LT.22 ôC–µ—ß¡ï§À§™§±§ÎPDCA§Úªÿ§ª§Î≠hæ≥òã∫B§Œ‘í
?Download as PPTX, PDF?
0 likes?2,057 views

°˘ ÷Í Ωª·…ÁGIG§«§œö∞‘¬…Áƒ⁄√„è䪷§Úåg ©§∑§∆§§§Þ§π GIG inc. Good is good. We provide opportunities to the SEKAI by fusing technology and ideas. •∆•Ø•Œ•Ì•∏©`§»•Ø•Í•®•§•∆•£•÷§«•ª•´•§§Ú§Ë§Í¡º§Ø§π§Î°£–°§µ§ •¡©`•ý§´§È•π•ø©`•»§∑§ø∂ý§Ø§Œœ»»Àþ_§¨°¢ ¿ΩÁ§Ú§Ë§ÍÿN§´§ •‚•Œ§Àâ‰∏Ô§∑§∆§≠§Þ§∑§ø°£Õ®–≈°¢UX°¢•«•–•§•π°¢ºº–g§Œâ‰ªØ§»π≤§À ¿ΩÁ§œ§Þ§¿§Þ§¿º”ÀŸ∂»µƒ§Àâ‰§Ô§Í§Þ§π°£ Good is good. §§§§§‚§Œ§œ§§§§°£GIG§œ°¢Èv§Ô§√§ø•Ê©`•∂©`§‰•Ø•È•§•¢•Û•»§¨«∞§ÀþM§·§Î"§≠§√§´§±"§Ú§ƒ§Ø§Í§ƒ§≈§±§Þ§π°£ °ˆ §™Üñ§§∫œ§ª https://giginc.co.jp/contact/
Convert to study materialsBETA
Transform any presentation into ready-made study material°™select from outputs like summaries, definitions, and practice questions.

















LT.22 ôC–µ—ß¡ï§À§™§±§ÎPDCA§Úªÿ§ª§Î≠hæ≥òã∫B§Œ‘í
- 2. ◊‘º∫ΩBΩÈ °Ò œ√˚£∫€ý±æ ∞∫ðx °Ò ΩUös£∫⁄Ê¥Û§Œª˘µAπ§/«ÈàÛ‘∫ ◊‰°£2018ƒÍ§ÀGIG§À»Î…Á§∑°¢ •·•«•£•¢•µ•§•»÷∆◊˜§Œ•–•√•Ø •®•Û•…§Úµ£µ±°£2019ƒÍ§´§È §œ◊‘…Á•µ©`•”•πWorkship§Œ •Ï•≥•·•Û•…•®•Û•∏•Û§‰•π•≥•¢ •Í•Û•∞•∑•π•∆•ý§ŒÈ_∞k°¢§™§Ë §”•«©`•ø∑÷ŒˆòIÑ’§Àèæ ¬§∑§∆ §§§Î°£ °Ò »§Œ∂£∫•≤©`•ý£®FPS£©°¢ΩÓ•» •Ï£®þL£≥£© 2
