








![11
2.1 ÍįÄÍ≤© ŪĆ®ŪĄī Ž∂ĄžĄĚ
Cosine Similar Ž∂ĄžĄĚ žėąžčú
[…………………………………………………….………………………..]
[…………………………………………………….………………………..]](https://image.slidesharecdn.com/20171-170811184826/85/PYCON-2017-12-320.jpg)


















![[PYCON KOREA 2017] Python žěÖŽ¨łžěźžĚė Data Science(Kaggle) ŽŹĄž†Ą](https://cdn.slidesharecdn.com/ss_thumbnails/pyconkr2017fianl-170810071737-thumbnail.jpg?width=560&fit=bounds)






![[224] ŠĄáŠÖ•ŠÜꊥčŠÖߊܮ ŠĄÜŠÖ©ŠĄÉŠÖ¶ŠÜĮ ŠĄÄŠÖĶŠĄáŠÖ°ŠÜę_ŠĄĆŠÖĶŠÜĮŠĄčŠÖī_ŠĄÄŠÖ≠ŠĄĆŠÖ•ŠÜľ_ŠĄČŠÖĶŠĄČŠÖ≥ŠĄźŠÖ¶ŠÜ∑](https://cdn.slidesharecdn.com/ss_thumbnails/242-150915010843-lva1-app6892-thumbnail.jpg?width=560&fit=bounds)



![[216]ŠĄÉŠÖĶŠÜłŠĄÖŠÖ•ŠĄāŠÖĶŠÜľŠĄčŠÖ®ŠĄĆŠÖ¶ŠĄÖŠÖ©ŠĄáŠÖ©ŠĄāŠÖ≥ŠÜꊥĊÖĘŠĄáŠÖ°ŠÜĮŠĄĆŠÖ°ŠĄÖŠÖ≥ŠÜĮŠĄčŠÖĪŠĄíŠÖ°ŠÜꊥźŠÖ©ŠÜľŠĄÄŠÖ® ŠĄéŠÖ¨ŠĄĆŠÖĘŠĄÄŠÖ•ŠÜĮ](https://cdn.slidesharecdn.com/ss_thumbnails/216-161025031655-thumbnail.jpg?width=560&fit=bounds)
![[221] ŠĄÉŠÖĶŠÜłŠĄÖŠÖ•ŠĄāŠÖĶŠÜľŠĄčŠÖ≥ŠÜĮ ŠĄčŠÖĶŠĄčŠÖ≠ŠÜľŠĄíŠÖ°ŠÜę ŠĄĆŠÖĶŠĄčŠÖߊܮ ŠĄŹŠÖ•ŠÜꊥźŠÖ¶ŠÜ®ŠĄČŠÖ≥ŠĄźŠÖ≥ ŠĄÄŠÖ•ŠÜ∑ŠĄČŠÖĘŠÜ® ŠĄÄŠÖĶŠÜ∑ŠĄĆŠÖĶŠÜꊥíŠÖ©](https://cdn.slidesharecdn.com/ss_thumbnails/221-161025004534-thumbnail.jpg?width=560&fit=bounds)
![[ Pycon Korea 2017 ] Infrastructure as CodeŽ•ľžúĄŪēú Ansible Ūôúžö©](https://cdn.slidesharecdn.com/ss_thumbnails/pycon2017iacansible-170811160817-thumbnail.jpg?width=560&fit=bounds)


![[F2]žěźžóįžĖīž≤ėŽ¶¨Ž•ľ žúĄŪēú ÍłįÍ≥ĄŪēôžäĶ žÜĆÍįú](https://cdn.slidesharecdn.com/ss_thumbnails/f2-120919022113-phpapp02-thumbnail.jpg?width=560&fit=bounds)




More Related Content
Viewers also liked (20)
Similar to PYCON 2017 ŽįúŪĎúžěźŽ£Ć ŪēúžĄĪž§Ä (20)



![įŕžčĶ”ä§ŪÖĶ”ĘÖ«Í©žĄ§Í≥Ą].ĪŤĪŤ≥Ŕ≥ś](https://cdn.slidesharecdn.com/ss_thumbnails/3doit-220608124356-ea37a6e3-thumbnail.jpg?width=560&fit=bounds)


![[Bespin Global ŪĆĆŪ䳎Ąą žĄłžÖė] Ž∂Ąžāį ŽćįžĚīŪĄį ŪÜĶŪē© (Data Lake) ÍłįŽįėžĚė ŽćįžĚīŪĄį Ž∂ĄžĄĚ ŪôėÍ≤Ĺ ÍĶ¨ž∂ē žā¨Ž°Ä - Ž≤†žä§ŪēÄ ÍłÄŽ°úŽ≤Ć žě•žĚĶ...](https://cdn.slidesharecdn.com/ss_thumbnails/session5-datalakebaseddataanalyticsenvironmentimplementationcaseexamplebespinglobal-190903082707-thumbnail.jpg?width=560&fit=bounds)



![[žĹĒžĄłŽāė, kosena] ŽĻÖŽćįžĚīŪĄį ÍĶ¨ž∂ē ŽįŹ ž†úžēą ÍįÄžĚīŽďú](https://cdn.slidesharecdn.com/ss_thumbnails/random-161220075637-thumbnail.jpg?width=560&fit=bounds)

![[ŪēúÍĶ≠IBM] ŽĻĄž†ēŪėēŽćįžĚīŪĄįŽ∂ĄžĄĚ WEX žÜĒŽ£®žÖė žÜĆÍįú](https://cdn.slidesharecdn.com/ss_thumbnails/wex-190725071809-thumbnail.jpg?width=560&fit=bounds)

