















![Mô tả
15 25
1112 1114
value1 value2
1112 1114mypointer
Gán cho mypointer địa
chỉ của value1 [dùng
toán tử lấy địa chỉ (&)]
Giá trị được trỏ bởi
mypointer
g√°n 10 cho gi√°
trị được trỏ
bởi mypointer
10
Địa chỉ biến
Giá trị của biến](https://image.slidesharecdn.com/n8sk2stpswu6v9kndgxe-signature-a2aefd15529654f3e87e362a46d23579b835dc4f23157856393aba9ec132c113-poli-160425153455/85/Pointer-vn-18-320.jpg)






![Ví dụ:
#include <iostream.h>
#include <conio.h>
void main()
{
const int SIZE=5;
int i, *point, a[SIZE]={98,87,76,65,54};
clrscr();
point=&a[0]; // point=grade
for (i=0;i<SIZE;i++)
cout<<*(a+i)<<" "; (a)
cout<<endl;
for (i=0;i<SIZE;i++)
cout<<*(point+i)<<" "; (b)
cout<<endl;
for (i=0;i<SIZE;i++)
cout<<*(point)++<<" "; (c)
getch();
}
- Cách ghi *(point+i) không
làm thay đổi giá trị trong
point
- Cách ghi *point++ thì làm
thay đổi giá trị của point
sau mỗi lần thực hiện.](https://image.slidesharecdn.com/n8sk2stpswu6v9kndgxe-signature-a2aefd15529654f3e87e362a46d23579b835dc4f23157856393aba9ec132c113-poli-160425153455/85/Pointer-vn-25-320.jpg)
![5. Con trỏ và mảng
Trong thực tế, tên của một mảng tương đương với
địa chỉ phần tử đầu tiên của nó, giống như một
con trỏ tương đương với địa chỉ của phần tử đầu
tiên mà nó trỏ tới, vì vậy thực tế chúng hoàn toàn
như nhau. Ví dụ, cho hai khai báo sau:
int numbers[20];
int *p;
lệnh sau sẽ hợp lệ:
p = numbers;](https://image.slidesharecdn.com/n8sk2stpswu6v9kndgxe-signature-a2aefd15529654f3e87e362a46d23579b835dc4f23157856393aba9ec132c113-poli-160425153455/85/Pointer-vn-26-320.jpg)

![Con trỏ - Mảng
#include <iostream.h>
int main ()
{
int numbers[5];
int *p;
p = numbers; *p = 10;
p++; *p = 20;
p = &numbers[2]; *p = 30;
p = numbers + 3; *p = 40;
p = numbers; *(p+4) = 50;
for (int n=0; n<5; n++)
cout << numbers[n] << ", ";
return 0;
}
10, 20, 30, 40, 50](https://image.slidesharecdn.com/n8sk2stpswu6v9kndgxe-signature-a2aefd15529654f3e87e362a46d23579b835dc4f23157856393aba9ec132c113-poli-160425153455/85/Pointer-vn-28-320.jpg)
![Truy cập các phần tử mảng theo dạng
con trỏ
• Cú pháp:
&<Tên_mảng>[0] t/đương với <Tên_mảng>
&<Tên_mảng> [<Vị_trí>] t/đương với <Tên_mảng> + <Vị_trí>
<Tên_mảng>[<Vị_trí>] t/đương với *(<Tên_mảng> + <Vị_trí>)](https://image.slidesharecdn.com/n8sk2stpswu6v9kndgxe-signature-a2aefd15529654f3e87e362a46d23579b835dc4f23157856393aba9ec132c113-poli-160425153455/85/Pointer-vn-29-320.jpg)
![#include <iostream.h>
#include <conio.h>
/* Nhap mang binh thuong*/
void NhapMang(int a[ ], int N){
int i;
for(i=0;i<N;i++){
cout<<"a["<<i<<"] =";
cin>>a[i];}
}
/* Nhap mang theo dang con
tro*/
void NhapContro(int a[ ], int N)
{
int i;
for(i=0;i<N;i++){
cout<<"a["<<i<<" ]=";
cin>>a+i;}
}
void main()
{
int a[20],N,i;
clrscr();
cout<<"So phan tu N= "; cin>>N;
NhapMang(a,N); /*
NhapContro(a,N)*/
cout<<"Truy cap theo kieu mang: ";
for(i=0;i<N;i++)
cout<<setw(3)<<a[i];
cout<<"Truy cap theo kieu con tro: ";
for(i=0;i<N;i++)
cout<<setw(3)<<*(a+i);
getch();
}](https://image.slidesharecdn.com/n8sk2stpswu6v9kndgxe-signature-a2aefd15529654f3e87e362a46d23579b835dc4f23157856393aba9ec132c113-poli-160425153455/85/Pointer-vn-30-320.jpg)
![Truy cập đến từng phần tử đang được
quản lý bởi con trỏ theo dạng mảng
• Cú pháp:
<Tên_biến>[<Vị_trí>] t/đương với *(<Tên_biến> + <Vị_trí>)
&<Tên_biến>[<Vị_trí>] t/đương với (<Tên_biến> + <Vị_trí>)
Tên biến con trỏ Số nguyên](https://image.slidesharecdn.com/n8sk2stpswu6v9kndgxe-signature-a2aefd15529654f3e87e362a46d23579b835dc4f23157856393aba9ec132c113-poli-160425153455/85/Pointer-vn-31-320.jpg)
![Có mảng a gồm các phân tử kiểu số nguyên, khi viết: a[3] ;
//truy xuất đến phần tử thứ 4 trong mảng a.