- 3. ƒø¥Œ °Ò •◊•Ï•º•Û§Œƒøµƒ§»åùœÛ’þ ° ƒøµƒ °ˆ ôC–µ—ߡ柳•«©`•ø∑÷Œˆª˘±P§Úòã∫B§π§Î…œ§«±„¿˚§¿§√§ø§≥§»§Œπ≤”– °ˆ …Áƒ⁄§Œ∑Ω°©§ÿ°¢ À ¬ƒ⁄»ð§Œπ≤”– ° åùœÛ’þ °ˆ •π•ø©`•»•¢•√•◊§«ôC–µ—ß¡ï°¢§‚§∑§Ø§œ•«©`•ø•µ•§•®•Û•π§ÚªÓ”√§∑§Ë§¶§»§∑§∆§§§Î∑Ω °ˆ ¥Û∆ÛòI§«§‚°¢–¬“é•◊•Ì•∏•ß•Ø•»§«•«©`•ø§¨§ §§or…Ÿ§ §§◊¥ëB§«þM§·§Ë§¶§»§∑§∆§§§Î∑Ω °Ò Workship ° ∏≈“™ ° •π•≥•¢•Í•Û•∞ °Ò ôC–µ—ß¡ïª˘±P ° ◊Ó≥ı§Œ»´ÃÂòã≥…§» PDCA °ˆ Google Cloud Functions ° ∏ƒ…∆··§Œ»´ÃÂòã≥…§» PDCA °ˆ •¢•Œ•∆©`•∑•Á•Û•∑•π•∆•ý °ˆ Docker ±æ∑¨þ\”√ °ˆ •π•≥•¢•Í•Û•∞ API °Ò •«©`•ø∑÷Œˆª˘±P ° KPI ¥_’J”√•∑©`•» ° •™•Û•È•§•Û∑÷Œˆ Jupyter Notebook ° •«©`•ø∑÷Œˆ§Œ PDCA 3
- 4. ƒø¥Œ °Ò •◊•Ï•º•Û§Œƒøµƒ§»åùœÛ’þ ° ƒøµƒ °ˆ ôC–µ—ߡ柳•«©`•ø∑÷Œˆª˘±P§Úòã∫B§π§Î…œ§«±„¿˚§¿§√§ø§≥§»§Œπ≤”– °ˆ …Áƒ⁄§Œ∑Ω°©§ÿ°¢ À ¬ƒ⁄»ð§Œπ≤”– ° åùœÛ’þ °ˆ •π•ø©`•»•¢•√•◊§«ôC–µ—ß¡ï°¢§‚§∑§Ø§œ•«©`•ø•µ•§•®•Û•π§ÚªÓ”√§∑§Ë§¶§»§∑§∆§§§Î∑Ω °ˆ ¥Û∆ÛòI§«§‚°¢–¬“é•◊•Ì•∏•ß•Ø•»§«•«©`•ø§¨§ §§or…Ÿ§ §§◊¥ëB§«þM§·§Ë§¶§»§∑§∆§§§Î∑Ω °Ò Workship ° ∏≈“™ ° •π•≥•¢•Í•Û•∞ °Ò ôC–µ—ß¡ïª˘±P ° ◊Ó≥ı§Œ»´ÃÂòã≥…§» PDCA °ˆ Google Cloud Functions ° ∏ƒ…∆··§Œ»´ÃÂòã≥…§» PDCA °ˆ •¢•Œ•∆©`•∑•Á•Û•∑•π•∆•ý °ˆ Docker ±æ∑¨þ\”√ °ˆ •π•≥•¢•Í•Û•∞ API °Ò •«©`•ø∑÷Œˆª˘±P ° KPI ¥_’J”√•∑©`•» ° •™•Û•È•§•Û∑÷Œˆ Jupyter Notebook ° •«©`•ø∑÷Œˆ§Œ PDCA 4
- 5. ƒø¥Œ °Ò •◊•Ï•º•Û§Œƒøµƒ§»åùœÛ’þ ° ƒøµƒ °ˆ ôC–µ—ߡ柳•«©`•ø∑÷Œˆª˘±P§Úòã∫B§π§Î…œ§«±„¿˚§¿§√§ø§≥§»§Œπ≤”– °ˆ …Áƒ⁄§Œ∑Ω°©§ÿ°¢ À ¬ƒ⁄»ð§Œπ≤”– ° åùœÛ’þ °ˆ •π•ø©`•»•¢•√•◊§«ôC–µ—ß¡ï°¢§‚§∑§Ø§œ•«©`•ø•µ•§•®•Û•π§ÚªÓ”√§∑§Ë§¶§»§∑§∆§§§Î∑Ω °ˆ ¥Û∆ÛòI§«§‚°¢–¬“é•◊•Ì•∏•ß•Ø•»§«•«©`•ø§¨§ §§or…Ÿ§ §§◊¥ëB§«þM§·§Ë§¶§»§∑§∆§§§Î∑Ω °Ò Workship ° ∏≈“™ ° •π•≥•¢•Í•Û•∞ °Ò ôC–µ—ß¡ïª˘±P ° ◊Ó≥ı§Œ»´ÃÂòã≥…§» PDCA °ˆ Google Cloud Functions ° ∏ƒ…∆··§Œ»´ÃÂòã≥…§» PDCA °ˆ •¢•Œ•∆©`•∑•Á•Û•∑•π•∆•ý °ˆ Docker ±æ∑¨þ\”√ °ˆ •π•≥•¢•Í•Û•∞ API °Ò •«©`•ø∑÷Œˆª˘±P ° KPI ¥_’J”√•∑©`•» ° •™•Û•È•§•Û∑÷Œˆ Jupyter Notebook ° •«©`•ø∑÷Œˆ§Œ PDCA 5
- 6. °Ò •◊•Ì•∏•ß•Ø•»§»•’•Í©`•È•Û•π §Œ•Þ•√•¡•Û•∞•µ©`•”•π ° ∑®»ÀÇ»§œ°¢•◊•Ì•∏•ß•Ø•»§Àþm«–§ •’•Í©`•È•Û•π§À°∏öð§À§ §Î°π ° •’•Í©`•È•Û•πÇ»§œ°¢≈dŒ∂§Ú≥÷§√§ø «Û»À§À°∏öð§À§ §Î°π ° §™ª•§§§Àöð§À§ §Î§Ú§∑§øïr§Ú•Þ•√ •¡•Û•∞§»∫Ù≥∆ °Ò ≈–∂œ≤ƒ¡œ ° ∑®»ÀÇ»£∫•’•Í©`•È•Û•π§Œ•◊•Ì•’•£ ©`•Î°¢•π•≥•¢§ §… ° •’•Í©`•È•Û•πÇ»£∫«Û»Àƒ⁄»ð°¢ª·…Á «ÈàÛ§ §… °Ò ôC–µ—ߡ琉ªÓ”√àˆÀ˘ ° •’•Í©`•È•Û•π§Œ•π•≥•¢•Í•Û•∞ ° «Û»À§‰•’•Í©`•È•Û•π§Œ•Ï•≥•·•Û•… Workship §Œ∏≈“™ 6
- 7. •π•≥•¢•Í•Û•∞ °Ò •◊•Ì•’•£©`•Î§‰•Ê©`•∂––Ñ”«ÈàÛµ»§Ú§‚§»§À°¢•’•Í©`•È•Û•π§Úµ„ ˝ªØ °Ò §≥§Ï§Þ§«§Œ•¢•◊•Ì©`•¡ ° •◊•Ì•’•£©`•Î§Œ∏˜«ÈàÛ§Àåù§∑§∆µ„ ˝§Ú∏∂”Χ∑°¢§Ω§Œ∫œ”ã§Ú•π•≥•¢§»§π§Î °ˆ Îx…¢µƒ§«≤Ó§¨§ƒ§´§ §§ ° •◊•Ì•’•£©`•Î§Œ∏˜«ÈàÛ§Àåù§∑§∆Èv ˝§Úþm”√§∑°¢§Ω§Œ∫œ”ã§Ú•π•≥•¢§»§π§Î °ˆ •π•≥•¢§Œ∑÷≤º§Œé⁄§¨§Í§Ú’{’˚§∑§À§Ø§§ °ˆ ‘uÅ˝§«§≠§ §§ °ˆ Ÿ|§«§œ§ §Ø°¢¡ø§«§∑§´≈–∂œ§«§≠§ §§ °Ò ¨F‘⁄§Œ•¢•◊•Ì©`•¡ ° ôC–µ—ߡ匿•π•≥•¢§Ú”Ëúy§π§Î °ˆ ÖgºÉ§ Èv ˝§«§œ§ §§ °ˆ ¿˝£±£∫Œƒ’¬¡ø§«øº§®§øàˆ∫œ°¢∂ý§π§Æ§∆§‚…Ÿ§ §π§Æ§∆§‚•¿•· °ˆ ¿˝£≤£∫¬öòI§À“¿§√§∆÷ÿ“™§ •π•≠•Î§œâ‰ªØ§π§Î °Ò ÜñÓ}µ„ ° ◊Ó≥ı§œ•«©`•ø§¨§ §§ °ˆ íÒ”√§Œ•◊•Ì§À•“•¢•Í•Û•∞§∑§ §¨§È°¢•◊•Ì•’•£©`•Î§Œ‘uÅ˝•«©`•ø§Ú◊˜≥…§π§Î±ÿ“™ 7
