Probabilistic Graphical Models ▌åši╗ß Chapter5
?
0 likes?942 views

Probabilistic Graphical Models ▌åši╗ßż╬┘Y┴ŽżŪż╣Ż«


![5.2 Deterministic CPDs
5.2.1 Representation
ēõ╩²Xż¼żĮż╬ėHż╬ øQČ©Ą─ ż╩ķv╩²ż╦ż╩ż├żŲżżżļCPD
f : V al(Pa ) ? V al(X)ż¼żóżļż╚żŁŻ¼ęįŽ┬ż╬żĶż”ż╩CPD
P(x©OPa ) =
ķv╩²fżŽŻ¼ż┐ż╚ż©żą
[2éÄēõ╩²] ėH═¼╩┐ż╬ or / and
[▀BŠAéÄēõ╩²] X = Y + Z ż╩ż╔
X
X {
1
0
x = f(Pa )X
otherwise](https://image.slidesharecdn.com/graphicalmodelchapter5-161023024226/85/Probabilistic-Graphical-Models-Chapter5-4-320.jpg)











![5.3.1.2 Rule CPDs
Definition 5.4 rule
źļ®`źļ”迎Ż¼?c; p?żŪśŗ│╔żĄżņżļŻ«
ż│ż│żŪŻ¼cżŽēõ╩²╝»║ŽCż╬żóżļ▓┐Ęų╝»║Žżžż╬ĖŅĄ▒żŲżŪżóżĻŻ¼
p Ī╩ [0, 1]żŪżóżļŻ«
CżŽScope[”č]żŪ▒ĒżĄżņżļŻ¼”čż╬ź╣ź│®`źūżŪżóżļŻ«](https://image.slidesharecdn.com/graphicalmodelchapter5-161023024226/85/Probabilistic-Graphical-Models-Chapter5-21-320.jpg)
![5.3.1.2 Rule CPDs
Definition 5.5 rule®\based CPD
rule®\based CPD P(X©OPa )ż╚żŽŻ¼
ęįŽ┬ż╬żĶż”ż╩źļ®`źļ╝»║ŽRżŪżóżļŻ«
Ė„źļ®`źļ ”č Ī╩ Rż╦ż─żżżŲŻ¼Scope[”č] ? {X} Ī╚ Pa
{X} Ī╚ Pa żžż╬Ė„ĖŅĄ▒żŲ(x, u)ż╦ż─żżżŲŻ¼
cż¼(x, u)ż╚ę╗ų┬ż╣żļżĶż”ż╩źļ®`źļ?c; p? Ī╩ Rż¼żęż╚ż─ż└
ż▒żóżļ
P(X©OU)żŽŻ¼ P(x©Ou) = 1ż“£║ż┐ż╣▀mĄ▒ż╩CPD
Ū░ź┌®`źĖż╬Example 5.11żŽż│ż╬Č©┴xż“£║ż┐żĘżŲżżżļ
X
X
X
ĪŲx](https://image.slidesharecdn.com/graphicalmodelchapter5-161023024226/85/Probabilistic-Graphical-Models-Chapter5-23-320.jpg)




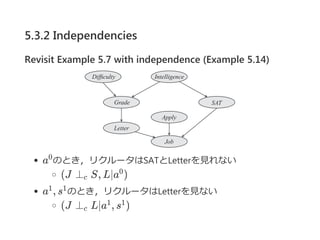
![5.3.2 Independencies
cż“tree®\CPDż╬żóżļų”żŪ▒Ē¼FżĄżņżļź│ź¾źŲźŁź╣ź╚ż╚żĘż┐ż╚żŁŻ¼
XżŽ(Pa ? Scope[c])ż╚Č└┴ó
Pa = {A, S, L}
Scope[c] = {A}, ?(J Ī═ S, L©Oa )
Scope[c] = {A, S}, ?(J Ī═ L©Oa , s )
X
J
c
0
c
1 1](https://image.slidesharecdn.com/graphicalmodelchapter5-161023024226/85/Probabilistic-Graphical-Models-Chapter5-30-320.jpg)
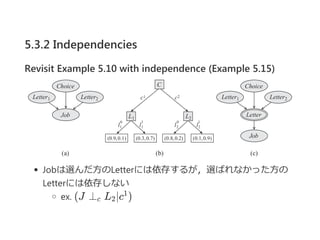

![5.3.2 Independencies
Deifinition 5.6 reduced rule
”č = ?c ; p?ż“źļ®`źļŻ¼C = cż“ź│ź¾źŲźŁź╣ź╚ż╚ż╣żļŻ«
c ż¼cż╚ę╗ų┬ż╣żļż╩żķŻ¼”č Ī½ cż╚żżż”Ż«
ż│ż╬ł÷║ŽŻ¼c = c ?Scope[c ] ? Scope[c]?ż“
Scope[c ] ? Scope[c]ż╬ēõ╩²ż½żķc żžż╬ĖŅĄ▒żŲż╚ż╣żļŻ«
żĮżĘżŲŻ¼reduced rule ”č[c] = ?c ; p?ż“Č©┴xż╣żļŻ«
źļ®`źļ╝»║Ž R ż╦ż─żżżŲŻ¼reduced rule ╝»║Ž
R[c] = {”č[c] : ”č Ī╩ R, ”č Ī½ c}
ż¼Č©┴xżĄżņżļŻ«
Īõ
Īõ
ĪõĪõ Īõ Īõ
Īõ Īõ
ĪõĪõ](https://image.slidesharecdn.com/graphicalmodelchapter5-161023024226/85/Probabilistic-Graphical-Models-Chapter5-33-320.jpg)
![5.3.2 Independencies
Revisit Example 5.12 with reduced rule (Example 5.17)
Example 5.12ż╬R[a ]żŽŻ¼
ż╚ż╩żļŻ«
a ż╚ę╗ų┬ż╣żļźļ®`źļż╬ż▀ż¼▓ążĻŻ¼źļ®`źļż½żķa ż¼Ž„│²żĄżņżļ
1
1 1
?](https://image.slidesharecdn.com/graphicalmodelchapter5-161023024226/85/Probabilistic-Graphical-Models-Chapter5-34-320.jpg)
![5.3.2 Independencies
Proposition 5.2 reduced rule
Rż“ēõ╩²Xż╦ż─żżżŲż╬rule®\based CPDż╬źļ®`źļ╝»║Žż╚żĘŻ¼
R ż“Rż╬ż”ż┴cż╚ę╗ų┬ż╣żļźļ®`źļ╝»║Žż╚ż╣żļŻ«
Y ? Pa ż“Ż¼Y Ī╔ Scope[c] = ?ż╬żĶż”ż╩Xż╬ėHż╬żóżļ▓┐
Ęų╝»║Žż╚ż╣żļŻ«
Ė„”č Ī╩ R[c]ż╦ż─żżżŲŻ¼Y Ī╔ Scope[”č] = ?ż╩żķżąŻ¼
(X Ī═ Y ©OPa ? Y , c) żŪżóżļŻ«
Ż©į^├„żŽexercise 5.4Ż®