− Nếu sử dụng chỉ số thì máy tính sẽ dựa vào chỉ số này
và địa chỉ bắt đầu của vùng nhớ dành cho mảng xác định
địa chỉ của phần tử mà ta muốn truy xuất tới
− Để truy xuất phần tử a[3], máy tính xác định như sau:
&a[3]= a[0] + (3*2) // giả sử kiểu int chiếm 2 byte bộ nhớ
a[4]a[3]a[2]a[1]a[0]
&a[0] &a[0]+(3*2)](https://image.slidesharecdn.com/n8sk2stpswu6v9kndgxe-signature-a2aefd15529654f3e87e362a46d23579b835dc4f23157856393aba9ec132c113-poli-160425153455/85/Pointer-vn-32-320.jpg)
![Ví dụ: #include <iostream.h>
#include <conio.h>
void main()
{
const int SIZE=5;
int i, *addr, a[SIZE]={98,87,76,65,54};
clrscr();
addr=&a[0];
for (i=0;i<SIZE;i++)
cout<<a[i]<<" "; (a)
cout <<endl;
for (i=0;i<SIZE;i++)
cout<<*(addr+i)<<" "; (b)
getch();
}
Địa chỉ bắt đầu của
mảng được gán
vào con trỏ addr
(addr+i) : Đại chỉ
phần tử thứ i trong
m·∫£ng
*(addr+i) : Giá trị
phần tử thứ i trong
m·∫£ng
*(a+i)](https://image.slidesharecdn.com/n8sk2stpswu6v9kndgxe-signature-a2aefd15529654f3e87e362a46d23579b835dc4f23157856393aba9ec132c113-poli-160425153455/85/Pointer-vn-33-320.jpg)






![9. Con trỏ và cấu trúc
• Như bất kì các kiểu dữ liệu nào khác, các cấu trúc có thể
được trỏ đến bởi con trỏ. Quy tắc hoàn toàn giống như
đối với bất kì kiểu dữ liệu cơ bản nào:
struct movies_t
{
char title [50];
int year;
}; movies_t amovie; movies_t *pmovie;
• Ở đây amovie là một đối tượng có kiểu movies_t và
pmovie là một con trỏ trỏ tới đối tượng movies_t.](https://image.slidesharecdn.com/n8sk2stpswu6v9kndgxe-signature-a2aefd15529654f3e87e362a46d23579b835dc4f23157856393aba9ec132c113-poli-160425153455/85/Pointer-vn-40-320.jpg)





![Bộ Nhớ Động
• Bộ nhớ động (heap)
– Bộ nhớ mà kích cỡ của nó chỉ có thể được xác
định khi chương trình chạy
• Hai toán tử được sử dụng
– new: cấp phát
– delete: thu hồi
void Foo (void)
{
int *ptr = new int;
char *str = new char[10];
//...
delete ptr;
delete [ ]str;
}
Ch∆∞∆°ng 5](https://image.slidesharecdn.com/n8sk2stpswu6v9kndgxe-signature-a2aefd15529654f3e87e362a46d23579b835dc4f23157856393aba9ec132c113-poli-160425153455/85/Pointer-vn-46-320.jpg)
![Toán tử new và new[ ]
• Dạng thức của toán tử này như sau:
pointer = new type
ho·∫∑c
pointer = new type [elements]
• Biểu thức đầu tiên được dùng để cấp phát
bộ nhớ chứa một phần tử có kiểu type.