- 8. ƒø¥Œ °Ò •◊•Ï•º•Û§Œƒøµƒ§»åùœÛ’þ ° ƒøµƒ °ˆ ôC–µ—ߡ柳•«©`•ø∑÷Œˆª˘±P§Úòã∫B§π§Î…œ§«±„¿˚§¿§√§ø§≥§»§Œπ≤”– °ˆ …Áƒ⁄§Œ∑Ω°©§ÿ°¢ À ¬ƒ⁄»ð§Œπ≤”– ° åùœÛ’þ °ˆ •π•ø©`•»•¢•√•◊§«ôC–µ—ß¡ï°¢§‚§∑§Ø§œ•«©`•ø•µ•§•®•Û•π§ÚªÓ”√§∑§Ë§¶§»§∑§∆§§§Î∑Ω °ˆ ¥Û∆ÛòI§«§‚°¢–¬“é•◊•Ì•∏•ß•Ø•»§«•«©`•ø§¨§ §§or…Ÿ§ §§◊¥ëB§«þM§·§Ë§¶§»§∑§∆§§§Î∑Ω °Ò Workship ° ∏≈“™ ° •π•≥•¢•Í•Û•∞ °Ò ôC–µ—ß¡ïª˘±P ° ◊Ó≥ı§Œ»´ÃÂòã≥…§» PDCA °ˆ Google Cloud Functions ° ∏ƒ…∆··§Œ»´ÃÂòã≥…§» PDCA °ˆ •¢•Œ•∆©`•∑•Á•Û•∑•π•∆•ý °ˆ Docker ±æ∑¨þ\”√ °ˆ •π•≥•¢•Í•Û•∞ API °Ò •«©`•ø∑÷Œˆª˘±P ° KPI ¥_’J”√•∑©`•» ° •™•Û•È•§•Û∑÷Œˆ Jupyter Notebook ° •«©`•ø∑÷Œˆ§Œ PDCA 8
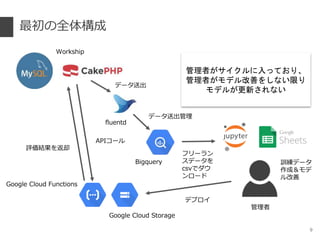
- 9. ◊Ó≥ı§Œ»´ÃÂòã≥… 9 Bigquery Workship Google Cloud Functions Google Cloud Storage fluentd πп̒þ§¨•µ•§•Ø•Î§À»Î§√§∆§™§Í°¢ πп̒þ§¨•‚•«•Î∏ƒ…∆§Ú§∑§ §§œÞ§Í •‚•«•Î§¨∏¸–¬§µ§Ï§ §§ πп̒þ •«©`•øÀÕ≥ˆ •«©`•øÀÕ≥ˆπÐ¿Ì ”ñæö•«©`•ø ◊˜≥…£¶•‚•« •Î∏ƒ…∆ •’•Í©`•È•Û •π•«©`•ø§Ú csv§«•¿•¶ •Û•Ì©`•… •«•◊•Ì•§ API•≥©`•Î ‘uÅ˝ΩYπ˚§Ú∑µ»¥
- 10. Google Cloud Functions °Ò GCP §Œ•µ©`•–•Ï•π•≥•Û•‘•Â©`•∆•£•Û•∞•µ©`•”•π °Ò •·•Í•√•» ° åùœÛ—‘’Z§«Èv ˝§Ú”õ ˆ§π§Î§»°¢•§•Ÿ•Û•»§Ú∆µ„§Àåg––§∑§∆§Ø§Ï§Î ° åùœÛ—‘’Z °ˆ Go 1.1 °ˆ Node.js 6, 8, 10 °ˆ Python 3.7 °Ò ÜñÓ} ° »ð¡ø§¨…Ÿ§ §§ (512MB) °ˆ Œƒ’¬§Úæ´ñÀ§π§Î§ø§·§Œ•”•Î•…úg§þΩ‚Œˆ∆˜§Ú—} ˝÷√§Ø§≥§»§¨§«§≠§ §§ °ˆ ∏þ∂»§ ¥«ï¯§Ú÷√§Ø§≥§»§¨§«§≠§ §§ °Ò Ω‚õQ≤þ ° Google NLP (Natural Language Processing) §»§ŒþB–Ø °ˆ ∏þ§§ (‘¬5ÕÚ) 10
