Purification of data in data warehouse after etl process
0 likes836 views
The document discusses data purification in a data warehouse. It makes three key points: 1) Data in a data warehouse comes from different source systems and is integrated together. It undergoes ETL processing to increase consistency and scope but purity cannot be guaranteed at 100%. 2) Purifying large amounts of data is challenging as the purification process is unpredictable. The document proposes dividing data by priority and purifying high priority data at 100% and medium at 50% to address this. 3) Eliminating redundant data is important as duplication is a main cause of impurity. Proper knowledge, tools, review, and maintaining priority and schedule are necessary for effective data purification.
1 of 14







Ad
Recommended
Data Preprocessing
Data PreprocessingObject-Frontier Software Pvt. Ltd
╠²
The document introduces data preprocessing techniques for data mining. It discusses why data preprocessing is important due to real-world data often being dirty, incomplete, noisy, inconsistent or duplicate. It then describes common data types and quality issues like missing values, noise, outliers and duplicates. The major tasks of data preprocessing are outlined as data cleaning, integration, transformation and reduction. Specific techniques for handling missing values, noise, outliers and duplicates are also summarized.Data preprocessing
Data preprocessingankur bhalla
╠²
Data preprocessing involves transforming raw data into an understandable and consistent format. It includes data cleaning, integration, transformation, and reduction. Data cleaning aims to fill missing values, smooth noise, and resolve inconsistencies. Data integration combines data from multiple sources. Data transformation handles tasks like normalization and aggregation to prepare the data for mining. Data reduction techniques obtain a reduced representation of data that maintains analytical results but reduces volume, such as through aggregation, dimensionality reduction, discretization, and sampling.Data Mining: Data processing
Data Mining: Data processingDataminingTools Inc
╠²
Data processing involves cleaning, integrating, transforming, reducing, and summarizing data from various sources into a coherent and useful format. It aims to handle issues like missing values, noise, inconsistencies, and volume to produce an accurate and compact representation of the original data without losing information. Some key techniques involved are data cleaning through binning, regression, and clustering to smooth or detect outliers; data integration to combine multiple sources; data transformation through smoothing, aggregation, generalization and normalization; and data reduction using cube aggregation, attribute selection, dimensionality reduction, and discretization.Data PreProcessing
Data PreProcessingtdharmaputhiran
╠²
Data preprocessing involves transforming raw data into a clean and understandable format. It includes data cleaning, integration, transformation, and reduction. Data cleaning identifies outliers and resolves inconsistencies. Data integration combines data from multiple sources. Data transformation performs operations like normalization and aggregation. Data reduction obtains a reduced representation of data to improve mining performance without losing essential information.ETL Testing Training Presentation
ETL Testing Training PresentationApurba Biswas
╠²
The document discusses ETL (extract, transform, load) which is a process used to clean and prepare data from various sources for analysis in a data warehouse. It describes how ETL extracts data from different source systems, transforms it into a uniform format, and loads it into a data warehouse. It also provides examples of ETL tools, the purpose of ETL testing including testing for data accuracy and integrity, and SQL queries commonly used for ETL testing.Recipe 5 of Data Warehouse and Business Intelligence - The null values manage...
Recipe 5 of Data Warehouse and Business Intelligence - The null values manage...Massimo Cenci
╠²
This document discusses best practices for managing NULL values in the ETL process for a data warehouse. It recommends:
1. Do not allow NULL values in the data warehouse and replace them with default values during the staging process. This avoids issues when querying or aggregating data.
2. Simplify data types and use consistent default values like '?' for text, 0 for numbers, and 99991231 for dates to replace NULLs.
3. Exceptions to the default values can be set based on business requirements and stored in configuration tables to generate dynamic SQL.
4. Create staging tables with default values set, load data from source systems while preserving the original values, then enrich the data with default valuesEtl process in data warehouse
Etl process in data warehouseKomal Choudhary
╠²
The ETL process in data warehousing involves extraction, transformation, and loading of data. Data is extracted from operational databases, transformed to match the data warehouse schema, and loaded into the data warehouse database. As source data and business needs change, the ETL process must also evolve to maintain the data warehouse's value as a business decision making tool. The ETL process consists of extracting data from sources, transforming it to resolve conflicts and quality issues, and loading it into the target data warehouse structures.ETL Process
ETL ProcessKarthik Selvaraj
╠²
ETL stands for Extraction, Transformation, and Loading. The document describes an example ETL process to load master customer data from an Excel file into an SAP BI platform. First, the data is extracted from the Excel file into the BI data warehouse using a data source and info package. Next, the data in the persistent staging area is transformed by defining the customer ID and name fields as characteristic info objects. Finally, a data transfer process loads the mapped data from the source into the appropriate info objects, completing the ETL process.A ROBUST APPROACH FOR DATA CLEANING USED BY DECISION TREE
A ROBUST APPROACH FOR DATA CLEANING USED BY DECISION TREEijcsa
╠²
The document presents a framework for robust data cleaning using the decision tree induction method to ensure high data quality in enterprise data warehouses. It details the processes of data cleansing, including investigation, standardization, deduplication, and transformation, necessary for accurate and consistent data analysis. The proposed framework aims to effectively integrate and clean heterogeneous data sources, addressing common issues like missing values, dummy and cryptic data.thegrowingimportanceofdatacleaning-211202141902.pptx
thegrowingimportanceofdatacleaning-211202141902.pptxYashaswiniSrinivasan1
╠²
The global data cleaning tools market is growing due to increased digitization from the COVID-19 pandemic. Data cleaning is the process of removing duplicate, inaccurate, or incomplete data from databases. It is important for obtaining clean data that can be analyzed without false conclusions. The benefits of data cleaning include removing errors, better reporting, and increased productivity from high-quality data.The Growing Importance of Data Cleaning
The Growing Importance of Data CleaningCarolineSmith912130
╠²
The global data cleaning tools market is projected to grow significantly due to increased digitization during the COVID-19 pandemic, highlighting the necessity for data cleansing to remove inaccuracies and duplicates. Data cleaning is essential for accurate analysis, helping businesses derive insights while avoiding erroneous conclusions. Implementing effective data cleaning processes leads to improved data quality, increased productivity, and better decision-making capabilities.Module-1.pptxcjxifkgzkzigoyxyxoxoyztiai. Tisi
Module-1.pptxcjxifkgzkzigoyxyxoxoyztiai. TisiArunnaik63
╠²
The document provides an overview of data analysis and visualization, covering topics such as data collection methods, data preparation, data cleaning, and transformation processes. It introduces Python libraries like NumPy and Pandas used for these tasks, emphasizing the importance of data abstraction, validation, and visualization in decision-making. Additionally, the document outlines various techniques and challenges faced in data management and offers insights into the benefits of effective data handling.Presentation by Ivan Schotsmans (DV Community) at the Data Vault Modelling an...