Lệnh thứ hai được dùng để cấp phát một
khối nhớ (một mảng) gồm các phần tử
kiểu type](https://image.slidesharecdn.com/n8sk2stpswu6v9kndgxe-signature-a2aefd15529654f3e87e362a46d23579b835dc4f23157856393aba9ec132c113-poli-160425153455/85/Pointer-vn-47-320.jpg)
![Ví dụ:
int * bobby;
bobby = new int [5];
• trong trường hợp này, hệ điều hành dành
chỗ cho 5 phần tử kiểu int trong bộ nhớ
và trả về một con trỏ trỏ đến đầu của khối
nhớ. Vì vậy lúc này bobby trỏ đến một
khối nhớ hợp lệ gồm 5 phần tử int.](https://image.slidesharecdn.com/n8sk2stpswu6v9kndgxe-signature-a2aefd15529654f3e87e362a46d23579b835dc4f23157856393aba9ec132c113-poli-160425153455/85/Pointer-vn-48-320.jpg)
![Toán tử delete
• Dạng thức của nó như sau:
delete pointer;
ho·∫∑c
delete [ ] pointer;
Biểu thức đầu tiên nên được dùng để giải phóng bộ nhớ
được cấp phát cho một phần tử
Lệnh thứ hai dùng để giải phóng một khối nhớ gồm nhiều
phần tử (mảng)](https://image.slidesharecdn.com/n8sk2stpswu6v9kndgxe-signature-a2aefd15529654f3e87e362a46d23579b835dc4f23157856393aba9ec132c113-poli-160425153455/85/Pointer-vn-49-320.jpg)
![Tạo giá trị cho một mảng động
và in mảng lên màn hình
#include <iostream.h>
#include <conio.h>
#include <stdlib.h>
void main(void)
{
long int num,i;
int* arr;
clrscr();
cout <<"n SPT";cin >>num;
if (num>0)
{
arr=new int[num];
if (arr!=NULL)
{
randomize();
for (i=0;i<num;i++)
arr[i]=random(100);
for (i=0;i<num;i++)
cout <<*(arr+i)<<" ";
delete(arr);
}
else
cout <<“K du bo nho";
}
getch();
}](https://image.slidesharecdn.com/n8sk2stpswu6v9kndgxe-signature-a2aefd15529654f3e87e362a46d23579b835dc4f23157856393aba9ec132c113-poli-160425153455/85/Pointer-vn-50-320.jpg)


































More Related Content
What's hot (15)
Similar to Pointer vn (20)













More from Harry Potter (20)




















Pointer vn
- 1. C:7 CON TRỎ 1. Khái niệm 2. Định nghĩa 3. Các thao tác 4. Một số phép toán 5. Con trỏ và mảng 6. Truyền địa chỉ cho tham số bởi con trỏ 7. Con trỏ trỏ đến con trỏ 8. Con trỏ không kiểu 9. Con trỏ và cấu trúc 10. Bộ nhớ động
- 2. 1. Khái niệm • Chúng ta đã biết các biến đều có kích thước, kiểu dữ liệu xác định (biến tĩnh) chính là các ô nhớ mà chúng ta có thể truy xuất dưới các tên. • Các biến này được lưu trữ tại những chỗ cụ thể trong bộ nhớ, tồn tại trong suốt thời gian thực thi chương trình • Hạn chế của biến tĩnh: – Cấp phát ô nhớ dư: Gây lãnh phí – Cấp phát ô nhớ thiếu: Lỗi chương trình
- 3. 1. Khái niệm C++ cung cấp một kiểu biến gọi là con trỏ với những đặc điểm sau: • Chỉ phát sinh trong quá trình thực hiện chương trình • Khi chạy chương trình, kích thước của biến, vùng nhớ và địa chỉ vùng nhớ được cấp phát cho biến có thể thay đổi • Sau khi thực hiện xong có thể giải phóng để tiết kiệm chỗ trong bộ nhớ • Kích thước của biến con trỏ không phụ thuộc kiểu dữ liệu, nó luôn có kích thước cố định là 2 byte (tùy thuộc HĐH)
- 4. 2. Định nghĩa • Con trỏ đơn giản chỉ là địa chỉ của một vị trí bộ nhớ và cung cấp cách gián tiếp để truy xuất dữ liệu trong bộ nhớ Chương 5 type *pointer_name; •Kiểu dữ liệu được trỏ tới •Không phải là kiểu của con trỏ Tên con trỏ Ý nghĩa: Khai báo một biến có tên là pointer_name dùng để chứa địa chỉ của các biến có kiểu là type
