PostgreSQL 9.5 CPU Read Scalability
?
0 likes?1,383 views

2016/05 Ą┌7╗ž PostgreSQLźóź¾ź½ź¾źšźĪźņź¾ź╣Ż└¢|Š®





![12Copyright?2016 NTT corp. All Rights Reserved.
USLż╦żĶżļĮŌ╬÷
The Universal Scalability Law (USL) ż╚żŽŻ┐
? ź│ź¾źįźÕ®`ź┐®`źĘź╣źŲźÓż╬ź╣ź▒®`źķźėźĻźŲźŻż“
źŌźŪźļ╗»ĪóČ©┴┐╗»
? ╠žČ©ż╬źĘź╣źŲźÓż╦ę└żķż║▀mÅĻ┐╔─▄
? źŽ®`ź╔ź”ź¦źóĪóźĮźšź╚ź”ź¦źóż╦ķvż’żķż║
ź╣ź▒®`źķźėźĻźŲźŻż“įuü²┐╔─▄
įöżĘż»żŽż│ż┴żķż“ęŖżŲŽ┬żĄżżĪŻ
[Gun08] Neil J. Gunther. A general theory of computational scalability based on rationalfunctions.
CoRR, abs/0808.1431, 2008. http://arxiv.org/pdf/0808.1431v2.pdf](https://image.slidesharecdn.com/postgresqlcpureadscalability2016051-161207072713/85/PostgreSQL-9-5-CPU-Read-Scalability-12-320.jpg)





PostgreSQL 9.5 CPU Read Scalability
- 1. Copyright?2016 NTT corp. All Rights Reserved. PostgreSQL 9.5 Read Scalability 2016/05/28 PostgreSQL źóź¾ź½ź¾źšźĪźņź¾ź╣ NTT OSSź╗ź¾ź┐ ┤¾╔Įšµīg
- 2. 2Copyright?2016 NTT corp. All Rights Reserved. Read Scalability ż╚żŽŻ┐ ? ż╔żņż└ż▒ČÓż»ż╬▓╬ššSQLż“üK┴ąäI└ĒżŪżŁżļż½ĪŻ ? ż─ż▐żĻĪóč}╩²ż╬ź»źķźżźóź¾ź╚ż½żķż╬▓╬ššSQLż“Īóč}╩²ż╬CPUź│ źóżŪż╔żņż└ż▒üK┴ąż╦äI└ĒżŪżŁżļż½ĪŻ żŽżĖżßż╦
- 3. 3Copyright?2016 NTT corp. All Rights Reserved. ĪĖź╣ź▒®`źļż╣żļĪ╣ĪĖź╣ź▒®`źķźėźĻźŲźŻż¼żóżļĪ╣żŽ Ż▓ż─ż╬ęŌ╬ČżŪ╩╣ż’żņżļż│ż╚ż¼ČÓżżĪŻ ? ź»źķźżźóź¾ź╚(źµ®`źČ/źūźĒź╗ź╣)ż╦īØż╣żļź╣ź▒®`źķźėźĻźŲźŻ ?10ź»źķźżźóź¾ź╚ż¼AźĄ®`źąż╦īØżĘżŲSQLż“░kąążĘż┐Ģr ?100ź»źķźżźóź¾ź╚ż¼AźĄ®`źąż╦īØżĘżŲSQLż“░kąążĘż┐Ģr ż“▒╚▌^ż╣żļż╚Īó10▒Čż╬ź╣źļ®`źūź├ź╚ż╦ż╩ż├żŲż█żĘżżĪŻ ->ūŅ┤¾ź╣źļ®`źūź├ź╚Ģrż╬ź»źķźżźóź¾ź╚╩²żŪįuü²ż╣żļĪŻ ? CPUź│źóż╦īØż╣żļź╣ź▒®`źķźėźĻźŲźŻ ?10ź│źóż╬AźĄ®`źąż╦īØżĘżŲSQLż“░kąążĘż┐Ģr ?100ź│źóż╬BźĄ®`źąż╦īØżĘżŲSQLż“░kąążĘż┐Ģr ż“▒╚▌^ż╣żļż╚Īó10▒Čż╬ź╣źļ®`źūź├ź╚ż╦ż╩ż├żŲż█żĘżżĪŻ ->Ė„CPUź│źó╩²ż╬ūŅ┤¾ź╣źļ®`źūź├ź╚żŪįuü²ż╣żļĪŻ żŽżĖżßż╦
