























∏È-∞‰±∑±∑§Œ‘≠¿Ì§»§≥§≥ ˝ƒÍ§Œ¡˜§Ï
- 2. Agenda - Introduction - R-CNN§Œ‘≠¿Ì - ÓI”Ú∑÷§± - CNN - ∑÷Óê∆˜ - R-CNN§ŒÜñÓ}µ„ - R-CNN§Œ◊ÓΩ¸§ŒÑ”œÚ - SSD (Single Shot multibox Detector) §Œ∏≈“™ - §Þ§»§· 2
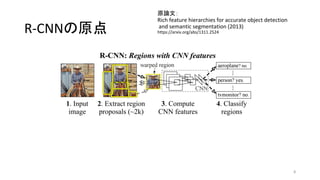
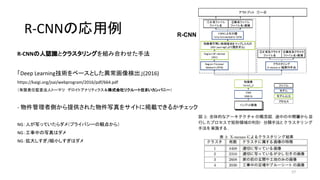
- 3. R-CNN (Regions with CNN features) ('n03085013', 'computer_keyboard', 0.78958303) ('n04264628', 'space_bar', 0.13960978) ('n04505470', 'typewriter_keyboard', 0.050729375) ('n03793489', 'mouse', 0.0087937126) ('n04074963', 'remote_control', 0.0026325041) * ≥ˆµ‰£∫»Àπ§÷™ƒÐ§ÀÈv§π§Î∂œÑìÂh - Keras§«VGG16§Ú 𧶠(2017) * http://aidiary.hatenablog.com/entry/20170104/1483535144 CNN (Convolutional Neural Network) Ög竧œ ª≠œÒ»´Ã§´§ÈÃÿè’¡ø (feature) §Ú≥È≥ˆø…ƒÐ ÓI”Ú∫Ú—a (Region Proposals) §Ú…˙≥…§π§Ï§–... Regionö∞§Œfeature§Ú≥È≥ˆø…ƒÐ »ÀÈg§¨––§¶§Ë§¶§ °±ŒÔÃÂ’J◊R°± * ≥ˆµ‰£∫Rich feature hierarchies for accurate object detection and semantic segmentation (2013) * https://arxiv.org/abs/1311.2524 3
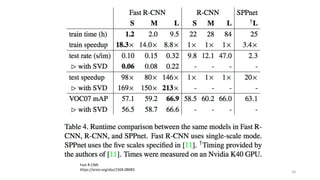
- 4. R-CNN§ŒèÍ”√¿˝ 4* NVIDIA Seminar •«•£©`•◊•È©`•À•Û•∞§À§Ë§Îª≠œÒ’J◊R§»èÍ”√ ¬¿˝ * /Takayosi/nvidia-51814334 §π§þ§Þ§ª§Û°¢RNN§ŒèÍ”√¿˝§«§∑§ø
- 5. R-CNN§ŒèÍ”√¿˝ 5* NVIDIA Seminar •«•£©`•◊•È©`•À•Û•∞§À§Ë§Îª≠œÒ’J◊R§»èÍ”√ ¬¿˝ * /Takayosi/nvidia-51814334
- 7. Agenda - Introduction - R-CNN§Œ‘≠¿Ì - ÓI”Ú∑÷§± - CNN - ∑÷Óê∆˜ - R-CNN§ŒÜñÓ}µ„ - R-CNN§Œ◊ÓΩ¸§ŒÑ”œÚ - SSD (Single Shot multibox Detector) §Œ∏≈“™ - §Þ§»§· 7
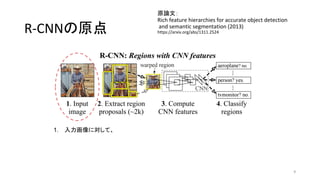
- 8. R-CNN§Œ‘≠µ„ ‘≠’쌃£∫ Rich feature hierarchies for accurate object detection and semantic segmentation (2013) https://arxiv.org/abs/1311.2524 8
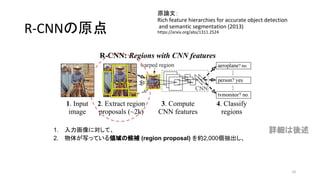
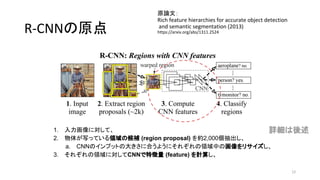
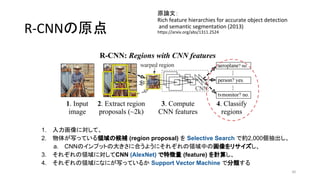
- 9. R-CNN§Œ‘≠µ„ ‘≠’쌃£∫ Rich feature hierarchies for accurate object detection and semantic segmentation (2013) https://arxiv.org/abs/1311.2524 9 1. »Î¡¶ª≠œÒ§Àåù§∑§∆°¢ 2. ŒÔ稖¥§√§∆§§§ÎÓI”Ú§Œ∫Ú—a (region proposal) §Ú≥È≥ˆ§∑°¢ a. CNN§Œ•§•Û•◊•√•»§Œ¥Û§≠§µ§À∫œ§¶§Ë§¶§ÀÓI”Ú÷–§Œª≠œÒ§Ú•Í•µ •§•∫§∑°¢ 3. §Ω§Ï§æ§Ï§ŒÓI”Ú§Àåù§∑§∆CNN§«Ãÿè’¡ø (feature) §Ú”ãÀ„§∑ 4. §Ω§Ï§æ§Ï§ŒÓI”Ú§À§ §À§¨–¥§√§∆§§§Î§´∑÷Óê§π§Î
