






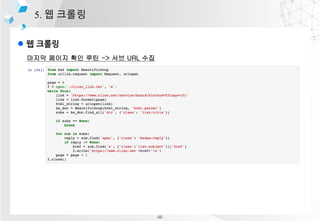
![l ??? ????
1. ?? ??
????
??
?? ??
??
?? ??
(???) ??
??
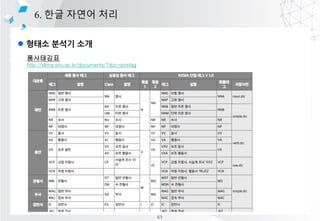
?? ?? ?? ?? ??
1. ???? ??
???? ???? ??
ex) ??? ?? ?? ????
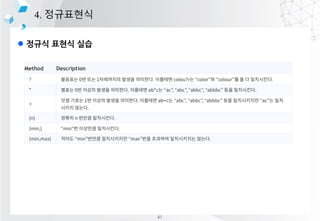
2. ?? ?? ??
??? ???? ?? ??(??? ??, ??? ??)
ex) [???, ??, ??, ????] -> [(??, ??), (??, ??), (????, ??)]
3. ?? ??
????? ?? ???? ?? ??? ??? ??
ex) ??, ??, ???? -> Ī░??Ī▒? ?? ??
4. (???) ?? ?? ©C Dialogue management System
?? ??? ???? ???? ??? ??, ??? ????? ??
ex)???? ???? ??????
5. ?? ?? ??
?? ??? ?? ?? ?? (?? ??? ?? ??? ??? ?? or ?? ??)
ex) ?? ??? ??? ??, ?? ?? ??
6. ?? ??
????? ??? ??
ex) ?? ??? ???????. ????? XXX???.
23](https://image.slidesharecdn.com/chatbotdevelopment1-180804075103/85/Python-1-17-320.jpg)




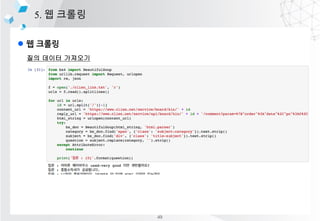
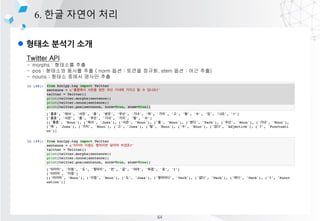
![l pandas? ??? ???
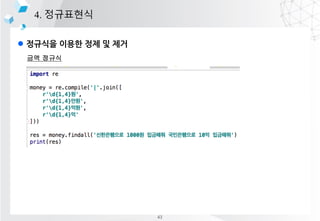
3. ??? ??? ??
index value
0 ?
dtypes1 ?
ĪŁ ĪŁ
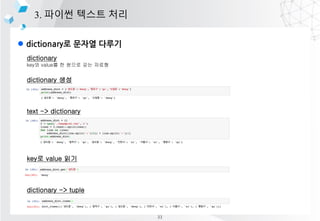
pandas
??? ????? ??? ?? ?? ??? ??? ??? ?????? series, dataframe, panel 3?? ??? ??
series : 1?? ???? ??
dataframe : 2?? ???? ??
panel : 3?? ???? ??
[Series]
column1 column2
index 0 ? 1?
index1 ? 2?
index2 ? 3?
[DataFame]
column1 column2
index 0
index1
index2
column1 column2
index 0
index1
index2
column1 column2
index 0
index1
index2
35](https://image.slidesharecdn.com/chatbotdevelopment1-180804075103/85/Python-1-29-320.jpg)



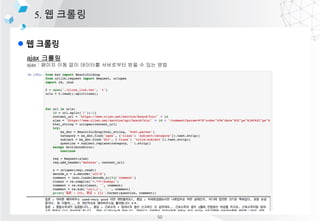
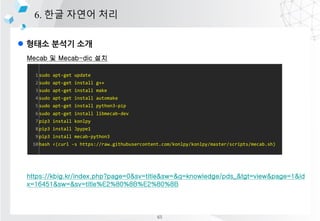
![l ???? ??? ?? ? ??
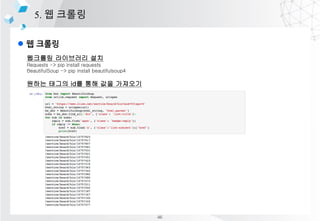
4. ?????
???
??? ??? ?? ???? ??? ???? ? ???? ?? ??
?????
[?-?] : ??? ??
[?-?s] : ?? + ????? ??
[a-zA-Z] : ??? ??
