










![global:
scrape_interval: 15s
evaluation_interval: 15s
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
ÅäÖÃĘūĀýĀýĢš](https://image.slidesharecdn.com/prometheus101-180322073533/85/Prometheus-101-12-320.jpg)

![ÎïĀíĀíÖũŧúžāŋØĢš
? node_expoter: ÎïĀíĀíŧúÔË?ÐÐÐÐŨīĖŽÐÅÏĒĘÕžŊ
? windows Ęđ?ÓÃ wmi_exporter
? ÅäÖÃĢš
scrape_con?gs:
- job_name: ĄŪnodeĄŊ
static_con?gs:
- targets: ['localhost:9100']](https://image.slidesharecdn.com/prometheus101-180322073533/85/Prometheus-101-15-320.jpg)
![ÓÅŧŊĢš
? žõÉŲĘýūÝēÉžŊÁŋÁŋ:
node_exporter --no-collector.arp --no-collector.bcache
? ―ĩĩÍĘýūÝēÉžŊÆĩÂĘĢš
scrape_con?gs:
- job_name: ĄŪnodeĄŊ
scrape_intervalĢš 30s # default is 15s
static_con?gs:
- targets: ['localhost:9100']](https://image.slidesharecdn.com/prometheus101-180322073533/85/Prometheus-101-16-320.jpg)
![CPU Ęđ?ÓÃÂĘĢš
100 - (avg by (instance) (irate(node_cpu{ mode="idle"}[5m])) * 100)](https://image.slidesharecdn.com/prometheus101-180322073533/85/Prometheus-101-17-320.jpg)






![Alertmanager ÅäÖÃĢš
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 5h
receiver: 'wechat'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname']
receivers:
- name: 'wechat'
wechat_configs:
- corp_id: ''
to_party: '1'
agent_id: '1000002'
api_secret: ''
·ÖŨéĢŽÂ·Â·ÓÉ](https://image.slidesharecdn.com/prometheus101-180322073533/85/Prometheus-101-25-320.jpg)
![Alertmanager ÅäÖÃĢš
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 5h
receiver: 'wechat'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname']
receivers:
- name: 'wechat'
wechat_configs:
- corp_id: ''
to_party: '1'
agent_id: '1000002'
api_secret: ''
―ĩÔë](https://image.slidesharecdn.com/prometheus101-180322073533/85/Prometheus-101-26-320.jpg)
![Alertmanager ÅäÖÃĢš
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 5h
receiver: 'wechat'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname']
receivers:
- name: 'wechat'
wechat_configs:
- corp_id: ''
to_party: '1'
agent_id: '1000002'
api_secret: ''
ÍĻÖŠĮþĩĀ](https://image.slidesharecdn.com/prometheus101-180322073533/85/Prometheus-101-27-320.jpg)














Prometheus 101
- 2. ķÔÓÚÎŌ ? ?ŌŧÏßÔÆžÆËãīÓŌĩÕß ? ĩį?ŨÓĘéĄķPrometheus ĘĩÕ―Ą·ŨũÕß ? Alertmanager īúÂëđąÏŨÕß ? GitHub: songjiayang ĢŽÎĒēĐĢšsmall_?sh__
- 3. ÖũĖâĢš ? Prometheus ? Alertmanager ? v1.x vs v2.x
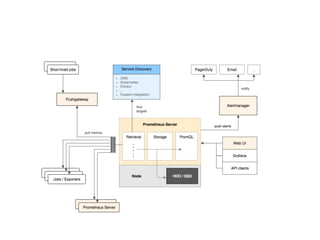
- 6. Prometheus ĘĮĢš ? žāŋØļæūŊÏĩÍģ ? ŧųÓÚÖļąęĢĻMetricĢĐ ? ĘąÐōĩÄ ? ŋŠÔīĩÄ
- 7. Prometheus ēŧēŧĘĮĢš ? trace ÏĩÍģ ? ?ČÕÖū·ÖÎö ? ÉóžÆÏĩÍģ ? Ą.