- 10. R-CNN§Œ‘≠µ„ ‘≠’쌃£∫ Rich feature hierarchies for accurate object detection and semantic segmentation (2013) https://arxiv.org/abs/1311.2524 10 1. »Î¡¶ª≠œÒ§Àåù§∑§∆°¢ 2. ŒÔ稖¥§√§∆§§§ÎÓI”Ú§Œ∫Ú—a (region proposal) §Úºs2,000ÇÄ≥È≥ˆ§∑°¢ a. CNN§Œ•§•Û•◊•√•»§Œ¥Û§≠§µ§À∫œ§¶§Ë§¶§ÀÓI”Ú÷–§Œª≠œÒ§Ú•Í•µ•§•∫§∑°¢ 3. §Ω§Ï§æ§Ï§ŒÓI”Ú§Àåù§∑§∆CNN§«Ãÿè’¡ø (feature) §Ú”ãÀ„§∑ 4. §Ω§Ï§æ§Ï§ŒÓI”Ú§À§ §À§¨–¥§√§∆§§§Î§´∑÷Óê§π§Î ‘îºö§œ·· ˆ
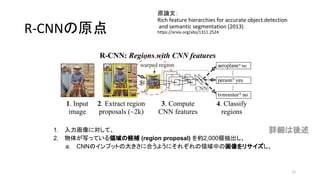
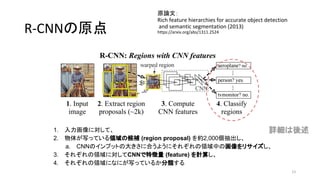
- 11. R-CNN§Œ‘≠µ„ ‘≠’쌃£∫ Rich feature hierarchies for accurate object detection and semantic segmentation (2013) https://arxiv.org/abs/1311.2524 11 1. »Î¡¶ª≠œÒ§Àåù§∑§∆°¢ 2. ŒÔ稖¥§√§∆§§§ÎÓI”Ú§Œ∫Ú—a (region proposal) §Úºs2,000ÇÄ≥È≥ˆ§∑°¢ a. CNN§Œ•§•Û•◊•√•»§Œ¥Û§≠§µ§À∫œ§¶§Ë§¶§À§Ω§Ï§æ§Ï§ŒÓI”Ú÷–§Œª≠œÒ§Ú•Í•µ•§•∫§∑°¢ 3. §Ω§Ï§æ§Ï§ŒÓI”Ú§Àåù§∑§∆CNN§«Ãÿè’¡ø (feature) §Ú”ãÀ„§∑ 4. §Ω§Ï§æ§Ï§ŒÓI”Ú§À§ §À§¨–¥§√§∆§§§Î§´∑÷Óê§π§Î ‘îºö§œ·· ˆ
- 12. R-CNN§Œ‘≠µ„ ‘≠’쌃£∫ Rich feature hierarchies for accurate object detection and semantic segmentation (2013) https://arxiv.org/abs/1311.2524 12 1. »Î¡¶ª≠œÒ§Àåù§∑§∆°¢ 2. ŒÔ稖¥§√§∆§§§ÎÓI”Ú§Œ∫Ú—a (region proposal) §Úºs2,000ÇÄ≥È≥ˆ§∑°¢ a. CNN§Œ•§•Û•◊•√•»§Œ¥Û§≠§µ§À∫œ§¶§Ë§¶§À§Ω§Ï§æ§Ï§ŒÓI”Ú÷–§Œª≠œÒ§Ú•Í•µ•§•∫§∑°¢ 3. §Ω§Ï§æ§Ï§ŒÓI”Ú§Àåù§∑§∆CNN§«Ãÿè’¡ø (feature) §Ú”ãÀ„§∑°¢ 4. §Ω§Ï§æ§Ï§ŒÓI”Ú§À§ §À§¨–¥§√§∆§§§Î§´∑÷Óê§π§Î ‘îºö§œ·· ˆ
- 13. R-CNN§Œ‘≠µ„ ‘≠’쌃£∫ Rich feature hierarchies for accurate object detection and semantic segmentation (2013) https://arxiv.org/abs/1311.2524 13 1. »Î¡¶ª≠œÒ§Àåù§∑§∆°¢ 2. ŒÔ稖¥§√§∆§§§ÎÓI”Ú§Œ∫Ú—a (region proposal) §Úºs2,000ÇÄ≥È≥ˆ§∑°¢ a. CNN§Œ•§•Û•◊•√•»§Œ¥Û§≠§µ§À∫œ§¶§Ë§¶§À§Ω§Ï§æ§Ï§ŒÓI”Ú÷–§Œª≠œÒ§Ú•Í•µ•§•∫§∑°¢ 3. §Ω§Ï§æ§Ï§ŒÓI”Ú§Àåù§∑§∆CNN§«Ãÿè’¡ø (feature) §Ú”ãÀ„§∑°¢ 4. §Ω§Ï§æ§Ï§ŒÓI”Ú§À§ §À§¨–¥§√§∆§§§Î§´∑÷Óê§π§Î ‘îºö§œ·· ˆ
- 15. R-CNN§Œ‘≠¿Ì(1)£∫ÓI”Ú∑÷§± …´°©§ •¢•Î•¥•Í•∫•ý§¨¥Ê‘⁄§π§Î§¨°¢£®§¢§Ø§Þ§«œ»––—–æø§»§Œ±»ð^§Œ§ø§·£© ‘≠’쌃§«§œselective search§Ú”√§§§∆§§§Î 15 1. …´§‰ù‚µ≠π¥≈‰§ §…§ŒÃÿè’§¨ÓêÀ∆§π§ÎÓI”Ú§À∑÷§±§Î 2. ÓêÀ∆∂»§¨∏þ§§ÎOΩ”ÓI”Ú§Ú§…§Û§…§ÛΩY∫œ§∑§∆§§§Ø §≥§¶§∑§∆–°§µ§§ÓI”Ú∫Ú—a§´§È¥Û§≠§ ÓI”Ú∫Ú—a§Þ§«æW¡_ £®≤Œøº£∫ÓI”Ú§Œ¥Û§≠§µ§Œ§≥§»§Ú•π•±©`•Î§»∫Ù§÷£© °∞Fast mode°±§«§œºs2,000ÇħŒ∫Ú—a (VOC @ ~500x300 pix) ïrœµ¡– * ≥ˆµ‰£∫Selective Search for Object Recognition * https://www.koen.me/research/selectivesearch/
