



















笔辞苍补苍锄补における强化学习とディープラーニングの応用
- 1. Ponanzaにおける 強化学習とディープ ラーニングの応用 大渡 勝己 HEROZ株式会社 2017/11/23 本文およびデータ等(P20, P22右中, P22右下, P23左, P23右, P26, P29上 のイラストを除く)の 著作権を含む知的所有権はHEROZ株式会社に帰属し、事前にHEROZ株式会社への書面による 承諾を得ることなく本資料およびその複製物に修正?加工することは堅く禁じられています。 また、本資料およびその複製物を送信、複製および配布?譲渡することは堅く禁じられています。
- 3. 2 AI(BtoC)サービス ? 人工知能関連技術を活かし、将棋?チェス?バックギャモン等のストラテジーゲームを世界中に展開中 ? IPの特性を最大限に活かした協業展開中 事業内容 人工知能(AI)を活用したインターネットサービスの企画?開発?運営 AI(BtoB)サービス ? 「将棋ウォーズ」等の開発を通じて蓄積した機械学習等の人工知能(AI)関連技術をFinTech (フィンテック:金融IT)、ヘルスケア、製造、交通、物流、建設、流通、人材等の各産業にも応用展開中 ? 既に大手金融機関に当社の人工知能技術が活用されるなど収益化にも成功しており、同分野における 研究開発を一層強化中 将棋ウォーズ どうぶつしょうぎ ウォーズ CHESS HEROZ (英語) BackgammonAce (英語) ポケモンコマスター (Pokémon Duel)
- 4. 3 HEROZ Kishin ? 「HEROZ Kishin」の由来 ? 「HEROZ Kishin(棋神)」は、将棋ウォーズ上で5 手自動で最善手を指してくれるAIから誕生 ? 将棋のプロ棋士に初勝利し名人を超えた棋神 ? 1秒間に読む局面数は、数百万に及びます 日本の伝統文化 将棋発 HEROZ Kishin(棋神)で世界を驚かす! HEROZ Kishin(棋神) これまでの人間には解決できなかった 問題に挑戦し、新時代の創造を目指していきます。
- 5. 4 講演者紹介 過去12種類のゲームAI大会に参加 大富豪、カーリング、囲碁、将棋、ぷよぷよ、Trax、 人狼、Block Go、Dots & Boxes、ターン制戦略ゲーム、 5五将棋、サイコロ将棋 ~ 2014.3 学部生 (5年間) 軟式庭球部 2014 (空白期間) 2015 大分県庁臨時職員(社会復帰) 2015.9 ~ 2017.9 大学院生 ゲームAI研究 2017.10 ~ HEROZ株式会社 プロフィール 大渡 勝己
- 6. 5 講演者紹介 過去12種類のゲームAI大会に参加 大富豪、カーリング、囲碁、将棋、ぷよぷよ、Trax、 人狼、Block Go、Dots & Boxes、ターン制戦略ゲーム、 5五将棋、サイコロ将棋 プロフィール 大渡 勝己 ~ 2014.3 学部生 (5年間) 軟式庭球部 2014 (空白期間) 2015 大分県庁臨時職員(社会復帰) 2015.9 ~ 2017.9 大学院生 ゲームAI研究 2017.10 ~ HEROZ株式会社
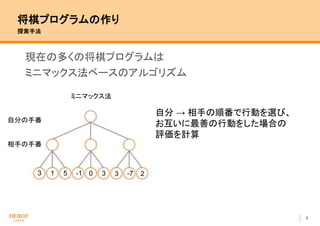
- 9. 8 将棋プログラムの作り 探索手法 現在の多くの将棋プログラムは ミニマックス法ベースのアルゴリズム 3 -11 3 30 ミニマックス法 25 -7 自分 → 相手の順番で行動を選び、 お互いに最善の行動をした場合の 評価を計算 相手の手番 自分の手番
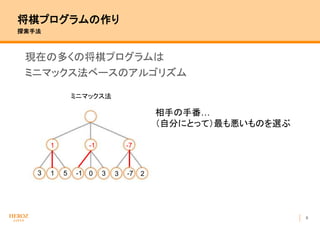
