ұКІвіЩіуҙЗІФӨЗұи»еҙЪӨтӨӨӨёӨГӨЖӨЯӨл
Download as PPTX, PDF6 likes21,338 views

өЪ21»ШЎЎёФЙҪұКІвіЩіуҙЗІФГгЗҝ»бӨОҘ№ҘйҘӨҘЙ



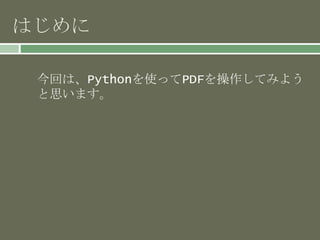














![ЦчӨКіцБҰҘӘҘЧҘ·ҘзҘу
? ҘіҘЮҘуҘЙҘйҘӨҘуӨЗіцБҰӨ№ӨллHӨЛК№УГӨЗӨӯӨлҘӘҘЧҘ·ҘзҘуӨ¬
ҳ”Ў©ӨўӨлЎЈ
-o:іцБҰҘХҘЎҘӨҘлГыЦё¶Ё
-p:PAGENO [,pageno,...] ійіцҘЪ©`Ҙё·¬әЕӨОҘ«ҘуҘЮЗшЗРӨОҘк
Ҙ№ҘИ
(ҘЪ©`Ҙё·¬әЕӨП1Ө«ӨйКјӨЮӨкӨЮӨ№ЎЈ)
-c:іцБҰҘі©`ҘЗҘГҘҜӨтЦё¶ЁӨ·ӨЮӨ№ЎЈ
-t:ҘҝҘӨҘЧ(txt/html/xml/tag)ЎщҘЗҘХҘ©ҘлҘИӨПtxt
-V:ҝk•шӨӯӨО—КіцӨтРРӨҰ](https://image.slidesharecdn.com/pythonpdf-151118104116-lva1-app6892/85/Python-pdf-19-320.jpg)































![[DLЭҶХi»б]Factorized Variational Autoencoders for Modeling Audience Reactions to...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180112-180115090630-thumbnail.jpg?width=560&fit=bounds)


More Related Content
What's hot (20)
Similar to ұКІвіЩіуҙЗІФӨЗұи»еҙЪӨтӨӨӨёӨГӨЖӨЯӨл (20)


















Recently uploaded (6)






