Preprocessing
1 like711 views

The document outlines the key steps in preprocessing text data: 1. Tokenization breaks text into individual words by removing punctuation and numbers and splitting on spaces. 2. Stop words, like "the" and "an", are removed to focus on meaningful words. 3. Stemming reduces words to their root form using an algorithm like Porter stemming. This groups related words together but does not always find the true root. 4. A vocabulary is created by taking the union of all words from all documents after stemming to prepare for further analysis.
1 of 5




Ad
Recommended
H A N D O U T S F O R E I G N E X C H A N G E
H A N D O U T S F O R E I G N E X C H A N G EJustine Guillerma Garcia
?
An exchange rate is the rate at which one currency can be exchanged for another. It represents the value of one country's currency in terms of another currency. Foreign currencies are treated as commodities that can be bought and sold, with the exchange rate determining the price at which transactions between different currencies occur.Rc - The Plan 9 Shell
Rc - The Plan 9 Shelltwopoint718
?
The document outlines the goals and features of the rc shell from Plan 9 OS, intending to enhance Unix shells with improved parsing and simplified syntax influenced by C. It discusses command usage, variable management, pipelines, and examples demonstrating the functionality of the shell. Key highlights include quoting, argument handling, and function definitions, showcasing rc's unique capabilities compared to traditional shells.¤¤¤«¤Ë¤·¤ĆĄ¨Ąí„Ó»¤ň—ĘË÷¤ą¤ë¤« GXEB #03
¤¤¤«¤Ë¤·¤ĆĄ¨Ąí„Ó»¤ň—ĘË÷¤ą¤ë¤« GXEB #03Yusuke Wada
?
This document discusses an API for searching and retrieving metadata and thumbnails from adult video sites. It provides sample code in Perl for using the API to check if a site is available, search for videos by keyword, and retrieve the thumbnail URL for matched videos. It also lists some example adult sites that can be searched through the API, including Empflix, FC2, Megaporn, and XVideos.Data preprocessing
Data preprocessingksamyMCA
?
This document discusses various techniques for data preprocessing including data cleaning, integration, transformation, reduction, and discretization.
Data cleaning involves filling in missing values, smoothing noisy data, identifying outliers, and resolving inconsistencies. Data integration combines data from multiple sources by integrating schemas and resolving value conflicts. Data transformation techniques include normalization, aggregation, generalization, and smoothing.
Data reduction aims to reduce the volume of data while maintaining similar analytical results. This includes data cube aggregation, dimensionality reduction by removing unimportant attributes, data compression, and discretization which converts continuous attributes to categorical bins.Dsip and its biometrics appln
Dsip and its biometrics applnDr. Vinayak Bharadi
?
This document discusses image processing techniques for biometrics. It describes key stages in digital image processing like image acquisition, enhancement, restoration, segmentation, and compression. It outlines common physiological biometric traits like fingerprints, palm prints, and iris as well as behavioral traits like signature and gait. The document focuses on fingerprint image processing, describing preprocessing techniques including smoothing, normalization, orientation estimation, and segmentation. It provides examples of fingerprint segmentation and core point detection. Finally, it discusses fingerprint enrollment and recognition using wavelet techniques.Feature Matching using SIFT algorithm
Feature Matching using SIFT algorithmSajid Pareeth
?
The document discusses a MATLAB procedure aimed at detecting levelling rods using the SIFT algorithm developed by David Lowe, which involves keypoint extraction and matching. It covers the algorithm's ability to identify invariant features across transformations, including scaling and rotation, utilizing methods like RANSAC to filter outliers. The final results indicate the algorithm's effectiveness, while also noting some limitations regarding image types and transformations.SIFT Algorithm Introduction
SIFT Algorithm IntroductionTruong LD
?
T¨¤i li?u tr¨¬nh b¨¤y v? thu?t to¨˘n SIFT (Scale-Invariant Feature Transform) trong nh?n d?ng ??i t??ng, v?i c¨˘c giai ?o?n ch¨Şnh nh? d¨° t¨¬m c?c tr? c?c b?, tr¨Şch xu?t keypoint, g?n h??ng cho keypoint v¨¤ t?o m? t? cho t?ng keypoint. SIFT ???c ?? xu?t b?i David Lowe, mang l?i hi?u qu? cao nh? v¨¤o vi?c s? d?ng c¨˘c ?i?m ??c tr?ng b?t bi?n. M?c d¨´ c¨® nhi?u ?u ?i?m, SIFT g?p kh¨® kh?n v? t?c ?? tr¨Şch xu?t keypoint v¨¤ chi ph¨Ş ??i s¨˘nh, do ?¨® c?n c?i ti?n trong nghi¨şn c?u ti?p theo.Scale Invariant Feature Tranform
Scale Invariant Feature TranformShanker Naik
?
SIFT extracts distinctive invariant features from images to enable object recognition despite variations in scale, rotation, and illumination. The algorithm involves:
1) Constructing scale-space images from differences of Gaussians to identify keypoints.
2) Detecting stable local extrema across scales as candidate keypoints.
3) Filtering out low contrast keypoints and those poorly localized along edges.
4) Assigning orientations based on local gradient directions.
5) Computing descriptors by sampling gradients around keypoints for matching between images.Scale Invariant feature transform
Scale Invariant feature transformShanker Naik
?
The document describes using the Scale Invariant Feature Transform (SIFT) algorithm for sub-image matching. It discusses rejecting the chain code algorithm and instead using SIFT. It then explains the various steps of SIFT including creating scale-space and Difference of Gaussian pyramids, extrema detection, noise elimination, orientation assignment, descriptor computation, and keypoints matching.SIFT
SIFTNitin Ramchandani
?
