SciKit Learn: How to Standardize Your Data
Download as pptx, pdf1 like400 views

The document discusses standardizing data as a preprocessing step for machine learning models. It defines standardization as shifting attribute distributions to have a mean of 0 and standard deviation of 1. Standardization is important because some models require normalized data distributions and can behave badly without it. The document provides a Python code recipe using Scikit-Learn to load the Iris dataset, separate features from targets, and standardize the features.
1 of 15
Download to read offline









Ad
Recommended
Redux data flow with angular
Redux data flow with angularGil Fink
?
This document discusses using Redux for data flow in Angular applications. Redux is a pattern that uses a single state tree and pure reducer functions to update state in response to actions. It advocates for single sources of truth, immutable state, and changes through pure functions. The ng2-redux library allows integrating Redux with Angular by providing the store via dependency injection and dispatching actions. Components can select state slices and dispatch actions to update state.Data Quality Everywhere
Data Quality EverywhereJean-Michel Franco
?
The document outlines Talend's data quality solutions and their integration into business processes, emphasizing the importance of real-time data quality for improved operational efficiency and customer experience. Talend offers a unified platform that supports data standardization, monitoring, and cleansing, enhancing data accuracy across various applications. Key benefits include reduced product introduction costs, better customer engagement, and compliance through embedded data quality controls.Oracle Ucm General Presentation Linked In
Oracle Ucm General Presentation Linked InJan Echarlod
?
The document provides an overview of Oracle Master Data Management (MDM) solutions. It discusses Oracle MDM's customer base of over 400 customers and 2 billion records mastered. It also outlines Oracle MDM's data cleansing, matching, linking, and publishing capabilities. Key benefits of Oracle MDM include a common customer view, customer intelligence and segmentation, and improved customer experience across channels.Crm strategy of call centre
Crm strategy of call centresouravpati
?
Customer Relationship Management (CRM) is a strategy and process to build relationships with valuable customers through acquiring, retaining, and partnering with them. CRM uses technology to integrate customer data across departments to increase profits and productivity. It puts customers at the core of a company's processes. Call centers have benefited from CRM by using customer data collected from calls to provide better customer service and increase customer satisfaction. CRM software allows call centers to store valuable customer information that representatives can access to handle calls more efficiently with shorter call times and improved customer understanding. This leads to increased productivity and customer loyalty for call centers.Scikit Learn: Data Normalization Techniques That Work
Scikit Learn: Data Normalization Techniques That WorkDamian R. Mingle, MBA
?
The document emphasizes the importance of normalizing data in machine learning to improve model accuracy and runtime. It explains normalization as the process of scaling data to a common scale and highlights its impact on various models. Additionally, it provides a normalization recipe using the Iris dataset and mentions resources like scikit-learn.Feature Scaling and Normalization Feature Scaling and Normalization.pptx
Feature Scaling and Normalization Feature Scaling and Normalization.pptxNishant83346
?
Feature scaling is a crucial preprocessing step in machine learning that standardizes independent features within a fixed range to improve model performance. Key techniques include standardization (zero mean and unit variance) and normalization (min-max scaling), with the choice depending on algorithm requirements and feature characteristics. Algorithms sensitive to feature magnitudes, such as k-nearest neighbors and PCA, particularly benefit from scaling, while tree-based models and certain algorithms like Naive Bayes are less affected.Data Preprocessing
Data PreprocessingzekeLabs Technologies
?
This document discusses data preprocessing techniques for machine learning. It covers common preprocessing steps like normalization, encoding categorical features, and handling outliers. Normalization techniques like StandardScaler, MinMaxScaler and RobustScaler are described. Label encoding and one-hot encoding are covered for processing categorical variables. The document also discusses polynomial features, custom transformations, and preprocessing text and image data. The goal of preprocessing is to prepare data so it can be better consumed by machine learning algorithms.Data Transformation ¨C Standardization & Normalization PPM.pptx
Data Transformation ¨C Standardization & Normalization PPM.pptxssuser5cdaa93
?
The document discusses data transformation techniques, specifically focusing on standardization and normalization, which are crucial for feature scaling in machine learning. It outlines the differences between these methods, their appropriate applications, and their impacts on datasets with varying scales, particularly emphasizing the importance of scaling in distance-based models. Standardization is noted for being more robust to outliers, while normalization is easier to apply but less effective in their presence.Data Preprocessing:Feature scaling methods
Data Preprocessing:Feature scaling methodssonali sonavane
?
The document discusses feature scaling, an important data preprocessing step that normalizes independent variables to improve algorithm performance and prevent dominant features during calculations. It outlines various techniques such as min-max scaling, normalization, and standardization, providing code examples for their implementation. The significance of feature scaling is emphasized in algorithms that utilize Euclidean distance measures, particularly in k-means, k-nearest neighbors, PCA, and gradient descent.Preparing your data for Machine Learning with Feature Scaling
Preparing your data for Machine Learning with Feature ScalingRahul K Chauhan
?
Feature scaling, including standardization and normalization, is crucial for ensuring that independent variables have a uniform scale, which is essential for machine learning algorithms that rely on distance calculations. Standardization rescales values to have a mean of 0 and a standard deviation of 1, while normalization adjusts attributes to a range of 0 to 1. Different algorithms have varying requirements for scaling techniques, with standardization preferred for linear regression and normalization for methods like SVM and k-nearest neighbors.Machine learning session 5
Machine learning session 5NirsandhG
?
The document discusses the importance of data preparation in machine learning, emphasizing that the quality and format of data are crucial for effective model training. It outlines various data preprocessing techniques such as scaling, normalization, binarization, standardization, and label encoding, which are essential for transforming raw data into a suitable format for algorithms. Techniques provided include specific classes in the scikit-learn library for each preprocessing method, along with examples using the Pima Indians diabetes dataset.Pandas Data Cleaning and Preprocessing PPT.pptx
Pandas Data Cleaning and Preprocessing PPT.pptxbajajrishabh96tech
?
The document outlines data cleaning and preprocessing techniques using pandas, detailing processes such as handling missing values, removing duplicates, dealing with outliers, and feature scaling. It emphasizes the importance of high-quality data for reliable insights, better decision-making, and avoiding bias in analytical models. Key steps in data preprocessing, including transforming raw data and encoding categorical variables, are also discussed, along with machine learning applications.Introduction to ML_Data Preprocessing.pptx
Introduction to ML_Data Preprocessing.pptxmousmiin
?
The document provides an overview of machine learning and data preprocessing techniques essential for preparing data before applying machine learning models. It details steps involved in data preprocessing such as importing libraries, loading datasets, performing statistical analysis, checking for outliers, and normalizing or standardizing data. Key concepts include the significance of data formatting for model execution and the use of specific algorithms to manage null values and format datasets appropriately.The model interacts with the environment seeking ways to maximize the reward....
The model interacts with the environment seeking ways to maximize the reward....petershicaramirez
?
Resumen sobre machine learningPreparing Data
Preparing DataEng Teong Cheah
?
The document outlines strategies for data preprocessing, focusing on handling incomplete datasets by cleaning, normalizing, and grouping data to enhance model training. It emphasizes the importance of addressing missing values thoughtfully to avoid skewing results, and discusses techniques like SMOTE for managing imbalanced data. Additionally, it presents options for binning data and categorizing values to improve data organization for machine learning applications.Introduction to Artificial Intelligence_ Lec 5
Introduction to Artificial Intelligence_ Lec 5Dalal2Ali
?
Introduction to Artificial Intelligence_ Lec 5Feature Scaling with R.pdf
Feature Scaling with R.pdfShakiruBankole2
?
Feature scaling is a technique used in machine learning to standardize the range of independent variables or features of data. There are several common feature scaling methods including standardization, min-max scaling, and mean normalization. Standardization transforms the data to have a mean of 0 and standard deviation of 1. Min-max scaling scales features between 0 and 1. Mean normalization scales the mean value to zero. The document then provides the formulas and R code examples for implementing each of these scaling methods.Data preprocessing in Machine learning
Data preprocessing in Machine learning pyingkodi maran
?