[0-9] : ??? ??
n{1,} : 1? ??? ???
s{1,} : 1? ??? ????
??? ? ??? ?? ??(search)
??? ? ???? ???? ? ????(findall)
39](https://image.slidesharecdn.com/chatbotdevelopment1-180804075103/85/Python-1-33-320.jpg)











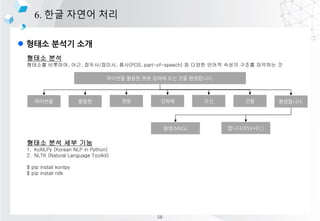


![l ??? ??? ??
6. ?? ??? ??
mecab? ??? ???? ??
??? ?? -> [('??', 'NNP'), ('?', 'JKG'), ('??', 'NNG')]
??? ??? -> [('???', 'NNP'), ('???', 'NNG')]
??? S8 -> [('???', 'NNP'), ('S', 'SL'), ('8', 'SN')]
??
?????????? ?? ??? 22? ?? 4? 40?? ?? ??? ?????? ? ??
? ?????? 18t? ?????? ???? ????.
???? ???
??????????^??^???^22?^??^4?^40??^??^???^??????^
?^???^??????^18t?^??????^????^????.
??? ??
[('??', 'NNG'), ('??', 'NNG'), ('??', 'NNG'), ('??', 'NNG'), ('??', 'NNG'), ('^', 'SY'),
('?', 'NNB'), ('?', 'JKB'), ('^', 'SY'), ('??', 'VV'), ('?', 'EC'), ('^', 'SY'), ('22', 'SN'), ('?',
'NNBC'), ('^', 'SY'), ('??', 'NNG'), ('^', 'SY'), ('4', 'SN'), ('?', 'NNBC'), ('^', 'SY'), ('40',
'SN'), ('?', 'NNBC'), ('?', 'XSN'), ('^', 'SY'), ('??', 'NNG'), ('^', 'SY'), ('???', 'NNP'),
('^', 'SY'), ('??', 'NNG'), ('?', 'XPN'), ('??', 'NNG'), ('?', 'JKG'), ('^', 'SY'), ('?', 'NNP'),
('^', 'SY'), ('???', 'NNG'), ('^', 'SY'), ('??', 'NNG'), ('??', 'NNG'), ('??', 'JKB'), ('^',
'SY'), ('18', 'SN'), ('t', 'SL'), ('?', 'NNG'), ('^', 'SY'), ('??', 'NNG'), ('???', 'NNG'), ('?',
'JKG'), ('^', 'SY'), ('???', 'NNG'), ('?', 'JKS'), ('^', 'SY'), ('???', 'VV+EP'), ('?', 'EF'),
('.', 'SF')]
NNG, NNP, SY, SN, JKG ?????????? ĪŁ
??? ?? ??
[[0, 1, 2, 3, 4, 5], [8], [11], [14, 15, 16], [19], [23, 24, 25, 26, 27, 28], [30], [32, 33, 34, 35,
36, 37, 38], [40], [43, 44, 45, 46], [48, 49], [51]]
72](https://image.slidesharecdn.com/chatbotdevelopment1-180804075103/85/Python-1-66-320.jpg)

Python? ??? ?? ??? ?? 1??
- 1. ???? ??? ?? ??? ?? 1??
- 2. 1. ??? ??? ????? ?? ??? ? ??. 2. ???? ???? ??? ???? ???? ???? ??? ??? ? ??. 3. ??? ???? ???? ?? ??? ?? ???? ??? ??? ? ? ??. 4. ??? ??? ??????, ????, ??? ???? ?? ??? ? ??. 5. ?? ?? ???? ???? ??? ?? ??? ??? ? ??. l ?? ?? 8
- 3. ???? ??? ?? ??? ?? 1??