- 10. 9 将棋プログラムの作り 探索手法 現在の多くの将棋プログラムは ミニマックス法ベースのアルゴリズム 3 -151 3 3 -70 ミニマックス法 2 1 -1 -7 相手の手番… (自分にとって)最も悪いものを選ぶ
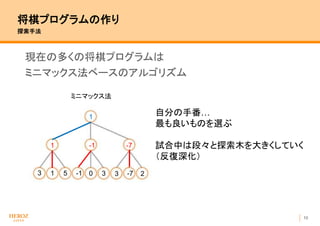
- 11. 10 将棋プログラムの作り 探索手法 現在の多くの将棋プログラムは ミニマックス法ベースのアルゴリズム 3 -151 3 3 -70 ミニマックス法 2 1 -1 -7 1 自分の手番… 最も良いものを選ぶ 試合中は段々と探索木を大きくしていく (反復深化)
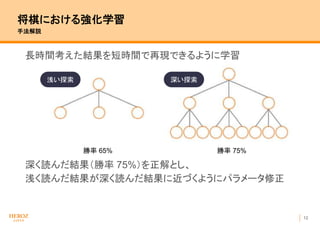
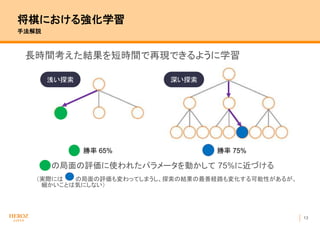
- 13. 12 将棋における強化学習 手法解説 長時間考えた結果を短時間で再現できるように学習 深く読んだ結果(勝率 75%)を正解とし、 浅く読んだ結果が深く読んだ結果に近づくようにパラメータ修正 勝率 65% 勝率 75% 浅い探索 深い探索
- 14. 13 将棋における強化学習 手法解説 長時間考えた結果を短時間で再現できるように学習 の局面の評価に使われたパラメータを動かして 75%に近づける (実際には の局面の評価も変わってしまうし、探索の結果の最善経路も変化する可能性があるが、 細かいことは気にしない) 勝率 65% 勝率 75% 浅い探索 深い探索
- 16. 15 コンピュータ将棋が新手を生み出す時代 強化学習によってコンピュータが 人間と違う手を選ぶようになる → 戦略が見直され、 人間同士の試合でも使われるようになる 例: 序盤に飛車を1段目に引く手
- 18. 17 将棋におけるディープラーニング Ponanza + Deep Learning Ponanza Chainer 2017春 - 最善手の予測を行うニューラルネット - 探索の際の手のオーダリング(良さそうな順に並び替え)に利用 Ponanza 2017秋 - AlphaGo Zero と同じく、 最善手の予測 (policy)、勝率の予測 (value)を 同時に計算するニューラルネット - 使用ライブラリがChainerからTensorflowに変更 - 自己対戦棋譜 約1500万試合 からの教師あり学習 - オーダリング以外の箇所でも利用 構成 3 x 3 convolution + α (構造に将棋向けの工夫あり) 入力 9 x 9 x 86 層数 入力層 1 + 共通層 9 + 分離層 1 + 各最終層 (計12) フィルタ数 256 計算可能 局面数 5000局面 / 秒 (GTX1080, バッチサイズ256) ニューラルネット概要 ※バッチサイズ …同時に計算する局面数
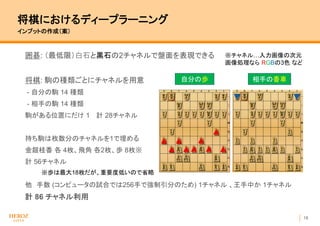
- 19. 18 将棋におけるディープラーニング インプットの作成(案) 囲碁: (最低限)白石と黒石の2チャネルで盤面を表現できる 将棋: 駒の種類ごとにチャネルを用意 - 自分の駒 14 種類 - 相手の駒 14 種類 駒がある位置にだけ 1 計 28チャネル 持ち駒は枚数分のチャネルを1で埋める 金銀桂香 各 4枚、飛角 各2枚、歩 8枚※ 計 56チャネル 他 手数 (コンピュータの試合では256手で強制引分のため) 1チャネル 、王手中か 1チャネル 計 86 チャネル利用 自分の歩 相手の香車 ※チャネル…入力画像の次元 画像処理なら RGBの3色 など ※歩は最大18枚だが、重要度低いので省略