- 4. 4Copyright?2016 NTT corp. All Rights Reserved. PostgreSQL ż╬ Read Scalability żŽĖ─╔ŲżĄżņŠAż▒żŲżżżļ ? ╠žż╦9ŽĄż½żķ┤¾Ę∙ż╩Ė─╔Ų żŽżĖżßż╦ Dilip Kumar: Scalability And Performance Improvements In PostgreSQL 9.6 (PgDay Asia 2016)
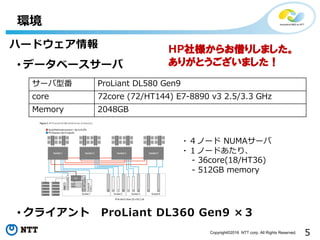
- 5. 5Copyright?2016 NTT corp. All Rights Reserved. ? źŪ®`ź┐ź┘®`ź╣źĄ®`źą ŁhŠ│ źĄ®`źąą═Ę¼ ProLiant DL580 Gen9 core 72core (72/HT144) E7-8890 v3 2.5/3.3 GHz Memory 2048GB ? ź»źķźżźóź¾ź╚ ProLiant DL360 Gen9 Ī┴Ż│ źŽ®`ź╔ź”ź¦źóŪķł¾ ?Ż┤ź╬®`ź╔ NUMAźĄ®`źą ?Ż▒ź╬®`ź╔żóż┐żĻĪó - 36core(18/HT36) - 512GB memory HP╔ńśöż½żķż¬ĮĶżĻżĘż▐żĘż┐ĪŻ żóżĻż¼ż╚ż”ż┤żČżżż▐żĘż┐ŻĪ
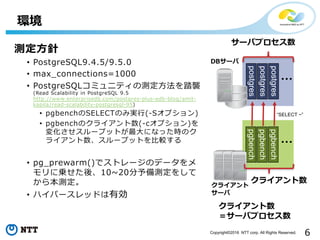
- 6. 6Copyright?2016 NTT corp. All Rights Reserved. ŁhŠ│ £yČ©ĘĮßś ? PostgreSQL9.4.5/9.5.0 ? max_connections=1000 ? PostgreSQLź│ź▀źÕź╦źŲźŻż╬£yČ©ĘĮĘ©ż“╠żęu (Read Scalability in PostgreSQL 9.5 http://www.enterprisedb.com /postgres-plus-edb-blog /amit- kapila/read-scalability-postgresql-95) ? pgbenchż╬SELECTż╬ż▀īgąą(-Sź¬źūźĘźńź¾) ? pgbenchż╬ź»źķźżźóź¾ź╚╩²(-cź¬źūźĘźńź¾)ż“ ēõ╗»żĄż╗ź╣źļ®`źūź├ź╚ż¼ūŅ┤¾ż╦ż╩ż├ż┐Ģrż╬ź» źķźżźóź¾ź╚╩²Īóź╣źļ®`źūź├ź╚ż“▒╚▌^ż╣żļ ? pg_prewarm()żŪź╣ź╚źņ®`źĖż╬źŪ®`ź┐ż“źß źŌźĻż╦ü\ż╗ż┐ßßĪó10~20ĘųėĶéõ£yČ©ż“żĘżŲ ż½żķ▒Š£yČ©ĪŻ ? źŽźżźč®`ź╣źņź├ź╔żŽėąä┐ Ī░SELECT ~Ī▒ pgbench pgbench pgbench ź»źķźżźóź¾ź╚╩² DBźĄ®`źą ź»źķźżźóź¾ź╚ źĄ®`źą postgres postgres postgres źĄ®`źąźūźĒź╗ź╣╩² ź»źķźżźóź¾ź╚╩² ŻĮźĄ®`źąźūźĒź╗ź╣╩² ??? ???
