







![Download tutorial notebook
# On the Shared Computing Cluster
[scc1 ~] cp /project/scv/examples/python/data_analysis/dataScience.ipynb .
# On a local computer save the link:
http://rcs.bu.edu/examples/python/data_analysis/dataScience.ipynb
10](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-10-320.jpg)
![Start Jupyter nootebook
# On the Shared Computing Cluster
[scc1 ~] jupyter notebook
11](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-11-320.jpg)
![In [ ]:
Loading Python Libraries
12
#Import Python Libraries
import numpy as np
import scipy as sp
import pandas as pd
import matplotlib as mpl
import seaborn as sns
Press Shift+Enter to execute the jupyter cell](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-12-320.jpg)
![In [ ]:
Reading data using pandas
13
#Read csv file
df = pd.read_csv("http://rcs.bu.edu/examples/python/data_analysis/Salaries.csv")
There is a number of pandas commands to read other data formats:
pd.read_excel('myfile.xlsx',sheet_name='Sheet1', index_col=None, na_values=['NA'])
pd.read_stata('myfile.dta')
pd.read_sas('myfile.sas7bdat')
pd.read_hdf('myfile.h5','df')
Note: The above command has many optional arguments to fine-tune the data import process.](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-13-320.jpg)
![In [3]:
Exploring data frames
14
#List first 5 records
df.head()
Out[3]:](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-14-320.jpg)
![Data Frame data types
Pandas Type Native Python Type Description
object string The most general dtype. Will be
assigned to your column if column
has mixed types (numbers and
strings).
int64 int Numeric characters. 64 refers to
the memory allocated to hold this
character.
float64 float Numeric characters with decimals.
If a column contains numbers and
NaNs(see below), pandas will
default to float64, in case your
missing value has a decimal.
datetime64, timedelta[ns] N/A (but see the datetime module
in Python’s standard library)
Values meant to hold time data.
Look into these for time series
experiments.
16](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-16-320.jpg)
![In [4]:
Data Frame data types
17
#Check a particular column type
df['salary'].dtype
Out[4]: dtype('int64')
In [5]: #Check types for all the columns
df.dtypes
Out[4]: rank
discipline
phd
service
sex
salary
dtype: object
object
object
int64
int64
object
int64](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-17-320.jpg)


![Data Frames methods
20
df.method() description
head( [n] ), tail( [n] ) first/last n rows
describe() generate descriptive statistics (for numeric columns only)
max(), min() return max/min values for all numeric columns
mean(), median() return mean/median values for all numeric columns
std() standard deviation
sample([n]) returns a random sample of the data frame
dropna() drop all the records with missing values
Unlike attributes, python methods have parenthesis.
All attributes and methods can be listed with a dir() function: dir(df)](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-20-320.jpg)

![Selecting a column in a Data Frame
Method 1: Subset the data frame using column name:
df['sex']
Method 2: Use the column name as an attribute:
df.sex
Note: there is an attribute rank for pandas data frames, so to select a column with a name
"rank" we should use method 1.
22](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-22-320.jpg)

![Data Frames groupby method
24
Using "group by" method we can:
• Split the data into groups based on some criteria
• Calculate statistics (or apply a function) to each group
• Similar to dplyr() function in R
In [ ]: #Group data using rank
df_rank = df.groupby(['rank'])
In [ ]: #Calculate mean value for each numeric column per each group
df_rank.mean()](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-24-320.jpg)
![Data Frames groupby method
25
Once groupby object is create we can calculate various statistics for each group:
In [ ]: #Calculate mean salary for each professor rank:
df.groupby('rank')[['salary']].mean()
Note: If single brackets are used to specify the column (e.g. salary), then the output is Pandas Series object.
When double brackets are used the output is a Data Frame](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-25-320.jpg)
![Data Frames groupby method
26
groupby performance notes:
- no grouping/splitting occurs until it's needed. Creating the groupby object
only verifies that you have passed a valid mapping
- by default the group keys are sorted during the groupby operation. You may
want to pass sort=False for potential speedup:
In [ ]: #Calculate mean salary for each professor rank:
df.groupby(['rank'], sort=False)[['salary']].mean()](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-26-320.jpg)
![Data Frame: filtering
27
To subset the data we can apply Boolean indexing. This indexing is commonly
known as a filter. For example if we want to subset the rows in which the salary
value is greater than $120K:
In [ ]: #Calculate mean salary for each professor rank:
df_sub = df[ df['salary'] > 120000 ]
In [ ]: #Select only those rows that contain female professors:
df_f = df[ df['sex'] == 'Female' ]
Any Boolean operator can be used to subset the data:
> greater; >= greater or equal;
< less; <= less or equal;
== equal; != not equal;](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-27-320.jpg)