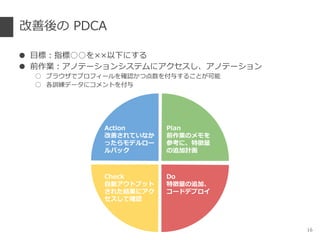
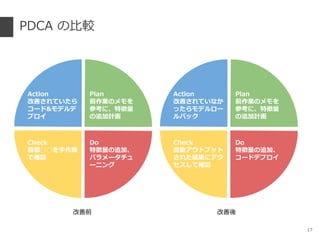
- 11. ◊Ó≥ı§Œ PDCA °Ò ƒøòÀ£∫÷∏òÀ°°§Ú°¡°¡“‘œ¬§À§π§Î °Ò «∞◊˜òI£∫Bigquery §´§È•Ê©`•∂•«©`•ø§Ú csv –Œ Ω§«•¿•¶•Û•Ì©`•…§∑°¢•π•◊•Ï •√•…•∑©`•»§«È_§§§∆•¢•Œ•∆©`•∑•Á•Û ° ∑«≥£§À“ä§À§Ø§§§Œ§«°¢Workship …œ§«•◊•Ì•’•£©`•Î§ÚÈ_§§§∆¥_’J °ˆ •◊•Ì•’•£©`•Î§¨∏¸–¬§µ§Ï§Î§»’`§√ §øµ„ ˝§Ú§ƒ§±§∆§∑§Þ§¶•Í•π•Ø ° •¢•Œ•∆©`•∑•Á•Û§ŒÎH°¢§…§Œ§Ë§¶§ µ„§À ◊≈ƒø§∑§∆µ„ ˝§Ú§ƒ§±§ø§´§Ú•·•‚ °ˆ Ãÿè’•Ÿ•Ø•»•Îòã∫B§Œ≤Œøº§À§π§Î 11 aa Plan «∞◊˜òI§Œ•·•‚§Ú ≤Œøº§À°¢Ãÿè’¡ø §Œ◊∑º””ãª≠ Do Ãÿè’¡ø§Œ◊∑º”°¢ •—•È•·©`•ø•¡•Â ©`•À•Û•∞ Check ÷∏òÀ°°§Ú ÷◊˜òI §«¥_’J Action ∏ƒ…∆§µ§Ï§∆§§§ø§È •≥©`•…&•‚•«•Î•« •◊•Ì•§
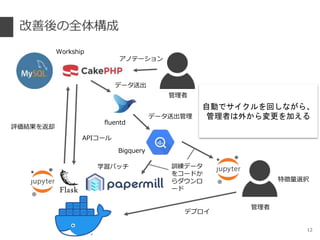
- 13. •¢•Œ•∆©`•∑•Á•Û•∑•π•∆•ý °Ò •«©`•ø§ÚÑø¬ §Ë§Ø◊˜≥…§π§Î•∑•π•∆•ý °Ò åg¨F§∑§ø§≥§» ° •÷•È•¶•∂§´§È•’•Í©`•È•Û•π§Œ•◊•Ì•’•£©`•Î§Ú ¥_’J ° ¨F‘⁄§Œ•‚•«•Î§À§Ë§Î”Ëúy•π•≥•¢§¨±Ì 槵§Ï°¢ §Ω§Ï§Ú≤Œøº§À§∑§ø‘uÅ˝ ° ‘uÅ˝§Œ≈–∂œª˘ú §ÀÈv§π§Î•≥•·•Û•» ° ‘uÅ˝§Œ∑Ω∑®§Úπ≤”–§π§Ï§–°¢’l§«§‚•¢•Œ•∆©`•∑ •Á•Û§π§Î§≥§»§¨ø…ƒÐ 13
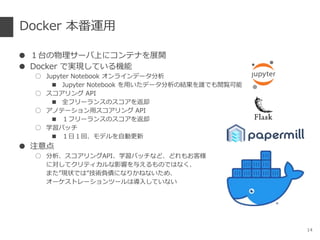