źļ®`źļėøĘ©ż½żķ"Šų╦∙Ą─ż╩"CSIż“═Ųšōż╣żļėŗ╦Ń╩ųĘ©
ēõ╩²Y ż¼Ż¼żóżļź│ź¾źŲźŁź╣ź╚ż╦ż─żżżŲż╬ reduced rule ╝»║Žż╦
║¼ż▐żņżļż½ż╔ż”ż½Ż¼źļ®`źļ╩²ż╬ŠĆą╬ĢrķgżŪ┤_šJżŪżŁżļ
Ż©į^├„żŽexercise 5.7Ż®
c
X
c X](https://image.slidesharecdn.com/graphicalmodelchapter5-161023024226/85/Probabilistic-Graphical-Models-Chapter5-35-320.jpg)
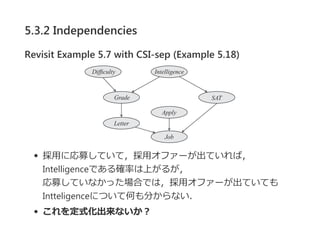
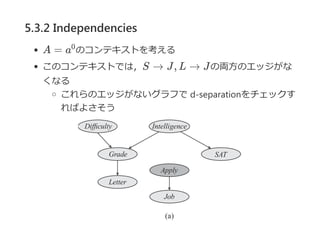
![5.3.2 Independencies
Deifinition 5.7 spurious edge
P(X©OPa )ż“CPDŻ¼Y Ī╩ Pa Ż¼cż“ź│ź¾źŲźŁź╣ź╚ż╚ż╣żļŻ«
P(X©OPa )ż¼(X Ī═ Y ©OPa ? {Y }, c )ż“£║ż┐ż╣ż╩żķŻ¼
ź©ź├źĖY Ī· XżŽŻ¼cż╦ż¬żżżŲöM╦ŲĄ─? spurious ?ż╚║¶żųŻ«
ż│ż│żŪŻ¼c = c?Pa ?żŽPa ż╬ēõ╩²╝»║Žż╦īØż╣żļcż╬ųŲ╝sżŪ
żóżļŻ«
CPDż¼źļ®`źļż╦żĶż├żŲ▒Ē¼FżĄżņżŲżżżļż╚żŁŻ¼
reduced rule ╝»║Žż“┤_šJż╣żļż│ż╚ż╦żĶż├żŲ
ź©ź├źĖż¼ spurious żŪżóżļż½ż╔ż”ż½øQČ©żŪżŁżļ
Y ż¼ reduced rule╝»║ŽR[c]ż╦│÷¼FżĘż╩żżż╩żķŻ¼
cż╦ż¬żżżŲY Ī· XżŽ spurious
X X
X c X
Īõ
Īõ
X X](https://image.slidesharecdn.com/graphicalmodelchapter5-161023024226/85/Probabilistic-Graphical-Models-Chapter5-38-320.jpg)
![5.3.2 Independencies
CSI®\separation
ż│ż│żŪŻ¼CSI®\separation ż“Č©┴xżŪżŁżļ
CSIż“┐╝æ]żĘż┐d®\separation
öM╦ŲĄ─ż╩ź©ź├źĖż“╚ĪżĻ│²ż»Šų╦∙Ą─ż╩▓┘ū„ż“żĘżŲŻ¼
Ą├żķżņż┐ź░źķźšż╦ ╗Õ®\▓§▒▒Ķ▓╣░∙▓╣│┘Š▒┤Ū▓įż“╩╩ė├ż╣żļ](https://image.slidesharecdn.com/graphicalmodelchapter5-161023024226/85/Probabilistic-Graphical-Models-Chapter5-39-320.jpg)


![5.4.1 The Noisy-Or Model
Į╠╩┌ż¼č¦╔·ż╬═Ų╦]ū┤Ż©LetterŻ®ż“Ģ°ż»└²ż“┐╝ż©żļ
Letterż╬┴╝żĄżŽŻ¼
┴╝żż┘|å¢ż“żĘżŲżżż┐ż½ ?Question?
ūŅĮKźņź▌®`ź╚ż╬│╔┐ā ?Final paper?
żŪżŁż▐żĻŻ¼č¦╔·żŽüIĘĮż╚żŌ┴╝żż═Ų╦]ū┤ż“żŌżķż”ż╦╩«Ęųż└ż¼
żĮż╬č¦╔·ż╬ėĪŽ¾ż¼żóż▐żĻ▓ąż├żŲżżż╩żżł÷║Ž
ūųż¼øAż»żŲźņź▌®`ź╚ż¼šiżßż╩żżł÷║Ž
ż╚żżż├ż┐ź╬źżź║ż“║¼żÓ](https://image.slidesharecdn.com/graphicalmodelchapter5-161023024226/85/Probabilistic-Graphical-Models-Chapter5-44-320.jpg)

![5.4.1 The Noisy-Or Model
┘|å¢żŌęÖż©żŲżżż╩żżŻ¼źņź▌®`ź╚ż╬ūųżŌšiżßż╩żż
0.2 ? 0.1 = 0.02
┴╝żż═Ų╦]ū┤ż¼żŌżķż©żļ┤_┬╩
P(l ©Oq , f ) = 0.981 1 1](https://image.slidesharecdn.com/graphicalmodelchapter5-161023024226/85/Probabilistic-Graphical-Models-Chapter5-46-320.jpg)
![5.4.1 The Noisy-Or Model
Definition 5.8 noisy®\or CPD
Y ż“kéĆż╬2éÄż“ż╚żļėHX , ..., X ż“żŌż─2éÄēõ╩²ż╚ż╣żļŻ«
P(y ©OX , ..., X ) = (1 ? ”╦ ) (1 ? ”╦ )
P(y ©OX , ..., X ) = 1 ? [(1 ? ”╦ ) (1 ? ”╦ )]
ż╚ż╩żļk + 1éĆż╬ź╬źżź║źčźķźß®`ź┐”╦ , ”╦ , ..., ”╦ ż¼żóżņżąŻ¼
PCD P(Y ©OX , ..., X )żŽnoisy®\orżŪżóżļŻ«
x ż“1, x ż“0ż╚ĮŌßŗż╣żņżąŻ¼ęįŽ┬ż╬żĶż”ż╦ēõą╬żŪżŁżļŻ«
P(y ©OX , ..., X ) = (1 ? ”╦ ) (1 ? ”╦ )
1 k
0
1 k 0 ĪŪi:X =xi i
1 i
1
1 k 0 ĪŪi:X =xi i
1 i
0 1 k
1 k
i
1
i
0
0
1 k 0
i=1
ĪŪ i
xi](https://image.slidesharecdn.com/graphicalmodelchapter5-161023024226/85/Probabilistic-Graphical-Models-Chapter5-48-320.jpg)





Probabilistic Graphical Models ▌åši╗ß Chapter5
- 1. Probabilistic Graphical Models ▌åši╗ß Chapter 5 Local Probabilistic Models Źu╠’┤¾śõ
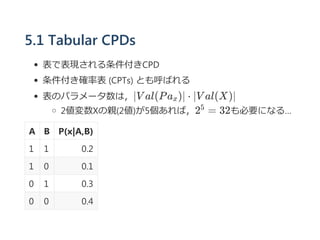