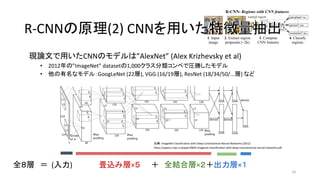
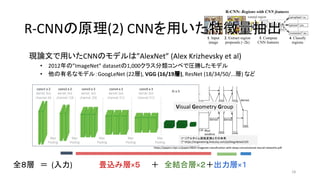
- 16. ¨F’쌃§«”√§§§øCNN§Œ•‚•«•Î§œ°±AlexNet°± (Alex Krizhevsky et al) ? 2012ƒÍ§Œ°±ImageNet°± dataset§Œ1,000•Ø•È•π∑÷Óê•≥•Û•⁄§«àRÑŸ§∑§ø•‚•«•Î ? À˚§Œ”–√˚§ •‚•«•Î£∫GoogLeNet (22å”), VGG (16/19å”), ResNet (18/34/50/...å”) § §… 16 ≥ˆµ‰£∫ImageNet Classification with Deep Convolutional Neural Networks (2012) https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf R-CNN§Œ‘≠¿Ì(2) CNN§Ú”√§§§øÃÿè’¡ø≥È≥ˆR-CNN§Œ‘≠¿Ì(2) CNN§Ú”√§§§øÃÿè’¡ø≥È≥ˆ »´£∏å”°°£Ω (»Î¡¶)°°°°°°°°°°ÆíÞz§þå”°¡£µ°°°°£´°°»´ΩY∫œå”°¡£≤£´≥ˆ¡¶å”°¡£±
- 17. ¨F’쌃§«”√§§§øCNN§Œ•‚•«•Î§œ°±AlexNet°± (Alex Krizhevsky et al) ? 2012ƒÍ§Œ°±ImageNet°± dataset§Œ1,000•Ø•È•π∑÷Óê•≥•Û•⁄§«àRÑŸ§∑§ø•‚•«•Î ? À˚§Œ”–√˚§ •‚•«•Î£∫GoogLeNet (22å”), VGG (16/19å”), ResNet (18/34/50/...å”) § §… 17 ≥ˆµ‰£∫ImageNet Classification with Deep Convolutional Neural Networks (2012) https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf R-CNN§Œ‘≠¿Ì(2) CNN§Ú”√§§§øÃÿè’¡ø≥È≥ˆR-CNN§Œ‘≠¿Ì(2) CNN§Ú”√§§§øÃÿè’¡ø≥È≥ˆ »´£∏å”°°£Ω (»Î¡¶)°°°°°°°°°°ÆíÞz§þå”°¡£µ°°°°£´°°»´ΩY∫œå”°¡£≤£´≥ˆ¡¶å”°¡£± * GoogLeNet in Keras * https://joelouismarino.github.io/blog_posts/blog_googlenet_keras.html
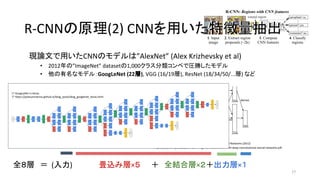
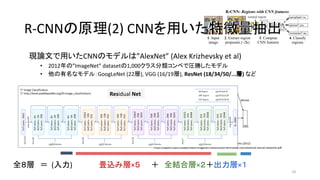
- 18. ¨F’쌃§«”√§§§øCNN§Œ•‚•«•Î§œ°±AlexNet°± (Alex Krizhevsky et al) ? 2012ƒÍ§Œ°±ImageNet°± dataset§Œ1,000•Ø•È•π∑÷Óê•≥•Û•⁄§«àRÑŸ§∑§ø•‚•«•Î ? À˚§Œ”–√˚§ •‚•«•Î£∫GoogLeNet (22å”), VGG (16/19å”), ResNet (18/34/50/...å”) § §… 18 ≥ˆµ‰£∫ImageNet Classification with Deep Convolutional Neural Networks (2012) https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf R-CNN§Œ‘≠¿Ì(2) CNN§Ú”√§§§øÃÿè’¡ø≥È≥ˆR-CNN§Œ‘≠¿Ì(2) CNN§Ú”√§§§øÃÿè’¡ø≥È≥ˆ »´£∏å”°°£Ω (»Î¡¶)°°°°°°°°°°ÆíÞz§þå”°¡£µ°°°°£´°°»´ΩY∫œå”°¡£≤£´≥ˆ¡¶å”°¡£± * •Í•¢•Î•ø•§•ýª≠ÔLâ‰ìQ§»§Ω§ŒŒ¥¿¥ * https://engineering.linecorp.com/ja/blog/detail/105 Visual Geometry Group