- 4. 1. ?? ?? 2. Docker ???? ?? 3. ??? ??? ?? 4. ????? 5. ? ??? ?? 6. ?? ??? ?? l 1?? ?? ?? 10
- 5. ?? ?? 11
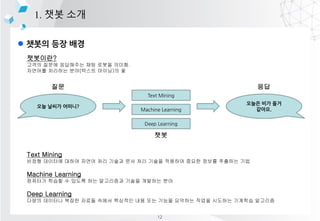
- 6. l ??? ?? ?? 1. ?? ?? ????? ??? ??? ????? ?? ??? ???. ???? ???? ??(??? ???)? ? Text Mining ??? ???? ??? ??? ?? ??? ?? ?? ??? ???? ??? ??? ???? ?? Machine Learning ???? ??? ? ??? ?? ????? ??? ???? ?? Deep Learning ??? ???? ??? ??? ??? ???? ?? ?? ??? ???? ??? ???? ???? ???? ?? ?? ?? ??? ???? Text Mining Machine Learning Deep Learning ??? ?? ?? ???. ?? 12
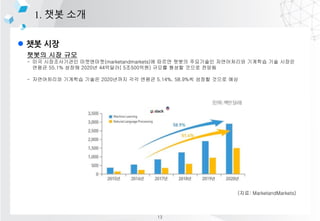
- 7. l ?? ?? 1. ?? ?? ??? ?? ?? - ?? ??????? ?????(marketandmarkets)? ??? ??? ????? ?????? ???? ?? ??? ??? 55.1% ??? 2020? 44???( 5?500??) ??? ??? ??? ??? - ?????? ???? ??? 2020??? ?? ??? 5.14%, 58.9%? ??? ??? ?? (??: MarketandMarkets) 13
- 8. l ?? ?? ?? 1. ?? ?? ?? wit.ai api.ai luis.ai ?? ???? ?? ??????? ???? ?? ?? 1?? 1?? ?? ?? ????? ???? ?? STT? TTS ?? NLU ?? ?? ? ?? ??, ??, URL, ???, ???? @sys.date, @sys.color, @sys. unit-currency Builtin .intent.alarm Builtin.intent.calendar Builtin.intent.email ?? ??? ? ??? API ???? ??? MS Azure ??? ?? ?? 2015? ? ??? ??? ?? 2016? ??? ? ?? ? ? ?? ?? Skype ?? ??? ?? MS Bot Framework ? ?? ?? ? ?? iOS, Android, Node.js, Raspberry Pi, Ruby, Python, C, Rust, Windows Pho ne ??. Front End ???? ?? JavaScript ???? Android, iOS, Appl Watch, Node.js, Cordova, Unity, C#, Xamarin, Windows Phone, Python, JavaScript SDK. Am azon Echo, MS Cortana? ? ? ?? LUIS ? ?????? ?? ? ? ??. ?? ?? X 14
- 9. l ?? ?? ?? ?? 1. ?? ?? Tommy Hilfiger H&M Burberry Pizza Hut KLM 15
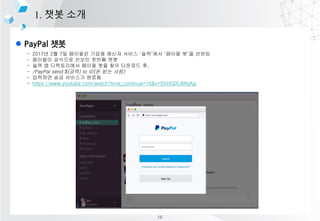
- 10. l PayPal ?? 1. ?? ?? - 2017? 2? 7? ???? ??? ??? ??? Ī«??Ī»?? Ī«??? ?Ī»? ??? - ???? ???? ??? ??? ?? - ?? ? ?????? ??? ?? ?? ???? ?, - /PayPal send $(??) to @(? ?? ??) - ???? ?? ???? ??? - https://www.youtube.com/watch?time_continue=16&v=SVHGDU8RsAg 16
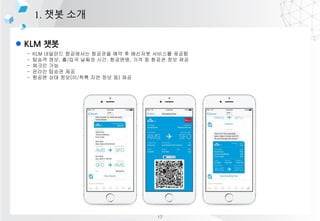
- 11. l KLM ?? 1. ?? ?? - KLM ???? ????? ???? ?? ? ???? ???? ??? - ??? ??, ?/?? ??? ??, ????, ?? ? ??? ?? ?? - ??? ?? - ??? ??? ?? - ??? ?? ??(?/?? ?? ?? ?) ?? 17
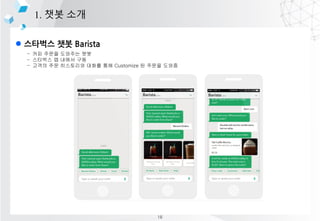
- 12. l ???? ?? Barista 1. ?? ?? - ?? ??? ???? ?? - ???? ? ??? ?? - ??? ?? ????? ??? ?? Customize ? ??? ??? 18
- 13. l ??? ???? 1. ?? ?? 19
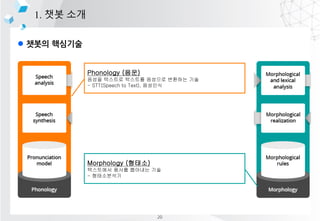
- 14. l ??? ???? 1. ?? ?? Phonology (??) ??? ???? ???? ???? ???? ?? - STT(Speech to Text), ???? Morphology (???) ????? ??? ???? ?? - ?????? 20
