Reliability and Resilience Patterns
ŌĆó
2 likesŌĆó450 views

Recording: https://vimeo.com/216912094 Presented at OpenTable Tech Talks ŌĆö Scalable and Resilient Microservices (https://www.meetup.com/OpenTable-SF-Engineering/events/239179062/)






























Reliability and Resilience Patterns
- 1. Reliability and Resilience Patterns 05/09/2017 Dmitry Chornyi dchornyi@opentable.com
- 2. Overview ŌŚÅ What are the common causes of service outages? ŌŚÅ Lessons learned from production incidents ŌŚÅ Patterns that we use to make our services resilient 2
- 3. About me ŌŚÅ Software engineer at OpenTable ŌŚÅ Own >20 microservices in production ŌŚÅ Currently on-call 3
- 4. About OpenTable ŌŚÅ Connecting 40k restaurants to 21m diners each month ŌŚÅ >2000 GitHub repositories ŌŚÅ Hundreds of microservices 4
- 5. ŌĆ£Developer looking at logs after a production outageŌĆØ Sir Joseph Noel Paton Oil on Canvas, 1861 5Source: http://classicprogrammerpaintings.com/
- 7. Simple Testing Can Prevent Most Critical Failures ŌĆ£... we also found that for the most catastrophic failures, almost all of them are caused by incorrect error handling, and 58% of them are trivial mistakes or can be exposed by statement coverage testing.ŌĆØ ŌĆö http://dl.acm.org/citation.cfm?id=2685068 7
- 8. 8 Release It!: Design and Deploy Production-Ready Software. Michael T. Nygard Drift into Failure: From Hunting Broken Components to Understanding Complex Systems. Sidney Dekker Site Reliability Engineering: How Google Runs Production Systems. Betsy Beyer, Chris Jones, Jennifer Petoff, Niall Richard Murphy Systems Performance: Enterprise and the Cloud. Brendan Gregg
- 9. Designing for Failure ŌŚÅ Complex systems are rife with failure and are resistant to top-down control ŌŚÅ Moving from eliminating failure to anticipating failure in every component ŌŚÅ Software should be prepared for real-world production challenges and not require constant life-support and human intervention ŌŚÅ Build systems and organizations that improve over time, rather than just not degrade ŌŚÅ Design for failure and operate to learn 9
- 10. Reliability vs Resilience Reliability: ŌŚÅ Stiff boundaries, layers ŌŚÅ Defense in depth ŌŚÅ Redundancy ŌŚÅ Interference protection ŌŚÅ Assurance ŌŚÅ Accountability 10 Resilience: ŌŚÅ Withstand transients ŌŚÅ Recover swiftly and smoothly ŌŚÅ Prioritize to serve high-level goals ŌŚÅ Recognize and respond to anomalies ŌŚÅ Adapt to change Source: Cook 2012
- 11. Failure Modes ŌŚÅ Failure is comprised of a chain of cracks in the system: a failure mode ŌŚÅ High levels of complexity provide more directions for the cracks to propagate ŌŚÅ Tightly coupled architectures increase the chance of propagation ŌŚÅ At each step in the chain, the crack can be accelerated, slowed, or stopped ŌŚÅ Design failure modes that drive failures away from indispensable features 11 Source: Nygard 2007
- 12. Bulkheads ŌŚÅ In a ship bulkheads create watertight compartments, restrict fires, separate cargo ŌŚÅ Partition your systems to keep failure in one part from destroying everything ŌŚÅ Requires more precise capacity planning 12
- 13. ŌĆ£Waiting for the server responseŌĆØ Victor Vasnetsov, 1898 Oil, canvas 13Source: http://classicprogrammerpaintings.com/
- 14. Timeouts ŌŚÅ Never ever block forever ŌŚÅ Set a timeout on any operation that can block threads ŌŚÅ Prefer queue-and-retry to synchronous retries and use circuit breakers ŌŚÅ DonŌĆÖt forget to clean up resources after a timeout happened ŌŚÅ How high should timeouts be? Try 99.9% response time 14
- 15. Resource Pools ŌŚÅ Pool and reuse resources whenever possible to increase efficiency, isolate failure, limit concurrency, separate workloads ŌŚÅ Prefer several smaller pools to one large pool ŌŚÅ Keep pool size as small as possible 15
- 16. Fail Fast ŌŚÅ Slow failure responses tie up capacity, waste system resources, and cascade ŌŚÅ If the system can determine in advance that it will fail at an operation, itŌĆÖs always better to fail fast ŌŚÅ Check that all resources are available and healthy before beginning a transaction 16
- 17. Load Shedding ŌŚÅ Define operational limits of your system and withstand excessive load spikes ŌŚÅ Shed load by rejecting excessive requests, executing a fallback method, returning static data, or applying backpressure to the caller ŌŚÅ Explicit backpressure with handshaking to signal to callers that a service is overloaded ŌŚÅ Implicit backpressure using blocking synchronous calls, semaphores, TCP protocol 17
- 18. Circuit Breakers ŌŚÅ Electrical fuses: detect excess usage, fail first, and open the circuit ŌŚÅ Wrap dangerous operations with a component that can circumvent calls when the system is not healthyŌĆöopposite of retries ŌŚÅ Automatically open the circuit when error threshold is exceeded, provide a fallback mechanism, autorecover when system heals ŌŚÅ Degrade application functionality in response to failure 18