Presentation by Ivan Schotsmans (DV Community) at the Data Vault Modelling an...Patrick Van Renterghem
╠²
The document discusses data quality integration within data warehouse architecture, emphasizing the need for a structured data strategy to improve decision-making capabilities. A focus on roles like data owners, stewards, and engineers is highlighted to ensure effective data management and governance. Challenges faced include disparate data cycles, necessitating a shift towards a comparate data cycle for enhanced accessibility and trust in data.Data Warehouse
Data WarehouseSamir Sabry
╠²
This document provides an overview of key concepts in data warehousing including:
1. The need for data warehousing to consolidate data from multiple sources and support decision making.
2. Common data warehouse architectures like the two-tier architecture and data marts.
3. The extract, transform, load (ETL) process used to reconcile data and populate the data warehouse.Top 30 Data Analyst Interview Questions.pdf
Top 30 Data Analyst Interview Questions.pdfShaikSikindar1
╠²
The document outlines the top 30 interview questions for data analysts, highlighting essential skills required for the role, such as statistical knowledge, programming abilities, and familiarity with data cleaning processes. It distinguishes between data mining and data analytics, describes the data analytics process, and covers common challenges faced by analysts, including data validation and handling missing data. Additionally, it introduces various statistical techniques and methodologies relevant for effective data analysis, providing insights into job expectations and the future of the data analytics field.DemographicsClients NameAddressCityStateZipPhone NumberDate of Bi.docx
DemographicsClients NameAddressCityStateZipPhone NumberDate of Bi.docxsimonithomas47935
╠²
The document outlines the challenges and solutions related to data cleaning, particularly in the context of integrating heterogeneous data sources and data warehouses. It classifies data quality problems and discusses how these issues arise at both the schema and instance levels, emphasizing the importance of proper design and integrity constraints to prevent dirty data. The document also highlights the need for effective tool support for data cleaning processes during extraction, transformation, and loading (ETL) to ensure accurate and consistent data for decision-making.IRJET- A Review of Data Cleaning and its Current Approaches
IRJET- A Review of Data Cleaning and its Current ApproachesIRJET Journal
╠²
This document summarizes various approaches to data cleaning. It begins by stating that data cleaning is an important preprocessing step in data mining to detect and remove corrupted, inaccurate, or inconsistent data. It then reviews several common data cleaning techniques, including constraint-based data repairing, statistical methods, interactive approaches, Hadoop-based distributed cleaning, and clustering-based outlier detection. The document concludes that the appropriate cleaning approach depends on the type of data but the overall goal is to improve data quality and accuracy for downstream analysis and mining.Data Cleaning Service for Data Warehouse: An Experimental Comparative Study o...
Data Cleaning Service for Data Warehouse: An Experimental Comparative Study o...TELKOMNIKA JOURNAL
╠²
The document presents a comparative study on data cleaning services for data warehouses, specifically focusing on duplicate elimination methods. It examines various duplicate detection services through experiments, highlighting issues like different spellings, misspellings, and name abbreviations that affect data quality. The findings suggest that certain services outperform others in specific scenarios, emphasizing the importance of data quality improvement in organizational data management.Role of Data Cleaning in Data Warehouse
Role of Data Cleaning in Data WarehouseRamakant Soni
╠²
Data cleaning is an essential part of building a data warehouse as it improves data quality by detecting and removing errors and inconsistencies. Data warehouses integrate large amounts of data from various sources, so the probability of dirty data is high. Clean data is vital for decision making based on the data warehouse. The data cleaning process involves data analysis, defining transformation rules, verification of cleaning, applying transformations, and incorporating cleaned data. Tools can help support the different phases of data cleaning from data profiling to specialized cleaning of particular domains.Intro to Data warehousing lecture 10
Intro to Data warehousing lecture 10AnwarrChaudary
╠²
The document discusses the details of data extraction, transformation, and loading (ETL) processes, focusing on change data capture (CDC) in both modern and legacy systems. It highlights the advantages and challenges of identifying modified data, the necessity of data cleansing, and common anomalies that arise. Additionally, it outlines various data transformation types and methods to address data quality issues.Data Preparation.pptx
Data Preparation.pptxDrAbhishekKumarSingh3
╠²
The document discusses various aspects of data preparation including data issues, the data preparation process, reasons for data preparation, benefits of data preparation, and key steps in data preparation such as data profiling, cleaning, integration, transformation, discretization, and binning. Specifically, it covers profiling data to ensure quality, cleaning data by handling anomalies and missing values, integrating and enriching data from multiple sources, transforming data for modeling purposes, discretizing continuous variables, and binning data to reduce effects of small errors. The overall goal of data preparation is to organize and structure raw data for analysis and modeling.Data warehouse
Data warehouseSamir Sabry
╠²
The document discusses various concepts related to data warehousing including:
1. The key characteristics of a data warehouse including being subject-oriented, integrated, time-variant, and non-updatable.
2. Common data warehouse architectures including two-level, independent data marts, dependent data marts with an operational data store, logical data marts with an active warehouse, and a three-layer architecture.