- 9. ? Why notĢŋ ? ÏÖīúĢĻ?Óà Go ąāÐīĢĐ ? ?ÎÞŌĀĀĩĢŽ°ēŨ°?·―ąãąãĢŽÉÏ?ĘÖČÝŌŨŌŨ ? šÜķāēåžþŧō exporter ? Grafana ÄŽČÏ?Ö§ģÖ ? K8s ÄŽČÏ?Ö§ģÖĢŽ?·ĮģĢĘĘšÏÔÆšÍÎĒ·þÎņ ? ÉįĮøŧîÔūĢŽËüēŧēŧ―ö―öĘĮļö?đĪūß?ķøĘĮ?ÉúĖŽ ŅĄÔņ Prometheus ĩÄÔŌōĢš
- 10. Prometheus °ēŨ°Ģš ? °ēŨ°°ü°ēŨ°ĢŽ·ÃÎĘ https://github.com/prometheus/ prometheus/releases ÏÂÔØķÔÓĶ°æąūĢŽ―âŅđžīŋÉĄĢ ? ÏĩÍģ°üđÜĀíĀí?đĪūß°ēŨ°ĢŽĀýĀýČį brew install prometheus ? Docker ūĩÏņĢš docker run --name prometheus -d -p 127.0.0.1:9090:9090 quay.io/prometheus/prometheus
- 11. Prometheus ÅäÖÃĢš ? globalĢšČŦūÖÅäÖà ? alerting: ļæūŊ―ÓĘÜĩØÖ· ? rule_?les: ļæūŊđæÔōÅäÖà ? scrape_conifgs: ĘýūÝĀČĄĩÄÅäÖÃ
- 12. global: scrape_interval: 15s evaluation_interval: 15s # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 rule_files: # - "first_rules.yml" # - "second_rules.yml" scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] ÅäÖÃĘūĀýĀýĢš
- 13. ?ŨÔīøēéŅŊ―į?ÃæĢš
- 15. ÎïĀíĀíÖũŧúžāŋØĢš ? node_expoter: ÎïĀíĀíŧúÔË?ÐÐÐÐŨīĖŽÐÅÏĒĘÕžŊ ? windows Ęđ?ÓÃ wmi_exporter ? ÅäÖÃĢš scrape_con?gs: - job_name: ĄŪnodeĄŊ static_con?gs: - targets: ['localhost:9100']
- 16. ÓÅŧŊĢš ? žõÉŲĘýūÝēÉžŊÁŋÁŋ: node_exporter --no-collector.arp --no-collector.bcache ? ―ĩĩÍĘýūÝēÉžŊÆĩÂĘĢš scrape_con?gs: - job_name: ĄŪnodeĄŊ scrape_intervalĢš 30s # default is 15s static_con?gs: - targets: ['localhost:9100']
- 17. CPU Ęđ?ÓÃÂĘĢš 100 - (avg by (instance) (irate(node_cpu{ mode="idle"}[5m])) * 100)
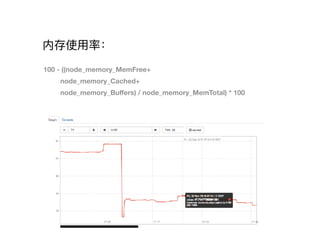
- 18. ÄÚīæĘđ?ÓÃÂĘĢš 100 - ((node_memory_MemFree+ node_memory_Cached+ node_memory_Bu?ers) / node_memory_MemTotal) * 100
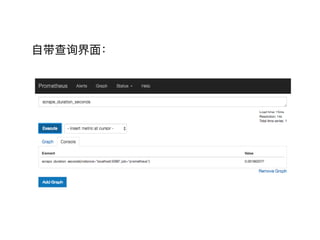
- 19. Prometheus ŨĘÁÏÁÏĢš ? Prometheus Demo ? ļüļüķāēéŅŊÓïūäūä
- 21. Alertmanager ―éÉÜĢš Prometheus ?ÓÃÓÚĘÕžŊĘýūÝĢŽAlertmanger ?ÓÃÓÚđÜĀíĀíšÍ·ĒËÍļæūŊĢŧÁ― Õß―ášÏĢŽēÅÄÜĩÄķÔÎŌÃĮŌĩÎņ―ø?ÐÐÐÐÓÐЧžāŋØĄĢ ? ―ÓĘÕļæūŊ ? ·ÖŨé ? ―ĩÔë ? ·áļŧĩÄÍĻÖŠĮþĩĀĢŽĢĻEmail, Slack, WeChat, WebhooksĄĢĐ
- 22. ÏÂÔØ°ēŨ°Ģš ? °ēŨ°°ü°ēŨ°ĢŽ·ÃÎĘ https://github.com/prometheus/ alertmanager/releases ÏÂÔØķÔÓĶ°æąūĢŽ―âŅđžīŋÉĄĢ
- 23. ŧųąūĘđ?ÓÃĢš ? Prometheus ÅäÖÃ ? Alertmanager ÅäÖÃ
- 24. Prometheus ÅäÖÃĢš ? ÐÞļÄ prometheus.yml rule_?les: - Ą°rules/node.ymlĄą ? ĖížÓ rules/node.yml ?ÎÄžþ groups: - name: node rules: - alert: InstanceDown expr: up{job=Ą°nodeĄą} == 0 for: 5m labels: severity: critical annotations: summary: "Instance {{ $labels.instance }} downĄą ? ĖížÓ alertmanager ĩØÖ· alerting: alertmanagers: - static_configs: - targets: - localhost:9093