The document describes the Scale-invariant feature transform (SIFT) algorithm. It outlines the key steps: 1) constructing scale space by generating blurred images at different scales, 2) calculating difference of Gaussian images to find keypoints, 3) assigning orientations to keypoints, and 4) generating 128-element feature vectors for each keypoint to uniquely describe local image features in a way that is invariant to scale, rotation, and illumination changes. The SIFT algorithm allows for reliable object recognition and image stitching.Face recognition
Face recognitionSatyendra Rajput
?
This document summarizes a student project on face recognition. It begins with an introduction to face recognition, its applications, and common challenges. It then reviews literature on existing face recognition methods and identifies problems related to tilted poses and variations in illumination and expression. The proposed method will work to improve recognition rates under these conditions in two phases - training and testing. The method aims to enhance the preprocessing and feature extraction steps to make the system more robust. A basic flowchart of the proposed approach is provided, and the document concludes with references.fMRI preprocessing steps (in SPM8)
fMRI preprocessing steps (in SPM8)Sunghyon Kyeong
?
The document outlines the preprocessing of fMRI data using statistical parametric mapping (SPM8), emphasizing various steps such as slice timing correction, realignment, coregistration, normalization, and smoothing for both event-related and resting state fMRI analysis. It details the input and output files at each stage and the application of regression for nuisance parameters and functional connectivity analysis. Additionally, the document includes guidelines for performing group-wise analyses and specific GLM specifications in SPM.Face recogntion Using PCA Algorithm
Face recogntion Using PCA Algorithm Ashwini Awatare
?
This document discusses face recognition and the PCA algorithm for face recognition. It begins with an introduction to face recognition and its uses. It then explains the PCA algorithm for face recognition in 6 steps: 1) converting images to vectors, 2) normalizing the vectors, 3) calculating eigenvectors from the normalized vectors, 4) selecting important eigenvectors, 5) representing faces as combinations of eigenvectors, and 6) recognizing faces. It discusses the strengths and weaknesses of face recognition and lists several applications such as access control, law enforcement, and banking.face recognition system using LBP
face recognition system using LBPMarwan H. Noman
?
This document outlines the implementation plan and milestones for a final year project on face recognition using local binary pattern (LBP) features. The project involves enrolling images by extracting LBP histograms and storing them in a matrix. It then tests the matching algorithm on low quality images and evaluates for false and positive matches. The conclusion reflects on lessons learned about LBP algorithms and face recognition challenges with image quality.PCA Based Face Recognition System
PCA Based Face Recognition SystemMd. Atiqur Rahman
?
This document describes a principal component analysis (PCA) based face recognition system. It discusses two main steps: initialization operations on the training faces and recognizing new faces. For training, faces are converted to vectors and normalized. Eigenvectors are calculated from the covariance matrix and used to reduce dimensionality. Each training face can then be represented as a linear combination of eigenvectors. For recognition, a new face is converted to a vector, normalized, projected onto the eigenspace to get its weight vector, and compared to stored weight vectors using Euclidean distance to identify the face.Local binary pattern
Local binary patternInternational Islamic University
?
The document outlines a report on the local binary pattern (LBP) algorithm used in digital image processing, detailing its steps and code for calculating LBP from images. It then discusses the proposed local binary pattern histogram Fourier features (LBP-HF), which provide a rotation-invariant image descriptor that maintains the discriminative nature of LBP histograms for various applications like texture classification and face recognition. The LBP-HF approach asserts advantages over previous methods by computing invariant features globally, preserving the relative distribution of local orientations, and demonstrating effective performance in empirical tests.Face Recognition using PCA-Principal Component Analysis using MATLAB
Face Recognition using PCA-Principal Component Analysis using MATLABSindhi Madhuri
?
PCA is used for face recognition. It involves calculating eigenvectors from a training set of face images to define a feature space called "eigenfaces". A new face is recognized by projecting it onto this space and comparing to existing faces. PCA works by identifying directions of maximum variance in the training data, capturing the most important information about faces with fewer vectors. Potential applications include identification, security, and human-computer interaction. However, it is sensitive to changes in lighting and expression.face recognition system using LBP
face recognition system using LBPMarwan H. Noman
?
1) The document discusses a final year project on face recognition using local features such as Gabor and LBP. 2) It reviews literature on biometrics and common face recognition algorithms like PCA, LDA, and LBP. 3) The methodology section explains how LBP works by comparing pixel values to label images and extracting histograms to represent facial features.Image pre processing
Image pre processingAshish Kumar
?
Image pre-processing involves operations on images to improve image data by suppressing distortions or enhancing features. There are four categories of pre-processing methods based on pixel neighborhood size used: pixel brightness transformations, geometric transformations, local neighborhood methods, and global image restoration. Pre-processing aims to correct degradations by using prior knowledge about the degradation, image acquisition device, or objects in the image. Common pre-processing methods include brightness and geometric transformations as well as brightness interpolation when re-sampling images.Information retrieval
Information retrievalUjjawal
?
The document discusses various natural language processing techniques including tokenization, stop word removal, stemming, lemmatization, part-of-speech tagging, and parsing. Tokenization breaks text into tokens. Stop words are extremely common words that provide minimal help in document selection. Stemming chops word endings while lemmatization returns the base form. Part-of-speech tagging assigns linguistic categories to words. Parsing analyzes sentences into syntactic constituents shown in a parse tree.NLP WITH NA?VE BAYES CLASSIFIER (1).pptx
NLP WITH NA?VE BAYES CLASSIFIER (1).pptxrohithprabhas1
?
