




























pipelining
- 2. Presented By ï Saifullah Abbasi 2K15-CSE-76 ï Abdul Jabbar Tunio 2K15-CSE-04
- 3. Presentation Topic 1. Parallel processing 2. Pipelining 3. Pipeline categories a) Arithmetic pipeline b) Instruction pipeline
- 4. Parallel Processing ï A Parallel Processing system is able to perform concurrent data processing to achieve faster execution time.
- 5. Parallel Processing Example: ï While an instruction is being executed in the ALU, the next instruction can be read from memory. ï The system may have two or more ALUs and be able to execute two or more instructions at the same time. âSo the purpose of parallel processing is to speedup the computer processing capabilities.â
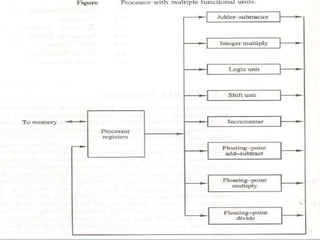
- 6. Parallel Processing Parallel Processing can be viewed from various level of complexity. 1. Lowest level: We distinguish between parallel and serial operations by the type of Registers used. 2. High level: Parallel Processing at higher level of complexity can be achieved by having an multiplicity of functional units the perform different operations simultaneously.
- 8. FLYNNâS CLASSIFICATION ï Flynnâs Classification of computer was based on new concepts which is âInstruction Stream and Data Streamâ for parallel computing.
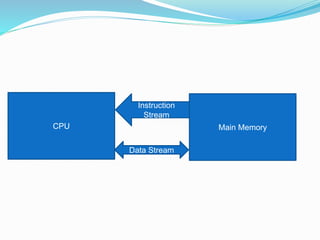
- 9. FLYNNâS CLASSIFICATION Instruction Stream & Data Stream The term âStreamâ refers to a sequence flow of either instruction or data operated on by the computer. ï Instruction Stream: In the complete cycle of instruction execution, a flow of instruction from main memory to the CPU is established, this flow of instruction is called IS. ï Data Stream: Flow of operands between processor and memory bi-directionally. The flow of operands is called DS.
- 10. CPU Main Memory Instruction Stream Data Stream
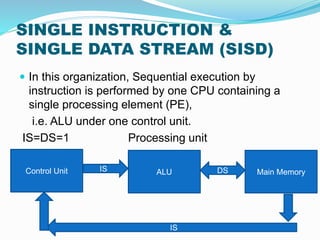
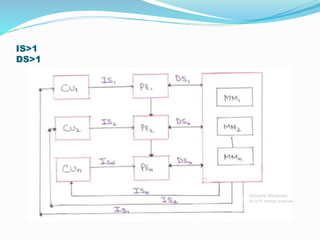
- 11. SINGLE INSTRUCTION & SINGLE DATA STREAM (SISD) ï In this organization, Sequential execution by instruction is performed by one CPU containing a single processing element (PE), i.e. ALU under one control unit. IS=DS=1 Processing unit Control Unit ALU Main MemoryIS DS IS
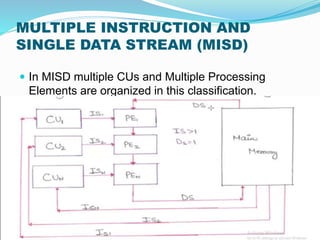
- 12. MULTIPLE INSTRUCTION & SINGLE DATA STREAM (MISD) ï In MISD multiple processing elements are organized under the control of multiple control unit. ï Each CU is handling one instruction stream and processed through its corresponding processing element. ï But each processing element is processing only a single data stream at a time.
- 13. MULTIPLE INSTRUCTION AND SINGLE DATA STREAM (MISD) ï In MISD multiple CUs and Multiple Processing Elements are organized in this classification.
- 14. MUTIPLE INSTRUCTION & MULTIPLE DATA STREAM (MIMD) ï In this Multiple Instruction Streams operate on Multiple Data Stream. ï Therefore handling Multiple Instruction Streams, Multiple Control Units & Multiple Processing elements are organized. Such that Multiple Processing Elements are handling Multiple Data Stream from main memory.
- 15. IS>1 DS>1
- 16. Pipelining ï Pipelining is a technique of decomposing sequence process into sub-operations, collection of processing segment through which binary information flows. ï A Pipeline is series of stages, where some work is done at each stage. The work is not finished until it has passed through all stages.
- 17. Pipelining ï Pipelining is an speed up technique where multiple instruction are overlapped in execution on a processor. ï Pipeline structure is to imagine that each segment consist of an input register followed by combinational circuit. The Register hold the data and combinational circuit performs the operations.