- 3. 5.1 Tabular CPDs ▒ĒżŪ▒Ē¼FżĄżņżļ╠§╝■ĖČżŁCPD ╠§╝■ĖČżŁ┤_┬╩▒Ē ?CPTs? ż╚żŌ║¶żążņżļ ▒Ēż╬źčźķźß®`ź┐╩²żŽŻ¼©OV al(Pa )©O ? ©OV al(X)©O 2éÄēõ╩²Xż╬ėH?2éÄ?ż¼5éĆżóżņżąŻ¼2 = 32żŌ▒žę¬ż╦ż╩żļĪŁ A B P?x|A,B? 1 1 0.2 1 0 0.1 0 1 0.3 0 0 0.4 x 5
- 4. 5.2 Deterministic CPDs 5.2.1 Representation ēõ╩²Xż¼żĮż╬ėHż╬ øQČ©Ą─ ż╩ķv╩²ż╦ż╩ż├żŲżżżļCPD f : V al(Pa ) ? V al(X)ż¼żóżļż╚żŁŻ¼ęįŽ┬ż╬żĶż”ż╩CPD P(x©OPa ) = ķv╩²fżŽŻ¼ż┐ż╚ż©żą [2éÄēõ╩²] ėH═¼╩┐ż╬ or / and [▀BŠAéÄēõ╩²] X = Y + Z ż╩ż╔ X X { 1 0 x = f(Pa )X otherwise
- 5. 5.2.2 Independencies Example 5.3 Ī∙ 2ųž═Ķż╬CżŽŻ©Aż╚Bż╬Ż®øQČ©Ą─ż╩ķv╩²żŪżóżļż│ż╚ż“╩Šż╣Ż« Aż╚Bż¼ėļż©żķżņżŲżżżļĢrŻ¼Cż╬éÄżŽ▒žż║øQż▐żļż╬żŪŻ¼ (D Ī═ E©OA, B) Cż¼Aż╚Bż╬øQČ©Ą─ż╩ķv╩²żŪż╩żżł÷║ŽŻ¼▒žż║żĘżŌż│ż╬Č└┴óąįżŽ│╔ ┴óżĘż╩żż īgļHŻ¼d®\separation żŪż│ż╬Č└┴óąįżŽ═ŲšōżŪżŁż╩żż d®\separation ż“Į±╗žż╬żĶż”ż╩ż╬Č└┴óąįż“ęŖż─ż▒żļż│ż╚ż╦▀mė├żŪżŁ ż╩żżż½Ż┐
- 6. 5.2.2 Independencies (X Ī═ Y ©OZ) ż╚żżż”ł÷║Žż“┐╝ż©żļŻ« deterministic CPDż“│ųż├żŲżżżļŻ¼ż½ż─ żĮż╬ėHPaX ż¼ż╣ż┘żŲėļż©żķżņżŲżżżļ (Z ż╬▓┐Ęų╝»║Ž) ēõ╩² X ż“ėQ£y┐╔─▄żŪżóżļż╚żĘżŲŻ¼ų┤╬Ą─ż╦Z ż╦ūĘ╝ėżĘżŲ d®\separationż“ėŗ╦Ńż╣żļ i + i +
- 7. 5.2.2 Independencies Č©└Ē5.1 Gż“ź═ź├ź╚ź’®`ź»ż╬śŗįņŻ¼D, X, Y , Zż“ēõ╩²ż╬╝»║Žż╚ż╣żļŻ« Zż¼ėļż©żķżņż┐ĢrXż¼Y ż╚ deterministically separated ż╩żķŻ¼ P ?I (G) ż╬żĶż”ż╩ż╣ż┘żŲż╬Ęų▓╝Pż╚Ż¼ øQČ©Ą─╠§╝■ĖČżŁ┤_┬╩Ęų▓╝P(X©OPa )Ż¼X Ī╩ Dż╬żĮżņżŠżņż╦ ż─żżżŲŻ¼P ? (X Ī═ Y ©OZ)ż“Ą├żļŻ« į^├„żŽ?exercise 5.1? ż│ż╬ĘĮĘ©żŪŻ¼╚½żŲż╬øQČ©Ą─ķv╩²ż“║¼żÓČ└┴óąįż“Ą├żķżņżļż½Ż┐ l X
- 8. 5.2.2 Independencies Č©└Ē5.2 Gż“ź═ź├ź╚ź’®`ź»ż╬śŗįņŻ¼D, X, Y , Zż“ēõ╩²ż╬╝»║Žż╚ż╣żļŻ« DET®\SEP(G, D, X, Y , Z)ż¼é╬ż╩żķŻ¼ P ?I (G) ż╬żĶż”ż╩Ęų▓╝Pż¼┤µį┌żĘżŲżżżŲŻ¼ øQČ©Ą─╠§╝■ĖČżŁ┤_┬╩Ęų▓╝P(X©OPa )Ż¼X Ī╩ DżŪżŌŻ¼ P ? (X Ī═ Y ©OZ)żŪżŽż╩żżŻ« DET®\SEPżŽėHż╬øQČ©Ą─ķv╩²ż╦ż╩ż├żŲżżżļēõ╩²ż½żķģgż╦ė╔└┤ż╣żļ Č└┴óąįżŽŻ¼ęŖż─ż▒żļż│ż╚ż¼żŪżŁżļŻ« żĘż½żĘŻ¼╠žäeż╩øQČ©Ą─ķv╩²żŽ╦¹ż╬Č└┴óąįż“ż─ż»żļż│ż╚ż¼żóżļ l X
- 9. 5.2.2 Independencies Example 5.4 Ī∙CżŽBż╚Aż╬XORż╦żĶż├żŲĄ├żķżņżļ AżŽŻ¼Cż╚Bż¼ėļż©żķżņżņżą▒žż║øQČ©ż╣żļ żĘż┐ż¼ż├żŲŻ¼(D Ī═ E©OB, C)
- 10. 5.2.2 Independencies Revisit Example 5.3 (Example 5.5) Ī∙ CżŽŻ©Aż╚Bż╬Ż®ORķv╩² A = a ż╬ĢrŻ¼CżŽėHż╬ORż“ż╚żļż╬żŪŻ¼Bż╬éÄż╦ķvéSż╩ż»øQČ© żĘż┐ż¼ż├żŲŻ¼P(D©OB, a ) = P(D©Oa )Ż«Ż©Bż╚DżŽČ└┴óŻ® A = a ż╬ĢrżŪżŽŻ¼CżŽż▐ż└øQČ©żĘż╩żżż╬żŪŻ¼╔ŽėøżŽ│╔┴óż╗ż║ øQČ©Ą─ż╩ēõ╩²żŽŻ¼╠žäeż╩ą╬ż╬Č└┴óż“│ųż─ż┐żßŻ¼▒ŠĢ°żŪżŽŻ¼ P(X©OY , Z) = P(X©OZ)ż╚üóČ©żĘż┐(X Ī═ Y ©OZ)ż╬ą╬╩Įż╬żŌ ż╬ż╦Ž▐Č©ż╣żļŻ« 1 1 1 0
- 11. 5.2.2 Independencies Definition 5.1 X, Y , Zż“╗źżżż╦╦žż╩ēõ╩²╝»║ŽŻ¼Cż“ēõ╩²╝»║ŽŻ© X Ī╚ Y Ī╚ Zż╚╦žżŪż╩ż»żŲżŌżĶżżŻ®Ż¼cż“c Ī╩ V al(C)ż╚ż╣ żļŻ« P(X©OY , Z, c) = P(X©OZ, c)whereneverP(Y , Z, c) > 0 ż╩żķżąŻ¼ Zż╚Ż¼(X Ī═ Y ©OZ, c)żŪ╩ŠżĄżņżļź│ź¾źŲźŁź╣ź╚cż¼ėļż©żķżņż┐ Ž┬żŪXż╚Y ż¼ contextually independentżŪżóżļż╚żżż”Ż« ż│ż╬ą╬ż╬Č└┴óż“ context®\specific independencies ?CSI?ż╚║¶żųŻ« c
- 12. 5.2.2 Independencies Revisit Example 5.3 with CSI (Example 5.6) Ī∙ CżŽŻ©Aż╚Bż╬Ż®ORķv╩² A = a ż╬ż╚żŁż╦żŽŻ¼Bż“ėQ£yż╗ż║ż╚żŌC = c ż¼øQČ©żĘż┐ żĘż┐ż¼ż├żŲŻ¼(C Ī═ B©Oa )Ż¼(D Ī═ B©Oa ) C = c ż╬ż╚żŁż╦żŽŻ¼A = a żŌB = b żŌøQČ©ż╣żļ żĘż┐ż¼ż├żŲŻ¼(A Ī═ B©Oc )Ż¼(D Ī═ E©Oc ) C = c Ż¼B = b ż╬ż╚żŁż╦żŽŻ¼A = a ż¼øQČ©ż╣żļ żĘż┐ż¼ż├żŲŻ¼(D Ī═ E©Ob , c ) 1 1 c 1 c 1 0 0 0 c 0 c 0 1 0 1 c 0 1