3. The Extract, Transform, Load (ETL) process and data reconciliation to integrate and transform data from source systems into the data warehouse.the study of data to extract meaningful insights for business
the study of data to extract meaningful insights for businessEyobTemesgen3
╠²
Chapter 2 of the introduction to data science provides a comprehensive overview of the field, including definitions of data and information, types of data, and the data value chain. It highlights the importance of data science in decision-making and predictions, detailing processes like data acquisition, analysis, curation, storage, and usage, as well as introducing big data concepts and the Hadoop ecosystem. The chapter emphasizes the evolving nature of data science as a multi-disciplinary field and its relevance in the modern data-driven landscape.Fit l05 data_processing
Fit l05 data_processingAakash software cell Gujrat.
╠²
The document discusses data and information processing. It defines data as raw unprocessed facts and figures, while information is processed data that provides meaning. There are two main types of data: numeric and character. Data processing involves collecting, organizing, and analyzing data to convert it into useful information. The data processing cycle has three steps: input, processing, and output. Processing techniques classify, sort, calculate, and summarize data. There are different types of data processing like manual, electronic, real-time, and batch processing.Developing A Universal Approach to Cleansing Customer and Product Data
Developing A Universal Approach to Cleansing Customer and Product DataFindWhitePapers
╠²
The document discusses the importance of data quality for businesses, highlighting that poor data quality can significantly impact financial performance. It emphasizes the need for a universal approach to data cleansing and management, especially regarding customer and product data, and illustrates how organizations can improve data quality through structured programs and tools. Case studies and industry surveys are used to demonstrate the relevance of data quality initiatives in enhancing operational efficiency and business decision-making.Data Quality in Data Warehouse and Business Intelligence Environments - Disc...
Data Quality in Data Warehouse and Business Intelligence Environments - Disc...Alan D. Duncan
╠²
This document discusses the significance of data quality in data warehousing (DW) and business intelligence (BI) environments, highlighting that over 50% of such projects fail due to overlooked data quality issues. It advocates for a 'data quality by design' approach, integrating data quality techniques throughout the stages of DW/BI implementation to improve project success and ensure better decision-making. The author emphasizes the need for proactive data quality measures, such as profiling and validation, to enhance trust in analytics and ultimately drive business value.DataManipulationTimeSeriesHandling asdfadsfas
DataManipulationTimeSeriesHandling asdfadsfasDrManojMV
╠²
The document outlines data manipulation techniques, including basic methods such as sorting, filtering, and aggregation, as well as advanced techniques like joins and pivoting. It also details data cleaning processes for addressing issues such as missing values and formatting inconsistencies. Additionally, it covers the relevance of time series data analysis and highlights Python libraries suitable for such tasks.CS3C - Jonbon Libreja
CS3C - Jonbon LibrejaPog Arenas
╠²
The document discusses data, types of data, data processing, and computer processing operations. It defines data as facts or figures that are input into a computer. There are two main types of data: numeric data represented by numbers, and character data like strings and graphical images. Data processing involves collecting data, processing it to convert it into useful information through activities like classification, calculation, and summarization, and outputting the results. Computer processing operations that enable data processing are input/output, calculation, logic/comparison, and storage and retrieval.2025 June Year 9 Presentation: Subject selection.pptx
2025 June Year 9 Presentation: Subject selection.pptxmansk2
╠²
2025 June Year 9 Presentation: Subject selectionHow to Manage Inventory Movement in Odoo 18 POS
How to Manage Inventory Movement in Odoo 18 POSCeline George
╠²
Inventory management in the Odoo 18 Point of Sale system is tightly integrated with the inventory module, offering a solution to businesses to manage sales and stock in one united system.More Related Content
Similar to Purification of data in data warehouse after etl process (20)
A ROBUST APPROACH FOR DATA CLEANING USED BY DECISION TREE
A ROBUST APPROACH FOR DATA CLEANING USED BY DECISION TREEijcsa
╠²
The document presents a framework for robust data cleaning using the decision tree induction method to ensure high data quality in enterprise data warehouses. It details the processes of data cleansing, including investigation, standardization, deduplication, and transformation, necessary for accurate and consistent data analysis. The proposed framework aims to effectively integrate and clean heterogeneous data sources, addressing common issues like missing values, dummy and cryptic data.thegrowingimportanceofdatacleaning-211202141902.pptx
thegrowingimportanceofdatacleaning-211202141902.pptxYashaswiniSrinivasan1
╠²
The global data cleaning tools market is growing due to increased digitization from the COVID-19 pandemic. Data cleaning is the process of removing duplicate, inaccurate, or incomplete data from databases. It is important for obtaining clean data that can be analyzed without false conclusions. The benefits of data cleaning include removing errors, better reporting, and increased productivity from high-quality data.The Growing Importance of Data Cleaning
The Growing Importance of Data CleaningCarolineSmith912130
╠²
The global data cleaning tools market is projected to grow significantly due to increased digitization during the COVID-19 pandemic, highlighting the necessity for data cleansing to remove inaccuracies and duplicates. Data cleaning is essential for accurate analysis, helping businesses derive insights while avoiding erroneous conclusions. Implementing effective data cleaning processes leads to improved data quality, increased productivity, and better decision-making capabilities.Module-1.pptxcjxifkgzkzigoyxyxoxoyztiai. Tisi
Module-1.pptxcjxifkgzkzigoyxyxoxoyztiai. TisiArunnaik63
╠²
The document provides an overview of data analysis and visualization, covering topics such as data collection methods, data preparation, data cleaning, and transformation processes. It introduces Python libraries like NumPy and Pandas used for these tasks, emphasizing the importance of data abstraction, validation, and visualization in decision-making. Additionally, the document outlines various techniques and challenges faced in data management and offers insights into the benefits of effective data handling.Presentation by Ivan Schotsmans (DV Community) at the Data Vault Modelling an...
