Rapid motor adaptation for legged robots
Download as PPTX, PDF1 like134 views

Rapid Motor Adaptation for Legged Robots (RMA) allows quadruped robots to rapidly adapt their walking gait when faced with new terrains or conditions. RMA consists of a base policy trained via reinforcement learning to walk in simulation, and an adaptation module that estimates environment factors to allow the base policy to adapt in real-time. When deployed on the A1 robot, RMA achieved a high success rate walking over various challenging terrains like sand, mud, and obstacles, without any failures in trials. The adaptation module allows the robot to adapt its gait within fractions of a second to respond to changes in conditions, outperforming alternatives that are slower to adapt or require explicit system identification.



































![[1808.00177] Learning Dexterous In-Hand Manipulation](https://cdn.slidesharecdn.com/ss_thumbnails/learningdextrousinhandmanipulation-180814000608-thumbnail.jpg?width=560&fit=bounds)











More Related Content
Similar to Rapid motor adaptation for legged robots (20)
More from Rohit Choudhury (10)








Recently uploaded (20)




















Rapid motor adaptation for legged robots
- 1. (RMA) Rapid Motor Adaptation for Legged Robots Ashish Kumar, UC Berkeley Zipeng Fu, Carnegie Mellon University Deepak Pathak, Carnegie Mellon University Jitendra Malik, UC Berkeley, Facebook - Rohit Choudhury Robotics: Science and Systems 2021
- 3. Introduction Demonstrated the performance of RMA on several challenging environments successfully by being able to walk on sand, mud, hiking trails, tall grass and dirt pile without a single failure in all the trials Success in real-world deployment requires the quadruped robot to adapt in real-time to unseen scenarios like changing terrains, changing payloads, wear and tear Consists of 2 components: a base policy and an adaptation module. The combination of these components enables the robot to adapt to novel situations in fractions of a second RMA is trained completely in simulation without using any domain knowledge like reference trajectories or predefined foot trajectory generators and is deployed on the A1 robot without any fine-tuning
- 4. Problem Statement Reinforcement learning and imitation learning techniques are being used in the modelling of physical dynamics and the tools of control theory, which thereby mimic the human designer The standard paradigm is to train an RL-based controller in a physics simulation environment and then transfer to the real world using various sim-to-real techniques This transfer has proven quite challenging, because the sim-to- real gap itself is the result of multiple factors: Difference between the physical robot and its model in the simulator Difference between the real-world terrains and the models of those in the simulator The physics simulator fails to accurately capture the physics of the real world
- 5. Solution A Human walking in the real world entails rapid adaptation as he moves on different soils, uphill or downhill, carrying loads, with rested or tired muscles, and coping with sprained ankles and the like Which means that there is no time to carry out multiple experiments in the physical world, rolling out multiple trajectories and optimizing to estimate various system parameters If we introduce the quadruped onto a rocky surface with no prior experience, the robot policy would fail often, causing serious damage to the robot. Collecting even 3-5 mins of walking data in order to adapt the walking policy may be practically infeasible (Understanding the problem by relating to real life example)
- 6. Solution ? trained via reinforcement learning in simulation using privileged information about the environment configuration ?? such as friction, payload, etc ? encoded into a latent feature space ?? using an encoder network ? ? is latent vector ??, which we call the extrinsics, is then fed into the base policy along with the current state ?? and the previous action ???1 ? base policy then predicts the desired joint positions of the robot ? Unfortunately, this policy cannot be directly deployed because we donˇŻt have access to ?? in the real world Base policy ?
- 7. Solution ? The adaptation module ?, estimates the extrinsics at run time as the excentrics help us predict the difference between desired and actual movement of the robot ? Specifically, the goal of ? is to estimate the extrinsics vector ?? from the robotˇŻs recent state and action history, without assuming any access to ?? ? Since both the state history and the extrinsics vector ?? can be computed in simulation, we can train this module via supervised learning Adaptation module ?
- 8. Solution Novel aspects - use of a varied terrain generator and ˇ°naturalˇ± reward functions motivated by bioenergetics which allows it to learn walking policies without using any reference demonstrations. But the truly novel contribution of this paper is the adaptation module, trained in simulation, which makes RMA possible Deployment ? Both these modules work together to perform robust and adaptive locomotion ? The two run asynchronously in parallel with no central clock to align them. The base policy just uploads the most recent prediction of the extrinsics vector ?? from the adaptation module to predict action ?? ? As mentioned earlier, collecting such a dataset, when the robot hasnˇŻt yet acquired a good policy for walking, could result in falls and damage the robot ? However, inclusion of Adaptation Module avoids this, through the rapid estimation of ?? that permits the walking policy to adapt quickly and hence avoid falls
- 9. Application ? We learn a base policy ?, which takes as input, the current state ?? ? ?30 , previous action ???1 ? ?12 and the extrinsics vector ?? ? ?8 to predict the next action ??. The predicted action ?? is the desired joint position for the 12 robot joints which is converted to torque using a PD controller ? The extrinsics vector ?? is a low dimensional encoding of the environment vector ?? ? ?17 generated by ? (environment vector encoder) ? Implement ? & ? as multi layer perceptron (class of feedforward artificial neural network); end to end joint training ? and ? using model-free reinforcement learning ? At time step t, ? takes the current state ??, previous action ???1 and the extrinsics ?? = ?(??), to predict an action ?? ? RL maximizes the following expected return of the policy ?, where ? is the trajectory of the agent when executing policy ? , and p(?|? ) represents the likelihood of the trajectory under ? Base Policy ?
