PVFS: A Parallel File System for Linux Clusters
ŌĆóDownload as PPT, PDFŌĆó
1 likeŌĆó436 views

PVFS is a parallel file system designed for Linux clusters that provides high-performance I/O. It has a client-server architecture with multiple I/O daemons on separate nodes storing striped portions of files. Performance tests showed read/write bandwidths increasing linearly with I/O nodes and leveling off, reaching over 600 MB/s with Myrinet. Future work includes improving fast ethernet scalability and using additional communication mechanisms beyond TCP.















PVFS: A Parallel File System for Linux Clusters
- 1. 1 PVFS: A Parallel File System for Linux Clusters Authors: Philip H. Carns, Walter B. Ligon III, Robert B. Ross and Rajeev Thakur Olamide Timothy Tawose
- 2. 2 Preamble Due to the rapid growth of Linux clusters as platforms for low cost, high-performance parallel computing; software applications providing vital functions have evolved, especially in areas such as message passing and networking. However, Linux clusters lacks support for parallel file systems which are essential for high-performance I/O on such clusters or which make it useful for large I/O- intensive parallel applications.
- 3. 3 Objectives The authors of this work presented the design and implementation of a parallel file system for Linux clusters called Parallel Virtual File System (PVFS) that can potentially fill this void. PVFS serves both as a high-performance parallel file system downloadable for use by anyone and as a tool for pursuing further research in parallel I/O and parallel file systems for Linux clusters.
- 4. 4 Design Goals ’üČ It must provide high bandwidth for concurrent read/write operations from multiple processes or threads to a common file. ’üČ It must support multiple APIs: a native PVFS API, the UNIX/POSIX I/O API, as well as other APIs such as MPI-IO. ’üČ Common UNIX shell commands, such as ls, cp, and rm, must work with PVFS files. ’üČ Applications developed with the UNIX I/O API must be able to access PVFS files without recompiling. ’üČ It must be robust and scalable.
- 5. 5 PVFS Design and Implementation Like many other file systems, PVFS is designed as a client-server system with multiple servers, called I/O daemons. I/O daemons typically run on separate nodes in the cluster, called I/O nodes, which have disks attached to them. Each PVFS file is striped across the disks on the I/O nodes to facilitate parallel access. Application processes interact with PVFS via a client library. PVFS also has a manager daemon that handles only metadata operations such as permission checking for file creation, open, close, and remove operations. The manager does not participate in read/write operations; the client library and the I/O daemons handle all file I/O without the intervention of the manager. PVFS currently uses TCP for all internal communication. faster communication mechanisms such as VIA, GM and ST not currently supported.
- 6. 6 Overview of Communication Application processes communicate directly with the PVFS manager (via TCP) when performing operations such as opening, creating, closing, and removing files. When an application opens a file, the PVFS manager returns to the application the locations of the I/O nodes on which file data is stored. This information allows applications to communicate directly with I/O nodes when file data is accessed. In other words, the manager is not contacted during read/write operations. Time Client or Application processes PVFS Manager Daemon I/O Daemon Ask for file location via TCP (through client library) Location of I/O nodes on which data is stored Read/Write Read/Write
- 7. 7 PVFS Manager and Metadata A single manager daemon is responsible for the storage of and access to all the metadata in the PVFS file system. Metadata, in the context of a file system, refers to information describing the characteristics of a file, such as permissions, the owner and group, and, more important, the physical distribution of the file data. Metadata (characteristics of a file)Metadata (characteristics of a file) permissionspermissions OwnerOwner GroupGroup Physical distribution of dataPhysical distribution of data File Location on DiskFile Location on Disk Disk Location in ClusterDisk Location in Cluster Base I/O Node NumberBase I/O Node Number Number of I/O NodesNumber of I/O Nodes Stripe SizeStripe Size
- 8. 8 PVFS Manager and Metadata The specifics of a given file distribution are described with three metadata parameters: base I/O node number, number of I/O nodes, and stripe size. These parameters, together with an ordering of the I/O nodes for the file system, allow the file distribution to be completely specified. An example of some of the metadata fields for a file /pvfs/foo is given in Table 1. The pcount field specifies that the data is spread across three I/O nodes, base specifies that the first (or base) I/O node is node 2, and ssize specifies that the stripe sizeŌĆöthe unit by which the file is divided among the I/O nodesŌĆöis 64 Kbytes. The user can set these parameters when the file is created, or PVFS will use a default set of values. inode number is assigned by the PVFS manager.