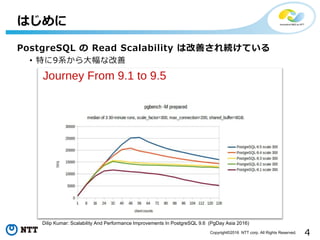
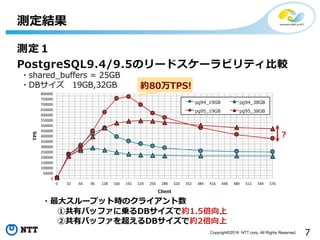
- 7. 7Copyright?2016 NTT corp. All Rights Reserved. £yČ©ĮY╣¹ £yČ©Ż▒ PostgreSQL9.4/9.5ż╬źĻ®`ź╔ź╣ź▒®`źķźėźĻźŲźŻ▒╚▌^ 0 32 64 96 128 160 192 224 256 288 320 352 384 416 448 480 512 544 576 0 50000 100000 150000 200000 250000 300000 350000 400000 450000 500000 550000 600000 650000 700000 750000 800000 Client TPS pg94_19GB pg94_38GB pg95_19GB pg95_38GB ?ūŅ┤¾ź╣źļ®`źūź├ź╚Ģrż╬ź»źķźżźóź¾ź╚╩² ? ?shared_buffers = 25GB ?DBźĄźżź║ 19GB,32GB ó┘╣▓ėąźąź├źšźĪż╦ü\żļDBźĄźżź║żŪ╝s1.5▒ČŽ“╔Ž ó┌╣▓ėąźąź├źšźĪż“│¼ż©żļDBźĄźżź║żŪ╝s2▒ČŽ“╔Ž ╝s80═“TPS!
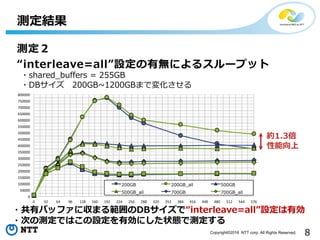
- 8. 8Copyright?2016 NTT corp. All Rights Reserved. £yČ©ĮY╣¹ £yČ©Ż▓ Ī░interleave=allĪ▒įOČ©ż╬ėą¤oż╦żĶżļź╣źļ®`źūź├ź╚ ?shared_buffers = 255GB ?DBźĄźżź║ 200GB~1200GBż▐żŪēõ╗»żĄż╗żļ 0 32 64 96 128 160 192 224 256 288 320 352 384 416 448 480 512 544 576 0 50000 100000 150000 200000 250000 300000 350000 400000 450000 500000 550000 600000 650000 700000 750000 800000 200GB 200GB_all 500GB 500GB_all 700GB 700GB_all 1200GB 1200GB_all ?╣▓ėąźąź├źšźĪż╦ģ¦ż▐żļ╣Āćņż╬DBźĄźżź║żŪĪ░interleave=allĪ▒įOČ©żŽėąä┐ ?┤╬ż╬£yČ©żŪżŽż│ż╬įOČ©ż“ėąä┐ż╦żĘż┐ū┤æBżŪ£yČ©ż╣żļ ╝s1.3▒Č ąį─▄Ž“╔Ž
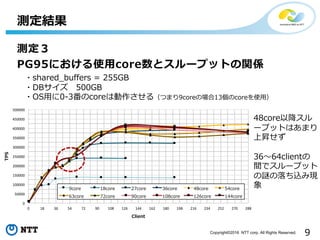
- 9. 9Copyright?2016 NTT corp. All Rights Reserved. £yČ©ĮY╣¹ £yČ©Ż│ PG95ż╦ż¬ż▒żļ╩╣ė├core╩²ż╚ź╣źļ®`źūź├ź╚ż╬ķvéS 0 18 36 54 72 90 108 126 144 162 180 198 216 234 252 270 288 0 50000 100000 150000 200000 250000 300000 350000 400000 450000 500000 Client TPS 9core 18core 27core 36core 48core 54core 63core 72core 90core 108core 126core 144core ?shared_buffers = 255GB ?DBźĄźżź║ 500GB ?OSė├ż╦0-3Ę¼ż╬coreżŽäėū„żĄż╗żļŻ©ż─ż▐żĻ9coreż╬ł÷║Ž13éĆż╬coreż“╩╣ė├Ż® 48coreęįĮĄź╣źļ ®`źūź├ź╚żŽżóż▐żĻ ╔ŽĢNż╗ż║ 36Ī½64clientż╬ ķgżŪź╣źļ®`źūź├ź╚ ż╬ųiż╬┬õż┴▐zż▀¼F Ž¾
