Practical solutions to implementing "Born Connected" data systems
Download as PPTX, PDF1 like595 views

Presentation in the Earth and Space Science Informatics stream at the 2015 American Geophysical Union Fall Meeting.











































More Related Content
Similar to Practical solutions to implementing "Born Connected" data systems (20)
More from Adam Leadbetter (20)


















Recently uploaded (20)




















Practical solutions to implementing "Born Connected" data systems
- 1. Practical solutions to implementing "Born Connected" data systems Adam Leadbetter, Marine Institute (adam.leadbetter@marine.ie) Justin Buck, British Oceanographic Data Centre Paul Stacey, Institute of Technology Blanchardstown
- 5. ŌĆ£Repositioning data management near data acquisitionŌĆØ Diviacco, Sorribas, Casas Munoz, de Cauwer, Busato, & Scory (2016)
- 7. Semantically Annotate / Connect ASAP! Memory, processing power Power Communications Constrained http://www.techworks.ie/media/cms_page_media/22/TechWorks%20Marine.700x450.jpg
- 8. http://argo.ucsd.edu Sensor Observation Service Observations & Measurements
- 9. http://argo.ucsd.edu Sensor Observation Service Observations & Measurements
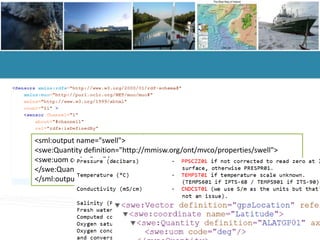
- 10. <sml:output name="swell"> <swe:Quantity definition="http://mmisw.org/ont/mvco/properties/swell"> <swe:uom code="cm"/> </swe:Quantity> </sml:output>
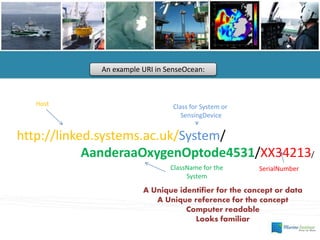
- 11. An example URI in SenseOcean: http://linked.systems.ac.uk/System/ AanderaaOxygenOptode4531/XX34213/ ClassName for the System SerialNumber Class for System or SensingDevice Host A Unique identifier for the concept or data A Unique reference for the concept Computer readable Looks familiar
- 12. Subject Predicate Object <lso:Aanderaa4531OxygenOptodeXXX34> <gr:hasMakeAndModel><lso:Aanderaa4531OxygenOptode> <ssn:onPlatform> < L06:25 > <ssn:hasDeployment> <DeploymentXX6E> < L06:25 > <ssn:inDeployment> <DeploymentXX6E>
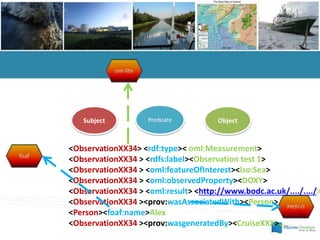
- 13. Subject Predicate Object <ObservationXX34> <rdf:type>< oml:Measurement> <ObservationXX34 > <rdfs:label><Observation test 1> <ObservationXX34 > <oml:featureOfInterest><lso:Sea> <ObservationXX34 > <oml:observedProperty><DOXY> <ObservationXX34 > <oml:result> <http://www.bodc.ac.uk/..../..../> <ObservationXX34 ><prov:wasAssociatedWith><Person> <Person><foaf:name>Alex <ObservationXX34 ><prov:wasgeneratedBy><CruiseXXX>
- 14. SensorML RDF ŌĆó Add a semantic layer on 52 North SOS ŌĆó Through D2RQ ŌĆó Expose some Sensor Descriptions ŌĆó Map them to the relevant ontologies
- 24. Adam Leadbetter, Marine Institute, Ireland adam.leadbetter@marine.ie @AdamLeadbetter https://github.com/IrishMarineInstitute/ sensor-observation-service https://github.com/peterataylor/om-json
Editor's Notes
- #2: Acknowledge: Janet Fredericks @ WHOI Damian Smyth & Rob Fuller @ MI Alexandra Kokinakki @ BODC Born Digital -> Born Semantic -> Born Connected
- #3: Why? Traditionally ŌĆō ocean data has been structured, and particularly, linked post fact
- #4: Why? Traditionally ŌĆō ocean data has been structured, and particularly, linked post fact Gliders, Argo floats, ROVs, seafloor observatories break the sustainability of that model
- #5: Why? Traditionally ŌĆō ocean data has been structured, and particularly, linked post fact Gliders, Argo floats, ROVs, seafloor observatories break the sustainability of that model ShepherdŌĆÖs metaphor Do you have the time to go to Dagobah and take the training with the ŌĆ£Big DataŌĆØ age Lesley Wyborn ŌĆ£Data needs to be ŌĆśBorn ConnectedŌĆÖ to enable Transdisciplinary ScienceŌĆØ ŌĆō and beginning at conceived connected! SoŌĆ”