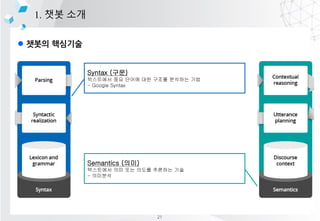
- 15. l ??? ???? 1. ?? ?? Syntax (??) ????? ?? ??? ?? ??? ???? ?? - Google Syntax Semantics (??) ????? ?? ?? ??? ???? ?? - ???? 21
- 16. l ??? ??? AI ?? 1. ?? ?? 1. Retrieval-Based Model ???? ??? ?? ??? ? ??? ?? ex) {??} ?? {??}? ???. ??? ??? ?? ?? ??? ???? ??? ???? ?? But, ?? ??? ??? ?? ?? ?? ?? ? ??. 2. Generative Model ???? ??? ??? ???? ??? ?? But, ??? ?? ??? ??? ??? ??? ??? ? ??. So, ?? ??? ???? Retrieval-Based Model? ?? ?? ??? ???? Generative Model? ??? ?? 22
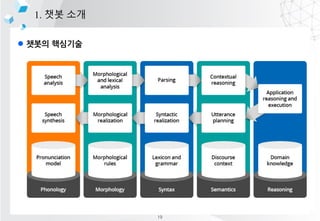
- 17. l ??? ???? 1. ?? ?? ???? ?? ?? ?? ?? ?? ?? (???) ?? ?? ?? ?? ?? ?? ?? 1. ???? ?? ???? ???? ?? ex) ??? ?? ?? ???? 2. ?? ?? ?? ??? ???? ?? ??(??? ??, ??? ??) ex) [???, ??, ??, ????] -> [(??, ??), (??, ??), (????, ??)] 3. ?? ?? ????? ?? ???? ?? ??? ??? ?? ex) ??, ??, ???? -> Ī░??Ī▒? ?? ?? 4. (???) ?? ?? ©C Dialogue management System ?? ??? ???? ???? ??? ??, ??? ????? ?? ex)???? ???? ?????? 5. ?? ?? ?? ?? ??? ?? ?? ?? (?? ??? ?? ??? ??? ?? or ?? ??) ex) ?? ??? ??? ??, ?? ?? ?? 6. ?? ?? ????? ??? ?? ex) ?? ??? ???????. ????? XXX???. 23
- 18. ?? ?? 24
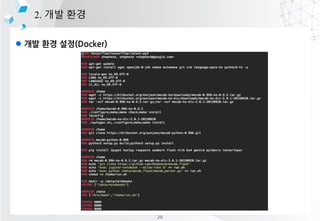
- 19. l ?? ?? ??(Docker) 2. ?? ?? Docker?? ?? ????? ??? ??????? build, ship, run ? ? ??, ??? ????? ????? ???. (https://www.docker.com) Docker Image ???? ??? ??? ??? ???? Docker Container ??? ???? ????? ?? 25
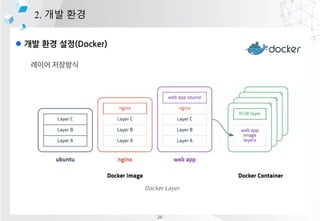
- 20. l ?? ?? ??(Docker) 2. ?? ?? 26
- 21. l ?? ?? ?? 2. ?? ?? 1. Docker ??? ??? ?? - docker images 2. Docker ??? ?? (hello-world and ubuntu) ©C docker search ubuntu 3. Docker ??? ???? ©C docker pull ubuntu:latest 4. Docker ??? ?? ©C docker run hello-world 5. Docker ???(run, inspect, history, ps) docker ps, docker inspect {container name} 6. Docker run ??(volume link: ©Cv, Port ???:-p, ???? ??-d, interactive tty: -it, ?? ?? ?) 7. ?? ?? ????? attach - docker exec {container name} 8. ?? ?? ??? Docker container? ?? docekr cp {file_name} {container_name}:{path} 9. Docker container ??? ??? ?? 10. ???? Dockerfile ?? ?, Build Test 27
- 22. l ?? ?? ??(Docker) 2. ?? ?? Docker?? ?? ????? ??? ??????? build, ship, run ? ? ??, ??? ????? ????? ???. (https://www.docker.com) Ubuntu 16.04 LTS + Python + Tensorflow + Konlpy + Mecab + Flask + Jupyter Image 28
- 23. l ?? ?? ??(Docker) 2. ?? ?? 29
- 24. ??? ??? ?? 30
- 25. l ??? ?? 3. ??? ??? ?? ??? ??? ??? ???? ??? ?? ? ?? ??? ?? 31
