






































































More Related Content
What's hot (20)
Similar to Sample Solution Blueprint (20)


















Sample Solution Blueprint
- 1. IT Solution Blueprints A Cookie Cutter Approach to Efficient IT Solutions
- 2. Today’s Itinerary • A Blue Print Primer • A Blue Print Based Disaster Recovery Solution • Our Demo Configuration • Failure, Data Loss: Fail Over • Repair, Planned Fail-Back • Analysis of the Solution and the Blue Print
- 3. SECTION 1: BLUE PRINT PRIMER
- 4. It’s The Data, Stupid!! • 60% of companies that lose their data go out of business within 6 months! • 93% of companies that lose the data center for 10 days or more file for bankruptcy within one year! (NA&RA) • Conclusion: The two critical components of DR are: – Protecting the data, and – To be able to resume quickly after disasters and losses!
- 5. Cisco and Blueprints • 2002: Cisco campus on Tasman Drive: – Every building was identical! • Identical blue print for all infrastructure: – Water, Sewer, Power, Networking, Fire safety, .. – Unifies all maintenance, management, upgrades, .. • The entire campus was built much faster and more efficiently “by cookie cutter”! – Populating the campus was done in a hurry. Everything looked the same. – Buildings were reusable as needs changed.
- 6. Our Blue Print Objective • Achieve the same level of efficiency with IT solutions as Cisco did with their campus blue print! • Reuse of architecture and modules to assure rapid an efficient scalability and unified management framework. • Enable rapid creation of new solutions within the same architectural framework. • Enable easier capacity scaling without affecting IT management.
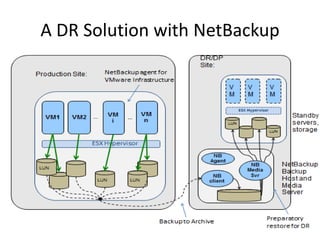
- 7. A DR Solution with NetBackup
- 8. DR/DP Solution Blue Print TOC: • The Platform: – The Physical: Sites, hardware, network – Virtualization: Server, storage, network • The Applications to protect • The Solution Engine: Backup software • Use cases that any DR solution must support • Normalized work flows implementing the use cases. • Questionnaire to assist adaption and customization
- 9. Blue Print Template: The Architectural Principles • Extensive use of virtualization in servers, storage and networking. • Integrating layers of the most cost effective products. • Creating a “building blocks” approach to solutions design and implementation. • Creating designs that can easily be adapted, extended and customized to meet specific requirements. • Unified architecture to simplify management of assets and decision points. • The results are sophisticated and complex, but integrated and efficient business solutions
- 10. Blue Print Summary • Virtualization + sound architectural principles enables a more effective approach to building and implementing solutions. • Customers gets more sophisticated and more reliable solutions per $$. • Resellers and integrators can reuse the building blocks and handle more customers in a shorter amount of time • Reuse of building blocks implies simplified and uniform management.
- 11. SECTION 2: A DR SOLUTION BLUE PRINT
- 12. Our DR Solution • We have a business critical application. • We want to protect it with a DR solution so that in the case of loss of disk, server, site etc., we can rapidly fail over to the DR instance. • Our platform consists of VMware, NetBackup and Windows on top of NEC’s servers, storage and network.
- 13. Objectives and Requirements • RPO: How much data/time are we willing to lose? – I.e. scheduled updates every RPO/2. • RTO: How soon must we operational? – This is total time recovery time. It includes: • The time to make the fail-over decision; • The time required to failover and start DR instance once the decision has been made. • DR or DP? – DR: DR site can support all critical applications. – DP: Only the data is protected. Repair of and recovery is to the production site? – Short RTO => DR standby capability!
- 14. RPO and RTO • RPO: Predominantly a WAN bandwidth issue. – WAN bandwidth is expensive!! – More frequent snapshots -> higher data change volume/hr. – Note that snapshots are inexpensive, they do not affect application performance. • RTO: Total Fail-Over Time: – When the decision is made, how fast to operational applications at DR site? – Cheat!! By updating your DR instances after every completed update! • How reliable is it! – Test often!! Or even better, perform planned fail-over/back regularly!!
- 15. NICHBA ESX Hypervisor NEC FT-Gemini Guest App Guest Guest Ap p Ap p Guest VM1 VM2 VM3 VMn LUN App … Array: FC/iSCSI SAN LUN SAN: NEC D3/D4 array with FC or iSCSI connect: NEC 5800 FT Server running VMware VMs with applications: Array: HBA TCP/IP Network NIC App
- 16. NEC Hydrastor V M V M V M LUN LUN Standby Servers and storage DR/DP Site: Backup from Production site Preparatory restore for DR ESX Hypervisor … NB Client
- 17. Required Use Cases • Unplanned and planned fail-over to the DR instance. – Planned: for maintenance or for testing. • Planned and unplanned (!!) fail-back. – Unplanned when the DR failover is aborted. • Recovery of lost files or folders back to the production instance. – This may include the entire disk/file system. – The backup software (NetBackup )provides this capability all by itself.
- 18. In Your World • What is the typical range for RPO and RTO in the DR solutions you build? • How do they vary across types or sizes of companies? • Other requirements you see that challenge the budget, your efficiency as designers or implementers, etc? • What is the % split between full DR and DP only solutions? Is it changing?