Data preprocessing is the process of preparing raw data for analysis by cleaning it, transforming it, and reducing it. The key steps in data preprocessing include data cleaning to handle missing values, outliers, and noise; data transformation techniques like normalization, discretization, and feature extraction; and data reduction methods like dimensionality reduction and sampling. Preprocessing ensures the data is consistent, accurate and suitable for building machine learning models.Data_Preparation.pptx
Data_Preparation.pptxImXaib
?
This document discusses data preparation, which is an important step in the knowledge discovery process. It covers topics such as outliers, missing data, data transformation, and data types. The goal of data preparation is to transform raw data into a format that will best expose useful information and relationships to data mining algorithms. It aims to reduce errors and produce better and faster models. Common tasks involve data cleaning, discretization, integration, reduction and normalization.ML-Unit-4.pdf
ML-Unit-4.pdfAnushaSharma81
?
This document discusses feature engineering, which is the process of transforming raw data into features that better represent the underlying problem for predictive models. It covers feature engineering categories like feature selection, feature transformation, and feature extraction. Specific techniques covered include imputation, handling outliers, binning, log transforms, scaling, and feature subset selection methods like filter, wrapper, and embedded methods. The goal of feature engineering is to improve machine learning model performance by preparing proper input data compatible with algorithm requirements.13_Data Preprocessing in Python.pptx (1).pdf
13_Data Preprocessing in Python.pptx (1).pdfandreyhapantenda
?
The document outlines a comprehensive guide on data preprocessing using Python for machine learning, detailing key steps such as dataset acquisition, library importation, and handling missing values. It emphasizes the importance of encoding categorical data, dataset splitting, and feature scaling, providing specific methods and solutions for each step. Additionally, it highlights the critical role of feature scaling in algorithms that rely on distance calculations and contrasts normalization with standardization techniques.Machine Learning - Dataset Preparation
Machine Learning - Dataset PreparationAndrew Ferlitsch
?
The document outlines the steps necessary for preparing a machine learning dataset, including importing, cleaning, handling missing values, categorical conversion, and feature scaling. Key practices such as data wrangling and encoding categorical variables with techniques like one-hot encoding and normalization are discussed. The importance of maintaining consistent numerical scales among features to avoid skewing model training is emphasized.Ijsws14 423 (1)-paper-17-normalization of data in (1)
Ijsws14 423 (1)-paper-17-normalization of data in (1)Raghavendra Pokuri
?
The document discusses the process and significance of data normalization in data mining, highlighting its role in optimizing resource utilization and decision-making across industries. It details various normalization techniques, including min-max normalization, z-score normalization, and decimal scaling, and their applications in machine learning and data analysis. The conclusion emphasizes the importance of normalization in enhancing database integrity and predictive analytics.Human breastcancer
Human breastcancerSAIRATHAN VENTRAPRAGADA
?
The document discusses analyzing the human breast cancer dataset. The dataset contains features like radius_mean and smoothness_mean to predict if a tumor is malignant or benign. Good models on this dataset can achieve 98% accuracy. Key steps in analyzing the dataset include data cleaning by handling null values and normalizing features, which takes 70% of the time. Different models are fit to the cleaned data and evaluated using metrics like accuracy, precision, and recall to select the best performing model and compare models. Developing a good model on this dataset can help pave a career in machine learning.Feature scaling
Feature scalingGautam Kumar
?
The document explains feature scaling, a process used to standardize independent features within a fixed range to improve performance in data analysis. It discusses various scaling techniques such as min-max normalization, standardization, and robust scaling, as well as when scaling is essential for algorithms like K-Nearest Neighbors and Principal Component Analysis. Feature scaling is crucial in preprocessing to normalize data and enhance algorithm efficiency, especially when dealing with features that vary significantly in magnitude.TDC2017 | S?o Paulo - Trilha Java EE How we figured out we had a SRE team at ...
TDC2017 | S?o Paulo - Trilha Java EE How we figured out we had a SRE team at ...tdc-globalcode
?
This document discusses various techniques for feature engineering raw data to improve machine learning model performance. It describes transforming data through techniques like handling missing values, aggregation, binning, encoding categorical features, and feature selection. The goal of feature engineering is to represent the underlying problem to models in a way that results in better accuracy on new data.overview of_data_processing
overview of_data_processingFEG
?
The document provides an overview of key concepts in data preprocessing including data cleaning, feature transformation, standardization and normalization. It discusses techniques such as handling missing values, binning noisy data, dimensionality reduction, discretizing continuous features, and different scaling methods like standardization, min-max scaling and robust scaling. Code examples are provided to demonstrate these preprocessing techniques on various datasets. Homework includes explaining z-score standardization and dimensionality reduction, and preprocessing the Titanic dataset through cleaning, standardization and normalization.Classify Rice Disease Using Self-Optimizing Models and Edge Computing with A...
Classify Rice Disease Using Self-Optimizing Models and Edge Computing with A...Damian R. Mingle, MBA
?
This document summarizes research on classifying rice diseases using self-optimizing machine learning models and edge computing. The researchers used an automated machine learning platform to build models for identifying 3 classes of rice diseases from images. They extracted features from the images using a deep learning network and then used those features to train traditional machine learning models like ExtraTrees Classifier and Stochastic Gradient Descent. The goal was to develop an end-to-end solution for rice farmers to easily and accurately detect diseases in the field and receive treatment recommendations in real-time.Predicting Diabetic Readmission Rates: Moving Beyond HbA1c
Predicting Diabetic Readmission Rates: Moving Beyond HbA1cDamian R. Mingle, MBA
?
The study explores using advanced machine learning techniques to predict 30-day hospital readmission rates for diabetic patients, aiming to improve accuracy over existing methods like the LACE score. By analyzing a dataset of over 100,000 admissions with 56 features, the researchers found that incorporating diverse clinical data can enhance risk assessments and potentially reduce healthcare costs. This research provides a foundational model to identify high-risk patients and improve inpatient diabetes care.More Related Content
Similar to SciKit Learn: How to Standardize Your Data (20)
Data Preprocessing:Feature scaling methods
Data Preprocessing:Feature scaling methodssonali sonavane
?
The document discusses feature scaling, an important data preprocessing step that normalizes independent variables to improve algorithm performance and prevent dominant features during calculations. It outlines various techniques such as min-max scaling, normalization, and standardization, providing code examples for their implementation. The significance of feature scaling is emphasized in algorithms that utilize Euclidean distance measures, particularly in k-means, k-nearest neighbors, PCA, and gradient descent.Preparing your data for Machine Learning with Feature Scaling
Preparing your data for Machine Learning with Feature ScalingRahul K Chauhan
?
Feature scaling, including standardization and normalization, is crucial for ensuring that independent variables have a uniform scale, which is essential for machine learning algorithms that rely on distance calculations. Standardization rescales values to have a mean of 0 and a standard deviation of 1, while normalization adjusts attributes to a range of 0 to 1. Different algorithms have varying requirements for scaling techniques, with standardization preferred for linear regression and normalization for methods like SVM and k-nearest neighbors.Machine learning session 5
Machine learning session 5NirsandhG
?
The document discusses the importance of data preparation in machine learning, emphasizing that the quality and format of data are crucial for effective model training. It outlines various data preprocessing techniques such as scaling, normalization, binarization, standardization, and label encoding, which are essential for transforming raw data into a suitable format for algorithms. Techniques provided include specific classes in the scikit-learn library for each preprocessing method, along with examples using the Pima Indians diabetes dataset.Pandas Data Cleaning and Preprocessing PPT.pptx
Pandas Data Cleaning and Preprocessing PPT.pptxbajajrishabh96tech
?