- 25. Alertmanager ÅäÖÃĢš global: resolve_timeout: 5m route: group_by: ['alertname'] group_wait: 30s group_interval: 5m repeat_interval: 5h receiver: 'wechat' inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname'] receivers: - name: 'wechat' wechat_configs: - corp_id: '' to_party: '1' agent_id: '1000002' api_secret: '' ·ÖŨéĢŽÂ·Â·ÓÉ
- 26. Alertmanager ÅäÖÃĢš global: resolve_timeout: 5m route: group_by: ['alertname'] group_wait: 30s group_interval: 5m repeat_interval: 5h receiver: 'wechat' inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname'] receivers: - name: 'wechat' wechat_configs: - corp_id: '' to_party: '1' agent_id: '1000002' api_secret: '' ―ĩÔë
- 27. Alertmanager ÅäÖÃĢš global: resolve_timeout: 5m route: group_by: ['alertname'] group_wait: 30s group_interval: 5m repeat_interval: 5h receiver: 'wechat' inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname'] receivers: - name: 'wechat' wechat_configs: - corp_id: '' to_party: '1' agent_id: '1000002' api_secret: '' ÍĻÖŠĮþĩĀ
- 28. Alertmanager ÍĻÖŠ?ļßŋÉ?ÓÃĢš ÐÞļÄ prometheus.yml alerting: alertmanagers: - static_configs: - targets: - localhost:9093 - localhost:9094 ËĩÃũ: ÎŌÃĮēÉ?ÓÃķāļąąūĩÄ alertmanager Āī―ÓĘÕļæūŊÐÅÏĒĢŽÍĻģĢ alertmanager ÅäÖÃΊšöÂÔÂÔŧÖļīļæūŊÐÅÏĒĢŽČÃÆäÖŧ·ĒËÍ firing ļæūŊĄĢ
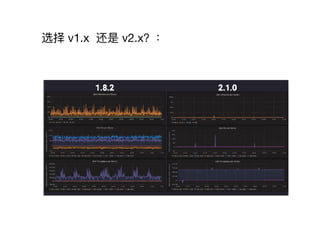
- 29. v1.x VS v2.x
- 30. ŅĄÔņ v1.x ŧđĘĮ ąđ2.ģæĢŋĢš
- 31. ŅĄÔņ v1.x ŧđĘĮ ąđ2.ģæĢŋĢš
- 32. v2.x ÐÔÄÜĖáÉý: ? Memory and CPU usage is already down ~3X ? Disk writes down by ~10X
- 34. Ęđ?ÓÃŨĒŌâĢšÏĩÍģÅäÖÃÓÅŧŊ # SSD ĩũÓÅ echo 0 > /sys/block/sdX/queue/rotational echo deadline > /sys/block/sdX/queue/scheduler # /etc/sysctl.d/local.conf vm.swappiness=1 # /etc/security/limits.d/00prometheus prometheus - no?le 10000000 # ČįđûĘđ?ÓÃĩÄĘĮ Intel CPU, Č·ąĢ scaling_governor šÍ CPU ÆĩÂĘ?ŌŧÖ intel_pstate=disable
- 35. Ęđ?ÓÃŨĒŌâĢš 2.x ÅäÖÃ ÐÂ TSDB īæīĒŌýĮæĢŽÖŧÐčŌŠ?Ōŧ?ÐÐÐÐÉčÖÃ: --storage.tsdb.retention
- 37. Éýžķ°æąūĢšīÓ 1.6x ĩ― 1.8x # ŨÜÄÚīæĩÄ 2/3 ŨóÓŌ -storage.local.target-heap-size # ÉčÖÃΊ 5m žõÉŲ SSD ĘýūÝķÁÐī -storage.local.checkpoint-interval # ČįđûÓÐ?īóÁŋÁŋĩÄ metrics ĢŽĩŦĘĮĀČĄÆĩÂĘ―ÏĩÍĢŽŋÉŌÔ―ŦÕâļöÖĩÉčÖÃΊ 10k ŌÔÉÏ -storage.local.num-?ngerprint-mutexes # ČįđûÄãĘđ?ÓÃĩÄĘĮ SSD , ÕâļöŋÉŌÔÉčÖÚÜ?ļß -storage.local.checkpoint-dirty-series-limit
- 39. ĘýūÝēÎŋž: ŧúÆũ?Ģš ? 32 cores ? 128GB RAM ? RAID 10 SSD ? Prometheus v2.1 ÐÔÄÜĢš ? 2.3M Öļąę ? 57k /s ēÉŅųĘýūÝ ? 30s ?ŌŧīÎĀČĄ ? ÃŧÓÐĘýūÝŅÓģŲ
- 41. ÍÆžöŨĘÁÏÁÏĢš ? đŲ?Íø ? GitHub ÔīÂëĢš Prometheus, Alertmanager ? https://www.robustperception.io/blog/ ĢĻēĐŋÍĢĐ ? https://kausal.co ĢĻēĐŋÍĢĐ ? https://www.weave.works ĢĻēĐŋÍĢĐ ? Prometheus up & running (ĘéžŪ) ? Monitor with Prometheus (ĘéžŪ) ? ļũÖÖŅÝ―ēļå (ppt) ? ÔÚÏßŅÝĘū Demo
- 42. Q&A Thanks