- 14. Docker ±æ∑¨þ\”√ °Ò £±Ã®§ŒŒÔ¿Ì•µ©`•–…œ§À•≥•Û•∆• §Ú’πÈ_ °Ò Docker §«åg¨F§∑§∆§§§ÎôCƒÐ ° Jupyter Notebook •™•Û•È•§•Û•«©`•ø∑÷Œˆ °ˆ Jupyter Notebook §Ú”√§§§ø•«©`•ø∑÷Œˆ§ŒΩYπ˚§Ú’l§«§‚Èá”Eø…ƒÐ ° •π•≥•¢•Í•Û•∞ API °ˆ »´•’•Í©`•È•Û•π§Œ•π•≥•¢§Ú∑µ»¥ ° •¢•Œ•∆©`•∑•Á•Û”√•π•≥•¢•Í•Û•∞ API °ˆ £±•’•Í©`•È•Û•π§Œ•π•≥•¢§Ú∑µ»¥ ° —ß¡ï•–•√•¡ °ˆ £±»’£±ªÿ°¢•‚•«•Î§Ú◊‘Ñ”∏¸–¬ °Ò ◊¢“‚µ„ ° ∑÷Œˆ°¢•π•≥•¢•Í•Û•∞API°¢—ß¡ï•–•√•¡§ §…°¢§…§Ï§‚§™øÕòî §Àåù§∑§∆•Ø•Í•∆•£•´•Î§ ”∞Ìë§Ú”Χ®§Î§‚§Œ§«§œ§ §Ø°¢ §Þ§ø°±¨F◊¥§«§œ°±ºº–gÿìǢ§À§ §Í§´§Õ§ §§§ø§·°¢ •™©`•±•π•»•Ï©`•∑•Á•Û•ƒ©`•Î§œå߻Χ∑§∆§§§ §§ 14
- 15. papermill °Ò Jupyter Notebook (.ipynb) §Ú CUI §´§Èåg––ø…ƒÐ§»§π§Î•ƒ©`•Î °Ò cron §»ΩM§þ∫œ§Ô§ª§Î§≥§»§« Jupyter Notebook §Œ•–•√•¡§Ú◊˜≥…ø…ƒÐ ° .ipynb §´§È .py §Àâ‰ìQ§π§Î ÷Èg§Ú °¬‘ ° £±»’ö∞§À•‚•«•Î—ß¡ï§Ú◊‘Ñ”åg–– °Ò åß»Î∑Ω∑® °Ò π§§∑Ω °Ò ÷ÿ“™§ µ„ ° åg––ΩYπ˚£®•‚•«•Î§Œ‘uÅ˝ΩYπ˚§Ú∫¨§ý£© result.ipynb §Ú•™•Û•È•§•Û§«¥_’Jø…ƒÐ ° -p §«“˝ ˝§Ú∂…§π§≥§»§¨ø…ƒÐ§ §Œ§«°¢§≥§Ï§ÚèÍ”√§π§Ï§–•–•√•¡—ß¡ïïr§À§œåg––§∑§ø§Ø§ §§•≥©` •…§Ú Notebook ƒ⁄§À÷√§§§∆§™§Ø§≥§»§¨ø…ƒÐ 15 $ pip install papermill $ papermill model_training.ipynb result.ipynb -p args False
- 16. ∏ƒ…∆··§Œ PDCA °Ò ƒøòÀ£∫÷∏òÀ°°§Ú°¡°¡“‘œ¬§À§π§Î °Ò «∞◊˜òI£∫•¢•Œ•∆©`•∑•Á•Û•∑•π•∆•ý§À•¢•Ø•ª•π§∑°¢•¢•Œ•∆©`•∑•Á•Û ° •÷•È•¶•∂§«•◊•Ì•’•£©`•Î§Ú¥_’J§´§ƒµ„ ˝§Ú∏∂”Χπ§Î§≥§»§¨ø…ƒÐ ° ∏˜”ñæö•«©`•ø§À•≥•·•Û•»§Ú∏∂”Î 16 aa Plan «∞◊˜òI§Œ•·•‚§Ú ≤Œøº§À°¢Ãÿè’¡ø §Œ◊∑º””ãª≠ Do Ãÿè’¡ø§Œ◊∑º”°¢ •≥©`•…•«•◊•Ì•§ Check ◊‘Ñ”•¢•¶•»•◊•√•» §µ§Ï§øΩYπ˚§À•¢•Ø •ª•π§∑§∆¥_’J Action ∏ƒ…∆§µ§Ï§∆§§§ §´ §√§ø§È•‚•«•Î•Ì©` •Î•–•√•Ø
