Review: Scalable Semantic Web Data Management Using Vertical Partitioning
ŌĆóDownload as PPTX, PDFŌĆó
1 likeŌĆó720 views

Part of the Semantic Web, Ontologies and the Cloud class at The University of Texas at Austin's Computer Science department during Spring 2010 term





















Review: Scalable Semantic Web Data Management Using Vertical Partitioning
- 1. Abadi, Marcus, Madden, Hollenbach VLDB 2007 Presented by: {Gui}llermo Cabrera The University of Texas at Austin
- 2. ’üĮ Problem ’üĮ Storage Goal ’üĮ RDBMS use ’üĮ RDF Physical Organization ’üĮ Column store vs. Row Store ’üĮ Materialized Path Expressions ’üĮ Experiment & Results ’üĮ Discussion
- 3. ’üĮ Performance: Self-joins ’üĮ Many triples
- 4. ’üĮ Achieve scalability & performance in triple storage ’üĮ Survey approaches in RDBMS ’üĮ Benefits of vertical partition and column store
- 5. ’üĮ 1 table with 3 indexed columns? ’üĮ Multi layer architecture ŌŚ” Translate -> Optimize -> Execute ’üĮ Mapping tables for long URI and literals ’üĮ Jena, Oracle, Sesame, 3store (Hyunjun), Hexastore (Donghyuk)
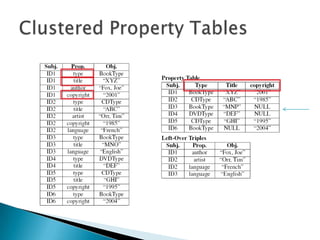
- 6. ’üĮ Property tables ŌŚ” Clustered property table ’é¢ Denormalize RDF (wider tables) ’é¢ Clustering algorithm ’é¢ NULL values
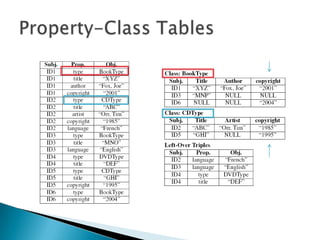
- 8. ’üĮ Property tables ŌŚ” Property-Class Tables ’é¢ Exploit the type property ’é¢ Properties may exist in multiple tables
- 10. ’üĮ Advantage: ŌŚ” Fewer joins ’üĮ Disadvantage: ŌŚ” NULL values ŌŚ” Multivalued attributes are complicated
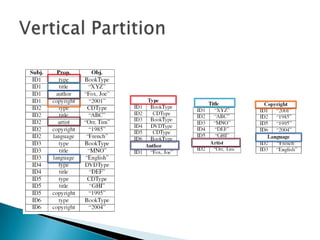
- 11. ’üĮ Vertical Partition ŌŚ” n two-column tables, n = # of unique properties ŌŚ” Table sorted by subject ’é¢ Merge join
- 13. ŌĆó Advantage ’é¢ Multi valued attributes supported ’é¢ No clustering algorithm (Property tables) ’é¢ Only accessed properties are read ŌĆó Disadvantage ’é¢ Use of multiple properties (table joins) ’é¢ Inserts expensive
- 14. ’üĮ Triple Store ’üĮ Property Table ’üĮ Vertical Partition (Row Store) ’üĮ Vertical Partition Store (Column Store)
- 15. ’üĮ Why? ’üĮ Projection is free ’üĮ Tuple headers (metadata on row) ŌŚ” 35 bytes in Postgres vs. 8 bytes in C-Store ’üĮ Column oriented compression ŌŚ” Run-length encoding (ex. 1,1,1,2,2 ’āĀ 1x3, 2x2) ’üĮ Optimized merge join ŌŚ” Prefetching
- 16. <BookID1, Author, http://preamble/FoxJoe> <http://preamble/FoxJoe,wasBorn, ŌĆ£1860ŌĆØ> Find all books whose authors were born in 1860
- 18. ’üĮ Barton Libraries Dataset ’üĮ Longwell Queries ŌŚ” Calculating counts ŌŚ” Filtering ŌŚ” Inference
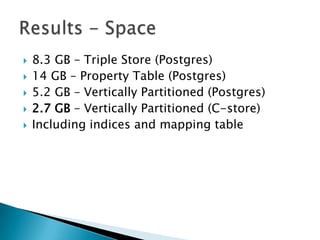
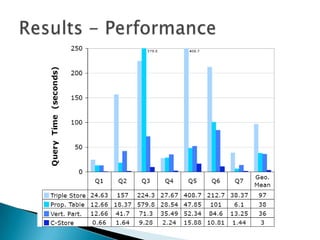
- 19. ’üĮ 8.3 GB ŌĆō Triple Store (Postgres) ’üĮ 14 GB ŌĆō Property Table (Postgres) ’üĮ 5.2 GB ŌĆō Vertically Partitioned (Postgres) ’üĮ 2.7 GB ŌĆō Vertically Partitioned (C-store) ’üĮ Including indices and mapping table