![[ŪēúÍĶ≠IBM] žóĒŪĄįŪĒĄŽĚľžĚīž¶ą AI Í≤ÄžÉČžóĒžßĄ Watson Discovery žÜĆÍįúžěźŽ£Ć](https://cdn.slidesharecdn.com/ss_thumbnails/watsondiscoverynov2020-201210042032-thumbnail.jpg?width=560&fit=bounds)



PYCON 2017 ŽįúŪĎúžěźŽ£Ć ŪēúžĄĪž§Ä
- 1. 0 2017. 8. 13 Ūēú žĄĪ ž§Ä
- 2. 1 ‚Äú žßßžĚÄ žčúÍįĄ Žāīžóź ŪĆĆžĚīžć¨žĚĄ ŽįįžöįÍ≥† Ūôúžö©Ūēėžó¨ ŪĀį Ūö®Í≥ľŽ•ľ Ž≥ł ŪĒĄŽ°úÍ∑łŽěėŽįć ŽĻĄž†ĄÍ≥ĶžěźžĚė žĚīžēľÍłįŽ•ľ Žď§Ž†§ŽďúŽ¶¨Í≤†žäĶŽčąŽč§.‚ÄĚ
- 3. 2 Contents 3. IPO Ūą¨žěź Ž™®Žćł ŽßĆŽď§Íłį 2. ŪĆĆžĚīžć¨žúľŽ°ú Ūē† žąė žěąŽäĒ Í≤ÉŽď§ 4. žčúžā¨ž†ź 1. ŪĆĆžĚīžć¨žĚĄ ŽįįžõĆžēľ ŪēėŽäĒ žĚīžú†
- 4. 3 Contents 3. IPO Ūą¨žěź Ž™®Žćł ŽßĆŽď§Íłį 2. ŪĆĆžĚīžć¨žúľŽ°ú Ūē† žąė žěąŽäĒ Í≤ÉŽď§ 4. žčúžā¨ž†ź 1. ŪĆĆžĚīžć¨žĚĄ ŽįįžõĆžēľ ŪēėŽäĒ žĚīžú†
- 5. 4 1. ž£ľžčĚŪą¨žěźžěźÍįÄ ŪĆĆžĚīžć¨žĚĄ ŪÜĶŪēī žĖĽžĚĄ žąė žěąŽäĒ Ūö®Í≥ľ Í≥†žßĎžĚī žéĄžßź ŽÖłžēą ž≤īŽ†•ÍįźžÜĆ ÍłįžĖĶŽ†• ÍįźžÜĆ Ūēúž†ēŽźú žĚłŽß• ‚Ķ žěźŽŹôŪôĒ žĚłÍįĄžĚė Ž≥łžĄĪ Í∑ĻŽ≥Ķ žÉąŽ°úžöī ŪÜĶžįįŽ†• Í≥†žßĎ, žßĎžį© Ž≥ÄŪôĒžóź ŽĆÄŪēú ŽĎźŽ†§žõÄ žÜźžč§ ŽĎźŽ†§žõÄ ŪäĻž†ē žąėžĚĶŽ™®Žćł žßĎžį© ‚Ķ ‚Äú ŽćįžĚīŪĄį žąėžßĎ/Ž∂ĄžĄĚ žěźŽŹôŪôĒ‚ÄĚ ‚Äú Žč®žąú žěĎžóÖ žěźŽŹôŪôĒ‚ÄĚ ‚Äú Ž∂ĄžĄĚ žěźŽŹôŪôĒ‚ÄĚ ‚Äú žč§žčúÍįĄ žěźŽ£Ć žąėžßĎ‚ÄĚ ‚Äú žčúžä§ŪÖú Ū䳎†ąžĚīŽĒ©‚ÄĚ ‚Äú žēĆÍ≥†Ž¶¨ž¶ė Ū䳎†ąžĚīŽĒ©‚ÄĚ ‚Äú žĄĪÍ≥ľ Ž™®ŽčąŪĄįŽßĀ‚ÄĚ ‚Äú Machine Learning‚ÄĚ ‚Äú Žč§žĖĎŪēú ŽĚľžĚīŽłĆŽü¨Ž¶¨‚ÄĚ Í∑łŽ¶¨Í≥† ???
- 6. 5 1. ž£ľžčĚŪą¨žěźžěźÍįÄ ŪĆĆžĚīžć¨žĚĄ ŽįįžõĆžēľ ŪēėŽäĒ žĚīžú† ‚Äú ŪĆĆžĚīžć¨žĚÄ ž£ľžčĚ Ūą¨žěźžěźžóźÍ≤Ć žěąžĖī žóĎžÖÄ ŽėźŽäĒ HTS žó≠Ūē†žĚĄ Ūē† Í≤Éžě֎蹎č§.‚ÄĚ ‚Äú ŪĆĆžĚīžć¨žĚĄ žěėŪēúŽč§Í≥† ŪēīžĄú ŽįėŽďúžčú žĘčžĚÄ žĄĪÍ≥ľŽ•ľ Žāľ žąėŽäĒ žóÜžßÄŽßĆ, žóÜžĖīžĄúŽäĒ žēą ŽźėŽäĒ ŽŹĄÍĶ¨ÍįÄ Žź† Í≤Éžě֎蹎č§.‚ÄĚ
- 7. 6 Contents 3. IPO Ūą¨žěź Ž™®Žćł ŽßĆŽď§Íłį 2. ŪĆĆžĚīžć¨žúľŽ°ú Ūē† žąė žěąŽäĒ Í≤ÉŽď§ 4. žčúžā¨ž†ź 1. ŪĆĆžĚīžć¨žĚĄ ŽįįžõĆžēľ ŪēėŽäĒ žĚīžú†
- 8. 7 ÔĀ≠ ŪĆĆžĚīžć¨žúľŽ°ú Žß§žöį ÍłČÍ≤©Ūēú žčúÍįĄ ž†ąžēĹÍ≥ľ Ūö®žú®žĄĪ ž¶ĚŽĆÄŽ•ľ Žč¨žĄĪŪē† žąė žěąžĚĆ ÔĀ≠ ŽėźŪēú Ž®łžč†Žü¨Žč̞̥ Ūôúžö©Ūēėžó¨ žĚłÍįĄžĚė ŽąąžúľŽ°ú Ž≥īžßÄ Ž™ĽŪēėŽäĒ žÉąŽ°úžöī ŪĆ®ŪĄīžĚĄ ŽįúÍ≤¨Ūē† žąė žěąžĚĆ 2. ŪĆĆžĚīžć¨žúľŽ°ú Ūē† žąė žěąŽäĒ Í≤ÉŽď§ Í≥Ķžčú/ŽČīžä§ Í≤ÄžÉČ ž†ēÍłį ŽćįžĚīŪĄį žóÖŽćįžĚīŪäł ŽįŹ Ž∂ĄžĄĚ žč§žčúÍįĄ žčúžě• ŽćįžĚīŪĄį Ž™®ŽčąŪĄįŽßĀ Íłįžą†ž†Ā Ž∂ĄžĄĚ žč§ž†Ā ŽįúŪĎú ž≤īŪĀ¨ žěźŽŹôŪôĒ Ūôēžě•žĄĪ/ Žßěž∂§Ūėē Ž®łžč†Žü¨ŽčĚ Žč§Ž•ł žĖłžĖīŽ≥īŽč§ žÉĀŽĆÄž†ĀžúľŽ°ú žČĹÍ≤Ć Ūôúžö© ÍįÄŽä• ž£ľžčĚ Ūą¨žěźžěźŽď§žĚī žā¨žö©ŪēėŽäĒ Ž∂ĄžĄĚŽ≤ē . . .