Presentation by Ivan Schotsmans (DV Community) at the Data Vault Modelling an...Patrick Van Renterghem
╠²
The document discusses data quality integration within data warehouse architecture, emphasizing the need for a structured data strategy to improve decision-making capabilities. A focus on roles like data owners, stewards, and engineers is highlighted to ensure effective data management and governance. Challenges faced include disparate data cycles, necessitating a shift towards a comparate data cycle for enhanced accessibility and trust in data.Data Warehouse
Data WarehouseSamir Sabry
╠²
This document provides an overview of key concepts in data warehousing including:
1. The need for data warehousing to consolidate data from multiple sources and support decision making.
2. Common data warehouse architectures like the two-tier architecture and data marts.
3. The extract, transform, load (ETL) process used to reconcile data and populate the data warehouse.Top 30 Data Analyst Interview Questions.pdf
Top 30 Data Analyst Interview Questions.pdfShaikSikindar1
╠²
The document outlines the top 30 interview questions for data analysts, highlighting essential skills required for the role, such as statistical knowledge, programming abilities, and familiarity with data cleaning processes. It distinguishes between data mining and data analytics, describes the data analytics process, and covers common challenges faced by analysts, including data validation and handling missing data. Additionally, it introduces various statistical techniques and methodologies relevant for effective data analysis, providing insights into job expectations and the future of the data analytics field.DemographicsClients NameAddressCityStateZipPhone NumberDate of Bi.docx
DemographicsClients NameAddressCityStateZipPhone NumberDate of Bi.docxsimonithomas47935
╠²
The document outlines the challenges and solutions related to data cleaning, particularly in the context of integrating heterogeneous data sources and data warehouses. It classifies data quality problems and discusses how these issues arise at both the schema and instance levels, emphasizing the importance of proper design and integrity constraints to prevent dirty data. The document also highlights the need for effective tool support for data cleaning processes during extraction, transformation, and loading (ETL) to ensure accurate and consistent data for decision-making.IRJET- A Review of Data Cleaning and its Current Approaches
IRJET- A Review of Data Cleaning and its Current ApproachesIRJET Journal
╠²
This document summarizes various approaches to data cleaning. It begins by stating that data cleaning is an important preprocessing step in data mining to detect and remove corrupted, inaccurate, or inconsistent data. It then reviews several common data cleaning techniques, including constraint-based data repairing, statistical methods, interactive approaches, Hadoop-based distributed cleaning, and clustering-based outlier detection. The document concludes that the appropriate cleaning approach depends on the type of data but the overall goal is to improve data quality and accuracy for downstream analysis and mining.Data Cleaning Service for Data Warehouse: An Experimental Comparative Study o...
Data Cleaning Service for Data Warehouse: An Experimental Comparative Study o...TELKOMNIKA JOURNAL
╠²
The document presents a comparative study on data cleaning services for data warehouses, specifically focusing on duplicate elimination methods. It examines various duplicate detection services through experiments, highlighting issues like different spellings, misspellings, and name abbreviations that affect data quality. The findings suggest that certain services outperform others in specific scenarios, emphasizing the importance of data quality improvement in organizational data management.Role of Data Cleaning in Data Warehouse
Role of Data Cleaning in Data WarehouseRamakant Soni
╠²
Data cleaning is an essential part of building a data warehouse as it improves data quality by detecting and removing errors and inconsistencies. Data warehouses integrate large amounts of data from various sources, so the probability of dirty data is high. Clean data is vital for decision making based on the data warehouse. The data cleaning process involves data analysis, defining transformation rules, verification of cleaning, applying transformations, and incorporating cleaned data. Tools can help support the different phases of data cleaning from data profiling to specialized cleaning of particular domains.Intro to Data warehousing lecture 10
Intro to Data warehousing lecture 10AnwarrChaudary
╠²
The document discusses the details of data extraction, transformation, and loading (ETL) processes, focusing on change data capture (CDC) in both modern and legacy systems. It highlights the advantages and challenges of identifying modified data, the necessity of data cleansing, and common anomalies that arise. Additionally, it outlines various data transformation types and methods to address data quality issues.Data Preparation.pptx
Data Preparation.pptxDrAbhishekKumarSingh3
╠²
The document discusses various aspects of data preparation including data issues, the data preparation process, reasons for data preparation, benefits of data preparation, and key steps in data preparation such as data profiling, cleaning, integration, transformation, discretization, and binning. Specifically, it covers profiling data to ensure quality, cleaning data by handling anomalies and missing values, integrating and enriching data from multiple sources, transforming data for modeling purposes, discretizing continuous variables, and binning data to reduce effects of small errors. The overall goal of data preparation is to organize and structure raw data for analysis and modeling.Data warehouse
Data warehouseSamir Sabry
╠²
The document discusses various concepts related to data warehousing including:
1. The key characteristics of a data warehouse including being subject-oriented, integrated, time-variant, and non-updatable.
2. Common data warehouse architectures including two-level, independent data marts, dependent data marts with an operational data store, logical data marts with an active warehouse, and a three-layer architecture.
3. The Extract, Transform, Load (ETL) process and data reconciliation to integrate and transform data from source systems into the data warehouse.the study of data to extract meaningful insights for business
the study of data to extract meaningful insights for businessEyobTemesgen3
╠²
Chapter 2 of the introduction to data science provides a comprehensive overview of the field, including definitions of data and information, types of data, and the data value chain. It highlights the importance of data science in decision-making and predictions, detailing processes like data acquisition, analysis, curation, storage, and usage, as well as introducing big data concepts and the Hadoop ecosystem. The chapter emphasizes the evolving nature of data science as a multi-disciplinary field and its relevance in the modern data-driven landscape.Fit l05 data_processing
Fit l05 data_processingAakash software cell Gujrat.