- 10. 10Copyright?2016 NTT corp. All Rights Reserved. £yČ©ĮY╣¹ £yČ©Ż│ PG95ż╦ż¬ż▒żļ╩╣ė├core╩²ż╚ź╣źļ®`źūź├ź╚ż╬ķvéS │ÓŻ║Ė„core╩²ż╦ż¬ż▒żļūŅ┤¾ź╣źļ®`źūź├ź╚ ŪÓŻ║Ż▒coreżóż┐żĻż╬ź╣źļ®`źūź├ź╚ 0 2000 4000 6000 8000 10000 12000 0 50000 100000 150000 200000 250000 300000 350000 400000 450000 500000 0 18 36 54 72 90 108 126 144 Ż▒coreżóż┐żĻż╬TPS(ūŅ┤¾TPS/core) ūŅ┤¾TPS ╩╣ė├core╩² ūŅ┤¾TPS ūŅ┤¾TPS / core ?36core(OSė├ź│źó║¼żß40core)ż▐żŪä┐┬╩Ą─ż╦CPUź│źóż“╩╣ė├┐╔
- 11. 11Copyright?2016 NTT corp. All Rights Reserved. ? Read only żŪżŽżóżļżŌż╬ż╬Īó80═“TPSż▐żŪ│÷żļż│ż╚ ż“┤_šJ ? PostgreSQL9.5żŽ9.4ż╚▒╚▌^żĘżŲĪ󟻟ķźżźóź¾ź╚╩²ż¼ Īó╣▓ėąźąź├źšźĪż╦ü\żļDBźĄźżź║żŪ1.5▒ČĪó╣▓ėąźąź├źš źĪż“│¼ż©żļDBźĄźżź║żŪ2▒Čż▐żŪź╣ź▒®`źļż╣żļż│ż╚ż“┤_ šJ ? PostgreSQL9.5żŽ40ź│źó│╠Č╚ż▐żŪź╣ź▒®`źļż╣żļż│ż╚ ż“┤_šJĪŻCPUż“40ź│źó│╠Č╚ż▐żŪä┐┬╩żĶż»╩╣ż©żļĪŻ ż│ż│ż▐żŪż╬ż▐ż╚żß
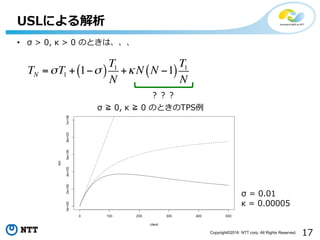
- 12. 12Copyright?2016 NTT corp. All Rights Reserved. USLż╦żĶżļĮŌ╬÷ The Universal Scalability Law (USL) ż╚żŽŻ┐ ? ź│ź¾źįźÕ®`ź┐®`źĘź╣źŲźÓż╬ź╣ź▒®`źķźėźĻźŲźŻż“ źŌźŪźļ╗»ĪóČ©┴┐╗» ? ╠žČ©ż╬źĘź╣źŲźÓż╦ę└żķż║▀mÅĻ┐╔─▄ ? źŽ®`ź╔ź”ź¦źóĪóźĮźšź╚ź”ź¦źóż╦ķvż’żķż║ ź╣ź▒®`źķźėźĻźŲźŻż“įuü²┐╔─▄ įöżĘż»żŽż│ż┴żķż“ęŖżŲŽ┬żĄżżĪŻ [Gun08] Neil J. Gunther. A general theory of computational scalability based on rationalfunctions. CoRR, abs/0808.1431, 2008. http://arxiv.org/pdf/0808.1431v2.pdf
- 13. 13Copyright?2016 NTT corp. All Rights Reserved. USLż╦żĶżļĮŌ╬÷ ? Universal Scalability Law ? Relative Capacity X(N)Ż║Nź»źķźżźóź¾ź╚ż▐ż┐żŽNéĆż╬CPUź│źóĢrż╬ź╣źļ®`źūź├ź╚ X(1)Ż║Ż▒ź»źķźżźóź¾ź╚ż▐ż┐żŽŻ▒CPUź│źóĢrż╬ź╣źļ®`źūź├ź╚ TŻ║äI└ĒĢrķg nŻ║äI└Ēż╣żļź┐ź╣ź»ż╬╩² S(N)Ż║Speedup C N( )= N 1+s N -1( )+kN N -1( ) C N( )= X(N) X(1) = n TN T1 n = T1 TN = S N( )
