Query recommendation by search filters and criteria prediction
?
2 likes?821 views

This document discusses using machine learning to predict a user's future search queries based on their search history. It proposes building a query flow graph using conditional probabilities calculated from historical query chains. This graph would be stored efficiently and queried to provide query recommendations. Testing on real estate search log data achieved 67-79% accuracy in predicting a user's next search criteria. The technique could benefit applications like query suggestions, page re-ordering, and ad placement.























Query recommendation by search filters and criteria prediction
- 1. Machine Learning for Search Criteria Prediction Dhwaj Raj
- 2. Convention Query = Search Critera = Set of search filters chosen by user
- 3. User searches : at our real estate portal 69121 70000 60000 Average Searches in active user session = 3.6 Users Over 50000 1 week 40000 30963 30000 17332 20000 Long tail samples ... 9561 10000 5911 3819 2481 1595 1206 0 2 3 4 5 6 7 8 Number of searches in an active user session 9 10
- 4. Aim of Query/ Search Criteria Recommendation Ī± One of the major ways to improve user experience. Ī± Minimize search actions while fulfulling the user intent. Ī± Ī± Facilitate and Guide users through their informationseeking tasks. Help them explore alternate ways to express their intent.
- 5. Introduction Ī± Ī± Ī± We propose search log mining to capture collective intelligence for providing query suggestions by predicting user's future search queries. When enough history is observed for a given query chain, future queries can be accurately modeled. Understanding what users are querying in the current search sessions, and predict what they will search next have many potential applications such as query recommendation, web page re-ordering, advertisement arrangement, and so on.
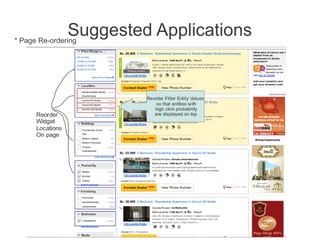
- 7. Suggested Applications * Page Re-ordering
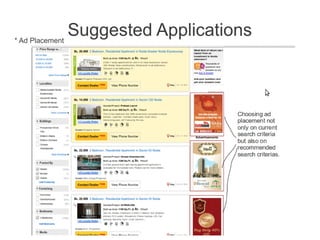
- 8. Suggested Applications * Ad Placement
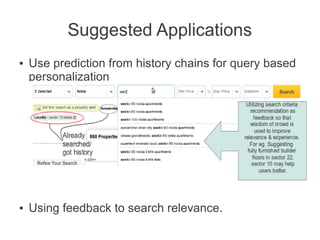
- 9. Suggested Applications Ī± Ī± Use prediction from history chains for query based personalization Using feedback to search relevance.
- 10. Suggested Applications Ī± Ī± AND MANY OTHER APPLICATIONS ĪŁ.. Also, This technology of action chain based predictions can be used for domains other than search query as well. Such as listing recommendation, page action prediction etc.
- 11. Search Query Chains Ī± User1: A Ī· B Ī· C Ī± User2: B Ī· C Ī· E Ī± User3: A Ī· B Ī· C Ī· E Ī± User4: B Ī· C Ī· F Ī± User5: A Ī· E Ī± Where A, B, C etc are search queries/criterias Ī± UserNew1: B Ī· C Ī· ? Ī± UserNew2: A Ī· ?
- 12. Basis of Model Ī± Following experiments were done: 1. Distribution of 2 action query chain does not correlate with high order query chains. For e.g distribution of E Ī· F does not correlate well with distribution of B Ī· E Ī· F, or C Ī· E Ī· F or BĪ·CĪ·EĪ·F ©C Observation: probability of step1 Ī· step2 also depends conditionally on the action history i.e. on past actions used to reach step1.