- 19. ¨F’쌃§«”√§§§øCNN§Œ•‚•«•Î§œ°±AlexNet°± (Alex Krizhevsky et al) ? 2012ƒÍ§Œ°±ImageNet°± dataset§Œ1,000•Ø•È•π∑÷Óê•≥•Û•⁄§«àRÑŸ§∑§ø•‚•«•Î ? À˚§Œ”–√˚§ •‚•«•Î£∫GoogLeNet (22å”), VGG (16/19å”), ResNet (18/34/50/...å”) § §… 19 ≥ˆµ‰£∫ImageNet Classification with Deep Convolutional Neural Networks (2012) https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf R-CNN§Œ‘≠¿Ì(2) CNN§Ú”√§§§øÃÿè’¡ø≥È≥ˆR-CNN§Œ‘≠¿Ì(2) CNN§Ú”√§§§øÃÿè’¡ø≥È≥ˆ »´£∏å”°°£Ω (»Î¡¶)°°°°°°°°°°ÆíÞz§þå”°¡£µ°°°°£´°°»´ΩY∫œå”°¡£≤£´≥ˆ¡¶å”°¡£± * Image Classification * http://book.paddlepaddle.org/03.image_classification/ Residual Net
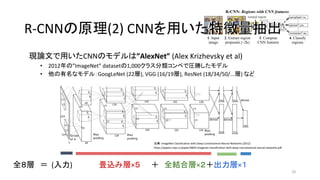
- 20. ¨F’쌃§«”√§§§øCNN§Œ•‚•«•Î§œ°±AlexNet°± (Alex Krizhevsky et al) ? 2012ƒÍ§Œ°±ImageNet°± dataset§Œ1,000•Ø•È•π∑÷Óê•≥•Û•⁄§«àRÑŸ§∑§ø•‚•«•Î ? À˚§Œ”–√˚§ •‚•«•Î£∫GoogLeNet (22å”), VGG (16/19å”), ResNet (18/34/50/...å”) § §… 20 ≥ˆµ‰£∫ImageNet Classification with Deep Convolutional Neural Networks (2012) https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf R-CNN§Œ‘≠¿Ì(2) CNN§Ú”√§§§øÃÿè’¡ø≥È≥ˆR-CNN§Œ‘≠¿Ì(2) CNN§Ú”√§§§øÃÿè’¡ø≥È≥ˆ »´£∏å”°°£Ω (»Î¡¶)°°°°°°°°°°ÆíÞz§þå”°¡£µ°°°°£´°°»´ΩY∫œå”°¡£≤£´≥ˆ¡¶å”°¡£±
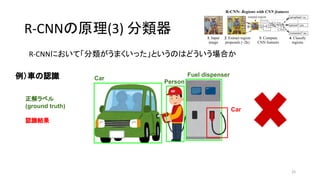
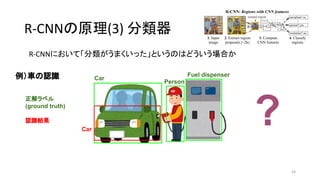
- 21. R-CNN§Œ‘≠¿Ì(3) ∑÷Óê∆˜ R-CNN§À§™§§§∆°∏∑÷Óꧨ§¶§Þ§Ø§§§√§ø°π§»§§§¶§Œ§œ§…§¶§§§¶àˆ∫œ§´ 21 Car Person Fuel dispenser ’˝Ω‚•È•Ÿ•Î (ground truth) ¿˝£©Ð᧌’J◊R
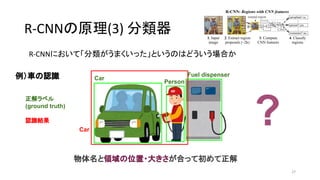
- 22. R-CNN§Œ‘≠¿Ì(3) ∑÷Óê∆˜ R-CNN§À§™§§§∆°∏∑÷Óꧨ§¶§Þ§Ø§§§√§ø°π§»§§§¶§Œ§œ§…§¶§§§¶àˆ∫œ§´ 22 Car Person Fuel dispenser ’˝Ω‚•È•Ÿ•Î (ground truth) ’J◊RΩYπ˚ ¿˝£©Ð᧌’J◊R Car
- 23. R-CNN§Œ‘≠¿Ì(3) ∑÷Óê∆˜ R-CNN§À§™§§§∆°∏∑÷Óꧨ§¶§Þ§Ø§§§√§ø°π§»§§§¶§Œ§œ§…§¶§§§¶àˆ∫œ§´ 23 Car Person Fuel dispenser ’˝Ω‚•È•Ÿ•Î (ground truth) ’J◊RΩYπ˚ ¿˝£©Ð᧌’J◊R Train
- 24. R-CNN§Œ‘≠¿Ì(3) ∑÷Óê∆˜ R-CNN§À§™§§§∆°∏∑÷Óꧨ§¶§Þ§Ø§§§√§ø°π§»§§§¶§Œ§œ§…§¶§§§¶àˆ∫œ§´ 24 Car Person Fuel dispenser ’˝Ω‚•È•Ÿ•Î (ground truth) ’J◊RΩYπ˚ ¿˝£©Ð᧌’J◊R Car
- 25. R-CNN§Œ‘≠¿Ì(3) ∑÷Óê∆˜ R-CNN§À§™§§§∆°∏∑÷Óꧨ§¶§Þ§Ø§§§√§ø°π§»§§§¶§Œ§œ§…§¶§§§¶àˆ∫œ§´ 25 Car Person Fuel dispenser ’˝Ω‚•È•Ÿ•Î (ground truth) ’J◊RΩYπ˚ ¿˝£©Ð᧌’J◊R Car
- 26. R-CNN§Œ‘≠¿Ì(3) ∑÷Óê∆˜ R-CNN§À§™§§§∆°∏∑÷Óꧨ§¶§Þ§Ø§§§√§ø°π§»§§§¶§Œ§œ§…§¶§§§¶àˆ∫œ§´ 26 Car Person Fuel dispenser ’˝Ω‚•È•Ÿ•Î (ground truth) ’J◊RΩYπ˚ ¿˝£©Ð᧌’J◊R Car ?