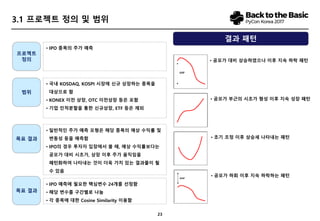
- 9. 8 2.1 ÍįÄÍ≤© ŪĆ®ŪĄī Ž∂ĄžĄĚ ŪĒĄŽ°úÍ∑łŽěėŽįćžĚĄ Ūôúžö©ŪēúŽč§Ž©ī? ‚ÄĘ žĚłÍįĄžĚė ŽąąžúľŽ°ú ž£ľÍįÄ ÍįÄÍ≤© Í∑łŽěėŪĒĄ Ž∂ĄžĄĚ ‚ÄĘ žě•ž†ź ‚Äď žė§Žěú Í≤ĹŽ†•žĚė ŪĒĄŽ°ú Ūą¨žěźžěźžĚė Í≤Ĺžöį ŽĮłŽ¨ėŪēú ŪĆ®ŪĄī ŽďĪžĚĄ ÍįźÍįĀž†ĀžúľŽ°ú Ž∂ĄžĄĚŪēėžó¨ Ūôúžö©Ūē† žąė žěąžĚĆ ‚ÄĘ Žč®ž†ź ‚Äď Žč§žąėžĚė žĘÖŽ™©žĚĄ ŪôēžĚłŪē† Í≤Ĺžöį žčúÍįĄžĚī ŽßéžĚī ÍĪłŽ¶ľ, žßĀÍįź žĚėž°ī ŪēúÍ≥Ą, Í≥ľÍĪį žā¨Ž°Ä ŽďĪ ž≤īŪĀ¨ ÍįÄŽä•žĄĪ Íłįž°īžĚė Žį©žčĚ žčúÍįĄžĚė ž†ąžēĹ ‚ÄĘ 2,000Íįú žĚīžÉĀžĚė žĘÖŽ™© ŪĆ®ŪĄī Í≤ÄžÉČ ÍįÄŽä• (2,000Íįú žĘÖŽ™©žĚė 2ŽÖĄžĻė ŽćįžĚīŪĄįŽ•ľ 600Íįú ÍĶ¨ÍįĄžúľŽ°ú ŽāėŽąĄžĖī Ž∂ĄžĄĚŪēīŽŹĄ 3Ž∂Ąžēąžóź ž≤ėŽ¶¨ÍįÄŽä•) žčúŽģ¨Ž†ąžĚī žÖė ÍįÄŽä• ‚ÄĘ ŪēīŽčĻ ŪĆ®ŽćėžĚī ž°īžě¨ŪĖąŽćė Í≥ľÍĪį žú†žā¨žā¨Ž°Ä Ž∂ĄžĄĚ ‚ÄĘ žú†žÉĀž¶Ěžěź ž†ĄŪõĄ ŽįŹ IPO ž£ľÍįÄ ŪĆ®ŪĄī Ž≥łžĚłžĚė Žį©žčĚžúľŽ°ú ‚ÄĘ Íłįž°ī HTS Í≤ÄžÉČÍłį žôłžóźŽŹĄ Ž≥łžĚłžĚė ŪäĻžĄĪžóź ŽßěŽäĒ žĖĎžčĚ ÍįúŽįúŪēėžó¨ žõźŪēėŽäĒ Žį©žčĚžúľŽ°ú Reporting ‚ÄĘ ŪēėŽĚĹÍįĀŽŹĄ, ŪĆ®ŪĄīÍłįÍįĄ, žĘÖŽ™©ž°įÍĪī, Ž∂ĄžĄĚŽĆÄžÉĀ ŽďĪ žÉąŽ°úžöī ŪĆ®ŪĄīžĚė ŽįúÍ≤¨ ‚ÄĘ Ž≥łžĚłžĚī žĄ§ž†ēŪēú ŪĆ®ŪĄī žôłžĚė žÉąŽ°úžöī ŪĆ®ŪĄī ž†úžčú ‚ÄĘ Ž®łžč† Žü¨ŽčĚžĚė žú†žā¨ŽŹĄ žįĺÍłį ŽįŹ ÍĶįžßĎŪôĒ žēĆÍ≥†Ž¶¨ž¶ė
- 10. 9 2.1 ÍįÄÍ≤© ŪĆ®ŪĄī Ž∂ĄžĄĚ žõźŪēėŽäĒ ŪĆ®ŪĄī ž†ēžĚė žěźŽ£Ć žěÖŽ†• žěźŽ£Ć ž≤ėŽ¶¨ ŽįŹ Ž∂ĄžĄĚ Ūôúžö© ŽįŹ Ž¶¨ŪŹ¨ŪĆÖ ‚ÄĘ Ž≥łžĚłžĚī žõźŪēėŽäĒ ÍįÄÍ≤© žį®Ūäł ŪĆ®ŪĄī ž†ēžĚė Í≥ľž†ē ‚ÄĘ žĘÖŽ™©, žßĀž†Ď Í∑łŽ¶į ŪĆ®ŪĄī, Ž∂ĄžĄĚŽĆÄžÉĀžĚė ŪäĻžĄĪ, žčúÍįÄžīĚžē°, žóÖžĘÖ, žĚīŽ≤§Ūäł ŽďĪ ‚ÄĘ žį®Ūäł ŪĆ®ŪĄī ž†ēžĚė ŪõĄ list ŪėēŪÉúŽ°ú žěÖŽ†• 1) žõźŪēėŽäĒ žĘÖŽ™©Í≥ľ ÍłįÍįĄžĚĄ žßÄž†ēŪēėžó¨ listŽ°ú Ž≥ÄŪôė ŪõĄ žěÖŽ†• 2) žõźŪēėŽäĒ žąėžč̞̥ žßÄž†ēŪēėžó¨ žěÖŽ†• 3) ŪĆ®ŪĄīžĚĄ ÍįĄžÜĆŪôĒŪēėžó¨ listŽ°ú Ž≥ÄŪôėŪēėžó¨ žěÖŽ†• ‚ÄĘ žěÖŽ†•Žźú žěźŽ£Ć ž≤ėŽ¶¨ ‚Äď Scikit Learn ŽďĪžĚė Ž™®Žďą žā¨žö© ‚ÄĘ Cosine Simillar, DTW ŽďĪžĚė Ž™®Žćł žĚīžö©Ūēėžó¨ žú†žā¨Ūēú ŪĆ®ŪĄī Í≤ÄžÉČ ‚ÄĘ ŪėĄžě¨ žčúž†ź Íłįž§Ä, ŽėźŽäĒ ŪäĻž†ē ÍłįÍįĄ ŽďĪžĚĄ Íłįž§ÄžúľŽ°ú žĄ§ž†ēŪēėžó¨ Ž∂ĄžĄĚ ‚ÄĘ žõźŪēėŽäĒ žĖĎžčĚžúľŽ°ú Ž≥ÄŪôėŪēėŽäĒ Í≥ľž†ēžĚĄ žčúÍįĀŪôĒ ‚ÄĘ Í≥ľÍĪį žčúŽģ¨Ž†ąžĚīžÖė žčú žú†žā¨Ūēú ŪĆ®ŪĄī ŽįŹ žĚīŪõĄ žĄĪÍ≥ľ Ž∂ĄžĄĚ ‚ÄĘ ŪėĄžě¨ žčúž†ź žú†žā¨ŽŹĄ Íłįž§ÄžúľŽ°ú ŪĆ®ŪĄī ž†ēŽ†¨
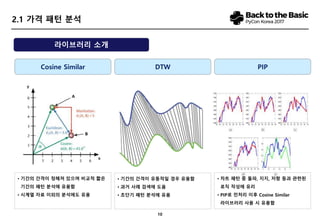
- 11. 10 2.1 ÍįÄÍ≤© ŪĆ®ŪĄī Ž∂ĄžĄĚ Cosine Similar ŽĚľžĚīŽłĆŽü¨Ž¶¨ žÜĆÍįú DTW PIP ‚ÄĘ ÍłįÍįĄžĚė ÍįĄÍ≤©žĚī ž†ēŪēīž†ł žěąžúľŽ©į ŽĻĄÍĶźž†Ā žßßžĚÄ ÍłįÍįĄžĚė ŪĆ®ŪĄī Ž∂ĄžĄĚžóź žú†žö©Ūē® ‚ÄĘ žčúÍ≥Ąžóī žěźŽ£Ć žĚīžôłžĚė Ž∂ĄžĄĚžóźŽŹĄ žú†žö© ‚ÄĘ ÍłįÍįĄžĚė ÍįĄÍ≤©žĚī žú†ŽŹôž†ĀžĚľ Í≤Ĺžöį žú†žö©Ūē® ‚ÄĘ Í≥ľÍĪį žā¨Ž°Ä Í≤ÄžÉČžóź ŽŹĄžõÄ ‚ÄĘ žīąŽč®Íłį ŪĆ®ŪĄī Ž∂ĄžĄĚžóź žú†žö© ‚ÄĘ žį®Ūäł ŪĆ®ŪĄī ž§Ď ŽŹĆŪĆĆ, žßÄžßÄ, ž†ÄŪē≠ ŽďĪÍ≥ľ ÍīÄŽ†®Žźú Ž°úžßĀ žěĎžĄĪžóź žú†Ž¶¨ ‚ÄĘ PIPŽ°ú ž†Ąž≤ėŽ¶¨ žĚīŪõĄ Cosine Similar ŽĚľžĚīŽłĆŽü¨Ž¶¨ žā¨žö© žčú žú†žö©Ūē®
- 12. 11 2.1 ÍįÄÍ≤© ŪĆ®ŪĄī Ž∂ĄžĄĚ Cosine Similar Ž∂ĄžĄĚ žėąžčú [‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ.‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ..] [‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ.‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ‚Ķ..]
