







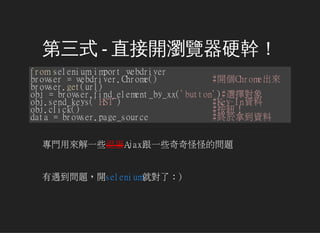






![看個例子
classWorker(threading.Thread):
def__init__(self,queue):
threading.Thread.__init__(self)
self.queue=queue
defrun(self):
whileTrue:
try:
url=self.queue.get(timeout=1)
exceptQueue.Empty:
return
GetData(url)
self.queue.task_done()
queue=Queue.Queue()
threads=[]
foriinrange(thread_num):
worker=Worker(queue)
worker.setDaemon(True)
worker.start()
threads.append(worker)](https://image.slidesharecdn.com/reveal-150517074138-lva1-app6892/85/Python-16-320.jpg)







Python 網頁爬蟲由淺入淺
- 5. 开始吧!
- 7. 第一式 - 先抓抓看再說 importurllib2 data=urllib2.urlopen(url).read() #拿到資料啦! 不管遇到什麼網站,我都一律先用urllib2來看看這是不是 個簡單抓的網站,用來決定開價技術程度
- 8. 第二式 - 換個姿勢 importpycurl importStringIO curl=pycurl.Curl() curl.fp=StringIO.StringIO() curl.setopt(pycurl.URL,url) curl.setopt(crl.WRITEFUNCTION,crl.fp.write) curl.setopt(pycurl.DEBUGFUNCTION,show)#重要!不然螢幕會很吵 curl.perform() data=crl.fp.getvalue() #終於拿到資料 有些網站輕微雞掰難抓,需要cookie或是agent才可以讀到 網頁,懶得用cookielib或是捏header的時候可以用
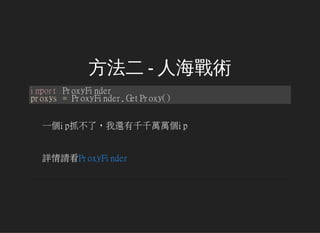
- 9. 第三式 - 直接開瀏覽器硬幹! fromseleniumimportwebdriver browser=webdriver.Chrome() #開個Chrome出來 browser.get(url) obj=browser.find_element_by_xx('button')#選擇對象 obj.send_keys('HST') #Key-In資料 obj.click() #按鈕! data=browser.page_source #終於拿到資料 專門用來解一些混蛋Ajax跟一些奇奇怪怪的問題 有遇到問題,開selenium就對了:)
- 11. 你以為问题就这样全解决了吗?
- 12. 第四式 - 毀天滅地不敢直式 importvirtkey #按鍵精靈 v=virtkey.virtkey() v.press_unicode(ord(s)) v.release_unicode(ord(s)) importpytesser #影像辨識 image=Image.open('fuck.png') data=image_to_string(image) #幹他媽的終於拿到資料 希望你不要走到這一步,使出這招你可能會有生活不能自 理或是對人生絕望等副作用
- 17. 什麼?因為尻抓太快被挡了?!
- 18. 这边讲一下我平常用的两种方法
- 21. 今天的小分享大概到这边
- 22. 如果我讲的这麼简单你都听不懂
- 24. Q & A