- 23. ’üĮ Replace ŌŚ” subject-object joins ’āĀ subject-subject joins
- 24. ’üĮ Add 60 integer valued columns ’üĮ 7 GB increase in size
- 25. ’üĮ Great for reads, writes not considered ’üĮ What about load times? ’üĮ Using another benchmark (ex. LUBM)? ’üĮ Native XML databases for RDF/XML? ’üĮ Test triple store in Sesame
Editor's Notes
- RDF as series of triples SPOPerformance: Self-joins, Low speed (# triples > memory)Need to manage large number of triplesBillion Triple Challenge (semanticweb.org)
- Self joins become PROBLEMATIC when the LESS selective the predicates.Mapping table ŌĆō 1 clustered (identifiers) and 1 unclsutered index
- Jena2 were first to proposeBasic idea is to cluster properties that tend to be DEFINED together (type title and copyrithg date). Also, LEFT OVER TriplesWhy fewer joins? Self joins on the subject column can be eliminated.Tradeoff ŌĆō narrow tables = less sparse = more tables used; wide table = more space = less joins.
- Property may exist in MLTIPLE property class tables Good for reified statements.
- Exploit Type propertyReified statements
- Object Relational ŌĆō Bag structure
- Tuple header dominates size of actual data resulting in table
- Multi-valued subjects as multiple rowsNo clustering algorithm
- Postgres has 27 byte tuple header, compare 8 byes to 35 bytesMerge join uses prefetching to avoid seeks between columns.
- Why? Row store to much overhead on vertical partition
- For VP not merge joins.PRECALCULATe these expressions, as 2-column tableGood: inference queries (of form x party of y, y part of z, then x part of z)Bad: many tables
- Convert from RDF/XML to triples using REDLAND50 million triples, 221 unique properties, multivalued
- Average of 3 runs of the queries.VP and PT factor of 2-3 faster than triple store.C-store is 32 times faster than triple storeQ1: PT and VP identical because use of idealized property tables.Q2: Avoids subject-subject joinsQ3: multiple sequential scans.Q4: High selectivityQ5:
- Involves all triples of property TYPE and count of object valuesNo join for Triple storePT and VP have same schema. {Type: subject, object}
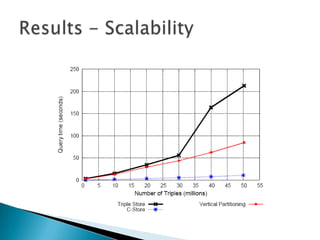
- 1 million to 50 million, run only query 6. linearly except triple storeall joins for this query are linear for vertical partitioningtriple-store sorts the intermediate results after performing the three selections and before performing the merge join
- For PT, add new column with MPEFor VP, add add table containing, subject column and a Records:Type object column.
- What is purpose of test???
- LUBM, universities, departments, students etc.15 MILLION triples
- Display list of PROPERTIES defined for resources of "Type -> Text"Multiple sequential scans