╠²
The document discusses data and information processing. It defines data as raw unprocessed facts and figures, while information is processed data that provides meaning. There are two main types of data: numeric and character. Data processing involves collecting, organizing, and analyzing data to convert it into useful information. The data processing cycle has three steps: input, processing, and output. Processing techniques classify, sort, calculate, and summarize data. There are different types of data processing like manual, electronic, real-time, and batch processing.Developing A Universal Approach to Cleansing Customer and Product Data
Developing A Universal Approach to Cleansing Customer and Product DataFindWhitePapers
╠²
The document discusses the importance of data quality for businesses, highlighting that poor data quality can significantly impact financial performance. It emphasizes the need for a universal approach to data cleansing and management, especially regarding customer and product data, and illustrates how organizations can improve data quality through structured programs and tools. Case studies and industry surveys are used to demonstrate the relevance of data quality initiatives in enhancing operational efficiency and business decision-making.Data Quality in Data Warehouse and Business Intelligence Environments - Disc...
Data Quality in Data Warehouse and Business Intelligence Environments - Disc...Alan D. Duncan
╠²
This document discusses the significance of data quality in data warehousing (DW) and business intelligence (BI) environments, highlighting that over 50% of such projects fail due to overlooked data quality issues. It advocates for a 'data quality by design' approach, integrating data quality techniques throughout the stages of DW/BI implementation to improve project success and ensure better decision-making. The author emphasizes the need for proactive data quality measures, such as profiling and validation, to enhance trust in analytics and ultimately drive business value.DataManipulationTimeSeriesHandling asdfadsfas
DataManipulationTimeSeriesHandling asdfadsfasDrManojMV
╠²
The document outlines data manipulation techniques, including basic methods such as sorting, filtering, and aggregation, as well as advanced techniques like joins and pivoting. It also details data cleaning processes for addressing issues such as missing values and formatting inconsistencies. Additionally, it covers the relevance of time series data analysis and highlights Python libraries suitable for such tasks.CS3C - Jonbon Libreja
CS3C - Jonbon LibrejaPog Arenas
╠²
The document discusses data, types of data, data processing, and computer processing operations. It defines data as facts or figures that are input into a computer. There are two main types of data: numeric data represented by numbers, and character data like strings and graphical images. Data processing involves collecting data, processing it to convert it into useful information through activities like classification, calculation, and summarization, and outputting the results. Computer processing operations that enable data processing are input/output, calculation, logic/comparison, and storage and retrieval.Presentation by Ivan Schotsmans (DV Community) at the Data Vault Modelling an...
Presentation by Ivan Schotsmans (DV Community) at the Data Vault Modelling an...Patrick Van Renterghem
╠²
Data Cleaning Service for Data Warehouse: An Experimental Comparative Study o...
Data Cleaning Service for Data Warehouse: An Experimental Comparative Study o...TELKOMNIKA JOURNAL
╠²
Recently uploaded (20)
2025 June Year 9 Presentation: Subject selection.pptx
2025 June Year 9 Presentation: Subject selection.pptxmansk2
╠²
2025 June Year 9 Presentation: Subject selectionHow to Manage Inventory Movement in Odoo 18 POS
How to Manage Inventory Movement in Odoo 18 POSCeline George
╠²
Inventory management in the Odoo 18 Point of Sale system is tightly integrated with the inventory module, offering a solution to businesses to manage sales and stock in one united system.K12 Tableau User Group virtual event June 18, 2025
K12 Tableau User Group virtual event June 18, 2025dogden2
╠²
National K12 Tableau User Group: June 2025 meeting slidesLDMMIA Practitioner Student Reiki Yoga S2 Video PDF Without Yogi Goddess
LDMMIA Practitioner Student Reiki Yoga S2 Video PDF Without Yogi GoddessLDM & Mia eStudios
╠²
A bonus dept update. Happy Summer 25 almost. Do Welcome or Welcome back. Our 10th Free workshop will be released the end of this week, June 20th Weekend. All Materials/updates/Workshops are timeless for future students.
ŌÖź Your Attendance is valued.
We hit over 5k views for Spring Workshops and Updates-TY.
ŌÖź Coming to our Shop This Weekend.
Timeless for Future Grad Level Students.
Practitioner Student. Level/Session 2 Packages.
* ŌÖźThe Review & Topics:
* All virtual, adult, education students must be over 18 years to attend LDMMIA eClasses and vStudio Thx.
* Please refer to our Free Workshops anytime for review/notes.
* Orientation Counts as S1 on introduction. Sold Separately as a PDF. Our S2 includes 2 Videos within 2 Mp4s. Sold Separately for Uploading.
* Reiki Is Japanese Energy Healing used Globally.
* Yoga is over 5k years old from India. It hosts many styles, teacher versions, and itŌĆÖs Mainstream now vs decades ago.
* Teaching Vod, 720 Res, Mp4: Yoga Therapy is Reviewed as a Hatha, Classical, Med Yoga (ND) Base. Take practice notes as needed or repeat videos.
* Fused Teaching Vod, 720 Res, Mp4: Yoga Therapy Meets Reiki Review. Take Practice notes as needed or repeat videos.
* Video, 720 Res, Mp4: Practitioner Congrats and Workshop Visual Review with Suggestions.
ŌÖź Bonus Studio Video, 720 Res, Mp4: Our 1st Reiki Video. Produced under Yogi Goddess, LDM Recording. As a Reiki, Kundalini, ASMR Spa, Music Visual. For Our Remastered, Beatz Single for Goddess Vevo Watchers. https://www.reverbnation.com/yogigoddess
* ŌÖź Our Videos are Vevo TV and promoted within the LDMMIA Profiles.
* Scheduled upload for or by Weekend Friday June 13th.
* LDMMIA Digital & Merch Shop: https://ldm-mia.creator-spring.com
* ŌÖź As a student, make sure you have high speed connections/wifi for attendance. This sounds basic, I know lol. But, for our video section. The High Speed and Tech is necessary. Otherwise, any device can be used. Our Zip drive files should serve MAC/PC as well.
* ŌÖź On TECH Emergency: I have had some rare, rough, horrid timed situations as a Remote Student. Pros and Cons to being on campus. So Any Starbucks (coffee shop) or library can be used for wifi hot spots. You can work at your own speed and pace.
* ŌÖź We will not be hosting deadlines, tests/exams.