- 14. 14Copyright?2016 NTT corp. All Rights Reserved. USLż╦żĶżļĮŌ╬÷ ? ź»ź©źĻż╬īgąąīgąąĢrķgż╚”ę,”╩źčźķźß®`ź┐ż╬ķvéS ╔Žėøż╬╩Įż“ż┤ż╦żńż┤ż╦żńż╣żļż╚ C N( )= N 1+s N -1( )+kN N -1( ) C N( ) = T1 TN = T1 sT1 + 1-s( ) T1 N +kN N -1( ) T1 N TN =sT1 + 1-s( ) T1 N +kN N -1( ) T1 N żĶż├żŲĪ󟻟ķźżźóź¾ź╚ż½żķż╬ź»ź©źĻż“NüK┴ążŪäI└ĒżĘż┐ł÷║Žż╬äI└ĒĢrķgżŽĪó
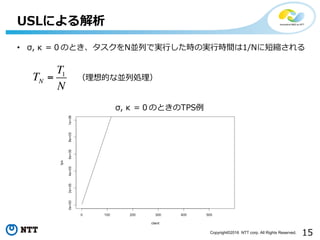
- 15. 15Copyright?2016 NTT corp. All Rights Reserved. USLż╦żĶżļĮŌ╬÷ ? ”ę, ”╩ ŻĮŻ░ż╬ż╚żŁĪóź┐ź╣ź»ż“NüK┴ążŪīgąążĘż┐Ģrż╬īgąąĢrķgżŽ1/Nż╦Č╠┐sżĄżņżļ TN = T1 N Ż©└ĒŽļĄ─ż╩üK┴ąäI└ĒŻ® ”ę, ”╩ ŻĮŻ░ż╬ż╚żŁż╬TPS└²
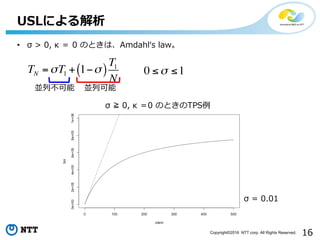
- 16. 16Copyright?2016 NTT corp. All Rights Reserved. USLż╦żĶżļĮŌ╬÷ ”ę ©R 0, ”╩ ŻĮ0 ż╬ż╚żŁż╬TPS└² TN =sT1 + 1-s( ) T1 N ? ”ę > 0, ”╩ ŻĮ 0 ż╬ż╚żŁżŽĪóAmdahlĪ«s lawĪŻ üK┴ą┐╔─▄üK┴ą▓╗┐╔─▄ 0 ?s ?1 ”ę = 0.01
- 17. 17Copyright?2016 NTT corp. All Rights Reserved. USLż╦żĶżļĮŌ╬÷ Ż┐Ż┐Ż┐ ? ”ę > 0, ”╩ > 0 ż╬ż╚żŁżŽĪóĪóĪó TN =sT1 + 1-s( ) T1 N +kN N -1( ) T1 N ”ę ©R 0, ”╩ ©R 0 ż╬ż╚żŁż╬TPS└² ”ę = 0.01 ”╩ = 0.00005
- 18. 18Copyright?2016 NTT corp. All Rights Reserved. USLż╦żĶżļĮŌ╬÷ USLż¼üóČ©żĘżŲżżżļż│ż╚ ? Synchronous Queueing ? ╚½żŲż╬ź»ź©źĻż¼═¼Ģrż╦īgąążĄżņżļż╚üóČ©ĪŻ ? 1ź»ź©źĻżŽäI└ĒżĄżņżļż¼ĪóN-1ź»ź©źĻżŽ┤²ÖCżĘżŲżżżļū┤æBĪŻ ż▐ż┐żŽĪó1CPUź│źóżŽäI└ĒżĘżŲżżżļż¼ĪóN-1CPUź│źóżŽ┤²ÖCżĘżŲżżżļū┤æB ? Ą▒╚╗ż╩ż¼żķĪóīgļHż╬źĘź╣źŲźÓżŪżŽĪóūŅ│§ż╬Nź»ź©źĻż¼═¼Ģrż╦└┤ż┐ż╚żĘżŲżŌ ĪóżĮżņęįĮĄż╬ź»ź©źĻż¼═¼Ģrż╦└┤żļż│ż╚żŽż╩żżĪŻżĶż├żŲĪóīgļHż╬ź╣źļ®`źūź├ ź╚żŽUSLż¼ŽļČ©żĘżŲżżżļéÄżĶżĻ┤¾żŁż»ż╩żļĪŻ ? State-Dependent Service ? M/G/1//Nż╦ż¬żżżŲ Residence Time ż¼źĘź╣źŲźÓż╬ū┤æBż╦ę└┤µż╣żļż╚üóČ© ? żĶżĻ╬’└ĒĄ─ż╩├ĶŽ±żŪżŽĪóĪĖCPUź│źóķgżŪż╬ coherency ż“▒Żż─Ī╣ż╩ż╔ N C2 = N N -1( ) 2 TN =sT1 + 1-s( ) T1 N +kN N -1( ) T1 N ->CPUź│źóż╬ĮM║Žż╗ż╦▒╚└²żĘżŲäI└ĒĢrķgż¼ēł╝ėż╣żļ