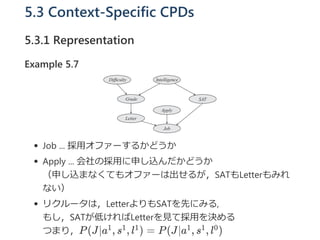
- 13. 5.3 Context-Specific CPDs 5.3.1 Representation Example 5.7 Job ... Ʊė├ź¬źšźĪ®`ż╣żļż½ż╔ż”ż½ Apply ... ╗ß╔ńż╬Ʊė├ż╦╔ĻżĘ▐zż¾ż└ż½ż╔ż”ż½ Ż©╔ĻżĘ▐zż▐ż╩ż»żŲżŌź¬źšźĪ®`żŽ│÷ż╗żļż¼Ż¼SATżŌLetterżŌż▀żņ ż╩żżŻ® źĻź»źļ®`ź┐żŽŻ¼LetterżĶżĻżŌSATż“Ž╚ż╦ż▀żļ, żŌżĘŻ¼SATż¼Ą═ż▒żņżąLetterż“ęŖżŲƱė├ż“øQżßżļ ż─ż▐żĻŻ¼P(J©Oa , s , l ) = P(J©Oa , s , l )1 1 1 1 1 0
- 14. 5.3.1.1 Tree-CPDs Example 5.7 with Tree-CPD (Example 5.8) żóżļJż╬┤_┬╩ż“ų¬żĻż┐ż▒żņżąŻ¼─Šż╬Ė∙ż½żķĒśĘ¼ż╦Ė„╩¶ąįż“ "źŲź╣ź╚"ż╣żņżą┴╝żż ex.? P(J©Oa , s , l )żŽŻ¼ J : P(j ) = 0.1, and?P(j ) = 0.9 1 1 0 0 1
- 15. 5.3.1.1 Tree-CPDs Definition 5.2 Ė∙ż¼1ż─ ?rooted tree? Ė„tź╬®`ź╔żŽ╚~ż½─┌▓┐tź╬®`ź╔ż“│ųż─ ╚~żŽP(X)ż“▒Ēż╣ ─┌▓┐tź╬®`ź╔żŽZ Ī╩ Pa ż╩żóżļēõ╩²Zż“▒Ēż╣ Ė„─┌▓┐tź╬®`ź╔żŽŻ¼ūėżžż╬╗Ī?arc, ź©ź├źĖ?ż╬╝»║Žż“│ųż─ żĮżņżŠżņŻ¼ēõ╩²ĖŅĄ▒żŲZ = z ?for?z Ī╩ V al(Z)ż“▒Ēż╣ ų””┬żŽĖ∙ż½żķ╚~ż▐żŪż╬ĮU┬Ęż“▒Ēż╣ ų”żŽŻ¼═¼żĖēõ╩²ż“╩Šż╣─┌▓┐tź╬®`ź╔ż“2ż─ęį╔Ž│ųż┐ż╩żż X i i
- 16. 5.3.1.1 Tree-CPDs Example 5.9 ėHź│ź¾źŲźŁź╣ź╚<a >żŽŻ¼╔ĻżĘ▐zż▐ż╩ż½ż├ż┐ł÷║Žż╦īØÅĻż╣żļ ėHź│ź¾źŲźŁź╣ź╚<a , s >żŽŻ¼Ė▀żżSATź╣ź│źóż╬╚╦ż¼Æ±ė├ż╦ÅĻ─╝ żĘż┐ł÷║Žż╦īØÅĻż╣żļ źŲ®`źųźļėøĘ©żŪżŽ8ż─ż╬źčźķźß®`ź┐ż¼▒žę¬ż└ż¼Ż¼ ─ŠėøĘ©żŪżŽ4ż─ż╬ż▀żŪżĶżżŻĪ tree®\CPDżŽżóżļēõ╩²ż¼Ż¼┤¾┴┐ż╬ēõ╩²╚║ż╬ż”ż┴ę╗ż─ż└ż▒ż╦ę└┤µ ż╣żļżĶż”ż╩ł÷║Žż╦żŽėąä┐ż╩ĘĮĘ© 0 1 1
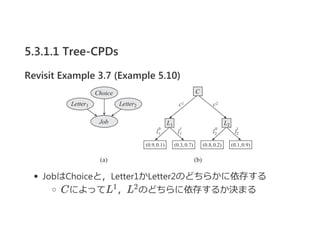
- 17. 5.3.1.1 Tree-CPDs Revisit Example 3.7 (Example 5.10) JobżŽChoiceż╚Ż¼Letter1ż½Letter2ż╬ż╔ż┴żķż½ż╦ę└┤µż╣żļ Cż╦żĶż├żŲL Ż¼L ż╬ż╔ż┴żķż╦ę└┤µż╣żļż½øQż▐żļ1 2
- 18. 5.3.1.1 Tree-CPDs Revisit Example 3.7 (Example 5.10) Ū░ź┌®`źĖż╬żĶż”ż╩CPDż“ multiplexer CPDż╦żĶż├żŲą╬╩Į╗»ż╣żļ Definition 5.3 V al(A) = {1, ..., k}ż½ż─Ż¼ P(Y ©Oa, Z , ..., Z ) = 1 {Y = Z } ż╩żķżąŻ¼ CPD P(Y ©OA, Z , ..., Z )żŽ multiplexer CPD ż╚żżż”Ż« multiplexer CPDżŽŻ¼╠§╝■ż╦ÅĻżĖżŲ╠žČ©ż╬ėHż“ź╣źżź├ź┴ż╣żļ ex.10żŪżŽChoiceż╦żĶż├żŲę└┤µķvéSż¼ź╣źżź├ź┴żĄżņżŲżżżļ 1 k a 1 k
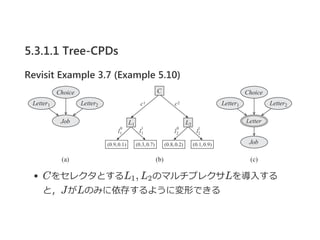
- 19. 5.3.1.1 Tree-CPDs Revisit Example 3.7 (Example 5.10) Cż“ź╗źņź»ź┐ż╚ż╣żļL , L ż╬ź▐źļź┴źūźņź»źĄLż“ī¦╚ļż╣żļ ż╚Ż¼Jż¼Lż╬ż▀ż╦ę└┤µż╣żļżĶż”ż╦ēõą╬żŪżŁżļ 1 2
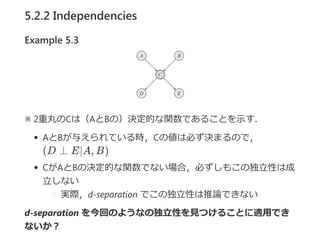
- 21. 5.3.1.2 Rule CPDs Definition 5.4 rule źļ®`źļ”迎Ż¼?c; p?żŪśŗ│╔żĄżņżļŻ« ż│ż│żŪŻ¼cżŽēõ╩²╝»║ŽCż╬żóżļ▓┐Ęų╝»║Žżžż╬ĖŅĄ▒żŲżŪżóżĻŻ¼ p Ī╩ [0, 1]żŪżóżļŻ« CżŽScope[”č]żŪ▒ĒżĄżņżļŻ¼”čż╬ź╣ź│®`źūżŪżóżļŻ«
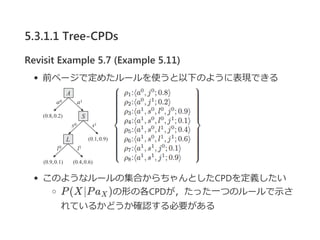
- 22. 5.3.1.1 Tree-CPDs Revisit Example 5.7 (Example 5.11) Ū░ź┌®`źĖżŪČ©żßż┐źļ®`źļż“╩╣ż”ż╚ęįŽ┬ż╬żĶż”ż╦▒Ē¼FżŪżŁżļ ż│ż╬żĶż”ż╩źļ®`źļż╬╝»║Žż½żķż┴żŃż¾ż╚żĘż┐CPDż“Č©┴xżĘż┐żż P(X©OPa )ż╬ą╬ż╬Ė„CPDż¼Ż¼ż┐ż├ż┐ę╗ż─ż╬źļ®`źļżŪ╩ŠżĄ żņżŲżżżļż½ż╔ż”ż½┤_šJż╣żļ▒žę¬ż¼żóżļ X
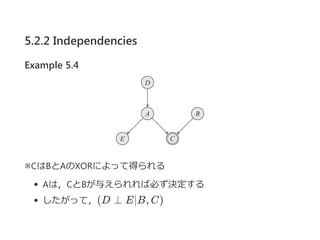
- 23. 5.3.1.2 Rule CPDs Definition 5.5 rule®\based CPD rule®\based CPD P(X©OPa )ż╚żŽŻ¼ ęįŽ┬ż╬żĶż”ż╩źļ®`źļ╝»║ŽRżŪżóżļŻ« Ė„źļ®`źļ ”č Ī╩ Rż╦ż─żżżŲŻ¼Scope[”č] ? {X} Ī╚ Pa {X} Ī╚ Pa żžż╬Ė„ĖŅĄ▒żŲ(x, u)ż╦ż─żżżŲŻ¼ cż¼(x, u)ż╚ę╗ų┬ż╣żļżĶż”ż╩źļ®`źļ?c; p? Ī╩ Rż¼żęż╚ż─ż└ ż▒żóżļ P(X©OU)żŽŻ¼ P(x©Ou) = 1ż“£║ż┐ż╣▀mĄ▒ż╩CPD Ū░ź┌®`źĖż╬Example 5.11żŽż│ż╬Č©┴xż“£║ż┐żĘżŲżżżļ X X X ĪŲx