* ŌÖźAny homework will be session practice and business planning. Nothing stressful or assignment submissions.
Non-Communicable Diseases and National Health Programs ŌĆō Unit 10 | B.Sc Nursi...
Non-Communicable Diseases and National Health Programs ŌĆō Unit 10 | B.Sc Nursi...RAKESH SAJJAN
╠²
This PowerPoint presentation is prepared for Unit 10 ŌĆō Non-Communicable Diseases and National Health Programs, as per the 5th Semester B.Sc Nursing syllabus outlined by the Indian Nursing Council (INC) under the subject Community Health Nursing ŌĆō I.
This unit focuses on equipping students with knowledge of the causes, prevention, and control of non-communicable diseases (NCDs), which are a major public health challenge in India. The presentation emphasizes the nurseŌĆÖs role in early detection, screening, management, and referral services under national-level programs.
¤ö╣ Key Topics Included:
Definition, burden, and impact of NCDs in India
Epidemiology, risk factors, signs/symptoms, prevention, and management of:
Diabetes Mellitus
Hypertension
Cardiovascular Diseases
Stroke & Obesity
Thyroid Disorders
Blindness
Deafness
Injuries and Accidents (incl. road traffic injuries and trauma guidelines)
NCD-2 Cancers:
Breast Cancer
Cervical Cancer
Oral Cancer
Risk factors, screening, diagnosis, early signs, referral & palliative care
Role of nurse in screening, referral, counseling, and continuum of care
National Programs:
National Program for Prevention and Control of Cancer, Diabetes, Cardiovascular Diseases and Stroke (NPCDCS)
National Program for Control of Blindness
National Program for Prevention and Control of Deafness
National Tobacco Control Program (NTCP)
Introduction to Universal Health Coverage and Ayushman Bharat
Use of standard treatment protocols and referral flowcharts
This presentation is ideal for:
Classroom lectures, field assignments, health education planning, and student projects
Preparing for university exams, class tests, and community field postingsUniversity of Ghana Cracks Down on Misconduct: Over 100 Students Sanctioned
University of Ghana Cracks Down on Misconduct: Over 100 Students SanctionedKweku Zurek
╠²
University of Ghana Cracks Down on Misconduct: Over 100 Students Sanctioned
Introduction to Generative AI and Copilot.pdf
Introduction to Generative AI and Copilot.pdfTechSoup
╠²
In this engaging and insightful two-part webinar series, where we will dive into the essentials of generative AI, address key AI concerns, and demonstrate how nonprofits can benefit from using MicrosoftŌĆÖs AI assistant, Copilot, to achieve their goals.
This event series to help nonprofits obtain Copilot skills is made possible by generous support from Microsoft.ROLE PLAY: FIRST AID -CPR & RECOVERY POSITION.pptx
ROLE PLAY: FIRST AID -CPR & RECOVERY POSITION.pptxBelicia R.S
╠²
Role play : First Aid- CPR, Recovery position and Hand hygiene.
Scene 1: Three friends are shopping in a mall
Scene 2: One of the friend becomes victim to electric shock.
Scene 3: Arrival of a first aider
Steps:
Safety First
Evaluate the victimŌĆśs condition
Call for help
Perform CPR- Secure an open airway, Chest compression, Recuse breaths.
Put the victim in Recovery position if unconscious and breathing normally.
ABCs of Bookkeeping for Nonprofits TechSoup.pdf
ABCs of Bookkeeping for Nonprofits TechSoup.pdfTechSoup
╠²
Accounting can be hard enough if you havenŌĆÖt studied it in school. Nonprofit accounting is actually very different and more challenging still.
Need help? Join Nonprofit CPA and QuickBooks expert Gregg Bossen in this first-time webinar and learn the ABCs of keeping books for a nonprofit organization.
Key takeaways
* What accounting is and how it works
* How to read a financial statement
* What financial statements should be given to the board each month
* What three things nonprofits are required to track
What features to use in QuickBooks to track programs and grantsLDMMIA Yoga S10 Free Workshop Grad Level
LDMMIA Yoga S10 Free Workshop Grad LevelLDM & Mia eStudios
╠²
This is complete for June 17th. For the weekend of Summer Solstice
June 20th-22nd.
6/17/25: ŌĆ£My now Grads, YouŌĆÖre doing well. I applaud your efforts to continue. We all are shifting to new paradigm realities. Its rough, thereŌĆÖs good and bad days/weeks. However, Reiki with Yoga assistance, does work.ŌĆØ
6/18/25: "For those planning the Training Program Do Welcome. Happy Summer 2k25. You are not ignored and much appreciated. Our updates are ongoing and weekly since Spring. I Hope you Enjoy the Practitioner Grad Level. There's more to come. We will also be wrapping up Level One. So I can work on Levels 2 topics. Please see documents for any news updates. Also visit our websites. Every decade I release a Campus eMap. I will work on that for summer 25. We have 2 old libraries online thats open. https://ldmchapels.weebly.com "
Your virtual attendance is appreciated. No admissions or registration needed.
We hit over 5k views for Spring Workshops and Updates-TY.
As a Guest Student,
You are now upgraded to Grad Level.
See Uploads for ŌĆ£Student CheckinsŌĆØ & ŌĆ£S9ŌĆØ. Thx.
Happy Summer 25.
These are also timeless.
Thank you for attending our workshops.
If you are new, do welcome.
For visual/Video style learning see our practitioner student status.
This is listed under our new training program. Updates ongoing levels 1-3 this summer. We just started Session 1 for level 1.