- 26. l ??? ?? 3. ??? ??? ?? ??? ??? ??? ???, ?? ??? ?? 32
- 27. l dictionary? ??? ??? 3. ??? ??? ?? dictionary key? value? ? ??? ?? ??? dictionary ?? text -> dictionary key? value ?? dictionary -> tuple 33
- 28. l ??? ???? 3. ??? ??? ?? ?? ??? -> ???? ??? ?? ?? ??? ?? ?? ??? ?? ??? 34
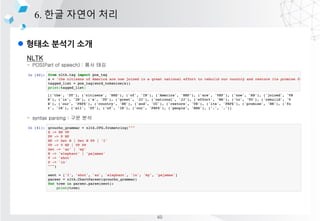
- 29. l pandas? ??? ??? 3. ??? ??? ?? index value 0 ? dtypes1 ? ĪŁ ĪŁ pandas ??? ????? ??? ?? ?? ??? ??? ??? ?????? series, dataframe, panel 3?? ??? ?? series : 1?? ???? ?? dataframe : 2?? ???? ?? panel : 3?? ???? ?? [Series] column1 column2 index 0 ? 1? index1 ? 2? index2 ? 3? [DataFame] column1 column2 index 0 index1 index2 column1 column2 index 0 index1 index2 column1 column2 index 0 index1 index2 35
- 30. l pandas? ??? ??? 3. ??? ??? ?? Dataframe csv load Dataframe csv save 36
- 31. l pandas? ??? ??? 3. ??? ??? ?? Dataframe ?? string ?? Dataframe groupby 37
- 32. ????? 38
- 33. l ???? ??? ?? ? ?? 4. ????? ??? ??? ??? ?? ???? ??? ???? ? ???? ?? ?? ????? [?-?] : ??? ?? [?-?s] : ?? + ????? ?? [a-zA-Z] : ??? ?? [0-9] : ??? ?? n{1,} : 1? ??? ??? s{1,} : 1? ??? ???? ??? ? ??? ?? ??(search) ??? ? ???? ???? ? ????(findall) 39
- 34. l ??? ??? ?? 4. ????? 1. Ī».Ī»??? ? ??? ?? ex) a.c -> abc,aec,avb,afc ... 2. Ī»*Ī»: 0? ???? ?? ??? ??? ?? ??? ??. ex) s*e -> se,see,ssefe ... 3. Ī»+Ī»: 1? ???? ?? ??? ?? ??? ?? ex) s+e -> sse,ssee ... 4. Ī»?Ī»: 0 ?? 1??? ?? ??? ??? ?? ?? ??. ex) th?e -> e, the ? ??? ?? ?? 5. Ī»^Ī»: ??????? ?? ??? ??. 6. Ī»$Ī»: ????? ?? ?? ??.Ī»()Ī»: ????? ?? ??? ?? ? ??.Ī»nĪ»:???? n?? ?????? ??? ? n??? ??. 40
- 35. l ??? ??? ?? 4. ????? 41
- 36. l ??? ??? ?? 4. ????? 42
- 37. l ???? ??? ?? ? ?? 4. ????? ?? ??? 43
- 38. l ??? ??? ?? 4. ????? ?? ??? ??( 1,000 ??, 1000??, 100??) ?? (?? ??? 2017-08-02??. -> 2017-08-02) ???? ?? (???? Home? ?????. -> ???? ? ?????.) ??? ?? (????, Home? ?????. -> Home) ???? ?? (????, Home? ?????! ->???? Home? ?????) ?? ?? (Ī░???? ?? ???? -> ??????????.Ī▒) ?? ?? ??? ?? (???? ?? ???? -> ???? ?? ????.Ī▒) 44
- 39. ? ??? 45
- 40. l ? ??? 5. ? ??? ???? ????? ?? Requests -> pip install requests BeautifulSoup -> pip install beautifulsoup4 ??? ??? id? ?? ?? ???? 46
- 41. l ? ??? 5. ? ??? HTML ?? ?? Chrome -> https://www.clien.net/service/board/kin -> F12 -> ?? 47
- 42. l ? ??? 5. ? ??? ??? ??? ?? ?? -> ?? URL ?? 48
- 43. l ? ??? 5. ? ??? ?? ??? ???? 49
- 44. l ? ??? 5. ? ??? ajax ??? ajax : ??? ?? ?? ???? ????? ?? ? ?? ?? 50