The document outlines data cleaning and preprocessing techniques using pandas, detailing processes such as handling missing values, removing duplicates, dealing with outliers, and feature scaling. It emphasizes the importance of high-quality data for reliable insights, better decision-making, and avoiding bias in analytical models. Key steps in data preprocessing, including transforming raw data and encoding categorical variables, are also discussed, along with machine learning applications.Introduction to ML_Data Preprocessing.pptx
Introduction to ML_Data Preprocessing.pptxmousmiin
?
The document provides an overview of machine learning and data preprocessing techniques essential for preparing data before applying machine learning models. It details steps involved in data preprocessing such as importing libraries, loading datasets, performing statistical analysis, checking for outliers, and normalizing or standardizing data. Key concepts include the significance of data formatting for model execution and the use of specific algorithms to manage null values and format datasets appropriately.The model interacts with the environment seeking ways to maximize the reward....
The model interacts with the environment seeking ways to maximize the reward....petershicaramirez
?
Resumen sobre machine learningPreparing Data
Preparing DataEng Teong Cheah
?
The document outlines strategies for data preprocessing, focusing on handling incomplete datasets by cleaning, normalizing, and grouping data to enhance model training. It emphasizes the importance of addressing missing values thoughtfully to avoid skewing results, and discusses techniques like SMOTE for managing imbalanced data. Additionally, it presents options for binning data and categorizing values to improve data organization for machine learning applications.Introduction to Artificial Intelligence_ Lec 5
Introduction to Artificial Intelligence_ Lec 5Dalal2Ali
?
Introduction to Artificial Intelligence_ Lec 5Feature Scaling with R.pdf
Feature Scaling with R.pdfShakiruBankole2
?
Feature scaling is a technique used in machine learning to standardize the range of independent variables or features of data. There are several common feature scaling methods including standardization, min-max scaling, and mean normalization. Standardization transforms the data to have a mean of 0 and standard deviation of 1. Min-max scaling scales features between 0 and 1. Mean normalization scales the mean value to zero. The document then provides the formulas and R code examples for implementing each of these scaling methods.Data preprocessing in Machine learning
Data preprocessing in Machine learning pyingkodi maran
?
Data preprocessing is the process of preparing raw data for analysis by cleaning it, transforming it, and reducing it. The key steps in data preprocessing include data cleaning to handle missing values, outliers, and noise; data transformation techniques like normalization, discretization, and feature extraction; and data reduction methods like dimensionality reduction and sampling. Preprocessing ensures the data is consistent, accurate and suitable for building machine learning models.Data_Preparation.pptx
Data_Preparation.pptxImXaib
?
This document discusses data preparation, which is an important step in the knowledge discovery process. It covers topics such as outliers, missing data, data transformation, and data types. The goal of data preparation is to transform raw data into a format that will best expose useful information and relationships to data mining algorithms. It aims to reduce errors and produce better and faster models. Common tasks involve data cleaning, discretization, integration, reduction and normalization.ML-Unit-4.pdf
ML-Unit-4.pdfAnushaSharma81
?
This document discusses feature engineering, which is the process of transforming raw data into features that better represent the underlying problem for predictive models. It covers feature engineering categories like feature selection, feature transformation, and feature extraction. Specific techniques covered include imputation, handling outliers, binning, log transforms, scaling, and feature subset selection methods like filter, wrapper, and embedded methods. The goal of feature engineering is to improve machine learning model performance by preparing proper input data compatible with algorithm requirements.13_Data Preprocessing in Python.pptx (1).pdf
13_Data Preprocessing in Python.pptx (1).pdfandreyhapantenda
?
The document outlines a comprehensive guide on data preprocessing using Python for machine learning, detailing key steps such as dataset acquisition, library importation, and handling missing values. It emphasizes the importance of encoding categorical data, dataset splitting, and feature scaling, providing specific methods and solutions for each step. Additionally, it highlights the critical role of feature scaling in algorithms that rely on distance calculations and contrasts normalization with standardization techniques.Machine Learning - Dataset Preparation
Machine Learning - Dataset PreparationAndrew Ferlitsch
?
The document outlines the steps necessary for preparing a machine learning dataset, including importing, cleaning, handling missing values, categorical conversion, and feature scaling. Key practices such as data wrangling and encoding categorical variables with techniques like one-hot encoding and normalization are discussed. The importance of maintaining consistent numerical scales among features to avoid skewing model training is emphasized.Ijsws14 423 (1)-paper-17-normalization of data in (1)
Ijsws14 423 (1)-paper-17-normalization of data in (1)Raghavendra Pokuri
?
The document discusses the process and significance of data normalization in data mining, highlighting its role in optimizing resource utilization and decision-making across industries. It details various normalization techniques, including min-max normalization, z-score normalization, and decimal scaling, and their applications in machine learning and data analysis. The conclusion emphasizes the importance of normalization in enhancing database integrity and predictive analytics.Human breastcancer
Human breastcancerSAIRATHAN VENTRAPRAGADA
?
The document discusses analyzing the human breast cancer dataset. The dataset contains features like radius_mean and smoothness_mean to predict if a tumor is malignant or benign. Good models on this dataset can achieve 98% accuracy. Key steps in analyzing the dataset include data cleaning by handling null values and normalizing features, which takes 70% of the time. Different models are fit to the cleaned data and evaluated using metrics like accuracy, precision, and recall to select the best performing model and compare models. Developing a good model on this dataset can help pave a career in machine learning.Feature scaling
Feature scalingGautam Kumar
?
The document explains feature scaling, a process used to standardize independent features within a fixed range to improve performance in data analysis. It discusses various scaling techniques such as min-max normalization, standardization, and robust scaling, as well as when scaling is essential for algorithms like K-Nearest Neighbors and Principal Component Analysis. Feature scaling is crucial in preprocessing to normalize data and enhance algorithm efficiency, especially when dealing with features that vary significantly in magnitude.TDC2017 | S?o Paulo - Trilha Java EE How we figured out we had a SRE team at ...
TDC2017 | S?o Paulo - Trilha Java EE How we figured out we had a SRE team at ...tdc-globalcode
?
This document discusses various techniques for feature engineering raw data to improve machine learning model performance. It describes transforming data through techniques like handling missing values, aggregation, binning, encoding categorical features, and feature selection. The goal of feature engineering is to represent the underlying problem to models in a way that results in better accuracy on new data.overview of_data_processing
overview of_data_processingFEG
?
The document provides an overview of key concepts in data preprocessing including data cleaning, feature transformation, standardization and normalization. It discusses techniques such as handling missing values, binning noisy data, dimensionality reduction, discretizing continuous features, and different scaling methods like standardization, min-max scaling and robust scaling. Code examples are provided to demonstrate these preprocessing techniques on various datasets. Homework includes explaining z-score standardization and dimensionality reduction, and preprocessing the Titanic dataset through cleaning, standardization and normalization.More from Damian R. Mingle, MBA (12)
Classify Rice Disease Using Self-Optimizing Models and Edge Computing with A...
Classify Rice Disease Using Self-Optimizing Models and Edge Computing with A...Damian R. Mingle, MBA
?
This document summarizes research on classifying rice diseases using self-optimizing machine learning models and edge computing. The researchers used an automated machine learning platform to build models for identifying 3 classes of rice diseases from images. They extracted features from the images using a deep learning network and then used those features to train traditional machine learning models like ExtraTrees Classifier and Stochastic Gradient Descent. The goal was to develop an end-to-end solution for rice farmers to easily and accurately detect diseases in the field and receive treatment recommendations in real-time.Predicting Diabetic Readmission Rates: Moving Beyond HbA1c
Predicting Diabetic Readmission Rates: Moving Beyond HbA1cDamian R. Mingle, MBA
?
The study explores using advanced machine learning techniques to predict 30-day hospital readmission rates for diabetic patients, aiming to improve accuracy over existing methods like the LACE score. By analyzing a dataset of over 100,000 admissions with 56 features, the researchers found that incorporating diverse clinical data can enhance risk assessments and potentially reduce healthcare costs. This research provides a foundational model to identify high-risk patients and improve inpatient diabetes care.Greek Letters with LaTeX Cheat Sheet
Greek Letters with LaTeX Cheat SheetDamian R. Mingle, MBA
?