These are optional programs. I also would like to redo our library ebooks about Hatha and Money Yoga. THe Money Yoga was very much energy healing without the Reiki Method. An updated ebook/course will be done this year. These Projects are for *all fans, followers, teams, and Readers. TY for being presenting.THE PSYCHOANALYTIC OF THE BLACK CAT BY EDGAR ALLAN POE (1).pdf
THE PSYCHOANALYTIC OF THE BLACK CAT BY EDGAR ALLAN POE (1).pdfnabilahk908
╠²
Psychoanalytic Analysis of The Black Cat by Edgar Allan Poe explores the deep psychological dimensions of the narratorŌĆÖs disturbed mind through the lens of Sigmund FreudŌĆÖs psychoanalytic theory. According to Freud (1923), the human psyche is structured into three components: the Id, which contains primitive and unconscious desires; the Ego, which operates on the reality principle and mediates between the Id and the external world; and the Superego, which reflects internalized moral standards.
In this story, Poe presents a narrator who experiences a psychological breakdown triggered by repressed guilt, aggression, and internal conflict. This analysis focuses not only on the gothic horror elements of the narrative but also on the narratorŌĆÖs mental instability and emotional repression, demonstrating how the imbalance of these three psychic forces contributes to his downfall.LDM Recording Presents Yogi Goddess by LDMMIA
LDM Recording Presents Yogi Goddess by LDMMIALDM & Mia eStudios
╠²
A bonus dept update. Happy Summer 25 almost. Do Welcome or Welcome back. Our 10th Free workshop will be released the end of this week, June 20th Weekend. All Materials/updates/Workshops are timeless for future students.
6/17/25: ŌĆ£My now Grads, YouŌĆÖre doing well. I applaud your efforts to continue. We all are shifting to new paradigm realities. Its rough, thereŌĆÖs good and bad days/weeks. However, Reiki with Yoga assistance, does work.ŌĆØ
6/18/25: "For those planning the Training Program Do Welcome. Happy Summer 2k25. You are not ignored and much appreciated. Our updates are ongoing and weekly since Spring. I Hope you Enjoy the Practitioner Grad Level. There's more to come. We will also be wrapping up Level One. So I can work on Levels 2 topics. Please see documents for any news updates. Also visit our websites. Every decade I release a Campus eMap. I will work on that for summer 25. We have 2 old libraries online thats open. https://ldmchapels.weebly.com "
A Safe House,
sanctuary of virtual relaxation and rejuvenation.
By ┬®YogiGoddess of ┬®LDMMIA, ┬®LDMYoga.
ŌÖźTeacher Dept: (Rev Dr) Leslie Moore, ND Yoga (Aide/LPN Trained), Metaphysician,
Using Reiki Practitioner/Master Level Trained.
#yogigoddess @YogiGoddessVEVO
ŌÖźLDMMIA & Depts: are fusing the fan clubs so do welcome.
We are timeless and a safe haven / Cyber Space. ThatŌĆÖs the design of our Fan/Reader/Loyal Blog.ŌÖź
LDM HQ Est. in Ann Arbor, MI 2005.
- Moved to Detroit in 2006,
- Expanded online 2007-2024+
- Became a Beatz Studio in 2009 as Yogi Goddess. After our Apple Podcast
- Relocated to Mount Pleasant MI for College The Pandemic Ending.
- Endemic - Present; Moved back to assist Family in Metro Detroit.
Practitioner Student. Level/Session 2
* The Review & Topics:
* All virtual, adult, education students must be over 18 years to attend LDMMIA eClasses and vStudio Thx.
* Please refer to our Free Workshops anytime for review/notes.
*Tech: Products Sold Separately are for Uploading Size Reasons, THX.
MIA TECH: Videos under Copyright including our Music Video for Yogi Goddess, Can only be picked up vs shop downloaded. We are under vydia.com
Pickup will be our Youtube, for unlisted Playlist.
We do have another Vod for Session 2, Level 1.
After that we move on to Session 3.
Levels 1-3 should be done by August to Sept.
LDM Recording, Yogi Goddess Bio (ReverbNation)
Organization functions as a Studio 1st. We are a Media Co, Private Sector, and Global Listed.
Imagine we are 2 different studios. One for Yoga, the Other for Music Beatz. We are also Vevo TV for Smart TV and Youtube, 2 platforms. The audience differs.
Our Biz income are Media monetization within The Entertainment genre. This includes the category of Yoga, Reiki, ASMR, and Music Beatz. Any other tips, donations, B2C sales/Student Tuition are extra. The Biz gifts are appreciated. (We have been given a few $K for random emergencies.)
ECONOMICS, DISASTER MANAGEMENT, ROAD SAFETY - STUDY MATERIAL [10TH]
ECONOMICS, DISASTER MANAGEMENT, ROAD SAFETY - STUDY MATERIAL [10TH]SHERAZ AHMAD LONE
╠²
This study material for Class 10th covers the core subjects of Economics, Disaster Management, and Road Safety Education, developed strictly in line with the JKBOSE textbook. It presents the content in a simplified, structured, and student-friendly format, ensuring clarity in concepts. The material includes reframed explanations, flowcharts, infographics, and key point summaries to support better understanding and retention. Designed for classroom teaching and exam preparation, it aims to enhance comprehension, critical thinking, and practical awareness among students.Assisting Individuals and Families to Promote and Maintain Health ŌĆō Unit 7 | ...
Assisting Individuals and Families to Promote and Maintain Health ŌĆō Unit 7 | ...RAKESH SAJJAN
╠²
This PowerPoint presentation is based on Unit 7 ŌĆō Assisting Individuals and Families to Promote and Maintain Their Health, a core topic in Community Health Nursing ŌĆō I for 5th Semester B.Sc Nursing students, as per the Indian Nursing Council (INC) guidelines.
The unit emphasizes the nurseŌĆÖs role in family-centered care, early detection of health problems, health promotion, and appropriate referrals, especially in the context of home visits and community outreach. It also strengthens the studentŌĆÖs understanding of nursing responsibilities in real-life community settings.