This document discusses using Naive Bayes classifiers for text classification with natural language processing. It describes text classification, natural language processing, and how preprocessing steps like cleaning, tokenization, and normalization are used to transform text into feature vectors for classification with algorithms like Naive Bayes. The key steps covered are data cleaning, tokenization, stopword removal, stemming/lemmatization, and representing tokens as bag-of-words feature vectors for classification.Text processing_the_university_of_azad_kashmir
Text processing_the_university_of_azad_kashmirmh187782
?
The document discusses the basics of natural language processing (NLP) using two libraries: Spacy and NLTK. It highlights Spacy's efficiency in NLP tasks while noting that it lacks options for algorithm selection and certain pre-created models, which NLTK provides but at a slower pace. The document covers fundamental NLP concepts such as tokenization, stemming, and lemmatization, and outlines how to use both libraries effectively for various tasks.Text Analysis Operations using NLTK.pptx
Text Analysis Operations using NLTK.pptxdevamrana27
?
The document provides an overview of text analysis operations using the Natural Language Toolkit (NLTK), a comprehensive Python library for natural language processing. It covers essential functions such as tokenization, part-of-speech tagging, stemming, lemmatization, frequency distribution, and named entity recognition, along with their implementations. The document illustrates these concepts with code examples and practical applications in text analysis.Concepts of NLP.pptx
Concepts of NLP.pptxJudesharp1
?
This document provides an overview of key concepts in natural language processing (NLP). It discusses how NLP breaks language problems into smaller pieces to simplify complexity and uses AI to process each piece. A corpus is defined as a large collection of machine-readable text documents. Key NLP techniques described include text normalization, sentence segmentation, tokenization, and removal of stopwords, special characters, and numbers to focus on meaningful terms. Stemming and lemmatization are discussed as processes to extract word roots by removing affixes.Text Pre-Processing Techniques in Natural Language Processing: A Review
Text Pre-Processing Techniques in Natural Language Processing: A ReviewIRJET Journal
?
This document provides a review of text pre-processing techniques in natural language processing. It discusses common text pre-processing steps like tokenization, stemming, lemmatization and removing stopwords. The document also outlines the typical order these steps should be performed in, and provides examples of each technique. It concludes that pre-processing helps structure text data to design efficient models and that the choice of techniques depends on the specific NLP problem and language being analyzed.Information retrieval chapter 2-Text Operations.ppt
Information retrieval chapter 2-Text Operations.pptSamuelKetema1
?
This document discusses text operations for information retrieval systems, including tokenization, stemming, and removing stop words. It explains that tokenization breaks text into discrete tokens or words. Stemming reduces words to their root form by removing affixes like prefixes and suffixes. Stop words, which are very common words like "the" and "of", are filtered out since they provide little meaning. The goal of these text operations is to select more meaningful index terms to represent document contents for retrieval tasks.Natural Language Processing in Artificial intelligence
Natural Language Processing in Artificial intelligenceraghu19136
?
NLP, or natural language processing, is a technique used to translate human language for machines. It combines computational linguistics with statistical, machine learning, and deep learning models to process spoken or written language. Common NLP tasks include predictive text, part-of-speech tagging, email filtering, sentiment analysis, language translation, and data analysis. Text preprocessing techniques like tokenization, stemming, lemmatization, removing stop words, and bag-of-words modeling are used to prepare text for machine learning algorithms. TF-IDF is used to calculate how important a term is to a document in a collection. Word embeddings represent words as vectors that can be used in machine learning models. The Python module Textblob performs basic NLP tasksstemming and tokanization in corpus.pptx
stemming and tokanization in corpus.pptxAthar Baig
?
The document discusses the processes of tokenization and stemming in text mining, emphasizing their importance for tasks like tagging and spam detection. It highlights the complexities involved in managing data and outlines the steps necessary for effective preprocessing, including feature extraction and stop word removal. The study concludes with the success of a naive Bayesian classifier anti-spam engine, achieving high accuracy rates and suggesting avenues for further research in multilingual applications.More Related Content
Viewers also liked (12)
Scale Invariant feature transform
Scale Invariant feature transformShanker Naik
?
The document describes using the Scale Invariant Feature Transform (SIFT) algorithm for sub-image matching. It discusses rejecting the chain code algorithm and instead using SIFT. It then explains the various steps of SIFT including creating scale-space and Difference of Gaussian pyramids, extrema detection, noise elimination, orientation assignment, descriptor computation, and keypoints matching.SIFT
SIFTNitin Ramchandani
?
The document describes the Scale-invariant feature transform (SIFT) algorithm. It outlines the key steps: 1) constructing scale space by generating blurred images at different scales, 2) calculating difference of Gaussian images to find keypoints, 3) assigning orientations to keypoints, and 4) generating 128-element feature vectors for each keypoint to uniquely describe local image features in a way that is invariant to scale, rotation, and illumination changes. The SIFT algorithm allows for reliable object recognition and image stitching.Face recognition
Face recognitionSatyendra Rajput
?
This document summarizes a student project on face recognition. It begins with an introduction to face recognition, its applications, and common challenges. It then reviews literature on existing face recognition methods and identifies problems related to tilted poses and variations in illumination and expression. The proposed method will work to improve recognition rates under these conditions in two phases - training and testing. The method aims to enhance the preprocessing and feature extraction steps to make the system more robust. A basic flowchart of the proposed approach is provided, and the document concludes with references.fMRI preprocessing steps (in SPM8)
fMRI preprocessing steps (in SPM8)Sunghyon Kyeong
?