- 24. 5.3.1.2 Rule CPDs Example 5.12 Xż“Pa = {A, B, C}ż“ėHż╦│ųż─ēõ╩²ż╚żĘŻ¼ Xż╬CPDż“ęįŽ┬ż╬ż╬źļ®`źļ╝»║Žż½żķČ©┴xż╣żļ ęįŽ┬ż╬żĶż”ż╩CPDż¼Č©┴xżŪżŁżļ Ė„┴ąż┤ż╚ż╦║═ż“ż╚żņżąŻ¼ż┴żŃż¾ż╚1ż╦ż╩ż├żŲżżżļ X
- 25. 5.3.1.2 Rule CPDs Proposition 5.1 Bż“ź┘źżźĖźóź¾ź═ź├ź╚ź’®`ź»Ż¼Bż╦ż¬ż▒żļĖ„CPD P(X©OPa ) ż¼źļ®`źļ╝»║ŽR ż╚żĘżŲ▒Ē¼FżĄżņżŲżżżļż╚ż╣żļŻ« RżŽĪ╚ R ż╚żĘżŲČ©┴xżĄżņżļČÓųž╝»║ŽżŪżóżļŻ« ż│ż│żŪŻ¼Ī╚ żŽČÓųž╝»║Ž║═żŪżóżĻŻ¼ųžč}ż“║¼żÓ╚½żŲż╬źļ®`źļźż ź¾ź╣ź┐ź¾ź╣ż“│ųż├żŲżżżļŻ« żĮżĘżŲŻ¼ź═ź├ź╚ź’®`ź»ēõ╩²Xżžż╬╚╬ęŌż╬ĖŅĄ▒żŲ”╬ż╬┤_┬╩żŽ, P(”╬) = p ż╚żĘżŲėŗ╦ŃżĄżņżļŻ« X X XĪ╩X + X + ĪŪ?c;p?Ī╩R,”╬Ī½c
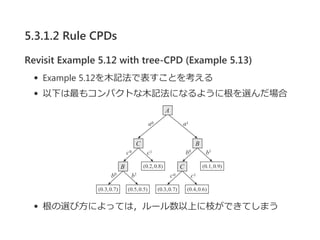
- 26. 5.3.1.2 Rule CPDs Revisit Example 5.12 with tree-CPD (Example 5.13) Example 5.12ż“─ŠėøĘ©żŪ▒Ēż╣ż│ż╚ż“┐╝ż©żļ ęįŽ┬żŽūŅżŌź│ź¾źčź»ź╚ż╩─ŠėøĘ©ż╦ż╩żļżĶż”ż╦Ė∙ż“▀xż¾ż└ł÷║Ž Ė∙ż╬▀xżėĘĮż╦żĶż├żŲżŽŻ¼źļ®`źļ╩²ęį╔Žż╦ų”ż¼żŪżŁżŲżĘż▐ż”
- 27. 5.3.1.3 Other Representatioins ų”żõźļ®`źļż“ÆłÅłżĘż┐▒Ē¼Fż“┐╝ż©żļż│ż╚żŌżŪżŁżļż¼Ż¼ę╗░Ńż╦ Č©╩Į╗»ż¼č}ļjż╦ż╩żļŻ« decision diagram ─Š▒Ēėøż╦ż¬żżżŲŻ¼ūėź╬®`ź╔ż╬╣▓ėąż“įS╚▌żĘżŲ╚▀ķLż╩▓┐Ęų ─Šż╬░k╔·ż“Ę└ż░ĘĮĘ©
- 28. 5.3 Context-Specific CPDs 5.3.2 Independencies "a ż╬ż╚żŁŻ¼źĻź»źļ®`ź┐żŽēõ╩²Sż╚Lż╦ę└żķż║ż╦Ʊė├ź¬źšźĪ®` ż“øQżßżļ" context®\specificż╩Č└┴óż“żŌż─CPDż“▒Ē¼FżĘżŲżżżļ ż│ż╬żĶż”ż╩CPDż╬śŗįņżŪżŽŻ¼ź═ź├ź╚ź’®`ź»╚½╠Õż“ęŖż╩żżŻ¼ Šų╦∙Ą─ż╩Č└┴óż“═Ųšōż╣żļż│ż╚ż¼żŪżŁżļ context®\specific CPDż╦żĶż├żŲ▒Ē¼FżĄżņżļČ└┴óąįż“┐╝ż©żļ 0
- 29. 5.3.2 Independencies Revisit Example 5.7 with independence (Example 5.14) a ż╬ż╚żŁŻ¼źĻź»źļ®`ź┐żŽSATż╚Letterż“ęŖżņż╩żż (J Ī═ S, L©Oa ) a , s ż╬ż╚żŁŻ¼źĻź»źļ®`ź┐żŽLetterż“ęŖż╩żż (J Ī═ L©Oa , s ) 0 c 0 1 1 c 1 1
- 30. 5.3.2 Independencies cż“tree®\CPDż╬żóżļų”żŪ▒Ē¼FżĄżņżļź│ź¾źŲźŁź╣ź╚ż╚żĘż┐ż╚żŁŻ¼ XżŽ(Pa ? Scope[c])ż╚Č└┴ó Pa = {A, S, L} Scope[c] = {A}, ?(J Ī═ S, L©Oa ) Scope[c] = {A, S}, ?(J Ī═ L©Oa , s ) X J c 0 c 1 1
- 31. 5.3.2 Independencies Revisit Example 5.10 with independence (Example 5.15) JobżŽ▀xż¾ż└ĘĮż╬Letterż╦żŽę└┤µż╣żļż¼Ż¼▀xżążņż╩ż½ż├ż┐ĘĮż╬ Letterż╦żŽę└┤µżĘż╩żż ex. (J Ī═ L ©Oc )c 2 1
- 32. 5.3.2 Independencies Revisit Example 5.14 with rule (Example 5.16) s ż╚żżż”ź│ź¾źŲźŁź╣ź╚ż¼ėļż©żķżņż┐ĢrŻ¼ s żŽaż╦ż─żżżŲż╬ź│ź¾źŲźŁź╣ź╚ż“║¼żÓ (J Ī═ L©Os ) Xż╬ėHY ż╦ż─żżżŲż╬źļ®`źļż¼ż╩żżż╩żķŻ¼XżŽcż¼ėļż©żķżņż┐ż╚ żŁY ż╚Č└┴óżŪżóżļ 1 1 c 1
- 33. 5.3.2 Independencies Deifinition 5.6 reduced rule ”č = ?c ; p?ż“źļ®`źļŻ¼C = cż“ź│ź¾źŲźŁź╣ź╚ż╚ż╣żļŻ« c ż¼cż╚ę╗ų┬ż╣żļż╩żķŻ¼”č Ī½ cż╚żżż”Ż« ż│ż╬ł÷║ŽŻ¼c = c ?Scope[c ] ? Scope[c]?ż“ Scope[c ] ? Scope[c]ż╬ēõ╩²ż½żķc żžż╬ĖŅĄ▒żŲż╚ż╣żļŻ« żĮżĘżŲŻ¼reduced rule ”č[c] = ?c ; p?ż“Č©┴xż╣żļŻ« źļ®`źļ╝»║Ž R ż╦ż─żżżŲŻ¼reduced rule ╝»║Ž R[c] = {”č[c] : ”č Ī╩ R, ”č Ī½ c} ż¼Č©┴xżĄżņżļŻ« Īõ Īõ ĪõĪõ Īõ Īõ Īõ Īõ ĪõĪõ
- 34. 5.3.2 Independencies Revisit Example 5.12 with reduced rule (Example 5.17) Example 5.12ż╬R[a ]żŽŻ¼ ż╚ż╩żļŻ« a ż╚ę╗ų┬ż╣żļźļ®`źļż╬ż▀ż¼▓ążĻŻ¼źļ®`źļż½żķa ż¼Ž„│²żĄżņżļ 1 1 1 ?