- 13. 12 2.2 ž†ēÍłįŽćįžĚīŪĄį žóÖŽćįžĚīŪäł ŽįŹ Ž∂ĄžĄĚ ŪĒĄŽ°úÍ∑łŽěėŽįćžĚĄ Ūôúžö©ŪēúŽč§Ž©ī? ‚ÄĘ žė§ž†Ąžóź žĚľŽ≥ĄŽ°ú Žč§žĖĎŪēú ž†ēŽ≥īŽ•ľ ž≤īŪĀ¨ ‚ÄĘ ŽČīžä§ ŽėźŽäĒ žąėžĻėŪôĒŽźú ž†ēŽ≥īŽ•ľ ž≤īŪĀ¨Ūē® ‚ÄĘ žÉĀŽčĻŪěą Žč§žĖĎŪēú ž†ēŽ≥īÍįÄ žěąžĖī žĚľžĚľžĚī ž≤īŪĀ¨ŪēėÍłįÍįÄ žĖīŽ†§žõÄ ‚ÄĘ ŽėźŪēú ŽčĻžĚľ žčúžě•Í≥ľ žóįŽŹôŽźėŽäĒ ŪēĶžč¨ žßÄŪĎú ŽďĪžĚĄ žĄ†ž†ēŪēėŽäĒŽćį Ž¨ľŽ¶¨ž†Ā ŪēúÍ≥Ą ž°īžě¨ Íłįž°īžĚė Žį©žčĚ žčúÍįĄžĚė ž†ąžēĹ ‚ÄĘ žčúžě•žĚė ž§ĎžöĒŪēú Ž≥ÄžąėŽ°ú žěĎžö©Ūē† žąė žěąŽäĒ 3,000Íįú žĚīžÉĀžĚė žßÄŪĎúŽ•ľ žÜźžČĹÍ≤Ć ž≤ėŽ¶¨ ÍįÄŽä• ‚ÄĘ žõźŪēėŽäĒ ŪĆ®ŪĄīžĚī žė¨ Í≤Ĺžöį ŪēīŽčĻ žßÄŪĎú žěźŽŹô žēĆŽěĆ žčúŽģ¨Ž†ąžĚī žÖė ÍįÄŽä• ‚ÄĘ ŪēīŽčĻ žßÄŪĎúžĚė ŪēīŽčĻ ŪĆ®ŪĄīžĚī žěąžóąŽćė Í≥ľÍĪį žā¨Ž°Ä Í≤ÄžÉČ ÍįÄŽä•Ūē® ‚ÄĘ Í≥ľÍĪį žā¨Ž°Ä Ž∂ĄžĄĚžóź ŽĒįŽ•ł ŪĆ®ŪĄīŪôĒ ÍįÄŽä• Ž≥łžĚłžĚė Žį©žčĚžúľŽ°ú ‚ÄĘ Í≤Ĺž†úŽČīžä§ žÉĀžĚė ŪēĶžč¨ žßÄŪĎúŽßĆžĚī žēĄŽčĆ, ‚ÄĘ Ž≥łžĚłžĚė ÍīĞ訞ĘÖŽ™©Í≥ľ žčúžě• ŪĆ®ŪĄīžóź Žßěž∂ĒžĖī žēĆŽěĆ ‚ÄĘ ž£ľžčĚžóź žėĀŪĖ•žĚĄ ž§Ą žąė žěąŽäĒ žÉĀŪô© žěźŽŹô žēĆŽěĆ ŽĻĄž†ēŪėē ŽćįžĚīŪĄį ŪôēžĚłÍįÄŽä• ‚ÄĘ ž†ēŪėēŪôĒŽźú ŽćįžĚīŪĄį žôłžóźŽŹĄ ÍĶ¨ÍłÄ Ū䳎ěúŽďú, žáľŪēĎŽ™į ŽćįžĚīŪĄį, ŽČīžä§ Ž∂ĄžĄĚ, žāįžóÖžßÄŪĎú ŽďĪŽŹĄ ŪĀ¨Ž°§ŽßĀŪēėžó¨ Ž∂ĄžĄĚ ÍįÄŽä•
- 14. 13 2.2 ž†ēÍłį ŽćįžĚīŪĄį žóÖŽćįžĚīŪäł ŽįŹ Ž∂ĄžĄĚ ŪēĄžöĒŪēú žěźŽ£Ć ŽįŹ ž≤ėŽ¶¨ Žį©Ž≤ē ž†ēžĚė žěźŽ£Ć žąėžßĎ ŽįŹ žěÖŽ†• žěźŽ£Ć ž≤ėŽ¶¨ ŽįŹ Ž∂ĄžĄĚ Ūôúžö© ŽįŹ Ž¶¨ŪŹ¨ŪĆÖ ‚ÄĘ ž≤īŪĀ¨Ūēīžēľ Ūē† ž£ľžöĒ žßÄŪĎúžĚė ž†ēžĚė ‚ÄĘ Í≤Ĺž†úŽćįžĚīŪĄį(Ūôėžú®, žú†ÍįÄ, žÉĀŪíąÍįÄÍ≤© ŽďĪ), Ūēīžôłž£ľžčĚ(ŽĮłÍĶ≠, žĚľŽ≥ł ŽďĪžĚė ÍįĀ žāįžóÖŽ≥Ą Ž∂ĄŽ•ė), žāįžóÖžßÄŪĎú(žąėž∂úžěÖ ŽćįžĚīŪĄį, žāįžóÖŪėĎŪöĆ žěźŽ£Ć ŽďĪ) ‚ÄĘ ÍįĀ žßÄŪĎúŽ≥Ą žąėžßĎ ŽįŹ ž≤ėŽ¶¨ Žį©Ž≤ē ž†ēžĚė ‚ÄĘ BeautifulSoup Ž™®Žďą Ūôúžö© ‚ÄĘ SeleniumŽįŹ ŪƨŪÖÄjs Ž™®Žďą Ūôúžö© ŽćįžĚīŪĄį žąėžßĎ ‚ÄĘ MySQL ŽďĪžĚĄ ŪÜĶŪēī žěÖŽ†• ‚ÄĘ žõźŪēėŽäĒ ÍįÄÍ≤© ŪĆ®ŪĄī Ž∂ĄŽ•ė(List ŪėēžčĚ) ‚ÄĘ žěÖŽ†•Žźú žěźŽ£Ć ž≤ėŽ¶¨ (Scikit Learn ŽďĪžĚė Ž™®Žďą žā¨žö©) ‚ÄĘ Cosine Simillar, DTW ŽďĪžĚė Ž™®Žćł žĚīžö©Ūēėžó¨ žĄ§ž†ēŪēú ŪĆ®ŪĄīžóź Ž∂ÄŪē©ŪēėŽäĒžßÄ žó¨Ž∂Ä ŪĆźŽ≥Ą ‚ÄĘ ÍįĀ žěźŽ£Ć Ž≥Ą žöįžĄ†žąúžúĄ Ž∂Äžó¨ žēĆÍ≥†Ž¶¨ž¶ė ÍįúŽįú ‚ÄĘ ž°įÍĪī ŽįúžÉĚ žčú ŪúīŽĆÄŪŹį žēĆŽěĆ ‚ÄĘ ÍįĀ ž°įÍĪī Ž≥Ą žčúŽģ¨Ž†ąžĚīžÖė ŽįŹ žú†žā¨žā¨Ž°Ä ž†źÍ≤Ä