- 9. 9 I/O Daemons and Data Storage At the time the file system is installed, the user specifies which nodes in the cluster will serve as I/O nodes. The I/O nodes need not be distinct from the compute nodes. An ordered set of PVFS I/O daemons runs on the I/O nodes. The I/O daemons are responsible for using the local disk on the I/O node for storing file data for PVFS files. Figure 1 shows how the example file /pvfs/foo is distributed in PVFS based on the metadata in Table 1. Note that although there are six I/O nodes in this example, the file is striped across only three I/O nodes, starting from node 2, because the metadata file specifies such a striping. Each I/O daemon stores its portion of the PVFS file in a file on the local file system on the I/O node. The name of this file is based on the inode number that the manager assigned to the PVFS file (here, 1092157504).
- 10. 10 Application Programming Interfaces PVFS can be used with multiple application programming interfaces (APIs): a native API, the UNIX/POSIX API, and MPI-IO. In all these APIs, the communication with I/O daemons and the manager is handled transparently within the API implementation. PVFS also supports the regular UNIX I/O functions, such as read() and write(), and common UNIX shell commands, such as ls, cp, and rm. (fcntl file locks are not yet implemented.) Furthermore, existing binaries that use the UNIX API can access PVFS files without recompiling.
- 11. 11 Performance Results using PVFS The experiment was carried out on the Chiba City cluster at Argonne National Laboratory. The cluster configuration at the time of this experiments are as follows: There were 256 nodes, each with two 500-MHz Pentium III processors, 512 Mbytes of RAM, a 9 Gbyte Quantum Atlas IV SCSI disk, a 100 Mbits/sec Intel EtherExpress Pro fast- ethernet network card operating in full-duplex mode, and a 64-bit Myrinet card (Revision 3). The nodes were running Linux 2.2.15pre4. Out of the 256 nodes, only 60 nodes were available at a time for the experiments. They used some of those 60 nodes as compute nodes and some as I/O nodes for PVFS. To measure PVFS performance, they performed experiments that can be grouped into three categories: concurrent reads and writes with native PVFS calls, concurrent reads and writes with MPI-IO, and the BTIO benchmark. They varied the number of I/O nodes, compute nodes, and I/O size and measured performance with both fast ethernet and Myrinet. the default filestripe size of 16 Kbytes was used in all experiments.
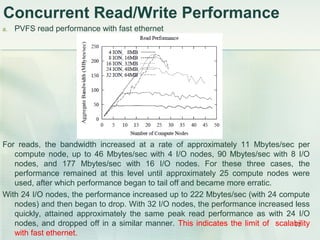
- 12. 12 Concurrent Read/Write Performance a. PVFS read performance with fast ethernet For reads, the bandwidth increased at a rate of approximately 11 Mbytes/sec per compute node, up to 46 Mbytes/sec with 4 I/O nodes, 90 Mbytes/sec with 8 I/O nodes, and 177 Mbytes/sec with 16 I/O nodes. For these three cases, the performance remained at this level until approximately 25 compute nodes were used, after which performance began to tail off and became more erratic. With 24 I/O nodes, the performance increased up to 222 Mbytes/sec (with 24 compute nodes) and then began to drop. With 32 I/O nodes, the performance increased less quickly, attained approximately the same peak read performance as with 24 I/O nodes, and dropped off in a similar manner. This indicates the limit of scalability with fast ethernet.