The document provides a list of Greek letters along with their LaTeX representations. It is authored by Damian Mingle and is sponsored by the Society of Data Scientists. The content focuses on the usage of Greek letters in LaTeX typesetting.Clustering: A Scikit Learn Tutorial
Clustering: A Scikit Learn TutorialDamian R. Mingle, MBA
?
This document provides an overview of k-means clustering, a method of unsupervised learning used to group data by measuring distances between data points. The tutorial covers how to implement k-means in the Python library scikit-learn, including parameters for setting clusters and optimizing results. It discusses the advantages and disadvantages of k-means, conditions for its use, and techniques for determining the optimal number of clusters.Scikit Learn: How to Deal with Missing Values
Scikit Learn: How to Deal with Missing ValuesDamian R. Mingle, MBA
?
The document discusses imputing missing data in machine learning models. It explains that some machine learning algorithms have issues handling missing values, so filling in missing data can improve results. Common imputation methods like mean, median or frequent imputation replace missing values with aggregate statistics rather than discarding samples containing any missing values. While imputing may improve predictions, cross-validation is recommended to verify the effects. In some cases, dropping rows or using marker values for missing data can work better than imputation. The document provides an example Python code recipe using scikit-learn to impute missing values in a dataset with the mean value.What is sepsis?
What is sepsis?Damian R. Mingle, MBA
?
The document discusses sepsis, highlighting its high treatment costs, mortality rates, and evolving definitions over time, notably through the sepsis-1, sepsis-2, and sepsis-3 frameworks. It emphasizes the challenges in diagnosing and treating sepsis, including the absence of standardized diagnostic tests, and presents the qSOFA scoring tool for identifying high-risk patients. Additionally, it raises concerns about the recent sepsis-3 criteria and the reliance on data science solutions for better monitoring and treatment in hospitals.Controlling informative features for improved accuracy and faster predictions...
Controlling informative features for improved accuracy and faster predictions...Damian R. Mingle, MBA
?
The research article discusses a novel machine-learning framework, Rip Curl, designed to improve the accuracy and speed of predicting phenotypic outcomes in omentum cancer models. By applying feature detection and engineering, the framework ranks informative features, ultimately leading to a more effective classification model that outperforms established methods. The study demonstrates significant advancements in prediction accuracy and computational efficiency using this framework on microarray datasets.The evolving definition of sepsis
The evolving definition of sepsis Damian R. Mingle, MBA
?
The document discusses the evolving definition of sepsis, a life-threatening condition resulting from a dysregulated immune response to infection that affects millions and has high treatment costs. It outlines historical perspectives, notably the changes leading to the current sepsis-3 definition established in 2016, which emphasizes organ dysfunction due to infection. The paper emphasizes the need for improved early detection and treatment strategies to reduce sepsis-related deaths and healthcare costs.Data and the Changing Role of the Tech Savvy CFO
Data and the Changing Role of the Tech Savvy CFODamian R. Mingle, MBA
?
The document discusses the evolving role of the CFO in leveraging big data and advanced analytics across various industries. It emphasizes the need for CFOs to utilize technology for improved financial management, strategic planning, and enhanced operational efficiency. Key strategies include incorporating additional data sources, advancing data visualization techniques, and understanding customer behavior to drive growth and innovation.A discriminative-feature-space-for-detecting-and-recognizing-pathologies-of-t...
A discriminative-feature-space-for-detecting-and-recognizing-pathologies-of-t...Damian R. Mingle, MBA
?
The article discusses advanced machine learning techniques for diagnosing pathologies of the vertebral column, focusing on improving accuracy in detecting conditions such as disc hernias and spondylolisthesis. A comparative analysis of various algorithms is conducted, demonstrating that data-driven models enhance classification efficiency by minimizing errors and optimizing feature selection. The study highlights significant benefits for healthcare providers through a framework that aids in decision support for orthopedists.Practical Data Science the WPC Healthcare Strategy for Delivering Meaningful ...
Practical Data Science the WPC Healthcare Strategy for Delivering Meaningful ...Damian R. Mingle, MBA
?
The document discusses the challenges faced by data scientists in healthcare and advocates for the use of Jupyter for interactive computing and a structured data science methodology. It outlines a series of exercises to guide data scientists through the phases of a data science project, from understanding and preparing data to modeling, evaluating, and deploying results. Overall, it emphasizes the need for business understanding, collaboration, and a systematic approach to ensure successful project outcomes.A Multi-Pronged Approach to Data Mining Post-Acute Care Episodes
A Multi-Pronged Approach to Data Mining Post-Acute Care EpisodesDamian R. Mingle, MBA
?
This study discusses data mining in post-acute care to enhance care delivery through the Bundled Payments for Care Improvement initiative. It outlines the integration and analysis of data from various care episodes to aid financial, operational, and clinical decision-making. The findings highlight the need for technological adoption and data visualization to improve patient outcomes and support the transition to value-based care.Classify Rice Disease Using Self-Optimizing Models and Edge Computing with A...
Classify Rice Disease Using Self-Optimizing Models and Edge Computing with A...Damian R. Mingle, MBA
?
Controlling informative features for improved accuracy and faster predictions...
Controlling informative features for improved accuracy and faster predictions...Damian R. Mingle, MBA
?
A discriminative-feature-space-for-detecting-and-recognizing-pathologies-of-t...
A discriminative-feature-space-for-detecting-and-recognizing-pathologies-of-t...Damian R. Mingle, MBA
?
Practical Data Science the WPC Healthcare Strategy for Delivering Meaningful ...
Practical Data Science the WPC Healthcare Strategy for Delivering Meaningful ...Damian R. Mingle, MBA
?
Ad
Recently uploaded (20)
×îĐ°ćŇâ´óŔűĂ×ŔĽ´óѧ±Ďҵ֤Ł¨±«±·±ő˛Ń±ő±Ďҵ֤Ę飩԰涨ÖĆ
×îĐ°ćŇâ´óŔűĂ×ŔĽ´óѧ±Ďҵ֤Ł¨±«±·±ő˛Ń±ő±Ďҵ֤Ę飩԰涨ÖĆtaqyea
?