![Data Frames: Slicing
29
When selecting one column, it is possible to use single set of brackets, but the
resulting object will be a Series (not a DataFrame):
In [ ]: #Select column salary:
df['salary']
When we need to select more than one column and/or make the output to be a
DataFrame, we should use double brackets:
In [ ]: #Select column salary:
df[['rank','salary']]](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-29-320.jpg)
![Data Frames: Selecting rows
30
If we need to select a range of rows, we can specify the range using ":"
In [ ]: #Select rows by their position:
df[10:20]
Notice that the first row has a position 0, and the last value in the range is omitted:
So for 0:10 range the first 10 rows are returned with the positions starting with 0
and ending with 9](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-30-320.jpg)
![Data Frames: method loc
31
If we need to select a range of rows, using their labels we can use method loc:
In [ ]: #Select rows by their labels:
df_sub.loc[10:20,['rank','sex','salary']]
Out[ ]:](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-31-320.jpg)
![Data Frames: method iloc
32
If we need to select a range of rows and/or columns, using their positions we can
use method iloc:
In [ ]: #Select rows by their labels:
df_sub.iloc[10:20,[0, 3, 4, 5]]
Out[ ]:](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-32-320.jpg)
![Data Frames: method iloc (summary)
33
df.iloc[0] # First row of a data frame
df.iloc[i] #(i+1)th row
df.iloc[-1] # Last row
df.iloc[:, 0] # First column
df.iloc[:, -1] # Last column
df.iloc[0:7] #First 7 rows
df.iloc[:, 0:2] #First 2 columns
df.iloc[1:3, 0:2] #Second through third rows and first 2 columns
df.iloc[[0,5], [1,3]] #1st and 6th rows and 2nd and 4th columns](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-33-320.jpg)
![Data Frames: Sorting
34
We can sort the data by a value in the column. By default the sorting will occur in
ascending order and a new data frame is return.
In [ ]: # Create a new data frame from the original sorted by the column Salary
df_sorted = df.sort_values( by ='service')
df_sorted.head()
Out[ ]:](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-34-320.jpg)
![Data Frames: Sorting
35
We can sort the data using 2 or more columns:
In [ ]: df_sorted = df.sort_values( by =['service', 'salary'], ascending = [True, False])
df_sorted.head(10)
Out[ ]:](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-35-320.jpg)
![Missing Values
36
Missing values are marked as NaN
In [ ]: # Read a dataset with missing values
flights = pd.read_csv("http://rcs.bu.edu/examples/python/data_analysis/flights.csv")
In [ ]: # Select the rows that have at least one missing value
flights[flights.isnull().any(axis=1)].head()
Out[ ]:](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-36-320.jpg)



![Aggregation Functions in Pandas
40
agg() method are useful when multiple statistics are computed per column:
In [ ]: flights[['dep_delay','arr_delay']].agg(['min','mean','max'])
Out[ ]:](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-40-320.jpg)

![Graphics to explore the data
42
To show graphs within Python notebook include inline directive:
In [ ]: %matplotlib inline
Seaborn package is built on matplotlib but provides high level
interface for drawing attractive statistical graphics, similar to ggplot2
library in R. It specifically targets statistical data visualization](https://image.slidesharecdn.com/python-for-data-analysis-230430141138-76619825/85/Python-for-Data-Analysis-pptx-42-320.jpg)
































More Related Content
Similar to Python-for-Data-Analysis.pptx (20)
Recently uploaded (20)


