- 45. l Pandas? ??? ??? ?? ?? 5. ? ??? ??? ??? ?? ?, Pandas Dataframe?? ?? Dataframe?? ??? ??? ?? - ??? - ?? ?????? ???? ??? ?? - ????? ??? ?? 51
- 46. ?? ??? ?? 52
- 47. l ??? ?? 4?? ?? ?? 6. ?? ??? ?? 1. ?? ?? ©C POS(Part of speech) tagging - ?? ?? ?? ???? ??(??, ??, ??? ?) ??? ???? ?? ex) (???, ??), (?,??) (??, ??), (?, ??) (?????, ??) 2. ??? ?? ©C NER(Named Entity Recognition) - ?? ??? ??, ??, ??, ?? ?? ?? ???? ??? ex) (??? ??, ??) (??, ??) ?????. 3. ?? ?? - Chunking(Shallow Parsing) - ????? ??? ???? ?? ?? ??? ?? ?? ex) (??? ???? ??, ??)? 4. ??? ?? ©C SRL(Semantic-role labeling) - ???? ??? ?? ??? ??? ??? ?? ex) (?)? ???, (?)? ???, (?)? ???? 53
- 48. l ??? ?? ?? ?? 6. ?? ??? ?? ??? ?? ?? ??? ??? ??? ?? ?? ??? ??? ??, ??, ?? ?? ?? ??? ??? ???? ??? ??? ?? ??? ???? ?? ?? ?? ??? ??????? ?? ???? ??, ??? ????? ???? ?? ???? ??? ?? ??? ??? ???? ??? ?? ???? ??? ??? ???? ??? ?? ???? ???? ??? ??? ?? ??? ???? ??? ?? ?? ?? ??? ???? 54
- 49. l ???? ?? 6. ?? ??? ?? 1. ??: ?? ?? ????? ?? ?? ?? ? ??: ? ?? ?? ??? ?? ????? ?? ??(??? ??, ex) ?,?,?) ? ??: ??? ??? ????? ???? ?? ??? ??? ??(?? ???, ??, ??) 2. ??: ??? ??? ?? ??? ?? ???? ?? 3. ???: ?? ?? ?? ?? ?? 4. ??: ???? ????? ?? ?? ? 5. ??: ??? ???? ?? ??? ?? 6. ??: ?? ?? ?? 1. ?: ?? ??? ? ? ??? ??? ???? ??? ?? ??? ?? ???(N + N) 2. ?: ??? ??? ??? ???? ? (S+V) 7. ??: ???? ??? ?? ??? ? ??? ??? ???? ?? ?? 8. ??: ?? ??? ?? ??? ?? ??? ???? ??? ?? > ?? > ??(?, ?) > ?? > ?? > ??? > ?? > ??(??, ??) 55
- 50. l ???? ?? 6. ?? ??? ?? 1. ??(Syllable) - ??? ?? ? ? ?? ???? ex) ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ? ? 2. ?? - ?? ? ??? ?? ?? ?? ex) ?? v ??? v ?? v ????. 3. ?? ?? ??? ?? ?? ? ?? ?? ?? 4. ??? ?? ??? ?? ?? ?? ?? ?? 1. ???? ??? ?? ?? ? ?????(?? ??) ex) ??, ? ? ?????(??? ??) ex) ?, ? 2. ??? ?? ? ?? ??? ? ?? ??? 56
- 51. l ??? ??? ?? 6. ?? ??? ?? ??:http://blog.naver.com/PostView.nhn?blogId=ccc192000&logNo=40095566627 57
- 52. l ??? ??? ?? 6. ?? ??? ?? ??? ?? ???? ????, ??, ???/???, ??(POS, part-of-speech) ? ??? ??? ??? ??? ???? ? ??? ?? ?? ?? 1. KoNLPy (Korean NLP in Python) 2. NLTK (Natural Language Toolkit) $ pip install konlpy $ pip install nltk ???? ??? ?? ??? ?? ?? ?????. ???? ??? ?? ??? ?? ?? ?????. ??(NNG) ???(XSV+EC) 58
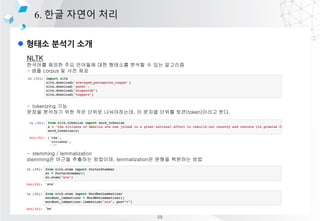