2025Ô°ćĂ×ŔĽ´óѧ±Ďҵ֤Ęépdfµç×Ӱ桾qޱ1954292140ˇżŇâ´óŔű±Ďҵ֤°ěŔíUNIMIĂ×ŔĽ´óѧ±Ďҵ֤Ęé¶ŕÉŮÇ®Łżˇľqޱ1954292140ˇżşŁÍâ¸÷´óѧDiploma°ć±ľŁ¬ŇňÎŞŇßÇéѧУÍƳٷ˘·ĹÖ¤Ę顢֤ĘéÔĽţ¶ŞĘ§˛ą°ěˇ˘Ă»ÓĐŐýłŁ±ĎҵδÄÜČĎ֤ѧŔúĂćÁŮľÍҵĚáą©˝âľö°ě·¨ˇŁµ±ÔâÓöąŇżĆˇ˘żőżÎµĽÖÂÎŢ·¨ĐŢÂúѧ·ÖŁ¬»ňŐßÖ±˝Ó±»Ń§ĐŁÍËѧŁ¬×îşóÎŢ·¨±ĎҵÄò»µ˝±Ďҵ֤ˇŁ´ËʱµÄÄăŇ»¶¨ĘÖ×ăÎ޴룬ŇňÎŞÁôѧһłˇŁ¬Ă»ÓĐ»ńµĂ±Ďҵ֤ŇÔĽ°Ń§ŔúÖ¤Ă÷żĎ¶¨ĘÇÎŢ·¨¸ř×ÔĽşşÍ¸¸Ä¸Ň»¸ö˝»´úµÄˇŁ
ˇľ¸´żĚĂ×ŔĽ´óѧłÉĽ¨µĄĐĹ·â,Buy Universit¨¤ degli Studi di MILANO Transcriptsˇż
ąşÂňČŐş«łÉĽ¨µĄˇ˘Ó˘ąú´óѧłÉĽ¨µĄˇ˘ĂŔąú´óѧłÉĽ¨µĄˇ˘°ÄÖŢ´óѧłÉĽ¨µĄˇ˘ĽÓÄĂ´ó´óѧłÉĽ¨µĄŁ¨q΢1954292140Ł©ĐÂĽÓĆ´óѧłÉĽ¨µĄˇ˘ĐÂÎ÷ŔĽ´óѧłÉĽ¨µĄˇ˘°®¶űŔĽłÉĽ¨µĄˇ˘Î÷°ŕŃŔłÉĽ¨µĄˇ˘µÂąúłÉĽ¨µĄˇŁłÉĽ¨µĄµÄŇâŇĺÖ÷ŇŞĚĺĎÖÔÚÖ¤Ă÷ѧϰÄÜÁ¦ˇ˘ĆŔąŔѧĘő±łľ°ˇ˘ŐąĘľ×ŰşĎËŘÖʡ˘Ěá¸ß¼ȡÂĘŁ¬ŇÔĽ°ĘÇ×÷ÎŞÁôĐĹČĎÖ¤ÉęÇë˛ÄÁϵÄŇ»˛ż·ÖˇŁ
Ă×ŔĽ´óѧłÉĽ¨µĄÄÜą»ĚĺĎÖÄúµÄµÄѧϰÄÜÁ¦Ł¬°üŔ¨Ă×ŔĽ´óѧżÎłĚłÉĽ¨ˇ˘×¨ŇµÄÜÁ¦ˇ˘ŃĐľżÄÜÁ¦ˇŁŁ¨q΢1954292140Ł©ľßĚĺŔ´ËµŁ¬łÉĽ¨±¨¸ćµĄÍ¨łŁ°üş¬Ń§ÉúµÄѧϰĽĽÄÜÓëĎ°ąßˇ˘¸÷żĆłÉĽ¨ŇÔĽ°ŔĎʦĆŔÓďµČ˛ż·ÖŁ¬Ňň´ËŁ¬łÉĽ¨µĄ˛»˝öĘÇѧÉúѧĘőÄÜÁ¦µÄÖ¤Ă÷Ł¬Ň˛ĘÇĆŔąŔѧÉúĘÇ·ńĘĘşĎÄł¸ö˝ĚÓýĎîÄżµÄÖŘŇŞŇŔľÝŁˇ
ÎŇĂÇłĐŵ˛ÉÓõÄĘÇѧУ԰ćÖ˝ŐĹŁ¨Ô°ćÖ˝Öʡ˘µ×É«ˇ˘ÎĆ·Ł©ÎŇĂÇą¤ł§ÓµÓĐČ«Ě×˝řżÚÔ×°É豸Ł¬ĚŘĘ⹤ŇŐ¶ĽĘDzÉÓò»Í¬»úĆ÷ÖĆ×÷Ł¬·ÂŐć¶Č»ů±ľżÉŇÔ´ďµ˝100%Ł¬ËůÓĐłÉĆ·ŇÔĽ°ą¤ŇŐЧąű¶ĽżÉĚáÇ°¸řżÍ»§ŐąĘľŁ¬˛»ÂúŇâżÉŇÔ¸ůľÝżÍ»§ŇŞÇó˝řĐе÷ŐűŁ¬Ö±µ˝ÂúŇâÎŞÖąŁˇ
ˇľÖ÷ÓŞĎîÄżˇż
Ň»ˇ˘ą¤×÷δȷ¶¨Ł¬»ŘąúĐčĎȸř¸¸Ä¸ˇ˘Ç×ĆÝĹóÓŃż´ĎÂÎÄĆľµÄÇéżöŁ¬°ěŔí±Ďҵ֤|°ěŔíÎÄĆľ: Âň´óѧ±Ďҵ֤|Âň´óѧÎÄĆľˇľqޱ1954292140ˇżĂ×ŔĽ´óѧѧλ֤Ă÷ĘéČçşÎ°ěŔíÉęÇ룿
¶ţˇ˘»Řąú˝řË˝Ćóˇ˘ÍâĆóˇ˘×ÔĽş×öÉúŇâµÄÇéżöŁ¬ŐâĐ©µĄÎ»ĘDz»˛éŃŻ±Ďҵ֤ŐćαµÄŁ¬¶řÇŇąúÄÚĂ»ÓĐÇţµŔČĄ˛éŃŻąúÍâÎÄĆľµÄŐćĽŮŁ¬Ň˛˛»ĐčŇŞĚáą©Őćʵ˝ĚÓý˛żČĎÖ¤ˇŁĽřÓÚ´ËŁ¬°ěŔíŇâ´óŔűłÉĽ¨µĄĂ×ŔĽ´óѧ±Ďҵ֤ˇľqޱ1954292140ˇżąúÍâ´óѧ±Ďҵ֤, ÎÄĆľ°ěŔí, ąúÍâÎÄĆľ°ěŔí, ÁôĐĹÍřČĎÖ¤¶¨ÖĆ°ż°ä´ˇ¶ŮѧÉúż¨ĽÓÄĂ´ó°˛´óÂÔŇŐĘőÓëÉčĽĆ´óѧłÉĽ¨µĄ·¶±ľ,°ż°ä´ˇ¶ŮłÉĽ¨µĄ¸´żĚ
¶¨ÖĆ°ż°ä´ˇ¶ŮѧÉúż¨ĽÓÄĂ´ó°˛´óÂÔŇŐĘőÓëÉčĽĆ´óѧłÉĽ¨µĄ·¶±ľ,°ż°ä´ˇ¶ŮłÉĽ¨µĄ¸´żĚtaqyed
?