Python-for-Data-Analysis.pptx
- 1. Python for Data Analysis
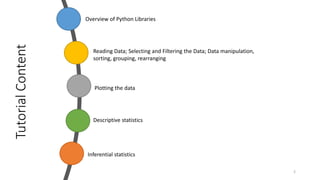
- 2. Tutorial Content 2 Overview of Python Libraries Reading Data; Selecting and Filtering the Data; Data manipulation, sorting, grouping, rearranging Plotting the data Descriptive statistics Inferential statistics
- 3. Python Libraries for Data Science Many popular Python toolboxes/libraries: • NumPy • SciPy • Pandas • SciKit-Learn Visualization libraries • matplotlib • Seaborn and many more … 3
- 4. Python Libraries for Data Science NumPy:  introduces objects for multidimensional arrays and matrices, as well as functions that allow to easily perform advanced mathematical and statistical operations on those objects  provides vectorization of mathematical operations on arrays and matrices which significantly improves the performance  many other python libraries are built on NumPy 4 Link: http://www.numpy.org/
- 5. Python Libraries for Data Science SciPy:  collection of algorithms for linear algebra, differential equations, numerical integration, optimization, statistics and more  part of SciPy Stack  built on NumPy 5 Link: https://www.scipy.org/scipylib/
- 6. Python Libraries for Data Science Pandas:  adds data structures and tools designed to work with table-like data (similar to Series and Data Frames in R)  provides tools for data manipulation: reshaping, merging, sorting, slicing, aggregation etc.  allows handling missing data 6 Link: http://pandas.pydata.org/
- 7. Link: http://scikit-learn.org/ Python Libraries for Data Science SciKit-Learn:  provides machine learning algorithms: classification, regression, clustering, model validation etc.  built on NumPy, SciPy and matplotlib 7
- 8. matplotlib:  python 2D plotting library which produces publication quality figures in a variety of hardcopy formats  a set of functionalities similar to those of MATLAB  line plots, scatter plots, barcharts, histograms, pie charts etc.  relatively low-level; some effort needed to create advanced visualization Link: https://matplotlib.org/ Python Libraries for Data Science 8
- 9. Seaborn:  based on matplotlib  provides high level interface for drawing attractive statistical graphics  Similar (in style) to the popular ggplot2 library in R Link: https://seaborn.pydata.org/ Python Libraries for Data Science 9
- 10. Download tutorial notebook # On the Shared Computing Cluster [scc1 ~] cp /project/scv/examples/python/data_analysis/dataScience.ipynb . # On a local computer save the link: http://rcs.bu.edu/examples/python/data_analysis/dataScience.ipynb 10
- 11. Start Jupyter nootebook # On the Shared Computing Cluster [scc1 ~] jupyter notebook 11
- 12. In [ ]: Loading Python Libraries 12 #Import Python Libraries import numpy as np import scipy as sp import pandas as pd import matplotlib as mpl import seaborn as sns Press Shift+Enter to execute the jupyter cell
- 13. In [ ]: Reading data using pandas 13 #Read csv file df = pd.read_csv("http://rcs.bu.edu/examples/python/data_analysis/Salaries.csv") There is a number of pandas commands to read other data formats: pd.read_excel('myfile.xlsx',sheet_name='Sheet1', index_col=None, na_values=['NA']) pd.read_stata('myfile.dta') pd.read_sas('myfile.sas7bdat') pd.read_hdf('myfile.h5','df') Note: The above command has many optional arguments to fine-tune the data import process.
- 14. In [3]: Exploring data frames 14 #List first 5 records df.head() Out[3]:
- 15. Hands-on exercises 15  Try to read the first 10, 20, 50 records;  Can you guess how to view the last few records; Hint:
- 16. Data Frame data types Pandas Type Native Python Type Description object string The most general dtype. Will be assigned to your column if column has mixed types (numbers and strings). int64 int Numeric characters. 64 refers to the memory allocated to hold this character. float64 float Numeric characters with decimals. If a column contains numbers and NaNs(see below), pandas will default to float64, in case your missing value has a decimal. datetime64, timedelta[ns] N/A (but see the datetime module in Python’s standard library) Values meant to hold time data. Look into these for time series experiments. 16
- 17. In [4]: Data Frame data types 17 #Check a particular column type df['salary'].dtype Out[4]: dtype('int64') In [5]: #Check types for all the columns df.dtypes Out[4]: rank discipline phd service sex salary dtype: object object object int64 int64 object int64