- 27. R-CNN§Œ‘≠¿Ì(3) ∑÷Óê∆˜ R-CNN§À§™§§§∆°∏∑÷Óꧨ§¶§Þ§Ø§§§√§ø°π§»§§§¶§Œ§œ§…§¶§§§¶àˆ∫œ§´ 27 Car Person Fuel dispenser ’˝Ω‚•È•Ÿ•Î (ground truth) ’J◊RΩYπ˚ ¿˝£©Ð᧌’J◊R Car ? ŒÔÃÂ√˚§»ÓI”Ú§ŒŒª÷√?¥Û§≠§µ§¨∫œ§√§∆≥ı§·§∆’˝Ω‚
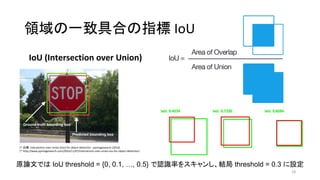
- 28. ÓI”Ú§Œ“ª÷¬æþ∫œ§Œ÷∏òÀ IoU IoU (Intersection over Union) 28 * ≥ˆµ‰£∫Intersection over Union (IoU) for object detection - pyimagesearch (2016) * http://www.pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/ ‘≠’쌃§«§œ IoU threshold = {0, 0.1, °≠, 0.5} §«’J◊R¬ §Ú•π•≠•„•Û§∑°¢ΩYæ÷ threshold = 0.3 §À‘O∂®
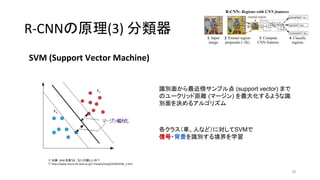
- 29. R-CNN§Œ‘≠¿Ì(3) ∑÷Óê∆˜ 29 SVM (Support Vector Machine) * ≥ˆµ‰£∫SVM §Ú 𧶧»£¨§ §À§¨Ê“§∑§§§Œ£ø * http://www.neuro.sfc.keio.ac.jp/~masato/study/SVM/SVM_1.htm ◊RÑe√ʧ´§È◊ÓΩ¸∞¯•µ•Û•◊•Îµ„ (support vector) §Þ§« §Œ•Ê©`•Ø•Í•√•…æýÎx (•Þ©`•∏•Û) §Ú◊ӥ۪اπ§Î§Ë§¶§ ◊R Ñe√ʧÚõQ§·§Î•¢•Î•¥•Í•∫•ý ∏˜•Ø•È•π£®Ðá°¢»À§ §…£©§Àåù§∑§∆SVM§« –≈∫≈?±≥æ∞§Ú◊RÑe§π§Îæ≥ΩÁ§Ú—ß¡ï
- 30. R-CNN§Œ‘≠µ„ ‘≠’쌃£∫ Rich feature hierarchies for accurate object detection and semantic segmentation (2013) https://arxiv.org/abs/1311.2524 30 1. »Î¡¶ª≠œÒ§Àåù§∑§∆°¢ 2. ŒÔ稖¥§√§∆§§§ÎÓI”Ú§Œ∫Ú—a (region proposal) §Ú Selective Search §«ºs2,000ÇÄ≥È≥ˆ§∑°¢ a. CNN§Œ•§•Û•◊•√•»§Œ¥Û§≠§µ§À∫œ§¶§Ë§¶§À§Ω§Ï§æ§Ï§ŒÓI”Ú÷–§Œª≠œÒ§Ú•Í•µ•§•∫§∑°¢ 3. §Ω§Ï§æ§Ï§ŒÓI”Ú§Àåù§∑§∆CNN (AlexNet) §«Ãÿè’¡ø (feature) §Ú”ãÀ„§∑°¢ 4. §Ω§Ï§æ§Ï§ŒÓI”Ú§À§ §À§¨–¥§√§∆§§§Î§´ Support Vector Machine §«∑÷Óê§π§Î
- 31. Agenda - Introduction - R-CNN§Œ‘≠¿Ì - ÓI”Ú∑÷§± - CNN - ∑÷Óê∆˜ - R-CNN§ŒÜñÓ}µ„ - R-CNN§Œ◊ÓΩ¸§ŒÑ”œÚ - SSD (Single Shot multibox Detector) §Œ∏≈“™ - §Þ§»§· 31
- 32. •™•Í•∏• •ÎR-CNN§Œ«∑µ„ —ߡ裡∂ý∂Œ§ŒÑI¿Ì§À§ §√§∆§§§∆ü©Îj 1. §Þ§∫°±ImageNet°± dataset£®£±ª≠œÒ§À£±ŒÔ㩧«CNN§Úpretrain 2. °∞VOC°± dataset£®£±ª≠œÒ§À—} ˝ŒÔ㩧«CNN§Úfine-tuning* *fine-tuning: …œ¡˜§Œå”§Œ÷ÿ§þ§œπÃ∂®§∑°¢»´ΩY∫œå”§ §…œ¬¡˜§Œå”§Œ÷ÿ§þ§Œ§þ§Ú training§π§Î§≥§» 3. CNN§Œ≥ˆ¡¶Ç»§ÀSVM§Úðd§ª§∆—ß¡ï 4. æÿ–Œªÿ颧Œ—ß¡ï åg––ïrÈg§¨þW§§ ? ÓI”Ú∫Ú—a 2,000 ÇħÀåù§∑§∆§Ω§Ï§æ§ÏCNN§Ú◊þ§È§ª§∆§§§Î ? ’J◊RïrÈg 10-45 s/image @ Nvidia Tesla K40 (cf: ◊Ó–¬Tesla P100§œThroughput~10±∂) ? ∂ý ˝§Œ°±þMªØ∞Ê°±§¨øº∞∏§µ§Ï§∆§§§Î 32 £®≤Œøº£©’쌃ΩBΩÈ£∫Fast R-CNN & Faster R-CNN /takashiabe338/fast-rcnnfaster-rcnn