- 35. 5.3.2 Independencies Proposition 5.2 reduced rule Rż“ēõ╩²Xż╦ż─żżżŲż╬rule®\based CPDż╬źļ®`źļ╝»║Žż╚żĘŻ¼ R ż“Rż╬ż”ż┴cż╚ę╗ų┬ż╣żļźļ®`źļ╝»║Žż╚ż╣żļŻ« Y ? Pa ż“Ż¼Y Ī╔ Scope[c] = ?ż╬żĶż”ż╩Xż╬ėHż╬żóżļ▓┐ Ęų╝»║Žż╚ż╣żļŻ« Ė„”č Ī╩ R[c]ż╦ż─żżżŲŻ¼Y Ī╔ Scope[”č] = ?ż╩żķżąŻ¼ (X Ī═ Y ©OPa ? Y , c) żŪżóżļŻ« Ż©į^├„żŽexercise 5.4Ż® źļ®`źļėøĘ©ż½żķ"Šų╦∙Ą─ż╩"CSIż“═Ųšōż╣żļėŗ╦Ń╩ųĘ© ēõ╩²Y ż¼Ż¼żóżļź│ź¾źŲźŁź╣ź╚ż╦ż─żżżŲż╬ reduced rule ╝»║Žż╦ ║¼ż▐żņżļż½ż╔ż”ż½Ż¼źļ®`źļ╩²ż╬ŠĆą╬ĢrķgżŪ┤_šJżŪżŁżļ Ż©į^├„żŽexercise 5.7Ż® c X c X
- 36. 5.3.2 Independencies Revisit Example 5.7 with CSI-sep (Example 5.18) Ʊė├ż╦ÅĻ─╝żĘżŲżżżŲŻ¼Æ±ė├ź¬źšźĪ®`ż¼│÷żŲżżżņżąŻ¼ IntelligenceżŪżóżļ┤_┬╩żŽ╔Žż¼żļż¼Ż¼ ÅĻ─╝żĘżŲżżż╩ż½ż├ż┐ł÷║ŽżŪżŽŻ¼Æ±ė├ź¬źšźĪ®`ż¼│÷żŲżżżŲżŌ Intteligenceż╦ż─żżżŲ║╬żŌĘųż½żķż╩żżŻ« ż│żņż“Č©╩Į╗»│÷└┤ż╩żżż½Ż┐
- 37. 5.3.2 Independencies A = a ż╬ź│ź¾źŲźŁź╣ź╚ż“┐╝ż©żļ ż│ż╬ź│ź¾źŲźŁź╣ź╚żŪżŽŻ¼S Ī· J, L Ī· Jż╬üIĘĮż╬ź©ź├źĖż¼ż╩ ż»ż╩żļ ż│żņżķż╬ź©ź├źĖż¼ż╩żżź░źķźšżŪ d®\separationż“ź┴ź¦ź├ź»ż╣ żņżążĶżĄżĮż” 0
- 38. 5.3.2 Independencies Deifinition 5.7 spurious edge P(X©OPa )ż“CPDŻ¼Y Ī╩ Pa Ż¼cż“ź│ź¾źŲźŁź╣ź╚ż╚ż╣żļŻ« P(X©OPa )ż¼(X Ī═ Y ©OPa ? {Y }, c )ż“£║ż┐ż╣ż╩żķŻ¼ ź©ź├źĖY Ī· XżŽŻ¼cż╦ż¬żżżŲöM╦ŲĄ─? spurious ?ż╚║¶żųŻ« ż│ż│żŪŻ¼c = c?Pa ?żŽPa ż╬ēõ╩²╝»║Žż╦īØż╣żļcż╬ųŲ╝sżŪ żóżļŻ« CPDż¼źļ®`źļż╦żĶż├żŲ▒Ē¼FżĄżņżŲżżżļż╚żŁŻ¼ reduced rule ╝»║Žż“┤_šJż╣żļż│ż╚ż╦żĶż├żŲ ź©ź├źĖż¼ spurious żŪżóżļż½ż╔ż”ż½øQČ©żŪżŁżļ Y ż¼ reduced rule╝»║ŽR[c]ż╦│÷¼FżĘż╩żżż╩żķŻ¼ cż╦ż¬żżżŲY Ī· XżŽ spurious X X X c X Īõ Īõ X X
- 39. 5.3.2 Independencies CSI®\separation ż│ż│żŪŻ¼CSI®\separation ż“Č©┴xżŪżŁżļ CSIż“┐╝æ]żĘż┐d®\separation öM╦ŲĄ─ż╩ź©ź├źĖż“╚ĪżĻ│²ż»Šų╦∙Ą─ż╩▓┘ū„ż“żĘżŲŻ¼ Ą├żķżņż┐ź░źķźšż╦ ╗Õ®\▓§▒▒Ķ▓╣░∙▓╣│┘Š▒┤Ū▓įż“╩╩ė├ż╣żļ
- 40. 5.3.2 Independencies Revisit Example 5.7 with CSI-sep (Example 5.18) S Ī· J, L Ī· JżŽ spurious żŪŻ¼?a?ż╬ź░źķźšż¼Ą├żķżņżļ ?a?ż╬ź░źķźšżŪJż╚IŻ¼Jż╚DżŽd®\separated żĘż┐ż¼ż├żŲŻ¼CSI®\SEPż“ė├żżżļż│ż╚żŪŻ¼ a ż¼ėļż©żķżņż┐ż╚żŁŻ¼Jż╚Iż¼a ż╬ż╚żŁż╦d®\separatedż└ż╚Ą├ żķżņż┐ ?b?żŽa , s ż╬ż╚żŁż╦Ą├żķżņżļź░źķźš 0 0 1 1
- 41. 5.3.2 Independencies CSI®\separationżŽcontext®\specificż╩Č└┴óż“øQČ©ż╣żļż┐żßż╬źŲź╣ ź╚ż╦ė├żżżļż│ż╚ż¼│÷└┤żļ Theorem 5.3 G ż“ź═ź├ź╚ź’®`ź»śŗįņŻ¼Pż“P ?L (G)ż╩Ęų▓╝Ż¼cż“ź│ź¾źŲ źŁź╣ź╚Ż¼X, Y , Zż“ēõ╩²╝»║Žż╚ż╣żļŻ« Xż¼cż╬Ž┬żŪZż¼ėļż©żķżņż┐ż╚żŁż╦Y ż╚CSI®\separatedż╩żķŻ¼ P ? (X Ī═ T©OZ, c) Ż©į^├„żŽexercise 5.8Ż® l c
- 42. 5.3.2 Independencies Revisit Example 5.10 with CSI-sep (Example 5.19) C = c ż╩żķŻ¼L Ī· JżŽspurious Jż¼ėļż©żķżņż┐ż╚żŁŻ¼L ż╚L ż╬ķgż╦źčź╣żŽż╩żżż╬żŪ (L Ī═ L ©OJ, c )ż¼ī¦ż½żņżļ C = c ż╬ż╚żŁżŌ═¼śöż╦┐╝ż©żņżąŻ¼ĮYŠų(L Ī═ L ©OJ, C) żĘż½żĘŻ¼CSI®\SEPżŪżŽż│żņżŽī¦ż▒ż╩żż Ż©Š▀╠ÕĄ─ż╩ź│ź¾źŲźŁź╣ź╚ż¼ż╩żżż╚Ż¼spuriousż╩ź©ź├źĖż¼ż’ ż½żķż╩żżŻ® ╚½ź▒®`ź╣ż╦ż─żżżŲź┴ź¦ź├ź»ż╣żņżążżżżż¼Ż¼ ēõ╩²ż╬╩²ż└ż▒ųĖ╩²Ą─ż╦ėŗ╦Ńż¼ēł╝ėż╣żļĪŁ 1 2 1 2 1 c 2 1 2 1 c 2