- 15. 14 2.3 žč§žčúÍįĄ žčúžě• ŽćįžĚīŪĄį Ž™®ŽčąŪĄįŽßĀ ‚ÄĘ Ūą¨žěźžěźŽ≥Ą ŽŹôŪĖ•, ž£ľÍįÄ, ÍĪįŽěėŽüČ ŽďĪžóź ŽĆÄŪēú ž†ēŽ≥īŽ•ľ ž£ľŽ°ú HTS ŽďĪžĚĄ ŪÜĶŪēėžó¨ ŪôēžĚł ‚ÄĘ HTS ÍłįŽä•žĚī Žįúž†ĄŪē®žóź ŽĒįŽĚľ Žč§žĖĎŪēú ÍłįŽä• žā¨žö© ÍįÄŽä•ŪēėžßÄŽßĆ Ž≥łžĚłŽßĆžĚė ž†ĄŽěĶ ÍīÄŽ†® žąėžßĎŪēėŽäĒŽćįŽäĒ ž†úŪēúž†Ā ‚ÄĘ ŪäĻŪěą Žč§žĖĎŪēú žĘÖŽ™©žĚĄ Í≤ÄžÉČŪē† Í≤Ĺžöį ŽąĄŽĚĹ ŽďĪžĚė žöįŽ†§ žěąžĚĆ Íłįž°īžĚė Žį©žčĚ ŪĒĄŽ°úÍ∑łŽěėŽįćžĚĄ Ūôúžö©ŪēúŽč§Ž©ī? žčúÍįĄžĚė ž†ąžēĹ ‚ÄĘ ž†Ą žĘÖŽ™©žóź ŽĆÄŪēėžó¨ žõźŪēėŽäĒ ž°įÍĪīžóź ŽĒįŽĚľ Í≤ÄžÉČ ‚ÄĘ ž¶ĚÍ∂Ćžā¨ API Ūôúžö© žčú Žč§žĖĎŪēú žßÄŪĎú ŽįŹ ž°įÍĪīžč̞̥ ŪēúŽ≤ąžóź ž≤ėŽ¶¨ ÍįÄŽä•Ūē® žčúŽģ¨Ž†ąžĚī žÖė ÍįÄŽä• ‚ÄĘ ŪēīŽčĻ ž°įÍĪīžóź ŽĆÄŪēú Í≥ľÍĪį žā¨Ž°Ä Ž™®ŽčąŪĄįŽßĀ ÍįÄŽä• ‚ÄĘ MySQL ŽďĪžĚĄ Ūôúžö©Ūēėžó¨ žčúÍįĄŽĆÄŽ≥Ą DBÍĶ¨ž∂ē ÍįÄŽä• Ž≥łžĚłžĚė Žį©žčĚžúľŽ°ú ‚ÄĘ HTS ÍłįŽä• ŽďĪžĚĄ Ž≥łžĚłžóź žĶúž†ĀŪôĒŽźėŽŹĄŽ°Ě žā¨žö© ‚ÄĘ ŪäĻž†ē žĘÖŽ™©ÍĶį, ž°įÍĪīŽ≥Ą (žčúÍįĄŽĆÄ, žôłÍĶ≠žĚł ŽďĪ) ž†ēŽ†¨
- 16. 15 2.3 žč§žčúÍįĄ žčúžě• ŽćįžĚīŪĄį Ž™®ŽčąŪĄįŽßĀ ŪēĄžöĒŪēú žěźŽ£Ć ŽįŹ ž≤ėŽ¶¨ Žį©Ž≤ē ž†ēžĚė ž¶ĚÍ∂Ćžā¨ API žóįŽŹô žěźŽ£Ć ž≤ėŽ¶¨ ŽįŹ Ž∂ĄžĄĚ Ūôúžö© ŽįŹ Ž¶¨ŪŹ¨ŪĆÖ ‚ÄĘ ž≤īŪĀ¨Ūēīžēľ Ūē† ž£ľžöĒ žčúžě• ŽćįžĚīŪĄį ž†ēžĚė(žôłÍĶ≠žĚł žąėÍłČ, ž£ľž≤īŽ≥Ą žąėÍłČ, ž£ľÍįÄ ŽćįžĚīŪĄį, žįĹÍĶ¨Ž≥Ą ŪėĄŪô© ŽďĪ) ‚ÄĘ ž≤īŪĀ¨ ž£ľÍłį, ž°įÍĪī ŽďĪžóź ŽĆÄŪēú Ž™ÖŪôēŪôĒ ‚ÄĘ žč§žčúÍįĄ ŽćįžĚīŪĄįžĚė Í≤Ĺžöį žĚłŪĄįŽĄ∑ žÉĀžóźžĄú žąėžßĎ žĖīŽ†§žõÄ ‚ÄĘ Ūā§žõÄž¶ĚÍ∂Ć, ŽĆĞ膞¶ĚÍ∂Ć ŽďĪžĚė API Ūôúžö© ‚ÄĘ žąėžßĎŪēú ŽćįžĚīŪĄįžóź ŽĆÄŪēú ž°įÍĪī ž≤ėŽ¶¨, žĄ§ž†ēŪēú ŪĆ®ŪĄīžóź Ž∂ÄŪē©ŪēėŽäĒžßÄ žó¨Ž∂Ä ŪĆźŽ≥Ą ‚ÄĘ ÍįĀ žčúÍįĄŽĆÄŽ≥ĄŽ°ú MySQLžóź DBŪôĒ žčúŪāī ‚ÄĘ ÍįĀ ž°įÍĪī ŽįúžÉĚ žčú Alarm ŽįŹ Reporting ÍłįŽä• ‚ÄĘ ÍįĀ ž°įÍĪī Ž≥Ą DB ž†Äžě• žěźŽ£ĆŽ•ľ ŪÜĶŪēú Í≥ľÍĪį žā¨Ž°Ä Ž∂ĄžĄĚ