- 19. Client-Side Load Balancing ŌŚÅ Load balancing distributes load, handles failover, reduces coupling ŌŚÅ Prefer client-side load balancing ŌŚÅ Lower latency, higher throughput, partition tolerance, advanced routing 19
- 20. ŌĆ£MySQL maintenanceŌĆØ Vasily Perov Oil on canvas, 1866 20Source: http://classicprogrammerpaintings.com/
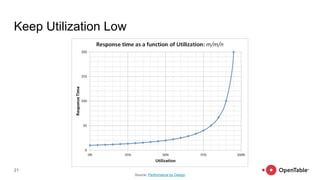
- 21. 21 Keep Utilization Low Source: Performance by Design
- 22. Queuing Effects ŌŚÅ In every system, exactly one constraint determines the systemŌĆÖs capacity ŌŚÅ Once it is reached, all other parts of the system will queue up or drop work ŌŚÅ Response time = processing time + latency (time spent in the queue) ŌŚÅ In practice queues are only found in two states: empty or full 22
- 23. Graceful Degradation ŌŚÅ Define features that your service absolutely needs to provide ŌŚÅ Route failure modes away from the critical path of these features ŌŚÅ Feature flags to shut down parts of your service 23
- 24. Steady State ŌŚÅ The system should be able to run indefinitely without human intervention ŌŚÅ Typical interventions: manual disk cleanups, nightly restarts ŌŚÅ For every mechanism that accumulates a resource, some other mechanism must recycle that resource ŌŚÅ Purge old DB data, rotate log files, expire cache, decommission infrastructure 24
- 25. Service Autonomy ŌŚÅ Expose yourself to latency as rarely as possible ŌŚÅ Use asynchronous communication to reduce temporal coupling ŌŚŗ No synchronous calls to other services on the request path ŌŚŗ No transactions that span multiple services ŌŚŗ Prefetch and cache reads, queue writes ŌŚŗ Eventsourcing and CQRS ŌŚŗ SOA Saga Pattern and Service Choreography 25 Source: Dahan 2006
- 26. Separation of Concerns ŌŚÅ Separate gateways to third parties are from the main transaction services ŌŚÅ API gateways can be used to implement load shedding, timeouts, circuit breakers, handshaking, failure-injection ŌŚÅ Also a good place for security, metrics, logging, and other cross-cutting concerns ŌŚÅ Particularly valuable for legacy systems 26
- 27. Understand your Platform ŌŚÅ You donŌĆÖt have to be an engineer to be be a racing driver, but you do have to have Mechanical Sympathy. ŌŚÅ Understand how hardware, OS, and VM work in order to create efficient software ŌŚÅ Abstractions are leaky: CPU cores, caches, RAM, HDD, network, JVM, GC, thread affinity, Docker, virtualization, data structures 27 Source: Mechanical Sympathy
- 28. Test for Failure ŌŚÅ Build test harnesses that can provoke socket, protocol, and application errors ŌŚÅ Run longevity tests using realistic data volumes to find steady state violations ŌŚÅ Use traffic bursts to measure latency variance and queuing ŌŚÅ Make failure a first-class citizen: game days, chaos monkey, failure injection 28
- 29. Incident Response ŌŚÅ Define an incident management framework ŌŚÅ Clear understanding of responsibilities: command, operational work, communication, planning ŌŚÅ Follow a systematic troubleshooting process ŌŚÅ Blameless postmortems 29
- 30. Antifragile Organization ŌŚÅ Banishing error also banishes innovation and adaptation ŌŚÅ Trade the precise robustness of complicated systems for the sloppy resilience of complex systems ŌŚÅ Remove organizational scar tissue, clean out, automate, reduce handoffs ŌŚÅ Diversity, loose coupling, slack, decentralized anticipation, communication ŌŚÅ Operational discretion at lower levels in the organization ŌŚÅ Regulation, compliance, oversight, inspection are mismatched to complexity 30 Source: Dekker 2011
- 31. ŌĆ£Github Major Service OutageŌĆØ Georges Seurat, 1884 Oil on canvas 31Source: http://classicprogrammerpaintings.com/
- 32. References Nygard, M. T. (2007). Release It!: Design and Deploy Production-Ready Software (Pragmatic Programmers) Dekker, S. (2011). Drift into Failure: From Hunting Broken Components to Understanding Complex Systems Beyer, B., Jones, C., Petoff, J., Murphy, N.R. (2016). Site Reliability Engineering: How Google Runs Production Systems Cook, R. (2012). How Complex Systems Fail Holtman, J., & Gunther, N. J. (2008). Getting in the Zone for Successful Scalability Gunther, N. (2010). Quantifying Scalability FTW Schwartz, B. (2015). Everything You Need To Know About Queueing Theory Herbert, F. (2014). Planning for Overload Thompson, M. (2012). Applying Back Pressure When Overloaded Dean, J. (2012). Achieving Rapid Response Times in Large Online Services Dahan, U. (2006). Autonomous Services and Enterprise Entity Aggregation Thompson, M. Mechanical Sympathy Rasmussen, J. (1997). Risk management in a dynamic society: a modelling problem Andrus, K. (2015). Breaking Bad at Netflix: Building Failure as a Service Tarjan, P. (2017). Scaling your API with rate limiters 32