- 5. 2. Định nghĩa • Giá trị của một biến con trỏ là địa chỉ mà nó trỏ đến • Nếu chưa muốn khai báo kiểu dữ liệu mà con trỏ chỉ đến, ta có thể khai báo như sau: void *<tên_con_trỏ>;
- 6. Ví dụ int *number; char *character; float *greatnumber; • Đây là ba khai báo của con trỏ • Mỗi biến trỏ tới một kiểu dữ liệu khác nhau • Chúng đều chiếm một lượng bộ nhớ như nhau (kích thước của một biến con trỏ tùy thuộc vào hệ điều hành) • Dữ liệu mà chúng trỏ tới không chiếm lượng bộ nhớ như nhau, một kiểu int, một kiểu char và cái còn lại kiểu float
- 7. 3. Các thao tác trên con trỏ • Lấy địa chỉ • Tham chiếu
- 8. Toán tử lấy địa chỉ (&) • Khai báo một biến thì nó phải được lưu trữ trong một vị trí cụ thể trong bộ nhớ • Chúng ta không quyết định nơi nào biến đó được đặt • Vậy: – Ai đặt vị trí của biến? – Chúng ta có thể biết biến đó được lưu trữ ở đâu ? Hệ điều hành Điều này có thể được thực hiện bằng cách đặt trước tên biến một dấu và (&), có nghĩa là "địa chỉ của".
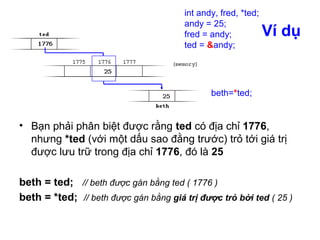
- 9. Lấy địa chỉ (tt) Giả sử rằng biến andy được đặt ở ô nhớ có địa chỉ 1776 và chúng ta viết như sau: int andy, fred; int* ted; andy = 25; fred = andy; ted = &andy;
- 10. Toán tử lấy địa chỉ (&) • Cú pháp: <tên_con_trỏ>=&<tên_biến>; • Ý nghĩa: Gán địa chỉ của <tên_biến> cho con trỏ <tên_con_trỏ>
- 11. Toán tử tham chiếu (*) • Có thể truy xuất trực tiếp đến giá trị được lưu trữ trong biến được trỏ bởi con trỏ bằng cách đặt trước tên biến con trỏ một dấu sao (*) - ở đây được dịch là "giá trị được trỏ bởi" •Vì vậy, nếu chúng ta viết: int beth = *ted; •C++ thể đọc nó là: "beth bằng giá trị được trỏ bởi ted" beth sẽ mang giá trị 25, vì ted bằng 1776 và giá trị trỏ bởi 1776 là 25 *<tên_con_trỏ>;
- 12. Ví dụ • Bạn phải phân biệt được rằng ted có địa chỉ 1776, nhưng *ted (với một dấu sao đằng trước) trỏ tới giá trị được lưu trữ trong địa chỉ 1776, đó là 25 beth = ted; // beth được gán bằng ted ( 1776 ) beth = *ted; // beth được gán bằng giá trị được trỏ bởi ted ( 25 ) int andy, fred, *ted; andy = 25; fred = andy; ted = &andy; beth=*ted;
- 13. Kết luận về & và * • Toán tử lấy địa chỉ (&) Nó được dùng như là một tiền tố của biến và có thể được dịch là "địa chỉ của“ &variable1 có thể được đọc là "địa chỉ của variable1“ • Toán tử tham chiếu (*) Nó chỉ ra rằng cái cần được tính toán là nội dung được trỏ bởi biểu thức được coi như là một địa chỉ. Được dịch là "giá trị được trỏ bởi".. *mypointer được đọc là "giá trị được trỏ bởi mypointer"
- 14. 3. Một số phép toán • Phép gán con trỏ • Phép cộng, trừ con trỏ với 1 số nguyên • Phép trừ 2 con trỏ • Tăng (giảm) 1 ngôi trên biến con trỏ
- 15. Phép gán con trỏ • 2 con trỏ cùng kiểu có thể gán cho nhau: int a, *p, *b ; float *f; a = 5 ; p = &a ; b = p ; /* đúng */ f = p ; /* sai do khác kiểu */
- 16. Phép gán con trỏ • Ta cũng có thể ép kiểu con trỏ theo cú pháp: (<kiểu_kết_quả>*)<tên_con_trỏ>; int a, *p, *q ; float *f; a = 5 ; p = &a ; q = p ; /* đúng */ f = (float*)p; /* đúng, nhờ ép kiểu*/