- 17. 16 žč§žčúÍįĄ žčúžě• Ž∂ĄžĄĚ žėąžčú 2.3 žč§žčúÍįĄ žčúžě• ŽćįžĚīŪĄį Ž™®ŽčąŪĄįŽßĀ
- 18. 17 2.4 Í≥Ķžčú/ŽČīžä§ ŽįúžÜ° ŽįŹ Ž∂ĄŽ•ė ‚ÄĘ ÍłįžóÖ Í≥Ķžčú ŽįŹ ŽČīžä§žóź ŽĆÄŪēėžó¨ HTS ŽėźŽäĒ ÍłąÍįźžõź ž†ĄžěźÍ≥Ķžčú žā¨žĚīŪäł žĚīžö©(ŽėźŽäĒ žĚľŽ∂Ä žēĪ žĚīžö©) ‚ÄĘ Í≥ĄžÜć Ž≥īÍ≥† žěąžßÄ žēäžúľŽ©ī ž§ĎžöĒŪēú ŽČīžä§Ž•ľ ŽÜďžĻ† ÍįÄŽä•žĄĪ žěąžĚĆ ‚ÄĘ Žč®Íłįž†ĀžĚł ŽĆÄžĚĎŽßĆ ÍįÄŽä•Ūē† žąė žěąžĚĆ ‚ÄĘ žõĆŽāô ŽßéžĚÄ ž†ēŽ≥īŽ°ú žĚłŪēī Íľ≠ ŪēĄžöĒŪēú ž†ēŽ≥īÍįÄ Ž¨ĽŪěź žąė žěąžĚĆ Íłįž°īžĚė Žį©žčĚ ŪĒĄŽ°úÍ∑łŽěėŽįćžĚĄ Ūôúžö©ŪēúŽč§Ž©ī? žčúÍįĄžĚė ž†ąžēĹ ‚ÄĘ ŪäĻž†ē Ūā§žõĆŽďúžóź ŽßěŽäĒ ŽČīžä§/Í≥Ķžčú ŽįúžÉĚ žčú ŪÖĒŽ†ąÍ∑łŽě® ŽįúžÜ° žčúŽģ¨Ž†ąžĚī žÖė ÍįÄŽä• ‚ÄĘ ŪēīŽčĻ Í≥Ķžčúžóź ŽĆÄŪēėžó¨ žú†žā¨Ūēú žā¨Ž°ÄžĚė Í≥ĶžčúžôÄ ŽčĻžčú ŪćľŪŹ¨Ž®ľžä§ Í≤ÄžÉČ ÍįÄŽä• Ūôēžě•žĄĪ ‚ÄĘ Í≥ĶžčúžĚė žĘÖŽ•ėŽ≥ĄŽ°ú ž†Äžě•Ūēėžó¨ Í≥ľÍĪį žā¨Ž°Ä Ž∂ĄžĄĚ (ÍłįžóÖŽ∂ĄŪē†, žē°Ž©īŽ∂ĄŪē†, žú†žÉĀž¶Ěžěź, žÉĀžě• ŽďĪ) ‚ÄĘ ž£ľÍįÄ ŪĆ®ŪĄīÍ≥ľ žóįŽŹô ÍįÄŽä•
- 19. 18 2.4 Í≥Ķžčú/ŽČīžä§ ŽįúžÜ° ŽįŹ Ž∂ĄŽ•ė Key Word ŽįŹ ŪäĻžĄĪ žĄ§ž†ē ŽćįžĚīŪĄį žąėžßĎ žěźŽ£Ć ž≤ėŽ¶¨ ŽįŹ Ž∂ĄžĄĚ Ūôúžö© ŽįŹ Ž¶¨ŪŹ¨ŪĆÖ ‚ÄĘ Í≤ÄžÉČŪēėŽ†§Í≥† ŪēėŽäĒ Key Word žĄ§ž†ē ‚ÄĘ ÍįĀ Key WordžĚė ŪäĻžĄĪ ÍĶ¨Ž∂Ą(žě•Íłį-Žč®Íłį, žĚīŽ≤§ŪäłžĄĪ, žĚīžäąžĄĪ-ŪéÄŽćĒŽ©ėŪĄłžĄĪ ŪēĄžöĒžĄĪ ŽďĪ) ‚ÄĘ BeautifulSoup, SeleniumŽįŹ ŪƨŪÖÄjs Ž™®Žďą Ūôúžö© ŽćįžĚīŪĄį žąėžßĎ ‚ÄĘ ž†ĄžěźÍ≥Ķžčú žā¨žĚīŪäł ŽįŹ ž¶ĚÍ∂Ćžā¨ API žóįŽŹô, Naver, Google ŽďĪ ŽČīžä§Ž©ī Ūôúžö© ‚ÄĘ žĖłŽ°†žā¨Ž≥Ą RSS ŽďĪ Ūôúžö© ‚ÄĘ ŽČīžä§/Í≥ĶžčúŽ≥Ą Key WordžĚė ŪäĻžĄĪžóź Žßěž∂ĒžĖī ž≤ėŽ¶¨ žßĄŪĖČ ‚ÄĘ žě•ÍłįžĄĪ, žĚīŽ≤§ŪäłžĄĪ, ŪéÄŽćĒŽ©ėŪĄłžĄĪžĚė Í≤ĹžöįŽ°ú Ž∂ĄŽ•ėŪēėžó¨ ž≤ėŽ¶¨ (Telegram API Ūôúžö©) ‚ÄĘ ÍįĀ ž°įÍĪī ŽįúžÉĚ žčú Alarm ŽįŹ Reporting ÍłįŽä• ‚ÄĘ ÍįĀ ž°įÍĪī Ž≥Ą DB ž†Äžě• žěźŽ£ĆŽ•ľ ŪÜĶŪēú Í≥ľÍĪį žā¨Ž°Ä Ž∂ĄžĄĚ ‚ÄĘ ž£ľÍįÄ žúĄžĻėŽ≥ĄŽ°ú ž§ĎžöĒŪēú ÍĶ≠Ž©īžĚľ Í≤Ĺžöį ŽįúžÜ° ÍįÄž§ĎžĻė Ž∂Äžó¨
- 20. 19 Í≥Ķžčú Ž∂ĄžĄĚ ŪõĄ ŽįúžÜ° žėąžčú 2.4 Í≥Ķžčú/ŽČīžä§ ŽįúžÜ° ŽįŹ Ž∂ĄŽ•ė
- 21. 20 Í≥Ķžčú Ž∂ĄžĄĚ ŪõĄ ŽįúžÜ° žėąžčú 2.4 Í≥Ķžčú/ŽČīžä§ ŽįúžÜ° ŽįŹ Ž∂ĄŽ•ė
