




![構成
Model(pl.LightningModule
)
moduleA(torch.nn.Module
)
network
forward()
network
net = moduleA()
main
def __init__():
model = Model()
check = ModelCheckpoint()
logger = Logger()
stopping = EarlyStopping()
trainer =
Trainer(model,
logger,
callbacks=[check, stopping])
def train(dataloader, datamodule):
trainer.fit(model, datamodule)
def train_from(dataloader, datamodule):
trainer =
Trainer(resume_frome_ckpt=ckpt,...)
trainer.fit(model, datamodule)
def test(dataloader, datamodule):
def get_anomaly_detection(dl, dm):
def forward(x):
y = net(x)
def training_step(batch):
x,_ = batch
x_hat = self(x)
loss = F.loss(x_hat,x)
self.log(‘loss’,loss)
return loss
def validation_step(batch):
x, _ = batch
x_hat = self(x)
loss = F.loss(x_hat, x)
self.log(‘val_loss, loss)
def test_step(batch):
def configure_optimizer():
return torch.optim.Adam()
logger に保存
logger に保存
moduleB(torch.nn.Module
)
network
forward()
MLFlow などの学習経過保存Callback
モデル保存Callback
早期終了Callback
def {train|val|test}_step :
batch 単位の処理を記述。
def {train|val|test}_epoch_end:
epoch 終了後にHookされる関数
multi GPU を想定しているぽい
訓練後の処理は、いろいろ考える
とtest_step 関数内で処理しておく
のが pytorch-lightning のメリットも
利用できてよさそう](https://image.slidesharecdn.com/pytorchlightninghydramlflowoptuna-210119073603/85/PyTorchLightning-Hydra-MLFlow-Optuna-8-320.jpg)








![trial.suggest_hoge()
Model_A_PS
study.optimize()
AD_PS.py
プログラムフォルダ構成
dataset.py
RootDir
config datasrc mlruns
model utils
Model A
modules.py
Model_A
model
module
forward()
training_step()
validation_step()
test_step()
configure_optimizer()
module
module
model
config.yaml
defaults
- model: default
- data: default
- trainer: default
- callbacks: default
data
trainer
callbacks
default.yaml
config.py
dataset.py
Dataset
DataModule
sample_data
train
val
test
other_data
Model B
Trainer()
callbacks
AD.py
module
model.py
opruns
def __init__(self, config, trial):
config.hoge = trial.suggest_int(‘hoge’,1,10)
config.optimizer.lr = trial.suggest_float(‘optimizer.lr’,0.01,0.1,log=True)
super(main.__class__, self).__init__(config)
検討したいパラメータはモデルごとに異なるため元モデルクラスを継承
def __init__(self, config, trial):
pruner = optuna.pruners.MedianPruner()
self.study = optuna.create_study(pruner, ...)
def do_optimize(self):
self.study.optimize(self.objective, ...)
def objective(self, trial):
model = Model()
metrics = MetricCallbacks()
trainer = Trainer(..., callbacks=[metrics, ...])
trainer.fit(model, data)
探索用関数が必要なため、別クラスとして実装
model
model
Sqlite3 形式で経過を保存可能
MLFlow を使わないほうがよさげ](https://image.slidesharecdn.com/pytorchlightninghydramlflowoptuna-210119073603/85/PyTorchLightning-Hydra-MLFlow-Optuna-17-320.jpg)


PyTorchLightning ベース Hydra+MLFlow+Optuna による機械学習開発環境の構築
- 1. Hydra + MLFlow + Optuna base on pytorch-lightning