- 17. Vì sao? #include <iostream.h> int main () { int value1 = 5, value2 = 15; int *mypointer; mypointer = &value1; *mypointer = 10; mypointer = &value2; *mypointer = 20; cout << "value1==" << value1 << "/ value2==" << value2; return 0; } 10 20 Đầu tiên chúng ta gán cho mypointer địa chỉ của value1 dùng toán tử lấy địa chỉ (&) Sau đó chúng ta gán 10 cho giá trị được trỏ bởi mypointer, đó là giá trị được trỏ bởi value1 Vậy chúng ta đã sửa biến value1 một cách gián tiếp ……
- 18. Mô tả 15 25 1112 1114 value1 value2 1112 1114mypointer Gán cho mypointer địa chỉ của value1 [dùng toán tử lấy địa chỉ (&)] Giá trị được trỏ bởi mypointer gán 10 cho giá trị được trỏ bởi mypointer 10 Địa chỉ biến Giá trị của biến
- 19. #include <iostream.h> int main () { int value1 = 5, value2 = 15; int *p1, *p2; p1 = &value1; // p1 = địa chỉ của value1 p2 = &value2; // p2 = địa chỉ của value2 *p1 = 10; // giá trị trỏ bởi p1 = 10 *p2 = *p1; // giá trị trỏ bởi p2 = giá trị trỏ bởi p1 p1 = p2; // p1 = p2 (phép gán con trỏ) *p1 = 20; // giá trị trỏ bởi p1 = 20 cout << "value1==" << value1 << "/ value2==" << value2; return 0; } 10 20
- 20. Cộng, trừ con trỏ với 1 số nguyên • Ta có thể cộng (+), trừ (-) 1 con trỏ với 1 số nguyên dương N; kết quả trả về là một con trỏ, con trỏ này chỉ đến vùng nhớ cách vùng nhớ hiện tại N int *a; a = (int*) malloc(20); /* cấp vùng nhớ 20byte=10 số nguyên*/ int *b, *c; b = a + 7; c = b - 3;
- 21. Trừ 2 con trỏ • Trừ 2 con trỏ cùng kiểu sẽ cho 1 số nguyên (int). Đây là khoảng cách (phần tử) giữa 2 con trỏ đó • Ví dụ: c-a=4 Không thể cộng 2 con trỏ với nhau b = a + 7; c = b - 3;
- 22. Tăng (giảm) 1 ngôi trên biến con trỏ • Giả sử chúng ta có 3 con trỏ sau: char *mychar; short *myshort; long *mylong; Chúng lần lượt trỏ tới ô nhớ 1000, 2000 và 3000. • Nếu chúng ta viết mychar++; myshort++; mylong++; 1001 2001 3001 1001 2003 3004 Nguyên nhân: Khi cộng thêm 1 vào một con trỏ thì nó sẽ trỏ tới phần tử tiếp theo có cùng kiểu mà nó đã được định nghĩa, vì vậy kích thước tính bằng byte của kiểu dữ liệu nó trỏ tới sẽ được cộng thêm vào biến con trỏ
- 23. Tăng (giảm) 1 ngôi trên biến con trỏ Viết cách khác: mychar = mychar + 1; myshort = myshort + 1; mylong = mylong + 1;
- 24. Lưu ý thứ tự ưu tiên của toán tử Cần phải cảnh báo bạn rằng cả hai toán tử tăng (++) và giảm (--) đều có quyền ưu tiên lớn hơn toán tử tham chiếu (*), vì vậy biểu thức sau đây có thể dẫn tới kết quả sai: *p++; *p++ = *q++; Lệnh đầu tiên tương đương với *(p++) điều mà nó thực hiện là tăng p (địa chỉ ô nhớ mà nó trỏ tới chứ không phải là giá trị trỏ tới). Lệnh thứ hai, cả hai toán tử tăng (++) đều được thực hiện sau khi giá trị của *q được gán cho *p và sau đó cả q và p đều tăng lên 1. Lệnh này tương đương với: *p = *q; p++; q++;
- 25. Ví dụ: #include <iostream.h> #include <conio.h> void main() { const int SIZE=5; int i, *point, a[SIZE]={98,87,76,65,54}; clrscr(); point=&a[0]; // point=grade for (i=0;i<SIZE;i++) cout<<*(a+i)<<" "; (a) cout<<endl; for (i=0;i<SIZE;i++) cout<<*(point+i)<<" "; (b) cout<<endl; for (i=0;i<SIZE;i++) cout<<*(point)++<<" "; (c) getch(); } - Cách ghi *(point+i) không làm thay đổi giá trị trong point - Cách ghi *point++ thì làm thay đổi giá trị của point sau mỗi lần thực hiện.