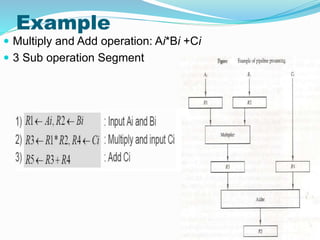
- 19. Example ï Multiply and Add operation: Ai*Bi +Ci ï 3 Sub operation Segment
- 20. How Pipeline Works? ï The pipeline is divided into segments and each segment can execute it operation concurrently with the other segments. Once a segment completes an operations, it passes the result to the next segment in the pipeline and fetches the next operations from the preceding segment.
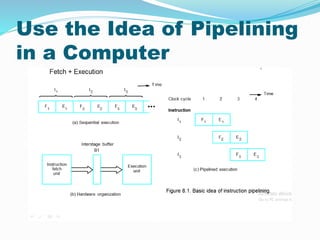
- 21. Idea of pipelining in computer ï The processor execute the program by fetching and executing instructions. One after the other. ï Let Fi and Ei refer to the fetch and execute steps for instruction Ii
- 22. Use the Idea of Pipelining in a Computer
- 23. Advantages/Disadvantage s Advantages: ï More efficient use of processor ï Quicker time of execution of large number of instructions
- 24. Arithmetic Pipeline ï Pipeline arithmetic units are usually found in very high speed computers. ï They are used to implement floating point operations. ï We will now discuss the pipeline unit for the floating point addition and subtraction.
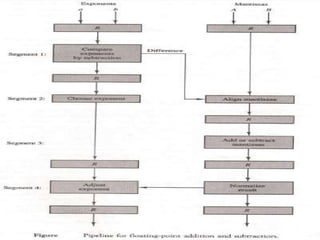
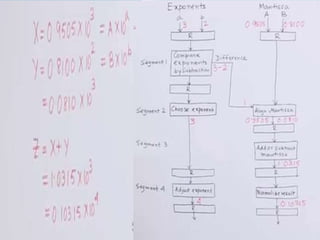
- 25. Arithmetic Pipeline ï The inputs to floating point adder pipeline are two normalized floating point numbers. ï A and B are mantissas and a and b are the exponents. ï The floating point addition and subtraction can be performed in four segments.
- 26. Arithmetic Pipeline ï The sub-operation performed in each segments are: ï Compare the exponents ï Align the mantissas ï Add or subtract the mantissas ï Normalize the result
- 27. ï Compare Exponent: The exponent are compared by subtracting them to determine their difference. âĒ Align the mantissas: The exponent difference determines how many times the mantissas associated with smaller exponent must be shifted to the right.
- 28. âĒ Normalize the result ï Overflow: Shifted right and exponent increments by one. ï Underflow: Shifted to left and number must be subtracted from exponent.
- 31. Instruction Pipeline ï Pipeline processing can occur not only in the data stream but in the instruction stream as well. ï An instruction pipeline reads consecutive instruction from memory while previous instruction are being executed in other segments. ï This caused the instruction fetch and execute segments to overlap and perform simultaneous operation.
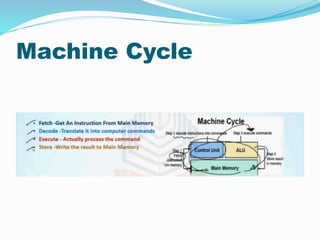
- 32. Machine Cycle
- 33. Instruction Pipeline ï Instruction execution process lends itself naturally to pipelining ï overlap the subtasks of instruction fetch, decode and execute ï Instruction pipeline has six operations, ï Fetch instruction (FI) ï Decode instruction (DI) ï Calculate operands (CO) ï Fetch operands (FO) ï Execute instructions (EI) ï Write result (WR) ï Overlap these operations
- 34. Instructions Fetch ï The IF stage is responsible for obtaining the requested instruction from memory. The instruction and the program counter are stored in the register as temporary storage. Decode Instruction ï The DI stage is responsible for decoding the instruction and sending out the various control lines to the other parts of the processor.
- 35. Calculate Operands ï The CO stage is where any calculations are performed. The main component in this stage is the ALU. The ALU is made up of arithmetic, logic and capabilities. Fetch Operands and Execute Instruction ï The FO and EI stages are responsible for storing and loading values to and from memory. They also responsible for input and output from the processor respectively.
- 36. Write Operands ï The WO stage is responsible for writing the result of a calculation, memory access or input into the register file.
- 37. Timing Diagram for Instruction Pipeline Operation
- 38. Any Questions???