The document outlines the preprocessing of fMRI data using statistical parametric mapping (SPM8), emphasizing various steps such as slice timing correction, realignment, coregistration, normalization, and smoothing for both event-related and resting state fMRI analysis. It details the input and output files at each stage and the application of regression for nuisance parameters and functional connectivity analysis. Additionally, the document includes guidelines for performing group-wise analyses and specific GLM specifications in SPM.Face recogntion Using PCA Algorithm
Face recogntion Using PCA Algorithm Ashwini Awatare
?
This document discusses face recognition and the PCA algorithm for face recognition. It begins with an introduction to face recognition and its uses. It then explains the PCA algorithm for face recognition in 6 steps: 1) converting images to vectors, 2) normalizing the vectors, 3) calculating eigenvectors from the normalized vectors, 4) selecting important eigenvectors, 5) representing faces as combinations of eigenvectors, and 6) recognizing faces. It discusses the strengths and weaknesses of face recognition and lists several applications such as access control, law enforcement, and banking.face recognition system using LBP
face recognition system using LBPMarwan H. Noman
?
This document outlines the implementation plan and milestones for a final year project on face recognition using local binary pattern (LBP) features. The project involves enrolling images by extracting LBP histograms and storing them in a matrix. It then tests the matching algorithm on low quality images and evaluates for false and positive matches. The conclusion reflects on lessons learned about LBP algorithms and face recognition challenges with image quality.PCA Based Face Recognition System
PCA Based Face Recognition SystemMd. Atiqur Rahman
?
This document describes a principal component analysis (PCA) based face recognition system. It discusses two main steps: initialization operations on the training faces and recognizing new faces. For training, faces are converted to vectors and normalized. Eigenvectors are calculated from the covariance matrix and used to reduce dimensionality. Each training face can then be represented as a linear combination of eigenvectors. For recognition, a new face is converted to a vector, normalized, projected onto the eigenspace to get its weight vector, and compared to stored weight vectors using Euclidean distance to identify the face.Local binary pattern
Local binary patternInternational Islamic University
?
The document outlines a report on the local binary pattern (LBP) algorithm used in digital image processing, detailing its steps and code for calculating LBP from images. It then discusses the proposed local binary pattern histogram Fourier features (LBP-HF), which provide a rotation-invariant image descriptor that maintains the discriminative nature of LBP histograms for various applications like texture classification and face recognition. The LBP-HF approach asserts advantages over previous methods by computing invariant features globally, preserving the relative distribution of local orientations, and demonstrating effective performance in empirical tests.Face Recognition using PCA-Principal Component Analysis using MATLAB
Face Recognition using PCA-Principal Component Analysis using MATLABSindhi Madhuri
?
PCA is used for face recognition. It involves calculating eigenvectors from a training set of face images to define a feature space called "eigenfaces". A new face is recognized by projecting it onto this space and comparing to existing faces. PCA works by identifying directions of maximum variance in the training data, capturing the most important information about faces with fewer vectors. Potential applications include identification, security, and human-computer interaction. However, it is sensitive to changes in lighting and expression.face recognition system using LBP
face recognition system using LBPMarwan H. Noman
?
1) The document discusses a final year project on face recognition using local features such as Gabor and LBP. 2) It reviews literature on biometrics and common face recognition algorithms like PCA, LDA, and LBP. 3) The methodology section explains how LBP works by comparing pixel values to label images and extracting histograms to represent facial features.Image pre processing
Image pre processingAshish Kumar
?
Image pre-processing involves operations on images to improve image data by suppressing distortions or enhancing features. There are four categories of pre-processing methods based on pixel neighborhood size used: pixel brightness transformations, geometric transformations, local neighborhood methods, and global image restoration. Pre-processing aims to correct degradations by using prior knowledge about the degradation, image acquisition device, or objects in the image. Common pre-processing methods include brightness and geometric transformations as well as brightness interpolation when re-sampling images.Similar to Preprocessing (17)
Information retrieval
Information retrievalUjjawal
?
The document discusses various natural language processing techniques including tokenization, stop word removal, stemming, lemmatization, part-of-speech tagging, and parsing. Tokenization breaks text into tokens. Stop words are extremely common words that provide minimal help in document selection. Stemming chops word endings while lemmatization returns the base form. Part-of-speech tagging assigns linguistic categories to words. Parsing analyzes sentences into syntactic constituents shown in a parse tree.NLP WITH NA?VE BAYES CLASSIFIER (1).pptx
NLP WITH NA?VE BAYES CLASSIFIER (1).pptxrohithprabhas1
?
This document discusses using Naive Bayes classifiers for text classification with natural language processing. It describes text classification, natural language processing, and how preprocessing steps like cleaning, tokenization, and normalization are used to transform text into feature vectors for classification with algorithms like Naive Bayes. The key steps covered are data cleaning, tokenization, stopword removal, stemming/lemmatization, and representing tokens as bag-of-words feature vectors for classification.Text processing_the_university_of_azad_kashmir
Text processing_the_university_of_azad_kashmirmh187782
?
The document discusses the basics of natural language processing (NLP) using two libraries: Spacy and NLTK. It highlights Spacy's efficiency in NLP tasks while noting that it lacks options for algorithm selection and certain pre-created models, which NLTK provides but at a slower pace. The document covers fundamental NLP concepts such as tokenization, stemming, and lemmatization, and outlines how to use both libraries effectively for various tasks.Text Analysis Operations using NLTK.pptx
Text Analysis Operations using NLTK.pptxdevamrana27
?
