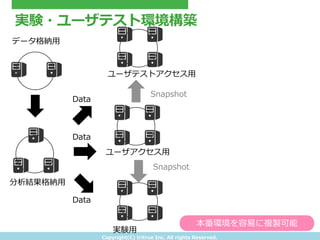
- 26. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. 実験?ユーザテスト環境構築 データ格納?用 分析結果格納?用 ユーザアクセス?用 ユーザテストアクセス?用 実験?用 Snapshot Snapshot Data Data Data 本番環境を容易易に複製可能
- 27. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. まとめ ■サービス開発から初期稼働時に?大量量データを扱いたい ? →クラウド上でCassandra運?用 ■課題 ? →コミュニティが少ない ? →国内にCassandra運?用経験者が少ない ■今後の期待 ? →海外サービス事業社では利利?用拡?大中 ■今後の展望 ? ?ファイル?システムをHDFSからHadoopに変更更 ? ?Spark導?入検討 ? ?パフォーマンス向上(チューニングやテーブル再設計)
- 28. Copyright(C) ?tritrue ?Inc. ?All ?rights ?Reserved. Con?dential 検索索エンジンPatheeがMSAzureと Cassandraをどう利利?用しているのか To ?Be ?The ?Next ?Big ?Thing