- 26. 5. Con trỏ và mảng Trong thực tế, tên của một mảng tương đương với địa chỉ phần tử đầu tiên của nó, giống như một con trỏ tương đương với địa chỉ của phần tử đầu tiên mà nó trỏ tới, vì vậy thực tế chúng hoàn toàn như nhau. Ví dụ, cho hai khai báo sau: int numbers[20]; int *p; lệnh sau sẽ hợp lệ: p = numbers;
- 27. 5. Con trỏ và mảng • Ở đây p và numbers là tương đương và chúng có cũng thuộc tính, sự khác biệt duy nhất là chúng ta có thể gán một giá trị khác cho con trỏ p trong khi numbers luôn trỏ đến phần tử đầu tiên trong số 20 phần tử kiểu int mà nó được định nghĩa. Vì vậy, không giống như p - đó là một biến con trỏ bình thường, numbers là một con trỏ hằng. Lệnh gán sau đây là không hợp lệ: numbers = p; • Bởi vì numbers là một mảng (con trỏ hằng) và không có giá trị nào có thể được gán cho các hằng
- 28. Con trỏ - Mảng #include <iostream.h> int main () { int numbers[5]; int *p; p = numbers; *p = 10; p++; *p = 20; p = &numbers[2]; *p = 30; p = numbers + 3; *p = 40; p = numbers; *(p+4) = 50; for (int n=0; n<5; n++) cout << numbers[n] << ", "; return 0; } 10, 20, 30, 40, 50
- 29. Truy cập các phần tử mảng theo dạng con trỏ • Cú pháp: &<Tên_mảng>[0] t/đương với <Tên_mảng> &<Tên_mảng> [<Vị_trí>] t/đương với <Tên_mảng> + <Vị_trí> <Tên_mảng>[<Vị_trí>] t/đương với *(<Tên_mảng> + <Vị_trí>)
- 30. #include <iostream.h> #include <conio.h> /* Nhap mang binh thuong*/ void NhapMang(int a[ ], int N){ int i; for(i=0;i<N;i++){ cout<<"a["<<i<<"] ="; cin>>a[i];} } /* Nhap mang theo dang con tro*/ void NhapContro(int a[ ], int N) { int i; for(i=0;i<N;i++){ cout<<"a["<<i<<" ]="; cin>>a+i;} } void main() { int a[20],N,i; clrscr(); cout<<"So phan tu N= "; cin>>N; NhapMang(a,N); /* NhapContro(a,N)*/ cout<<"Truy cap theo kieu mang: "; for(i=0;i<N;i++) cout<<setw(3)<<a[i]; cout<<"Truy cap theo kieu con tro: "; for(i=0;i<N;i++) cout<<setw(3)<<*(a+i); getch(); }
- 31. Truy cập đến từng phần tử đang được quản lý bởi con trỏ theo dạng mảng • Cú pháp: <Tên_biến>[<Vị_trí>] t/đương với *(<Tên_biến> + <Vị_trí>) &<Tên_biến>[<Vị_trí>] t/đương với (<Tên_biến> + <Vị_trí>) Tên biến con trỏ Số nguyên
- 32. Có mảng a gồm các phân tử kiểu số nguyên, khi viết: a[3] ; //truy xuất đến phần tử thứ 4 trong mảng a. − Nếu sử dụng chỉ số thì máy tính sẽ dựa vào chỉ số này và địa chỉ bắt đầu của vùng nhớ dành cho mảng xác định địa chỉ của phần tử mà ta muốn truy xuất tới − Để truy xuất phần tử a[3], máy tính xác định như sau: &a[3]= a[0] + (3*2) // giả sử kiểu int chiếm 2 byte bộ nhớ a[4]a[3]a[2]a[1]a[0] &a[0] &a[0]+(3*2)
- 33. Ví dụ: #include <iostream.h> #include <conio.h> void main() { const int SIZE=5; int i, *addr, a[SIZE]={98,87,76,65,54}; clrscr(); addr=&a[0]; for (i=0;i<SIZE;i++) cout<<a[i]<<" "; (a) cout <<endl; for (i=0;i<SIZE;i++) cout<<*(addr+i)<<" "; (b) getch(); } Địa chỉ bắt đầu của mảng được gán vào con trỏ addr (addr+i) : Đại chỉ phần tử thứ i trong mảng *(addr+i) : Giá trị phần tử thứ i trong mảng *(a+i)