- 18. Data Frames attributes 18 Python objects have attributes and methods. df.attribute description dtypes list the types of the columns columns list the column names axes list the row labels and column names ndim number of dimensions size number of elements shape return a tuple representing the dimensionality values numpy representation of the data
- 19. Hands-on exercises 19  Find how many records this data frame has;  How many elements are there?  What are the column names?  What types of columns we have in this data frame?
- 20. Data Frames methods 20 df.method() description head( [n] ), tail( [n] ) first/last n rows describe() generate descriptive statistics (for numeric columns only) max(), min() return max/min values for all numeric columns mean(), median() return mean/median values for all numeric columns std() standard deviation sample([n]) returns a random sample of the data frame dropna() drop all the records with missing values Unlike attributes, python methods have parenthesis. All attributes and methods can be listed with a dir() function: dir(df)
- 21. Hands-on exercises 21  Give the summary for the numeric columns in the dataset  Calculate standard deviation for all numeric columns;  What are the mean values of the first 50 records in the dataset? Hint: use head() method to subset the first 50 records and then calculate the mean
- 22. Selecting a column in a Data Frame Method 1: Subset the data frame using column name: df['sex'] Method 2: Use the column name as an attribute: df.sex Note: there is an attribute rank for pandas data frames, so to select a column with a name "rank" we should use method 1. 22
- 23. Hands-on exercises 23  Calculate the basic statistics for the salary column;  Find how many values in the salary column (use count method);  Calculate the average salary;
- 24. Data Frames groupby method 24 Using "group by" method we can: • Split the data into groups based on some criteria • Calculate statistics (or apply a function) to each group • Similar to dplyr() function in R In [ ]: #Group data using rank df_rank = df.groupby(['rank']) In [ ]: #Calculate mean value for each numeric column per each group df_rank.mean()
- 25. Data Frames groupby method 25 Once groupby object is create we can calculate various statistics for each group: In [ ]: #Calculate mean salary for each professor rank: df.groupby('rank')[['salary']].mean() Note: If single brackets are used to specify the column (e.g. salary), then the output is Pandas Series object. When double brackets are used the output is a Data Frame
- 26. Data Frames groupby method 26 groupby performance notes: - no grouping/splitting occurs until it's needed. Creating the groupby object only verifies that you have passed a valid mapping - by default the group keys are sorted during the groupby operation. You may want to pass sort=False for potential speedup: In [ ]: #Calculate mean salary for each professor rank: df.groupby(['rank'], sort=False)[['salary']].mean()
- 27. Data Frame: filtering 27 To subset the data we can apply Boolean indexing. This indexing is commonly known as a filter. For example if we want to subset the rows in which the salary value is greater than $120K: In [ ]: #Calculate mean salary for each professor rank: df_sub = df[ df['salary'] > 120000 ] In [ ]: #Select only those rows that contain female professors: df_f = df[ df['sex'] == 'Female' ] Any Boolean operator can be used to subset the data: > greater; >= greater or equal; < less; <= less or equal; == equal; != not equal;
- 28. Data Frames: Slicing 28 There are a number of ways to subset the Data Frame: • one or more columns • one or more rows • a subset of rows and columns Rows and columns can be selected by their position or label
- 29. Data Frames: Slicing 29 When selecting one column, it is possible to use single set of brackets, but the resulting object will be a Series (not a DataFrame): In [ ]: #Select column salary: df['salary'] When we need to select more than one column and/or make the output to be a DataFrame, we should use double brackets: In [ ]: #Select column salary: df[['rank','salary']]
- 30. Data Frames: Selecting rows 30 If we need to select a range of rows, we can specify the range using ":" In [ ]: #Select rows by their position: df[10:20] Notice that the first row has a position 0, and the last value in the range is omitted: So for 0:10 range the first 10 rows are returned with the positions starting with 0 and ending with 9
- 31. Data Frames: method loc 31 If we need to select a range of rows, using their labels we can use method loc: In [ ]: #Select rows by their labels: df_sub.loc[10:20,['rank','sex','salary']] Out[ ]:
- 32. Data Frames: method iloc 32 If we need to select a range of rows and/or columns, using their positions we can use method iloc: In [ ]: #Select rows by their labels: df_sub.iloc[10:20,[0, 3, 4, 5]] Out[ ]:
- 33. Data Frames: method iloc (summary) 33 df.iloc[0] # First row of a data frame df.iloc[i] #(i+1)th row df.iloc[-1] # Last row df.iloc[:, 0] # First column df.iloc[:, -1] # Last column df.iloc[0:7] #First 7 rows df.iloc[:, 0:2] #First 2 columns df.iloc[1:3, 0:2] #Second through third rows and first 2 columns df.iloc[[0,5], [1,3]] #1st and 6th rows and 2nd and 4th columns
- 34. Data Frames: Sorting 34 We can sort the data by a value in the column. By default the sorting will occur in ascending order and a new data frame is return. In [ ]: # Create a new data frame from the original sorted by the column Salary df_sorted = df.sort_values( by ='service') df_sorted.head() Out[ ]:
- 35. Data Frames: Sorting 35 We can sort the data using 2 or more columns: In [ ]: df_sorted = df.sort_values( by =['service', 'salary'], ascending = [True, False]) df_sorted.head(10) Out[ ]:
- 36. Missing Values 36 Missing values are marked as NaN In [ ]: # Read a dataset with missing values flights = pd.read_csv("http://rcs.bu.edu/examples/python/data_analysis/flights.csv") In [ ]: # Select the rows that have at least one missing value flights[flights.isnull().any(axis=1)].head() Out[ ]:
- 37. Missing Values 37 There are a number of methods to deal with missing values in the data frame: df.method() description dropna() Drop missing observations dropna(how='all') Drop observations where all cells is NA dropna(axis=1, how='all') Drop column if all the values are missing dropna(thresh = 5) Drop rows that contain less than 5 non-missing values fillna(0) Replace missing values with zeros isnull() returns True if the value is missing notnull() Returns True for non-missing values
- 38. Missing Values 38 • When summing the data, missing values will be treated as zero • If all values are missing, the sum will be equal to NaN • cumsum() and cumprod() methods ignore missing values but preserve them in the resulting arrays • Missing values in GroupBy method are excluded (just like in R) • Many descriptive statistics methods have skipna option to control if missing data should be excluded . This value is set to True by default (unlike R)
- 39. Aggregation Functions in Pandas 39 Aggregation - computing a summary statistic about each group, i.e. • compute group sums or means • compute group sizes/counts Common aggregation functions: min, max count, sum, prod mean, median, mode, mad std, var
- 40. Aggregation Functions in Pandas 40 agg() method are useful when multiple statistics are computed per column: In [ ]: flights[['dep_delay','arr_delay']].agg(['min','mean','max']) Out[ ]:
- 41. Basic Descriptive Statistics 41 df.method() description describe Basic statistics (count, mean, std, min, quantiles, max) min, max Minimum and maximum values mean, median, mode Arithmetic average, median and mode var, std Variance and standard deviation sem Standard error of mean skew Sample skewness kurt kurtosis
- 42. Graphics to explore the data 42 To show graphs within Python notebook include inline directive: In [ ]: %matplotlib inline Seaborn package is built on matplotlib but provides high level interface for drawing attractive statistical graphics, similar to ggplot2 library in R. It specifically targets statistical data visualization
- 43. Graphics 43 description distplot histogram barplot estimate of central tendency for a numeric variable violinplot similar to boxplot, also shows the probability density of the data jointplot Scatterplot regplot Regression plot pairplot Pairplot boxplot boxplot swarmplot categorical scatterplot factorplot General categorical plot
- 44. Basic statistical Analysis 44 statsmodel and scikit-learn - both have a number of function for statistical analysis The first one is mostly used for regular analysis using R style formulas, while scikit-learn is more tailored for Machine Learning. statsmodels: • linear regressions • ANOVA tests • hypothesis testings • many more ... scikit-learn: • kmeans • support vector machines • random forests • many more ... See examples in the Tutorial Notebook
- 45. Conclusion Thank you for attending the tutorial. Please fill the evaluation form: http://scv.bu.edu/survey/tutorial_evaluation.html Questions: email: koleinik@bu.edu (Katia Oleinik) 45