The document provides an overview of text analysis operations using the Natural Language Toolkit (NLTK), a comprehensive Python library for natural language processing. It covers essential functions such as tokenization, part-of-speech tagging, stemming, lemmatization, frequency distribution, and named entity recognition, along with their implementations. The document illustrates these concepts with code examples and practical applications in text analysis.Concepts of NLP.pptx
Concepts of NLP.pptxJudesharp1
?
This document provides an overview of key concepts in natural language processing (NLP). It discusses how NLP breaks language problems into smaller pieces to simplify complexity and uses AI to process each piece. A corpus is defined as a large collection of machine-readable text documents. Key NLP techniques described include text normalization, sentence segmentation, tokenization, and removal of stopwords, special characters, and numbers to focus on meaningful terms. Stemming and lemmatization are discussed as processes to extract word roots by removing affixes.Text Pre-Processing Techniques in Natural Language Processing: A Review
Text Pre-Processing Techniques in Natural Language Processing: A ReviewIRJET Journal
?
This document provides a review of text pre-processing techniques in natural language processing. It discusses common text pre-processing steps like tokenization, stemming, lemmatization and removing stopwords. The document also outlines the typical order these steps should be performed in, and provides examples of each technique. It concludes that pre-processing helps structure text data to design efficient models and that the choice of techniques depends on the specific NLP problem and language being analyzed.Information retrieval chapter 2-Text Operations.ppt
Information retrieval chapter 2-Text Operations.pptSamuelKetema1
?
This document discusses text operations for information retrieval systems, including tokenization, stemming, and removing stop words. It explains that tokenization breaks text into discrete tokens or words. Stemming reduces words to their root form by removing affixes like prefixes and suffixes. Stop words, which are very common words like "the" and "of", are filtered out since they provide little meaning. The goal of these text operations is to select more meaningful index terms to represent document contents for retrieval tasks.Natural Language Processing in Artificial intelligence
Natural Language Processing in Artificial intelligenceraghu19136
?
NLP, or natural language processing, is a technique used to translate human language for machines. It combines computational linguistics with statistical, machine learning, and deep learning models to process spoken or written language. Common NLP tasks include predictive text, part-of-speech tagging, email filtering, sentiment analysis, language translation, and data analysis. Text preprocessing techniques like tokenization, stemming, lemmatization, removing stop words, and bag-of-words modeling are used to prepare text for machine learning algorithms. TF-IDF is used to calculate how important a term is to a document in a collection. Word embeddings represent words as vectors that can be used in machine learning models. The Python module Textblob performs basic NLP tasksstemming and tokanization in corpus.pptx
stemming and tokanization in corpus.pptxAthar Baig
?
The document discusses the processes of tokenization and stemming in text mining, emphasizing their importance for tasks like tagging and spam detection. It highlights the complexities involved in managing data and outlines the steps necessary for effective preprocessing, including feature extraction and stop word removal. The study concludes with the success of a naive Bayesian classifier anti-spam engine, achieving high accuracy rates and suggesting avenues for further research in multilingual applications.overview of natural language processing concepts
overview of natural language processing conceptsnazimsattar
?
the basic concepts of NLP related to different terminologies are discussedNLP Msc Computer science S2 Kerala University
NLP Msc Computer science S2 Kerala Universityvineethpradeep50
?
The document discusses text preprocessing in Natural Language Processing (NLP), highlighting its importance in preparing raw text data for analysis by cleaning, normalizing, and tokenizing it. Key preprocessing steps include tokenization, stop word removal, stemming, and lemmatization, all aimed at improving model accuracy and reducing data complexity. Various tokenization methods and use cases in applications like search engines, machine translation, and chatbots are also detailed.01_Unit_2 (1).pptx kjnjnlknknkjnnnm kmn n
01_Unit_2 (1).pptx kjnjnlknknkjnnnm kmn nBharathRoyal11
?
The document discusses the importance of word frequencies and stop words in text analysis, highlighting their roles in natural language processing. It explains techniques such as tokenization, bag-of-words representation, stemming, and lemmatization, which are fundamental for processing and analyzing textual data accurately. The final representation aids in various applications like sentiment analysis and information retrieval by transforming unstructured text into a structured numerical format.NLP Concepts detail explained in details.pptx
NLP Concepts detail explained in details.pptxFaizRahman56
?
The document discusses key concepts in natural language processing (NLP), focusing on techniques such as regular expressions, bag-of-words models, stemming, lemmatization, phonetic hashing, and part-of-speech tagging. It also covers probabilistic context-free grammars and parsing methods, including the use of hidden Markov models in NLP tasks. Additionally, it provides examples and explanations of various algorithms and tools used in machine learning applications related to text processing.learn about text preprocessing nip using nltk
learn about text preprocessing nip using nltken21cs301047
?
The document provides an extensive overview of text preprocessing techniques, focusing on tokenization, lemmatization, and part-of-speech tagging in the context of natural language processing and information retrieval. It discusses the significance of documents as indexed units and the various challenges involved in processing text, including the intricacies of tokenization and normalization. Additionally, it covers the importance of part-of-speech tagging and the approaches used to disambiguate word classes within text.Stemming And Lemmatization Tutorial | Natural Language Processing (NLP) With ...
Stemming And Lemmatization Tutorial | Natural Language Processing (NLP) With ...Edureka!
?