- 18. ƒø¥Œ °Ò •◊•Ï•º•Û§Œƒøµƒ§»åùœÛ’þ ° ƒøµƒ °ˆ ôC–µ—ߡ柳•«©`•ø∑÷Œˆª˘±P§Úòã∫B§π§Î…œ§«±„¿˚§¿§√§ø§≥§»§Œπ≤”– °ˆ …Áƒ⁄§Œ∑Ω°©§ÿ°¢ À ¬ƒ⁄»ð§Œπ≤”– ° åùœÛ’þ °ˆ •π•ø©`•»•¢•√•◊§«ôC–µ—ß¡ï°¢§‚§∑§Ø§œ•«©`•ø•µ•§•®•Û•π§ÚªÓ”√§∑§Ë§¶§»§∑§∆§§§Î∑Ω °ˆ ¥Û∆ÛòI§«§‚°¢–¬“é•◊•Ì•∏•ß•Ø•»§«•«©`•ø§¨§ §§or…Ÿ§ §§◊¥ëB§«þM§·§Ë§¶§»§∑§∆§§§Î∑Ω °Ò Workship ° ∏≈“™ ° •π•≥•¢•Í•Û•∞ °Ò ôC–µ—ß¡ïª˘±P ° ◊Ó≥ı§Œ»´ÃÂòã≥…§» PDCA °ˆ Google Cloud Functions ° ∏ƒ…∆··§Œ»´ÃÂòã≥…§» PDCA °ˆ •¢•Œ•∆©`•∑•Á•Û•∑•π•∆•ý °ˆ Docker ±æ∑¨þ\”√ °ˆ •π•≥•¢•Í•Û•∞ API °Ò •«©`•ø∑÷Œˆª˘±P ° KPI ¥_’J”√•∑©`•» ° •™•Û•È•§•Û∑÷Œˆ Jupyter Notebook ° •«©`•ø∑÷Œˆ§Œ PDCA 18
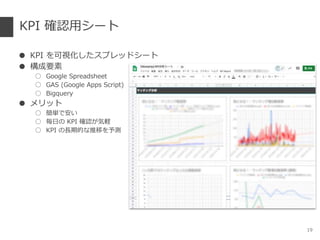
- 19. KPI ¥_’J”√•∑©`•» °Ò KPI §Úø…“ïªØ§∑§ø•π•◊•Ï•√•…•∑©`•» °Ò òã≥…“™Àÿ ° Google Spreadsheet ° GAS (Google Apps Script) ° Bigquery °Ò •·•Í•√•» ° ∫ÜÖg§«∞≤§§ ° ö∞»’§Œ KPI ¥_’J§¨öððX ° KPI §ŒÈL∆⁄µƒ§ Õ∆“∆§Ú”Ëúy 19
- 20. •™•Û•È•§•Û Jupyter Notebook °Ò KPI ¥_’J”√•∑©`•»§«§œ—a§§§≠§Ï§ §§∑÷Œˆ§Ú––§ §√§∆§§§Î Jupyter Notebook °Ò •·•Í•√•» ° •™•Û•È•§•Û§«π´È_§∑§∆§™§Í°¢ òÿœÞ§¨§¢§Ï§–Èá”E§«§≠§Î ° ‘î§∑§§∑÷Œˆ§œ§≥§≥§«––§§°¢ Markdown –Œ Ω§«•Ï•ð©`•» §Ú≤–§∑§∆§™§±§–°¢§Ô§∂§Ô§∂ •«©`•ø•µ•§•®•Û•∆•£•π•»§À §¢§Í§¨§¡§ •…•≠•Â•·•Û•»§Ú ◊˜≥…§π§Î±ÿ“™§¨§ §§ 20
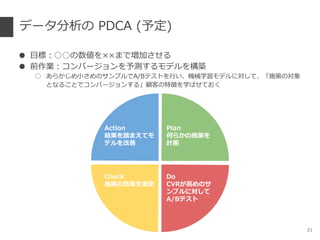