- 33. Agenda - Introduction - R-CNN§Œ‘≠¿Ì - ÓI”Ú∑÷§± - CNN - ∑÷Óê∆˜ - R-CNN§ŒÜñÓ}µ„ - R-CNN§Œ◊ÓΩ¸§ŒÑ”œÚ - SSD (Single Shot multibox Detector) §Œ∏≈“™ - §Þ§»§· 33
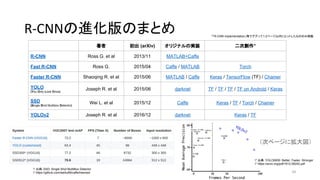
- 34. R-CNN§ŒþMªØ∞ʧŒ§Þ§»§· 34 ÷¯’þ ≥ı≥ˆ (arXiv) •™•Í•∏• •Î§Œåg◊∞ ∂˛¥ŒÑì◊˜* R-CNN Ross G. et al 2013/11 MATLAB+Caffe Fast R-CNN Ross G. 2015/04 Caffe / MATLAB Torch Faster R-CNN Shaoqing R. et at 2015/06 MATLAB / Caffe Keras / TensorFlow (TF) / Chainer YOLO (You Only Look Once) Joseph R. et al 2015/06 darknet TF / TF / TF / TF on Android / Keras SSD (Single Shot Multibox Detector) Wei L. et al 2015/12 Caffe Keras / TF / Torch / Chainer YOLOv2 Joseph R. et al 2016/12 darknet Keras / TF *°∏R-CNN implementation°πµ»§«•∞•∞§√§∆1-2•⁄©`•∏“‘ƒ⁄§À•“•√•»§∑§ø§‚§Œ§Œ§þí˜ðd * ≥ˆµ‰£∫SSD: Single Shot MultiBox Detector * https://github.com/weiliu89/caffe/tree/ssd * ≥ˆµ‰£∫YOLO9000: Better, Faster, Stronger * https://arxiv.org/pdf/1612.08242.pdf £®¥Œ•⁄©`•∏§Àíà¥ÛáÌ£©
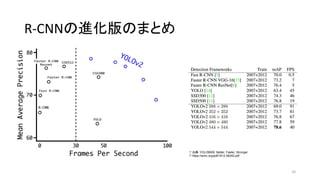
- 35. R-CNN§ŒþMªØ∞ʧŒ§Þ§»§· 35 * ≥ˆµ‰£∫YOLO9000: Better, Faster, Stronger * https://arxiv.org/pdf/1612.08242.pdf
- 36. Agenda - Introduction - R-CNN§Œ‘≠¿Ì - ÓI”Ú∑÷§± - CNN - ∑÷Óê∆˜ - R-CNN§ŒÜñÓ}µ„ - R-CNN§Œ◊ÓΩ¸§ŒÑ”œÚ - SSD (Single Shot multibox Detector) §Œ∏≈“™ - §Þ§»§· 36
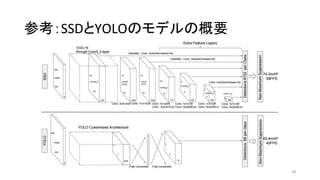
- 37. SSD§Œ∏≈“™ ? Single Shot multibox Detector (SSD) ? Single Shot (§“§»§ƒ§Œ•Õ•√•»•Ô©`•Ø) §«—} ˝§ŒŒÔçڒJ◊R ? YOLOv1§Ë§Í§‚ÀŸ§Ø°¢Faster R-CNN§»Õ¨≥Ã∂»§Œæ´∂» ? Feature map§Àåù§∑§∆–°§µ§ Æí§þÞz§þ•’•£•Î•ø§Ú§´§±°¢§Ω§Ï§æ§Ï§ŒÓI”Ú §«∏˜ŒÔÃÂ•Ø•È•π§Œ•π•≥•¢§»•Ð•√•Ø•πŒª÷√§Œ•™•’•ª•√•»§Ú”Ëúy£®·· ˆ£© ? Æê§ §Î•π•±©`•Î?•¢•π•⁄•Ø•»±»§«…œ ˆ§Œ≤Ÿ◊˜§Ú¿R§Í∑µ§π ? R-CNN§œÓI”Ú∫Ú—a§Ú≥ˆ§∑§∆§´§È°¢»´∫Ú—a§ÀCNN§Ú◊þ§È§ª§Î ? ŒÔÃÂ’J◊R§»•Ð•√•Ø•πŒª÷√§Ω§Ï§æ§Ï§Œìp ßÈv ˝§Œ∫Õ§Ú◊Ó–°ªØ§µ§ª§Î£®·· ˆ£© ? °∞end-to-end°±§«trainingø…ƒÐ ? R-CNN§œ∂ý∂ŒÎA§Œtraining§¨±ÿ“™ 37