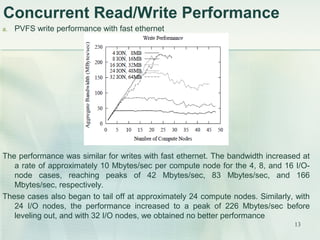
- 13. 13 Concurrent Read/Write Performance a. PVFS write performance with fast ethernet The performance was similar for writes with fast ethernet. The bandwidth increased at a rate of approximately 10 Mbytes/sec per compute node for the 4, 8, and 16 I/O- node cases, reaching peaks of 42 Mbytes/sec, 83 Mbytes/sec, and 166 Mbytes/sec, respectively. These cases also began to tail off at approximately 24 compute nodes. Similarly, with 24 I/O nodes, the performance increased to a peak of 226 Mbytes/sec before leveling out, and with 32 I/O nodes, we obtained no better performance
- 14. 14 Concurrent Read/Write Performance b. PVFS read performance with Myrinet Significant performance improvements was observed by running the same PVFS code (using TCP) on Myrinet instead of fast ethernet as shown above. The read bandwidth increased at 31 Mbytes/sec per compute process and leveled out at approximately 138 Mbytes/sec with 4 I/O nodes, 255 Mbytes/sec with 8 I/O nodes, 450 Mbytes/sec with 16 I/O nodes, and 650 Mbytes/sec with 24 I/O nodes. With 32 I/O nodes, the bandwidth reached 687 Mbytes/sec for 28 compute nodes, the maximum tested size
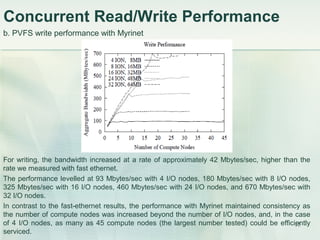
- 15. 15 Concurrent Read/Write Performance b. PVFS write performance with Myrinet For writing, the bandwidth increased at a rate of approximately 42 Mbytes/sec, higher than the rate we measured with fast ethernet. The performance levelled at 93 Mbytes/sec with 4 I/O nodes, 180 Mbytes/sec with 8 I/O nodes, 325 Mbytes/sec with 16 I/O nodes, 460 Mbytes/sec with 24 I/O nodes, and 670 Mbytes/sec with 32 I/O nodes. In contrast to the fast-ethernet results, the performance with Myrinet maintained consistency as the number of compute nodes was increased beyond the number of I/O nodes, and, in the case of 4 I/O nodes, as many as 45 compute nodes (the largest number tested) could be efficiently serviced.
- 16. 16 MPI-IO Performance c. ROMIO versus native PVFS performance with Myrinet and 32 I/O nodes The same test program was modified to use MPI-IO calls rather than native PVFS calls. The number of I/O nodes was fixed at 32, and the number of compute nodes was varied. Figure above shows the performance of the MPI-IO and native PVFS versions of the program. The performance of the two versions was comparable: MPI-IO added a small overhead of at most 7ŌĆō8% on top of native PVFS. The authors believe that this overhead can be reduced further with careful tuning.
- 17. 17 Conclusion and Future Works PVFS brings high-performance parallel file systems to Linux clusters and, although more testing and tuning are needed for production use, it is ready and available for use. PVFS also serves as a tool that enables us to pursue further research into various aspects of parallel I/O and parallel file systems for clusters. Future work plan to focus on improving the scalability limit of PVFS with fast ethernet where it currently scales up well with up to 16 I/O nodes. In the current PVFS, concurrent read/write performance began to tail off and become more erratic when until approximately 25 compute nodes were used. The authors plan to redesign the PVFS to use TCP as well as other communication mechanisms such as VIA, GM and ST. The current PVFS uses only TCP for all communications. In conclusion, the authors should consider developing a backup manager daemon that can continue handling metadata operations in case the single PVFS manager daemon fails.
- 18. 18 THANK YOU FOR LISTENING