The document provides an overview of natural language processing (NLP) and its components, including text mining, stemming, and lemmatization. It highlights the processes of stemming, which reduces words to their root forms, and lemmatization, which groups inflected forms of a word into their base form. Applications of these techniques include sentiment analysis and document clustering.AM4TM_WS22_Practice_01_NLP_Basics.pdf
AM4TM_WS22_Practice_01_NLP_Basics.pdfmewajok782
?
The document provides an overview of natural language processing (NLP), defining it as a field that enables computers to understand and analyze human language. It outlines the typical NLP workflow, including data gathering, text preprocessing, and various downstream tasks like classification and text generation. Additional sections detail specific preprocessing techniques such as tokenization, stemming, and lemmatization, as well as resources for starting NLP projects using Python.Ad
Recently uploaded (20)
FME for Good: Integrating Multiple Data Sources with APIs to Support Local Ch...
FME for Good: Integrating Multiple Data Sources with APIs to Support Local Ch...Safe Software
?
Have-a-skate-with-Bob (HASB-KC) is a local charity that holds two Hockey Tournaments every year to raise money in the fight against Pancreatic Cancer. The FME Form software is used to integrate and exchange data via API, between Google Forms, Google Sheets, Stripe payments, SmartWaiver, and the GoDaddy email marketing tools to build a grass-roots Customer Relationship Management (CRM) system for the charity. The CRM is used to communicate effectively and readily with the participants of the hockey events and most importantly the local area sponsors of the event. Communication consists of a BLOG used to inform participants of event details including, the ever-important team rosters. Funds raised by these events are used to support families in the local area to fight cancer and support PanCan research efforts to find a cure against this insidious disease. FME Form removes the tedium and error-prone manual ETL processes against these systems into 1 or 2 workbenches that put the data needed at the fingertips of the event organizers daily freeing them to work on outreach and marketing of the events in the community.FIDO Seminar: New Data: Passkey Adoption in the Workforce.pptx
FIDO Seminar: New Data: Passkey Adoption in the Workforce.pptxFIDO Alliance
?
FIDO Seminar: New Data: Passkey Adoption in the WorkforceEdge-banding-machines-edgeteq-s-200-en-.pdf
Edge-banding-machines-edgeteq-s-200-en-.pdfAmirStern2
?
????? ????? ??????? ??????? ????? ?? ?????? (?????? ?????).
?????? ????? ????? ?? ????, ?? ???? ??? ¨C 3 ?"? ????? ???? ?? 40 ?"?. ??? ?????? ?????? ?? ?????, ??????? ???????? ????????? ??? ??????? ???????.OpenACC and Open Hackathons Monthly Highlights June 2025
OpenACC and Open Hackathons Monthly Highlights June 2025OpenACC
?
The OpenACC organization focuses on enhancing parallel computing skills and advancing interoperability in scientific applications through hackathons and training. The upcoming 2025 Open Accelerated Computing Summit (OACS) aims to explore the convergence of AI and HPC in scientific computing and foster knowledge sharing. This year's OACS welcomes talk submissions from a variety of topics, from Using Standard Language Parallelism to Computer Vision Applications. The document also highlights several open hackathons, a call to apply for NVIDIA Academic Grant Program and resources for optimizing scientific applications using OpenACC directives.No-Code Workflows for CAD & 3D Data: Scaling AI-Driven Infrastructure
No-Code Workflows for CAD & 3D Data: Scaling AI-Driven InfrastructureSafe Software
?
When projects depend on fast, reliable spatial data, every minute counts.
AI Clearing needed a faster way to handle complex spatial data from drone surveys, CAD designs and 3D project models across construction sites. With FME Form, they built no-code workflows to clean, convert, integrate, and validate dozens of data formats ¨C cutting analysis time from 5 hours to just 30 minutes.
Join us, our partner Globema, and customer AI Clearing to see how they:
-Automate processing of 2D, 3D, drone, spatial, and non-spatial data
-Analyze construction progress 10x faster and with fewer errors
-Handle diverse formats like DWG, KML, SHP, and PDF with ease
-Scale their workflows for international projects in solar, roads, and pipelines
If you work with complex data, join us to learn how to optimize your own processes and transform your results with FME.Enabling BIM / GIS integrations with Other Systems with FME
Enabling BIM / GIS integrations with Other Systems with FMESafe Software
?
Jacobs has successfully utilized FME to tackle the complexities of integrating diverse data sources in a confidential $1 billion campus improvement project. The project aimed to create a comprehensive digital twin by merging Building Information Modeling (BIM) data, Construction Operations Building Information Exchange (COBie) data, and various other data sources into a unified Geographic Information System (GIS) platform. The challenge lay in the disparate nature of these data sources, which were siloed and incompatible with each other, hindering efficient data management and decision-making processes.
To address this, Jacobs leveraged FME to automate the extraction, transformation, and loading (ETL) of data between ArcGIS Indoors and IBM Maximo. This process ensured accurate transfer of maintainable asset and work order data, creating a comprehensive 2D and 3D representation of the campus for Facility Management. FME's server capabilities enabled real-time updates and synchronization between ArcGIS Indoors and Maximo, facilitating automatic updates of asset information and work orders. Additionally, Survey123 forms allowed field personnel to capture and submit data directly from their mobile devices, triggering FME workflows via webhooks for real-time data updates. This seamless integration has significantly enhanced data management, improved decision-making processes, and ensured data consistency across the project lifecycle.High Availability On-Premises FME Flow.pdf
High Availability On-Premises FME Flow.pdfSafe Software
?