- 10. Application ? Used to estimate the extrinsics online ? Instead of ??, the adaptation module uses the recent history of robotˇŻs states ????:??1 and actions ????:??1 to generate ?? which is an estimate of the true extrinsics vector ?? ? Both state-action history and the target value of ?? are available in simulation, and hence, ? can be trained via supervised learning to minimize mean square error ? Collect the state-action history by unrolling the trained base policy ? with the ground truth ??. However, such a dataset will contain few good trajectories where the robot walks seamlessly but deviation from these dataset will cost us the robustness ? This is solved by unrolling the base policy ? with the ?? predicted by the randomly initialized policy ?. We then use this state action history, paired with the ground truth ?? to train ?. We iteratively repeat this until convergence. This training procedure ensures that RMA sees enough exploration trajectories during training due to randomly initialized ?, and imperfect prediction of ??. This adds robustness to the performance of RMA during deployment Adaptation module ?
- 11. Experiment ? Hardware Details : A1 robot from Unitree (18 DoF), motor encoders to measure joint position and velocity, roll and pitch from the IMU sensor and the binarized foot contact indicators from the foot sensors ? Environmental Variations : ?? includes mass and its position on the robot (3 dims), motor strength (12 dims), friction (scalar) and local terrain height (scalar), making it a 17-dim vector Environment Details
- 12. Experiment ? Base Policy ? and Environment Factor Encoder ? Architecture : The base policy is a 3-layer multi-layer perceptron (class of feedforward artificial neural network) which takes in the current state ?? ? ?30 , previous action ???1 ? ?12 and the extrinsics vector ?? ? ?8 and outputs 12-dim target joint angles ? Adaptation Module ? Architecture : The adaptation module first embeds the recent states and actions into 32-dim representations using a 2-layer MLP. Then, a 3-layer 1-D CNN convolves the representations across the time dimension to capture temporal correlations in the input ? Learning ? and ? Network : We jointly train the base policy and the environment encoder network using proximal policy optimization for 15000 iterations each of which uses batch size of 80000 split into 4 mini- batches. The learning rate is set to 5??4 ? Learning ? : Train the adaptation module using supervised learning. Adam optimizer used to minimize MSE loss. Run the optimization process for 1000 iterations with a learning rate of 5??4 each of which uses a batch size of 80,000 split up into 4 mini-batches Training Details
- 13. Results ? We observe that RMA achieves a high success rate in all these setups ? A1ˇŻs controller struggled with uneven foam and with a large step down and step up ? RMA w/o adaptation mostly doesnˇŻt fall, but also doesnˇŻt move forward ? The robot successfully walks across the oily patch. RMA w/o adaptation was able to walk successfully on wooden floor without any fine-tuning or simulation calibration Indoor Setup
- 14. Results ? Robot is successfully able to walk on sand, mud and dirt without a single failure in all trials that terrains make locomotion difficult due to sinking and sticking feet, which requires the robot to change the footholds dynamically to ensure stability ? Had a 100% success rate for walking on tall vegetation or crossing a bush, obstructing the feet of the robot, making it periodically unstable as it walks. To successfully walk in these setups, the robot has to stabilize against foot entanglements, and power through some of these obstructions aggressively ? 70% success rate while walking down some stairs found on a hiking trail. Remarkable as the robot never sees a staircase during training ? On construction debris it was successful 100% of the times when walking downhill over a mud pile and 80% of the times when walking across a cement pile and a pile of pebbles which was steeply sloping sideways, making it very challenging for the robot to go across the pile Outdoor Setup
- 15. Results ? RMA performs the best with only a slight degradation compared to ExpertˇŻs performance ? constantly changing environment leads to poor performance of AWR which is very slow to adapt ? Robust baseline being agnostic to extrinsics, it learns a very conservative policy which loses on performance ? low performance of SysID implies that explicitly estimating ?? is difficult and unnecessary to achieve superior performance ? RMA shows a significant performance gain over RMA w/o adaptation Simulation Results
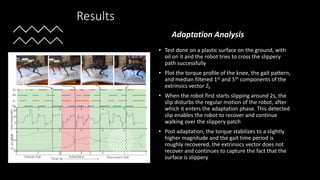
- 16. Results ? Test done on a plastic surface on the ground, with oil on it and the robot tries to cross the slippery path successfully ? Plot the torque profile of the knee, the gait pattern, and median filtered 1st and 5th components of the extrinsics vector ?? ? When the robot first starts slipping around 2s, the slip disturbs the regular motion of the robot, after which it enters the adaptation phase. This detected slip enables the robot to recover and continue walking over the slippery patch ? Post adaptation, the torque stabilizes to a slightly higher magnitude and the gait time period is roughly recovered, the extrinsics vector does not recover and continues to capture the fact that the surface is slippery Adaptation Analysis
- 17. Conclusion ? No demonstrations or predefined motion templates were needed ? Despite only having access to proprioceptive data, the robot can also go downstairs and walk across rocks ? However, sudden falls while going downstairs, or due to multiple leg obstructions from rocks, sometimes lead to failures ? To develop a truly reliable walking robot, we need to use not just proprioception but also exteroception with an onboard vision sensor