Predictive Analytics - BarCamp Boston 2011
ŌĆó
0 likesŌĆó2,137 views

An overview of the state of the art in predictive analytics technology. Presented at BarCamp Boston 2011.










Predictive Analytics - BarCamp Boston 2011
- 1. predictive analytics! the future of predicting the future Vedant Misra vedant.misra@gmail.com Boston BarCamp 2011
- 2. the big picture We are witnessing a data explosion. "Everywhere you look, the quantity of information in the world is soaring. According to one estimate, mankind created 150 exabytes of data in 2005. This year, it will create 1,200 exabytes." The Data Deluge. The Economist, Feb 25, 2010. P.S. 1 exabyte is 1 million terabytes.
- 3. the big picture We are witnessing a data explosion. "we create as much information* in two days now as we did from the dawn of man through 2003" -Larry Page, CEO, Google *This is mostly lolcats and duckface photos.
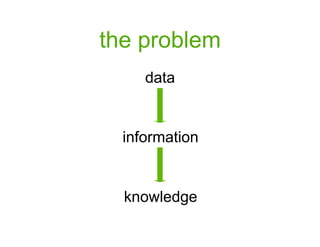
- 4. the problem data information knowledge
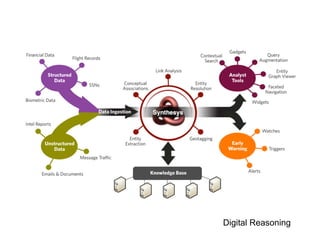
- 5. modus operandi 1.ŌĆłngest data I ŌĆóŌĆł tructured s ŌĆóŌĆł nstructured u 2.ŌĆł igest data D ŌĆóŌĆł LP N ŌĆóŌĆł ntity extraction e 3.ŌĆł pit data back up S ŌĆóŌĆł isualization v ŌĆóŌĆłederated search f
- 6. the state of the art Omniture, Stratify, Jedox, Bime, Kosmix, I2, SpotFire, Quid Scoremind, Birst, Predixion Software, PivotLink, GoodData, Endeca, FSI, Informatica, IBM, Kofax, SPSS, Data Applied, Mathematica, Matlab, Octave, R, Stata, Statistica, ROOT, Geant, Attensity360, Sysomos, SAS, ISS CIDNE, Centrifuge Systems, Prediction Company, CASA, Info Mesa, FreeBase, YouCalc, Inxight
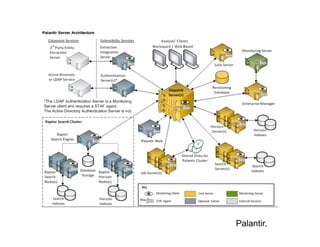
- 7. Palantir.
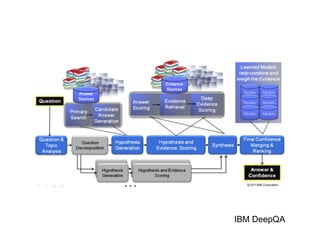
- 9. IBM DeepQA
- 10. ingesting data ŌĆóŌĆł tructured information s ŌĆóŌĆł xplicitly defined format e ŌĆóŌĆł elationships are clear r ŌĆóŌĆł SVs, relational C databases, XLS ŌĆóŌĆł nstructured information u ŌĆóŌĆł o data model n ŌĆóŌĆł ixed text, numbers, m figures ŌĆóŌĆł mails, webpages, e books, health records, call logs, phone recordings, video footage
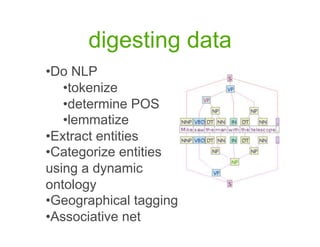
- 11. digesting data ŌĆóŌĆł o NLP D ŌĆóŌĆłokenize t ŌĆóŌĆł etermine POS d ŌĆóŌĆłemmatize l ŌĆóŌĆł xtract entities E ŌĆóŌĆł ategorize entities C using a dynamic ontology ŌĆóŌĆł eographical tagging G ŌĆóŌĆł ssociative net A
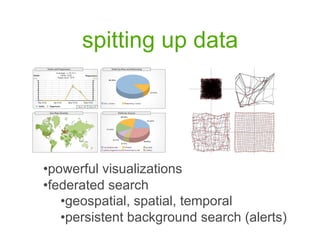
- 12. spitting up data ŌĆóŌĆł owerful visualizations p ŌĆóŌĆłederated search f ŌĆóŌĆł eospatial, spatial, temporal g ŌĆóŌĆł ersistent background search (alerts) p
- 13. complications ŌĆóŌĆł igh-resolution access control h ŌĆóŌĆł ource, date, location, and other s metadata for tracking pedigree and lineage ŌĆóŌĆł dding insight and new data back into a data layer ŌĆóŌĆł ir-gapped networks a ŌĆóŌĆł evisioning databases r ŌĆóŌĆł eal-time hypothesis and intuition r sharing
- 14. what's left? ŌĆóŌĆł eep analytics: platforms that d understand ŌĆóŌĆł eplacing IA with AI r ŌĆóŌĆł ven fancier statistical methods e naive Bayes classifier, support vector machine, kernel estimation, neural networks, k-nearest neighbor, k-means clustering, kernel PCA, hierarchical clustering, linear regression, neural networks, gaussian process regression, principal component analysis, independent component analysis, hidden Markov models, maximum entropy Markov models, Kalman filters, particle filters, Bayesian networks, Markov random fields, bootstrap aggregating, ensemble averaging...
- 15. what's left? ŌĆóŌĆł ore science of prediction: m ŌĆóŌĆł odelling and validation m ŌĆóŌĆł enetic algorithms for finding g symbolic expressions ŌĆóŌĆł hen are systems unpredictable? w ŌĆóŌĆł escribing groups with game d theory ŌĆóŌĆł hen is individual behavior w important?
- 16. thanks!