- 22. 21 Contents 3. IPO Ūą¨žěź Ž™®Žćł ŽßĆŽď§Íłį 2. ŪĆĆžĚīžć¨žúľŽ°ú Ūē† žąė žěąŽäĒ Í≤ÉŽď§ 4. žčúžā¨ž†ź 1. ŪĆĆžĚīžć¨žĚĄ ŽįįžõĆžēľ ŪēėŽäĒ žĚīžú†
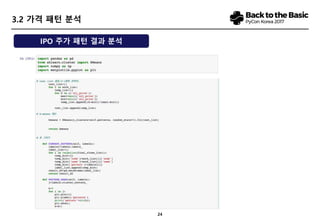
- 23. 22 3.1 ŪĒĄŽ°úž†ĚŪäł ž†ēžĚė ŽįŹ Ž≤ĒžúĄ ŪĒĄŽ°úž†ĚŪäł ž†ēžĚė ‚ÄĘ IPO žĘÖŽ™©žĚė ž£ľÍįÄ žėąžł° Ž≤ĒžúĄ ‚ÄĘ ÍĶ≠Žāī KOSDAQ, KOSPI žčúžě•žóź žč†Í∑ú žÉĀžě•ŪēėŽäĒ žĘÖŽ™©žĚĄ ŽĆÄžÉĀžúľŽ°ú Ūē® ‚ÄĘ KONEX žĚīž†Ą žÉĀžě•, OTC žĚīž†ĄžÉĀžě• ŽďĪžĚÄ ŪŹ¨Ūē® ‚ÄĘ ÍłįžóÖ žĚłž†ĀŽ∂ĄŪē†žĚĄ ŪÜĶŪēú žč†Í∑úžÉĀžě•, ETF ŽďĪžĚÄ ž†úžôł Ž™©ŪĎú Í≤įÍ≥ľ ‚ÄĘ žĚľŽįėž†ĀžĚł ž£ľÍįÄ žėąžł° Ž™®ŪėēžĚÄ ŪēīŽčĻ žĘÖŽ™©žĚė žėąžÉĀ žąėžĚĶŽ•† ŽįŹ Ž≥ÄŽŹôžĄĪ ŽďĪžĚĄ žėąžł°Ūē® ‚ÄĘ IPOžĚė Í≤Ĺžöį Ūą¨žěźžěź žě֞앞󟞥ú Ž≥ľ ŽēĆ, žėąžÉĀ žąėžĚĶŽ•†Ž≥īŽč§ŽäĒ Í≥ĶŽ™®ÍįÄ ŽĆÄŽĻĄ žčúžīąÍįÄ, žÉĀžě• žĚīŪõĄ ž£ľÍįÄ žõÄžßĀžěĄžĚĄ ŪĆ®ŪĄīŪôĒŪēėžó¨ ŽāėŪÉÄŽāīŽäĒ Í≤ÉžĚī ŽćĒžöĪ ÍįÄžĻė žěąŽäĒ Í≤įÍ≥ľŽ¨ľžĚī Žź† žąė žěąžĚĆ Í≤įÍ≥ľ ŪĆ®ŪĄī Ž™©ŪĎú Í≤įÍ≥ľ ‚ÄĘ IPO žėąžł°žóź ŪēĄžöĒŪēú ŪēĶžč¨Ž≥Äžąė 24ÍįúŽ•ľ žĄ†ž†ēŪē® ‚ÄĘ ŪēīŽčĻ Ž≥ÄžąėŽ•ľ ÍĶ¨ÍįĄŽ≥ĄŽ°ú ŽāėŽąĒ ‚ÄĘ ÍįĀ žĘÖŽ™©žóź ŽĆÄŪēú Cosine Similarity žĚīžö©Ūē® ‚ÄĘ Í≥ĶŽ™®ÍįÄ ŽĆÄŽĻĄ žÉĀžäĻŪēėžėÄžúľŽāė žĚīŪõĄ žßÄžÜć ŪēėŽĚĹ ŪĆ®ŪĄī ‚ÄĘ Í≥ĶŽ™®ÍįÄ Ž∂ÄÍ∑ľžĚė žčúžīąÍįÄ ŪėēžĄĪ žĚīŪõĄ žßÄžÜć žĄĪžě• ŪĆ®ŪĄī ‚ÄĘ žīąÍłį ž°įž†ē žĚīŪõĄ žÉĀžäĻžĄł ŽāėŪÉÄŽāīŽäĒ ŪĆ®ŪĄī ‚ÄĘ Í≥ĶŽ™®ÍįÄ ŪēėŪöĆ žĚīŪõĄ žßÄžÜć ŪēėŽĚĹŪēėŽäĒ ŪĆ®ŪĄī
- 24. 23 3.3 ž£ľžöĒ Ž≥ÄžąėžĚė ž†ēžĚė ÔĀ≠ IPO ž£ľÍįÄ ŪėēžĄĪžóź žėĀŪĖ•žĚĄ ŽĮłžĻėŽäĒ Ž≥Äžąė 24ÍįÄžßÄ ž∂Ēž∂úŪē®. ÔĀ≠ žīĚ 60Íįú žĄ†ž†ē žĚīŪõĄ ž§ĎŽ≥ĶžĄĪ, ž§ĎžöĒŽŹĄ, Í≥ĄŽüČŪôĒ ÍįÄŽä•žĄĪ ŽďĪžĚĄ Í≤ÄŪ܆Ūēėžó¨ Ž≤ĒžúĄ ž∂ēžÜĆ ÔĀ≠ ÍįĀ Žč®Í≥ĄŽäĒ 1~5Ž°ú ÍĶ¨Ž∂Ą. žĚľŽ∂ÄŽäĒ clustering ÍłįŽ≤ē Ūôúžö©ŪēėžėÄžúľŽ©į, žĚľŽ∂ÄŽäĒ Ūą¨žěźžěźžě֞앞󟞥ú žú†žĚėŽĮłŪēú Íłįž§Ä ÍĶ¨Ž∂Ą
- 25. 24 3.4 ŽćįžĚīŪĄį žąėžßĎ ÔĀ≠ IPO ž£ľÍįÄ ŪėēžĄĪžóź žėĀŪĖ•žĚĄ ŽĮłžĻėŽäĒ Ž≥Äžąė 24ÍįÄžßÄ ž∂Ēž∂úŪē®. ÔĀ≠ žīĚ 60Íįú žĄ†ž†ē žĚīŪõĄ ž§ĎŽ≥ĶžĄĪ, ž§ĎžöĒŽŹĄ, Í≥ĄŽüČŪôĒ ÍįÄŽä•žĄĪ ŽďĪžĚĄ Í≤ÄŪ܆Ūēėžó¨ Ž≤ĒžúĄ ž∂ēžÜĆ ÔĀ≠ ÍįĀ Žč®Í≥ĄŽäĒ 1~5Ž°ú ÍĶ¨Ž∂Ą. žĚľŽ∂ÄŽäĒ clustering ÍłįŽ≤ē Ūôúžö©ŪēėžėÄžúľŽ©į, žĚľŽ∂ÄŽäĒ Ūą¨žěźžěźžě֞앞󟞥ú žú†žĚėŽĮłŪēú Íłįž§Ä žĄ†Ž≥Ą