¤ōś Key Topics Covered in the Presentation:
Introduction to family health care: needs, principles, and objectives
Assessment of health needs of individuals, families, and groups
Observation and documentation during home visits and field assessments
Identifying risk factors: environmental, behavioral, genetic, and social
Conducting growth and development monitoring in infants and children
Recording and observing:
Milestones of development
Menstrual health and reproductive cycle
Temperature, blood pressure, and vital signs
General physical appearance and personal hygiene
Social assessment: understanding family dynamics, occupation, income, living conditions
Health education and counseling for individuals and families
Guidelines for early detection and referral of communicable and non-communicable diseases
Maintenance of family health records and individual health cards
Assisting families with:
Maternal and child care
Elderly and chronic disease management
Hygiene and nutrition guidance
Utilization of community resources ŌĆō referral linkages, support services, and local health programs
Role of nurse in coordinating care, advocating for vulnerable individuals, and empowering families
Promoting self-care and family participation in disease prevention and health maintenance
This presentation is highly useful for:
Nursing students preparing for internal exams, university theory papers, or community postings
Health educators conducting family teaching sessions
Students conducting fieldwork and project work during community postings
Public health nurses and outreach workers dealing with preventive, promotive, and rehabilitative care
ItŌĆÖs structured in a step-by-step format, featuring tables, case examples, and simplified explanations tailored for easy understanding and classroom delivery.How to Implement Least Package Removal Strategy in Odoo 18 Inventory
How to Implement Least Package Removal Strategy in Odoo 18 InventoryCeline George
╠²
In Odoo, the least package removal strategy is a feature designed to optimize inventory management by minimizing the number of packages open to fulfill the orders. This strategy is particularly useful for the business that deals with products packages in various quantities such as boxes, cartons or palettes. How to Manage Multi Language for Invoice in Odoo 18
How to Manage Multi Language for Invoice in Odoo 18Celine George
╠²
Odoo supports multi-language functionality for invoices, allowing you to generate invoices in your customersŌĆÖ preferred languages. Multi-language support for invoices is crucial for businesses operating in global markets or dealing with customers from different linguistic backgrounds. VCE Literature Section A Exam Response Guide
VCE Literature Section A Exam Response Guidejpinnuck
╠²
This practical guide shows students of Unit 3&4 VCE Literature how to write responses to Section A of the exam. Including a range of examples writing about different types of texts, this guide:
*Breaks down and explains what Q1 and Q2 tasks involve and expect
*Breaks down example responses for each question
*Explains and scaffolds students to write responses for each question
*Includes a comprehensive range of sentence starters and vocabulary for responding to each question
*Includes critical theory vocabulary╠² lists to support Q2 responsesPests of Maize: An comprehensive overview.pptx
Pests of Maize: An comprehensive overview.pptxArshad Shaikh
╠²
Maize is susceptible to various pests that can significantly impact yields. Key pests include the fall armyworm, stem borers, cob earworms, shoot fly. These pests can cause extensive damage, from leaf feeding and stalk tunneling to grain destruction. Effective management strategies, such as integrated pest management (IPM), resistant varieties, biological control, and judicious use of chemicals, are essential to mitigate losses and ensure sustainable maize production.Ad
Purification of data in data warehouse after etl process
- 1. DATA WAREHOUSING PURIFICATION OF DATA NADAR MISPA PAULRAJ
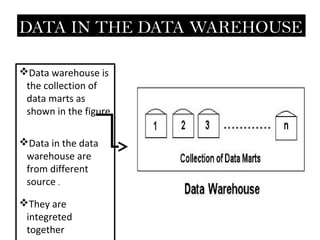
- 2. DATA IN THE DATA WAREHOUSE ’üČData warehouse is the collection of data marts as shown in the figure ’üČData in the data warehouse are from different source . ’üČThey are integreted together
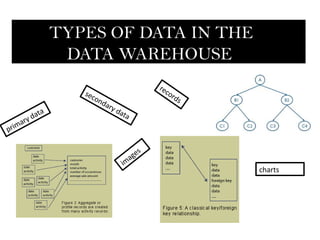
- 3. TYPES OF DATA IN THE DATA WAREHOUSE rec sec or on ds d ary a dat d at a m ary pri e s ag im charts
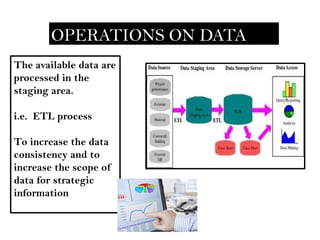
- 5. OPERATIONS ON DATA The available data are processed in the staging area. i.e. ETL process To increase the data consistency and to increase the scope of data for strategic information
- 6. DATA AFTER ETL PROCESS Even though, the data are processed in the staging area and made available for the end user. The data purity cannot be calculated and set to 100% . The level of data quality is rare. Thus data purification process is important
- 7. PURIFICATION PROCESS Purification Process Is Unpredictable i.e. We CanŌĆÖt Have Idea How To Purify And SINCE DATA IN When To Stop Purification THE DATA Process On Particular Data. WAREHOUSE IS LARGE IN NUMBER
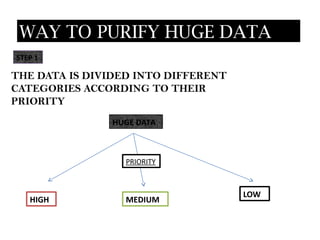
- 8. WAY TO PURIFY HUGE DATA STEP 1 THE DATA IS DIVIDED INTO DIFFERENT CATEGORIES ACCORDING TO THEIR PRIORITY HUGE DATA PRIORITY LOW HIGH MEDIUM
- 10. STEP 2 Process Each Data According To Its Priority Such As ŌĆ”.. Data In The High Priority Should Be Purified 100% Data In The Medium Priority Should Be Purified 50% Data In The Low Priority Can Be Left As Such No Problem
- 11. STEP 3 ELIMINATION OF REDUNDENT DATA The Main Reason Of Data Corruption i.e. Impurity Of Data Is Caused Due To Duplication Of Data . Example: record of a person in multiple name or in different format
- 12. Necessary things during purification of data: knowledge to differentiate data Select tools for data purification Review each data after purification. Data is ready to use with high scope Priority should b maintained. Schedule i.e. is time period of purification should be conformed.
- 13. Data is ready to useŌĆ”