- 38. ? Single Shot multibox Detector (SSD) ? Single Shot (§“§»§ƒ§Œ•Õ•√•»•Ô©`•Ø) §«—} ˝§ŒŒÔçڒJ◊R ? YOLOv1§Ë§Í§‚ÀŸ§Ø°¢Faster R-CNN§»Õ¨≥Ã∂»§Œæ´∂» ? Feature map§Àåù§∑§∆–°§µ§ Æí§þÞz§þ•’•£•Î•ø§Ú§´§±°¢§Ω§Ï§æ§Ï§ŒÓI”Ú §«∏˜ŒÔÃÂ•Ø•È•π§Œ•π•≥•¢§»•Ð•√•Ø•πŒª÷√§Œ•™•’•ª•√•»§Ú”Ëúy£®·· ˆ£© ? Æê§ §Î•π•±©`•Î?•¢•π•⁄•Ø•»±»§«…œ ˆ§Œ≤Ÿ◊˜§Ú¿R§Í∑µ§π ? R-CNN§œÓI”Ú∫Ú—a§Ú≥ˆ§∑§∆§´§È°¢»´∫Ú—a§ÀCNN§Ú◊þ§È§ª§Î ? ŒÔÃÂ’J◊R§»•Ð•√•Ø•πŒª÷√§Ω§Ï§æ§Ï§Œìp ßÈv ˝§Œ∫Õ§Ú◊Ó–°ªØ§µ§ª§Î£®·· ˆ£© ? °∞end-to-end°±§«trainingø…ƒÐ ? R-CNN§œ∂ý∂ŒÎA§Œtraining§¨±ÿ“™ SSD§Œ∏≈“™ 38 SSD300 in Keras @ TiTan X
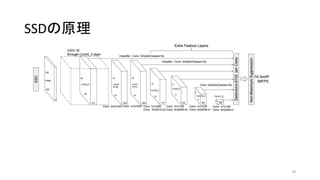
- 39. SSD§Œ‘≠¿Ì 39
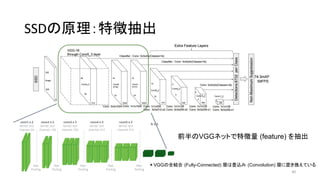
- 40. SSD§Œ‘≠¿Ì£∫Ãÿè’≥È≥ˆ 40 £™VGG§Œ»´ΩY∫œ (Fully-Connected) 唧œÆíÞz§þ (Convolution) 唧À÷√§≠ìQ§®§∆§§§Î «∞∞ΧŒVGG•Õ•√•»§«Ãÿè’¡ø (feature) §Ú≥È≥ˆ
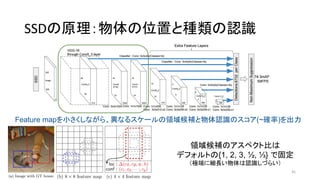
- 41. SSD§Œ‘≠¿Ì£∫ŒÔ猌ª÷√§»∑NÓ꧌’J◊R 41 Feature map§Ú–°§µ§Ø§∑§ §¨§È°¢Æê§ §Î•π•±©`•Î§ŒÓI”Ú∫Ú—a§»ŒÔÃÂ’J◊R§Œ•π•≥•¢(~¥_¬ )§Ú≥ˆ¡¶ ÓI”Ú∫Ú—a§Œ•¢•π•⁄•Ø•»±»§œ •«•’•©•Î•»§Œ{1, 2, 3, ?, ?} §«πÃ∂® £®òO∂À§ÀºöÈL§§ŒÔ眒J◊R§∑§≈§È§§£©
- 42. SSD§Œ‘≠¿Ì£∫ŒÔ猌ª÷√§»∑NÓ꧌’J◊R 42 Feature map§Ú–°§µ§Ø§∑§ §¨§È°¢Æê§ §Î•π•±©`•Î§ŒÓI”Ú∫Ú—a§»ŒÔÃÂ’J◊R§Œ•π•≥•¢(~¥_¬ )§Ú≥ˆ¡¶ ÓI”Ú∫Ú—a§Œ•¢•π•⁄•Ø•»±»§œ •«•’•©•Î•»§Œ{1, 2, 3, ?, ?} §«πÃ∂® £®òO∂À§ÀºöÈL§§ŒÔ眒J◊R§∑§≈§È§§£ø£© ≥ˆµ‰£∫/xavigiro/ssd-single-shot-multibox-detector
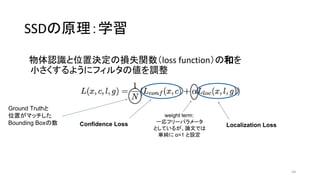
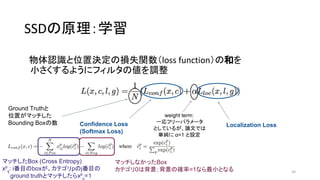
- 44. SSD§Œ‘≠¿Ì£∫—ß¡ï ŒÔÃÂ’J◊R§»Œª÷√õQ∂®§Œìp ßÈv ˝£®loss function£©§Œ∫Õ§Ú –°§µ§Ø§π§Î§Ë§¶§À•’•£•Î•ø§ŒÇé§Ú’{’˚ 44 Confidence Loss Localization Loss weight term: “ªèÍ•’•Í©`•—•È•·©`•ø §»§∑§∆§§§Î§¨°¢’쌃§«§œ ÖgºÉ§À ¶¡=1 §»‘O∂® Ground Truth§» Œª÷√§¨•Þ•√•¡§∑§ø Bounding Box§Œ ˝
- 45. SSD§Œ‘≠¿Ì£∫—ß¡ï ŒÔÃÂ’J◊R§»Œª÷√õQ∂®§Œìp ßÈv ˝£®loss function£©§Œ∫Õ§Ú –°§µ§Ø§π§Î§Ë§¶§À•’•£•Î•ø§ŒÇé§Ú’{’˚ 45 Ground Truth§» Œª÷√§¨•Þ•√•¡§∑§ø Bounding Box§Œ ˝ Confidence Loss (Softmax Loss) Localization Loss •Þ•√•¡§∑§øBox (Cross Entropy) xp ij : i∑¨ƒø§Œbox§¨°¢•´•∆•¥•Íp§Œj∑¨ƒø§Œ °°°°ground truth§»•Þ•√•¡§∑§ø§Èxp =£± •Þ•√•¡§∑§ §´§√§øBox •´•∆•¥•Í0§œ±≥æ∞£ª±≥æ∞§Œ¥_¬ =1§ §È◊Ó–°§»§ §Î weight term: “ªèÍ•’•Í©`•—•È•·©`•ø §»§∑§∆§§§Î§¨°¢’쌃§«§œ ÖgºÉ§À ¶¡=1 §»‘O∂®