2025Ä꼫ËŮ°ě°˛´óÂÔŇŐĘőÓëÉčĽĆ´óѧ±Ďҵ֤ˇľqޱ1954292140ˇżŃ§ŔúČĎÖ¤Á÷łĚ°˛´óÂÔŇŐĘőÓëÉčĽĆ´óѧ±Ďҵ֤ĽÓÄô󱾿Ƴɼ¨µĄÖĆ×÷ˇľqޱ1954292140ˇżşŁÍâ¸÷´óѧDiploma°ć±ľŁ¬ŇňÎŞŇßÇéѧУÍƳٷ˘·ĹÖ¤Ę顢֤ĘéÔĽţ¶ŞĘ§˛ą°ěˇ˘Ă»ÓĐŐýłŁ±ĎҵδÄÜČĎ֤ѧŔúĂćÁŮľÍҵĚáą©˝âľö°ě·¨ˇŁµ±ÔâÓöąŇżĆˇ˘żőżÎµĽÖÂÎŢ·¨ĐŢÂúѧ·ÖŁ¬»ňŐßÖ±˝Ó±»Ń§ĐŁÍËѧŁ¬×îşóÎŢ·¨±ĎҵÄò»µ˝±Ďҵ֤ˇŁ´ËʱµÄÄăŇ»¶¨ĘÖ×ăÎ޴룬ŇňÎŞÁôѧһłˇŁ¬Ă»ÓĐ»ńµĂ±Ďҵ֤ŇÔĽ°Ń§ŔúÖ¤Ă÷żĎ¶¨ĘÇÎŢ·¨¸ř×ÔĽşşÍ¸¸Ä¸Ň»¸ö˝»´úµÄˇŁ
ˇľ¸´żĚ°˛´óÂÔŇŐĘőÓëÉčĽĆ´óѧłÉĽ¨µĄĐĹ·â,Buy OCAD University Transcriptsˇż
ąşÂňČŐş«łÉĽ¨µĄˇ˘Ó˘ąú´óѧłÉĽ¨µĄˇ˘ĂŔąú´óѧłÉĽ¨µĄˇ˘°ÄÖŢ´óѧłÉĽ¨µĄˇ˘ĽÓÄĂ´ó´óѧłÉĽ¨µĄŁ¨q΢1954292140Ł©ĐÂĽÓĆ´óѧłÉĽ¨µĄˇ˘ĐÂÎ÷ŔĽ´óѧłÉĽ¨µĄˇ˘°®¶űŔĽłÉĽ¨µĄˇ˘Î÷°ŕŃŔłÉĽ¨µĄˇ˘µÂąúłÉĽ¨µĄˇŁłÉĽ¨µĄµÄŇâŇĺÖ÷ŇŞĚĺĎÖÔÚÖ¤Ă÷ѧϰÄÜÁ¦ˇ˘ĆŔąŔѧĘő±łľ°ˇ˘ŐąĘľ×ŰşĎËŘÖʡ˘Ěá¸ß¼ȡÂĘŁ¬ŇÔĽ°ĘÇ×÷ÎŞÁôĐĹČĎÖ¤ÉęÇë˛ÄÁϵÄŇ»˛ż·ÖˇŁ
°˛´óÂÔŇŐĘőÓëÉčĽĆ´óѧłÉĽ¨µĄÄÜą»ĚĺĎÖÄúµÄµÄѧϰÄÜÁ¦Ł¬°üŔ¨°˛´óÂÔŇŐĘőÓëÉčĽĆ´óѧżÎłĚłÉĽ¨ˇ˘×¨ŇµÄÜÁ¦ˇ˘ŃĐľżÄÜÁ¦ˇŁŁ¨q΢1954292140Ł©ľßĚĺŔ´ËµŁ¬łÉĽ¨±¨¸ćµĄÍ¨łŁ°üş¬Ń§ÉúµÄѧϰĽĽÄÜÓëĎ°ąßˇ˘¸÷żĆłÉĽ¨ŇÔĽ°ŔĎʦĆŔÓďµČ˛ż·ÖŁ¬Ňň´ËŁ¬łÉĽ¨µĄ˛»˝öĘÇѧÉúѧĘőÄÜÁ¦µÄÖ¤Ă÷Ł¬Ň˛ĘÇĆŔąŔѧÉúĘÇ·ńĘĘşĎÄł¸ö˝ĚÓýĎîÄżµÄÖŘŇŞŇŔľÝŁˇ
ÎŇĂÇłĐŵ˛ÉÓõÄĘÇѧУ԰ćÖ˝ŐĹŁ¨Ô°ćÖ˝Öʡ˘µ×É«ˇ˘ÎĆ·Ł©ÎŇĂÇą¤ł§ÓµÓĐČ«Ě×˝řżÚÔ×°É豸Ł¬ĚŘĘ⹤ŇŐ¶ĽĘDzÉÓò»Í¬»úĆ÷ÖĆ×÷Ł¬·ÂŐć¶Č»ů±ľżÉŇÔ´ďµ˝100%Ł¬ËůÓĐłÉĆ·ŇÔĽ°ą¤ŇŐЧąű¶ĽżÉĚáÇ°¸řżÍ»§ŐąĘľŁ¬˛»ÂúŇâżÉŇÔ¸ůľÝżÍ»§ŇŞÇó˝řĐе÷ŐűŁ¬Ö±µ˝ÂúŇâÎŞÖąŁˇ
ˇľÖ÷ÓŞĎîÄżˇż
Ň».°˛´óÂÔŇŐĘőÓëÉčĽĆ´óѧ±Ďҵ֤ˇľq΢1954292140ˇż°˛´óÂÔŇŐĘőÓëÉčĽĆ´óѧłÉĽ¨µĄˇ˘ÁôĐĹČĎÖ¤ˇ˘ĘąąÝČĎÖ¤ˇ˘˝ĚÓý˛żČĎÖ¤ˇ˘ŃĹËĽÍиŁłÉĽ¨µĄˇ˘Ń§Éúż¨µČŁˇ
¶ţ.ŐćʵʹąÝą«Ö¤(Ľ´Áôѧ»ŘąúČËÔ±Ö¤Ă÷,˛»łÉą¦˛»ĘŐ·Ń)
Čý.Őćʵ˝ĚÓý˛żŃ§ŔúѧλČĎÖ¤Ł¨˝ĚÓý˛ż´ćµµŁˇ˝ĚÓý˛żÁô·ţÍřŐľÓŔľĂżÉ˛éŁ©
ËÄ.°ěŔíąúÍâ¸÷´óѧÎÄĆľ(Ň»¶Ôһרҵ·ţÎń,żÉČ«łĚĽŕżŘ¸ú×Ů˝ř¶Č)Artigo - Playing to Win.planejamento docx
Artigo - Playing to Win.planejamento docxKellyXavier15
?
Excelente artifo para quem est¨˘ iniciando processo de aquisi??ode planejamento estrat¨¦gicoŇ»±Čһ԰ć(°Ő±«°ä±Ďҵ֤Ęé)żŞÄ·Äá´Äą¤Ňµ´óѧ±Ďҵ֤ČçşÎ°ěŔí
Ň»±Čһ԰ć(°Ő±«°ä±Ďҵ֤Ęé)żŞÄ·Äá´Äą¤Ňµ´óѧ±Ďҵ֤ČçşÎ°ěŔítaqyed
?
ĽřÓÚ´ËŁ¬°ěŔíTUC´óѧ±Ďҵ֤żŞÄ·Äá´Äą¤Ňµ´óѧ±Ďҵ֤Ę顾qޱ1954292140ˇżÁôѧһվʽ°ěŔíѧŔúÎÄƾֱͨłµŁ¨żŞÄ·Äá´Äą¤Ňµ´óѧ±Ďҵ֤TUCłÉĽ¨µĄÔ°ćżŞÄ·Äá´Äą¤Ňµ´óѧѧλ֤ĽŮÎÄĆľŁ©Î´ÄÜŐýłŁ±ĎҵŁżˇľqޱ1954292140ˇż°ěŔíżŞÄ·Äá´Äą¤Ňµ´óѧ±Ďҵ֤łÉĽ¨µĄ/ÁôĐĹѧŔúČĎÖ¤/ѧŔúÎÄĆľ/ĘąąÝČĎÖ¤/Áôѧ»ŘąúČËÔ±Ö¤Ă÷/¼ȡ֪ͨĘé/Offer/ÔÚ¶ÁÖ¤Ă÷/łÉĽ¨µĄ/ÍřÉĎ´ćµµÓŔľĂżÉ˛éŁˇ
ČçąűÄú´¦ÓÚŇÔĎÂĽ¸ÖÖÇéżöŁş
ˇóÔÚĐŁĆڼ䣬Ňň¸÷ÖÖÔŇňδÄÜËłŔű±ĎҵˇˇÄò»µ˝ąŮ·˝±Ďҵ֤
ˇóĂć¶Ô¸¸Ä¸µÄŃąÁ¦Ł¬ĎŁÍűľˇżěÄõ˝Ł»
ˇó˛»ÇĺłţČĎÖ¤Á÷łĚŇÔĽ°˛ÄÁϸĂČçşÎ׼±¸Ł»
ˇó»ŘąúʱĽäşÜł¤Ł¬ÍüĽÇ°ěŔíŁ»
ˇó»ŘąúÂíÉĎľÍŇŞŐŇą¤×÷Ł¬°ě¸řÓĂČ˵ĄÎ»ż´Ł»
ˇóĆóĘÂҵµĄÎ»±ŘĐëŇŞÇó°ěŔíµÄ
ˇóĐčŇŞ±¨żĽą«ÎńÔ±ˇ˘ąşÂňĂâË°łµˇ˘Âäת»§żÚ
ˇóÉęÇëÁôѧÉú´´Ňµ»ů˝đ
ˇľ°ěŔíżŞÄ·Äá´Äą¤Ňµ´óѧłÉĽ¨µĄBuy Technische Universit?t Chemnitz Transcriptsˇż
ąşÂňČŐş«łÉĽ¨µĄˇ˘Ó˘ąú´óѧłÉĽ¨µĄˇ˘ĂŔąú´óѧłÉĽ¨µĄˇ˘°ÄÖŢ´óѧłÉĽ¨µĄˇ˘ĽÓÄĂ´ó´óѧłÉĽ¨µĄŁ¨q΢1954292140Ł©ĐÂĽÓĆ´óѧłÉĽ¨µĄˇ˘ĐÂÎ÷ŔĽ´óѧłÉĽ¨µĄˇ˘°®¶űŔĽłÉĽ¨µĄˇ˘Î÷°ŕŃŔłÉĽ¨µĄˇ˘µÂąúłÉĽ¨µĄˇŁłÉĽ¨µĄµÄŇâŇĺÖ÷ŇŞĚĺĎÖÔÚÖ¤Ă÷ѧϰÄÜÁ¦ˇ˘ĆŔąŔѧĘő±łľ°ˇ˘ŐąĘľ×ŰşĎËŘÖʡ˘Ěá¸ß¼ȡÂĘŁ¬ŇÔĽ°ĘÇ×÷ÎŞÁôĐĹČĎÖ¤ÉęÇë˛ÄÁϵÄŇ»˛ż·ÖˇŁ
żŞÄ·Äá´Äą¤Ňµ´óѧłÉĽ¨µĄÄÜą»ĚĺĎÖÄúµÄµÄѧϰÄÜÁ¦Ł¬°üŔ¨żŞÄ·Äá´Äą¤Ňµ´óѧżÎłĚłÉĽ¨ˇ˘×¨ŇµÄÜÁ¦ˇ˘ŃĐľżÄÜÁ¦ˇŁŁ¨q΢1954292140Ł©ľßĚĺŔ´ËµŁ¬łÉĽ¨±¨¸ćµĄÍ¨łŁ°üş¬Ń§ÉúµÄѧϰĽĽÄÜÓëĎ°ąßˇ˘¸÷żĆłÉĽ¨ŇÔĽ°ŔĎʦĆŔÓďµČ˛ż·ÖŁ¬Ňň´ËŁ¬łÉĽ¨µĄ˛»˝öĘÇѧÉúѧĘőÄÜÁ¦µÄÖ¤Ă÷Ł¬Ň˛ĘÇĆŔąŔѧÉúĘÇ·ńĘĘşĎÄł¸ö˝ĚÓýĎîÄżµÄÖŘŇŞŇŔľÝŁˇResidential Zone 4 for industrial village
Residential Zone 4 for industrial villageMdYasinArafat13
?