- #8: Extending the ŌĆ£Born SemanticŌĆØ to ultra-constrained observation environments Achieving ŌĆ£Born SemanticŌĆØ data in an ultra-constrained environment presents more difficulties. Communications may be intermittent, very low bandwidth, data-logger must be highly power efficient etc.. Extending the ŌĆ£Born SemanticŌĆØ to ultra-resource constrained environments There has been a recently flurry of development activity around Internet of Things (IoT) technologies. This has lead to a drive for IoT enabling technologies that presents opportunities to further realise the concept of Born Semantic data, pushing the semantic annotation closer to the data capture point. These technologies are all about ŌĆ£squeezing the bitsŌĆØ reducing storage, processing and communication overhead. Low-power, highly efficient operating systems such as TinyOS and Contiki (among others) provide ŌĆ£powerful enoughŌĆØ capabilities to leverage semantic annotation efforts. Fernandez et al. have recently addressed compression of RDF, with the Header-Dictionary-Triples approach that compresses tuple elements into a dictionary, followed by a compressed representation of triples of dictionary keys. This approach is only applicable to large data sets, which is not an option in a constrained environment. Wiselib TupleStore and RDF provider, provides a suitable solution here as it is a light weight flexible data storage solution. The Constrained Application Protocol (CoAP) is a specialised web ╠²transfer protocol for use with constrained embedded systems and networks. CoAP is designed to easily interface with HTTP for integration with the Web with very low overhead, and simplicity for constrained environments. Although HTTP is the defacto standard for RESTful architectures CoAP. CoAP specifies a minimal subset of REST requests (GET, POST, PUT, and DELETE) it also relies on UDP as a transport protocol while providing reliability with a simple built-in retransmission mechanism and so the communications overhead is small compared to HTTP.
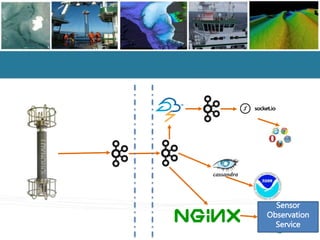
- #10: Ocean Data Interoperability Platform 52N plus others Different encodings for SOS results RESTful URLs for SOS access
- #11: EGU 2014 ŌĆō prototypes in RDFa (CTD); SensorML 1.0 (Qartod 2 OGC ŌĆō now re-funded as X-DOMES; Direct embedding concept ids in file headers (Lake Ellswort Drilling Project) or SWE XML definitions (Q2O). Funding from EU SenseOCEAN, BRIDGES, OpenGovIntelligence Funding from SEAI Onto SenseOCEAN ŌĆō slides from BODC
- #12: First step is a sensor / instrument register Built on Fuseki ŌĆō with custom Java API Live in next few months
- #13: SSN = has some issues with alignment later with O&M, which will be introduced in the next slideŌĆō Simon Cox will go into detailsŌĆ”
- #14: Ideally associated with something like an ORCiD not just the personŌĆÖs name
- #15: We have created the models. But we are still gathering metadata from the manufacturers. So will be able to publish some example sensor descriptions soon enough (couple of months).
- #19: Single machine Distributed processing One-to-one communication Publish-subscribe pattern No fault tolerance Replication, auto-recovery Fixed schema, encoding Schema management, evolvable encoding
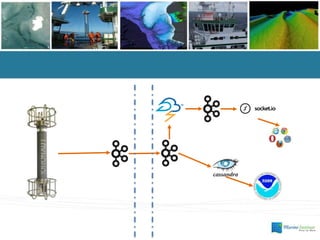
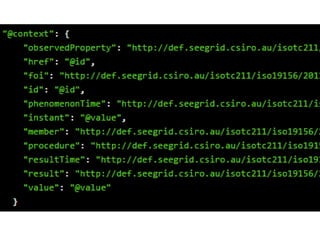
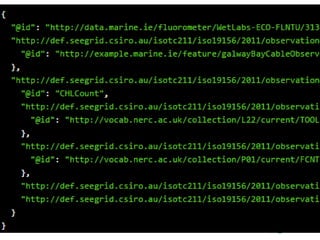
- #22: Simon Cox & Peter Taylor presentation at OGC TC in September 2015 Work ongoing in Ocean Acidification community to use the proposed O&M JSON schema Here is a snapshot from a SOS call to the Galway Bay Cable Observatory
- #24: Adding a JSON-LD context to the output allows us to generate a triple-ified model of the SOS outputŌĆ”