- 34. Xem xét…
- 35. 6. Truyền địa chỉ cho tham số bởi con trỏ #include <iostream.h> #include <conio.h> void swap(int*, int*); void main() { int i=5,j=10; clrscr(); cout <<"n Truoc khi goi ham swapn" <<"i= "<<i<<" " <<"j= "<<j <<endl; //I=5 j=10 swap(&i,&j); cout <<"Sau khi goi ham swapn" <<"i= "<<i<<" " <<"j= "<<j <<endl; //I=10 j=5 getch(); } void swap(int* x,int* y) { int tam; tam=*x; *x=*y; *y=tam; } Hàm swap để đổi giá trị của 2 biến truyền cho nó, các tham số của hàm được khai báo theo dạng con trỏ và lời gọi hàm phải thêm toán tử & đằng trước tên biến truyền cho hàm
- 36. Ví dụ #include <iostream.h> int addition (int a, int b) { return (a+b); } int subtraction (int a, int b) { return (a-b); } int (*minus) (int,int) = subtraction; int operation (int x, int y, int (*functocall) (int,int)) { int g; g = (*functocall) (x,y); return (g); } int main () { int m,n; m = operation (7, 5, &addition); n = operation (20, m, minus); cout <<n; return 0; } 8
- 37. 7. Con trỏ trỏ đến con trỏ char a; char * b; char ** c; a = 'z'; b = &a; c = &b; giả sử rằng a,b,c được lưu ở các ô nhớ 7230, 8092 and 10502, ta có thể mô tả đoạn mã trên như sau c là một biến có kiểu (char **) mang giá trị 8092 *c là một biến có kiểu (char*) mang giá trị 7230 **c là một biến có kiểu (char) mang giá trị 'z'
- 38. 8. Con trỏ không kiểu •Con trỏ không kiểu là một loại con trỏ đặc biệt. Nó có thể trỏ tới bất kì loại dữ liệu nào, từ giá trị nguyên hoặc thực cho tới một xâu kí tự. •Hạn chế duy nhất của nó là dữ liệu được trỏ tới không thể được tham chiếu tới một cách trực tiếp (chúng ta không thể dùng toán tử tham chiếu * với chúng) vì độ dài của nó là không xác định •Vì vậy chúng ta phải dùng đến toán tử chuyển kiểu dữ liệu hay phép gán để chuyển con trỏ không kiểu thành một con trỏ trỏ tới một loại dữ liệu cụ thể
- 39. Ví dụ #include <iostream.h> void increase (void* data, int type) { switch (type) { case sizeof(char) : (*((char*)data))++; break; case sizeof(short): (*((short*)data))++; break; case sizeof(long) : (*((long*)data))++; break; } } int main () { char a = 5; short b = 9; long c = 12; increase (&a,sizeof(a)); increase (&b,sizeof(b)); increase (&c,sizeof(c)); cout << (int) a << ", " << b << ", " << c; return 0; } 6, 10, 13 sizeof trả về một giá trị hằng là kích thước tính bằng byte của tham số truyền cho nó, ví dụ sizeof(char) bằng 1 vì kích thước của char là 1 byte
- 40. 9. Con trỏ và cấu trúc • Như bất kì các kiểu dữ liệu nào khác, các cấu trúc có thể được trỏ đến bởi con trỏ. Quy tắc hoàn toàn giống như đối với bất kì kiểu dữ liệu cơ bản nào: struct movies_t { char title [50]; int year; }; movies_t amovie; movies_t *pmovie; • Ở đây amovie là một đối tượng có kiểu movies_t và pmovie là một con trỏ trỏ tới đối tượng movies_t.