- 2. モデル開発の効率化のポイント ? 訓練データの管理 ? 元データから訓練データの生成とその特徴の把握を容易 にする ? ハイパーパラメータ探索効率化 ? モデルやデータごとに異なるパラメータ群の管理 ? 探索手法の導入 ? モデル構築のテンプレート化 ? モデル実装時間を短くする ? 既存モデルを使いまわせるようにする ? 学習結果の保存?可視化 ? 学習結果とハイパーパラメタ、モデルを結び付けられる ? 結果や学習過程の可視化によって把握を容易にする
- 3. PyTorchLightning, Hydra, MLFlow, Optunaの導入 特徴分析 訓練データ生成 訓練?評価データ パラメータ探索 データ パラメータ 学習済モデル モデル 訓練 重みデータ 訓練過程データ 訓練結果 モデル実装 テンプレート パラメータ管理 モデル保存 保存?可視化 保存?可視化 比較 訓練データ管理 モデル観測 (再学習) MLFlow Hydra Optuna pytorch-lightning
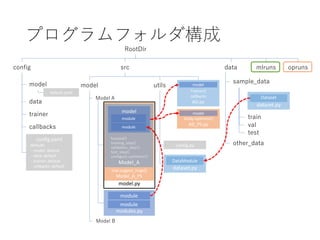
- 4. trial.suggest_hoge() Model_A_PS プログラムフォルダ構成 dataset.py RootDir config datasrc mlruns model utils Model A modules.py Model_A model module forward() training_step() validation_step() test_step() configure_optimizer() module module model config.yaml defaults - model: default - data: default - trainer: default - callbacks: default data trainer callbacks default.yaml config.py dataset.py Dataset DataModule sample_data train val test other_data Model B module model.py opruns study.optimize() AD_PS.py Trainer() callbacks AD.py model model
- 7. 概要 ? pytorch 用フレームワーク ? tensorflow における Keras のようなもの ? 主な構成 ? pl.LightningModule: ネットワーク構成とloss計算等のモ ジュール ? pl.DataModule: dataloaderを準備するモジュール ? pl.Trainer: model と データ、callback 処理を管理?実行 ? callbacks ? Logger: csv, tensorboard, mlflow などロガー処理 ? ModelCheckpoint: モデル保存処理 ? EarlyStopping: 早期終了処理 ? ProgressBar: 実行状況表示
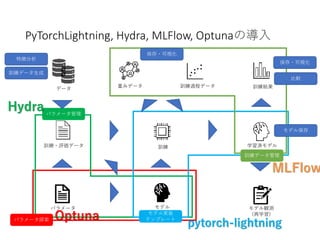
- 8. 構成 Model(pl.LightningModule ) moduleA(torch.nn.Module ) network forward() network net = moduleA() main def __init__(): model = Model() check = ModelCheckpoint() logger = Logger() stopping = EarlyStopping() trainer = Trainer(model, logger, callbacks=[check, stopping]) def train(dataloader, datamodule): trainer.fit(model, datamodule) def train_from(dataloader, datamodule): trainer = Trainer(resume_frome_ckpt=ckpt,...) trainer.fit(model, datamodule) def test(dataloader, datamodule): def get_anomaly_detection(dl, dm): def forward(x): y = net(x) def training_step(batch): x,_ = batch x_hat = self(x) loss = F.loss(x_hat,x) self.log(‘loss’,loss) return loss def validation_step(batch): x, _ = batch x_hat = self(x) loss = F.loss(x_hat, x) self.log(‘val_loss, loss) def test_step(batch): def configure_optimizer(): return torch.optim.Adam() logger に保存 logger に保存 moduleB(torch.nn.Module ) network forward() MLFlow などの学習経過保存Callback モデル保存Callback 早期終了Callback def {train|val|test}_step : batch 単位の処理を記述。 def {train|val|test}_epoch_end: epoch 終了後にHookされる関数 multi GPU を想定しているぽい 訓練後の処理は、いろいろ考える とtest_step 関数内で処理しておく のが pytorch-lightning のメリットも 利用できてよさそう
- 9. メモ ? 訓練後の処理をGPUの有無とか考えないでも行う のであれば、test_step 関数の中で行うのがよさそ う ? ModelCheckpoint callback で任意のfolderに保存する には、dir_path などで指定するのがよさそう。 ? Trainer.test を実行するとき resume_from_ckpt を使 用して resume したあとだと、なぜか resume して から実行しようとするため、resume 後に fit を実行 すると best ではない、model で test を実行してし まうか、ckpt ファイルがないとエラーが出るので 注意
- 10. Hydra pytorch-lightning と Hydra が统合するかもしれないだと...