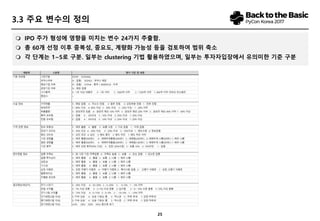
- 26. 25 3.5 žú†žā¨ žĘÖŽ™© Í≤ÄžÉČ ÔĀ≠ ÍįĀ žĘÖŽ™©Ž≥ĄŽ°ú ž†źžąė žěÖŽ†•Ūēėžó¨ List žěĎžĄĪ ÔĀ≠ Cosine Similarity Ūôúžö©Ūēėžó¨ žú†žā¨ŽŹĄ Í≥ĄžāįŪē® ÔĀ≠ ŪēīŽčĻ žĘÖŽ™© žěÖŽ†• žčú ÍįĀ žĘÖŽ™©Ž≥ĄŽ°ú Í≥ľÍĪį žú†žā¨ŽŹĄÍįÄ ŽÜížēėŽćė žĘÖŽ™© žúĄž£ľŽ°ú Í≤ÄžÉČ
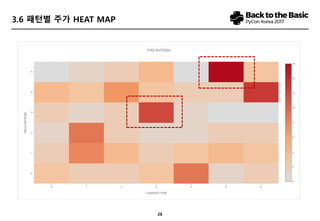
- 27. 26 3.6 ŪĆ®ŪĄīŽ≥Ą ž£ľÍįÄ HEAT MAP
- 28. 27 3.7 Í≤įÍ≥ľ ÔĀ≠ ŪēīŽčĻ žĘÖŽ™©žĚĄ žěÖŽ†• žčú ÍįĀ žĘÖŽ™©Ž≥ĄŽ°ú Í≥ľÍĪį žú†žā¨ŽŹĄÍįÄ ŽÜížēėŽćė žąúžúľŽ°ú Í≤ÄžÉČ, 2011ŽÖĄ žĚīŪõĄŽ•ľ Ž∂ĄžĄĚÍłįÍįĄžúľŽ°ú žĄ†ž†ēŪēėžó¨ ÍłįŽ≥ł ŽćįžĚīŪĄįŽäĒ 289Íįú žĘÖŽ™© Ūôúžö©Ūē® ÔĀ≠ ŽćįžĚīŪĄįÍįÄ ŽąĄž†ĀŽźú 2015ŽÖĄ žĚīŪõĄ 110Íįú žĘÖŽ™©žóź ŽĆÄŪēú Ž∂ĄžĄĚÍ≤įÍ≥ľ ‚ÄėžčúžīąÍįÄ‚Äė Ūē≠Ž™©žĚė Í≤Ĺžöį 85%, ‚ÄėŽčĻžĚľÍĪįŽěė‚Äô Ūē≠Ž™©žĚÄ 73%, žÉĀžě• ŪõĄ ž£ľÍįÄ ŪĆ®ŪĄīžĚė Í≤Ĺžöį ‚Äô66%‚ÄôžĚė žú†žĚėŽĮłŪēú žú†žö©žĄĪžĚĄ Ž≥īžěĄ ÔĀ≠ ŽĆÄŪėēž£ľžĚė Í≤Ĺžöį ž†Āž§ĎŽŹĄÍįÄ ŽāģžēėÍ≥† ŽįėŽ©īžóź ž§ĎžÜĆŪėēž£ľŽäĒ Žß§žöį ŽÜížĚÄ ž†ēŪôēžĄĪ Ž≥īžěĄ (ŽĆÄŪėēž£ľŽäĒ Ž∂ĄžĄĚžĚī žÉĀŽčĻŽ∂ÄŽ∂Ą žĚīŽ£®žĖīž†ł Í≥ľÍĪį ŽćįžĚīŪĄįŽßĆžúľŽ°úŽäĒ žīąÍ≥ľ žąėžĚĶ ÍįÄŽä•žĄĪ ŽÜížßÄ žēäžĚĆ) ÔĀ≠ Žč®žąúŪěą Í≥ľÍĪį ž†Āž§Ďžú®Ž≥īŽč§ŽäĒ žÉąŽ°úžöī ŪĆ®ŪĄī ŽįúÍ≤¨Í≥ľ žĘÖŽ™©ÍĶį Ž∂ĄŽ•ėŽ•ľ ŪÜĶŪēī Ūą¨žěź Insight ŪĖ•žÉĀ
- 29. 28 Í≤įŽ°† ŪĒĄŽ°úÍ∑łŽěėŽįć ŪēôžäĶžĚĄ ŪÜĶŪēī žĄúŽ°úŽ•ľ Ž≥īžôĄŪē† žąė žěąžĚĆ ÍłįÍ≥ĄžĚė žėĀžó≠ ‚Äú ŽĻÖŽćįžĚīŪĄįžôÄ Ž®łžč†Žü¨ŽčĚžúľŽ°ú ŽĆÄŪĎú‚ÄĚ ‚Äú žĚłŪĒĄŽĚľ ŽįŹ ŽćįžĚīŪĄį ÍįÄÍ≥ĶžĚī ž§ĎžöĒ‚ÄĚ ‚ÄúÍ≥ľÍĪį ŽćįžĚīŪĄįŽ•ľ ŪÜĶŪēú ŪĆ®ŪĄī ŪĆĆžēÖÔľā ‚Äú žīąŽč®Íłį Žß§Žß§žóź ž†ĀŪē©‚ÄĚ ‚ÄúPassive Ūą¨žěź, žěźžāįŽįįŽ∂Ą ŽďĪžóź ž£ľŽ°ú Ūôúžö©‚ÄĚ žĚłÍįĄžĚė žėĀžó≠ ‚Äú žßĀÍįź, ŪÜĶžįįŽ†• ŽďĪžúľŽ°ú ŽĆÄŪĎú‚ÄĚ ‚Äú Í≤ĹŪóė ŽįŹ žě¨Žä• ŽďĪžĚī ž§ĎžöĒ‚ÄĚ ‚Äú ŪĆ®Žü¨Žč§žěĄ ŽįŹ Ū䳎ěúŽďú Ž≥ÄŪôĒ žĚłžčĚÔľā ‚Äúž§ĎÍłį, žě•Íłį Ūą¨žěźžóź ž†ĀŪē©‚Äú ‚ÄúžßĎž§Ď Ūą¨žěźžóź Ūôúžö© ÍįÄŽä•Ôľā