- 53. l ??? ??? ?? 6. ?? ??? ?? NLTK ???? ??? ?? ???? ?? ???? ??? ? ?? ???? - ?? corpus ? ?? ?? - tokenizing ?? ??? ???? ?? ?? ??? ??????, ? ??? ??? ??(token)??? ??. - stemming / lemmatization stemming? ??? ???? ????, lemmatization? ??? ???? ?? 59
- 54. l ??? ??? ?? 6. ?? ??? ?? NLTK - POS(Part of speech) : ?? ?? - syntax parsing : ?? ?? 60
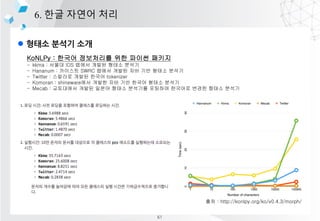
- 55. l ??? ??? ?? 6. ?? ??? ?? KoNLPy : ??? ????? ?? ??? ??? - kkma : ??? IDS ??? ??? ??? ??? - Hananum : ???? SWRC ??? ??? ?? ?? ??? ??? - Twitter : ???? ??? ??? tokenizer - Komoran : shineware?? ??? ?? ?? ??? ??? ??? - Mecab : ????? ??? ??? ??? ???? ???? ???? ??? ??? ??? ?? : http://konlpy.org/ko/v0.4.3/morph/ 61
- 56. l ??? ??? ?? 6. ?? ??? ?? KoNLPy : ??? ????? ?? ??? ??? - kkma : ??? IDS ??? ??? ??? ??? - Hananum : ???? SWRC ??? ??? ?? ?? ??? ??? - Twitter : ???? ??? ??? tokenizer - Komoran : shineware?? ??? ?? ?? ??? ??? ??? - Mecab : ????? ??? ??? ??? ???? ???? ???? ??? ??? ??? ?? : http://konlpy.org/ko/v0.4.3/morph/ ?? ?? ??? vs ??? ?? ??? ??????????? 62
- 57. l ??? ??? ?? 6. ?? ??? ?? ????? http://kkma.snu.ac.kr/documents/?doc=postag 63
- 58. l ??? ??? ?? 6. ?? ??? ?? Twitter API - morphs : ???? ?? - pos : ???? ??? ?? ( norm ?? : ??? ???, stem ?? : ?? ??) - nouns : ??? ??? ??? ?? 64
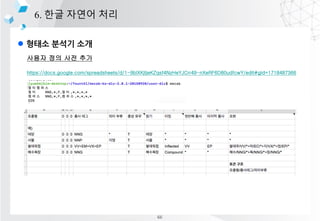
- 59. l ??? ??? ?? 6. ?? ??? ?? Mecab ? Mecab-dic ?? ????? ?? NIADic https://kbig.kr/index.php?page=0&sv=title&sw=&q=knowledge/pds_&tgt=view&page=1&id x=16451&sw=&sv=title%E2%80%8B%E2%80%8B 1 2 3 4 5 6 7 8 9 10 sudo apt-get update sudo apt-get install g++ sudo apt-get install make sudo apt-get install automake sudo apt-get install python3-pip sudo apt-get install libmecab-dev pip3 install konlpy pip3 install Jpype1 pip3 install mecab-python3 bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh) 65
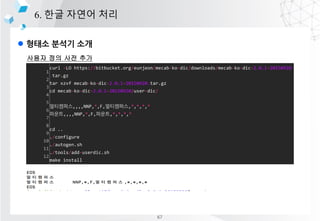
- 60. l ??? ??? ?? 6. ?? ??? ?? ??? ?? ?? ?? https://docs.google.com/spreadsheets/d/1-9blXKjtjeKZqsf4NzHeYJCrr49-nXeRF6D80udfcwY/edit#gid=1718487366 66
- 61. l ??? ??? ?? 6. ?? ??? ?? ??? ?? ?? ?? 1 2 3 4 5 6 7 8 9 10 11 12 curl -LO https://bitbucket.org/eunjeon/mecab-ko-dic/downloads/mecab-ko-dic-2.0.1-20150920 .tar.gz tar xzvf mecab-ko-dic-2.0.1-20150920.tar.gz cd mecab-ko-dic-2.0.1-20150920/user-dic/ ?????,,,,NNP,*,F,?????,*,*,*,* ???,,,,NNP,*,F,???,*,*,*,* cd .. ./configure ./autogen.sh ./tools/add-userdic.sh make install 67
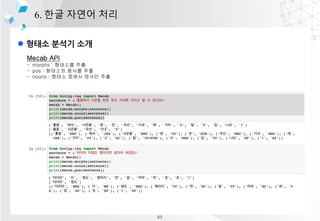