- 13. Basis of Model 2. Search criteria is a set of filter entities: A,B,C can be represented as (e1,e2,e3,e4,e5...) Where e1,e2 etc are entity types for e.g. proptype, city, locality, budget etc. Ī± Experiments show that probability of a criteria state A,B or C depends conditionally on set of entities present in the criteria. For eg. Probability of A(resi,sector105noida,underconstr) Ī· B(resi,sector110noida,underconstr) has a different probability distribution than A(resi,sector105noida,readyPosess) Ī· B(resi,sector110noida,readyPosess) and A(resi,sector105noida) Ī· B(resi,sector110noida)
- 14. Basis of Model 3. Experiments were to done to observe correlation among distribution of history chains. Ī± Observation: AĪ·BĪ·CĪ·E correlate with B Ī· A Ī· C Ī· E but same history order chains have higher correlation. Ī± Conclusion: Order matters in history but unordered history also correlate well, so order should be given improtance but should not be sole criteria for model. Ī± Use bayesian independence but give reward to same order. P( next | A Ī· B Ī· C Ī· D) = k. P(next | B Ī· A Ī· C Ī· D)
- 15. Markov Chains & decision process At each time step, the process is in some state s, and the decision maker may choose any action a that is available in state s. The process responds at the next time step by randomly moving into a new state s', and giving the decision maker a corresponding reward R_a(s,s'). Conditianal Probability computations to make these chain graphs memoryless:
- 16. Constructing query-flow graphs query flow graphs are generally stored as a transition matrix. Ī± Each cell is filled with computed conditional probability. Ī± A B C A B C A 0 0 0.02 AA 0.1 0 0.3 B 0 0 0 AB 0.9 0 0 C 0.1 0.5 0 AC 0 0.2 0 D 0 0 BA 0.1 0 E 0 0.1 0 0 0 BC 0.6 0.3 0
- 17. Sub-Chains & Sub-Criteria-Chains Help reduce sparseness. Ī± training from log: resi_flat_sale_sector12noida Ī· resi_flat_sale_sector22noida Ī± Testing for : resi_flat_sale_sector12noida_10-25laks Ī· ? Sub Chains Ī± Window shifting algorithm A Ī· B Ī· C Ī· D Ī· E Ī· F Ī· G Ī· H transform to : (A Ī· B Ī· C, B Ī· C Ī· D, A Ī· B, B Ī· C, etc...) Ī± Skip sequence A Ī· B Ī· C Ī· D Ī· E Ī· F Ī· G Ī· H transform to : ( A Ī· B Ī· D, A Ī· B Ī· E etc..) Sub Criteria Chains Ī± resi_flat_sale_sector12noida_10-25laks_unfurnished Ī· resi_flat_sale_sector10noida_2530laks_unfurnished Transforms to (resi_flat_sale_sector12noida Ī· resi_flat_sale_sector10noida, resi_flat_sale_sector12noida_10-25laks Ī· resi_flat_sale_sector10noida_25-30laks, resi_flat_sale_sector12noida_unfurnished Ī· resi_flat_sale_sector10noida_unfurnished) Ī± Only minor criteria items get replaced because major criteria is representative of an unique search focus.
- 18. Query Log Mining Ī± Visitor session info Ī± Visitor search actions Ī± Ī± Active Session : current session tracking keeps session alive for days. Written optimized procedure queries to change vam id for every change in major criteria and for every idle time of 1hr. Clustering similar entity values to reduce sparseness.
- 20. Storing query flow graphs Ī± Ī± Transition matrices are very sparse and eat up unnecessary space for 0 prob pairs. To overcome these we use state transition map: State seq prob A->B->C D 0.02 A->B->C E 0.05 A->B Ī± next C 0.1 These query flow graph will be queried very frequently.
- 21. Retrieval -1 Ī± Ī± Ī± Ī± Query flow graph can be seen as a key value map where key is (stateseq) and val is (next,probability) pair. To utilize the system for various applications including real time interaction, the retrieval part should be really fast (>100ms). Key set size > 30 million Inverted index storages like lucene etc are not used because insertion is very slow for given key set size.
- 22. Retrieval - 2 Ī± Ī± Ī± Ī± Ī± Relational databases like mysql etc yielded slow insertion and slower retrieval. In memory structures like redis or hashmaps were not able to occupy all keys. Finally we used Cassandra NoSQL which is giving a very good insertion and retrieval performance. Advantage of cassandra : can be expanded and extended to our need and it's cool to use. Ref: using_cassandra
- 23. Prediction Already prepared in training phase Learned weights Query Flow Transition Map Entity type prediction Entity value Prediction Predictor State Fetcher Input {curr state, past state seq} Sub Chains Generator Sub Criteria Chains generator 1. Predicting next entity type to be clicked. For e.g. next filter will be on locality, or furnishing or budget etc. 2. Predicting next entity value to be clicked. For e.g. for each entity type which value will be chosen next such as which locality or which budget range.
- 24. What is not covered in this project Ī± Some of the work on query recommendation focuses on measures of query attribute similarity based on domain knowledgebase but we have not included this in project scope. Ī± For 99acres it can be seen as locality affinity etc. Ī± Why not : maintainance issues. Ī± Ī± Why not : we do not want too much dependency on domain specific data rather it should stay as plug and play model working only on query logs. Why not: domain similarity unable to capture crowd's wisdom ©C ©C ©C ©C Conditional nature of attribute dependency. For e.g user's choice for next locality also depend on choice of budget, bedroom etc. For eg. A user searching for sector xx is presented sector yy due to affinity but users are aware of the current affairs and they do not want to search in yy because HC has banned work there. A user is searching for jaypee kosmos and is presented supertech upcountry(near) but users had some knowledge of hidden attributes like FRR and green space so he makes next search to jaypee aman(far). Our Assumption: user crowd have more knowledge of current trends and ground realities so entity relations can be better captured from their behaviors.
- 25. Results Ī± Ī± Ī± Ī± In user behavior modelling, it is very difficult to say that model is x% accurate for new user. Even if we model accurately and predict accurately majority of users may have different search focuses. So accuracy can be measured truly by presenting the prediction to the user and then evaluating that how many users we influenced. So in user behavior modeling we can conclude with data that our model fits well for already seen users/history. In our case, a full fledged demo was created with 10 days of search_criteria training. Ī± On same validation set it provides accuracy of 79%. Ī± On separate training and fresh test sets accuracy of 67%. Ī± Demo has been hosted on local server for testing (link to be distributed).
- 26. Ī± Thank you.