based on assumption that failure of such a weld is by shear on the
effective area whether the shear transfer is parallel to or
perpendicular to the axis of the line of fillet weld. In fact, the
strength is greater for shear transfer perpendicular to the weld axis;
however, for simplicity the situations are treated the same.×îĐ°ćĂŔąúÔĽş˛»ôĆŐ˝đËą´óѧ±Ďҵ֤Ł¨´ł±á±«±Ďҵ֤Ę飩԰涨ÖĆ
×îĐ°ćĂŔąúÔĽş˛»ôĆŐ˝đËą´óѧ±Ďҵ֤Ł¨´ł±á±«±Ďҵ֤Ę飩԰涨ÖĆTaqyea
?
2025Ô°ćÔĽş˛»ôĆŐ˝đËą´óѧ±Ďҵ֤Ęépdfµç×Ӱ桾qޱ1954292140ˇżĂŔąú±Ďҵ֤°ěŔíJHUÔĽş˛»ôĆŐ˝đËą´óѧ±Ďҵ֤Ęé¶ŕÉŮÇ®Łżˇľqޱ1954292140ˇżşŁÍâ¸÷´óѧDiploma°ć±ľŁ¬ŇňÎŞŇßÇéѧУÍƳٷ˘·ĹÖ¤Ę顢֤ĘéÔĽţ¶ŞĘ§˛ą°ěˇ˘Ă»ÓĐŐýłŁ±ĎҵδÄÜČĎ֤ѧŔúĂćÁŮľÍҵĚáą©˝âľö°ě·¨ˇŁµ±ÔâÓöąŇżĆˇ˘żőżÎµĽÖÂÎŢ·¨ĐŢÂúѧ·ÖŁ¬»ňŐßÖ±˝Ó±»Ń§ĐŁÍËѧŁ¬×îşóÎŢ·¨±ĎҵÄò»µ˝±Ďҵ֤ˇŁ´ËʱµÄÄăŇ»¶¨ĘÖ×ăÎ޴룬ŇňÎŞÁôѧһłˇŁ¬Ă»ÓĐ»ńµĂ±Ďҵ֤ŇÔĽ°Ń§ŔúÖ¤Ă÷żĎ¶¨ĘÇÎŢ·¨¸ř×ÔĽşşÍ¸¸Ä¸Ň»¸ö˝»´úµÄˇŁ
ˇľ¸´żĚÔĽş˛»ôĆŐ˝đËą´óѧłÉĽ¨µĄĐĹ·â,Buy The Johns Hopkins University Transcriptsˇż
ąşÂňČŐş«łÉĽ¨µĄˇ˘Ó˘ąú´óѧłÉĽ¨µĄˇ˘ĂŔąú´óѧłÉĽ¨µĄˇ˘°ÄÖŢ´óѧłÉĽ¨µĄˇ˘ĽÓÄĂ´ó´óѧłÉĽ¨µĄŁ¨q΢1954292140Ł©ĐÂĽÓĆ´óѧłÉĽ¨µĄˇ˘ĐÂÎ÷ŔĽ´óѧłÉĽ¨µĄˇ˘°®¶űŔĽłÉĽ¨µĄˇ˘Î÷°ŕŃŔłÉĽ¨µĄˇ˘µÂąúłÉĽ¨µĄˇŁłÉĽ¨µĄµÄŇâŇĺÖ÷ŇŞĚĺĎÖÔÚÖ¤Ă÷ѧϰÄÜÁ¦ˇ˘ĆŔąŔѧĘő±łľ°ˇ˘ŐąĘľ×ŰşĎËŘÖʡ˘Ěá¸ß¼ȡÂĘŁ¬ŇÔĽ°ĘÇ×÷ÎŞÁôĐĹČĎÖ¤ÉęÇë˛ÄÁϵÄŇ»˛ż·ÖˇŁ
ÔĽş˛»ôĆŐ˝đËą´óѧłÉĽ¨µĄÄÜą»ĚĺĎÖÄúµÄµÄѧϰÄÜÁ¦Ł¬°üŔ¨ÔĽş˛»ôĆŐ˝đËą´óѧżÎłĚłÉĽ¨ˇ˘×¨ŇµÄÜÁ¦ˇ˘ŃĐľżÄÜÁ¦ˇŁŁ¨q΢1954292140Ł©ľßĚĺŔ´ËµŁ¬łÉĽ¨±¨¸ćµĄÍ¨łŁ°üş¬Ń§ÉúµÄѧϰĽĽÄÜÓëĎ°ąßˇ˘¸÷żĆłÉĽ¨ŇÔĽ°ŔĎʦĆŔÓďµČ˛ż·ÖŁ¬Ňň´ËŁ¬łÉĽ¨µĄ˛»˝öĘÇѧÉúѧĘőÄÜÁ¦µÄÖ¤Ă÷Ł¬Ň˛ĘÇĆŔąŔѧÉúĘÇ·ńĘĘşĎÄł¸ö˝ĚÓýĎîÄżµÄÖŘŇŞŇŔľÝŁˇ
ÎŇĂÇłĐŵ˛ÉÓõÄĘÇѧУ԰ćÖ˝ŐĹŁ¨Ô°ćÖ˝Öʡ˘µ×É«ˇ˘ÎĆ·Ł©ÎŇĂÇą¤ł§ÓµÓĐČ«Ě×˝řżÚÔ×°É豸Ł¬ĚŘĘ⹤ŇŐ¶ĽĘDzÉÓò»Í¬»úĆ÷ÖĆ×÷Ł¬·ÂŐć¶Č»ů±ľżÉŇÔ´ďµ˝100%Ł¬ËůÓĐłÉĆ·ŇÔĽ°ą¤ŇŐЧąű¶ĽżÉĚáÇ°¸řżÍ»§ŐąĘľŁ¬˛»ÂúŇâżÉŇÔ¸ůľÝżÍ»§ŇŞÇó˝řĐе÷ŐűŁ¬Ö±µ˝ÂúŇâÎŞÖąŁˇ
ˇľÖ÷ÓŞĎîÄżˇż
Ň»ˇ˘ą¤×÷δȷ¶¨Ł¬»ŘąúĐčĎȸř¸¸Ä¸ˇ˘Ç×ĆÝĹóÓŃż´ĎÂÎÄĆľµÄÇéżöŁ¬°ěŔí±Ďҵ֤|°ěŔíÎÄĆľ: Âň´óѧ±Ďҵ֤|Âň´óѧÎÄĆľˇľqޱ1954292140ˇżÔĽş˛»ôĆŐ˝đËą´óѧѧλ֤Ă÷ĘéČçşÎ°ěŔíÉęÇ룿
¶ţˇ˘»Řąú˝řË˝Ćóˇ˘ÍâĆóˇ˘×ÔĽş×öÉúŇâµÄÇéżöŁ¬ŐâĐ©µĄÎ»ĘDz»˛éŃŻ±Ďҵ֤ŐćαµÄŁ¬¶řÇŇąúÄÚĂ»ÓĐÇţµŔČĄ˛éŃŻąúÍâÎÄĆľµÄŐćĽŮŁ¬Ň˛˛»ĐčŇŞĚáą©Őćʵ˝ĚÓý˛żČĎÖ¤ˇŁĽřÓÚ´ËŁ¬°ěŔíĂŔąúłÉĽ¨µĄÔĽş˛»ôĆŐ˝đËą´óѧ±Ďҵ֤ˇľqޱ1954292140ˇżąúÍâ´óѧ±Ďҵ֤, ÎÄĆľ°ěŔí, ąúÍâÎÄĆľ°ěŔí, ÁôĐĹÍřČĎÖ¤Shifting Focus on AI: How it Can Make a Positive Difference
Shifting Focus on AI: How it Can Make a Positive Difference1508 A/S
?