- 62. l ??? ??? ?? ?? 6. ?? ??? ?? Mecab API - morphs : ???? ?? - pos : ???? ??? ?? - nouns : ??? ??? ??? ?? Twitter API - morphs : ???? ?? - pos : ???? ??? ?? - nouns : ??? ??? ??? ?? Kkma API - morphs : ???? ?? - pos : ???? ??? ?? - nouns : ??? ??? ??? ?? Hannanum API - morphs : ???? ?? - pos : ???? ??? ?? - nouns : ??? ??? ??? ?? Sample text - string1 = '????????????Ī» - string2 = '??? ?? ?? ????Ī» - string3 = '??? ?? ?? ???Ī» - string4 = '??? ??? ??? ?? ??? ???? ??? ?? ??? ?? ??????' 68
- 63. l ??? ??? ?? 6. ?? ??? ?? Mecab API - morphs : ???? ?? - pos : ???? ??? ?? - nouns : ??? ??? ??? ?? 69
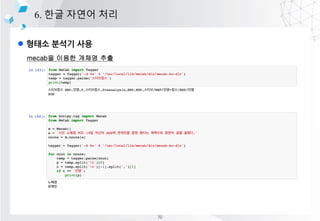
- 64. l ??? ??? ?? 6. ?? ??? ?? mecab? ??? ??? ?? 70
- 65. l ??? ??? ?? 6. ?? ??? ?? Mecab + ??? ?? ??? ??? ??? ??? ?????,,,,NNP,*,F,?????,*,*,??,* ????,,,,NNP,*,F,????,*,*,??,* company.csv 71
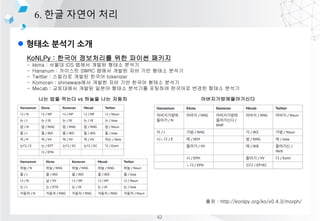
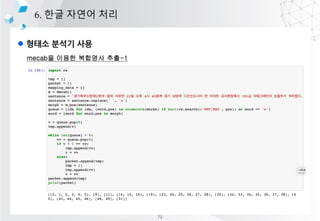
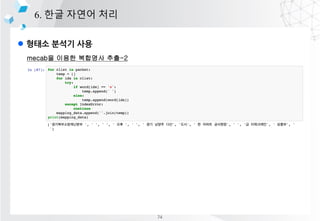
- 66. l ??? ??? ?? 6. ?? ??? ?? mecab? ??? ???? ?? ??? ?? -> [('??', 'NNP'), ('?', 'JKG'), ('??', 'NNG')] ??? ??? -> [('???', 'NNP'), ('???', 'NNG')] ??? S8 -> [('???', 'NNP'), ('S', 'SL'), ('8', 'SN')] ?? ?????????? ?? ??? 22? ?? 4? 40?? ?? ??? ?????? ? ?? ? ?????? 18t? ?????? ???? ????. ???? ??? ??????????^??^???^22?^??^4?^40??^??^???^??????^ ?^???^??????^18t?^??????^????^????. ??? ?? [('??', 'NNG'), ('??', 'NNG'), ('??', 'NNG'), ('??', 'NNG'), ('??', 'NNG'), ('^', 'SY'), ('?', 'NNB'), ('?', 'JKB'), ('^', 'SY'), ('??', 'VV'), ('?', 'EC'), ('^', 'SY'), ('22', 'SN'), ('?', 'NNBC'), ('^', 'SY'), ('??', 'NNG'), ('^', 'SY'), ('4', 'SN'), ('?', 'NNBC'), ('^', 'SY'), ('40', 'SN'), ('?', 'NNBC'), ('?', 'XSN'), ('^', 'SY'), ('??', 'NNG'), ('^', 'SY'), ('???', 'NNP'), ('^', 'SY'), ('??', 'NNG'), ('?', 'XPN'), ('??', 'NNG'), ('?', 'JKG'), ('^', 'SY'), ('?', 'NNP'), ('^', 'SY'), ('???', 'NNG'), ('^', 'SY'), ('??', 'NNG'), ('??', 'NNG'), ('??', 'JKB'), ('^', 'SY'), ('18', 'SN'), ('t', 'SL'), ('?', 'NNG'), ('^', 'SY'), ('??', 'NNG'), ('???', 'NNG'), ('?', 'JKG'), ('^', 'SY'), ('???', 'NNG'), ('?', 'JKS'), ('^', 'SY'), ('???', 'VV+EP'), ('?', 'EF'), ('.', 'SF')] NNG, NNP, SY, SN, JKG ?????????? ĪŁ ??? ?? ?? [[0, 1, 2, 3, 4, 5], [8], [11], [14, 15, 16], [19], [23, 24, 25, 26, 27, 28], [30], [32, 33, 34, 35, 36, 37, 38], [40], [43, 44, 45, 46], [48, 49], [51]] 72
- 67. l ??? ??? ?? 6. ?? ??? ?? mecab? ??? ???? ??-1 73
- 68. l ??? ??? ?? 6. ?? ??? ?? mecab? ??? ???? ??-2 74
- 69. Q&A 75