- 19. SECTION 3: OUR IMPLEMENTED SOLUTION
- 20. Our Demo Solution • A VM with a file system holding user data. • For demo purposes our objectives are tight. – RPO: 5 minutes: • I.e. scheduled updates every 2.5 minutes. – RTO: 5 minutes: • Total time recovery time. Includes the time to make the fail-over decision and the time required to start DR instance once decision to fail over has been made.
- 22. SECTION 4: SERVICE OR DATA LOSS: FAIL-OVER
- 23. Ready, Set, Fail • Kill the disk or VM • Verify service is dead • Show solution or site diagram with big red mark on failed component
- 24. NetBackup Backup Host and Media Server V M V M V M LUN LUN Standby servers, storage Production Site: DR/DP Site: VM1 VM2 LUN FS LUN LUN VM n LUN NB client Backup to Archive Preparatory restore for DR NB Agent ESX Hypervisor ESX Hypervisor VM i …… NB Media Svr FS FS client FS
- 25. Fail-Over: Should/shouldn’t • If you fail over you WILL lose some data. • If you can resume in less than RPO time, net win! • If you can wait it out for some time, a bit beyond the RTO, low risk and convenience. • Otherwise we’ll push the button and start the fail-over work flow
- 26. NetBackup Backup Host and Media Server V M V M V M LUN LUN Standby servers, storage Production Site: DR/DP Site: VM1 VM2 LUN FS LUN LUN VM n LUN NB client Backup to Archive Prep. restore for DR NB Agent ESX Hypervisor ESX Hypervisor VM i …… NB Media Svr FS FS client FS Failing Over, UC-DR-2:
- 27. Work Flow for UC-DR-2: 1. Shut down any remaining production side VMs that are part of the application. – This prevents data corruption and network configuration errors. 2. In parallel with step 3, begin performing any required network reconfiguration required for all clients to reach the DR solution instance. Save the last step that enables client access. 3. Start the DR instances of the component applications in the prescribed order to bring the business application on-line. Verify data/operational integrity. 4. Perform the last network configuration steps to allow clients to connect to the DR instance of the application.
- 28. Work Flow Verification • Verify with PC that we have completed the fail-over. – Connect to DR instance with PC • Verify that we did lose some data, changes that occurred after the last complete update.
- 29. SECTION 5: REPAIR, PLANNED FAIL-BACK
- 30. The Fail-Back Decision • Have we repaired the production instance? • Have we tested the new production instance? • What is the optimal time for a planned fail- back? – Does the organization have a time period that is more convenient for application shutdown?
- 31. NetBackup Backup Host and Media Server V M V M V M LUN LUN Standby servers, storage Production Site: DR/DP Site: VM1 VM2 LUN FS LUN LUN VM n LUN NB client Backup to Archive Preparatory restore for DR NB Agent ESX Hypervisor ESX Hypervisor VM i …… NB Media Svr FS FS client FS
- 32. Planned Fail-Back: UC-DR-5 1. Shut down the DR instance of the application, running at the DR site. 2. Start reconfiguring the network an all other infrastructure components for steering clients to the production site instance of the application. Note that for steps 3 and 4, which are described below, they can be carried out in parallel with this step. 3. Perform the last NetBackup backup cycle for the LUNs in the DR site to the backup archive. 4. Perform a restore from the backup archive to the LUNs in the production site. 5. When steps 2 - 4 have all completed, start up the restored production instance of the application. Clients will now have full service. 6. Restart NetBackup protection of the production isntance to the backup archive at the DR site.
- 33. Verify restored service .. • Verify that the new production instance is accessible: – Connect to the repaired VM/FS/LUN and verify that service from the production instance have been restored. • Verify that all data set changes made at the DR instance has been transferred to the production instance.
- 34. Discussion Topics • How can we shorten the application downtime? – Iterative recovery: (Level 0 +) Incremental “backups” to the repaired instance shortens the last update. – Large data set, limited WAN bandwidth: Out-of- band restore. • Testing the new instance: – Start it up and access data using the next to last incremental above.
- 35. SECTION 6: DISCUSSION AND ANALYSIS OF THE SOLUTION AND THE BLUE PRINT
- 36. Blue Prints: Why A Better Result • Using tested architectural principles and building blocks that are common to many solutions. • The solution is based on a well proven architecture. • The building blocks have been “road tested” with other solutions and customers. • The same BP enables easier integration across new applications: – Easy to protect new applications by simply expanding the existing DR solution • The resulting solution is easily integrated into the management framework.
- 37. Blue Prints: Efficiency! • Starting out with an 80% complete design, and a well understood set of building blocks. • The same BP enables easier integration across new applications: – Easy to protect new applications by simply expanding the existing DR solution • Adaptation of the blue print to the customers’ specific environments and requirements are guided by the questions in the questionnaire – These variations do not break with the blue print, the principles are still intact • Scalability is built in at the application, solution and infrastructure level.
- 38. Meeting The Requirements? • Does the solution meet our requirements? • How many (%) of the DR solutions you have built or managed have tighter requirements? – Or looser requirements? – Should any of that be reflected in the blue print?
- 39. Improving the Solution • What questions do we ask, what data do we collect, what experience do we need to take this solution to the next iteration?
- 40. Improvements, Savings • How can we improve the solution for the customer? – Can critical applications (customer db, ..) run on a different schedule than the common set (email, home dir)? – How much to pay for the next amount of WAN bw? • How can we save $$s for the customer? – Reducing the DR foot print?
- 41. Q&A
- 42. NetBackup Backup Host and Media Server V M V M V M LUN LUN Standby servers, storage Production Site: DR/DP Site: VM1 VM2 LUN FS LUN LUN VM n LUN NB client Backup to Archive Preparatory restore for DR NB Agent ESX Hypervisor ESX Hypervisor VM i …… NB Media Svr FS FS client FS