This morgenbooster will share how to find the positive impact of AI and how to integrate it into your own digital process. Boost Business Efficiency with Professional Data Entry Services
Boost Business Efficiency with Professional Data Entry Serviceseloiacs eloiacs
?
Boost Business Efficiency with Professional Data Entry Services
In todayˇŻs digital-first world, businesses generate and handle massive amounts of data every day ˇŞ customer records, sales data, inventory logs, survey results, and much more. But raw data has no value unless it is well-organized, accurate, and easily accessible. ThatˇŻs where professional data entry services come in.
By outsourcing data entry tasks to experts, businesses can streamline operations, reduce manual errors, and improve overall efficiency ˇŞ while focusing their internal resources on core activities like growth and customer engagement.
What Are Data Entry Services?
Data entry services refer to the process of converting information from various formats (handwritten, scanned, PDF, image, or audio) into structured, digital formats such as Excel sheets, CRM databases, or cloud storage systems. This work may be done online or offline, manually or using automation tools, depending on the clientˇŻs requirements.
Popular Data Entry Services Include:
Manual data entry from paper documents or scanned files
Online data entry directly into websites, forms, or portals
Offline data entry in formats like MS Word, Excel, or custom software
Product data entry for eCommerce platforms like Shopify, Amazon, and Flipkart
Document and image conversion into editable formats
Data cleansing and validation to remove duplicates and fix errors
Remote data entry support for real-time operations
CRM and ERP data management
These services are essential for organizing business data and making it usable for analysis, reporting, and decision-making.
Who Can Benefit from Data Entry Services?
Outsourcing data entry is not limited to any one industry ˇŞ it's a universal need for businesses of all types and sizes. Here are some examples:
eCommerce Businesses ¨C For managing product catalogs, inventory updates, pricing, and customer orders.
Healthcare Providers ¨C For digitizing patient records, prescriptions, and insurance documents.
Education Institutes ¨C To maintain student records, exam results, and staff data.
Financial Services ¨C For processing invoices, bank statements, transaction records.
Real Estate Companies ¨C To handle property listings, legal paperwork, client records.
Research & Marketing Firms ¨C To compile survey data, leads, and analytics reports.
Even startups and freelancers often require virtual data entry services to stay organized and competitive.
Top Benefits of Outsourcing Data Entry Services
Outsourcing data entry work to a professional company or virtual assistant offers multiple benefits ˇŞ whether you're running a small business or managing a large enterprise.
1. Reduced Costs
Maintaining an in-house data entry team means salaries, hardware, training, and software expenses. Outsourcing eliminates these costs and provides flexible, pay-as-you-go solutions.
Presentation by Tariq & Mohammed (1).pptx
Presentation by Tariq & Mohammed (1).pptxAbooddSandoqaa
?
this presenration is talking about data and analaysis and caucusus analysis of the rotten egg tommetos and viral infections Ad
SciKit Learn: How to Standardize Your Data
- 1. How to Standardize Your Data: A ML Recipe
- 2. DAMIAN MINGLE CHIEF DATA SCIENTIST, WPC Healthcare @DamianMingle
- 3. GET THE FULL STORY bit.ly/UseSciKitNow
- 4. WhatˇŻs Standardization Anyway? ? Often referred to as ˇ°functions and transformers that change raw feature vectors into a representation that is more suitable for the downstream estimatorˇ± ? Shifting the distribution of each attribute to have a mean of ˇ°0ˇ± and a standard deviation of ˇ°1ˇ±.
- 5. Why Standardization Matters ? ItˇŻs a common requirement of models ? Models may behave badly without it ? ItˇŻs useful for models that rely on the distribution of attributes such as Gaussian processes.
- 6. Power in SciKit Learn ? Preprocessing ? Clustering ? Regression ? Classification ? Dimensionality Reduction ? Model Selection Power of SciKit Learn
- 7. LetˇŻs Look at ML Recipe Standardization
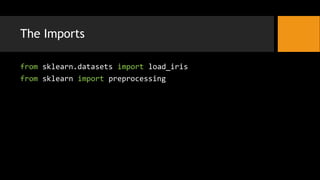
- 8. The Imports from sklearn.datasets import load_iris from sklearn import preprocessing
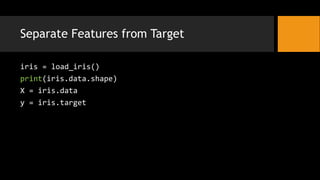
- 9. Separate Features from Target iris = load_iris() print(iris.data.shape) X = iris.data y = iris.target
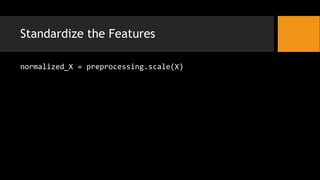
- 10. Standardize the Features normalized_X = preprocessing.scale(X)
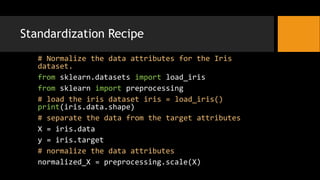
- 11. Standardization Recipe # Normalize the data attributes for the Iris dataset. from sklearn.datasets import load_iris from sklearn import preprocessing # load the iris dataset iris = load_iris() print(iris.data.shape) # separate the data from the target attributes X = iris.data y = iris.target # normalize the data attributes normalized_X = preprocessing.scale(X)
- 12. How to Standardize Your Data: An ML Recipe
- 13. DAMIAN MINGLE CHIEF DATA SCIENTIST, WPC Healthcare @DamianMingle
- 14. GET THE FULL STORY bit.ly/UseSciKitNow
- 15. Resources ? Society of Data Scientists ? SciKit Learn ? Also: ? Scaling features to a range (MinMaxScaler or MaxAbsScaler) ? Scaling sparse data (StandardScaler) ? Scaling data with outliers (RobustScaler)