- 41. Ví dụ
- 42. Đoạn mã trên giới thiệu một điều quan trọng: toán tử ->. Đây là một toán tử tham chiếu chỉ dùng để trỏ tới các cấu trúc và các lớp (class). Nó cho phép chúng ta không phải dùng ngoặc mỗi khi tham chiếu đến một phần tử của cấu trúc. Trong ví dụ này chúng ta sử dụng: movies->title nó có thể được dịch thành: (*movies).title cả hai biểu thức movies->title và (*movies).title đều hợp lệ và chúng đều dùng để tham chiếu đến phần tử title của cấu trúc được trỏ bởi movies. Bạn cần phân biệt rõ ràng với: *movies.title nó tương đương với *(movies.title) lệnh này dùng để tính toán giá trị được trỏ bởi phần tử title của cấu trúc movies, trong trường hợp này (title không phải là một con trỏ) nó chẳng có ý nghĩa gì nhiều
- 43. các kết hợp có thể được giữa con trỏ và cấu trúc
- 44. 10. Bộ nhớ động • Bộ nhớ tĩnh • Bộ nhớ động • Toán tử new • Toán tử delete
- 45. Bộ nhớ tĩnh • Bộ nhớ tĩnh (stack) – Vùng nhớ được sử dụng để lưu trữ các biến toàn cục và lời gọi hàm • Tất cả những phần bộ nhớ chúng ta có thể sử dụng là các biến các mảng và các đối tượng khác mà chúng ta đã khai báo. Kích cỡ của chúng là cố định và không thể thay đổi trong thời gian chương trình chạy
- 46. Bộ Nhớ Động • Bộ nhớ động (heap) – Bộ nhớ mà kích cỡ của nó chỉ có thể được xác định khi chương trình chạy • Hai toán tử được sử dụng – new: cấp phát – delete: thu hồi void Foo (void) { int *ptr = new int; char *str = new char[10]; //... delete ptr; delete [ ]str; } Chương 5
- 47. Toán tử new và new[ ] • Dạng thức của toán tử này như sau: pointer = new type hoặc pointer = new type [elements] • Biểu thức đầu tiên được dùng để cấp phát bộ nhớ chứa một phần tử có kiểu type. Lệnh thứ hai được dùng để cấp phát một khối nhớ (một mảng) gồm các phần tử kiểu type
- 48. Ví dụ: int * bobby; bobby = new int [5]; • trong trường hợp này, hệ điều hành dành chỗ cho 5 phần tử kiểu int trong bộ nhớ và trả về một con trỏ trỏ đến đầu của khối nhớ. Vì vậy lúc này bobby trỏ đến một khối nhớ hợp lệ gồm 5 phần tử int.
- 49. Toán tử delete • Dạng thức của nó như sau: delete pointer; hoặc delete [ ] pointer; Biểu thức đầu tiên nên được dùng để giải phóng bộ nhớ được cấp phát cho một phần tử Lệnh thứ hai dùng để giải phóng một khối nhớ gồm nhiều phần tử (mảng)
- 50. Tạo giá trị cho một mảng động và in mảng lên màn hình #include <iostream.h> #include <conio.h> #include <stdlib.h> void main(void) { long int num,i; int* arr; clrscr(); cout <<"n SPT";cin >>num; if (num>0) { arr=new int[num]; if (arr!=NULL) { randomize(); for (i=0;i<num;i++) arr[i]=random(100); for (i=0;i<num;i++) cout <<*(arr+i)<<" "; delete(arr); } else cout <<“K du bo nho"; } getch(); }
- 51. Ví dụ
- 52. NULL • Null là một hằng số được định nghĩa trong thư viện C++ dùng để biểu thị con trỏ null. Trong trường hợp hằng số này chưa được định nghĩa, bạn có thể tự định nghĩa nó • Cú pháp: #define NULL 0
- 53. Bộ nhớ động trong ANSI-C • Toán tử new và delete là độc quyền của C++ và chúng không có trong ngôn ngữ C. • Trong ngôn ngữ C, để sử dụng bộ nhớ động phải sử dụng thư viện stdlib.h. • Cách này cũng hợp lệ trong C++ và nó vẫn được sử dụng trong một số chương trình.
- 54. • Hàm malloc: Cấp phát bộ nhớ động cho con trỏ void * malloc (size_t nbytes); • Hàm calloc: Giống malloc void * calloc (size_t nelements, size_t size); • Hàm realloc: Thay đổi kích thước khối nhớ đã được cấp phát cho con trỏ void * realloc (void * pointer, size_t size); • Hàm realloc: Giải phòng một khối nhớ động đã được cấp phát bởi malloc, calloc hoặc realloc. void free (void * pointer);