- 43. 5.4 Independence of Causal Influence Šų╦∙┤_┬╩źŌźŪźļż╦ż¬ż▒żļ«Éż╩żļĘNŅÉż╬śŗįņż“ż▀żŲżżż» noisy®\or model generalized linear model
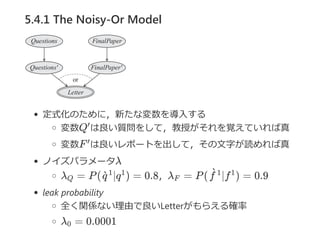
- 44. 5.4.1 The Noisy-Or Model Į╠╩┌ż¼č¦╔·ż╬═Ų╦]ū┤Ż©LetterŻ®ż“Ģ°ż»└²ż“┐╝ż©żļ Letterż╬┴╝żĄżŽŻ¼ ┴╝żż┘|å¢ż“żĘżŲżżż┐ż½ ?Question? ūŅĮKźņź▌®`ź╚ż╬│╔┐ā ?Final paper? żŪżŁż▐żĻŻ¼č¦╔·żŽüIĘĮż╚żŌ┴╝żż═Ų╦]ū┤ż“żŌżķż”ż╦╩«Ęųż└ż¼ żĮż╬č¦╔·ż╬ėĪŽ¾ż¼żóż▐żĻ▓ąż├żŲżżż╩żżł÷║Ž ūųż¼øAż»żŲźņź▌®`ź╚ż¼šiżßż╩żżł÷║Ž ż╚żżż├ż┐ź╬źżź║ż“║¼żÓ
- 45. 5.4.1 The Noisy-Or Model 2ż─ż╬ causal mechanism Į╠╩┌ż¼č¦╔·ż╬╩┌śIæBČ╚żõ┘|å¢ż“ęÖż©żŲżżż┐ P(l ©Oq , f ) = 0.8 20%żŪ┘|å¢ż“ęÖż©żŲżżż╩żż źņź▌®`ź╚ż╬╬─ūųż¼šiżßż┐ P(l ©Oq , f ) = 0.9 10%żŪźņź▌®`ź╚ż╬ūųż¼šiżßż╩żż ┘|å¢żŌęÖż©żŲżżż╩żżŻ¼źņź▌®`ź╚ż╬ūųżŌšiżßż╩żż┤_┬╩żŽŻ┐ 1 1 0 1 0 1
- 46. 5.4.1 The Noisy-Or Model ┘|å¢żŌęÖż©żŲżżż╩żżŻ¼źņź▌®`ź╚ż╬ūųżŌšiżßż╩żż 0.2 ? 0.1 = 0.02 ┴╝żż═Ų╦]ū┤ż¼żŌżķż©żļ┤_┬╩ P(l ©Oq , f ) = 0.981 1 1
- 47. 5.4.1 The Noisy-Or Model Č©╩Į╗»ż╬ż┐żßż╦Ż¼ą┬ż┐ż╩ēõ╩²ż“ī¦╚ļż╣żļ ēõ╩²Q żŽ┴╝żż┘|å¢ż“żĘżŲŻ¼Į╠╩┌ż¼żĮżņż“ęÖż©żŲżżżņżąšµ ēõ╩²F żŽ┴╝żżźņź▌®`ź╚ż“│÷żĘżŲŻ¼żĮż╬╬─ūųż¼šiżßżņżąšµ ź╬źżź║źčźķźß®`ź┐”╦ ”╦ = P( ©Oq ) = 0.8Ż¼”╦ = P( ©Of ) = 0.9 leak probability ╚½ż»ķvéSż╩żż└Ēė╔żŪ┴╝żżLetterż¼żŌżķż©żļ┤_┬╩ ”╦ = 0.0001 Īõ Īõ Q q`1 1 F f`1 1 0
- 48. 5.4.1 The Noisy-Or Model Definition 5.8 noisy®\or CPD Y ż“kéĆż╬2éÄż“ż╚żļėHX , ..., X ż“żŌż─2éÄēõ╩²ż╚ż╣żļŻ« P(y ©OX , ..., X ) = (1 ? ”╦ ) (1 ? ”╦ ) P(y ©OX , ..., X ) = 1 ? [(1 ? ”╦ ) (1 ? ”╦ )] ż╚ż╩żļk + 1éĆż╬ź╬źżź║źčźķźß®`ź┐”╦ , ”╦ , ..., ”╦ ż¼żóżņżąŻ¼ PCD P(Y ©OX , ..., X )żŽnoisy®\orżŪżóżļŻ« x ż“1, x ż“0ż╚ĮŌßŗż╣żņżąŻ¼ęįŽ┬ż╬żĶż”ż╦ēõą╬żŪżŁżļŻ« P(y ©OX , ..., X ) = (1 ? ”╦ ) (1 ? ”╦ ) 1 k 0 1 k 0 ĪŪi:X =xi i 1 i 1 1 k 0 ĪŪi:X =xi i 1 i 0 1 k 1 k i 1 i 0 0 1 k 0 i=1 ĪŪ i xi
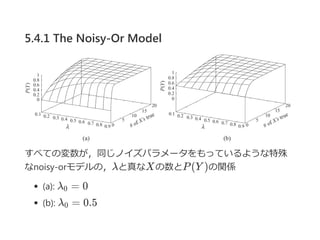
- 49. 5.4.1 The Noisy-Or Model ż╣ż┘żŲż╬ēõ╩²ż¼Ż¼═¼żĖź╬źżź║źčźķźß®`ź┐ż“żŌż├żŲżżżļżĶż”ż╩╠ž╩Ō ż╩noisy®\orźŌźŪźļż╬Ż¼”╦ż╚šµż╩Xż╬╩²ż╚P(Y )ż╬ķvéS ?a?: ”╦ = 0 ?b?: ”╦ = 0.5 0 0
- 50. 5.4.2 Generalized Linear Models causal influenceż╬Č└┴óąįż“£║ż┐ż╣«Éż╩ż├ż┐źŌźŪźļż┐ż┴ż“ Generalized Linear Modelsż╚żĶżų ČÓż»ż╬źŌźŪźļż¼┤µį┌ż╣żļż¼Ż¼ż│ż│żŪżŽY ż¼żóżļ▓╗▀BŠAż╩ėąŽ▐ ┐šķg─┌ż╬éÄż“╚Īżļ┤_┬╩Ęų▓╝P(Y ©OX , ...X )ż“Č©┴xż╣żļźŌźŪźļ ż“ÆQż” 1 k
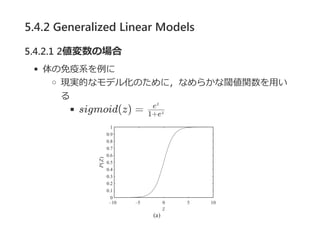