- 11. 概要 ? フォルダ+yamlファイルで管理 ? パラメータの上書きは、コマンドラインのオプション だけでなく、jupyter などからも可能 ? メリット ? フォルダ+yamlファイルで階層的に管理 ? model.train.batch_size という定義が可能 ? configからインスタンス作成も可能 ? 他の設定を参照定義できる ? デメリット ? list や dic 形式は Omegalist や Omegadict という独自形式 ? インスタンスは sys.path が通っているところから宣言が必要 ? 上書きする際には参照関係を認識する必要がある model data autoencoder.yaml vea.yaml eeg.yaml 階層的管理イメージ
- 12. 実装メモ ? initialize は複数回行うとエラーが起きるため、 GlobalHydra.instance() をクリアする必要がある from hydra.core.global_hydra import GlobalHydra GlobalHydra.instance().clear() ? 基本yaml形式での定義なので、ファイル内での階層化は可能 ? ただし、統合するときに各ファイルの先頭に # @package _global_ が必要。 そうしないとサブグループとして読み込まれる ? list や dict データを取得には以下の変換が必要 OmegaConf.to_container(cfg.hoge) ? 要素hogeがlistかどうかのチェック OmegaConf.is_list(cfg.hoge) ? 要素を直接呼び出した場合には、参照は補完されるが、上位要素 からだと補完されないため以下の処理が必要 OmegaConf.to_container(cfg, resolve=True) ? study.optimize の n_jobs を実行する際には MLFlowLogger などで注 意が必要. sqlite3 への保存だけにしたらいいのかな?
- 13. MLFlow
- 14. 概要 ? mlflow をインストール ? プログラム中に以下を加える ? pl.logger.MLFlowLogger を作成 ? pl.Trainer に logger として渡す。 ? あとは、プログラム中の pl.LightningModule.log 関数を実行した metric が保存される ? model を保存する場合 ? callback クラスの ModelCheckpoint の dir_path に logger のフォルダを わたす。フォルダは logger のインスタンスが生成されていれば、 logger.save_dir, logger.experience_id, logger.run_id などで構成可能 ? MLFlowLogger に autolog() があるが、これだと、モデルが最後 に訓練された状態でしか保存されない様子 ? 保存データの確認方法 ? プロジェクトフォルダに移動 (defaultの保存先: ./mlruns) % mflow ui --backend-store-uri <logger.save_dir>
- 15. その他の実験結果管理ツール ? tensorflowboard ? WandB ? ネットワークの重みの状態の可視化も行えるようす ? 実験終了後にメールを送る機能もあるらしい ? Comet.ml ? 実験コード(jupyter notebookも)保存可能
- 16. Optuna
- 17. trial.suggest_hoge() Model_A_PS study.optimize() AD_PS.py プログラムフォルダ構成 dataset.py RootDir config datasrc mlruns model utils Model A modules.py Model_A model module forward() training_step() validation_step() test_step() configure_optimizer() module module model config.yaml defaults - model: default - data: default - trainer: default - callbacks: default data trainer callbacks default.yaml config.py dataset.py Dataset DataModule sample_data train val test other_data Model B Trainer() callbacks AD.py module model.py opruns def __init__(self, config, trial): config.hoge = trial.suggest_int(‘hoge’,1,10) config.optimizer.lr = trial.suggest_float(‘optimizer.lr’,0.01,0.1,log=True) super(main.__class__, self).__init__(config) 検討したいパラメータはモデルごとに異なるため元モデルクラスを継承 def __init__(self, config, trial): pruner = optuna.pruners.MedianPruner() self.study = optuna.create_study(pruner, ...) def do_optimize(self): self.study.optimize(self.objective, ...) def objective(self, trial): model = Model() metrics = MetricCallbacks() trainer = Trainer(..., callbacks=[metrics, ...]) trainer.fit(model, data) 探索用関数が必要なため、別クラスとして実装 model model Sqlite3 形式で経過を保存可能 MLFlow を使わないほうがよさげ
- 18. 概要 ? 定義 ? optuna.study で探索手法、データ保存 ? optuna.study.optimize で探索を実行 ? データ保存は sqlite3 を利用 ? optuna.Trial.suggest_hoge で探索空間を定義 ? optuna-dashboard をインストールすることで、 保存したDBから経過を確認可能。 ? ただ、リアルタイムに更新してくれず、optuna- dashboard を再起動しないとグラフが更新されない のはなぜ?
- 19. 実装上の注意 ? Sqlite3 をインストールしてなくても保存できて いるように見えるが、実際にはインストール後 しかデータが確認できなかった。フォルダの場 所の自由度は少なそう... ? optuna.logging.get_logger("optuna").addHandler(logging.StreamHandler(sys.stdout)) ? create_study(pruner, storage=‘sqlite:///<フォルダ名>/hoge.db) ※ パラメータは config に記述 ? optuna の保存フォルダを指定した場合に、 フォルダを自動作成してくれないので、自分で 準備すること ? 現時点(2021/01)では、optuna-dashboard よりは、 visualize 以下の関数で表示した内容のほうがわ かりやすそう