- 19. 19Copyright?2016 NTT corp. All Rights Reserved. USLż╦żĶżļĮŌ╬÷ USL ż╚ ”ę, ”╩ ż╬ęŌ╬Č C N( )= N 1+s N -1( )+kN N -1( ) A. Ideal concurrency ”ę, ”╩ ŻĮŻ░ A. Contention-limited ”ę > 0, ”╩ ŻĮ 0 B. Coherency-limited ”ę = 0, ”╩ > 0 C. Worst case ”ę > 0, ”╩ > 0 ”ę ©R 0, ”╩ ©R 0 ż╬ż╚żŁż╬TPS└²
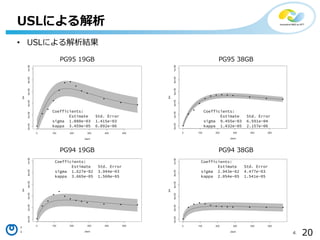
- 20. 20Copyright?2016 NTT corp. All Rights Reserved. USLż╦żĶżļĮŌ╬÷ ? USLż╦żĶżļĮŌ╬÷ĮY╣¹ PG95 19GB PG95 38GB PG94 19GB PG94 38GB Coefficients: Estimate Std. Error sigma 1.080e-03 1.415e-03 kappa 3.459e-05 6.092e-06 Coefficients: Estimate Std. Error sigma 1.627e-02 3.944e-03 kappa 3.665e-05 1.560e-05 Coefficients: Estimate Std. Error sigma 2.943e-02 4.477e-03 kappa 2.054e-05 1.541e-05 Coefficients: Estimate Std. Error sigma 9.455e-03 6.591e-04 kappa 1.432e-05 2.157e-06
- 21. 21Copyright?2016 NTT corp. All Rights Reserved. USLż╦żĶżļĮŌ╬÷ PostgreSQL 9.5 ż╚ 9.4 ż╦ż¬ż▒żļĪó”ę, ”╩ ż╬▒╚▌^ ╣▓ėąźßźŌźĻż╦ü\żļDBźĄźżź║Īó ╣▓ėąźßźŌźĻż╦ü\żķż╩żżDBźĄźż ź║╣▓ż╦ĪóĖé║Žż╦żĶżļź╣źļ®`źū ź├ź╚ż╬Ą═£pż¼┤¾żŁż»£p╔┘żĘżŲ żżżļż½żŌŻ┐ -> LWLockż╬Ė─╔Ų ╣▓ėąźßźŌźĻż╦ü\żķż╩żżDBźĄźż ź║żŪĪóź│źę®`źņź¾źĘż╦żĶżļź╣ źļ®`źūź├ź╚ż╬Ą═£pż¼ČÓ╔┘£p╔┘ żĘżŲżżżļż½żŌŻ┐ ╣▓ėąźßźŌźĻż╦ü\żļDBźĄźżź║żŪ żŽĖ─╔Ųż¼żóż▐żĻż▀żķżņż╩żż 0.E+00 1.E-02 2.E-02 3.E-02 4.E-02 pg95_19GB pg94_19GB pg95_38GB pg94_38GB ”ęŻ║Contention Effect 0.E+00 1.E-05 2.E-05 3.E-05 4.E-05 pg95_19GB pg94_19GB pg95_38GB pg94_38GB ”╩Ż║Coherency Effect
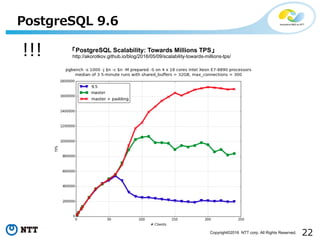
- 22. 22Copyright?2016 NTT corp. All Rights Reserved. PostgreSQL 9.6 ĪĖPostgreSQL Scalability: Towards Millions TPSĪ╣ http://akorotkov.github.io/blog/2016/05/09/scalability-towards-millions-tps/!!!