- 21. •«©`•ø∑÷Œˆ§Œ PDCA (”Ë∂®) °Ò ƒøòÀ£∫°°§Œ ˝Çé§Ú°¡°¡§Þ§«âດ§µ§ª§Î °Ò «∞◊˜òI£∫•≥•Û•–©`•∏•Á•Û§Ú”Ëúy§π§Î•‚•«•Î§Úòã∫B ° §¢§È§´§∏§·–°§µ§·§Œ•µ•Û•◊•Î§«A/B•∆•π•»§Ú––§§°¢ôC–µ—ß¡ï•‚•«•Î§Àåù§∑§∆°¢°∏ ©≤þ§ŒåùœÛ §»§ §Î§≥§»§«•≥•Û•–©`•∏•Á•Û§π§Î°πÓôøÕ§ŒÃÿ蒧ڗߧ–§ª§∆§™§Ø 21 aa Plan ∫Œ§È§´§Œ ©≤þ§Ú ”ãª≠ Do CVR§¨∏þ§·§Œ•µ •Û•◊•Î§Àåù§∑§∆ A/B•∆•π•» Check ©≤þ§ŒÑøπ˚§Úúy∂® Action ΩYπ˚§Úç§Þ§®§∆•‚ •«•Î§Ú∏ƒ…∆
- 23. ≤Œøº °Ò À ¬§«§œ§∏§·§ÎôC–µ—ß¡ï ° ”–ŸR øµÓá°¢÷–…Ω –ƒÃ´°¢Œ˜¡÷ –¢ ÷¯ O°ØREILLY °Ò Jupyter §¿§±§«ôC–µ—ß¡ï§Úåg•µ©`•”•π’πÈ_§«§≠§Îª˘±P ° https://engineer.recruit-lifestyle.co.jp/techblog/2018-10-04-ml-platform/ °Ò 2018ƒÍ§ §ºÀΩþ_§œ•≥•Û•∆• /Docker§Ú 𧶧Œ§´ ° https://cloudpack.media/41647 23
- 24. Good is good. We provide opportunities to The SEKAI by fusing technology and ideas. •∆•Ø•Œ•Ì•∏©`§»•Ø•Í•®•§•∆•£•÷§«•ª•´•§§Ú§Ë§Í¡º§Ø§π§Î
- 25. GIG INC. …ÁÜT°¢òIÑ’ŒØ”ö »´¬ö∑N∑eòOíÒ”√÷–§«§π£° ΩUÚY’þíÒ”√£®1ƒÍ“‘…œ£© °Ò •«•£•Ï•Ø•ø©` / •Þ©`•±•ø©` / æéºØ’þ °Ò •’•Ì•Û•»•®•Û•… / •–•√•Ø•®•Û•… / •§•Û•’•È °Ò •«•∂•§• ©` / •¢©`•»•«•£•Ï•Ø•ø©` °Ò »À ¬ / ÿîÑ’ ¬ö∑NŒ¥ΩUÚY’þ§‚ó ”ë °Ò •«•£•Ï•Ø•ø©` / •Þ©`•±•ø©` / æéºØ’þ °Ò •–•√•Ø•®•Û•… –¬◊‰§‚ó ”ë °Ò •Þ©`•±•ø©` / æéºØ’þ GIG INC§Œ§≥§» §≥§¡§È§Œœ‰§ÀþBΩjœ»§Ú§§§Ï§∆§Ø§¿§µ§§
- 26. Copyright ? GIG INC. All Rights Reserved.CONFIDENTIAL þ\√¸§Œ À ¬œý ÷ Dramatic project matching