FME Flow is a highly robust tool for transforming data both automatically and by user-initiated workflows. At the Finnish telecommunications company Elisa, FME Flow serves processes and internal stakeholders that require 24/7 availability from underlying systems, while imposing limitations on the use of cloud based systems. In response to these business requirements, Elisa has implemented a high-availability on-premises setup of FME Flow, where all components of the system have been duplicated or clustered. The goal of the presentation is to provide insights into the architecture behind the high-availability functionality. The presentation will show in basic technical terms how the different parts of the system work together. Basic level understanding of IT technologies is required to understand the technical portion of the presentation, namely understanding the purpose of the following components: load balancer, FME Flow host nodes, FME Flow worker nodes, network file storage drives, databases, and external authentication services. The presentation will also outline our lessons learned from the high-availability project, both benefits and challenges to consider.Reducing Conflicts and Increasing Safety Along the Cycling Networks of East-F...
Reducing Conflicts and Increasing Safety Along the Cycling Networks of East-F...Safe Software
?
In partnership with the Belgian Province of East-Flanders this project aimed to reduce conflicts and increase safety along a cycling route between the cities of Oudenaarde and Ghent. To achieve this goal, the current cycling network data needed some extra key information, including: Speed limits for segments, Access restrictions for different users (pedestrians, cyclists, motor vehicles, etc.), Priority rules at intersections. Using a 360ˇă camera and GPS mounted on a measuring bicycle, we collected images of traffic signs and ground markings along the cycling lanes building up mobile mapping data. Image recognition technologies identified the road signs, creating a dataset with their locations and codes. The data processing entailed three FME workspaces. These included identifying valid intersections with other networks (e.g., roads, railways), creating a topological network between segments and intersections and linking road signs to segments and intersections based on proximity and orientation. Additional features, such as speed zones, inheritance of speed and access to neighbouring segments were also implemented to further enhance the data. The final results were visualized in ArcGIS, enabling analysis for the end users. The project provided them with key insights, including statistics on accessible road segments, speed limits, and intersection priorities. These will make the cycling paths more safe and uniform, by reducing conflicts between users.FIDO Seminar: Evolving Landscape of Post-Quantum Cryptography.pptx
FIDO Seminar: Evolving Landscape of Post-Quantum Cryptography.pptxFIDO Alliance
?
FIDO Seminar: Evolving Landscape of Post-Quantum Cryptographyˇ°Why ItˇŻs Critical to Have an Integrated Development Methodology for Edge AI,...
ˇ°Why ItˇŻs Critical to Have an Integrated Development Methodology for Edge AI,...Edge AI and Vision Alliance
?
For the full video of this presentation, please visit: https://www.edge-ai-vision.com/2025/06/why-its-critical-to-have-an-integrated-development-methodology-for-edge-ai-a-presentation-from-lattice-semiconductor/
Sreepada Hegade, Director of ML Systems and Software at Lattice Semiconductor, presents the ˇ°Why ItˇŻs Critical to Have an Integrated Development Methodology for Edge AIˇ± tutorial at the May 2025 Embedded Vision Summit.
The deployment of neural networks near sensors brings well-known advantages such as lower latency, privacy and reduced overall system costˇŞbut also brings significant challenges that complicate development. These challenges can be addressed effectively by choosing the right solution and design methodology. The low-power FPGAs from Lattice are well poised to enable efficient edge implementation of models, while LatticeˇŻs proven development methodology helps to mitigate the challenges and risks associated with edge model deployment.
In this presentation, Hegade explains the importance of an integrated framework that tightly consolidates different aspects of edge AI development, including training, quantization of networks for edge deployment, integration with sensors and inferencing. He also illustrates how LatticeˇŻs simplified tool flow helps to achieve the best trade-off between power, performance and efficiency using low-power FPGAs for edge deployment of various AI workloads.ˇ°Addressing Evolving AI Model Challenges Through Memory and Storage,ˇ± a Prese...
ˇ°Addressing Evolving AI Model Challenges Through Memory and Storage,ˇ± a Prese...Edge AI and Vision Alliance
?
For the full video of this presentation, please visit: https://www.edge-ai-vision.com/2025/06/addressing-evolving-ai-model-challenges-through-memory-and-storage-a-presentation-from-micron/
Wil Florentino, Senior Segment Marketing Manager at Micron, presents the ˇ°Addressing Evolving AI Model Challenges Through Memory and Storageˇ± tutorial at the May 2025 Embedded Vision Summit.
In the fast-changing world of artificial intelligence, the industry is deploying more AI compute at the edge. But the growing diversity and data footprint of transformers and models such as large language models and large multimodal models puts a spotlight on memory performance and data storage capacity as key bottlenecks. Enabling the full potential of AI in industries such as manufacturing, automotive, robotics and transportation will require us to find efficient ways to deploy this new generation of complex models.
In this presentation, Florentino explores how memory and storage are responding to this need and solving complex issues in the AI market. He examines the storage capacity and memory bandwidth requirements of edge AI use cases ranging from tiny devices with severe cost and power constraints to edge servers, and he explains how new memory technologies such as LPDDR5, LPCAMM2 and multi-port SSDs are helping system developers to meet these challenges.MuleSoft for AgentForce : Topic Center and API Catalog
MuleSoft for AgentForce : Topic Center and API Catalogshyamraj55
?
This presentation dives into how MuleSoft empowers AgentForce with organized API discovery and streamlined integration using Topic Center and the API Catalog. Learn how these tools help structure APIs around business needs, improve reusability, and simplify collaboration across teams. Ideal for developers, architects, and business stakeholders looking to build a connected and scalable API ecosystem within AgentForce.Crypto Super 500 - 14th Report - June2025.pdf
Crypto Super 500 - 14th Report - June2025.pdfStephen Perrenod
?