- 46. SSD§Œ‘≠¿Ì£∫—ß¡ï ŒÔÃÂ’J◊R§»Œª÷√õQ∂®§Œìp ßÈv ˝£®loss function£©§Œ∫Õ§Ú –°§µ§Ø§π§Î§Ë§¶§À•’•£•Î•ø§ŒÇé§Ú’{’˚ 46 Ground Truth§» Œª÷√§¨•Þ•√•¡§∑§ø Bounding Box§Œ ˝ Confidence Loss (Softmax Loss) weight term: “ªèÍ•’•Í©`•—•È•·©`•ø §»§∑§∆§§§Î§¨°¢’쌃§«§œ ÖgºÉ§À ¶¡=1 §»‘O∂® Localization Loss (Smooth L1 Loss) lm i : Predicted Box§Œcenter x, y, width, height gm j : Ground truth§Œcenter x, y, width, heightπ¥≈‰§¨¥Û§≠§Ø§ §Íþ^§Æ§ §§ (at most 1)
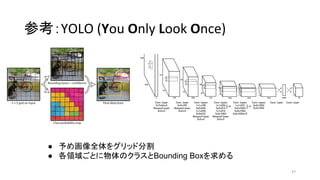
- 47. ≤Œøº£∫YOLO (You Only Look Once) 47 °Ò ”˧·ª≠œÒ»´Ã§ڕ∞•Í•√•…∑÷∏Ó °Ò ∏˜ÓI”Ú§¥§»§ÀŒÔ猕ؕȕπ§»Bounding Box§Ú«Û§·§Î
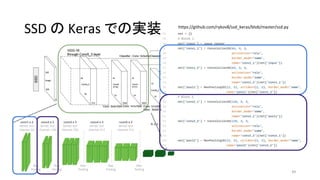
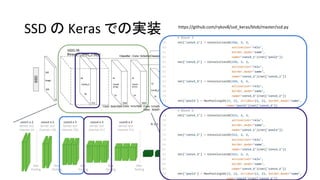
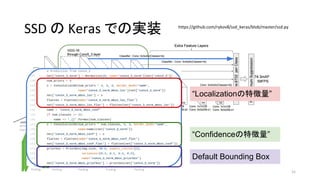
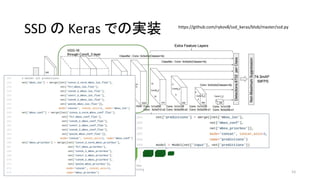
- 51. https://github.com/rykov8/ssd_keras/blob/master/ssd.py 51 SSD §Œ Keras §«§Œåg◊∞ °∞Localization§ŒÃÿè’¡ø°± °∞Confidence§ŒÃÿè’¡ø°± Default Bounding Box
- 53. §Þ§»§· ? R-CNN (Regions with CNN features) §œ °°ÓI”Ú∑÷§±£´CNN§ŒÃÿè’¡ø≥È≥ˆ §ÚΩM§þ∫œ§Ô§ª§∆°¢ª≠œÒƒ⁄§Œ—} ˝ŒÔÃÂ’J◊R§Ú––§¶ ? •™•Í•∏• •Î§ŒR-CNN§œÑ”◊˜§¨þW§π§Æ§∆ π§§ŒÔ§À§ §È§ §§ ? R-CNN∏ƒ¡º∞ʧŒSSD§‰YOLO ? §“§»§ƒ§Œ•À•Â©`•È•Î•Õ•√•»§«ÅI∑Ω§Œ•ø•π•Ø§Úµ£§¶ ? CNN§«Ãÿè’¡ø§Ú’J◊R§∑§∆§´§ÈÓI”Ú∑÷§±§Ú––§¶ 53
- 54. Backup 54
- 60. 60
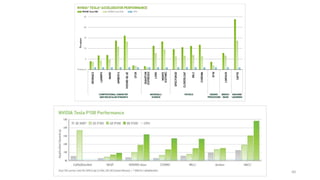
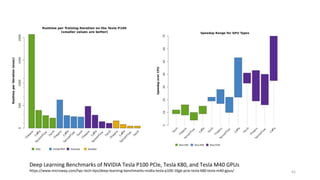
- 61. 61 Deep Learning Benchmarks of NVIDIA Tesla P100 PCIe, Tesla K80, and Tesla M40 GPUs https://www.microway.com/hpc-tech-tips/deep-learning-benchmarks-nvidia-tesla-p100-16gb-pcie-tesla-k80-tesla-m40-gpus/
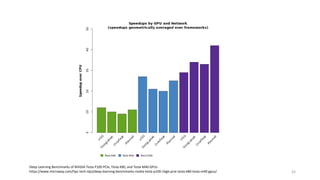
- 62. 62 Deep Learning Benchmarks of NVIDIA Tesla P100 PCIe, Tesla K80, and Tesla M40 GPUs https://www.microway.com/hpc-tech-tips/deep-learning-benchmarks-nvidia-tesla-p100-16gb-pcie-tesla-k80-tesla-m40-gpus/