- 51. 5.4.2 Generalized Linear Models 5.4.2.1 2éÄēõ╩²ż╬ł÷║Ž ╠Õż╬├Ōę▀ŽĄż“└²ż╦ Ūų╚ļš▀żŽ╠ÕżžžōĄŻŻ©burdenŻ®ż“ż½ż▒żļ total burden ... ż╔żņż»żķżż▓ĪÜ▌ż“ę²żŁŲż│żĘżĮż”ż½ f(X , ..., X ) = w X w żŽżĮż╬žōĄŻż¼ż╔żņż█ż╔▓ĪÜ▌ż“ę²żŁŲż│ż╣ż╬ż╦ė░Ēæ ż╣żļż½ żĮż╬žōĄŻż¼ķōéÄż“│¼ż©żļż╚Ż¼░k¤ßżõżĮż╬╦¹ż╬Ėą╚Šųóż╬ųó ū┤ż¼│÷¼FżĘżŽżĖżßżļ f(X , ..., X )ż¼ķōéÄ”ėż“│¼ż©żņżąųóū┤ż¼żŪżļ f(X , ..., X ) = w + w X w = ?”ė 1 k ĪŲi=1 k i i i 1 k 1 k 0 ĪŲi=1 k i i 0
- 52. 5.4.2 Generalized Linear Models 5.4.2.1 2éÄēõ╩²ż╬ł÷║Ž ╠Õż╬├Ōę▀ŽĄż“└²ż╦ ¼FīgĄ─ż╩źŌźŪźļ╗»ż╬ż┐żßż╦Ż¼ż╩żßżķż½ż╩ķōéÄķv╩²ż“ė├żż żļ sigmoid(z) = 1+ez ez
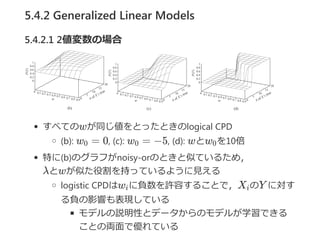
- 53. 5.4.2 Generalized Linear Models 5.4.2.1 2éÄēõ╩²ż╬ł÷║Ž Definition 5.9 logistic CPD Y ż“Ż¼╩²éÄż“ż╚żļkéĆż╬ėHX , ..., X ż“żŌż─2éÄēõ╩²ż╚ż╣żļŻ« P(y ©OX , ..., X ) = sigmoid(w + w X ) ż╬żĶż”ż╩k + 1éĆż╬ųžż▀w , w , ..., w ż¼żóżļż╩żķŻ¼ CPD P(Y ©OX , ..., X )żŽlogistic CPDżŪżóżļŻ« źčźķźß®`ź┐wżŽŻ¼Y ż╬īØ╩²ź¬ź├ź║ż╦╝░ż▄ż╣ė░Ēæż╚żżż”ĮŌßŗż¼żŪ żŁżļŻ« 2éÄēõ╩²ż╬ź¬ź├ź║▒╚żŽy ż╚y ż╬┤_┬╩▒╚ż╩ż╬żŪŻ¼ O(X) = = = e żóżļX ż¼é╬ż½żķšµż╦ż╩ż├ż┐ż╚żŁż╬ė░Ēæż“┐╝ż©żļż╚Ż¼ = = e 1 k 1 1 k 0 ĪŲi=1 k i i 0 1 k 1 k 1 0 P(y ©OX ,...,X )0 1 k P(y ©OX ,...,X )1 1 k 1/(1+e )z e /(1+e )z z z j O(X ,x )?j j 0 O(X ,x )?j j 1 exp(w + w X )0 ĪŲiĪ┘j i i exp(w + w X +w )0 ĪŲiĪ┘j i i j wj
- 54. 5.4.2 Generalized Linear Models 5.4.2.1 2éÄēõ╩²ż╬ł÷║Ž ż╣ż┘żŲż╬wż¼═¼żĖéÄż“ż╚ż├ż┐ż╚żŁż╬logical CPD ?b?: w = 0, ?c?: w = ?5, ?d?: wż╚w ż“10▒Č ╠žż╦?b?ż╬ź░źķźšż¼noisy®\orż╬ż╚żŁż╚╦ŲżŲżżżļż┐żßŻ¼ ”╦ż╚wż¼╦Ųż┐ę█ĖŅż“│ųż├żŲżżżļżĶż”ż╦ęŖż©żļ logistic CPDżŽw ż╦žō╩²ż“įS╚▌ż╣żļż│ż╚żŪŻ¼X ż╬Y ż╦īØż╣ żļžōż╬ė░ĒæżŌ▒Ē¼FżĘżŲżżżļ źŌźŪźļż╬šh├„ąįż╚źŪ®`ź┐ż½żķż╬źŌźŪźļż¼č¦┴ĢżŪżŁżļ ż│ż╚ż╬üI├µżŪā׿ņżŲżżżļ 0 0 0 i i
- 55. 5.4.2 Generalized Linear Models 5.4.2.2 ČÓéÄēõ╩²ż╬ł÷║Ž Y ż“y , ..., y ż╬č}╩²ż╬éÄż“╚ĪżļżĶż”ż╦ż╣żļż│ż╚żŪŻ¼ logistic CPDż“ČÓéÄż╦ÆłÅłżŪżŁżļ Y ż╬éÄż╬▀xÆkż╦Ż¼ż╩żßżķż½ż╩"winner®\takes®\all"ż“ė├żżżļ żóżļy ż¼1ż╦Į³żżéÄż“╚ĪżĻŻ¼żĮż╬╦¹ż¼0ż╦Į³żżéÄż“╚Īżļ Definition 5.10 multinomial logistic PCD Y ż“Ż¼kéĆż╬ėHX , ..., X ż“żŌż─méÄēõ╩²ż╚ż╣żļŻ« Ė„j = 1, ..., mż╦ż─żżżŲŻ¼ l (X , ..., X ) = w + w X P(y ©OX , ..., X ) = ż╬żĶż”ż╩k + 1éĆż╬ųžż▀w , w , ..., w ż¼żóżļż╩żķŻ¼ CPD P(Y ©OX , ..., X )żŽmultinomial logistic CPDżŪżóżļŻ« 1 n i 1 k i 1 k j,0 ĪŲi=1 k j,i i j 1 k exp(l (X ,...,X ))ĪŲj =1Īõ m jĪõ 1 k exp(l (X ,...,X ))j 1 k j,0 j,1 j,k 1 k
- 56. 5.4.2 Generalized Linear Models 5.4.2.2 ČÓéÄēõ╩²ż╬ł÷║Ž ėHX , X ż“│ųż─3éÄż╬Y ż╦ż─żżżŲż╬źŌźŪźļż╬└² ėHX ż¼2éÄęį╔Žż“╚ĪżļżĶż”ż╩ł÷║ŽżŌÆQż©żļ X = x , ..., x ż╩żķŻ¼X = jż╬ż╚żŁX = x ż╦ż╩żļ 2éÄēõ╩²X , ..., X ż“Č©┴xż╣żņżą┴╝żż méÄż“ż╚żļėHXż“żŌż─2éÄēõ╩²Y ż╩żķŻ¼m + 1éĆż╬ųžż▀ż“ ╩╣ż├żŲ P(y ©OX) = sigmoid(w + w 1{X = x }) 1 2 i i i 1 i m i i,j i,j 1 i,1 i,m 1 0 ĪŲj=1 m j j