This OrionX's 14th semi-annual report on the state of the cryptocurrency mining market. The report focuses on Proof-of-Work cryptocurrencies since those use substantial supercomputer power to mint new coins and encode transactions on their blockchains. Only two make the cut this time, Bitcoin with $18 billion of annual economic value produced and Dogecoin with $1 billion. Bitcoin has now reached the Zettascale with typical hash rates of 0.9 Zettahashes per second. Bitcoin is powered by the world's largest decentralized supercomputer in a continuous winner take all lottery incentive network.The State of Web3 Industry- Industry Report
The State of Web3 Industry- Industry ReportLiveplex
?
Web3 is poised for mainstream integration by 2030, with decentralized applications potentially reaching billions of users through improved scalability, user-friendly wallets, and regulatory clarity. Many forecasts project trillions of dollars in tokenized assets by 2030 , integration of AI, IoT, and Web3 (e.g. autonomous agents and decentralized physical infrastructure), and the possible emergence of global interoperability standards. Key challenges going forward include ensuring security at scale, preserving decentralization principles under regulatory oversight, and demonstrating tangible consumer value to sustain adoption beyond speculative cycles.Mastering AI Workflows with FME - Peak of Data & AI 2025
Mastering AI Workflows with FME - Peak of Data & AI 2025Safe Software
?
Harness the full potential of AI with FME: From creating high-quality training data to optimizing models and utilizing results, FME supports every step of your AI workflow. Seamlessly integrate a wide range of models, including those for data enhancement, forecasting, image and object recognition, and large language models. Customize AI models to meet your exact needs with FMEˇŻs powerful tools for training, optimization, and seamless integrationDown the Rabbit Hole ¨C Solving 5 Training Roadblocks
Down the Rabbit Hole ¨C Solving 5 Training RoadblocksRustici Software
?
Feeling stuck in the Matrix of your training technologies? YouˇŻre not alone. Managing your training catalog, wrangling LMSs and delivering content across different tools and audiences can feel like dodging digital bullets. At some point, you hit a fork in the road: Keep patching things up as issues pop upˇ or follow the rabbit hole to the root of the problems.
Good news, weˇŻve already been down that rabbit hole. Peter Overton and Cameron Gray of Rustici Software are here to share what we found. In this webinar, weˇŻll break down 5 training roadblocks in delivery and management and show you how theyˇŻre easier to fix than you might think.Viral>Wondershare Filmora 14.5.18.12900 Crack Free Download
Viral>Wondershare Filmora 14.5.18.12900 Crack Free DownloadPuppy jhon
?
? ???COPY & PASTE LINK??? ? ?? https://drfiles.net/
Wondershare Filmora Crack is a user-friendly video editing software designed for both beginners and experienced users.
June Patch Tuesday
June Patch TuesdayIvanti
?
IvantiˇŻs Patch Tuesday breakdown goes beyond patching your applications and brings you the intelligence and guidance needed to prioritize where to focus your attention first. Catch early analysis on our Ivanti blog, then join industry expert Chris Goettl for the Patch Tuesday Webinar Event. There weˇŻll do a deep dive into each of the bulletins and give guidance on the risks associated with the newly-identified vulnerabilities. ˇ°Why ItˇŻs Critical to Have an Integrated Development Methodology for Edge AI,...
ˇ°Why ItˇŻs Critical to Have an Integrated Development Methodology for Edge AI,...Edge AI and Vision Alliance
?
ˇ°Addressing Evolving AI Model Challenges Through Memory and Storage,ˇ± a Prese...
ˇ°Addressing Evolving AI Model Challenges Through Memory and Storage,ˇ± a Prese...Edge AI and Vision Alliance
?
Ad
Preprocessing
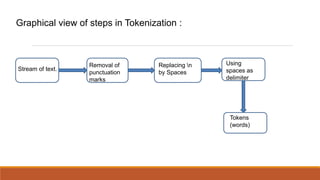
- 1. Steps involved in Preprocessing : 1.Tokenization : ˇń Tokenization : The process of breaking a stream of text into words ˇń Removal of Punctuation marks and numbers ˇń Replacing ˇ®nˇŻ by Spaces ˇń Splitting the string by space as a delimiter ˇń Tokens
- 2. Graphical view of steps in Tokenization : Removal of Replacing n Using Stream of text. spaces as punctuation by Spaces marks delimiter Tokens (words)
- 3. 2. Removal of stop words : ˇń Passing the list of Tokens. ˇń Removing the unnecessary words like the, an, so, after, all, etc (stop words). ˇń Output : A list of meaningful words.
- 4. 3.Stemming : ˇń Stemming : The process for reducing inflected words to their stem, base or root form. For example : Stemming algorithm reduces ˇ°fishing", "fished", "fish", and "fisher" to the root word "fishˇ°. ˇń Stemmer used : Porter Stemmer Algorithm. ˇń Removing ˇ®¨CeeˇŻ,ˇŻ ¨CedˇŻ, ˇ®-ingˇŻ, ˇ®-enceˇŻ, ˇ®-erˇŻ, etc. & adding ˇ®yˇŻ, ˇ®IˇŻ as required. ˇń DoesnˇŻt give accurate roots . Example : stem(flying) =fli stem(fly)=fli ˇń Same roots for all inflected forms ¨C serves our purpose
- 5. 4. Vocabulary creation :- ˇń Vocabulary : Generally, vocabulary is the set of words. ˇń Vocabulary = Union of words from all files. ˇń For each document : Converting list obtained after stemming into Set & taking union. ˇń Processed further for Tf-idf evaluation.