- 20. 19 AlphaGo vs Ponanza AlphaGoとPonanzaのニューラルネットを比較 AlphaGo Zero Ponanza 2017秋 ネットワーク構成 インプット 19 x 19 x 17 80層 256フィルタ インプット 9 x 9 x 86 12層 256フィルタ (小さい) 学習方法 ゼロから探索ありの 強化学習(すごい) 過去のPonanzaの 着手?評価?勝敗から教師あり学習 学習使用リソース 大量(諸説あり)、3日 GPU1枚、1ヶ月 利用法 ニューラルネットだけで モンテカルロ木探索 既存の評価関数による アルファベータ系探索との アンサンブル
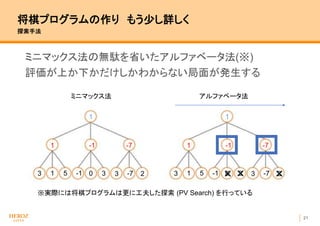
- 22. 21 将棋プログラムの作り もう少し詳しく 探索手法 ミニマックス法の無駄を省いたアルファベータ法(※) 評価が上か下かだけしかわからない局面が発生する 3 -151 3 3 -70 ミニマックス法 アルファベータ法 2 1 -1 -7 1 3 -151 3 3 -70 2 1 -1 -7 1 ? ? ? ※実際には将棋プログラムは更に工夫した探索 (PV Search) を行っている
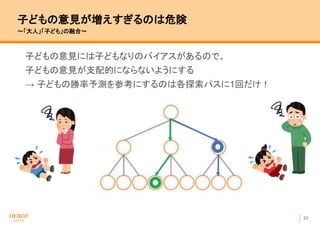
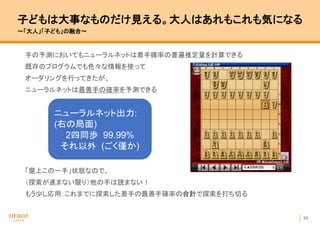
- 23. 22 子どもは絶対評価。大人は相対評価 ?「大人」「子ども」の融合? アルファベータ探索においては、 多くの局面の評価は、ある勝率より「上」か「下」かだけ ニューラルネットの出力する予測勝率は「勝率○%」 と絶対的な値なので、 精度が低くても有効な情報になることが多い 例1 大人 45%よりは良い 子ども 85% → (平均して) 結論 65% よりは良い可能性が高い
- 26. 25 子どもに「1億千万」以上の大きな数を求めない ?「大人」「子ども」の融合? ニューラルネット(CNN)は足し算と掛け算の集合。 大きな値を学習すれば重みが大きな値になる。 囲碁 大局的な陣取り(各マスがどちらの陣地になるか) → 各マスに(-1 ~ +1)の値が付けば良い 将棋 玉の周りの局所的な詰みの有無 → 詰みにつながる駒の配置パターンに大きな値が付くと考えられる 互角局面での精度向上のため、 Ponanzaのニューラルネットでは、 「学習中のニューラルネットの評価」、「教師の評価」の双方を 25% ~ 75% の範囲にクリップして学習
Editor's Notes
- #2: 3位になってしまって、引退微妙
- #5: 滨叠惭ワトソンみたいなもの? 分野に合った担当者が対応するのでご安心ください
- #6: 起承転结の転
- #7: 古典的なゲームの础滨全般の人
- #8: ディープについては自分のやったこと
- #9: まずはトッププログラムがみんなやっていることを话す。笔辞苍补苍锄补は2年以上前からやっている
- #10: ゲーム木
- #15: 学习のターゲットの値は试合の胜ち负け等も入れられる
- #16: 正則化とかしない データを増やすことが圧倒的に大事だった 翻訳でも使える 人間だって数十億年分のデータが溜まっている
- #17: ここまでで前半终わり 10分くらい
- #18: ディープについては自分のやったこと
- #19: ここコピーしてもあんまり意味ないよ TensorflowはC++から使える PFNの方々の+alpha
- #21: 础濒辫丑补驳辞の狈狈は骋笔鲍のメモリにちょうどのるくらい
- #22: ここからどう使うか 自分は大人と子供のイメージでプログラムを描いてきた
- #23: 以下しかわからない
- #25: 探索の结果负けが分かっていても子供が駄々をこねることがある
- #29: スレッド…脳みたいなもの これは人に見せる用です
- #30: 技術的に難しいのは接合部分 GPU使用率90%
- #31: 反復深化 リアルタイムでなかった
- #32: 2日前に书いたコードを当日朝使うことが决定した