ұКІвіЩіуҙЗІФӨЗұи»еҙЪӨтӨӨӨёӨГӨЖӨЯӨл
- 10. PDFІЩЧчУГPythonҘвҘёҘе©`Ҙл ? PDFДЪӨЛӨўӨлЗйҲуӨтійіцӨ№ӨлӨҝӨбӨОҘвҘёҘе©`Ҙл ? ҘйҘӨҘ»ҘуҘ№РО‘BӨПЎўMITҘйҘӨҘ»ҘуҘ№ ? ИХұҫХZӨОҢқҸкӨвӨдӨГӨЖӨӨӨл Pdfminer(http://urx2.nu/oXgp)
- 12. ҘӨҘуҘ№ҘИ©`Ҙл ТФПВӨОURLӨиӨкzipҘХҘЎҘӨҘлӨтҘАҘҰҘуҘн©`ҘЙ https://github.com/euske/pdfminer/ $ python setup.py install ҘӨҘуҘ№ҘИ©`Ҙлҙ_ХJӨПЎўpip freezeӨЗЎӯ
- 13. „УЧчҙ_ХJ Quick StartӨ«Өй $ python ~/pdf2txt.py ~/sample/simple1.pdf Hello World Hello World H e l l o W o r l d H e l l o W o r l d ScriptsҘХҘЎҘлҘАДЪӨЛӨўӨл ӨОӨЗҘСҘ№ӨтЦё¶Ё
- 14. ӨҝӨАӨ·Ўӯ ? ӨіӨОӨЮӨЮӨАӨИИХұҫХZӨ¬ӨЮӨИӨвӨЛұнКҫӨөӨмӨЮӨ»Өу ? ИХұҫХZӨЛҢқҸкӨөӨ»ӨлӨҝӨбӨЛӨПЎўCJKӨОөЗеhӨтӨ·ӨК ӨӨӨИОДЧЦ»ҜӨұӨтЖрӨіӨ№ӨОӨЗӨЮӨәӨПҘ»ҘГҘИҘўҘГҘЧӨ№ Өл ? ҘПҘЮӨкӨЙӨіӨнӨПӨЙӨіӨЛәОӨтЦГӨҜӨ«Ө¬ЧоіхӨпӨ«ӨйӨә А§ӨГӨҝӨИӨі
- 16. ИХұҫӯhҫіӨОФO¶Ё ТФПВӨОҘіҘЮҘуҘЙӨтҢgРР cd ~site-package python .pdfminerpdfminer-mastertoolsconv_cmap.py -c B5=cp950 -c UniCNS-UTF8=utf-8 .pdfminercmap Adobe-CNS1 .pdfminerpdfminer-mastercmaprsrccid2code_Adobe_CNS1.txt python .pdfminerpdfminer-mastertoolsconv_cmap.py -c GBK-EUC=cp936 -c UniGB- UTF8=utf-8 .pdfminercmap Adobe-GB1 .pdfminerpdfminer- mastercmaprsrccid2code_Adobe_GB1.txt python .pdfminerpdfminer-mastertoolsconv_cmap.py -c RKSJ=cp932 -c EUC=euc-jp -c UniJIS-UTF8=utf-8 .pdfminercmap Adobe-Japan1 .pdfminerpdfminer- mastercmaprsrccid2code_Adobe_Japan1.txt python .pdfminerpdfminer-mastertoolsconv_cmap.py -c KSC-EUC=euc-kr -c KSC- Johab=johab -c KSCms-UHC=cp949 -c UniKS-UTF8=utf-8 .pdfminercmap Adobe-Korea1 .pdfminerpdfminer-mastercmaprsrccid2code_Adobe_Korea1.txt cd pdfminerpdfminer-master python setup.py install
- 17. ҘЭҘӨҘуҘИ ? MACӨПЎў ? WindowsӨПЎўҪ~ҢқҘСҘ№ӨЗЦё¶ЁӨ№ӨлұШТӘӨ¬ӨўӨкӨіӨО Іҝ·ЦӨЗӨ«ӨКӨкҗҳӨуӨА ? ӨБӨКӨЯӨЛЧоббӨЛӨўӨГӨҝн—ДҝӨПЎўнn№ъХZӨОҢқҸкУГӨК ӨОӨЗҪс»ШӨПӨКӨҜӨЖӨвӨӨӨӨӨ«Өв make cmap python setup.py install
- 18. ҢgлHӨЛіцБҰӨ·ӨЖӨЯӨл ? „УЧчҙ_ХJӨОһйӨЛТФПВӨОҘіҘЮҘуҘЙӨтҢgРРӨ·ЎўИХұҫХZӨ¬іцБҰ ӨөӨмӨлӨ«Өтҙ_ХJ python ~pdf2txt.py -o c:workoutput.txt ~japaneseSample.pdf
- 19. ЦчӨКіцБҰҘӘҘЧҘ·ҘзҘу ? ҘіҘЮҘуҘЙҘйҘӨҘуӨЗіцБҰӨ№ӨллHӨЛК№УГӨЗӨӯӨлҘӘҘЧҘ·ҘзҘуӨ¬ ҳ”Ў©ӨўӨлЎЈ -o:іцБҰҘХҘЎҘӨҘлГыЦё¶Ё -p:PAGENO [,pageno,...] ійіцҘЪ©`Ҙё·¬әЕӨОҘ«ҘуҘЮЗшЗРӨОҘк Ҙ№ҘИ (ҘЪ©`Ҙё·¬әЕӨП1Ө«ӨйКјӨЮӨкӨЮӨ№ЎЈ) -c:іцБҰҘі©`ҘЗҘГҘҜӨтЦё¶ЁӨ·ӨЮӨ№ЎЈ -t:ҘҝҘӨҘЧ(txt/html/xml/tag)ЎщҘЗҘХҘ©ҘлҘИӨПtxt -V:ҝk•шӨӯӨО—КіцӨтРРӨҰ
- 20. ӨҪӨОЛыӨОҷCДЬ ? ӨҪӨОЛыӨОҘЗҘРҘГҘ°ҷCДЬӨИӨ·ӨЖdumppdf.pyҘіҘЮҘуҘЙӨ¬Өў ӨкӨЮӨ№ЎЈ $python ~/dumppdf.py -a ~/japanesesample2.pdf ҘЗҘРҘГҘ°УГӨО”MЛЖxmlӨтіцБҰӨ·ӨҝӨкЦРӨЛВсӨбЮzӨЮӨмӨҝ»ӯПс ӨтійіцӨ·ӨҝӨкӨЗӨӯӨЮӨ№ЎЈ
- 21. ӨЮӨИӨб ? ҘіҘЮҘуҘЙҘйҘӨҘуөДӨЛӨП2ӨДӨОӨЯӨОҘ·ҘуҘЧҘлӨКҳӢіЙ ? PDFДЪӨЛӨўӨлҘЖҘӯҘ№ҘИӨтійіцӨ№ӨлӨЛӨПұгАы ? ИХұҫХZӨОҢқҸкӨПЎўCMAPӨОФO¶ЁӨ¬ұШТӘЎЈФO¶Ё•rӨЛҘСҘ№ ӨОЦё¶ЁӨЛЧўТвӨ№ӨлұШТӘӨ¬ӨўӨл(windows°жӨПЧўТв) ? ҘЗҘРҘГҘ°УГӨОҘіҘЮҘуҘЙҘйҘӨҘуӨПЎў»ӯПсӨОійіцӨ¬ҝЙДЬ ӨКӨОӨЗӨҰӨЮӨҜК№ӨЁӨРІҝ·ЦөДӨК„IАнӨ¬ҝЙДЬ ? ӨўӨліМ¶ИјҡӨ«ӨӨӨіӨИӨтӨ·ӨиӨҰӨИӨ№ӨлӨИPDFӨОҳӢФмӨт АнҪвӨ№ӨлұШТӘӨ¬ӨўӨлӨ«ӨвЎӯ